爬虫之路: 字体文件反爬一
前言
今天就来记录一下破解汽车之家的字体反爬, 完整代码在末尾
分析页面
首先我们看一下页面显示, 全都是""
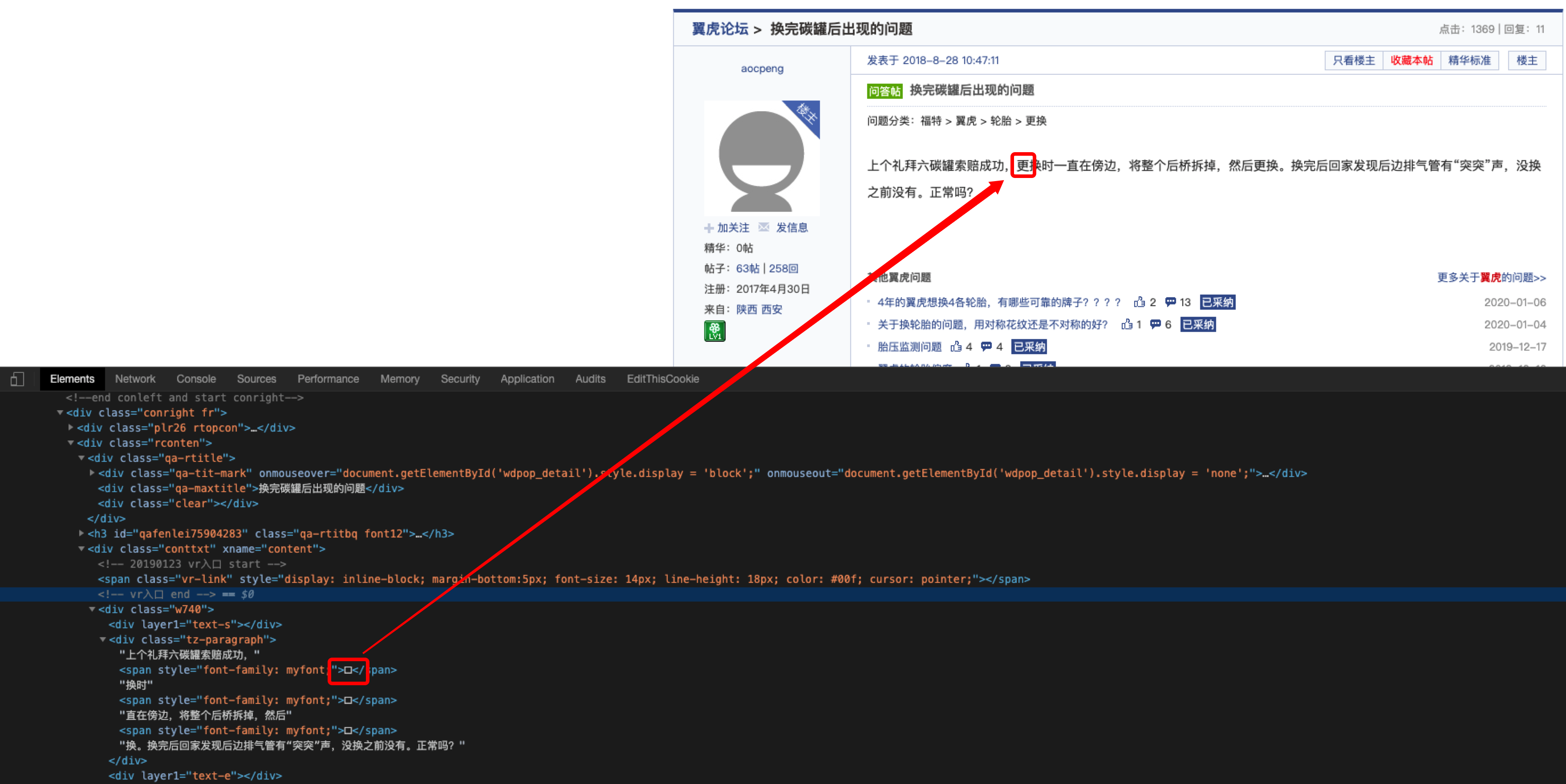
在查看下源码, 显示的是""

很明显的字体反爬, 接下来我们就一步步来揭开字体文件的神秘面纱
查看字体文件
首先将字体文件下载到本地
使用在线工具查看字体文件内容, 在线查看地址
打开看一下, 有没有很眼熟这个编码, 这不就是上面源码里的编码嘛

破解字体文件
使用fontTools来处理字体文件
# 安装fonttools pip3 install fonttools
读取字体编码表
# 解析字体库 font = TTFont('ChcCQ1sUz1WATUkcAABj5B4DyuQ43..ttff') # 读取字体编码的列表 uni_list = font.getGlyphOrder() print(uni_list)
输出:(第一个是空白字符, 下面会切除掉)
['.notdef', 'uniEDD2', 'uniEC30', 'uniED71', 'uniECBD', 'uniED0F', 'uniEC5C', 'uniED9C', 'uniEDEE', 'uniED3B', 'uniED8D', 'uniECD9', 'uniEC26', 'uniEC78', 'uniEDB8', 'uniED05', 'uniED57', 'uniECA3', 'uniECF5', 'uniEC42', 'uniED82', 'uniEDD4', 'uniED21', 'uniEC6D', 'uniECBF', 'uniEE00', 'uniEC5D', 'uniED9E', 'uniECEB', 'uniED3C', 'uniEC89', 'uniEDCA', 'uniEC27', 'uniED68', 'uniEDBA', 'uniED06', 'uniEC53', 'uniECA5', 'uniEDE5']
制作字体和文字的映射表
必备条件是, 需要先手写一个文字的列表(就是不知道怎么自动获取这个列表, 求指教)
word_list = [ "坏", "少", "远", "大", "九", "左", "近", "呢", "十", "高", "着", "矮", "八", "二", "右", "是", "得", "的", "小", "短", "很", "一", "了", "地", "好", "多", "七", "不", "长", "低", "三", "五", "六", "下", "更", "和", "四", "上" ] # 处理字体编码 utf_list = [uni[3:].lower() for uni in uni_list[1:]] # 编码和字体映射表 utf_word_map = dict(zip(utf_list, word_list))
替换源码, 提取内容
这里使用的是先替换源码, 在提取内容
# 请求内容 response = requests.get(url, headers=headers) html = response.text for utf_code, word in utf_word_map.items(): html = html.replace("&#x%s;" % utf_code, word) # 使用xpath 获取 主贴 xp_html = etree.HTML(html) subject_text = ''.join(xp_html.xpath('//div[@xname="content"]//div[@class="tz-paragraph"]//text()')) print(subject_text)
输出, 字体破解成功
上个礼拜六碳罐索赔成功,更换时一直在傍边,将整个后桥拆掉,然后更换。换完后回家发现后边排气管有“突突”声,没换之前没有。正常吗?
本页源码
# -*- coding: utf-8 -*- # @Author: Mehaei # @Date: 2020-01-09 10:01:59 # @Last Modified by: Mehaei # @Last Modified time: 2020-01-10 11:52:19 import re import requests from lxml import etree from fontTools.ttLib import TTFont class NotFoundFontFileUrl(Exception): pass class CarHomeFont(object): def __init__(self, url, *args, **kwargs): self.download_ttf_name = 'norm_font.ttf' self._download_ttf_file(url) self._making_code_map() def _download_ttf_file(self, url): self.page_html = self.download(url) or "" # 获取字体的连接文件 font_file_name = (re.findall(r",url\('(//.*\.ttf)?'\) format", self.page_html) or [""])[0] if not font_file_name: raise NotFoundFontFileUrl("not found font file name") # 下载字体文件 file_content = self.download("https:%s" % font_file_name, content=True) # 讲字体文件保存到本地 with open(self.download_ttf_name, 'wb') as f: f.write(file_content) print("font file download success") def _making_code_map(self): font = TTFont(self.download_ttf_name) uni_list = font.getGlyphOrder() # 转换格式 utf_list = [uni[3:].lower() for uni in uni_list[1:]] # 被替换的字体的列表 word_list = [ "坏", "少", "远", "大", "九", "左", "近", "呢", "十", "高", "着", "矮", "八", "二", "右", "是", "得", "的", "小", "短", "很", "一", "了", "地", "好", "多", "七", "不", "长", "低", "三", "五", "六", "下", "更", "和", "四", "上" ] self.utf_word_map = dict(zip(utf_list, word_list)) def repalce_source_code(self): replaced_html = self.page_html for utf_code, word in self.utf_word_map.items(): replaced_html = replaced_html.replace("&#x%s;" % utf_code, word) return replaced_html def get_subject_content(self): normal_html = self.repalce_source_code() # 使用xpath 获取 主贴 xp_html = etree.HTML(normal_html) subject_text = ''.join(xp_html.xpath('//div[@xname="content"]//div[@class="tz-paragraph"]//text()')) return subject_text def download(self, url, *args, try_time=5, method="GET", content=False, **kwargs): kwargs.setdefault("headers", {}) kwargs["headers"].update({"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}) while try_time: try: response = requests.request(method.upper(), url, *args, **kwargs) if response.ok: if content: return response.content return response.text else: continue except Exception as e: try_time -= 1 print("download error: %s" % e) if __name__ == "__main__": url = "https://club.autohome.com.cn/bbs/thread/62c48ae0f0ae73ef/75904283-1.html" car = CarHomeFont(url) text = car.get_subject_content() print(text)
后续
到这里本以为就已经结束了, 却发现, 这个爬虫只能在这一页使用, 再换一页还是输出乱码
下一篇就来讲讲如何解决这种情况
点击这里查看, 动态字体文件破解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号