

作者:计算机毕业设计杰瑞
个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小应用、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小软件、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
想说的话:感谢大家的关注与支持!
网站实战工程
安卓/小程序实战项目
大数据实战项目
深度学校实战项目
计算机毕业设计选题推荐
目录
基于大数据的睡眠中人体压力资料可视化分析系统介绍
本系统是一套面向睡眠健康领域的大数据分析平台,凭借Hadoop分布式存储和Spark计算引擎处理海量睡眠监测数据。体系采用Django作为后端框架,结合Vue+ElementUI+Echarts构建可视化前端界面,实现对睡眠过程中人体压力数据的深度挖掘。核心功能涵盖压力水平指标均值分析、生理指标关联度分析、睡眠压力水平分布分析以及综合健康指数趋势分析四大模块。系统利用Spark SQL对HDFS存储的压力数据进行快速查询,凭借Pandas和NumPy完成数据清洗与统计计算,最终以Echarts图表形式呈现分析结果。整个架构充分发挥大内容框架在处理大规模时序数据方面的优势,为用户提供睡眠质量评估和健康趋势预测的技术支撑,同时系统预留了个人信息管理和密码修改等基础功能,保障数据安全与用户体验。
基于大素材的睡眠中人体压力信息可视化分析环境演示视频
【数据分析】基于大材料的睡眠中人体压力素材可视化分析架构 | 大数据毕设实战计划 数据可视化大屏 选题推荐 文档指导 Hadoop SPark java
基于大素材的睡眠中人体压力数据可视化分析框架演示图片


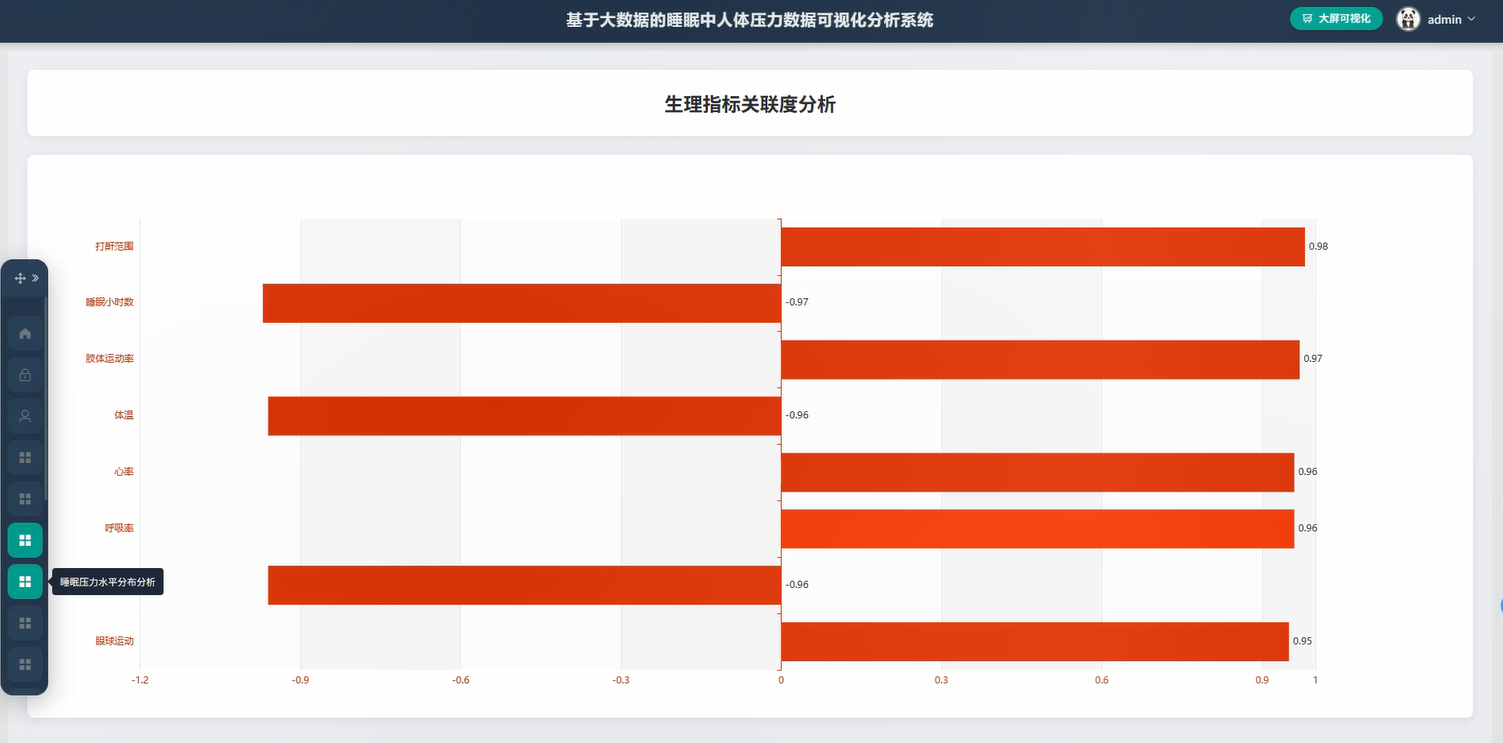


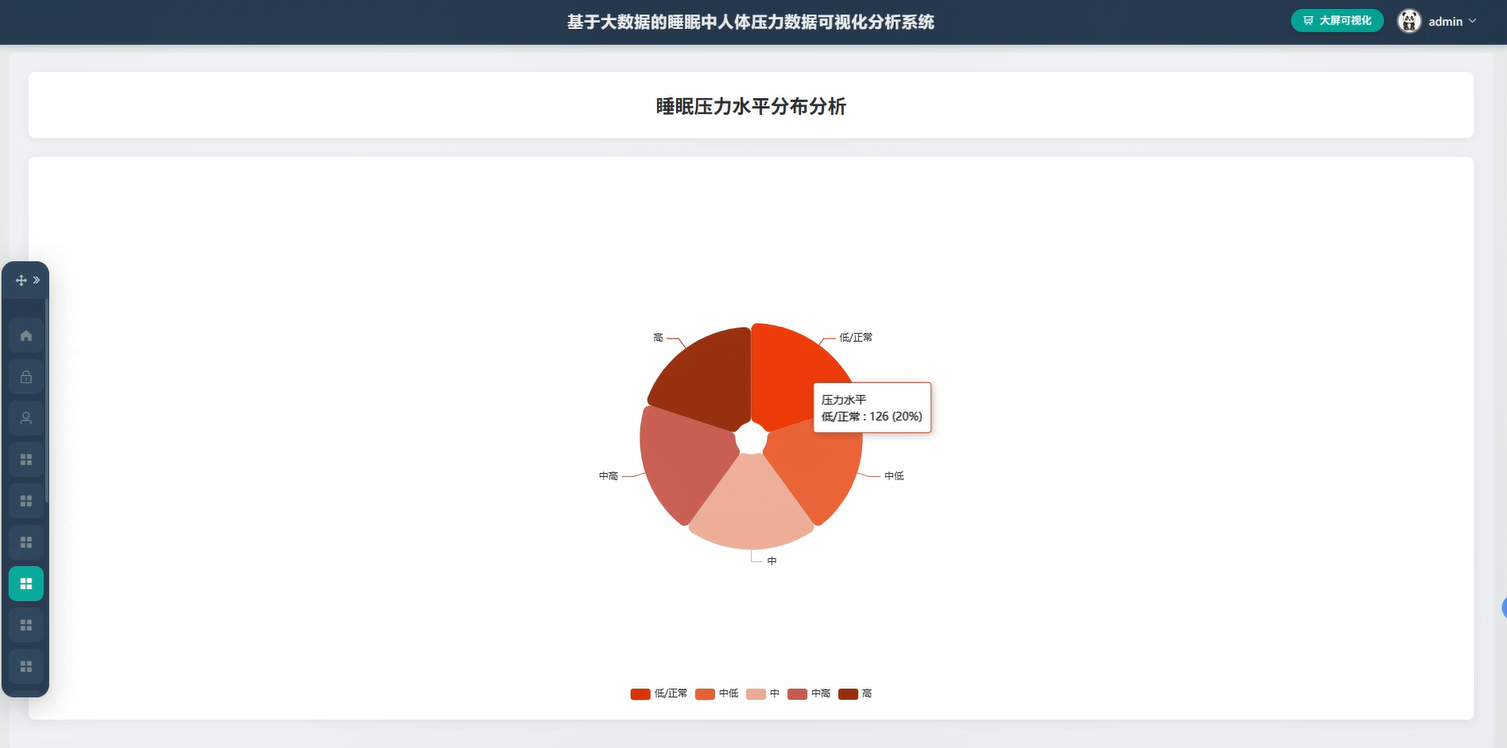
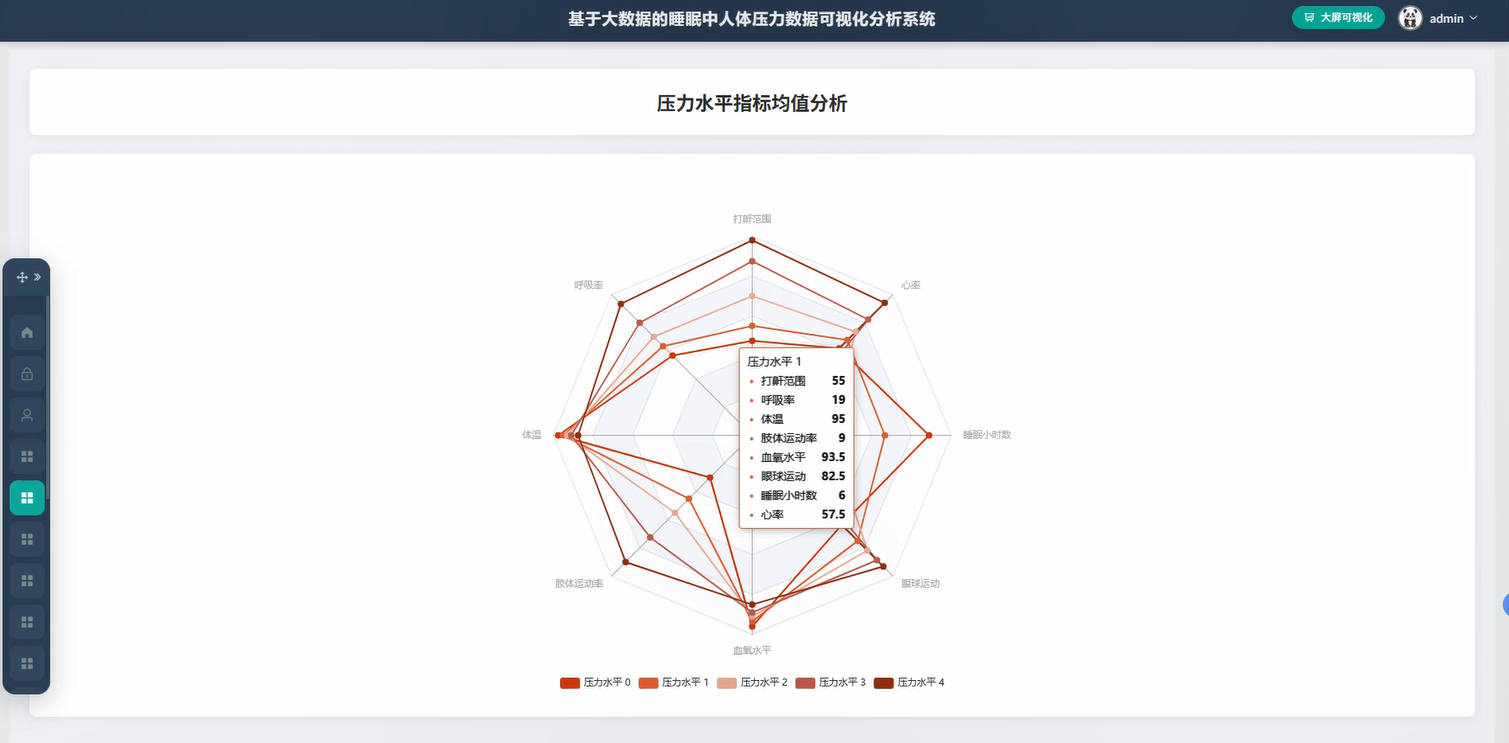

基于大数据的睡眠中人体压力数据可视化分析系统代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, stddev, corr, count, col, when
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from django.http import JsonResponse
from django.views.decorators.http import require_http_methods
import json
spark = SparkSession.builder.appName("SleepPressureAnalysis").config("spark.sql.warehouse.dir", "/user/hive/warehouse").config("spark.executor.memory", "2g").config("spark.driver.memory", "1g").getOrCreate()
@require_http_methods(["POST"])
def pressure_level_avg_analysis(request):
try:
params = json.loads(request.body)
start_date = params.get('start_date')
end_date = params.get('end_date')
user_id = params.get('user_id')
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/sleep_data/pressure_records.csv")
filtered_df = df.filter((col("record_date") >= start_date) & (col("record_date") <= end_date) & (col("user_id") == user_id))
avg_result = filtered_df.groupBy("sleep_stage").agg(avg("pressure_value").alias("avg_pressure"),stddev("pressure_value").alias("std_pressure"),count("pressure_value").alias("sample_count"))
result_list = avg_result.collect()
data_dict = {}
for row in result_list:
stage = row['sleep_stage']
data_dict[stage] = {"avg_pressure": round(row['avg_pressure'], 2),"std_pressure": round(row['std_pressure'], 2) if row['std_pressure'] else 0,"sample_count": row['sample_count']}
return JsonResponse({"code": 200, "message": "分析成功", "data": data_dict})
except Exception as e:
return JsonResponse({"code": 500, "message": f"分析失败: {str(e)}"})
@require_http_methods(["POST"])
def physiological_correlation_analysis(request):
try:
params = json.loads(request.body)
user_id = params.get('user_id')
date_range = params.get('date_range', 30)
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/sleep_data/physiological_records.csv")
user_df = df.filter(col("user_id") == user_id).limit(date_range * 480)
correlation_pressure_heartrate = user_df.stat.corr("pressure_value", "heart_rate")
correlation_pressure_breath = user_df.stat.corr("pressure_value", "breath_rate")
correlation_pressure_movement = user_df.stat.corr("pressure_value", "movement_intensity")
correlation_heartrate_breath = user_df.stat.corr("heart_rate", "breath_rate")
high_pressure_df = user_df.filter(col("pressure_value") > 80)
high_pressure_stats = high_pressure_df.agg(avg("heart_rate").alias("avg_hr_high_pressure"),avg("breath_rate").alias("avg_br_high_pressure"),avg("movement_intensity").alias("avg_movement_high_pressure"))
low_pressure_df = user_df.filter(col("pressure_value") < 40)
low_pressure_stats = low_pressure_df.agg(avg("heart_rate").alias("avg_hr_low_pressure"),avg("breath_rate").alias("avg_br_low_pressure"),avg("movement_intensity").alias("avg_movement_low_pressure"))
high_stats = high_pressure_stats.collect()[0]
low_stats = low_pressure_stats.collect()[0]
result_data = {"correlation_matrix": {"pressure_heartrate": round(correlation_pressure_heartrate, 3),"pressure_breath": round(correlation_pressure_breath, 3),"pressure_movement": round(correlation_pressure_movement, 3),"heartrate_breath": round(correlation_heartrate_breath, 3)},"high_pressure_condition": {"avg_heart_rate": round(high_stats['avg_hr_high_pressure'], 2) if high_stats['avg_hr_high_pressure'] else 0,"avg_breath_rate": round(high_stats['avg_br_high_pressure'], 2) if high_stats['avg_br_high_pressure'] else 0,"avg_movement": round(high_stats['avg_movement_high_pressure'], 2) if high_stats['avg_movement_high_pressure'] else 0},"low_pressure_condition": {"avg_heart_rate": round(low_stats['avg_hr_low_pressure'], 2) if low_stats['avg_hr_low_pressure'] else 0,"avg_breath_rate": round(low_stats['avg_br_low_pressure'], 2) if low_stats['avg_br_low_pressure'] else 0,"avg_movement": round(low_stats['avg_movement_low_pressure'], 2) if low_stats['avg_movement_low_pressure'] else 0}}
return JsonResponse({"code": 200, "message": "关联分析完成", "data": result_data})
except Exception as e:
return JsonResponse({"code": 500, "message": f"关联分析失败: {str(e)}"})
@require_http_methods(["POST"])
def health_index_trend_analysis(request):
try:
params = json.loads(request.body)
user_id = params.get('user_id')
days = params.get('days', 30)
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/sleep_data/daily_health_index.csv")
user_df = df.filter(col("user_id") == user_id).orderBy(col("record_date").desc()).limit(days)
user_df = user_df.withColumn("pressure_score", when(col("avg_pressure") < 40, 90).when((col("avg_pressure") >= 40) & (col("avg_pressure") < 60), 75).when((col("avg_pressure") >= 60) & (col("avg_pressure") < 80), 60).otherwise(40))
user_df = user_df.withColumn("sleep_quality_score", when(col("deep_sleep_ratio") > 0.25, 90).when((col("deep_sleep_ratio") >= 0.15) & (col("deep_sleep_ratio") <= 0.25), 70).otherwise(50))
user_df = user_df.withColumn("health_index", (col("pressure_score") * 0.4 + col("sleep_quality_score") * 0.6))
window_spec = Window.orderBy("record_date").rowsBetween(-6, 0)
user_df = user_df.withColumn("moving_avg_health_index", F.avg("health_index").over(window_spec))
user_df = user_df.withColumn("trend_direction", when(col("moving_avg_health_index") > F.lag("moving_avg_health_index", 1).over(Window.orderBy("record_date")), "上升").when(col("moving_avg_health_index") < F.lag("moving_avg_health_index", 1).over(Window.orderBy("record_date")), "下降").otherwise("平稳"))
result_rows = user_df.select("record_date", "health_index", "moving_avg_health_index", "trend_direction", "pressure_score", "sleep_quality_score").orderBy("record_date").collect()
trend_data = []
for row in result_rows:
trend_data.append({"date": str(row['record_date']),"health_index": round(row['health_index'], 2),"moving_avg": round(row['moving_avg_health_index'], 2) if row['moving_avg_health_index'] else 0,"trend": row['trend_direction'],"pressure_score": round(row['pressure_score'], 2),"sleep_quality_score": round(row['sleep_quality_score'], 2)})
overall_avg = user_df.agg(avg("health_index").alias("overall_avg")).collect()[0]['overall_avg']
return JsonResponse({"code": 200, "message": "趋势分析完成", "data": {"trend_list": trend_data, "overall_avg_index": round(overall_avg, 2) if overall_avg else 0}})
except Exception as e:
return JsonResponse({"code": 500, "message": f"趋势分析失败: {str(e)}"})基于大数据的睡眠中人体压力素材可视化分析系统文档展示

作者:计算机毕业设计杰瑞
个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大内容、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化研发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流科技,大家有科技代码这一块的疑问允许问我!
想说的话:感谢大家的关注与支持!
网站实战任务
安卓/小程序实战项目
大内容实战项目
深度学校实战方案
计算机毕业设计选题推荐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号