mit6.824课程笔记
欢迎来到我的MIT6.824(分布式系统)学习笔记
资源分享
关于课堂笔记请看: Lecture 12 - Distributed Transaction | MIT6.824
分布式系统简介
6 lab简介
-
Lab 1: 分布式大数据框架 (如 MapReduce)
-
实验 2: 使用复制的容错库 (Raft)
-
实验 3: 一个简单的容错数据库
-
实验 4: 通过分片实现可伸缩的数据库性能


7 三种基础架构:
- 存储
- 通信
- 计算
通信是实现分布式系统的工具, 保证可靠性
大目标: 我们想要把分布式的存储和计算的逻辑抽象封装成简单易用的接口, 就像在单个主机下操作文件系统一样简单
8 考虑的主题(目标)
在对基础架构抽象的过程中需要考虑的一些主题:
-
例如RPC: 就是将我们底层通过不可靠⽹络进⾏通信这个事实进⾏隐藏,
-
通信还需要考虑多线程并发, 锁等
-
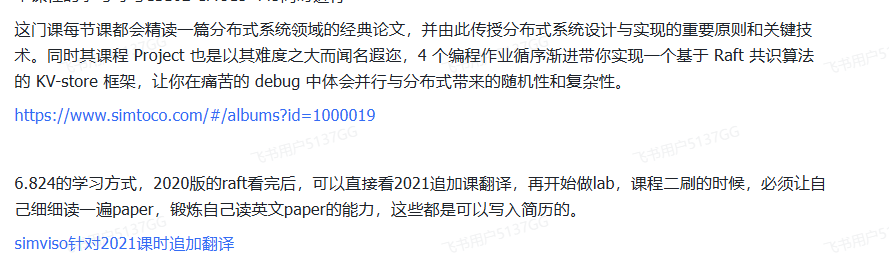
通过可拓展性获得高性能 : 如果你按照某种系数增加⽤于解决问题的计算机数量,那么你就可以得到该系数倍
的吞吐量和系统性能
以http服务器⽹站为例: 起初你可能只需要两台主机(一台充当Web服务器,一台充当数据库); 但随着用户访问量的增加,
要加快处理的速度的⽅法⾸先要做的就是买更多的web服务器,并分流⽤户;
但不幸的是,这种可扩展性并⾮⽆限的,当你有了10台,20台或者100台web服务器访问同⼀个数据库,此时对于这些系统⽽⾔, 此时,数据库就成为了瓶颈,此时你应该去做些系统设计上的⼯作,比如使用分布式数据库系统
你需要进⾏⼀些设计上的⼯作,以此来将这个想法⽆⽌境的推进:
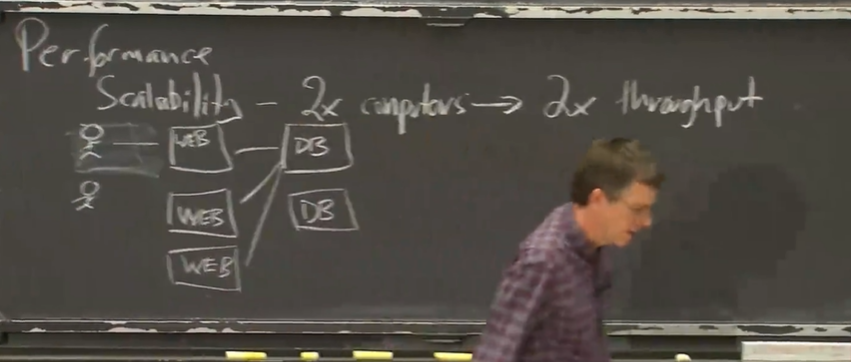
- 容错性: ⼤规模会让你本来不⽤担⼼的⼩概率事件变成了⼀个常⻅问题
- 可用性: 当遇到一些局部故障后, 仍能提供可用的服务
- 可恢复性: 系统感知到太多故障后选择停止服务, 维修减少故障数量后, 能恢复正常(可能需要把最新的数据从硬盘(故障时数据保存)中读取)
- 使用非易失性存储(但是非易失性存储如磁盘,磁臂的移动太慢了相比于CPU)
- 保存系统状态的检查点或Log(就是复制副本, 对副本的管理是一个难题, lab2就是管理副本实现容错)
如果每台电脑预期⼀年会出一次故障(硬件? 软件? 网络? 断电?…)的话,⼀千台电脑也就意味着,你每天可能遇上⼤约有三台电脑出现故障
因为故障总是出现,无法避免 —> 这意味着必须很少发⽣故障,或者只需要在设计中内置⽆故障进⾏能⼒,即掩饰故障的能⼒
- 最终主题: 一致性
我们想要容错,想要高性能, 通常需要数据副本, 假如你只对一个K-V存储系统做Put和Get, 很难保证一致性:
由于容错的原因,A,B两个副本可能存储在不同的城市, 你用PUT保持数据一致,先修改A(A可能是主服务器),再修改B,但是在修改完A后,和B之间网络故障,或者B主机down了, 总有一天, 主服务器down了.需要切换到B,你可能就读到了旧的数据
即: 在分布式系统中,由于复制或者缓存之类的东⻄,就会造成有多个数据副本的存在, 该键值对可能有很多不同版本 —> 你不一定总能看到最新的数据
强一致性 or 弱一致性?
要保持良好的⼀致性就必须进⾏通信,这可能代价会极其⾼;
或者同时检查所有副本找出最新的那个,但是需要很⾼的代价
MapReduce(分布式计算)
请按照以下顺序食用:
[MapReduce论文翻译](MapReduce:在大型集群上简化数据处理 - 知乎)
重要的是: [6.824Schedule](6.824 Schedule: Spring 2022)中的这节课的Introduction, 说是介绍,其实更像总结(一节课的比较详细的大纲),并且总结的很好
RPC和多线程
1 使用Go的原因:
- ⽐如,对线程的良好⽀持,线程之间的锁和同步;
- 用简单易用的RPC包;类型安全和内存安全(不用担心段错误等);
- 垃圾回收(这就意味着,你永远不需要担⼼会对同⼀段内存释放两次或者释放那些依然在使⽤的内存之类的问题, 当这些东⻄停⽌使⽤的时候,垃圾回收器就会将它们释放, 尤其是在并发场景,这很有用, 因为你只能在所有的线程都不需要某个共享对象时才能释放, 实现很麻烦,如果你使⽤垃圾回收,那这种问题就再也不会困扰我们);
- 最后,那就是这⻔语⾔很简单
GFS(分布式存储)

论文提出了一种观点: 让分布式系统拥有弱一致性也是可以的
- 文件系统的演变: 单机文件系统 → 分布式文件系统 → GFS
图中的关键点:
-
把文件切分为多个chunk, 每个chunk由一个chunkhandle唯一标志
-
单个master
-
master中保存元数据, chunkserver中存具体的数据
-
master中元数据有:
-
filename —> [chunkhandle1, chunkhandle2 …] (需要保存到Disk)
-
chunkhandle —> [chunkserver1, chunkserver2, chunkserver3] // 每个chunk保存三个副本,在不同的chunkserver上 (不需要保存到Disk, master重启或运行时通过心跳通信获取)
-
version 号 (需要保存到Disk) ,每往这个chunk写入一次,chunk的version #就更新一次,version #越大说明数据越新, 在没有设置primary chunk时,在读/追加写场景下,我们都需要获取最新的chunk(由master询问chunk server,他们保存chunk的 version #,来获取最新的chunk保存在哪个chunkserver上, 因为数据有可能不一致)
使用版本号的原因就是master可以通过chunk的version号来确定,最新的chunk存在哪个chunkserver上,进而确定Primary chunk
-
primary
-
租约
- 不使用租约有脑裂的风险: 当master发送心跳包给primary chunk, 或者当primary chunk给master回复的时候,出现局部网络故障(primary chunk 与 master无法通信, 但是primary chunk与其他chunk副本仍正常通信) 这时候master会再次指定其他的chunk副本作为新的primary chunk—>出现了两个primary chunk
- 租约的作用: 当租约到期primary chunk会自动拒接client的请求, 转为普通chunk; 而master发现与primary chunk失联,要等当前租约到期,才能重新选primary chunk并提供租约
-
-
通过LOG,checkpoint(COW: cope on write) —> Disk
-
-
client会缓存master发来的: chunkhandle —> [chunkserver1, chunkserver2, chunkserver3]
-
写入: 写入分两种: 改写和追加
-
没有Primary chunk时: master去找要获取的chunk的最新version(有记录,并持久化), 找到保存该chunk的chunk server, 将其设置为Primary chunk(写操作是由Primary chunk来控制的)
- 流水线写入, 从离client最近的chunkserver开始, 这里只是缓存在chunkserver上,并没有实际写入chunk
- 具体的写入控制是由chunk primary来做的, chunk primary完成写操作后才通知其他副本进行写入, 这里只有所有副本都写入成功chunk primary才向client汇报写入成功
- 如果应用程序很注重写入的顺序—> 不要把并发写入任务交给多个client,(即使交给同一个client, 如果每次写入任务都涉及多个不同的chunk,那么写入顺序将由各个primary chunk指定, 还是有很大可能顺序不一致(不同chunk之间))
-
可改进的点: 两阶段提交, 当client发送一个请求给primary chunk, primary chunk会先询问各个chunk副本,这个活你们能不能干, 只有所有的chunk副本都回复能干, 等待primary chunk一声令下,再去执行
问题思考:
- A1. 文件怎样分散存储在多台服务器上?怎样实现自动扩缩容?
——****分割存储;自动扩缩容在master单点上增减、
调整chunk的元数据即可
- A2. 怎样知道一个文件存储在哪台机器上?
**——****根据master中文件到chunk再到chunk位置的映射来定位具体的chunkserver
- A3. 怎样保证服务器在故障时文件不损坏不丢失?
——****master的WAL和主备、chunk的多副本
- A4. 使用多副本的话,怎样保证副本之间的一致?
——GFS对改写和追加不同写入模式的区分,在串行和并行情况下设计了不同的一致性
- B1. 怎样支持大文件(几个GB)存储?
——****采用了更大的chunk,以及配套的一致性策略
- B2. 超多机器的情况下,怎样实现自动监控、容错与恢复?
——****master的主备切换由chubby负责,chunk的租约、副本位置与数量由master负责**
- B3. 怎样支持快速的顺序读和追加写?
——****整体上是三写一读的模式,采用了流水线技术和数据流与控制流分离技术保证性能**
Primary-Backup Replication
推荐一个视频:
【【Cloud Explained ∙ 第十六期】虚拟机 Fault Tolerance(上)】https://www.bilibili.com/video/BV1Ta2UYuEtQ?vd_source=c5fdcb7e8bfbd07851554854d73aa1fa

摘要:
- 实时复制内存不可取, 数据量太大
- 复制指令: 同步 or 异步
- 不可靠指令: 如时间戳, 随机数, IO中断, cpu相关信息等
- 由Hypervisor捕捉指令, 在backup上重放, backup输出被丢弃

- Primary和backup共用一个disk
- 复制指令: 同步 or 异步 —> 实时一致性 or 效率
- 不以不确定性指令作为同步点, 以cpu和内存向外的写操作(外部可见)作为同步点, 即到达该指令,让master阻塞等待把之前的指令都同步到backup

- FT-vm的缺陷: 在多CPU处理机上无法使用, 因为又引入了新的不确定性事件- 在不同cpu上指令的执行顺序
- 新的方法:
- 复制内存页, 仍以输出操作为同步点
- 每到一个同步点, 不着急去同步数据, 先判断该输出结果是否相同, 再确定要不要同步
6.5840 2025 讲座3:主/备复制(Primary/Backup Replication)
今日主题
主/备复制实现容错,以VMware FT(2010)为案例研究——该理念的极致实践
为何研读此文?
-
清晰的主/备设计,揭示本学期反复出现的核心问题:
- 状态机复制(state-machine replication)
- 输出规则(output rule)
- 故障切换/主节点选举(fail-over/primary election)
-
突破性:在
机器指令级
实现复制
- 可透明复制任意应用
- 后续设计需应用层配合,而VM-FT无需
目标:高可用性
- 单机故障时服务不中断
- 实现方式:复制
复制能应对的故障类型
-
适用:单副本"故障-停止"(fail-stop)
- 风扇停转、CPU过热关机
-
电源/网线被拔
- 磁盘空间不足自停
-
不适用(软/硬件BUG):
- 程序错误/操作失误(非故障停止,可能级联崩溃)
-
地震/全市停电(需物理分散的副本)
主流复制方案:复制状态机
- 客户端向主节点发送操作
- 主节点排序后转发备节点
- 所有副本执行相同操作序列
- 起始状态相同 + 操作相同 + 顺序相同 + 确定性 → 最终状态相同
(替代方案:状态转移)
- 起始状态相同 + 操作相同 + 顺序相同 + 确定性 → 最终状态相同
VM-FT采用复制状态机
- 同本课程实验
- 同其他指定论文
副本数量权衡
- 成本限制:通常3-5副本
- 本文仅用2副本(容忍单点故障)
核心问题
- 状态与操作是什么?
- 主节点需等待备节点?
- 备节点如何决策接管?
- 切换时是否可见异常?
- 如何同步新备节点?
复制层级选择
-
应用状态级
(如数据库表)
- 高效(主节点仅发送高层操作)
- 需应用理解容错(如GFS)
-
机器状态级
(寄存器+内存)
- 透明性:可复制任意未修改应用!
- 需转发机器事件(中断、网络包等)
- 需修改机器以收发事件流...
VMware FT:机器级状态复制
- 透明性:运行任意现有OS/服务器软件
- 客户端视角:单台服务器
架构概览
graph LR
A[客户端] --> B[网络]
B --> C[主节点 hypervisor]
B --> D[备节点 hypervisor]
C & D --> E[共享磁盘服务器]
subgraph 物理机1
C --> F[主虚拟机 OS+App]
end
subgraph 物理机2
D --> G[备虚拟机 OS+App]
end
核心机制
- 初始状态同步:主备内存/寄存器完全一致
- 常规指令:多数指令无需同步(如ADD)
- 同步触发点:任何可能导致执行分叉的事件
分叉根源与消除
- 非确定性指令(如读当前时间)
- 外部输入(网络包/磁盘读 → DMA+中断)
- 中断时机
- 不处理多核竞争(仅单处理器)
分叉灾难案例
- 场景:6.5840作业提交服务器
- 主节点:作业包在计时器触发前到达 → 判有效
- 备节点:同一包在计时器后到达 → 判超时
- 后果:主节点故障后,备节点状态不一致暴露
日志通道(Logging Channel)
- 主节点向备节点发送所有事件:
- 中断、网络包、磁盘读取数据
- 备节点输入源:日志条目
- 备节点输出抑制
- 网络中断处理:
- 主/备无法通信时"上线"(go live)提供独立服务
- 主节点上线后停止发送日志
事件处理详解
| 事件类型 | 主节点处理 | 备节点处理 |
|---|---|---|
| 计时器中断 | 1. 截获中断 2. 读指令编号X 3. 发日志"计时器中断@X" 4. 传递中断给虚拟机 | 1. 忽略本地时钟 2. 在指令X处跳转至FT 3. 模拟中断 |
| 网络包到达 | 1. NIC(网卡)写包到弹跳缓冲区 2. 截获中断 3. 复制数据到虚拟机内存 4. 模拟中断 | 1. 从日志读数据/指令号X 2. 在指令X处跳转至FT 3. 复制数据+模拟中断 |
| 非确定性指令 | 1. 截获指令 2. 执行并记录结果 3. 发日志(结果+指令号) | 1. 在指令X处跳转至FT 2. 注入主节点结果(不执行指令) |
跳跃缓冲区作用
- 控制Primary和backup看到网络数据的时机
- 确保主备在相同指令位置看到相同数据
- 避免预读数据导致状态分叉
磁盘I/O处理
- 虚拟本地磁盘 → 实际共享网络磁盘
- 仅主节点读写磁盘:
- 主节点转发读取的数据块
- 备节点忽略应用写操作,读操作用主节点数据
备节点延迟执行
- 要求:至少缓存1个日志条目
- 原因:若主节点在指令X处中断,备节点执行超过X则无法同步
输出处理(关键!)
- 主备同时执行输出指令
- 实际输出者:主节点FT
- 备节点:丢弃输出
输出规则漏洞案例
sequenceDiagram
participant C as 客户端
participant P as 主节点
participant B as 备节点
C->>P: 增值请求(值=10→11)
P->>B: 发送日志条目
P->>C: 回复"11"(随后崩溃)
B->>日志: 条目丢失
B--xC: 未收到请求
C->>B: 新请求:11→12?
B->>C: 回复"11"(状态仍为10!)
解决方案:输出规则
主节点发送输出(网络回复/磁盘写)前,必须等待备节点确认所有先前日志条目
输出规则执行流程
sequenceDiagram
participant C as 客户端
participant P as 主节点
participant B as 备节点
C->>P: 增值请求
P->>B: 发送日志条目
P->>B: 等待ACK
B->>P: 确认ACK
P->>C: 发送"11"回复
输出规则重要性
-
强一致性系统的核心机制(常称"同步复制")
-
性能瓶颈:主节点在某个时间点必须等待, 保证数据以全部同步到backup
-
优化方向:
- 只读操作可能无需等待
-
FT无应用层知识,需保守处理
边界问题解答
| 问题 | 答案 |
|---|---|
| 主节点收ACK后发输出前崩溃 | 备节点接管后: - 若在发送指令前 → 补发输出 - 若在发送后 → TCP机制自动重传(因ACK未达) |
| 主节点发输出后崩溃 | 备节点可能重复输出 - TCP:序列号去重 - 磁盘写:相同数据写相同块 结论:需客户端处理重复或设计幂等操作 |
| 网络分区(脑裂) 当Primary和backup之间存在网络分区,即没办法通信时, 都会认为自己是Primary去和client交互, 不再向对方send log, 导致states不一致 |
共享磁盘仲裁: 1. 节点(Primary/backup)尝试原子性测试并设置(test-and-set) 2. 仅成功者上线 要求:共享磁盘需高可用(单点故障风险); 只要其中一个宕机了, 其他的节点并不知道是什么情况(有可能是网络问题), 这时候就要test-and-set |
| 备节点恢复时崩溃 | 系统完全宕机 → 需集群服务启动新虚拟机 |
| 为何不支持多核? | 未明确说明(推测因多核竞争引入非确定性) |
性能数据
- FT/非FT:延迟增加甚微(表1)
- 日志带宽:18 Mbit/s(反映磁盘读+网络输入速率)
- 局限:高吞吐场景不适用(如高速磁盘读取)
适用场景
- 关键但低强度服务(如域名服务器)
- 不便修改软件的服务
高性能复制替代方案
应用级状态机
(如数据库):
- 状态=数据库(非全内存/磁盘)
- 事件=DB命令(非原始网络包)
- 优势:日志量少,输出规则暂停少
- 案例:GFS、实验2
总结
- 主备复制:VM-FT是经典实现
- 无单点故障的分区应对:下节课内容
- 性能提升:应用级状态机复制
附:多核支持说明
- VMware KB#1013428提及多CPU支持
- VM-FT或从状态机复制转向状态转移(未证实)
- 参考链接:
vSphere容错机制
学术论文1
学术论文2
test-and-set
Test-and-Set:并发编程中的关键原子操作
Test-and-Set(测试并设置)是计算机科学中一种关键的原子操作,用于在多线程或分布式系统中实现互斥锁(mutex)和同步机制。它是构建更高级同步原语(如信号量、屏障等)的基础。
核心概念
-
什么是原子操作?
原子操作是指不可分割的操作——要么完全执行成功,要么完全不执行,中间状态不会被其他线程或进程观察到。在并发环境中,原子操作是构建线程安全数据结构的基础。
2. Test-and-Set 定义
Test-and-Set 是一个硬件支持的原子指令,其功能可以用以下伪代码表示:
function TestAndSet(boolean *lock) {
boolean old = *lock; // 读取当前值
*lock = true; // 无论原值是什么,都设置为true
return old; // 返回原始值
}
这个操作在单个不可中断的步骤中完成:
- 读取内存位置的值
- 将该内存位置设置为true
- 返回读取到的原始值
实现自旋锁(Spinlock)
Test-and-Set 最常见的应用是实现自旋锁:
typedef struct {
int flag;
} spinlock_t;
void spinlock_init(spinlock_t *lock) {
lock->flag = 0; // 0=未锁定, 1=已锁定
}
void spinlock_lock(spinlock_t *lock) {
while (TestAndSet(&lock->flag) == 1) {
// 自旋等待,直到锁可用
}
}
void spinlock_unlock(spinlock_t *lock) {
lock->flag = 0;
}
工作流程:
- 加锁尝试:
- 线程调用
TestAndSet(&lock->flag) - 如果返回0(锁空闲),线程获得锁
- 如果返回1(锁已被占用),线程循环重试
- 线程调用
- 解锁操作:
- 将锁标志设置为0(空闲)
- 注意:解锁不需要原子操作,因为只有锁持有者才能解锁, 其他线程都被阻塞陷入忙等待了
关键特性
- 原子性保证
- 整个操作在单个CPU指令周期完成
- 不会被线程切换或中断打断
- 确保并发环境下状态一致性
- 忙等待(Busy Waiting)
- 等待锁的线程会持续循环检查
- 优点:响应速度快(锁释放后立即获取)
- 缺点:浪费CPU资源(尤其在长时间等待时)
- 内存可见性
- 强制内存屏障(memory barrier)
- 确保锁状态变更对所有处理器核心可见
- 防止指令重排序导致的状态不一致
优缺点分析
优点:
- 简单高效:实现简单,在低竞争环境下性能好
- 无上下文切换:避免操作系统调度开销
- 响应及时:锁释放后可立即获取
缺点:
- 忙等待问题:
- 高竞争时浪费CPU周期
- 可能导致优先级反转(priority inversion)
- 公平性问题:
- 不保证先请求的线程先获得锁
- 可能导致线程饥饿
- 缓存一致性压力:
- 频繁的原子操作增加缓存同步开销
- 在多核系统中可能成为瓶颈
实际应用场景
- 操作系统内核
- Linux内核中的
ticket spinlock - Windows内核的
KSPIN_LOCK
- 并发数据结构
- 无锁队列(lock-free queues)
- 并发哈希表
- 内存分配器
- 分布式系统
- 分布式锁的基础实现
- 领导者选举算法
高级变种
- Compare-and-Swap (CAS)
bool CAS(int *ptr, int expected, int new) {
if (*ptr == expected) {
*ptr = new;
return true;
}
return false;
}
更灵活的原子操作,现代无锁编程的基础
- Fetch-and-Add
int FetchAndAdd(int *ptr, int value) {
int old = *ptr;
*ptr = old + value;
return old;
}
用于实现高效的计数器
- Load-Linked/Store-Conditional (LL/SC)
int LoadLinked(int *ptr) {
return *ptr; // 标记内存地址
}
bool StoreConditional(int *ptr, int value) {
// 仅当标记地址未被修改时存储
}
更灵活的原子操作原语
总结
Test-and-Set作为并发编程的基石:
- 提供硬件级别的原子性保证
- 是构建高效同步机制的基础
- 在操作系统内核和低延迟系统中至关重要
- 理解其原理对优化高性能系统至关重要
在现代系统中,虽然开发者通常使用更高级的同步原语(如互斥锁、信号量),但这些高级原语底层往往依赖于类似Test-and-Set的原子操作。掌握这些基础原理,有助于设计更高效、更可靠的并发系统。
compare-and-swap(CAS)
Compare-and-Swap (CAS):并发编程的基石
Compare-and-Swap (CAS) 是现代并发编程中最重要的原子操作之一,它提供了实现无锁数据结构和同步原语的基础能力。CAS 操作是构建高性能、可扩展并发系统的关键工具。
1. 什么是 CAS?
CAS 是一个原子操作,它执行以下三个步骤:
- 读取内存位置的值
- 比较该值与预期值
- 如果值匹配,则写入新值
整个过程在单个不可中断的操作中完成,伪代码如下:
bool CAS(T* ptr, T expected, T new_value) {
if (*ptr == expected) {
*ptr = new_value;
return true;
}
return false;
}
其中:
- ptr`:指向内存位置的指针
- expected`:预期值(比较值)
new_value:要写入的新值
2. 原子性保证
CAS 操作的关键特性是原子性:
- 整个操作(比较+交换)在单个CPU指令周期完成
- 不会被线程切换或中断打断
- 确保并发环境下状态一致性
3. 实现自旋锁(Spinlock)
CAS 最常见的应用是实现自旋锁:
typedef struct {
int flag; // 0=未锁定, 1=已锁定
} spinlock_t;
void spinlock_lock(spinlock_t *lock) {
while (true) {
if (CAS(&lock->flag, 0, 1)) {
break; // 成功获取锁
}
// 等待并重试
}
}
void spinlock_unlock(spinlock_t *lock) {
lock->flag = 0; // 不需要原子操作
}
zookeeper论文
摘要
在本文中,我们描述了 ZooKeeper,一个用于协调分布式应用程序进程的服务。由于 ZooKeeper 是关键基础设施的一部分,其目标是提供一个简单且高性能的内核,以便客户端在其之上构建更复杂的协调原语。它在一个复制的、集中式的服务中,融合了组消息传递、共享寄存器和分布式锁服务的元素。ZooKeeper 暴露的接口兼具共享寄存器的无等待特性,以及一个类似于分布式文件系统缓存失效机制的事件驱动机制,从而提供了一个简单而强大的协调服务。
ZooKeeper 的接口使其能够实现高性能的服务。除了无等待特性,ZooKeeper 还保证了每个客户端的请求按 FIFO(先进先出)顺序执行,并且对所有改变 ZooKeeper 状态的请求提供线性一致性。这些设计决策使得实现一个高性能的处理管道成为可能,其中读请求可以由本地服务器直接满足。我们通过目标工作负载(读写比从 2:1 到 100:1)表明,ZooKeeper 可以每秒处理数万至数十万次事务。这种性能使得 ZooKeeper 能够被客户端应用程序广泛使用。
详细解释与关键术语解析
这段摘要精炼地概括了 ZooKeeper 的设计目标、核心特性和性能优势。
1. 核心定位:分布式协调服务
- 是什么:ZooKeeper 是一个专门为分布式系统提供协调功能的中心化服务。所谓“协调”,包括但不限于:选举主节点、管理配置信息、发现服务、分布式锁、同步操作等。
- 设计哲学:它不直接提供所有复杂的协调功能,而是提供一个简单、可靠、高性能的核心(Kernel)。应用程序可以基于这个核心,像搭积木一样,构建出自己需要的、更复杂的协调功能(原语)。这是一种“提供机制而非策略”的设计思想。
2. 关键术语解析
a. 组消息传递
- 基本概念:指一种一对多的通信模式,一个节点发送的消息可以被组内的所有其他节点接收。在分布式系统中,这常用于实现状态同步、事件通知或成员管理(如某个节点加入或离开集群)。
- 在 ZooKeeper 中的体现:ZooKeeper 本身是一个复制(Replicated)服务,由多个服务器节点组成一个集群(一个组)。服务器之间使用类似组消息传递的共识协议(如Zab协议)来复制数据、达成状态一致。对于客户端,它通过 “Watch”机制 实现了一种事件通知,客户端可以监听一个数据节点(Znode),当该节点发生变化时,所有监听了它的客户端都会收到通知,这类似于一种反向的组消息传递。
b. 共享寄存器
- 基本概念:在分布式系统中,可以将其想象成一个小小的、可被网络间多个进程共同访问和修改的数据存储单元。它类似于编程中的共享变量,但要解决分布式环境下的并发控制和数据一致性问题。
- 在 ZooKeeper 中的体现:ZooKeeper 的数据模型是一棵树(Znode Tree),每个节点(Znode)就像一个共享寄存器,可以存储少量数据(通常用于存储配置、状态等)。多个客户端可以并发地读取和写入这些 Znode。
c. 分布式锁
- 基本概念:用于控制分布式系统中多个进程/线程对共享资源的互斥访问,确保在同一时间只有一个参与者可以执行临界区代码。实现分布式锁比实现单机锁复杂得多,需要处理网络延迟、节点故障等问题。
- 在 ZooKeeper 中的体现:ZooKeeper 是实现分布式锁的理想基石。利用其有序临时节点(Sequential Ephemeral Nodes)和 Watch 机制,可以非常可靠地实现公平的分布式锁,而无需应用程序自己处理复杂的分布式共识问题。论文说 ZooKeeper 融合了其元素,意味着它提供了构建锁所需的基本工具。
3. 核心特性与设计决策
a. 无等待
- 含义:指客户端的操作(特别是读请求)不需要等待其他客户端的操作完成即可执行。这极大地提升了读操作的性能和可扩展性。
- 实现:ZooKeeper 允许读请求由任何服务器本地处理,无需与其他服务器进行复杂的协调,因此速度极快,是“无等待”的。
b. 事件驱动机制
- 含义:客户端不需要通过轮询(不断重复查询)来获取数据变化,而是事先注册一个监听(Watch)。当数据发生变化时,服务端会主动通知客户端。
- 类比:类似于分布式文件系统的“缓存无效化”(Cache Invalidation)。当客户端缓存的数据在服务器端失效(被修改)时,服务器会通知客户端“你的缓存过期了”,客户端从而知道需要重新获取数据。
c. FIFO 客户端顺序 & 线性一致性
- FIFO 客户端顺序:来自同一个客户端的所有请求(无论是读还是写), ZooKeeper 保证会严格按照它们被发送的顺序执行。这是实现 Watch 机制正确性的基础(你不可能在更新操作完成前先收到更新通知)。
- 线性一致性:所有修改系统状态的写请求(跨所有客户端),当它们完成后,其效果看起来就像是瞬间完成的,并且所有客户端后续的读请求都能看到这个最新的结果。这是非常强的一致性保证,简化了上层应用的开发。
- 注意:ZooKeeper 的全局一致性是写线性化,而读是可能读到稍旧数据的(因为它可以由本地服务器处理)。但这种设计在协调场景中通常是可接受的,并且换来了极高的读性能。
4. 高性能实现
- 读写分离:利用上述特性,ZooKeeper 构建了一个高性能管道。大量的读请求(占工作负载的绝大部分)由本地服务器直接返回数据,延迟极低。只有写请求需要由 Leader 协调进行集群间的共识复制。
- 目标场景:非常适合读多写少的场景(读写比 2:1 到 100:1)。在这种场景下,它的扩展性非常好,可以达到极高的吞吐量(每秒数万至数十万事务)。
总结
ZooKeeper 的成功在于其精妙的设计取舍:
- 提供基础原语而非完整解决方案,使其灵活且通用。
- 通过写线性化 + 读本地化的策略,在保证强一致性的同时,为读多写少的场景提供了极致性能。
- 通过 FIFO 和 Watch 机制,构建了一个简单而强大的事件通知系统。
- 它将组消息(集群复制)、共享寄存器(Znode)和分布式锁(构建能力)等概念融合在一个集中、复制的服务中,为构建可靠的分布式系统提供了至关重要的协调“内核”。
Introduction
大规模分布式应用需要不同形式的协调。配置是最基本的协调形式之一。在其最简单的形式中,配置只是系统进程的操作参数列表,而更复杂的系统则拥有动态配置参数。组成员管理和领导者选举在分布式系统中也很常见:进程通常需要知道哪些其他进程存活以及这些进程负责什么。锁构成了一种强大的协调原语,用于实现对关键资源的互斥访问。
协调的一种方法是为每种不同的协调需求开发专门的服务。例如,Amazon Simple Queue Service [3] 专门专注于队列服务。其他服务则专门为领导者选举 [25] 和配置 [27] 而开发。实现更强大原语的服务可以用来实现功能较弱的原则。例如,Chubby [6] 是一个提供强同步保证的锁服务。锁随后可被用来实现领导者选举、组成员管理等。
在设计我们的协调服务时,我们摒弃了在服务器端实现特定原语的方法,而是选择暴露一个 API,让应用程序开发者能够实现他们自己的原语。这一选择导致我们实现了一个协调内核,它能够在无需更改服务核心的情况下启用新的原语。这种方法实现了多种适应应用需求的协调形式,而不是将开发者限制在一组固定的原语中。
在设计 ZooKeeper 的 API 时,我们避开了阻塞性原语,例如锁。协调服务的阻塞性原语可能导致诸多问题,例如缓慢或故障的客户端会对更快客户端的性能产生负面影响。如果处理请求依赖于其他客户端的响应和故障检测,那么服务本身的实现会变得更加复杂。因此,我们的系统 ZooKeeper 实现了一个 API,用于操作以分层结构组织(如文件系统)的简单无等待数据对象。事实上,ZooKeeper 的 API 类似于任何其他文件系统,仅从 API 签名来看,ZooKeeper 似乎就是去掉了锁方法、open 和 close 的 Chubby。然而,实现无等待数据对象使 ZooKeeper 与基于阻塞原语(如锁)的系统显著不同。
尽管无等待特性对性能和容错很重要,但它对于协调来说并不足够。我们还必须为操作提供顺序保证。特别是,我们发现保证所有操作的 FIFO 客户端顺序和线性化写入,既能够实现服务的高效运行,也足以实现我们应用程序感兴趣的协调原语。事实上,我们可以用我们的 API 为任意数量的进程实现共识,根据 Herlihy 的层次结构,ZooKeeper 实现了一个通用对象[14]。
ZooKeeper 服务包含一个服务器集合(ensemble),它们使用复制来实现高可用性和高性能。其高性能使得包含大量进程的应用程序能够使用这样的协调内核来管理协调的各个方面。我们能够使用一种简单的流水线架构来实现 ZooKeeper,这种架构允许我们有成百上千个未完成的请求,同时仍能实现低延迟。这样的流水线自然支持以 FIFO 顺序执行来自单个客户端的操作。保证 FIFO 客户端顺序使得客户端能够异步提交操作。通过异步操作,一个客户端能够同时拥有多个未完成的操作。这个特性是非常可取的,例如,当一个新客户端成为领导者时,它必须操作元数据并相应地更新它。如果没有多个未完成操作的可能性,初始化时间可能会是秒级而不是亚秒级。
为了保证更新操作满足线性一致性,我们实现了一个基于领导者的原子广播协议[23],称为 Zab[24]。然而,ZooKeeper 应用的典型工作负载以读操作为主,因此扩展读取吞吐量变得非常必要。在 ZooKeeper 中,服务器在本地处理读操作,我们不使用 Zab 来完全排序它们。
在客户端缓存数据是提高读取性能的一项重要技术。例如,一个进程缓存当前领导者的标识符,而不是每次需要知道领导者时都去探测 ZooKeeper,这是有用的。ZooKeeper 使用一种 Watch 机制使客户端能够缓存数据,而无需直接管理客户端缓存。通过这种机制,客户端可以监视给定数据对象的更新,并在更新时收到通知。Chubby 直接管理客户端缓存。它通过阻塞更新来使所有缓存了正在更改数据的客户端缓存失效。在这种设计下,如果这些客户端中有任何一个缓慢或发生故障,更新就会被延迟。Chubby 使用租约(leases)来防止故障客户端无限期地阻塞系统。然而,租约只是限制了缓慢或故障客户端的影响,而 ZooKeeper 的 Watch 则完全避免了这个问题。
在本文中,我们讨论了 ZooKeeper 的设计和实现。使用 ZooKeeper,我们能够实现我们应用程序所需的所有协调原语,尽管只有写操作是线性化的。为了验证我们的方法,我们展示了如何使用 ZooKeeper 实现一些协调原语。
总结来说,我们在本文中的主要贡献是:
- 协调内核:我们提出了一种具有宽松一致性保证的无等待协调服务,用于分布式系统。特别是,我们描述了我们协调内核的设计和实现,我们已在许多关键应用中用它来实现各种协调技术。
- 协调方案(Recipes):我们展示了如何使用 ZooKeeper 来构建更高级的协调原语,甚至是分布式应用中常用的阻塞性和强一致性原语。
- 协调经验:我们分享了我们使用 ZooKeeper 的一些方式,并评估了其性能。
详细解释与关键术语解析
这段文字深入阐述了 ZooKeeper 的设计动机、核心决策及其优势。
1. 设计哲学:提供机制,而非策略(Coordination Kernel)
- 核心思想:ZooKeeper 没有直接提供像“锁”、“选举”这样的具体协调功能(策略)。相反,它提供了一个非常核心的、基础的数据模型(类似文件系统的层次结构节点树)和一套操作这些数据的 API(机制)。
- 好处: 灵活性:开发者可以基于这些简单的基础构件,组合出任何他们需要的、更适合其特定应用的复杂协调原语(即所谓的 "Coordination Recipes")。 稳定性:服务核心(Kernel)非常简单稳定,因为不需要为各种复杂多变的协调场景添加逻辑。所有复杂性都被推到了客户端库中。 通用性:一个 ZooKeeper 集群可以被公司内所有不同类型的分布式应用使用,每个应用按自己的方式使用它。
2. 关键设计决策:无等待 (Wait-free) 与异步 API
- 无等待:客户端的操作(请求)不会因为服务端要等待其他客户端的动作(如释放锁)而被阻塞。客户端发出请求后,总会(很快)得到响应,无论成功或失败。
- 避免阻塞原语:像锁这样的原语本质上是阻塞的(拿不到锁就要等待)。ZooKeeper 的 API 本身不提供这种会阻塞客户端请求的原语。
- 好处: 性能与容错:一个“慢”或“宕机”的客户端不会直接影响其他客户端的性能和可用性。在基于锁的服务中,一个客户端宕机不释放锁,会导致所有其他客户端被阻塞。ZooKeeper 从根本上避免了这个问题。 简化服务端:服务端无需跟踪和管理每个客户端的状态(如谁持有什么锁),只需处理简单的数据读写请求,实现更简单、更健壮。
3. 顺序保证 (Order Guarantees):强大功能的基石
虽然数据模型和 API 很简单,但 ZooKeeper 提供了两个至关重要的顺序保证,使得在其上构建强一致性的原语成为可能:
- FIFO 客户端顺序:来自同一个客户端的所有请求(A, B, C...),会严格按照它们被发送的顺序被 ZooKeeper 服务执行。这是实现异步操作和 Watch 可靠性的基础。
- 线性化写入 (Linearizable Writes):所有客户端的的所有写操作,在完成后,其效果看起来就像是瞬间完成的,并且所有客户端后续的读请求都能看到这个最新的结果。这是一个非常强的一致性保证。
两者的结合:FIFO Client Order + Linearizable Writes 这个组合被证明是构建分布式协调原语的充分条件。论文甚至提到,根据 Herlihy 的理论,ZooKeeper 的数据模型是一个通用对象 (Universal Object),意味着可以用它来实现任何并发对象(包括锁、队列等),即可以实现共识。
4. 高性能架构
- 读写分离: 写操作:使用 Zab 协议(一种原子广播协议)在所有服务器间进行复制,保证线性一致性。这相对较慢,但写操作通常占比较少。 读操作:可以由任何服务器本地处理,无需与其他服务器通信。这使得读吞吐量可以随服务器数量线性扩展,且延迟极低。这是 ZooKeeper 高性能的关键。
- 流水线架构 (Pipelined Architecture):服务器可以异步处理请求,允许单个客户端同时发出大量请求(
have multiple outstanding operations),而服务器会按 FIFO 顺序处理它们。这极大提升了效率,例如一个新主节点可以快速完成初始化。
5. Watch 机制 vs. Chubby 的客户端缓存管理
这是一个非常关键的对比,凸显了 ZooKeeper 的设计优势。
- Chubby (由服务端直接管理客户端缓存):
- 模式:采用“无效化 (Invalidation)”模式。当数据要更新时,服务端会阻塞本次更新,并主动联系所有缓存了该数据的客户端,要求它们失效缓存(这需要客户端的确认应答),然后才完成更新。
- 缺点:如果其中一个客户端响应慢或宕机,本次更新操作就会被阻塞。虽然通过租约 (Leases)(一个有时间限制的授权)来防止故障客户端无限期阻塞(租约到期后服务端会单方面失效缓存),但问题依然存在,只是影响被限制了。慢客户端会直接影响系统更新速度。
- ZooKeeper (Watch 机制):
- 模式:采用“主动通知 (Publish-Subscribe)”模式。客户端在数据上设置一个 Watch(监听器)。当数据变化时,ZooKeeper 服务会异步地、尽力地推送一个事件通知给客户端,告知“数据变了”。客户端随后自己决定何时去获取新数据。服务端不关心客户端是否处理了这个通知,也不等待客户端响应。
- 优点:服务端完全不管理客户端缓存。写操作的成功与否不依赖于任何客户端的行为。一个客户端的慢或故障完全不影响服务端的更新操作和其他客户端。从根本上避免了由客户端引起的阻塞问题。
6. 关键术语:Chubby
- 是什么:Chubby 是 Google 开发的一个粗粒度分布式锁服务。它被设计用于 Google 内部系统(如 Bigtable)来进行领导者选举和元数据存储。
- 核心特性: 提供类似文件系统的接口,但核心抽象是锁。 提供强一致性(线性化)保证。 采用主从复制。 如论文所述,其直接管理客户端缓存的设计是其与 ZooKeeper 的一个重要区别。
- 与 ZooKeeper 的关系:Chubby 是 ZooKeeper 的一个重要的思想先驱和比较对象。ZooKeeper 的设计在很多方面借鉴了 Chubby(如类似文件系统的接口),但又在关键决策上(无等待、Watch 机制)做出了不同的、被认为更优的选择。论文中说 ZooKeeper 的 API 看起来像“没有锁操作的 Chubby”,恰恰说明了两者的渊源和差异。
总结
这段文字清晰地展示了 ZooKeeper 的成功之道:它通过一个简单、无等待的数据内核,辅以强大的顺序保证(FIFO + 线性化写) 和高效的读写分离架构,成功地提供了一个灵活、高性能、高可用的分布式协调基础组件。其“提供机制而非策略”的设计哲学,使其成为了构建分布式系统的“瑞士军刀”,能够适应各种复杂的协调需求。与 Chubby 的对比尤其突出了其在避免客户端引起的阻塞问题上的卓越设计。
The ZooKeeper service
好的,我们将分部分翻译和解释这篇关于 ZooKeeper 的论文内容。
1. 服务概述与术语
翻译:
ZooKeeper 服务
客户端通过客户端 API(使用 ZooKeeper 客户端库)向 ZooKeeper 提交请求。除了通过客户端 API 暴露 ZooKeeper 服务接口外,客户端库还管理着客户端与 ZooKeeper 服务器之间的网络连接。
在本节中,我们首先提供 ZooKeeper 服务的高层概览。然后我们讨论客户端用于与 ZooKeeper 交互的 API。
术语:在本文中,我们使用 客户端 来指代 ZooKeeper 服务的用户,服务器 来指代提供 ZooKeeper 服务的进程,znode 来指代 ZooKeeper 数据中一个内存中的数据节点,这些数据被组织在一个称为数据树的分层命名空间中。我们也使用更新和写入来指代任何修改数据树状态的操作。客户端在连接到 ZooKeeper 时建立一个会话,并获得一个会话句柄,通过它来发出请求。
解释:
这部分介绍了 ZooKeeper 的基本交互模型和核心术语。客户端不直接与服务器集群打交道,而是通过一个客户端库。这个库扮演着关键角色:1)提供编程接口(API);2)管理所有网络通信(如寻找可用的服务器、保持连接等),对应用开发者隐藏了分布式系统的复杂性。
- 客户端:使用 ZooKeeper 服务的应用程序进程。
- 服务器:组成 ZooKeeper 集群的进程,共同提供协调服务。
- znode:这是 ZooKeeper 的核心抽象。它是数据树中的一个节点,可以存储数据(通常是元数据或配置信息)。它不是为存储大文件设计的。
- 数据树:所有 znode 组成的层次结构命名空间,类似于文件系统的目录树。这是 ZooKeeper 组织数据的方式。
- 会话:客户端与 ZooKeeper 服务之间的一个长期连接。会话有超时时间,如果 ZooKeeper 在超时时间内未收到客户端的心跳,则会认为该客户端故障并终止会话。会话是许多功能(如临时节点)的基础。
2.1 服务概述
翻译:
ZooKeeper 向其客户端提供了一组数据节点(znodes)的抽象,这些节点按照分层命名空间组织。客户端通过 ZooKeeper API 操作此层次结构中的 znode 数据对象。分层命名空间通常在文件系统中使用。这是一种组织数据对象的理想方式,因为用户熟悉这种抽象,并且它能更好地组织应用程序元数据。为了引用特定的 znode,我们使用标准的 UNIX 文件系统路径表示法。例如,我们使用 /A/B/C 来表示 znode C 的路径,其中 C 的父节点是 B,B 的父节点是 A。所有 znode 都存储数据,并且除临时节点外,所有 znode 都可以拥有子节点。
客户端可以创建两种类型的 znode:
- 常规节点:客户端通过显式创建和删除来操作常规节点;
- 临时节点:客户端创建此类节点,并可以显式删除它们,或者让系统在创建它们的会话终止时(主动终止或因故障终止)自动删除它们。
此外,在创建新 znode 时,客户端可以设置一个顺序标志。设置了顺序标志创建的节点,其名称后会附加一个单调递增计数器的值。如果 n 是新 znode,p 是父 znode,那么 n 的序列值永远不会小于曾经在 p 下创建的任何其他顺序 znode 名称中的值。
ZooKeeper 实现了 Watch 机制,允许客户端及时接收变更通知,而无需轮询。当客户端发出设置了 watch 标志的读操作时,操作正常完成,但服务器承诺在返回的信息发生变化时通知客户端。Watch 是与会话关联的一次性触发器;一旦被触发或会话关闭,它们就会被注销。Watch 指示发生了变化,但不提供变更内容。例如,如果客户端在 “/foo” 被更改两次之前发出了 getData("/foo", true),客户端将收到一个 watch 事件,告知 “/foo” 的数据已更改。会话事件,例如连接丢失事件,也会发送到 watch 回调函数,以便客户端知道 watch 事件可能会延迟。
解释:
这部分详细说明了 ZooKeeper 的数据模型和核心概念。
- 分层命名空间:这是 ZooKeeper 组织数据的核心方式,类似于文件路径。这种结构非常直观,便于对不同应用的元数据进行分类和管理(例如,
/app1/config,/app2/locks)。 - znode 类型: 常规节点:持久存在的节点,除非显式删除。 临时节点:节点的生命周期与创建它的客户端会话绑定。会话结束(客户端断开或崩溃),节点自动消失。这是实现组 membership(成员管理)和发现机制的基础。例如,每个进程创建一个临时节点代表自己,进程存活则节点在,进程退出则节点自动删除,其他进程通过查看这些节点就知道哪些成员在线。 顺序节点:创建节点时,ZooKeeper 会自动在节点名后附加一个单调递增的、全局唯一的序列号。这是实现公平锁、队列等高级原语的关键。它保证了创建的全局顺序性。
- Watch 机制:这是 ZooKeeper 实现事件驱动编程模型的核心。 一次性:Watch 被触发一次后就需要重新设置。这简化了服务端的实现,避免了维护复杂的状态。 异步通知:客户端不必轮询(不断查询)数据是否变化,而是设置一个 Watch 后就可以继续处理其他任务。当数据变更时,服务端会发送一个事件通知。 不传递数据:Watch 只通知“某事发生了”,客户端需要在收到通知后主动去获取最新数据。这避免了在通知中传输可能很大的数据内容。
翻译:
数据模型。ZooKeeper 的数据模型本质上是一个具有简化 API 且仅支持完整数据读取和写入的文件系统,或者一个具有分层键的键/值表。分层命名空间对于为不同应用程序的命名空间分配子树以及为这些子树设置访问权限非常有用。我们还在客户端利用目录的概念来构建更高级的原语,正如我们将在第 2.4 节中看到的那样。
与文件系统中的文件不同,znode 并非为通用数据存储而设计。相反,znode 映射到客户端应用程序的抽象,通常对应于用于协调目的的元数据。如图 1 所示,我们有两个子树,一个用于应用程序 1 (/app1),另一个用于应用程序 2 (/app2)。应用程序 1 的子树实现了一个简单的组成员协议:每个客户端进程 p_i 在 /app1 下创建一个 znode p_i,只要进程正在运行,该 znode 就会持续存在。
尽管 znode 并非为通用数据存储而设计,但 ZooKeeper 确实允许客户端存储一些信息,这些信息可用于分布式计算中的元数据或配置。例如,在基于领导者的应用程序中,刚刚启动的应用服务器了解当前哪个服务器是领导者是非常有用的。为了实现这个目标,我们可以让当前领导者将这一信息写入 znode 空间中的一个已知位置。Znode 还具有带时间戳和版本计数器的关联元数据,这允许客户端跟踪 znode 的更改并根据 znode 的版本执行条件更新。
会话。客户端连接到 ZooKeeper 并启动一个会话。会话有一个关联的超时时间。如果 ZooKeeper 在超过该超时时间后未从其会话收到任何信息,则认为客户端故障。当客户端显式关闭会话句柄或 ZooKeeper 检测到客户端故障时,会话结束。在一个会话内,客户端观察到一系列状态变化,这些状态变化反映了其操作的执行。会话使客户端能够在 ZooKeeper 集群内透明地从一个服务器移动到另一个服务器,从而在 ZooKeeper 服务器之间持久存在。
解释:
- 数据模型用途:再次强调,ZooKeeper 存储的是元数据(关于数据的数据)和配置信息,而不是大量的应用数据。例如,它存储的是“谁是主节点”、“某个任务是否完成”等信息,而不是任务本身的具体数据。
- 图 1 示例:图中
/app1下的p_1,p_2,p_3就是临时节点的典型应用。每个进程启动时创建一个代表自己的临时节点,进程退出时节点消失。其他进程通过列出/app1的子节点就能知道当前所有存活的进程成员。 - 会话:会话是有状态的连接。客户端的所有操作都在一个会话上下文中进行。会话的超时机制是容错的关键:它允许 ZooKeeper 自动清理故障客户端留下的临时节点和锁。透明故障转移是指如果客户端当前连接的服务器宕机,客户端库会自动将会话重新连接到集群中的另一台服务器,而客户端应用程序可能对此毫无感知(除了短暂的连接延迟)。
2.2 客户端 API
翻译:
我们在下面展示了 ZooKeeper API 的一个相关子集,并讨论了每个请求的语义。
create(path, data, flags):创建一个路径名为path的 znode,将data[]存储在其中,并返回新 znode 的名称。flags使客户端能够选择 znode 的类型:常规、临时,并设置顺序标志;delete(path, version):如果 znodepath处于预期的版本,则删除它;exists(path, watch):如果路径名为path的 znode 存在则返回 true,否则返回 false。watch标志使客户端能够在 znode 上设置一个监视点(watch);getData(path, watch):返回与 znode 关联的数据和元数据,例如版本信息。watch标志的工作方式与exists()相同, except that ZooKeeper does not set the watch if the znode does not exist(除了当 znode 不存在时 ZooKeeper 不会设置监视点);setData(path, data, version):如果版本号是 znode 的当前版本,则将data[]写入 znodepath;getChildren(path, watch):返回 znode 的子节点名称集合;sync(path):等待操作开始时所有未完成的更新传播到客户端所连接的服务器。目前path被忽略。
所有方法在 API 中都同时有同步和异步版本可用。当应用程序需要执行单个 ZooKeeper 操作并且没有并发任务要执行时,它使用同步 API,因此它进行必要的 ZooKeeper 调用并阻塞。然而,异步 API 使应用程序能够同时拥有多个未完成的 ZooKeeper 操作和其他并行执行的任务。ZooKeeper 客户端保证每个操作的相应回调按顺序被调用。
请注意,ZooKeeper 不使用句柄来访问 znode。每个请求都包含被操作 znode 的完整路径。这一选择不仅简化了 API(没有 open() 或 close() 方法),而且消除了服务器需要维护的额外状态。
每个更新方法都接受一个预期的版本号,这实现了条件更新。如果 znode 的实际版本号与预期版本号不匹配,则更新失败并返回意外版本错误。如果版本号为 -1,则不执行版本检查。
解释:
这部分列出了 ZooKeeper 的核心 API。
- API 设计:API 非常精简,主要围绕 znode 的 CRUD(创建、读取、更新、删除)操作。
- 同步 vs 异步: 同步 API:调用会阻塞,直到收到服务器的响应。简单,但吞吐量低。 异步 API:调用立即返回,应用程序提供一个回调函数。当操作完成时,库会在后台线程中调用该回调函数。这是实现高性能的关键,允许客户端并行发送大量请求。
- 无句柄设计:每次操作都使用完整路径。这使 API 变得无状态(服务器不需要为每个客户端维护“打开文件”的表),极大地简化了服务端的实现并提高了可扩展性。
- 条件更新(版本号):这是实现乐观锁的关键机制。 客户端读取数据时,会获取到该数据的版本号(例如
version=5)。 当客户端要更新数据时,它必须提供之前读到的版本号 (setData(path, newData, 5))。 如果在此期间没有其他客户端修改过数据(版本号还是5),则更新成功,版本号变为6。 如果在此期间数据已被其他客户端修改(版本号变为6),则本次更新失败,客户端必须重新读取数据并重试。 这避免了使用沉重的悲观锁,非常适合读多写少的场景。
2.3 ZooKeeper 保证
翻译:
ZooKeeper 有两个基本的顺序保证:
- 线性化写入:所有更新 ZooKeeper 状态的请求都是可串行化的并尊重先后顺序;
- FIFO 客户端顺序:来自给定客户端的的所有请求都按照客户端发送的顺序执行。
请注意,我们对线性化的定义与 Herlihy [15] 最初提出的定义不同,我们称之为 A-线性化(异步线性化)。在 Herlihy 的线性化原始定义中,一个客户端一次只能有一个未完成的操作(一个客户端是一个线程)。在我们的定义中,我们允许一个客户端有多个未完成的操作,因此我们可以选择保证同一客户端未完成操作没有特定顺序,或者保证 FIFO 顺序。我们为我们的特性选择后者。
观察到所有对线性化对象成立的结果对 A-线性化对象也成立是非常重要的,因为满足 A-线性化的系统也满足线性化。因为只有更新请求是 A-线性化的,ZooKeeper 在每个副本本地处理读请求。这使得服务能够随着服务器添加到系统中而线性扩展。
为了了解这两个保证如何相互作用,请考虑以下场景。一个包含多个进程的系统选举一个领导者来指挥工作进程。当一个新的领导者接管系统时,它必须更改大量配置参数并在完成后通知其他进程。我们有两个重要的要求:
- 当新领导者开始进行更改时,我们不希望其他进程开始使用正在更改的配置;
- 如果新领导者在配置完全更新之前死亡,我们不希望进程使用这部分配置。
观察到分布式锁,例如 Chubby 提供的锁,有助于第一个要求,但不足以满足第二个要求。使用 ZooKeeper,新领导者可以将一个路径指定为就绪 znode(ready znode);其他进程仅在该 znode 存在时才会使用配置。新领导者通过删除 ready、更新各种配置 znode 和创建 ready 来进行配置更改。所有这些更改都可以通过流水线操作和异步发出,以快速更新配置状态。尽管更改操作的延迟大约为 2 毫秒,但如果一个接一个地发出请求,一个必须更新 5000 个不同 znode 的新领导者将需要 10 秒;通过异步发出请求,请求将花费不到一秒。由于顺序保证,如果一个进程看到就绪 znode,它必须也看到新领导者所做的所有配置更改。如果新领导者在就绪 znode 创建之前死亡,其他进程知道配置尚未最终确定,并且不会使用它。
上述方案仍然有一个问题:如果一个进程在新领导者开始更改之前看到 ready 存在,然后在更改进行时开始读取配置,会发生什么。这个问题通过通知的顺序保证得到解决:如果客户端正在监视更改,客户端将在看到更改后系统的新状态之前看到通知事件。因此,如果读取就绪 znode 的进程请求被通知该 znode 的更改,它将在可以读取任何新配置之前看到一个通知客户端更改的事件。
当客户端除了 ZooKeeper 之外还有自己的通信通道时,可能会出现另一个问题。例如,考虑两个客户端 A 和 B,它们在 ZooKeeper 中有一个共享配置,并通过共享通信通道进行通信。如果 A 更改了 ZooKeeper 中的共享配置,并通过共享通信通道将更改告知 B,B 会期望在重新读取配置时看到更改。如果 B 的 ZooKeeper 副本稍微落后于 A 的副本,它可能看不到新配置。使用上述保证,B 可以通过在重新读取配置之前发出写入来确保它看到最新的信息。为了更有效地处理这种情况,ZooKeeper 提供了 sync 请求:后跟一个读操作时,构成一个慢速读取。sync 导致服务器在处理读取之前应用所有未完成的写入请求,而没有完整写入的开销。此原语在思想上类似于 ISIS [5] 的 flush 原语。
ZooKeeper 还具有以下两个活性和持久性保证:如果大多数 ZooKeeper 服务器处于活动状态并相互通信,服务将可用;并且如果 ZooKeeper 服务成功响应更改请求,那么只要法定数量的服务器最终能够恢复,该更改就会在任意数量的故障中持续存在。
解释:
这部分阐述了 ZooKeeper 最核心的理论基础和行为保证。
- 两个核心保证: 线性化写入:所有写操作是强一致性的。一旦一个写操作成功,所有后续的读操作(无论从哪个服务器读)都必须能看到这个写操作的结果,或者之后更新的结果。这保证了全局顺序。 FIFO 客户端顺序:来自同一个客户端的所有操作(读和写)都会按照它们发出的顺序被应用。这保证了单个客户端的操作顺序。
- A-线性化:这是对经典线性化定义的扩展,以适应 ZooKeeper 的异步 API。经典定义要求客户端是同步的(一个操作完成后再发下一个)。ZooKeeper 允许客户端异步地发出大量操作,但保证这些操作在服务器端最终会按照客户端发出的顺序(FIFO)被处理。这既提供了强一致性,又提供了高性能。
- 读写分离的性能优势:写操作需要集群共识(通过 Zab 协议),所以慢。读操作可以由任何服务器本地处理(因为数据是复制的),所以非常快。这使得 ZooKeeper 的读吞吐量可以近乎线性地随着服务器数量增长。
- 示例:新领导者配置更新:这个例子完美展示了两个保证如何协同工作。 领导者异步地发出大量写请求(
delete(ready),setData(config1),setData(config2), ...,create(ready))。 由于 FIFO 顺序,这些请求在服务器端会按照这个顺序被处理。 由于线性化写入,所有客户端看到的状态变化顺序是一致的。 因此,任何看到ready节点被创建出来的客户端,必定已经看到了之前所有对configX的修改。这是一个非常强大且有用的属性。 - Watch 顺序保证:Watch 通知先于数据变化对客户端可见。这确保了客户端在读到新数据之前就知道数据已经变了,避免了竞态条件。
sync操作:用于解决“跨信道”问题。如果客户端通过 ZooKeeper 之外的方式(如另一个网络消息)得知数据已变更,它不能直接去读,因为可能读到旧数据(如果它连接的服务器刚好滞后)。sync操作会强制客户端等待,直到它连接的服务器追上了最新的写操作,然后接下来的读操作就能读到最新值。它是一种轻量级的“写操作”,只用于同步状态,不传输数据。
2.4 原语示例
翻译:
在本节中,我们展示如何使用 ZooKeeper API 来实现更强大的原语。ZooKeeper 服务对这些更强大的原语一无所知,因为它们完全是在客户端使用 ZooKeeper 客户端 API 实现的。一些常见的原语,如组成员关系和配置管理,也是无等待的。对于其他原语,例如 rendezvous ,客户端需要等待事件。尽管 ZooKeeper 是无等待的,但我们可以使用 ZooKeeper 实现高效的阻塞原语。ZooKeeper 的顺序保证允许有效地推理系统状态,而监视允许高效地等待。
配置管理 ZooKeeper 可用于在分布式应用程序中实现动态配置。在其最简单的形式中,配置存储在一个 znode zc 中。进程启动时带有 zc 的完整路径名。启动的进程通过读取 zc 并设置 watch 标志为 true 来获取其配置。如果 zc 中的配置被更新,进程会收到通知并读取新配置,再次将 watch 标志设置为 true。
请注意,在此方案中,与大多数其他使用监视的方案一样,监视用于确保进程拥有最新的信息。例如,如果一个正在监视 zc 的进程收到 zc 更改的通知,并且在它能够发出对 zc 的读取之前 zc 又发生了三次更改,该进程不会收到另外三个通知事件。这不会影响进程的行为,因为这三个事件只会通知进程它已经知道的事情:它拥有的 zc 信息已经过时。
Rendezvous 有时在分布式系统中,最终系统配置会是什么样子并不总是先验清楚的。例如,客户端可能想要启动一个主进程和几个工作进程,但启动进程是由调度程序完成的,因此客户端无法提前知道诸如地址和端口等信息,以便提供给工作进程来连接到主进程。我们使用 ZooKeeper 处理这种情况,使用一个 rendezvous znode zr,这是一个由客户端创建的节点。客户端将 zr 的完整路径名作为主进程和工作进程的启动参数传递。当主进程启动时,它用它正在使用的地址和端口信息填充 zr。当工作进程启动时,它们读取 zr 并将 watch 设置为 true。如果 zr 尚未被填充,工作进程等待被通知 zr 被更新。如果 zr 是一个临时节点,主进程和工作进程可以监视 zr 被删除,并在客户端结束时自行清理。
组成员关系 我们利用临时节点来实现组成员关系。具体来说,我们利用临时节点允许我们看到创建节点的会话状态这一事实。我们首先指定一个 znode zg 来表示组。当组中的一个进程成员启动时,它在 zg 下创建一个临时子 znode。如果每个进程有唯一的名称或标识符,则该名称用作子 znode 的名称;否则,进程使用 SEQUENTIAL 标志创建 znode 以获得唯一的名称分配。进程可以将进程信息放在子 znode 的数据中,例如进程使用的地址和端口。
在 zg 下创建子 znode 后,进程正常启动。它不需要做任何其他事情。如果进程失败或结束,代表它的 zg 下的 znode 会自动被移除。
进程可以通过简单列出 zg 的子节点来获取组信息。如果一个进程想要监视组成员关系的变化,该进程可以将 watch 标志设置为 true,并在收到更改通知时刷新组信息(始终将 watch 标志设置为 true)。
解释:
这部分展示了如何用 ZooKeeper 的基础 API 构建高级功能,体现了其“提供机制而非策略”的设计哲学。
- 配置管理:这是一个典型的“发布-订阅”模式。客户端订阅(watch)一个配置节点,当配置变更时收到通知,然后拉取新配置。一次性 Watch 的语义在这里是合适的,因为客户端只需要知道“配置变了”这一事件,而不需要知道变了多少次,最终它都会去拉取最新的完整配置。
- Rendezvous(汇合点):用于解决动态发现问题。主进程的地址信息在启动前是未知的。通过一个预先约定好的 znode (
zr),主进程启动后将自己的地址信息写入这里,工作进程启动后来自动从这里读取。Watch 机制让工作进程在主进程还没启动时能耐心等待。 - 组成员关系:这是临时节点的经典用例。每个进程在组 znode (
zg) 下创建一个临时子节点代表自己。进程存活,节点就在;进程崩溃或断开,节点自动消失。其他进程通过getChildren就能获取到当前在线的、健康的成员列表。配合 Watch,可以实时监控组成员的变化。
翻译:
简单锁 尽管 ZooKeeper 不是一个锁服务,但它可用于实现锁。使用 ZooKeeper 的应用程序通常使用根据其需求定制的同步原语,例如上面显示的那些。这里我们展示如何使用 ZooKeeper 实现锁,以表明它可以实现各种通用的同步原语。
最简单的锁实现使用“锁文件”。锁由一个 znode 表示。为了获取锁,客户端尝试使用 EPHEMERAL 标志创建指定的 znode。如果创建成功,客户端持有锁。否则,客户端可以读取该 znode 并将 watch 标志设置为 true,以便在当前领导者死亡时收到通知。客户端在其死亡或显式删除 znode 时释放锁。一旦观察到 znode 被删除,正在等待锁的其他客户端会再次尝试获取锁。
虽然这个简单的锁协议有效,但它确实有一些问题。首先,它受到羊群效应的影响。如果有许多客户端等待获取锁,当锁被释放时它们都会争夺锁,尽管只有一个客户端可以获取锁。其次,它只实现排他锁。以下两个原语展示了如何克服这两个问题。
无羊群效应的简单锁 我们定义一个锁 znode l 来实现此类锁。直观上,我们将所有请求锁的客户端排队,每个客户端按请求到达的顺序获取锁。因此,希望获取锁的客户端执行以下操作:
加锁
n = create(l + "/lock-", EPHEMERAL|SEQUENTIAL)C = getChildren(l, false)- 如果
n是C中序号最小的 znode,退出(获得锁) p=C中按顺序排在n之前的那个 znode- 如果
exists(p, true)等待 watch 事件 - 回到第 2 步
解锁
delete(n)
在加锁的第 1 行中使用 SEQUENTIAL 标志相对于所有其他尝试对客户端的加锁尝试进行排序。如果客户端的 znode 在第 3 行具有最小的序列号,则客户端持有锁。否则,客户端等待要么持有锁要么将在此客户端的 znode 之前获得锁的那个 znode 被删除。通过仅监视在客户端的 znode 之前的 znode,当锁被释放或锁请求被放弃时,我们通过仅唤醒一个进程来避免羊群效应。一旦客户端正在监视的 znode 消失,客户端必须检查它现在是否持有锁。(先前的锁请求可能已被放弃,并且可能仍然有一个序列号更低的 znode 在等待或持有锁。)释放锁就像删除代表锁请求的 znode n 一样简单。通过在创建时使用 EPHEMERAL 标志,崩溃的进程将自动清理任何锁请求或释放它们可能持有的任何锁。
总之,这种锁方案具有以下优点:
- 一个 znode 的移除只会引起一个客户端被唤醒,因为每个 znode 正好被另一个客户端监视,所以我们没有羊群效应;
- 没有轮询或超时;
- 由于我们实现锁的方式,我们可以通过浏览 ZooKeeper 数据来查看锁争用的程度、打破锁以及调试锁问题。
读写锁 为了实现读写锁,我们稍微修改锁过程,并拥有单独的读锁和写锁过程。解锁过程与全局锁情况相同。
写锁
n = create(l + "/write-", EPHEMERAL|SEQUENTIAL)C = getChildren(l, false)- 如果
n是C中序号最小的 znode,退出 p=C中按顺序排在n之前的那个 znode- 如果
exists(p, true)等待事件 - 回到第 2 步
读锁
n = create(l + "/read-", EPHEMERAL|SEQUENTIAL)C = getChildren(l, false)- 如果
C中没有比n序号更小的写 znode,退出 p=C中按顺序排在n之前的那个写 znode- 如果
exists(p, true)等待事件 - 回到第 3 步
这个锁过程与之前的锁略有不同。写锁仅在命名上不同。由于读锁可以共享,第 3 和第 4 行略有不同,因为只有更早的写锁 znode 会阻止客户端获取读锁。当有几个客户端等待读锁并在序号较低的 “write-” znode 被删除时收到通知,看起来我们可能有了“羊群效应”;事实上,这是一个期望的行为,所有这些读客户端都应该被释放,因为它们现在可能获得了锁。
解释:
这部分展示了如何实现分布式锁,这是最经典的协调原语之一。
- 简单锁(有问题):尝试创建同一个临时节点作为锁。谁创建成功谁就获得锁。问题在于羊群效应:锁释放时,所有等待的客户端都会被通知,然后一起蜂拥而至地竞争,给网络和 ZooKeeper 集群带来巨大压力。
- 无羊群效应的锁(队列锁):这是 ZooKeeper 实现锁的标准且推荐的方式。它利用了顺序临时节点。 排队:每个想获取锁的客户端在锁目录下创建一个顺序临时节点。ZooKeeper 保证了这些节点名称的全局唯一和递增顺序。这相当于所有客户端都拿到了一个排队号。 检查:客户端获取锁目录下的所有子节点(即所有排队号)。 判断:如果自己的节点是序号最小的,则获得锁。 等待:如果不是,它只监视排在自己前面的那个节点的存在与否(
exists(p, true))。 链式唤醒:当前一个节点被删除(代表前一个客户端释放了锁)时,只有监视它的这一个客户端会被通知。然后这个客户端醒来,检查自己是否变成了最小的节点(是则获锁,否则继续监视新的前一个节点)。
这样,锁的释放只会唤醒一个客户端,完全避免了羊群效应。这是一个非常巧妙的设计。 - 读写锁:在队列锁的基础上进行扩展。核心思想是: 写锁:是排他的,所以逻辑和普通队列锁一样。它必须等待所有前面的节点(无论是读是写)释放。 读锁:是共享的。它只需要等待前面的写锁释放即可。一旦前面没有写锁了,所有的读锁可以同时共享资源。当最后一个写锁释放时,它会通知下一个节点(可能是一个读锁,也可能是一个写锁)。如果下一个是读锁,那么这个读锁获锁,并且由于读锁可以共享,它之后连续的所有读锁都可以同时获锁,这就造成了“羊群效应”,但这是读写锁语义所期望的。
翻译:
双屏障 双屏障使客户端能够同步计算的开始和结束。当足够多的进程(由屏障阈值定义)加入屏障后,进程开始其计算,并在完成后离开屏障。我们在 ZooKeeper 中用一个称为 b 的 znode 来表示一个屏障。每个进程 p 在进入时通过创建一个作为 b 的子节点的 znode 来向 b 注册,并在准备离开时注销——删除该子节点。当 b 的子 znode 数量超过屏障阈值时,进程可以进入屏障。当所有进程都移除了它们的子节点时,进程可以离开屏障。我们使用监视来高效地等待进入和退出条件得到满足。为了进入,进程监视 b 的一个就绪子节点的存在,该子节点将由导致子节点数量超过屏障阈值的进程创建。为了离开,进程监视一个特定的子节点消失,并且仅在该 znode 被移除后检查退出条件。
解释:
- 双屏障:用于同步一个分布式计算的开始和结束。例如,所有进程必须等到 N 个进程都准备好才开始计算,并且必须等到所有进程都计算完才一起结束。
- 实现: 注册:每个进程在屏障 znode
b下创建一个子节点(通常是临时节点)来注册自己。 进入(开始):进程通过getChildren检查b的子节点数量。如果数量达到阈值,就可以开始计算。如果没达到,可以 watchb的子节点变化,等待条件满足。论文中提到一个优化:由一个进程在条件满足时创建一个ready节点,其他进程 watch 这个ready节点是否存在,这样可以避免所有进程都去 watchb的子节点列表变化(羊群效应)。 离开(结束):进程计算完成后,删除自己注册的节点。然后,它需要等待所有其他进程也删除它们的节点(即子节点数量降为0)。同样,可以通过 watch 最后一个被删除的节点来实现高效等待。
总结
这篇论文详细阐述了 ZooKeeper 作为一个分布式协调“内核”的设计理念、实现机制和广泛应用。其核心在于提供一个简单、高效、可靠的基础数据模型(分层命名空间、znode、Watch)和 API,并通过强大的一致性保证(线性化写、FIFO 客户端顺序)使得客户端能够在此基础上构建出各种复杂的分布式协调原语,如配置管理、服务发现、分布式锁、队列、屏障等。这种“机制而非策略”的设计使得 ZooKeeper 极其灵活和强大,成为众多分布式系统的基础组件。
Consistency and Linearizability
6.5840 2025 讲座4:一致性模型,线性一致性
今日主题:一致性模型,特别是线性一致性
存储作为独立服务非常普遍
因此计算和存储分离,通过RPC通信
[简单图示]
例如:网站应用逻辑 vs 数据库
例如:MapReduce vs GFS
我们需要能够推理分布式存储的正确行为
例如:应用开发者对GFS或实验2的期望
部分涉及单个请求的行为
今日重点:并发客户端如何交互
--> 一致性模型
什么是一致性模型?
规范不同客户端对服务视图的关系
聚焦带网络客户端的键值存储:
put(k, v) -> <完成>
get(k) -> v
给定put/get调用,哪些结果是有效的?
在普通顺序编程中无需讨论:
我们期望读操作返回最后写入的值
何时需要讨论正确性?
[简单客户端/服务器图示]
读与写并发
副本
缓存
故障恢复
消息丢失
重传
为何存储系统需要显式一致性模型?
对应用:没有存储保证则难以确保正确性
例如生产者计算后执行:
put("result", 27)
put("done", true)
消费者执行:
while get("done") == false:
pause
v = get("result")
v是否保证为27?
对服务:没有规范则难以设计/实现/优化
例如:客户端从GFS副本(而非主节点)读取是否可行?
存在多种一致性模型
有时为简化应用开发者工作
有时为追求存储性能
有时描述实现者便利的行为
不同领域定义重叠(如文件系统、数据库、CPU内存)
今日重点:线性一致性
但也会涉及:
最终一致性
因果一致性
分叉一致性
可串行化
驱动力:性能/便利性/容错的权衡
线性一致性
这是一种规范——服务必须如何行为的要求
从客户端视角:从服务外部观察
通常被称为"强一致性"
线性一致性较符合程序员直觉
但排除许多优化
你将在实验2实现线性化键值存储
并在实验4中实现容错版本
起点
假设存在串行规范定义单个操作行为
串行 = 单服务器顺序执行操作
db[]
put(k, v):
db[k] = v
return true
get(k):
return db[k]
此处无意外
并发客户端操作如何处理?
客户端发送请求:
网络传输耗时;
服务器计算,与副本通信等;
回复通过网络返回;
客户端接收回复
在此期间其他客户端可能发送/接收/等待!
因此串行规范不能直接应用
我们需要描述并发场景的方法,
以讨论哪些结果有效/无效
定义:历史记录
描述可能并发操作的时间线
每个操作有客户端开始和结束时间
(客户端发送RPC请求和接收回复的时间)
以及参数和返回值
示例:
C1: |-Wx1-| |-Wx2-|
C2: |---Rx2---|
X轴为真实时间
|- 表示客户端发送请求时间
-| 表示客户端接收回复时间
"Wx1"表示put(x, 1)
"Rx2"表示get(x) -> 2
C1发送put(x,1),收到回复,发送put(x,2),收到回复
写操作有响应,表示完成
C2发送get(x),收到回复=2
历史记录是实际执行中客户端观察的追踪
用于检查执行是否线性化
设计者用于"这样是否可行"的思想实验
定义:历史记录线性化当且仅当
- 能为每个操作在开始(客户端发出请求)和结束(客户端收到回复)之间找到一个时间点(客户端操作在服务器端已完成)
- 历史记录的结果值与按时间点顺序串行执行相同
示例历史1:
|--Wx1--| |--Wx2--|
|----Rx2----|
|--Rx1--|
此历史是否线性化?
能否为每个操作找到线性化点?
可能需要尝试不同时间点分配方案
以下顺序满足规则:
Wx1 Rx1 Wx2 Rx2
- 每个点位于开始和结束之间
- 序列满足串行put/get规范
注意:任一读操作可能返回1或2
因此线性化常允许多种不同结果
我们常无法提前预测,但可事后检查
注意:服务可能未在这些点执行操作!
我们不关心服务内部如何运作
只关注客户端可见结果可能
源于某种时间点顺序的执行
线性化定义的用途?
设计者:此优化是否导致非线性化结果?
程序员:作为客户端能假设/期望什么?
测试:生成请求,检查观察到的历史
为何称"线性化"?
线性化点将并发操作转为串行执行——"线性"
因此"可线性化"指结果等同于
操作的某种线性执行
示例2:
|-Wx1-| |----Wx2----|
|---Rx2---|
|-Rx1-|
可尝试几种线性化点分配
如Wx1 Wx2 Rx2 Rx1?
无效,因"Wx2 Rx1"不符合串行规范
如何证明非线性化?
证明无时间点分配方案可行
即违反时间规则或值规则
常可简化排除大量分配方案
例如时间规则要求Wx1或Rx2必须在前
此示例无可行方案!
Wx2的点必须在Rx2之前
因此Wx2点也在Rx1之前
第二次读获得不可能的值
若系统产生此历史,则说明:
系统非线性化:存在缺陷,或从未承诺线性化
若无Rx2,Rx1本可合法
读(及写)操作会影响未来的合法性
因此若需线性化:
一旦读操作观察到写,所有严格后续读必须也观察到
排除脑裂
不能遗忘已揭示的写操作
排除如崩溃后遗忘数据
GFS非线性化:可能产生示例2历史
因Rx1可能来自未更新的副本
若需GFS线性化,
一种方法是让客户端读也通过主节点
但会更慢!
示例3:
|--Wx0--| |--Wx1--|
|--Wx2--|
|-Rx2-| |-Rx1-|
看似非线性化:因Rx2应强制第二次读也看到2
但此顺序显示可线性化:Wx0 Wx2 Rx2 Wx1 Rx1
因此:
服务可为并发写选择任意顺序
线性顺序可与开始/结束时间不同!
示例4:
|--Wx0--| |--Wx1--|
|--Wx2--|
C1: |-Rx2-| |-Rx1-|
C2: |-Rx1-| |-Rx2-|
是否存在串行顺序?
C1需 Wx2 Rx2 Wx1 Rx1
C2需 Wx1 Rx1 Wx2 Rx2
无法同时满足Wx2在Wx1前和后
故非线性化
因此:
服务可为并发写选择任意顺序
但所有客户端必须看到相同写顺序
存在副本或缓存时至关重要
所有副本必须以相同顺序执行操作
示例5:
|-Wx1-|
|-Wx2-|
|-Rx1-|
无可行顺序——非线性化
因此:
读必须返回最新数据:线性化排除陈旧读
即使读者不知晓写操作
时间规则要求读返回最新数据
再次影响缓存和副本的使用
线性化禁止的诱人设计/错误:
脑裂(双主节点)
崩溃重启后遗忘已完成写操作
从滞后副本或过期缓存读取
示例6:
[客户端/网络/服务器图示]
C1发送put(x,1)
C2发送put(x,2)
服务接收C1请求;
网络丢弃响应;
C1的RPC库重传请求
服务执行C1的两个请求是否合法?
若C3读取三次可能看到:
C1: |--------Wx1---------| (due to retransmission(重传))
C2: |-Wx2-|
C3: |-Rx1-| |-Rx2-| |-Rx1-|
假设x初始为0
此历史非线性化!
因此若需线性化:
必须抑制重传的重复请求!
实验2...
线性化系统不限于读写操作
递增
追加
测试并设置(实现锁)
服务器状态的任何操作
应用开发者青睐线性化——相对易用:
- 读看到新数据——非陈旧
- 无写时所有客户端看到相同数据
- 所有客户端以相同顺序看到数据变更
因此put(v,27); put(done,true)示例成立
对比弱一致性时这些优势更明显
如何实现线性化?
取决于所需的副本数、缓存和容错能力
单机串行无故障服务器
[图示:客户端、服务器、操作队列、状态]
服务器为并发到达的请求选择顺序
按序逐个执行,
回复后再处理下一个
加上重复请求抑制
注意:服务器无需推理历史、
线性化点或并发
能否有比线性化更强的一致性?
例如get看到最近完成的put?
此场景保证Rx2,永不Rx1:
C1: |---Wx1---|
C2: |---Wx2---|
C3: |--Rx2--|
此场景保证Rx1,永不Rx2:
C1: |---Wx1---|
C2: |---Wx2---|
C3: |--Rx1--|
如此一个保证可能是困难的:
服务器不易知晓操作何时在客户端完成
线性化对服务器友好,因其允许
自由排序并发操作
若需高可用性?
主备复制
[图示:主节点、两个备节点]
所有请求到主节点
选择串行顺序
转发给备节点
备节点按相同顺序执行
主节点仅在备节点执行后回复客户端
因此若客户端收到响应,所有备节点保证已执行
主节点故障时至关重要
避免遗忘已完成请求
客户端不能像GFS中直读备节点
C1可能看到新值,后续又看到旧值
需外部仲裁决定备节点接管
避免脑裂
例如VMware FT共享磁盘的原子测试并设置,或GFS协调者
线性化系统性能?
坏消息:串行特性难以并行加速
坏消息:副本化需大量通信和等待
坏消息:副本化要求副本可达,限制容错
好消息:可按键分片
其他一致性模型?
能否提供更好性能?
是否有直观语义?
示例:最终一致性——弱模型
数据多副本(如不同数据中心)
读操作咨询任意副本(如最近)
写操作更新任意副本(如最近)
副本a在单次更新完成后即响应
副本后台同步更新
最终其他副本将看到更新
最终一致性较流行
比线性化更快
尤其副本在不同城市时
可用性更高——任意副本即可响应
无需等待主备通信
Amazon Dynamo;Cassandra;GFS
但最终一致性向应用开发者暴露异常:
- 读可能看不到最新写——读可能看到陈旧数据
密码更改、ACL变更时成问题 - 写可能乱序
破坏result/done示例 - 不同客户端可能看到不同数据
- 并发写同一项需解决冲突!
C1: put(x,1)
C2: put(x,2)
可能先应用于不同副本
之后才同步到其他副本
如何合并并发新值?
如何确保所有副本选择相同终值?
最终达成一致 - 最终一致性不支持测试并设置等操作
通用模式:通常只能二选一
强一致性
最大可用性
不可兼得
强一致性需等待副本更新,
过多副本不可达时无法进行
故可用性差
最终一致性在无其他副本可达时仍可进行
但一致性弱
FAQ(frequently asked questions 常见问题解答)
好的,这是您提供的关于线性一致性的问答内容的中文翻译:
问:什么是线性一致性?
答: 线性一致性是定义服务在面对并发客户端请求时行为正确性的一种方式。粗略地说,它规定服务应该表现得好像它按照客户端操作到达的顺序一个接一个地执行这些操作。
线性一致性是针对“历史”(history)定义的:即客户端操作的追踪记录,标注了客户端开始每个操作的时间以及客户端看到该操作完成的时间。线性一致性告诉你单个历史是否合法;如果服务可能生成的每个历史都是线性一致的,我们就可以说该服务是线性一致的。
历史中有一个事件对应客户端开始一个操作,另一个事件对应客户端判定操作已完成。因此,历史显式地体现了客户端之间的并发性和网络延迟。通常,开始和完成事件对应于与服务器交换的请求和响应消息。
一个历史是线性一致的,如果你能为每个操作分配一个“线性化点”(一个时间点),其中每个操作的点位于其开始和完成事件的时间之间,并且历史的响应值与如果你按点顺序一个接一个地执行操作所得到的值相同。如果没有线性化点的分配能满足这两个要求,则该历史不是线性一致的。
线性一致性的一个重要结果是服务在执行并发(时间上重叠的)操作顺序方面具有自由度。特别是,如果客户端 C1 和 C2 的操作是并发的,服务器可以执行 C2 的操作在先,即使 C1 在 C2 之前开始。另一方面,如果 C1 在 C2 开始之前完成,线性一致性要求服务表现得好像它在 C2 的操作之前执行了 C1 的操作(即,如果有的话,C2 的操作必须观察到 C1 操作的效果)。
问:线性一致性检查器如何工作?
答: 一个简单的线性一致性检查器会尝试所有可能的顺序(或线性化点的选择),以查看是否有一种顺序根据线性一致性的定义规则是有效的。因为这在大型历史上会太慢,聪明的检查器会避免查看明显不可能的排序(例如,如果提议的线性化点在操作开始时间之前),将历史分解成可以单独检查的子历史(当可能时),并使用启发式方法优先尝试更可能的顺序。
这些论文描述了相关技术;我认为 Knossos 基于第一篇论文,而 Porcupine 添加了第二篇论文的思想:
http://www.cs.ox.ac.uk/people/gavin.lowe/LinearizabiltyTesting/paper.pdf
https://arxiv.org/pdf/1504.00204.pdf
问:服务是否使用线性一致性检查器来实现线性一致性?
答: 不;检查器仅作为测试的一部分使用。
问:那么服务如何实现线性一致性?
答: 如果服务实现为单个服务器,没有复制、缓存或内部并行性,那么服务按照请求到达的顺序一个接一个地执行客户端请求几乎就足够了。主要的复杂性来自于客户端因为认为网络丢失消息而重发请求:对于有副作用的请求,服务必须注意只执行任何给定的客户端请求一次。如果服务涉及复制或缓存,则需要更复杂的设计。
问:有没有使用 Porcupine 或类似测试框架测试过的现实世界系统的例子?
答: 这种测试很常见——例如,看看 ;Jepsen 是一个组织,它测试了许多存储系统的正确性(以及在适用情况下的线性一致性)。
具体到 Porcupine,这里有一个例子:
问:其他一致性模型有哪些?
答: 可以查找
最终一致性 (eventual consistency)
因果一致性 (causal consistency)
分叉一致性 (fork consistency)
可串行化 (serializability)
顺序一致性 (sequential consistency)
时间线一致性 (timeline consistency)
在数据库、CPU 内存/缓存系统和文件系统领域还有其他的模型。
一般来说,不同的模型在它们对应用程序员有多直观,以及你能用它们获得多少性能方面有所不同。例如,最终一致性允许许多异常结果(例如,即使一个写操作已完成,后续的读取也可能看不到它),但在分布式/复制环境中,它可以比线性一致性以更高的性能实现。
问:为什么线性一致性被称为强一致性模型?
答: 它在禁止许多可能让应用程序员惊讶的情况的意义上是“强”的。
例如,如果我调用 put(x, 22),并且我的 put 完成了,并且没有其他人写 x,随后你调用 get(x),线性一致性保证你看到的除了 22 之外没有其他值。也就是说,读取看到的是新数据。
再举一个例子,如果没有人写 x,我调用 get(x),你也调用 get(x),我们不会看到不同的值。
这些属性在我们稍后将看到的其他一些一致性模型中并不成立,例如最终一致性和因果一致性。后面这些模型通常被称为“弱”一致性。
问:在实践中,人们如何确保他们的分布式系统是正确的?
答: 彻底的测试是一个常见的计划。
形式化方法的使用也很常见;这里有一些例子:
~stavros/papers/2022-cpp-published.pdf
问:为什么使用线性一致性作为一致性模型,而不是其他模型,比如最终一致性?
答: 人们确实经常构建提供比线性一致性更弱一致性的存储系统,例如最终一致性和因果一致性。
线性一致性对应用程序编写者有一些很好的特性:
- 读取总是观察到新数据。
- 如果没有并发写入,所有读取者看到相同的数据。
- 在大多数线性一致的系统上,你可以添加像测试并设置(test-and-set)这样的小型事务(因为大多数线性一致的设计最终会对每个数据项上的操作进行一个接一个的执行)。
像最终一致性和因果一致性这样的较弱方案可以实现更高的性能,因为它们不需要立即更新所有数据副本。这种更高的性能通常是决定性因素。对于一些应用程序,弱一致性不会引起问题,例如,如果存储的是从不更新的数据项,如图像或视频。
然而,弱一致性给应用程序编写者带来了一些复杂性:
- 读取可能观察到过时(陈旧)的数据。
- 读取可能观察到乱序的写入。
- 如果你写入,然后读取,你可能看不到你的写入,而是看到陈旧的数据。
- 对相同项目的并发更新不是一次一个执行的,因此很难实现像测试并设置或原子递增这样的小型事务。
问:你如何决定那条橙色小线(操作的线性化点)放在哪里?在图中,它看起来像是随机画在请求主体内的某个地方。
答: 其思想是,为了证明一个执行是线性一致的,你(作为人)需要找到放置这些橙色小线(线性化点)的位置。也就是说,为了证明一个历史是线性一致的,你需要找到一个线性化点的分配(从而一个操作顺序),该分配符合这些要求:
- 所有函数调用在其调用和响应之间的某个瞬间有一个线性化点。
- 所有函数在其线性化点瞬间发生,行为符合顺序定义。
因此,一些线性化点的放置是无效的,因为它们位于请求的时间跨度之外;另一些是无效的,因为它们违反了顺序定义(对于键值存储,违反意味着读取没有观察到最近写入的值,这里的“最近”指的是线性化点)。
对于一个复杂的历史,你可能需要尝试许多线性化点的分配,以找到一个能证明该历史是线性一致的分配。如果你尝试了所有可能都无法找到,那么这个历史就不是线性一致的。
问:是否存在这样的情况:当两个命令同时执行时,我们能够强制执行特定的行为,使得一个命令总是先执行(即它总是有一个更早的线性化点)?
答: 在一个线性一致的存储服务中(例如 GFS 或你的 Lab 4),如果来自多个客户端的请求是并发的,服务可以自由选择执行它们的顺序。在实践中,大多数服务按照请求碰巧到达网络的顺序执行请求。实际的实现通常不涉及显式的线性化点概念。
问:我们可以执行哪些其他类型的更强的一致性检查?不知何故,线性一致性在直觉上感觉不太有帮助,因为即使你在同一时间执行两个命令,你也可能读取到不同的数据。
答: 确实,线性一致性让人想起在程序中使用线程而不使用锁。这种方式可以正确编程,但需要小心。
更强一致性概念的一个例子是事务(transactions),如许多数据库中发现的,它有效地锁定了所使用的任何数据。对于读写多个数据项的程序,事务比线性一致性更容易编程。“可串行化”(Serializability)是提供事务的一种一致性模型的名称。
然而,事务系统比线性一致系统要复杂得多、慢得多,并且更难实现容错。
问:是什么使得验证现实系统涉及“巨大的努力”?
答: 验证意味着证明一个程序是正确的,保证它符合某些规范。事实证明,证明关于复杂程序的重要定理是困难的——比普通编程困难得多。
你可以尝试本课程的实验来感受一下:
问:根据指定的阅读材料,大多数分布式系统并没有被正式证明是正确的。那么一个团队如何决定他们已经对产品进行了足够彻底的测试,可以交付给客户?
答: 在产品上市并获得收入之前就开始发货是一个好主意,否则公司可能会耗尽资金而破产。人们会在此之前尽可能多地进行测试,并且通常会说服一些早期客户使用该产品(并帮助发现错误),同时理解它可能无法正常工作。也许当产品功能足以满足许多客户并且没有已知的重大错误时,你就准备好发货了。
除此之外,明智的客户也会测试他们所依赖的软件。任何严肃的组织都不会期望任何软件没有错误。
问:为什么不使用客户端发送命令的时间作为线性化点?也就是说,让系统按照客户端发送操作的顺序执行操作?
答: 构建一个保证这种行为的系统很困难——开始时间是客户端代码发出请求的时间,但由于网络延迟,服务可能直到很久以后才收到请求。也就是说,请求到达服务的顺序可能与开始时间的顺序大不相同。原则上,服务可以延迟执行每个到达的请求,以防有更早发出时间的请求稍后到达,但很难知道要等多久,因为网络延迟可能是无界的。而且这会增加每个请求的延迟,可能增加很多。话虽如此,我们稍后将看到的 Spanner 使用了相关的技术。
像线性一致性这样的正确性规范需要在足够宽松以便高效实现,但又足够严格以向应用程序提供有用保证之间走一条细线。“看起来按调用顺序执行操作”对于高效实现来说太严格了,而线性一致性的“看起来在调用和响应之间的某个时间点执行”是可实现的,尽管对应用程序员来说不那么直观。
问:如果同时存在一个并发的 put(),并发的 get() 可能看到不同的值,这是一个问题吗?
答: 在存储系统的背景下,这通常不是问题。例如,如果我们讨论的值是我的个人资料照片,并且两个不同的人在我更新照片的同时请求查看它,那么他们看到不同的照片(旧的或新的)是合理的。
问:在哪些应用场景下,线性一致性比弱一致性模型更容易编程?
答: 假设应用程序的一部分计算一个值,将其写入存储系统,然后在存储系统中设置一个标志,指示计算的值已就绪:
v = compute...
put("value", v)
put("done", true)
在另一台计算机上,一个程序检查 "done" 以查看值是否可用,如果可用就使用它:
if get("done") == true:
v = get("value")
print v
如果实现 put() 和 get() 的存储系统是线性一致的,上述程序将按预期工作。
对于许多弱一致性模型,上述程序可能不会如人们所希望的那样工作。例如,提供“最终一致性”的存储系统可能会对两个 put 进行重排序(导致 "done" 为 true 而 "value" 不可用),或者可能为任何一个 get() 返回一个陈旧(旧)的值。
问:现实世界中有哪些线性一致存储系统的例子?以及哪些存储系统提供较弱的一致性保证?
答: Google 的 Spanner 和 Amazon 的 S3 是提供线性一致性的存储系统。
Google 的 GFS、Amazon 的 Dynamo 和 Cassandra 提供较弱的一致性;它们可能最好被归类为最终一致的。
一些BUG
调用RPC时不要加锁
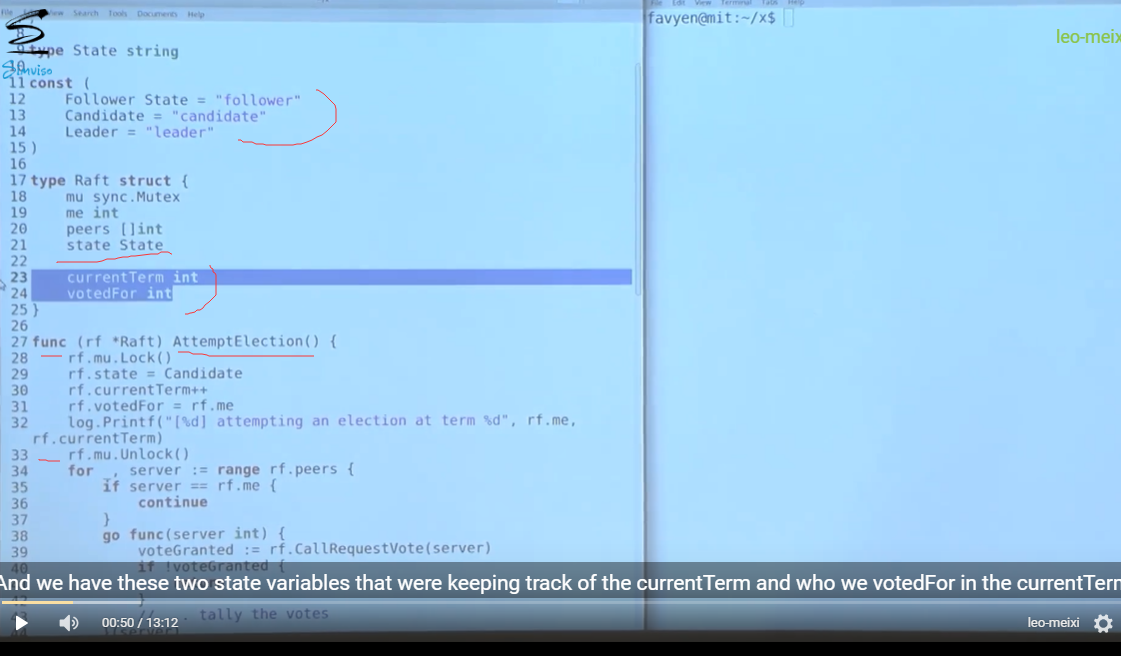
attemptElection()
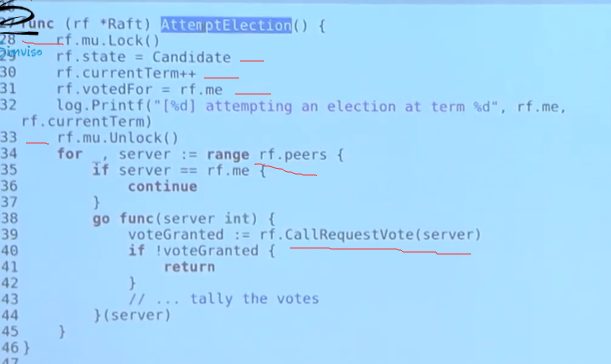
callRequestVote()
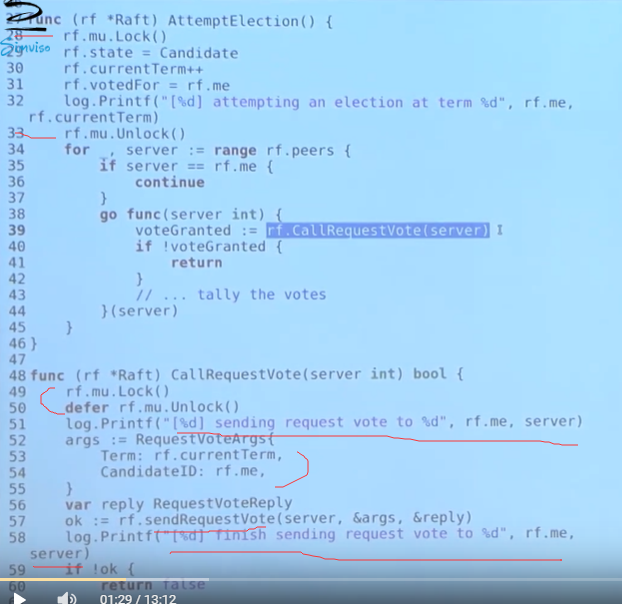
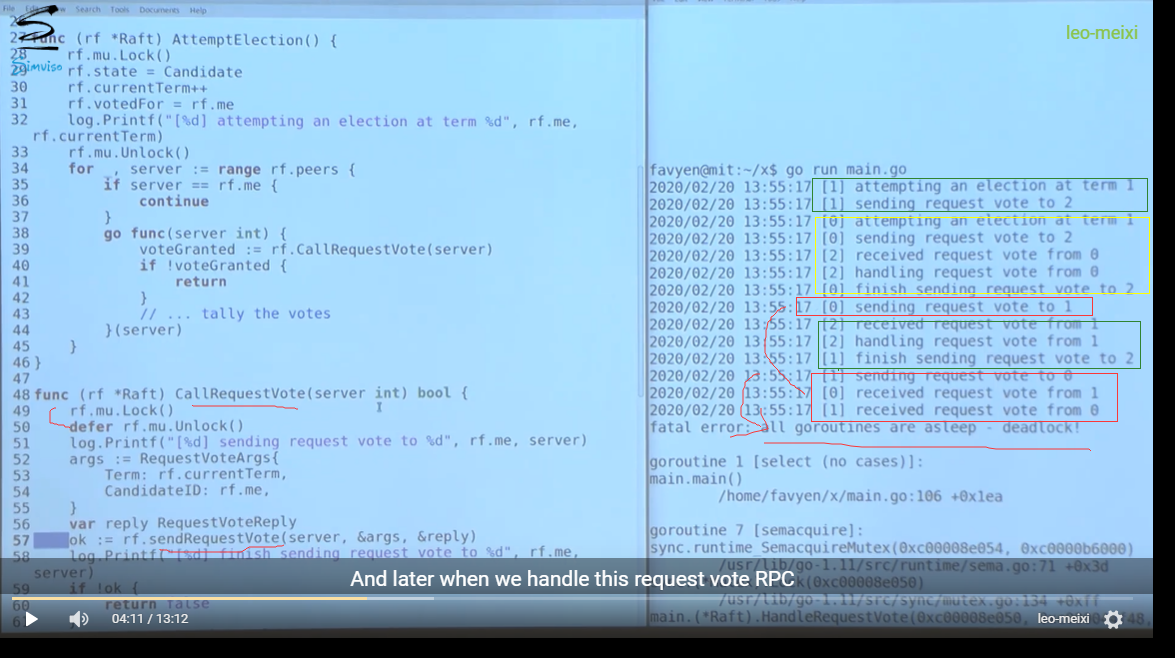
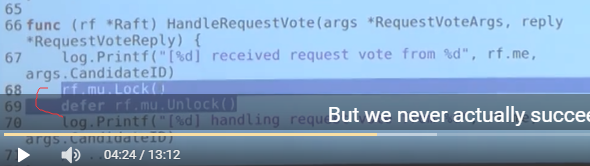
结果死锁了, 原因如下:
- call rpc 和 receive rpc 过程都加锁了
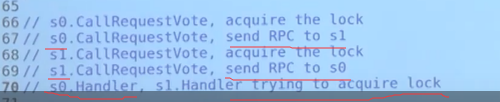
- 尝试重复加锁导致死锁
解决死锁:
- 首先加锁是为了保护共享变量 currrentTerm
- 两个思路,
- 在callRequestVote中并没有改变currrentTerm, 因此可以把currrentTerm当做局部变量(函数的参数传进来);
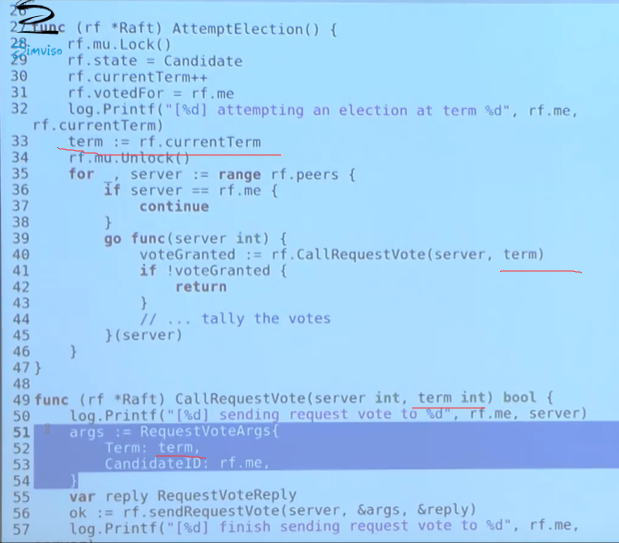
- 在callRequestVote中保护currrentTerm后及时释放锁
此外如果网络不可靠, 你在rpc的时候使用了锁, 那么就会导致其他go routinue 阻塞, 降低效率
因此,在调用rpc时不要加锁
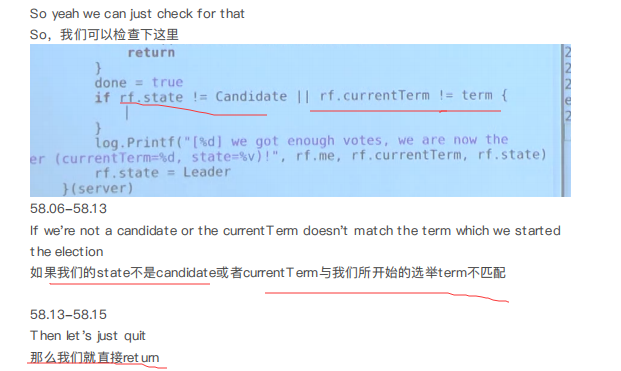
增加了选举计数机制, 一个Term内出现了两个leader
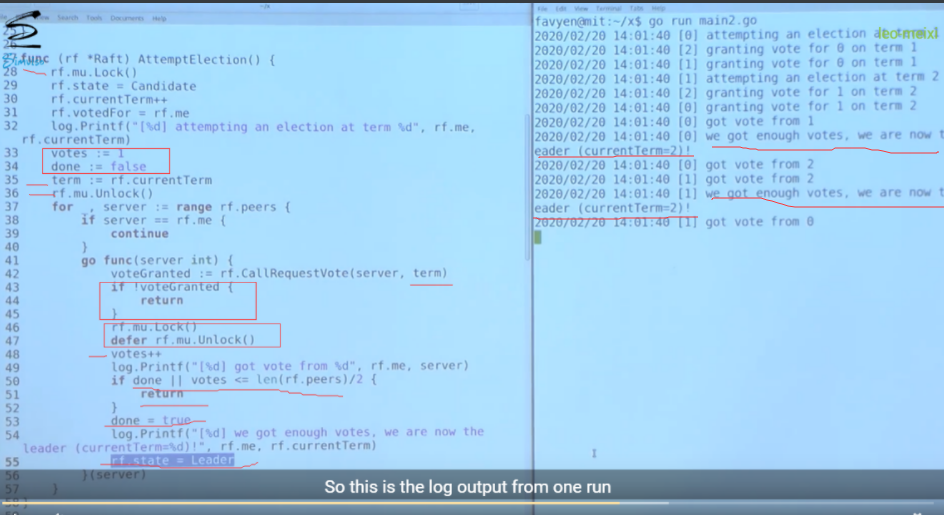
问题就是, 0在处理投票结果之前(成为leader之前)收到了1的RequestVote, 由于1的termId : 2 > 1(0的Termid), 所以0会把状态从candidate变为follower, 并且Termid设为2, 但是我们在选举计数处理中,在投票超过半数后, 直接把状态改成了leader, 即没有对当前的Termid和states进行检查

怎么去DEBUG
加printf—> 缩小排查范围
最好在printf中加上位置信息, eg: 哪个文件, 哪个函数, 哪一行, 能帮助你快速定位BUG位置
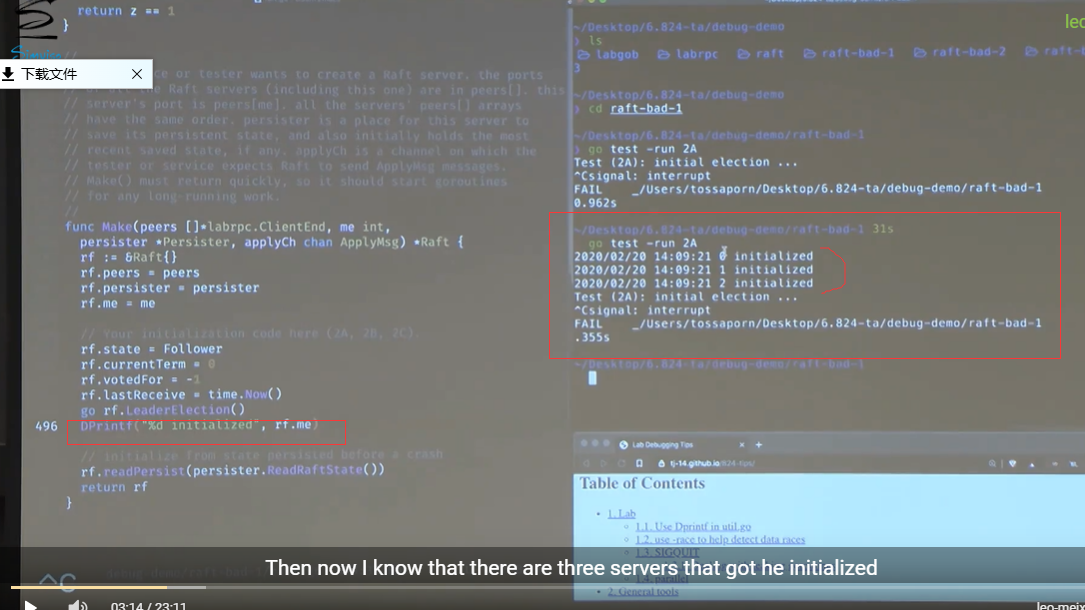
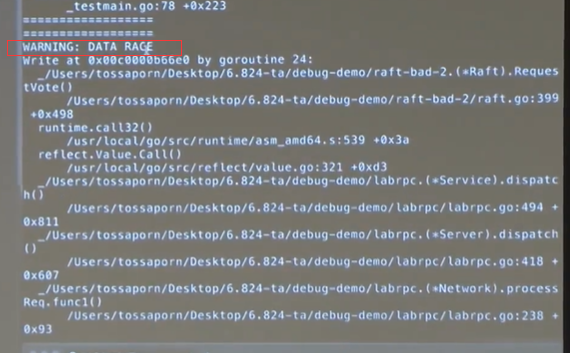
测试加 -race
在测试的时候加 -race 可以检测出data race的情况
raft
回顾


vm依赖test-and-set在脑裂的时候判断哪个是Primary
网络是不可靠的, 一旦网络分区就容易发生脑裂, 要想办法解决

-
节点总数最好是奇数
-
节点数和最大卡发生故障次数关系:
-
一个candidate想成为新的leader, 支持新leader和旧leader中的followers中肯定有重合的(至少有一个), 也就是说新leader想上位必须要争取至少一个支持过旧leader的follower的投票(或者它本身就是) —> 这个candidate的log要足够新;
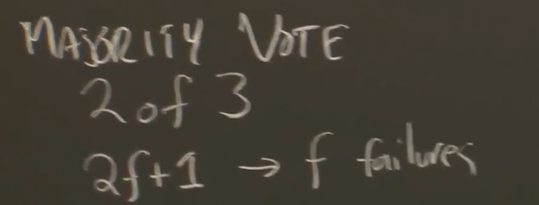
6.5840 2025 讲座5:Raft (第一部分)
本次讲座内容
- 今日主题: 状态机复制、多数决原则与 Raft 选举(实验 3A)
- 下期预告: Raft 持久化、客户端行为与快照机制(实验 3B, 3C, 3D)
*主题:状态机复制 (State-Machine Replication)
- 构建容错应用程序的一种流行方法
- 客户端将操作发送给主节点 (Primary)
- 主节点对操作进行排序并发送给备份节点 (Backups)
- 所有副本 (Replicas) 执行所有操作
- 如果起始状态相同、
- 执行的操作相同、
- 执行顺序相同、
- 且操作是确定性的 (Deterministic),
- 那么最终状态必然相同。
- 示例:VM FT (虚拟机容错) 中的主备模式
- 操作单元:机器指令 (Instructions)
- 主节点故障怎么办?
- • 在 GFS (Google 文件系统) 中,协调器 (Coordinator) 会挑选新的主节点。
- • 如果协调器自身故障了怎么办?
- 能否让副本节点自主选举新主节点?
- 考虑两个服务器 S1 和 S2 的场景:
- 如果两者都正常运行,S1 负责,将决策转发给 S2。
- 如果 S2 发现 S1 宕机,S2 接管成为协调器。
- 可能出现什么问题?
- 网络分区 (Network Partition)!脑裂 (Split Brain)!
- 考虑两个服务器 S1 和 S2 的场景:
- 核心难题: 计算机无法区分“服务器崩溃”和“网络中断”
- 两者的症状相同:通过网络发送的查询没有响应。
- 这个难题在很长一段时间内似乎无法克服。
- 似乎需要外部代理(例如人类)来决定何时切换服务器。
- 我们更倾向于一种自动化方案!
*主题:多数决原则 (Majority Rule)
- 应对网络分区的关键洞见:多数表决机制 (Majority Vote)
- 配置奇数台服务器(例如 3 台)。
- 任何决策都需要获得多数派 (Majority) 的同意 —— 例如 3 台中的 2 台。
- 如果无法形成多数派,则等待。
- 为什么多数派能帮助避免脑裂?
- 最多只有一个分区 (Partition) 能够拥有多数派。
- 这打破了我们在仅有两台服务器时看到的对称性困局。
- 注意: 多数派是基于所有服务器总数计算的,而不仅仅是当前存活的服务器。
- 注意: 获得多数派同意后立即推进操作。
- 不要等待更多响应,因为它们可能已经宕机。
- 更通用的公式:
2f + 1台服务器可以容忍f台服务器故障。- 因为剩余的
f + 1台服务器构成了2f + 1的多数派。 - 如果超过
f台服务器故障(或无法联系),则系统无法取得进展。
- 因为剩余的
- 这种机制通常被称为“法定人数 (Quorum)”系统。
- 多数派的一个关键特性: 任意两个多数派必有交集 (Intersect)。
- 交集内的服务器可以传递关于先前决策的信息。
- 例如:当前任期 (Term) 已经选举了另一个 Raft 领导者。
- 大约在 1990 年,发明了两种分区容忍的复制方案:
- Paxos 和 视图戳复制 (View-Stamped Replication, VSR)。
- 它们被称为“共识 (Consensus)”或“一致性协议 (Agreement Protocols)”。
- 在过去的 15 年里,这项技术得到了大量的实际应用。
- Raft 论文是了解现代技术的一个很好的入门指南。
*主题:基于 Raft 的状态机复制 (State-Machine Replication with Raft)
- 使用 Raft 实现状态机复制 —— 以实验 2 + 4 为例:
- [架构图:客户端 (Clients), 3 个副本 (Replicas), 键值层 (k/v layer) + 状态机 (state), Raft 层 (raft layer) + 日志 (logs)]
- Raft 是一个库 (Library),包含在每个副本中。
- 一个客户端命令的时序图:
- [C (客户端), L (领导者), F1, F2 (跟随者)]
- 客户端向领导者 (Leader) 的键值层发送 Put/Get “命令”。
- 键值层调用
Start()来调用 Raft。- 领导者的 Raft 层将命令添加到其日志中。
- 领导者向跟随者 (Followers) 发送 AppendEntries RPCs。
- 跟随者将命令添加到它们各自的日志中。
- 领导者等待来自简单多数派 (Bare Majority)(包括它自己)的回复。
- 如果一个多数派将命令放入了它们的日志中,则该日志条目 (Entry) 被视为“已提交 (Committed)”。
- “已提交”意味着即使发生故障也不会被遗忘。
- 多数派 -> 该条目将在下一任领导者的投票请求中被看到。
- 领导者通过下一次 AppendEntries RPC “捎带 (Piggybacks)” 提交信息。
- 一旦条目被提交,领导者和跟随者将命令交给键值层执行。
- 对应实验中的
ApplyMsg和applyCh。
- 对应实验中的
- 领导者向客户端发送响应。
- 为什么需要日志 (Logs)?
- 服务 (Service) 维护状态机的状态,例如键/值数据库 (Key/Value DB)。
- 日志是相同信息的另一种表示形式!
- 为什么两者都需要?
- 日志对命令进行排序 (Orders)。
- 帮助副本就单一的执行顺序达成一致。
- 帮助领导者确保跟随者拥有相同的日志。
- 日志存储临时 (Tentative) 命令直到它们被提交。
- 日志存储命令,以防领导者需要重新发送给跟随者。
- 日志持久化 (Persistently) 存储命令,以便在重启后重放 (Replay)。
- 服务 (Service) 维护状态机的状态,例如键/值数据库 (Key/Value DB)。
- 各服务器的日志是彼此完全相同的副本吗?
- 否: 一些副本可能滞后 (Lag)。
- 否: 我们会看到它们可能暂时拥有不同的条目。
- 好消息:
- 它们最终会收敛 (Converge) 为完全相同。
- 提交机制确保服务器只执行稳定的 (Stable) 条目。
- 实现挑战:
- 故障 (Failures)
- 网络分区、消息丢失、服务器崩溃。
- 并发 (Concurrency)
- 服务器内部以及服务器之间的并发。
- 结果: 存在许多可能的执行路径和许多边界情况 (Corner Cases)。
- 需要处理大量细节 —— 见图 2 (Figure 2)。
- 今日重点: 选举新领导者必须应对这些挑战。
- 故障 (Failures)
*主题:领导者选举 (Leader Election) (实验 3A)
- 为什么需要领导者?
- 确保所有副本以相同的顺序执行相同的命令。
- (一些设计,例如 Paxos,没有领导者)。
- Raft 为领导者序列编号:
- 新领导者 -> 新任期 (New Term)。
- 一个任期最多有一个领导者;也可能没有领导者。
- 编号有助于服务器跟随最新的领导者,而不是被取代的 (Superseded) 领导者。
- Raft 节点何时开始领导者选举?
- 当它在“选举超时 (Election Timeout)”期间内没有收到当前领导者的消息时。
- 递增本地的
currentTerm,尝试收集选票 (Votes)。 - 注意: 这可能导致不必要的选举;虽然安全但效率较低。
- 注意: 旧的领导者可能仍然存活并认为自己是领导者。
- 如何确保一个任期内最多只有一个领导者?
- (见图 2 RequestVote RPC 和服务器规则)
- 领导者必须获得来自服务器多数派的“是 (Yes)”投票。
- 每个服务器在每个任期内只能投一票。
- 如果自己是候选者 (Candidate),则投票给自己。
- 如果不是候选者,则投票给第一个请求投票且符合图 2 规则的候选者。
- 在给定的任期内,最多只有一个服务器能获得多数票。
- -> 即使发生网络分区,也最多只有一个领导者。
- -> 即使一些服务器发生故障,选举也能成功。
- 注意: 再次强调,多数派是基于所有服务器总数计算的(不仅仅是存活的服务器)。
- 服务器如何得知新选举出的领导者?
- 领导者发出带有新的更高任期号的 AppendEntries 心跳包 (Heart-beats)。
- 只有领导者才能发送 AppendEntries。
- 每个任期只有一个领导者。
- 因此,如果你看到带有任期 T 的 AppendEntries,你就知道谁是任期 T 的领导者。
- 心跳包抑制 (Suppress) 任何新的选举。
- 领导者发送心跳包的频率必须高于选举超时时间。
- 选举可能因两个原因而不成功:
- • 可连通 (Reachable) 的服务器少于多数派。
- • 同时出现的候选者 (Simultaneous Candidates) 分散了选票 (Split the Vote),没有人获得多数票。
- 如果选举不成功会发生什么?
- 没有心跳包 -> 另一个超时 -> 为新任期发起新的选举。
- 更高的任期具有优先权 (Precedence),旧任期的候选者退出。
- 如果没有特殊处理,选举经常会因票数分散而失败:
- 所有选举计时器 (Election Timers) 很可能在大致相同的时间到期。
- 每个候选者都投票给自己。
- 所以没有人会投票给别人!
- 所以每个人都将恰好获得一票,没有人拥有多数票。
- Raft 如何避免票数分散?
- 每个服务器为其选举超时期限添加一些随机性 (Randomness)。
- [服务器超时到期时间示意图]
- 随机性打破了服务器之间的对称性 (Symmetry)。
- 一个服务器会选择最低的随机延迟。
- 希望在下一个超时到期之前有足够的时间完成选举。
- 其他服务器将看到新领导者的 AppendEntries 心跳包,从而不会成为候选者。
- 随机延迟是网络协议中的一种常见模式。
- 如何选择选举超时时间?
- • 至少包含几个心跳间隔 (Heartbeat Intervals)(以防网络丢失心跳包)。
- 以避免不必要的选举,这会浪费时间。
- • 随机部分要足够长,以便让一个候选者在下一个候选者开始之前成功。
- • 足够短以快速响应故障,避免长时间停顿。
- • 足够短以允许在测试程序 (Tester) 报错之前进行几次重试。
- 测试程序要求选举在 5 秒或更短时间内完成。
- • 至少包含几个心跳间隔 (Heartbeat Intervals)(以防网络丢失心跳包)。
- 如果旧领导者不知道新领导者已被选出怎么办?
- 可能旧领导者没有看到选举消息。
- 可能旧领导者处于少数派网络分区中。
- 新领导者的出现意味着多数派服务器已经递增了
currentTerm。 - 要么旧领导者会在 AppendEntries 回复中看到新的任期号并退位 (Step Down)。
- 要么旧领导者将无法获得多数派的回复。
- 因此旧领导者将无法提交或执行任何新的日志条目。
- 因此避免了脑裂。
- 但是,少数派可能接受旧服务器的 AppendEntries。
- 因此,在旧任期的末尾,日志可能会出现分歧 (Diverge)。
6.5840 2025 第7讲:Raft(2)
Raft
- 用于构建复制状态机(Replicated State Machine)的库
- 容忍网络分区(network partition)
- 自动故障转移至新主节点(leader/primary)
- 核心思想:法定多数(quorum)
- 大规模分布式系统的构建模块,例如:
- Etcd(配置服务)使用 Raft 库
- Etcd 用于构建更高级服务(如 Kubernetes)
- CockroachDB(分片分布式数据库)使用 Raft
- Etcd(配置服务)使用 Raft 库
上节课内容:选举安全性(Election Safety)
- 每个任期(term)仅有一个主节点
- 只要主节点存活:
- 客户端仅与主节点交互
- 客户端不会看到从节点(follower)的状态或日志
今日主题:日志的复制、持久化与压缩
主题:Raft 日志(实验 2B)
挑战:日志分歧(Log Divergence)
-
主节点崩溃前未向所有从节点发送
AppendEntries-
示例:
- S1:
[3] - S2:
[3, 3] - S3:
[3, 3] - (
3是日志条目的任期号)
- S1:
-
更严重的情况:同一日志位置可能出现不同命令!
-
例如:
日志条目编号:10 11 12 13 S1: [3] S2: [3, 3, 4] S3: [3, 3, 5] -
如何发生的?
- S2 是任期 3 的主节点:
- 向 S1、S2、S3 追加条目 10
- 向 S2、S3 追加条目 11(S1 崩溃)
- S2 崩溃并快速重启,成为任期 4 的主节点:
- 向自己的日志追加条目 12,然后崩溃
- S3 在任期 5 成为主节点(借助 S1):
- 向自己的日志追加不同的条目 12
- S2 是任期 3 的主节点:
-
-
Raft 如何确保一致性?
-
目标:
-
如果任一服务器执行了某日志条目的命令,则其他服务器不能对该条目执行不同操作(图 3 的“状态机安全性”)
-
原因:如果服务器对操作有分歧,主节点切换可能导致客户端可见状态变化,违反“模拟单机”的目标
-
示例:
S1: put(k1,1) | put(k1,2) S2: put(k1,1) | put(k2,3)- 不允许两者都执行它们的第二个日志条目!
-
Raft 的解决方案:强制从节点采纳新主节点的日志
- 示例:
- S3 被选为任期 6 的新主节点,希望追加条目 13
- S3 向所有从节点发送
AppendEntriesRPC:prevLogIndex=12prevLogTerm=5
- S2 返回
false(AppendEntries步骤 2) - S3 将
nextIndex[S2]递减至 12,重新发送包含条目 12 和 13 的 RPC - S2 删除自己的条目 12(
AppendEntries步骤 3),追加新条目 - S1 同理,但需回退更多
回滚(Rollback)的结果:
- 存活的从节点删除与主节点日志不一致的尾部
- 接受主节点的新条目
- 最终所有从节点日志与主节点一致
Q:为何可以忽略 S2 的 index=12, term=4条目?
Q:新主节点能否回滚已提交(committed)的条目?
- 灾难性后果:旧主节点可能已向客户端返回“成功”
- Raft 的保障:新主节点必须包含所有已提交的日志条目
为何不选举日志最长的服务器为主节点?
-
示例:
S1: [5, 6, 7] S2: [5, 8] S3: [5, 8]- S1 在任期 6 和 7 作为主节点,仅追加日志到自身后崩溃
- S2/S3 在任期 8 成为主节点(因已知任期 7)
- 问题:S1 的日志最长,但条目 8 可能已提交!
- 解决方案:选举限制(Election Restriction)
RequestVote仅投票给“至少与自己日志一样新”的候选者:- 候选者最后一条日志的任期更高,或
- 相同任期但日志更长
- 结果:S2/S3 不会投票给 S1,仅 S2/S3 可能成为主节点
关键点:
- “至少一样新”的规则确保新主节点日志包含所有可能已提交的条目
- 因此新主节点不会回滚任何已提交的操作
持久化(实验 2C)
服务器崩溃后需保留哪些状态?
- 持久化状态(图 2):
log[]、currentTerm、votedFor- 必须写入非易失性存储(磁盘、SSD 等)
- 每次状态变更后保存,或发送 RPC 前保存
- 为何需要这些?
log[]:确保已提交条目不被遗忘(即使重启)votedFor:防止同一任期内投票给不同候选者(导致脑裂)currentTerm:避免跟随过期的主节点或参与过期的选举
易失性状态:commitIndex、lastApplied、nextIndex[]/matchIndex[]
- 为何无需持久化?因其可安全重建
持久化是性能瓶颈:
- 磁盘写入耗时(HDD 10ms,SSD 0.1ms)
- 优化技巧:
- 批量写入日志条目
- 使用电池供电的 RAM
- 容忍最后几条更新的丢失风险
服务(如键值存储)如何恢复?
- 简单方法:从空状态重放完整日志(图 2 的做法)
- 高效方法:使用快照(Snapshot)仅重放日志尾部
日志压缩与快照(实验 2D)
问题:日志可能远大于状态机状态,重启或新节点同步耗时
解决方案:服务定期创建持久化快照
- 快照包含截至某日志索引的服务状态(如键值表)
- Raft 丢弃快照索引之前的日志
- 所有服务器均需快照(非仅主节点)
崩溃恢复流程:
- 服务从磁盘读取快照
- Raft 读取持久化日志
- Raft 设置
lastApplied为快照的最后索引,避免重复应用已执行的日志
问题:从节点日志落后于主节点日志的起始点?
- 解决方案:
InstallSnapshotRPC
哲学思考:
- 状态(State)与操作历史(Operation History)可相互转换
- 存储或通信时选择更高效的形式
实际注意事项:
- 快照适用于小状态(如配置),不适用于大型数据库
- 替代方案:服务数据直接存储在磁盘(如 B-Tree)
- 需处理落后副本的同步问题
只读操作(第 8 节末尾)
Q:Raft 主节点是否需将只读操作(如 Get(key))提交到日志后才能响应?
A:
- 图 2 和实验要求:必须提交
Get()到日志- 避免返回过时数据(如主节点未察觉自己已失去领导权)
- 若无法获取多数
AppendEntries确认,则不响应客户端
- 优化思路:租约(Leases)
- 主节点在租约期内(如 5 秒)可直接响应只读请求
- 新主节点需等待旧租约过期才能执行写操作
- 注意:实验中仍需提交
Get()到日志
现实权衡:
- 许多应用为读多写少,提交
Get()影响性能 - 实践中常容忍过时数据以换取更高吞吐量
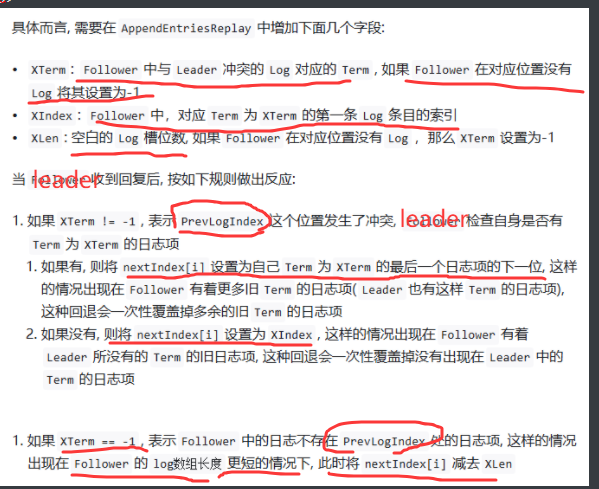
raft论文figure2
这张图是 Raft 一致性算法的核心机制流程图,清晰展示了算法运行所需的状态、RPC 交互和服务器行为规则。以下是图中四个核心模块的中文详解:
1. State (状态)
- 持久化状态 (所有服务器必须写入稳定存储):
currentTerm:服务器已知的最新任期号(首次启动为0,单调递增)。votedFor:在当前任期内收到其投票的候选者ID(若无投票则为空)。log[]:日志条目数组。每个条目包含:状态机命令 + 领导者接收该条目时的任期号(索引从1开始)。
- 易失性状态 (所有服务器):
commitIndex:已知已提交的最高日志条目索引(初始为0,单调递增)。lastApplied:已应用到状态机的最高日志条目索引(初始为0,单调递增)。
- 易失性状态 (领导者专用,选举后重置):
nextIndex[]:nextIndex[]是一个数组,领导者为集群中的每个跟随者维护一个条目。对于跟随者i,nextIndex[i]表示领导者将要发送给该跟随者的下一条日志条目的索引。matchIndex[]:matchIndex[]也是一个数组,领导者为集群中的每个跟随者维护一个条目。对于跟随者i,matchIndex[i]表示领导者已知的、已经成功复制到该跟随者上的最高日志条目的索引。
2. AppendEntries RPC (日志复制/心跳 RPC)
- 用途:领导者复制日志条目(§5.3)或发送心跳包(§5.2)。
- 参数:
term:领导者的任期号。leaderId:领导者ID(用于跟随者重定向客户端)。prevLogIndex:新条目前一条日志的索引。prevLogTerm:prevLogIndex条目的任期号。entries[]:需存储的日志条目(心跳包为空,可批量发送)。leaderCommit:领导者的commitIndex。
- 结果:
term:跟随者的当前任期(供领导者更新自身)。success:若跟随者日志包含与prevLogIndex和prevLogTerm匹配的条目,则为true。
- 接收者处理逻辑:
- 若
term < currentTerm,返回false(§5.1)。 - 若日志在
prevLogIndex处无条目或任期不匹配,返回false(§5.3)。 - 冲突处理:若新条目与现存条目冲突(同索引不同任期),删除冲突条目及其后所有条目(§5.3)。
- 追加日志:添加所有不存在的新条目。
- 更新提交索引:若
leaderCommit > commitIndex,则设置commitIndex = min(leaderCommit, 最后新条目索引)。
- 若
3. RequestVote RPC (选举投票 RPC)
- 用途:候选者收集选票(§5.2)。
- 参数:
term:候选者的任期号。candidateId:请求投票的候选者ID。lastLogIndex:候选者最后一条日志的索引(§5.4)。lastLogTerm:候选者最后一条日志的任期号(§5.4)。
- 结果:
term:接收者的当前任期(供候选者更新自身)。voteGranted:若投票给该候选者,则为true。
- 接收者处理逻辑:
- 若
term < currentTerm,返回false(§5.1)。 - 投票条件:若
votedFor为空或已是candidateId,且候选者日志至少与接收者日志一样新(§5.2, §5.4),则授予投票。
- 若
4. Rules for Servers (服务器行为规则)
- 所有服务器:
- 若
commitIndex > lastApplied:递增lastApplied,将log[lastApplied]应用到状态机(§5.3)。 - 若 RPC 请求/响应中的
term T > currentTerm:设置currentTerm = T,转换为跟随者(§5.1)。
- 若
- 跟随者 (Followers):
- 响应来自候选者和领导者的 RPC。
- 触发选举条件:若在选举超时内未收到当前领导者的
AppendEntries或未给候选者投票,则转换为候选者。
- 候选者 (Candidates):
- 开始选举:转换时立即执行:
- 递增
currentTerm。 - 投票给自己。
- 重置选举计时器。
- 向所有其他服务器发送
RequestVoteRPC。
- 递增
- 成为领导者:若获得多数派投票。
- 收到心跳:若收到新领导者的
AppendEntries,转换为跟随者。 - 选举超时:若超时未胜选,发起新一轮选举。
- 开始选举:转换时立即执行:
- 领导者 (Leaders):
- 当选后:立即向每个服务器发送初始空
AppendEntries(心跳),并在空闲时重复发送(防止选举超时)(§5.2)。 - 接收客户端命令:追加条目到本地日志,在条目应用到状态机后响应客户端(§5.3)。
- 日志同步:若某跟随者的
nextIndex≤ 领导者最后日志索引:- 发送从
nextIndex开始的AppendEntries。 - 若成功:更新该跟随者的
nextIndex和matchIndex(§5.3)。 - 若因日志不一致失败:递减
nextIndex并重试(§5.3)。
- 发送从
- 提交新条目:若存在满足以下条件的
N:N > commitIndex- 多数派的
matchIndex[i] ≥ N log[N].term == currentTerm- 则设置
commitIndex = N(§5.3, §5.4)。
- 当选后:立即向每个服务器发送初始空
核心要点总结
- 任期机制:
currentTerm标识逻辑时间,确保同一任期最多一个有效领导者。 - 心跳保活:领导者通过
AppendEntries心跳维持权威,抑制选举。 - 日志一致性:
- 领导者强制覆盖跟随者的冲突日志(步骤3)。
- 提交需满足 多数派复制 + 当前任期 条件(规则4)。
- 选举安全:
- 投票需满足 日志至少一样新(
lastLogTerm和lastLogIndex比较)。 - 同一任期每台服务器只能投一票。
- 投票需满足 日志至少一样新(
- 状态机安全:仅提交的日志条目(
commitIndex)才会被应用到状态机。
这张图是 Raft 算法的“操作手册”,Lab 3 的实现需严格遵循这些规则。理解图中交互逻辑(如日志冲突处理、心跳抑制选举、提交条件)是完成实验的关键。
追加日志
快速恢复不一致follower的Log


持久化
持久化的内容


总结对比表
| 状态 | 是否持久化 | 原因 |
|---|---|---|
currentTerm |
必须 | 防止同一个任期内出现多个领导者(保证安全性)。 |
votedFor |
必须 | 防止在一个任期内投出多张票(保证安全性)。 |
log[] |
必须 | 这是状态机的操作历史,是最终状态的来源(保证安全性)。 |
state |
不持久化 | 角色是瞬时的,由当前集群状态决定。重启后必须从Follower开始。 |
commitIndex |
不持久化 | 可由领导者通过心跳广播;重新应用日志是幂等的。 |
lastApplied |
不持久化 | 可从持久化的日志中重新应用至 commitIndex。 |
nextIndex[] |
不持久化 | 领导者的工作状态,新领导者会重置并重新探测。 |
matchIndex[] |
不持久化 | 领导者的工作状态,新领导者会重置并重新累积。 |
持久化内容的核心思想
Raft 持久化的设计遵循一个核心原则:只持久化用于保证安全性的最小状态子集。这些状态是确保系统在崩溃恢复后仍能维持一致性的绝对必要条件。其他状态都是用于优化性能或记录临时进度的“工作状态”,可以在运行中通过 RPC 交互重新构建。
问题 1: 为什么 commitIndex, lastApplied, nextIndex, matchIndex不用持久化?它们是如何重建的?
这些索引被称为 “易失性状态”(Volatile State)。它们不需要持久化的原因在于,其功能是优化和记录进度,而非保证安全性的核心。它们可以在节点重启后,通过正常的 Raft 协议交互(主要是心跳和日志追加)安全地重新构建出来。
1. commitIndex(提交索引)
-
•
为什么不需要持久化?:
commitIndex表示已知已提交的最高日志索引。领导者通过心跳 (AppendEntriesRPC) 中的leaderCommit字段将其广播给所有追随者。因此,一个重启后的节点,无论是领导者还是追随者,都会在收到下一个有效的心跳或日志追加 RPC 时,从领导者那里获取到最新的commitIndex。 -
•
如何重建?:
-
•
追随者:直接从领导者发来的
AppendEntriesRPC 参数中的leaderCommit字段获取。 -
•
领导者:领导者需要重新计算
commitIndex。它通过向所有追随者发送心跳,收集他们的matchIndex,然后按照 Raft 规则(取所有matchIndex的中位数)来更新自己的commitIndex。
-
2. lastApplied(最后应用索引)
-
•
为什么不需要持久化?:
lastApplied是状态机应用的进度,它总是小于等于commitIndex。应用日志条目是幂等的(多次应用同一条日志命令不会改变最终状态)。重启后,节点只需从lastApplied = 0开始,重新应用所有已提交的日志(从持久化的日志中读取),直到追上当前的commitIndex即可。虽然效率不高,但能保证正确性。 -
•
如何重建?:节点重启后,将
lastApplied初始化为 0,然后从日志中依次重新应用所有已提交的条目(即索引从 1 到commitIndex的条目)。
3. nextIndex和 matchIndex(下一个索引和匹配索引)
-
•
为什么不需要持久化?:这两个是领导者独有的工作状态,用于追踪每个追随者的日志复制进度。它们是领导者的“最佳猜测”,本身就是临时性的。如果领导者崩溃,新选举产生的领导者会重置这些值,并从头开始与追随者同步日志,这是最安全的方式。
-
•
如何重建?:
-
•
新领导者当选后:它会立即将所有追随者的
nextIndex[]初始化为自己最后一条日志的索引 + 1(即len(log)),这是一个乐观的假设(认为所有追随者的日志都和它一样新)。同时,将matchIndex[]初始化为 0。 -
•
通过后续 RPC 调整:领导者通过发送
AppendEntriesRPC 来探测每个追随者的实际日志状态。如果追随者拒绝(因为日志不匹配),领导者会根据回复信息(如您之前提到的XTerm,XIndex)递减nextIndex,直到找到一致点。一旦某个AppendEntries成功,领导者就能相应地更新matchIndex和nextIndex。
-
总结:不持久化这些索引,相当于用网络通信和重试来换取实现的简单性和一致性。虽然重启后可能需要一些时间来重新同步,但协议保证了最终所有状态都能正确恢复,而不会破坏安全性。
问题 2: State (节点状态) 为什么不持久化?一个 Leader 宕机恢复后它的状态是什么?
为什么不持久化 State?
节点状态(Follower/Candidate/Leader)是一个瞬时的角色,完全由当前任期号和日志内容派生而来。持久化它是没有意义且危险的:
-
无意义:角色取决于集群的整体状态。一个节点崩溃后,集群的任期可能已经前进(
currentTerm增加),其他节点可能已经当选为新的领导者。重启后的节点绝不能假设自己仍然是领导者,否则会导致“脑裂”(Split Brain),即出现多个领导者。 -
危险:如果持久化了
state = Leader,但重启后集群的currentTerm已经变大,这个过期的领导者会以为自己是合法的,会继续发送心跳和日志,扰乱集群的正常运行。
一个 Leader 宕机恢复后它的状态是什么?
一个领导者节点宕机重启后,它的状态永远是 Follower。
其恢复过程如下:
-
从磁盘加载持久化状态:读取
currentTerm、votedFor和log。 -
初始化易失性状态:将
state初始化为Follower。将commitIndex和lastApplied初始化为 0(或从快照中恢复的位置)。nextIndex和matchIndex只有在成为领导者时才会被创建和初始化,此时为空或不使用。 -
等待心跳或超时:
-
•
如果它能很快收到来自当前任期领导者的有效心跳,它就会安心做一个追随者。
-
•
如果一段时间内没有收到心跳(选举超时),它就会自荐为候选人(
state = Candidate),增加自己的currentTerm,并开始新一轮的选举。
-
这个设计非常关键:它确保了任何节点重启后都必须以“谦虚”的追随者身份重新加入集群,通过通信来确认自己的角色,从而避免了过期的领导者扰乱集群。这是 Raft 安全性的又一重保障。
持久化的时机

Log compaction
好的,我们来详细解析这段关于 Raft 快照(Snapshotting) 机制的论述。这段文字解释了为什么需要快照、如何工作以及其设计上的权衡。
核心问题:日志无限增长的挑战
在正常操作中,Raft 的日志会不断增长以容纳更多的客户端请求。但这会带来实际问题:
- 空间占用:日志越长,占用的存储空间越多。
- 时间开销:服务器重启后,需要重放(replay) 所有日志来重建状态,日志越长,耗时越久。
- 可用性问题:最终,上述两点会导致系统可用性下降。
因此,需要一种机制来丢弃日志中积累的、已经过时的(obsolete) 信息。这个过程称为 日志压缩(Compaction)。
解决方案:快照(Snapshotting)
1. 基本概念
快照是最简单的压缩方法。其核心思想是:
- 将整个当前系统状态序列化后写入稳定存储(如硬盘)的一个快照文件中。
- 然后,丢弃该快照点之前的所有日志条目。
举个例子:假设状态机是一个键值存储,当前状态是 {A=1, B=2, C=3}。打快照就是将 {A=1, B=2, C=3}这个完整状态直接保存到文件中,然后就可以丢弃所有导致这个状态的 PUT A=1, PUT B=2, PUT C=3等日志条目。
2. 快照中包含的内容
- 状态机状态:这是快照的主体,由应用程序负责生成。
- 关键元数据(Raft 添加):
- 最后包含的索引(last included index):该快照所覆盖的最后一条日志的索引。
- 最后包含的任期(last included term):上述索引对应的日志条目的任期号。
- 最新的配置信息:用于支持集群成员变更。
元数据的作用:为了支持快照之后的第一个日志条目的 AppendEntries一致性检查。因为领导者发送 PrevLogIndex和 PrevLogTerm时,如果追随者的日志已经被快照截断,它就需要用这些元数据来证明自己的日志与领导者在快照点是一致的。
3. 创建快照的时机
- 各服务器独立进行:每个服务器根据自己的情况决定何时创建快照,通常与领导者无关。
- 常见策略:当日志大小达到一个固定的字节数时触发。这个阈值应显著大于快照的预期大小,以减少磁盘带宽开销。
4. 性能优化:写入时不阻塞
写入快照可能很耗时,不能因此阻塞正常操作。解决方案是:
- 写时复制(Copy-on-Write):允许在写入快照的同时接受新的更新。
- 使用函数式数据结构的状态机天然支持此特性。
- 利用操作系统的支持,如 Linux 的
fork系统调用,创建整个状态机的内存快照。
关键 RPC:InstallSnapshot
当某个追随者远远落后(例如刚重启或新加入集群),而领导者已经丢弃了它需要发送给该追随者的下一批日志条目时,领导者就需要通过网络发送快照。这是通过 InstallSnapshotRPC 实现的。
接收方(Follower)处理逻辑:
- 基本检查:如果 RPC 中的
term小于自己的当前任期,立即拒绝。 - 分块处理:快照可能分多次发送。根据
offset将data[]写入快照文件的指定位置。如果done为false,说明还有后续分块,等待即可。 - 安装决策(这是核心):
- 情况A:快照包含新信息(最常见)。追随者会丢弃其整个日志,因为快照包含了所有最新信息,且其本地日志可能包含与快照冲突的未提交条目。
- 情况B:快照是其日志的前缀(通常因重传或错误导致)。追随者仅删除快照所覆盖的那部分日志,而保留快照之后的日志条目(这些条目仍然有效,必须保留)。
- 重置状态机:最后,追随者使用快照内容重置其状态机。
设计权衡与选择
1. 为什么采用“各自快照”而非“领导者统一快照”?
文章探讨了另一种方案:只由领导者创建快照,然后分发给所有追随者。但认为当前方案(各自快照)更优,原因如下:
- 网络带宽和速度:将快照从领导者发送给所有追随者会浪费大量网络带宽且过程缓慢。而让追随者自己利用本地状态生成快照,成本要低得多。
- 领导者复杂度:领导者需要并行处理——既要给落后的追随者发送快照,又要给跟得上的追随者复制新的日志条目,设计非常复杂。当前的方案简化了领导者的逻辑。
2. 这是否违背了 Raft 的“强领导者原则”?
强领导者原则要求所有数据都从领导者流向追随者。在快照机制中,追随者可以独立创建快照,看似违背了这一原则。
文章的解释是合理的:虽然创建快照的行为是独立的,但快照本身所包含的数据(状态机状态)最初完全来自于领导者通过 RPC 复制的日志。共识已经在快照所覆盖的日志条目上达成,因此不会引发新的决策冲突。数据流的源头依然是领导者,追随者只是在重组自己本地的数据。
总结
| 方面 | Raft 快照机制 |
|---|---|
| 目的 | 解决日志无限增长带来的存储和恢复效率问题 |
| 核心操作 | 将整个系统状态写入快照文件,并丢弃之前的所有日志 |
| 关键元数据 | lastIncludedIndex, lastIncludedTerm, 配置信息 |
| 创建方式 | 各服务器独立进行,通常由日志大小触发 |
| 落后追赶 | 领导者通过 InstallSnapshotRPC 向落后追随者发送快照 |
| 设计选择 | 选择“各自快照”而非“领导者统一快照”,以节省带宽和简化领导者逻辑 |
快照机制是 Raft 实践中的重要组成部分,它在保证一致性的前提下,巧妙地解决了日志压缩这一实际问题,并通过 InstallSnapshotRPC 确保了集群成员最终能恢复一致。
好的,我们来详细解释 Raft 中的快照(Snapshot)机制,它如何解决日志无限增长的问题,以及如何处理由此引发的 Follower 日志缺失问题。
1. 核心问题:为什么需要快照?
以你提到的 K/V 数据库为例:
- 日志(Log):记录了所有更改状态的操作序列,例如
[Put A=1, Put B=2, Put A=3, Put C=4]。 - 状态(State):是这些操作应用后的最终结果,例如
{A=3, B=2, C=4}。
运行很长时间后,日志会变得非常长,但其中大部分是历史中间状态(如 Put A=1 已被 Put A=3 覆盖)。存储所有日志既浪费空间,又在节点重启后需要重放所有日志,极其低效。
快照的核心思想就是定期将整个当前状态({A=3, B=2, C=4})保存下来,并丢弃产生此状态之前的所有日志。这样就只用存储最终状态和之后的日志,极大地节省了空间并加快了恢复速度。
2. 快照机制如何工作?
a) 触发时机(由应用程序决定)
Raft 本身不知道何时做快照。它向上层应用提供一个接口(例如 Snapshot(index int, snapshotData []byte))。应用需要自己决定触发策略,常见的有:
- 日志大小阈值:当日志体积超过一定值(如 1MB)时触发。
- 条目数量阈值:当日志条数超过一定数量时触发。
- 定时触发:定期创建快照。
b) 创建过程
- 选择分界点:应用选择一个已提交(committed)且已应用(applied)的日志索引,假设为
X。这意味着索引X及之前的所有操作的效果都已经体现在当前状态中。 - 生成快照:应用将自己的完整当前状态序列化(对于 K/V 数据库,就是序列化整个键值对映射表),生成
snapshot_data。 - 通知 Raft:应用调用
rf.Snapshot(X, snapshot_data)。 - Raft 持久化:Raft 层会同时持久化: 快照数据 (
snapshot_data) 快照的元数据:最后包含的索引 (lastIncludedIndex) = X 和 最后包含的任期 (lastIncludedTerm)(即日志中索引X对应的任期号)。 - 截断日志:Raft 层安全地丢弃索引
X及之前的所有日志条目。
c) 节点启动恢复
节点重启后,Raft 的启动流程变为:
- 从稳定存储中读取最新的快照和其元数据 (
lastIncludedIndex,lastIncludedTerm)。 - 将快照数据交给上层应用,应用加载此快照来直接恢复其状态,而无需重放任何历史日志。
- 然后读取并重放快照点之后(索引
X+1开始)的日志(如果有的话)。
3. 关键挑战与 Raft 的解决方案
快照引入了一个新问题:如果 Leader 已经丢弃了 Follower 所需要的旧日志,如何同步?
问题场景
- Leader:日志索引为 1-1000。它在索引 800 处做了快照,因此丢弃了索引 1-800 的日志,只保留 801-1000。
- Follower:因宕机离线,日志只到索引 500。
- Follower 恢复:它需要从索引 501 开始同步,但 Leader 已经没有 501-800 的日志了!
解决方案 1:Leader 不丢弃落后 Follower 所需的日志
- 做法:Leader 为每个 Follower 维护一个“最低所需索引”,只有当所有 Follower 的
matchIndex都超过快照点X时,Leader 才真正丢弃X之前的日志。 - 缺陷:不可行。如果有一个 Follower 严重落后(如关机一周),Leader 将永远无法丢弃任何日志,使得快照机制完全失效,违背了初衷。
解决方案 2:Raft 的标准方案 —— InstallSnapshot RPC
这是 Raft 论文中采用的方案,其流程完美地解决了该问题,如下图所示:
flowchart TD
A[Leader尝试通过<br>AppendEntries同步日志] --> B{Follower日志是否<br>落后到已被Leader丢弃?}
B -- 否 --> C[正常日志复制流程]
B -- 是 --> D[Leader通过InstallSnapshot RPC<br>将快照发送给Follower]
D --> E{Follower处理快照}
E --> F[丢弃所有现有日志]
F --> G[用快照数据加载状态机]
G --> H[后续通过AppendEntries<br>接收快照点后的新日志]
H --> I[最终状态一致]
其工作原理如下:
- 探测到落后:Leader 通过正常的
AppendEntriesRPC 发现某个 Follower 所需要的下一个日志索引(nextIndex)已经被自己丢弃(即nextIndex <= lastIncludedIndex)。 - 切换至发送快照:Leader 停止尝试发送日志条目,转而发起
InstallSnapshotRPC。 - 发送快照:Leader 将它的快照数据(包括
lastIncludedIndex、lastIncludedTerm和应用程序的完整状态数据)发送给 Follower。快照可能被分成多个块(chunk)传输。 - Follower 处理快照: 如果快照是最新的(其
lastIncludedIndex大于 Follower 的最后日志索引),Follower 会丢弃其整个日志,因为快照包含了所有最新信息。 它将快照数据交给上层应用,应用完全重置其状态为快照所保存的状态。 它将自己的lastApplied和commitIndex至少更新到lastIncludedIndex。 - 恢复日志同步:此后,Follower 的日志“起点”变成了
lastIncludedIndex。Leader 接下来就可以通过正常的AppendEntriesRPC,从lastIncludedIndex + 1开始,将其后的新日志(801-1000)发送给 Follower,最终使其完全同步。
总结
| 方面 | Raft 快照机制 |
|---|---|
| 目的 | 解决日志无限增长问题,节省空间,加速恢复 |
| 触发者 | 上层应用程序(根据自身策略决定) |
| 内容 | 应用程序状态 + Raft 元数据(lastIncludedIndex, lastIncludedTerm) |
| 核心挑战 | Leader 丢弃的日志如何同步给严重落后的 Follower |
| 解决方案 | InstallSnapshot RPC,直接发送状态快照而非历史日志 |
| 优势 | 允许 Leader 积极丢弃日志,而不受个别落后 Follower 的制约,真正实现了日志压缩的目标 |
通过这种设计,Raft 在保证一致性的前提下,优雅地解决了实际工程中的存储和效率问题。一个离线很久的 Follower 可以通过接收一个快照和一小段新日志迅速追上集群进度,而不需要重传整个历史操作记录。
lab简介

lab相关
lab1
第一讲(引言)及 MapReduce
好的,这是麻省理工学院 6.5840 分布式系统工程 2025 年第一讲(引言)及 MapReduce 案例研究部分的中文翻译:
6.5840 2025 第一讲:引言
6.5840:分布式系统工程
我对“分布式系统”的定义:
一组协同工作以提供服务的计算机
示例
- 我们都使用分布式系统:
- 流行应用的后端(例如消息应用)
- 大型网站
- 电话系统
- 本课程重点关注分布式基础设施:
- 存储系统
- 事务处理系统
- “大数据”处理框架
- 认证服务
以这种方式构建系统并非易事:
- 并发性(Concurrency)
- 复杂的交互(Complex interactions)
- 性能瓶颈(Performance bottlenecks)
- 部分故障(Partial failure)
那么,人们为什么要构建分布式系统?
- 通过并行处理(Parallel processing)提高容量(Capacity)
- 通过复制(Replication)实现容错(Fault tolerance)
- 匹配物理设备的分布(如传感器)
- 通过隔离(Isolation)增强安全性(Security)
为什么学习这个主题?
- 有趣:充满挑战性的问题和强大的解决方案
- 广泛应用:由大型网站的兴起所驱动
- 活跃的研究领域:存在重要的未解决问题
- 构建具有挑战性:你将在实验中亲身体验
课程结构 (COURSE STRUCTURE)
课程网站:http://pdos.csail.mit.edu/6.5840
课程团队成员:
- 主讲教师: Frans Kaashoek 和 Robert Morris
- 助教: Kenneth Choi, Yun-Sheng Chang, Ivy Wu, Aryan Kumar
课程组成:
- 讲座(Lectures)
- 论文(Papers)
- 两次考试(Two exams)
- 实验(Labs)
- 期末项目(Final project - 可选)
讲座:
- 讲解核心思想、论文讨论、实验指导
论文:
- 每次讲座对应一篇论文
- 研究论文,包括经典文献和新近成果
- 内容涵盖:问题、思路、实现细节、评估方法
- 请在课前阅读论文!
- 网站会为每篇论文提供一个简短问题让你回答
- 同时要求你提交一个关于该论文的问题
- 在讲座开始前提交答案和问题
考试:
- 期中考试在课堂上进行
- 期末考试在期末考试周进行
- 考试内容主要围绕论文和实验
- 必须参加考试!
实验 (Labs):
- 目标: 运用并实现一些关键技术
- 目标: 获取分布式编程的实际经验
- 第一个实验截止日期是下周五
- 之后的实验基本上每周一个
- Lab 1: 分布式大数据处理框架(类似于 MapReduce)
- Lab 2: 客户端/服务器 vs 不可靠网络
- Lab 3: 使用复制实现容错(Raft 共识算法)
- Lab 4: 容错数据库实现
- Lab 5: 通过分片(Sharding)实现可扩展的数据库性能
- 我们使用一套测试用例来评分实验
- 我们提供所有测试用例,没有隐藏测试。
可选期末项目 (Optional final project) 在课程最后进行,可以 2 或 3 人一组:
- 期末项目可以替代 Lab 5。
- 需要构思项目想法并获得课程组批准。
- 要求提交代码、简短报告,并在最后一天进行演示。
重要提示:调试实验可能非常耗时!
- 尽早开始!
- 在 Piazza(课程问答平台)上提问!
- 利用助教的 Office Hours(答疑时间)!
核心主题 (MAIN TOPICS)
这是一门关于为应用提供基础设施支持的课程。
- 存储 (Storage)。
- 通信 (Communication)。
- 计算 (Computation)。
核心目标: 向应用程序隐藏分布式系统的复杂性。
-
主题:容错性 (Fault tolerance)
-
数千台服务器,庞大的网络 -> 总会出现故障。我们希望能向应用隐藏这些故障。
-
“高可用性”:服务在故障发生时能够持续运行。
核心思路:服务器复制 (Replicated servers)。
- 如果一台服务器崩溃,可以使用其他服务器继续运行。
-
-
主题:一致性 (Consistency)
- 通用基础设施需要明确定义的行为。例如,“read(x) 返回最近一次 write(x) 的值”。
- 实现良好行为非常困难!例如,保持“副本”服务器完全相同非常困难。
-
主题:性能 (Performance)
目标:可扩展的吞吐量 (Scalable throughput)
-
N 倍服务器 -> 通过并行利用 CPU、内存、磁盘、网络实现 N 倍总吞吐量。
-
随着 N 的增长,扩展变得更难:
- 负载不均衡 (Load imbalance)。
- N 节点中最慢节点的延迟 (Slowest-of-N latency)。
-
-
主题:权衡 (Tradeoffs)
- 容错性、一致性和性能是相互制约的。
- 容错性和一致性需要通信:
- 例如,发送数据到备份服务器。
- 例如,检查缓存数据是否是最新的。
- 通信通常速度慢且难以扩展。
- 许多设计牺牲一致性来换取速度。
- 例如,read(x) 可能不返回最近一次 write(x) 的值!
- 这对应用程序员(或用户)来说是痛苦的。
- 我们将看到在一致性/性能频谱上的多种设计权衡点。
-
主题:实现 (Implementation)
- RPC (远程过程调用), 线程 (Threads), 并发控制 (Concurrency control), 配置管理 (Configuration)。
- ...就是实验中要做的事情。
该领域知识在现实世界中应用广泛:
- 所有大型网站和云服务提供商都是分布式系统领域的专家。
- 许多开源项目都围绕着这些思想构建。
- 在学术界和工业界都是一个热门话题。
案例研究:MapReduce (CASE STUDY: MapReduce)
我们来探讨一下 MapReduce (MR):
- 它是阐明 6.5840 核心主题的一个极佳范例
- 具有巨大的影响力
- 是 Lab 1 的重点
MapReduce 概述
背景 (context):
对
太字节 (terabyte) 级别
的数据集进行
耗时数小时
的计算
-
例如:构建搜索索引,或排序,或分析网络结构。
-
只有使用上千台计算机才具有实际可行性。
核心目标:让非专业程序员更容易上手
- 程序员只需定义
Map和Reduce函数。 - 通常这些是相当简单的串行代码。
- MR 负责管理并隐藏分布式处理的所有细节!
MapReduce 作业的抽象视图 —— 单词计数 (word count)
Input1 -> Map -> a,1 b,1
Input2 -> Map -> b,1
Input3 -> Map -> a,1 c,1
| | |
| | -> Reduce -> c,1
| -----> Reduce -> b,2
---------> Reduce -> a,2
- 输入 (Input) 被(预先)分割成
M个小文件 (pieces)。 - MR 为每个输入分片调用
Map()函数,生成<键, 值>(k, v) 对列表 —— 即 “中间数据” (intermediate data)。每个Map()调用被称为一个 “任务” (task)。 - 当所有
Map任务完成后,MR 为每个键k收集其所有中间值v,并将每个k及其对应的values传递给一个Reduce调用。 - 最终输出 (Final output) 是来自所有
Reduce()调用的<k, v>对的集合。
单词计数代码示例
Map(d)
将文档 d 分割成单词
对于每个单词 w:
输出(w, "1")
Reduce(k, v[])
输出( len(v[]) ) // 输出该单词的总数 (即values列表v的长度)
MapReduce 扩展性良好:
-
拥有
N个“工作节点” (worker computers)(可能)带来
N倍的吞吐量。
Map()任务可以并行运行,因为它们之间不交互。Reduce()任务同样如此。
-
因此,更多的计算机 -> 更高的吞吐量 —— 非常棒!
MapReduce 隐藏了大量复杂性:
- 向服务器发送 map 和 reduce 代码
- 跟踪哪些任务已完成
- 将中间数据从 Map 节点“混洗” (Shuffling) 到 Reduce 节点
- 在服务器之间平衡负载
- 从崩溃的服务器中恢复
为了获得这些好处,MapReduce 对应用程序施加了限制:
- 除通过中间输出外,没有交互或状态(No interaction or state)。
- 数据处理流仅限于 Map/Reduce 这一种模式(Just the one Map/Reduce pattern)。
- 不支持实时或流处理(No real-time or streaming processing)。
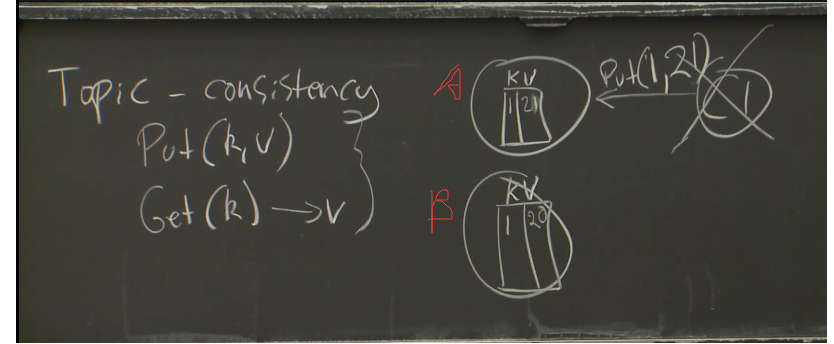
一些细节(论文中的图 1)
-
输入和输出存储在 GFS 集群文件系统上
- MapReduce 需要巨大的并行输入和输出吞吐量。
- GFS 将文件分割存储在许多服务器、许多磁盘上,每个块大小为 64 MB。
- Map 任务并行读取输入。
- Reduce 任务并行写入输出。
- GFS 将所有数据复制在 2 或 3 台服务器上,以实现容错。
- GFS 对 MapReduce 来说是一个巨大的优势。
-
“协调器”(Coordinator)管理作业中的所有步骤:
协调器将 Map 任务分配给工作进程,直到所有 Map 任务完成:
- Map 任务将输出(中间数据)写入本地磁盘。
- Map 任务将其输出根据
hash(key) mod R进行分片,为每个 Reduce 任务生成一个文件(R 是 Reduce 任务的数量)。
在所有 Map 任务完成后,协调器分发 Reduce 任务:
- 每个 Reduce 任务对应一个中间输出文件的哈希桶。
- 每个 Reduce 任务从每一个 Map 工作进程那里获取属于它的桶(的文件)。
- (Reduce 端)按键(key)进行排序,并为每个键调用
Reduce()函数。 - 每个 Reduce 任务在 GFS 上写入一个单独的输出文件。
-
哪些因素可能限制性能?
-
我们关心这个问题,因为性能瓶颈是需要优化的重点。
-
CPU?内存?磁盘?网络?
-
在 2004 年(论文发表时),作者们主要受限于
网络速度
。
- MapReduce 在网络上传输什么?
- Map 任务从 GFS 读取输入。
- Reduce 任务获取 Map 任务的中间输出 —— 这称为 Shuffle(混洗)。这通常和输入一样大(例如排序作业)。
- Reduce 任务将输出文件写入 GFS。
- [图:服务器,网络交换机的树状拓扑]
- 在 MapReduce 的全对全(all-to-all)Shuffle 阶段,一半的流量会经过根交换机。
- 论文使用的根交换机:总计 100 到 200 Gb/s。
- 共有 1800 台机器,平均每台机器只有约 55 Mb/s (55 兆比特每秒)。
- 55 Mb/s 很小:远低于磁盘或内存的速度。
- MapReduce 在网络上传输什么?
-
-
MapReduce 如何最小化网络使用?
-
协调器尽量在
存储输入数据
的 GFS 服务器上运行每个 Map 任务。
- 所有计算机都同时运行 GFS 和 MapReduce 工作进程。
- 因此,Map 的输入通常直接从本地磁盘上的 GFS 数据读取,无需经过网络。
中间数据只在网络上传输一次:
-
Map 工作进程将(中间数据)写入其本地磁盘。
-
Reduce 工作进程通过网络从 Map 工作进程的磁盘上读取(中间数据)。
-
(如果将它们存储在 GFS 中则至少需要在网络上传输两次。)
-
中间数据被
哈希分区
成包含多个键的文件:
- Reduce 任务处理的基本单元是一个哈希桶(而不是单个键)。
- 大型的网络传输效率更高。
-
-
MapReduce 如何实现良好的负载均衡?
-
为什么我们需要关心负载均衡?
- 如果一台服务器的任务量比其他服务器多,或者速度更慢。
- 那么在工作结束时,其他服务器将会空闲等待(资源被浪费)。
-
但是任务大小可能不同,计算机速度也可能不同。
-
解决方案:使用
远多于工作机器数量
的任务。
- 协调器将新任务分配给已完成前一个任务的工作进程。
- 因此,更快的服务器会处理更多的任务,而较慢的服务器则处理较少的任务。
- 较慢的服务器被分配较少的任务,从而减少了它们对总执行时间的影响。
-
-
容错是如何处理的?
- 如果一个工作进程计算机崩溃了怎么办?
- 我们希望对应用程序开发人员隐藏这些失败!
- MapReduce 是否必须从头重新运行整个作业?
- 为什么不呢?
- MapReduce只需重新运行失败的 Map 任务和 Reduce 任务。
-
假设 MapReduce 将同一个 Map 任务运行了两次,假设一个 Reduce 任务看到了第一次运行的输出,而另一个 Reduce 任务看到了第二次运行的输出,会发生什么?
-
两次 Map 执行必须产生完全相同的中间输出!
-
Map 函数和 Reduce 函数
必须是纯确定性函数
:
- 它们只能查看其参数/输入。
- 不能有状态、不能进行文件 I/O、不能交互、不能进行外部通信、不能使用随机数。
-
程序员有责任确保这种确定性。
-
-
工作进程崩溃恢复的细节:
一个工作进程在运行 Map 任务时崩溃:
-
协调器注意到该工作进程无响应。
-
协调器知道在那个工作进程上运行了哪些 Map 任务。
-
这些任务的中间输出现已丢失,必须重新生成。
-
协调器通知其他工作进程运行这些(丢失的)任务。
-
如果所有 Reduce 任务都已经获取了该(崩溃的 Map 节点)的中间数据,则可以省略重新运行这些 Map 任务。
一个工作进程在运行 Reduce 任务时崩溃:
- 已经完成的任务是没问题的——它们存储在具有副本的 GFS 中。
- 协调器将该工作进程未完成的任务重新分配给其他工作进程。
-
-
其他失败/问题:
如果协调器把同一个 Map() 任务分配给两个工作进程会怎样?
-
可能是协调器错误地认为其中一个工作进程死掉了。
-
它只会告诉 Reduce 工作进程关于其中一个(Map 任务实例)的信息。
如果协调器把同一个 Reduce() 任务分配给两个工作进程会怎样?
-
它们都会尝试在 GFS 上写入相同的输出文件!
-
GFS 的原子重命名操作防止了混合输出;最终只会有一个完成的文件是可见的。
如果一个工作进程非常慢 —— 一个“掉队者节点”(straggler)?
-
可能是由于不稳定的硬件造成的。
-
协调器为最后几个任务启动第二个备份副本运行(称为备份执行 / Speculative Execution)。
如果一个工作进程由于损坏的硬件或软件而计算出错误的输出怎么办?
-
那就太糟糕了!MapReduce 假设 CPU 和软件是“故障-停止”的(只发生崩溃故障,不会产生错误结果)。
-
如果协调器自己崩溃了怎么办? (论文未详细说明此问题,这是系统的单点故障)。
-
-
性能如何?
- 图 2
- X 轴:时间
- Y 轴:类似 'grep' 作业读取其输入的总速率
- 输入大小为 1 TB (1000 GB)
- 1764 个工作进程
- 30,000 MB/s (30 GB/s) 是巨大的吞吐量!
- 为什么是 30,000 MB/s?
- 每台工作机器约 17 MB/s —— 140 兆比特每秒 (Mb/s)
- 这超过了我们之前对每台机器网络带宽(55 Mb/s)的猜测。
- 输入文件可能直接从本地 GFS 磁盘读取。
- 所以磁盘的读取速度可能大约就是 17 MB/s。
- 为什么主要活动期大约是 30 秒?
- 为什么需要 50 秒才能使吞吐量达到最大值?(启动、任务分发、GFS读取预热等因素导致前期吞吐量较低)。
-
现状如何?
-
极具影响力 (Hadoop, Spark 等均由其启发)。
在谷歌内部可能不再使用
。
- 被 Flume / FlumeJava 取代 (见 Chambers 等人的论文)。
- GFS 被 Colossus (无详细公开描述) 和 BigTable 取代。
-
-
结论
- MapReduce 开创并普及了大型集群计算。
- - 它不是最高效或最灵活的。
- + 可扩展性非常好。
- + 编程简单——MapReduce 隐藏了失败和数据移动的复杂性。
- 这些在实践中是很好的权衡。
- 我们将在课程后续部分看到一些更高级的继任者。
- 祝你在 Lab 1 中愉快(Have fun with Lab 1)!
第二讲:线程与 RPC
好的,这是麻省理工学院 6.5840 分布式系统工程 2025 年第二讲(线程与 RPC)的中文翻译:
6.5840 2025 第二讲:线程与 RPC
主题:实现分布式系统
- ...以及为实验准备的 Go 编程
- Go 协程(goroutine)与网络爬虫示例
- Go RPC(远程过程调用)
为什么选择 Go?
- 对线程(协程)的良好支持
- 方便的 RPC 机制
- 类型安全和内存安全
- 垃圾回收(GC)(避免释放后使用问题)
- 线程 + GC 的组合特别有吸引力!
- 语言本身不太复杂
- Go 常用于分布式系统开发
(提示:学习完本教程后,可参考 )
线程 (Threads)
- 一种有用的结构化工具,但也可能很棘手
- Go 称其为 goroutines(协程);其他语言通常称为 threads(线程)
线程 = "执行线程" (thread of execution)
- 线程允许一个程序同时做多件事情
- 每个线程自身是串行执行的,就像一个非线程程序一样
- 线程之间共享内存
- 每个线程包含一些自身状态:
- 程序计数器 (PC)、寄存器、栈
为什么需要线程?
I/O 并发 (I/O concurrency)
- 客户端并行地向多个服务器发送请求并等待回复。
- 服务器同时处理多个客户端请求。
- 每个请求都可能阻塞。
- 在等待为客户端 X 从磁盘读取数据时,可以处理客户端 Y 的请求。
多核性能 (Multicore performance)
- 在多个核心上并行执行代码。
便利性 (Convenience)
- 在后台,每秒检查一次每个工作器是否仍然存活。
线程的替代方案?
-
有:编写在单个线程中
显式交错
多个活动的代码。
- 通常称为 “事件驱动” (event-driven)。
-
为每个活动(例如每个客户端请求)维护一个状态表。
-
一个“事件”循环 (event loop) 负责:
- 检查每个活动的新输入(例如,来自服务器的回复到达),
- 执行每个活动的下一步操作,
- 更新状态。
-
事件驱动可以实现
I/O 并发
,
- 并消除了线程开销(可能很大),
- 但无法获得多核加速,
- 并且编程起来很痛苦。
线程编程的挑战:
安全地共享数据 (Sharing data safely)
-
如果两个线程同时执行
n = n + 1会怎样? -
或者一个线程读取时另一个线程在递增?
-
这就是
“竞态条件” (race)
- = 两个线程同时使用同一块内存,其中一个(或两个)执行写入操作。
- 通常是一个 bug。
解决方案:
- 使用锁(Go 的 `sync.Mutex`)
- 或者避免共享可变数据 (mutable data)。
线程间协调 (Coordination between threads)
- 一个线程生产数据,另一个线程消费数据。
- 消费者如何等待(并释放 CPU)?
- 生产者如何唤醒消费者?
- 解决方案: 使用 Go 的通道 (
channels)、sync.Cond或sync.WaitGroup。
死锁 (Deadlock)
- 线程之间形成循环等待。
- 通过锁、通道或 RPC 发生。
让我们以教程中的网络爬虫作为线程示例。
什么是网络爬虫?
-
目标: 抓取所有网页(例如,提供给索引器)。
-
你给它一个起始网页。
-
它递归地跟踪所有链接。
-
[图示:页面、链接、一个有向无环图 (DAG)、一个环]
-
但
不要重复抓取
同一个页面,
- 并且不要陷入循环。
爬虫的挑战
利用 I/O 并发 (Exploit I/O concurrency)
-
网络延迟比网络容量更具限制性
- 互联网延迟:大约 0.1 秒(受光速等因素影响)
- 互联网吞吐量:可能为 MB/秒 或 GB/秒
并行抓取多个页面
- 以提高每秒抓取的 URL 数量。
- => 使用线程实现并发。
每个 URL 只抓取一次 (Fetch each URL only once)
- 避免浪费网络带宽。
- 避免链接循环。
- 对远程服务器友好。
- => 需要记录哪些 URL 已被访问过。
- 知道何时完成 (Know when finished)
我们将看三种解决方案 [参见课程页面上的 crawler.go]
- 串行爬虫 (Serial)
- 基于共享数据协调的并发爬虫 (Concurrent, coordination via shared data)
- 基于通道协调的并发爬虫 (Concurrent, coordination via channels)
1. 串行爬虫 (Serial crawler):
-
通过递归调用
Serial()进行深度优先探索。 -
fetched映射(map)避免重复抓取并打破循环。
- 一个单一的映射,通过引用传递,调用者能看到被调用者的更新。
-
当所有 [递归] 链接都被探索完毕时完成:简单。
缺点:
一次只抓取一个页面 ——
慢
。
- 我们能在
Serial()调用前加个go吗? - 会发生什么?
- 让我们试试... 发生了什么?
2. 基于互斥锁的并发爬虫 (ConcurrentMutex crawler):
-
为每个页面抓取创建一个线程(协程)。
- 许多并发抓取,更高的抓取速率。
-
go func...创建一个 goroutine 并启动它运行。
func...是一个“匿名函数”。
-
线程共享
fs.fetched映射。
- 因此只有一个线程会抓取任何给定的页面。
-
为什么在
testAndSet()中需要互斥锁 (
Lock()和
Unlock())?
原因一:
-
两个线程同时使用相同的 URL 调用
ConcurrentMutex()。
- 由于两个不同的页面包含指向同一个 URL 的链接。
-
T1 读取
fetched[url],T2 读取fetched[url]。 -
两者都看到该 URL 尚未被抓取 (
fetched[url] = false)。 -
两者都去抓取 —— 这是错误的!
-
互斥锁导致一个线程等待,而另一个线程执行检查和设置操作。
- 因此只有一个线程看到
fetched[url]==false。
- 因此只有一个线程看到
-
我们说
“锁保护了
fs.fetched[]”。
- 但请注意 Go 并不强制锁和数据之间的任何关系!
-
锁/解锁之间的代码通常称为 “临界区” (critical section)。
原因二:
-
在内部,映射 (
map) 是一个复杂的数据结构(树?可扩展哈希表?)。 -
并发更新/更新可能会破坏其内部不变性 (invariants)。
-
并发更新/读取可能导致读取崩溃。
-
defer...(用于确保解锁) -
如果我注释掉
Lock()/
Unlock()会怎样?
-
go run crawler.go- 它总是有效吗?总是失败吗?为什么?
-
go run -race crawler.go- 即使输出正确,也能检测到竞态条件!
-
-
如果我忘记
Unlock()会怎样?死锁 (deadlock)。
-
-
ConcurrentMutex爬虫如何知道它完成了?
-
sync.WaitGroup—— 它基本上是一个计数器。 -
Wait()等待所有的
Add()操作被
Done()操作平衡掉。
- 即等待所有子线程完成。
-
[图示:覆盖在循环 URL 图上的 goroutine 树]
-
树中的每个节点都有一个
WaitGroup。
-
-
可能有多少个并发线程?
3. 基于通道的并发爬虫 (ConcurrentChannel crawler)
Go 通道 (channel):
-
通道是一个对象
ch := make(chan int)
-
通道允许一个线程向另一个线程发送对象。
-
ch <- x- 发送者 (
sender) 等待,直到某个 goroutine 接收。
- 发送者 (
-
y := <- ch- 接收者 (
receiver) 等待,直到某个 goroutine 发送。
- 接收者 (
-
还有:
for y := range ch -
通道既通信又同步。
-
多个线程可以在一个通道上发送和接收。
-
发送+接收耗时不到一微秒 —— 相当高效。
-
记住:
发送者会阻塞直到接收者接收!
- “同步的” (
synchronous) - 小心死锁!
- “同步的” (
-
ConcurrentChannel的
coordinator()-
coordinator()为每个页面抓取创建一个工作器 (worker) goroutine。 -
worker()在通道上发送页面 URL 的切片 (
slice)。
- 多个工作器在同一个通道上发送。
-
coordinator()从通道读取 URL 切片。
-
-
协调器在
哪一行代码处等待
?
- 协调器在等待时是否占用 CPU 时间?
-
注意:这里没有递归;
coordinator()创建所有工作器。 -
注意:不需要锁
fetched映射,因为它没有被共享! -
协调器如何知道它完成了?
- 保持工作器数量的计数
n。 - 每个工作器在通道上恰好发送一个条目 (
item)。
- 保持工作器数量的计数
-
通道做两件事:
- 值的通信。
- 事件的通知(例如线程终止)。
为什么多个线程使用同一个通道是安全的?
这是竞态条件吗?
- 工作器线程修改(创建)URL 切片,协调器使用它?
- 工作器只在发送之前写入切片
- 协调器只在接收之后读取切片
- 因此它们不能同时使用切片,所以没有竞态。
为什么 ConcurrentChannel() 为 ch <- ... 专门创建一个 goroutine?
- 让我们去掉这个 goroutine... (尝试省略 goroutine 创建,观察行为变化)
何时使用共享和锁,何时使用通道?
-
大多数(所有?)问题都可以用任一种风格解决。
-
哪种更有意义取决于程序员的思维方式:
- 状态 (State) —— 共享和锁
- 通信 (Communication) —— 通道
-
对于
6.824 实验
,我建议:
- 使用共享+锁处理状态,
- 使用
sync.Cond、通道或time.Sleep()处理等待/通知。
远程过程调用 (RPC - Remote Procedure Call)
- 分布式系统机制的关键部分;所有实验都使用 RPC。
- 目标: 易于编程的客户端/服务器通信。
- 隐藏网络协议的细节。
- 将数据(字符串、数组、映射等)转换为“线路格式” (
wire format)。 - 可移植性 / 互操作性。
RPC 消息图示:
Client Server
request--->
<---response
软件结构:
client app handler fns (处理函数)
stub fns (存根函数) dispatcher (分发器)
RPC lib (RPC库) RPC lib (RPC库)
net ------------ net
Go 示例: 课程页面上的 kv.go
-
一个简单的键/值存储服务器 ——
Put(key,value),Get(key)->value -
使用 Go 的 RPC 库。
通用步骤:
-
为每个服务器处理函数声明
Args和Reply结构体。
客户端 (Client):
-
connect()中的Dial()创建到服务器的 TCP 连接。 -
get()和put()是客户端 “存根” (stubs)。 -
Call()要求 RPC 库执行调用。
- 你指定连接、函数名、参数、存放回复的位置。
- 库编组 (marshalls) 参数,发送请求,等待,解组 (unmarshalls) 回复。
Call()的返回值指示是否收到了回复。- 通常你还会有一个
reply.Err指示服务级别的失败。
服务器 (Server):
-
Go 要求服务器声明一个对象,其方法作为 RPC 处理函数。
-
服务器然后用 RPC 库注册 (Register) 该对象。
-
服务器接受 TCP 连接,并将它们交给 RPC 库。
-
RPC 库:
- 读取每个请求。
- 为这个请求创建一个新的 goroutine。
- 解组请求。
- 查找命名对象(在
Register()创建的表中)。 - 调用对象的命名方法(分发
dispatch)。 - 编组回复。
- 在 TCP 连接上写入回复。
-
服务器的
Get()和
Put()处理函数:
- 必须加锁,因为 RPC 库为每个请求创建了一个新的 goroutine。
- 读取参数 (
args);修改回复 (reply)。
一些细节:
绑定 (Binding):
客户端如何知道要与哪台服务器计算机通信?
-
对于 Go 的 RPC,服务器名称/端口是
Dial的参数。 -
大型系统有某种名称或配置服务器。
编组 (Marshalling):
将数据格式化为数据包。
- Go 的 RPC 库可以传递字符串、数组、对象、映射等。
- Go 通过复制所指向的数据来传递指针。
- 不能传递通道 (
channels) 或函数 (functions)。 - 只编组导出的字段(即字段名以大写字母开头的字段)。
RPC 问题:如何处理故障?
- 例如:丢包、网络中断、服务器缓慢、服务器崩溃。
故障对客户端 RPC 库来说是什么样子的?
-
客户端从未看到来自服务器的响应。
-
客户端
不知道
服务器是否看到了请求!
- [图示:请求在不同环节丢失的可能情况]
- 可能服务器从未看到请求。
- 可能服务器执行了,但在发送回复之前崩溃了。
- 可能服务器执行了,但在回复即将送达时网络中断了。
远程过程调用与单机上的过程调用行为不同!
- 这是实现分布式系统时反复出现的挑战。
最简单的故障处理方案:“尽力而为 RPC” (best-effort RPC)
Call()等待响应一段时间。- 如果没有响应到达,重新发送请求。
- 重复几次。
- 然后放弃并返回错误。
问题:应用程序处理“尽力而为”容易吗?
一个特别糟糕的情况:
-
客户端执行:
Put("k", 10);Put("k", 20);
-
两者都报告成功。
-
Get("k")会返回什么?
- [图示:超时、重发、原始请求延迟到达]
10还是20?结果不确定!
问题:“尽力而为”是否可行?
-
对于只读操作可能可行。
-
对于
重复执行无害
的操作可能可行。
- 例如,数据库检查记录是否已插入。
其他常见的语义:“最多一次” (at-most-once)
-
例如,Go RPC 是“最多一次”的一种简单形式。
-
打开 TCP 连接。
-
将请求写入 TCP 连接。
Go RPC 从不重新发送请求。
-
因此服务器不会看到重复请求。
-
Go RPC 代码在未收到回复时返回错误。
- 可能由于超时(来自 TCP)。
- 可能服务器没看到请求。
- 可能服务器处理了请求,但在回复返回之前服务器或网络故障了。
-
实验探索了实现“最多一次”的其他方式。
- 完全不重试对于复制服务器来说限制太大。
- 如果第一个副本失败,我们希望能在另一个副本上重试。
你的任务
好的,这是您提供的关于 Lab 1 任务描述的中文翻译:
你的任务(中等/困难)
你的任务是实现一个分布式的 MapReduce 系统,包含两个程序:协调器 (coordinator) 和 工作器 (worker)。系统中将只有一个协调器进程,以及一个或多个并行执行的工作器进程。在真实系统中,工作器会运行在多台不同的机器上,但在本实验中,你将在单台机器上运行所有进程。工作器将通过 RPC (远程过程调用) 与协调器通信。
每个工作器进程将在循环中执行以下操作:
- 向协调器请求一个任务。
- 从一个或多个文件中读取该任务的输入。
- 执行该任务。
- 将该任务的输出写入一个或多个文件。
- 再次向协调器请求新任务。
协调器应能检测到某个工作器未能在合理时间内(本实验使用 十秒)完成其任务,并将相同的任务分配给另一个工作器。
我们提供了一些起始代码。协调器和工作器的 "main" 函数分别在 main/mrcoordinator.go 和 main/mrworker.go 中;不要修改这些文件。你应该将你的实现放在 mr/coordinator.go, mr/worker.go 和 mr/rpc.go 中。
如何运行你的代码(以单词计数应用为例):
-
首先,确保单词计数插件已重新构建:
$ go build -buildmode=plugin ../mrapps/wc.go -
在
main目录下,运行协调器:
$ rm mr-out* # 删除之前的输出文件(如果有) $ go run mrcoordinator.go pg-*.txt- 传递给
mrcoordinator.go的pg-*.txt参数是输入文件;每个文件对应一个 "分片" (split),是单个 Map 任务的输入。
- 传递给
-
在一个或多个其他窗口中,运行一些工作器:
$ go run mrworker.go wc.so -
当工作器和协调器都完成后,查看
mr-out-*中的输出。完成实验后,所有输出文件的排序合并结果应该与顺序执行的输出匹配,如下所示:
$ cat mr-out-* | sort | more A 509 ABOUT 2 ACT 8 ...
我们在 main/test-mr.sh 中为你提供了一个测试脚本。这些测试会检查当输入是 pg-xxx.txt 文件时,wc(单词计数)和 indexer(索引器)这两个 MapReduce 应用是否产生了正确的输出。测试还会检查你的实现是否并行运行 Map 和 Reduce 任务,以及是否能从运行任务时崩溃的工作器中恢复。
测试说明:
-
如果你现在运行测试脚本,它会挂起,因为协调器永远不会结束:
$ cd ~/6.5840/src/main $ bash test-mr.sh *** Starting wc test. -
你可以修改
mr/coordinator.go中
Done函数里的
ret := false为
true,这样协调器会立即退出。然后:
$ bash test-mr.sh *** Starting wc test. sort: No such file or directory cmp: EOF on mr-wc-all --- wc output is not the same as mr-correct-wc.txt --- wc test: FAIL $- 测试脚本期望看到名为
mr-out-X的输出文件(每个 Reduce 任务对应一个)。mr/coordinator.go和mr/worker.go的空实现不会生成这些文件(也几乎不做任何事情),所以测试会失败。
- 测试脚本期望看到名为
-
当你完成实现后,测试脚本的输出应该如下所示:
$ bash test-mr.sh *** Starting wc test. --- wc test: PASS *** Starting indexer test. --- indexer test: PASS *** Starting map parallelism test. # Map 并行度测试 --- map parallelism test: PASS *** Starting reduce parallelism test. # Reduce 并行度测试 --- reduce parallelism test: PASS *** Starting job count test. # 任务计数测试 --- job count test: PASS *** Starting early exit test. # 提前退出测试 --- early exit test: PASS *** Starting crash test. # 崩溃测试 --- crash test: PASS *** PASSED ALL TESTS $
注意事项:
-
你可能会看到一些来自 Go RPC 包的类似错误:
2019/12/16 13:27:09 rpc.Register: method "Done" has 1 input parameters; needs exactly three- 忽略这些消息。 将协调器注册为 RPC 服务器时会检查其所有方法是否适合 RPC(需要 3 个输入参数);我们知道
Done方法不是通过 RPC 调用的。
- 忽略这些消息。 将协调器注册为 RPC 服务器时会检查其所有方法是否适合 RPC(需要 3 个输入参数);我们知道
-
此外,根据你终止工作器进程的策略,你可能会看到一些类似错误:
2025/02/11 16:21:32 dialing:dial unix /var/tmp/5840-mr-501: connect: connection refused- 每个测试中出现少量这样的消息是正常的;它们发生在协调器退出后,工作器无法联系到协调器 RPC 服务器时。
规则:
- Map 阶段分桶: Map 阶段应将中间键 (intermediate keys) 划分到
nReduce个桶中,对应nReduce个 Reduce 任务。nReduce是main/mrcoordinator.go传递给MakeCoordinator()的参数(Reduce 任务的数量)。每个 Mapper 应该为 Reduce 任务创建nReduce个中间文件。 - Reduce 输出文件: 工作器实现应将第
X个 Reduce 任务的输出放在文件mr-out-X中。 - 输出文件格式:
mr-out-X文件应包含 Reduce 函数输出的每一行。该行应使用 Go 的"%v %v"格式生成,传入键 (key) 和值 (value)。请参考main/mrsequential.go中注释为 "this is the correct format" 的那行代码。如果你的实现偏离此格式太多,测试脚本将失败。 - 可修改文件: 你可以修改
mr/worker.go,mr/coordinator.go和mr/rpc.go。你可以临时修改其他文件进行测试,但请确保你的代码能在原始版本上工作;我们将使用原始版本进行测试。 - 中间文件位置: 工作器应将 Map 的中间输出放在当前目录的文件中,以便你的工作器稍后可以将它们作为 Reduce 任务的输入读取。
- 协调器退出:
main/mrcoordinator.go期望mr/coordinator.go实现一个Done()方法,当 MapReduce 作业完全完成时返回true;此时,mrcoordinator.go将退出。 - 工作器退出: 当作业完全完成后,工作器进程也应退出。一个简单的实现方法是使用
call()的返回值:如果工作器无法联系到协调器,它可以认为协调器已退出(因为作业已完成),因此工作器也可以终止。根据你的设计,你可能还会发现让协调器给工作器分配一个 "请退出" 伪任务 ("please exit" pseudo-task) 很有帮助。
提示:
-
课程指南页面 提供了一些开发和调试技巧。
-
一个起步方法是修改
mr/worker.go中的Worker()函数,使其向协调器发送 RPC 请求任务。然后修改协调器,使其响应一个尚未开始的 Map 任务的文件名。接着修改工作器读取该文件并调用应用程序的 Map 函数(如mrsequential.go中所示)。 -
应用程序的 Map 和 Reduce 函数是在运行时使用 Go 的
plugin包从文件名以.so结尾的文件中加载的。 -
如果你修改了
mr/目录下的任何内容,你可能需要重新构建你使用的 MapReduce 插件,例如:go build -buildmode=plugin ../mrapps/wc.go。 -
本实验依赖于工作器共享文件系统。当所有工作器运行在同一台机器上时,这很简单;但如果工作器运行在不同机器上,则需要像 GFS 这样的全局文件系统。
-
中间文件的合理命名约定是
mr-X-Y,其中X是 Map 任务编号,Y是 Reduce 任务编号。 -
工作器的 Map 任务代码需要一种方式将中间键值对存储到文件中,以便在 Reduce 任务期间能正确读取回来。一种方法是使用 Go 的
encoding/json包:
-
写入 JSON 格式的键值对:
enc := json.NewEncoder(file) for _, kv := KeyValue { err := enc.Encode(&kv) if err != nil { log.Fatal("编码失败:", err) } } -
读取 JSON 格式的键值对:
dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) }
-
-
工作器的 Map 部分可以使用
ihash(key)函数(在worker.go中)为给定键选择 Reduce 任务。 -
你可以从
mrsequential.go中借鉴一些代码,用于读取 Map 输入文件、在 Map 和 Reduce 之间排序中间键值对,以及将 Reduce 输出存储到文件中。 -
协调器作为 RPC 服务器将是并发的;别忘了锁住共享数据。
-
使用 Go 的竞态检测器 (race detector):
go run -race。test-mr.sh开头有注释说明如何使用-race运行它。注意: 我们评分时不会使用竞态检测器。然而,如果你的代码存在竞态条件,即使不使用竞态检测器,在我们测试时也很可能失败。 -
工作器有时需要等待(例如,在最后一个 Map 完成之前,Reduce 无法启动)。一种方法是让工作器定期向协调器请求工作,在每次请求之间使用
time.Sleep()休眠。另一种方法是让协调器中相关的 RPC 处理程序包含一个等待循环(使用time.Sleep()或sync.Cond)。Go 为每个 RPC 的处理程序运行在自己的线程中,因此一个处理程序在等待并不会阻止协调器处理其他 RPC。 -
协调器无法可靠地区分崩溃的工作器、存活但因某种原因停滞的工作器和正在执行但速度过慢的工作器。你能做的最好方法是让协调器等待一段时间,然后放弃并将任务重新分配给另一个工作器。对于本实验,让协调器等待十秒;之后协调器应假定该工作器已死亡(当然,它可能并没有死)。
-
如果你选择实现备份任务 (Backup Tasks)(论文第 3.6 节),请注意我们测试你的代码在工作器执行任务且未崩溃时不会调度多余的任务。备份任务只应在相对较长的时间段(例如 10 秒)后才被调度。
-
要测试崩溃恢复,你可以使用
mrapps/crash.go应用插件。它会在 Map 和 Reduce 函数中随机退出。 -
为了确保在崩溃发生时没有人观察到部分写入的文件,MapReduce 论文提到了一个技巧:使用临时文件,并在其完全写入后原子性地重命名它。你可以使用
ioutil.TempFile(如果你运行的是 Go 1.17 或更高版本,则使用os.CreateTemp)创建临时文件,并使用os.Rename原子性地重命名它。 -
test-mr.sh在子目录mr-tmp中运行其所有进程。因此,如果出现问题,你想查看中间文件或输出文件,请在那里查找。你可以临时修改test-mr.sh使其在失败的测试后退出,这样脚本就不会继续测试(也不会覆盖输出文件)。 -
test-mr-many.sh连续多次运行test-mr.sh,你可能需要这样做以发现低概率的 bug。它接受一个参数指定运行测试的次数。不应并行运行多个test-mr.sh实例,因为协调器会重用相同的套接字,导致冲突。
Go RPC 注意事项:
-
Go RPC 仅发送字段名以大写字母开头的结构体字段。子结构也必须具有大写的字段名。
-
调用 RPC
call()函数时,回复结构体 (
reply struct) 应包含所有
默认值
。RPC 调用应如下所示:
reply := SomeType{} call(..., &reply)在调用之前
不要设置
reply的任何字段。如果你传递了具有非默认字段的
reply结构体,RPC 系统可能会静默地返回错误的值。
无学分挑战练习:
-
实现你自己的 MapReduce 应用(参考
mrapps/*中的示例),例如,分布式 Grep(MapReduce 论文第 2.3 节)。
在多台机器上运行:
让你的 MapReduce 协调器和工作器在
不同的机器
上运行(就像实际应用中那样)。你需要:
- 将 RPC 设置为通过 TCP/IP 通信(而不是 Unix 套接字,参见
Coordinator.server()中被注释掉的行)。 - 使用共享文件系统读写文件。
- 例如,你可以通过 SSH 登录到 MIT 的多个 Athena 集群机器(它们使用 AFS 共享文件);或者你可以租用几个 AWS 实例并使用 S3 进行存储。
lab2
好的,这是您提供的分布式系统实验文档的中文翻译:
介绍
在本实验中,您将为单台机器构建一个键/值(Key/Value)服务器,该服务器确保即使在网络故障的情况下,每个 Put 操作也最多执行一次(at-most-once),并且操作是线性一致(linearizable)的。您将使用此 KV 服务器来实现一个锁(lock)。在后续的实验中,将复制类似这样的服务器以处理服务器崩溃。
KV 服务器
每个客户端使用一个 Clerk 与键/值服务器交互,Clerk 向服务器发送 RPC(远程过程调用)。客户端可以向服务器发送两种不同的 RPC:Put(key, value, version) 和 Get(key)。服务器维护一个内存中的映射(map),该映射记录每个键对应的(值, 版本号)元组。键(key)和值(value)是字符串。版本号(version)记录该键被写入的次数。
Put(key, value, version) 仅在 Put 的版本号与服务器为该键记录的版本号匹配时,才在映射中安装或替换该键的值。如果版本号匹配,服务器还会增加该键的版本号。如果版本号不匹配,服务器应返回 rpc.ErrVersion。
客户端可以通过调用版本号为 0 的 Put 来创建一个新键(服务器存储的最终版本号将是 1)。如果 Put 的版本号大于 0 且该键在服务器上不存在,服务器应返回 rpc.ErrNoKey。
Get(key) 获取该键的当前值及其关联的版本号。如果该键在服务器上不存在,服务器应返回 rpc.ErrNoKey。
为每个键维护一个版本号,对于使用 Put 实现锁以及在网络不可靠且客户端重传时确保 Put 操作的最多一次(at-most-once)语义非常有用。
当您完成本实验并通过所有测试后,从调用 Clerk.Get 和 Clerk.Put 的客户端角度来看,您将拥有一个线性一致的键/值服务。也就是说,如果客户端操作不是并发的,每个客户端的 Clerk.Get 和 Clerk.Put 将观察到由先前操作序列所隐含的状态修改。对于并发操作,返回值和最终状态将与这些操作按某种顺序一次执行一个相同。如果操作在时间上重叠,则它们是并发的:例如,如果客户端 X 调用 Clerk.Put(),然后客户端 Y 调用 Clerk.Put(),接着客户端 X 的调用返回。一个操作必须观察到在该操作开始之前所有已完成操作的效果。有关线性一致性的更多背景信息,请参阅 FAQ。
线性一致性对应用程序来说很方便,因为它是您从单台服务器(一次处理一个请求)看到的行为。例如,如果一个客户端从服务器收到更新请求的成功响应,那么随后启动的其他客户端的读取操作保证能看到该更新的效果。对于单台服务器来说,提供线性一致性相对容易。
开始
我们在 src/kvsrv1 中为您提供了骨架代码和测试。kvsrv1/client.go 实现了一个 Clerk,客户端用它来管理与服务器的 RPC 交互;Clerk 提供了 Put 和 Get 方法。kvsrv1/server.go 包含服务器代码,包括实现 RPC 请求服务器端的 Put 和 Get 处理程序。您需要修改 client.go 和 server.go。RPC 请求、回复和错误值定义在 kvsrv1/rpc 包中的文件 kvsrv1/rpc/rpc.go 中,您应该查看该文件,但无需修改 rpc.go。
要开始运行,请执行以下命令。别忘了 git pull 以获取最新软件。
$ cd ~/6.5840
$ git pull
...
$ cd src/kvsrv1
$ go test -v
=== RUN TestReliablePut
One client and reliable Put (reliable network)...
kvsrv_test.go:25: Put err ErrNoKey
...
$
具有可靠网络的键/值服务器(简单)
您的第一个任务是在没有消息丢失的情况下实现一个解决方案。您需要在 client.go 中的 Clerk 的 Put/Get 方法中添加发送 RPC 的代码,并在 server.go 中实现 Put 和 Get 的 RPC 处理程序。
当您通过测试套件中的 Reliable 测试时,即完成此任务:
$ go test -v -run Reliable
=== RUN TestReliablePut
One client and reliable Put (reliable network)...
... Passed -- 0.0 1 5 0
--- PASS: TestReliablePut (0.00s)
=== RUN TestPutConcurrentReliable
Test: many clients racing to put values to the same key (reliable network)...
info: linearizability check timed out, assuming history is ok
... Passed -- 3.1 1 90171 90171
--- PASS: TestPutConcurrentReliable (3.07s)
=== RUN TestMemPutManyClientsReliable
Test: memory use many put clients (reliable network)...
... Passed -- 9.2 1 100000 0
--- PASS: TestMemPutManyClientsReliable (16.59s)
PASS
ok 6.5840/kvsrv1 19.681s
每个 Passed 后面的数字分别是:实际时间(秒)、常量 1、发送的 RPC 数量(包括客户端 RPC)以及执行的键/值操作数量(Clerk 的 Get 和 Put 调用)。
使用 go test -race 检查您的代码是否存在竞争条件。
使用键/值 Clerk 实现锁(中等)
在许多分布式应用程序中,运行在不同机器上的客户端使用键/值服务器来协调它们的活动。例如,ZooKeeper 和 Etcd 允许客户端使用分布式锁进行协调,类似于 Go 程序中的线程如何使用锁(即 sync.Mutex)进行协调。Zookeeper 和 Etcd 使用条件写入(conditional put)来实现这种锁。
在本练习中,您的任务是实现一个基于客户端 Clerk.Put 和 Clerk.Get 调用的锁。该锁支持两个方法:Acquire(获取)和 Release(释放)。锁的规范是:一次只能有一个客户端成功获取锁;其他客户端必须等待第一个客户端使用 Release 释放锁。
我们在 src/kvsrv1/lock/ 中为您提供了骨架代码和测试。您需要修改 src/kvsrv1/lock/lock.go。您的 Acquire 和 Release 代码可以通过调用 lk.ck.Put() 和 lk.ck.Get() 与您的键/值服务器通信。
注意:如果客户端在持有锁时崩溃,该锁将永远不会被释放。在比本实验更复杂的设计中,客户端会为锁附加一个租约(lease)。当租约到期时,锁服务器将代表客户端释放锁。在本实验中,客户端不会崩溃,您可以忽略此问题。
实现 Acquire 和 Release。当您的代码通过 lock 子目录中测试套件的 Reliable 测试时,即完成此练习:
$ cd lock
$ go test -v -run Reliable
=== RUN TestOneClientReliable
Test: 1 lock clients (reliable network)...
... Passed -- 2.0 1 974 0
--- PASS: TestOneClientReliable (2.01s)
=== RUN TestManyClientsReliable
Test: 10 lock clients (reliable network)...
... Passed -- 2.1 1 83194 0
--- PASS: TestManyClientsReliable (2.11s)
PASS
ok 6.5840/kvsrv1/lock 4.120s
(如果尚未实现锁,第一个测试会成功。)
此练习需要很少的代码,但比前一个练习需要更多独立思考。
- 您需要为每个锁客户端生成一个唯一标识符;调用
kvtest.RandValue(8)生成一个随机字符串。 - 锁服务应使用一个特定的键来存储“锁状态”(您需要精确决定锁状态是什么)。要使用的键通过
src/kvsrv1/lock/lock.go中MakeLock的参数l传递。
具有消息丢失的键/值服务器(中等)
本练习的主要挑战在于网络可能会重新排序、延迟或丢弃 RPC 请求和/或回复。为了从丢弃的请求/回复中恢复,Clerk 必须不断重试每个 RPC,直到收到服务器的回复。
如果网络丢弃了一个 RPC 请求消息,那么客户端重新发送请求将解决问题:服务器将接收并仅执行重新发送的请求。
然而,网络也可能丢弃 RPC 回复消息。客户端不知道哪条消息被丢弃;客户端只观察到它没有收到回复。如果是回复被丢弃,并且客户端重新发送 RPC 请求,那么服务器将收到该请求的两个副本。这对于 Get 是可以的,因为 Get 不会修改服务器状态。使用相同的版本号重新发送 Put RPC 是安全的,因为服务器根据版本号有条件地执行 Put;如果服务器已经接收并执行了一个 Put RPC,它将对重新传输的该 RPC 副本响应 rpc.ErrVersion,而不是第二次执行 Put。
一个棘手的情况是,如果服务器对 Clerk 重试的 RPC 回复了 rpc.ErrVersion。在这种情况下,Clerk 无法知道其 Put 是否已被服务器执行:第一个 RPC 可能已被服务器执行,但网络可能丢弃了服务器的成功响应,因此服务器仅对重传的 RPC 发送了 rpc.ErrVersion。或者,可能是在该 Clerk 的第一个 RPC 到达服务器之前,另一个 Clerk 更新了该键,因此服务器既没有执行该 Clerk 的两个 RPC,并对两者都回复了 rpc.ErrVersion。因此,如果 Clerk 为重传的 Put RPC 收到 rpc.ErrVersion,Clerk.Put 必须向应用程序返回 rpc.ErrMaybe 而不是 rpc.ErrVersion,因为该请求可能已被执行。然后由应用程序来处理这种情况。如果服务器对初始(非重传的)Put RPC 响应 rpc.ErrVersion,那么 Clerk 应向应用程序返回 rpc.ErrVersion,因为该 RPC 肯定没有被服务器执行。
(对应用程序开发者来说,如果 Put 是精确一次(exactly-once)的(即没有 rpc.ErrMaybe 错误)会更方便,但这很难保证,除非在服务器上为每个 Clerk 维护状态。在本实验的最后一个练习中,您将使用您的 Clerk 实现一个锁,以探索如何使用最多一次(at-most-once)的 Clerk.Put 进行编程。)
现在,您应该修改您的 kvsrv1/client.go,以便在面对丢弃的 RPC 请求和回复时继续工作。客户端 ck.clnt.Call() 返回 true 表示客户端收到了来自服务器的 RPC 回复;返回 false 表示它没有收到回复(更准确地说,Call() 等待回复消息超时,如果在超时间隔内没有回复到达,则返回 false)。您的 Clerk 应不断重新发送 RPC,直到收到回复。请记住上面关于 rpc.ErrMaybe 的讨论。您的解决方案不应要求对服务器进行任何更改。
在 Clerk 中添加代码,使其在未收到回复时重试。如果您的代码通过了 kvsrv1/ 中的所有测试,即完成此任务,如下所示:
$ go test -v
=== RUN TestReliablePut
One client and reliable Put (reliable network)...
... Passed -- 0.0 1 5 0
--- PASS: TestReliablePut (0.00s)
=== RUN TestPutConcurrentReliable
Test: many clients racing to put values to the same key (reliable network)...
info: linearizability check timed out, assuming history is ok
... Passed -- 3.1 1 106647 106647
--- PASS: TestPutConcurrentReliable (3.09s)
=== RUN TestMemPutManyClientsReliable
Test: memory use many put clients (reliable network)...
... Passed -- 8.0 1 100000 0
--- PASS: TestMemPutManyClientsReliable (14.61s)
=== RUN TestUnreliableNet
One client (unreliable network)...
... Passed -- 7.6 1 251 208
--- PASS: TestUnreliableNet (7.60s)
PASS
ok 6.5840/kvsrv1 25.319s
(在客户端重试之前,它应该等待一小会儿;您可以使用 Go 的 time 包并调用 time.Sleep(100 \* time.Millisecond))
使用键/值 Clerk 和不可靠网络实现锁(简单)
修改您的锁实现,使其在网络不可靠时与您修改后的键/值客户端一起正确工作。当您的代码通过 kvsrv1/lock/ 中的所有测试(包括不可靠网络的测试)时,即完成此练习:
$ cd lock
$ go test -v
=== RUN TestOneClientReliable
Test: 1 lock clients (reliable network)...
... Passed -- 2.0 1 968 0
--- PASS: TestOneClientReliable (2.01s)
=== RUN TestManyClientsReliable
Test: 10 lock clients (reliable network)...
... Passed -- 2.1 1 10789 0
--- PASS: TestManyClientsReliable (2.12s)
=== RUN TestOneClientUnreliable
Test: 1 lock clients (unreliable network)...
... Passed -- 2.3 1 70 0
--- PASS: TestOneClientUnreliable (2.27s)
=== RUN TestManyClientsUnreliable
Test: 10 lock clients (unreliable network)...
... Passed -- 3.6 1 908 0
--- PASS: TestManyClientsUnreliable (3.62s)
PASS
ok 6.5840/kvsrv1/lock 10.033s
lab3
Raft 学生避坑指南(阅读时间:30 分钟)
发布于 2016 年 3 月 16 日 — 分享于 Hacker News Twitter Lobsters
在过去的几个月里,我一直担任麻省理工学院(MIT)6.824 分布式系统课程的助教。该课程传统上包含一系列基于 Paxos 共识算法的实验,但今年我们决定转向 Raft。Raft 被“设计得易于理解”,我们希望这一转变能让学生们更轻松。
本文以及随附的《Raft 教师指南》记录了我们使用 Raft 的历程,希望对 Raft 协议的实现者和试图更好理解 Raft 内部机制的学生们有所帮助。如果你在寻找 Paxos 与 Raft 的比较,或者对 Raft 进行更教学式的分析,你应该去阅读《教师指南》。本文末尾列出了 6.824 学生常问的问题及其答案。如果你遇到的问题不在本文主要内容中,请查看问答部分。文章相当长,但其中提出的所有观点都是许多 6.824 学生(和助教)真正遇到的问题。这是一篇值得一读的文章。
背景
在我们深入探讨 Raft 之前,一些背景信息可能有用。6.824 过去有一套基于 Paxos 的实验,用 Go 语言构建;选择 Go 既因为它对学生来说易于学习,也因为它非常适合编写并发、分布式应用程序(goroutine 尤其方便)。在四个实验的过程中,学生们构建了一个容错的、分片的键值存储。第一个实验让他们构建一个基于共识的日志库,第二个实验在其之上添加一个键值存储,第三个实验在多个容错集群之间对键空间进行分片,并由一个容错的分片主节点处理配置变更。我们还有第四个实验,学生必须处理机器的故障和恢复,包括磁盘完好和损坏的情况。这个实验是学生可选的最终项目。
今年,我们决定使用 Raft 重写所有这些实验。前三个实验保持不变,但第四个实验被取消了,因为持久性和故障恢复已经内置在 Raft 中。本文将主要讨论我们在第一个实验中的经验,因为它与 Raft 最直接相关,不过我也会谈到在 Raft 之上构建应用程序(如第二个实验)。
对于刚刚了解 Raft 的人来说,该协议网站上的文字是最好的描述:
Raft 是一种旨在易于理解的共识算法。它在容错性和性能上与 Paxos 等效。不同之处在于,它被分解成相对独立的子问题,并且清晰地解决了实际系统所需的所有主要部分。我们希望 Raft 能使共识算法更广泛地可用,并且这个更广泛的受众能够开发出比当今更高质量的多种基于共识的系统。
像这样的可视化很好地概述了协议的主要组成部分,论文很好地说明了为什么需要各个部分。如果你还没有阅读扩展的 Raft 论文,你应该在继续阅读本文之前先去阅读,因为我将假定你对 Raft 有相当的熟悉度。
与所有分布式共识协议一样,细节决定成败。在没有故障的稳定状态下,Raft 的行为很容易理解,并且可以直观地解释。例如,从可视化中可以简单地看出,假设没有故障,最终会选出一个领导者,并且最终所有发送给领导者的操作都会被追随者以正确的顺序应用。然而,当引入延迟消息、网络分区和服务器故障时,每一个 if、but和 and都变得至关重要。特别是,由于阅读论文时的误解或疏忽,我们会反复看到一些错误。这个问题并非 Raft 独有,而是所有提供正确性的复杂分布式系统中都会出现的问题。
实现 Raft
Raft 的终极指南在 Raft 论文的图 2 中。该图规定了 Raft 服务器之间交换的每个 RPC 的行为,给出了服务器必须维护的各种不变量,并规定了某些操作应在何时发生。在本文的其余部分,我们将大量讨论图 2。必须严格遵守它。
图 2 定义了每个服务器在每个状态下对于每个传入 RPC 应该做什么,以及某些其他事情应该在什么时候发生(例如,何时可以安全地应用日志中的条目)。起初,你可能会试图将图 2 视为一种非正式的指南;你阅读一次,然后开始编写一个大致遵循其所说的实现。这样做,你很快就会得到一个几乎可以工作的 Raft 实现。然后问题开始出现。
实际上,图 2 极其精确,它所做的每一个陈述在规范术语上都应被视为 MUST(必须),而不是 SHOULD(应该)。例如,你可能会在收到 AppendEntries或 RequestVoteRPC 时合理地重置对等体的选举计时器,因为两者都表明其他对等体要么认为自己是领导者,要么正试图成为领导者。直观上,这意味着我们不应该干扰。然而,如果你仔细阅读图 2,它说:
如果选举超时过去,而没有收到当前领导者的
AppendEntriesRPC 或授予投票给候选人:转换为候选人。
这种区别结果非常重要,因为前一种实现可能在特定情况下导致活性显著降低。
注:
-
如果AppendEntries中Entries==nil, 说明是心跳
-
心跳也要执行图2中的检查:
-
term检查:
if args.term < rf.currentTerm { reply.term = rf.currentTerm reply.success = false return } -
logIndex 和logTerm检查:
// prevLog检查 if args.prevLogIndex >= len(rf.log)-1 || rf.log[args.prevLogIndex].term != args.prevLogTerm { reply.term = rf.currentTerm reply.success = false return } // 新增的log检查 如果现有条目与新条目冲突(索引相同但术语不同),请删除现有条目及其后面的所有条目
-
细节的重要性
为了使讨论更具体,让我们考虑一个困扰了许多 6.824 学生的例子。Raft 论文在多个地方提到了心跳 RPC。具体来说,领导者会偶尔(至少每个心跳间隔一次)向所有对等体发送 AppendEntriesRPC,以防止它们开始新的选举。如果领导者没有新的条目要发送给特定的对等体,则 AppendEntriesRPC 不包含任何条目,并被视为心跳。
我们的许多学生假设心跳在某种程度上是“特殊的”;当对等体收到心跳时,它应该以不同于非心跳 AppendEntriesRPC 的方式处理。特别是,许多人会在收到心跳时简单地重置他们的选举计时器,然后返回成功,而不执行图 2 中指定的任何检查。这是极其危险的。通过接受 RPC,追随者隐式地告诉领导者,他们的日志与领导者的日志匹配,直到并包括 AppendEntries参数中包含的 prevLogIndex。收到回复后,领导者可能(错误地)决定某个条目已被复制到大多数服务器,并开始提交它。
许多人遇到的另一个问题(通常是在修复上述问题之后)是,在收到心跳时,他们会截断追随者日志中 prevLogIndex之后的部分,然后附加 AppendEntries参数中包含的任何条目。这也是不正确的。我们可以再次参考图 2:
如果现有条目与新条目冲突(索引相同但任期不同),则删除现有条目及其后的所有条目。
这里的 if至关重要。如果追随者拥有领导者发送的所有条目,追随者绝不能截断其日志。领导者发送的条目之后的任何元素必须保留。这是因为我们可能收到来自领导者的过时 AppendEntriesRPC,截断日志将意味着“收回”我们可能已经告诉领导者我们日志中已有的条目。
调试 Raft
不可避免地,你的 Raft 实现的第一个版本会有错误。第二个也是。第三个也是。第四个也是。一般来说,每一个都会比前一个错误少,而且根据经验,你的大多数错误都是由于没有严格遵守图 2 造成的。
在调试 Raft 时,通常有四个主要的错误来源:活锁(livelocks)、不正确或不完整的 RPC 处理程序、未能遵循规则(The Rules)以及任期混淆(term confusion)。死锁(deadlocks)也是一个常见问题,但通常可以通过记录所有锁的获取和释放,并找出哪些锁被获取但未释放来调试。让我们依次考虑这些:
活锁(Livelocks)
当你的系统发生活锁时,系统中的每个节点都在做某事,但你的节点集体处于一种无法取得进展的状态。这在 Raft 中很容易发生,特别是如果你没有严格遵守图 2。一种活锁场景尤其常见: 没有领导者被选出,或者一旦领导者被选出,其他某个节点开始选举,迫使刚选出的领导者立即退位。
这种情况出现的原因有很多,但我们看到许多学生犯了一小部分错误:
-
确保你** exactly **在图 2 规定的时间重置你的选举计时器。具体来说,你应该只在以下情况重置你的选举计时器:a) 你从当前领导者那里收到
AppendEntriesRPC(即,如果AppendEntries参数中的任期过时,你不应重置计时器);b) 你开始一次选举;或 c) 你授予投票给另一个对等体(说明对方日志比较新)。- 最后一种情况在不可靠网络中尤其重要,因为追随者很可能拥有不同的日志;在这些情况下,你通常最终只有少数服务器能够获得大多数服务器的投票。如果你在每次有人要求你投票给他们时都重置选举计时器,那么日志过时的服务器站出来竞选的可能性与日志更长的服务器相同。
- 实际上,因为拥有足够新的日志的服务器非常少,这些服务器不太可能能够在足够的平静中进行选举并当选。如果你遵循图 2 的规则,拥有更新日志的服务器不会被过时服务器的选举打断,因此更可能完成选举并成为领导者。
-
•遵循图 2 关于何时应开始选举的指示。特别要注意,如果你是一个候选人(即,你当前正在运行一次选举),但选举计时器触发,你应该开始另一次选举。这对于避免由于 RPC 延迟或丢失而导致系统停滞很重要。
-
•确保在处理传入 RPC之前遵循“服务器规则”中的第二条规则。第二条规则指出:
如果 RPC 请求或响应包含任期 T > currentTerm:设置 currentTerm = T,转换为追随者 (§5.1)
- •例如,如果你已经在当前任期投过票,而一个传入的
RequestVoteRPC 的任期比你高,你应该首先下台并采用他们的任期(从而重置votedFor),然后处理 RPC,这将导致你授予投票!
- •例如,如果你已经在当前任期投过票,而一个传入的
注:
1 重置选举定时器时刻:
- a) 您从当前领导者那里收到 AppendEntries RPC(即,如果 AppendEntries 参数中的任期已过时,您不应重置计时器);
- b) 您开始选举;
- c) 您向另一个对等节点授予投票(该对等节点拥有较新的log)。
2 candidate遇到选举超时:
如果节点是候选人,并且其选举超时(election timeout)过去,那么它应该立即开始一次新的选举(增加自己的任期 term,给自己投票,向其他节点发送新的 RequestVoteRPC)。
这大大增加了它在网络问题或临时拒绝情况下最终获得足够票数的机会,避免了系统卡在无休止的“发起-放弃”循环中。
深入解析 Raft 活锁(Livelocks):原因、场景与正确实践
活锁(Livelocks)是 Raft 系统中最棘手的活性(Liveness)问题之一。它表现为:所有节点都在“忙碌”执行协议操作(如发送 RPC、处理投票),但整体系统无法取得任何实质性进展(例如无法选出领导者,或领导者频繁下台导致无主状态)。本节将结合 Raft 协议的核心规则(尤其是图 2),详细解释活锁的常见场景、错误根源及正确解决方法。
一、活锁的本质:节点“忙而无功”
在 Raft 中,活锁的典型表现是:
- 无领导者当选:所有节点不断尝试成为候选人并发起选举,但因无法获得多数投票而始终无法当选;
- 领导者频繁下台:刚当选的领导者因其他节点发起的选举(即使对方日志更旧)被强制降级为跟随者,导致系统反复“震荡”。
活锁的根本原因是节点对选举规则的错误遵守,导致选举过程无法收敛。Raft 的选举机制依赖“多数派投票”和“日志完整性”的双重约束,任何对这两个约束的破坏都会导致活锁。
二、活锁的常见场景与错误根源
场景 1:错误重置选举计时器,导致过时日志节点干扰选举
Raft 的选举计时器(Election Timer)用于检测当前领导者是否失效(未发送心跳)。当计时器超时(未收到领导者的心跳),节点会转为候选人并发起选举。但许多学生错误地在以下情况重置计时器:
- 错误行为:每当收到其他节点的投票请求(
RequestVoteRPC)时,无论对方日志是否更新,都重置自己的选举计时器。 - 错误后果:
假设网络中存在多个过时日志的节点(日志长度短或任期低),它们会频繁向其他节点发送投票请求。每个收到请求的节点因重置计时器,会不断推迟选举(或提前发起新的选举),导致日志较新(更可能成为领导者)的节点无法获得足够时间收集多数投票。最终,系统陷入“过时节点不断竞争,日志新节点始终无法当选”的死循环。 - 正确规则(图 2 明确要求):
仅当以下三种情况之一发生时,才应重置选举计时器:- 收到当前领导者的
AppendEntriesRPC(且 RPC 中的任期未过时):领导者的心跳表明其仍存活,无需发起选举; - 自己发起选举(转为候选人):主动触发选举流程;
- 向其他节点授予投票(
RequestVote回复voteGranted=true):说明对方日志可能更优,需重新评估选举状态。
- 收到当前领导者的
场景 2:候选人状态下未及时发起新一轮选举
当节点作为候选人(Candidate)发起选举后,若选举计时器超时(未收到多数投票),图 2 要求立即发起新一轮选举(增加任期并重新请求投票)。但许多学生在此处犯错:
- 错误行为:计时器超时后,未立即发起新选举,而是等待一段时间或直接转为跟随者。
- 错误后果:
若因网络延迟(如 RPC 丢失)导致多数投票未及时到达,候选人会错误地认为“选举失败”并退出,导致系统长期无领导者。 - 正确规则(图 2 明确要求):
候选人状态的计时器超时后,必须立即增加任期(currentTerm += 1),重置投票状态(votedFor = self),并重新向所有节点发送RequestVoteRPC。这一机制确保候选人不会因临时网络问题放弃选举,最终通过多次尝试获得多数投票。
场景 3:处理 RPC 前未检查任期,导致“过时任期”干扰选举
Raft 的“服务器规则”第二条(图 2 右侧)明确要求:
如果 RPC 请求或响应包含任期
T > currentTerm:设置currentTerm = T,转换为追随者(§5.1)。
许多学生在处理 RequestVote 或 AppendEntries RPC 时,未优先检查这一条件:
- 错误行为:
假设当前节点的任期为T=3,收到一个来自任期T=5的RequestVoteRPC(对方可能因网络延迟未感知到自己的任期已更新)。若未更新自己的任期并转为追随者,而是直接处理投票请求(可能授予对方投票),会导致以下问题:- 对方(任期 5)可能因获得当前节点的投票而当选领导者,但当前节点的任期仍为 3,后续可能因“任期不一致”拒绝执行领导者的指令,破坏一致性。
- 正确规则(图 2 明确要求):
处理任何 RPC(包括RequestVote和AppendEntries)前,必须首先检查 RPC 中的任期T:- 若
T > currentTerm:立即更新currentTerm = T,转为追随者(role = Follower),并重置选举计时器; - 若
T < currentTerm:拒绝该 RPC(如RequestVote回复voteGranted=false); - 若
T == currentTerm:继续处理 RPC(如验证日志一致性)。
- 若
三、活锁的底层逻辑:Raft 的“多数派”与“日志完整性”约束
Raft 的选举机制依赖两个核心约束:
- 多数派投票:候选人需获得超过半数节点的投票才能当选;
- 日志完整性:领导者的日志必须是“最完整”的(即对于任意日志索引
i,领导者的日志条目log[i]的任期不小于其他节点的log[i])。
活锁的本质是这两个约束被破坏:
- 若错误重置选举计时器,过时日志节点可能通过频繁请求投票获得多数派(即使其日志不完整),导致日志新节点无法满足“多数派”条件;
- 若未及时处理任期更高的 RPC,过时任期的节点可能非法获得领导权,破坏“日志完整性”约束(如强制提交未同步的日志)。
四、总结:避免活锁的关键实践
要避免 Raft 活锁,必须严格遵守图 2 的规则,重点关注以下三点:
- 严格重置选举计时器:仅在收到当前领导者的心跳、自己发起选举或授予投票时重置,避免过时节点干扰;
- 及时发起新一轮选举:候选人状态下计时器超时后,立即增加任期并重新请求投票,避免因网络延迟导致选举停滞;
- 优先处理任期检查:处理任何 RPC 前,先检查任期是否高于当前任期,确保及时降级为追随者,维护日志完整性。
通过遵循这些规则,Raft 系统能够有效避免活锁,确保在网络分区、消息延迟等异常场景下仍能选出稳定的领导者,维持系统活性。
不正确的 RPC 处理程序
尽管图 2 明确说明了每个 RPC 处理程序应该做什么,但一些细微之处仍然容易被忽略。以下是我们一遍又一遍地看到的一些问题,你在实现时应该注意:
- •如果一个步骤说“回复 false”,这意味着你应该立即回复,而不是执行任何后续步骤。
- •如果你收到一个
prevLogIndex指向你日志末尾之后的AppendEntriesRPC,你应该以与你拥有该条目但任期不匹配相同的方式处理它(即,回复 false)。 - •即使领导者没有发送任何条目,也应该执行
AppendEntriesRPC 处理程序的检查 2。 - •
AppendEntries最后一步(#5)中的min是必要的,并且需要使用最后一个新条目的索引来计算。仅仅让在lastApplied和commitIndex之间应用日志内容的函数在到达日志末尾时停止是不够的。这是因为在领导者发送给你的条目(这些条目都与你日志中的条目匹配)之后,你的日志中可能有一些与领导者日志不同的条目。由于 #3 规定只有在有冲突条目时才截断日志,这些条目不会被移除,如果leaderCommit超出了领导者发送给你的条目,你可能会应用不正确的条目。 - •完全按照第 5.4 节所述实现“最新日志”检查非常重要。不要作弊只检查长度!
注:
-
1. "reply false" 的即时性
- 规则:若图 2 的某步骤明确要求 "reply false",必须立即回复失败,禁止继续执行后续步骤。
- 原因:后续步骤可能依赖于前置条件(如日志匹配),若条件已失败仍执行会导致状态不一致。
- 示例:
- 当追随者收到
AppendEntries时,若prevLogTerm不匹配(图 2 中 AppendEntries RPC 的步骤 2),必须立即返回false,不得执行日志追加或更新commitIndex。
- 当追随者收到
2.
prevLogIndex越界的处理- 规则:当
AppendEntries的prevLogIndex超出追随者日志范围时,必须视为此位置日志任期不匹配(即按图 2 步骤 2 返回false)。
3 空心跳仍需检查日志一致性
- 规则:即使心跳不包含新条目(
entries[]为空),也必须执行图 2 中AppendEntries的 步骤 2(prevLogTerm检查): 如果日志不包含其术语与日志LogTerm匹配的日志LogIndex中的条目,则回复false
- 原因:心跳不仅是保活机制,更是领导者对日志一致性的声明。不检查会导致已失效领导者维持权威
4
commitIndex更新必须用min-
规则:
AppendEntries的最后一步(图 2 步骤 5)更新commitIndex时必须计算:commitIndex = min(leaderCommit, index_of_last_new_entry)不能仅依赖当前日志长度。
未能遵循规则(Failure to follow The Rules)
虽然 Raft 论文非常明确地说明了如何实现每个 RPC 处理程序,但它也留下了一些规则和不变量的实现未指定。这些规则列在图 2 右侧的“服务器规则”块中。虽然其中一些相当不言自明,但也有一些需要非常仔细地设计你的应用程序,以免违反规则:
- •如果在执行过程中任何时候
commitIndex > lastApplied,你应该应用一个特定的日志条目。你不必立即执行(例如,在AppendEntriesRPC 处理程序中),但重要的是你要确保这个应用只由一个实体完成。具体来说,你需要要么有一个专用的“应用器”(applier),要么在这些应用周围加锁,这样其他例程不会也检测到需要应用条目并尝试应用。 - •确保你要么定期检查
commitIndex > lastApplied,要么在commitIndex更新后(即,在matchIndex更新后)检查。例如,如果你在向对等体发送AppendEntries的同时检查commitIndex,你可能必须等到下一个条目被附加到日志后,才能应用你刚刚发送并得到确认的条目。 - •如果领导者发送出一个
AppendEntriesRPC,并且被拒绝,但不是因为日志不一致(这只有在我们的任期已过时才会发生),那么你应该立即下台,并且不要更新nextIndex。如果你更新了,如果你立即重新当选,可能会与nextIndex的重置发生竞争。 - •领导者不允许将
commitIndex更新到前一个任期(或者,就此而言,未来的任期)的某个位置。因此,正如规则所说,你特别需要检查log[N].term == currentTerm。这是因为如果条目不是来自当前任期,Raft 领导者无法确定某个条目是否实际已提交(并且将来永远不会被更改)。论文中的图 8 说明了这一点。 - •一个常见的混淆来源是
nextIndex和matchIndex之间的区别。特别是,你可能会观察到matchIndex = nextIndex - 1,并干脆不实现matchIndex。这是不安全的。虽然nextIndex和matchIndex通常同时更新为相似的值(具体来说,nextIndex = matchIndex + 1),但两者的用途截然不同。nextIndex是对领导者与给定追随者共享的前缀的一种猜测。它通常非常乐观(我们共享所有内容),并且只在收到负面响应时向后移动。例如,当领导者刚当选时,nextIndex被设置为日志末尾的索引。在某种程度上,nextIndex用于性能——你只需要将这些内容发送给这个对等体。- •
matchIndex用于安全。它是领导者与给定追随者共享的日志前缀的保守度量。matchIndex绝不能设置得太高,因为这可能导致commitIndex向前移动得太远。这就是为什么matchIndex被初始化为 -1(即,我们不同意任何前缀),并且只在追随者肯定确认AppendEntriesRPC 时更新。
- •
注:
好的,我们来详细解释 Raft 图 2 中“服务器规则”(Rules for Servers)部分这些至关重要的实现细节。这些规则虽未在 RPC 处理流程中明确列出,但对保证整个系统的正确性和安全性至关重要。
1. 日志应用(Applying Entries)的安全性与并发控制
- 规则:只要
commitIndex > lastApplied,就必须将[lastApplied+1, commitIndex]区间的日志条目应用到状态机。应用操作不要求实时(例如,不必在AppendEntriesRPC 处理函数中同步进行),但必须保证应用操作的原子性,即同一时刻只有一个实体(线程/协程)在执行应用操作。 - 原因:应用日志条目会修改状态机的状态(例如,修改键值对)。如果多个执行流同时检测到有待应用的条目并并发执行,会导致状态机处于不一致的中间状态。
- 正确实现方案:
- 专用应用器线程(推荐):创建一个独立的、循环运行的 goroutine(或线程)。它持续检查
commitIndex > lastApplied的条件。一旦满足,它就获取锁,应用一批条目,更新lastApplied,然后释放锁。这是最清晰、最安全的方式。 - 加锁应用:在任何可能更新
commitIndex或需要应用条目的地方(如 RPC 处理函数、心跳例程),先获取一个互斥锁,然后检查并应用所有可应用的条目,最后释放锁。
- 专用应用器线程(推荐):创建一个独立的、循环运行的 goroutine(或线程)。它持续检查
- 例子:假设
commitIndex更新为 5,lastApplied是 3。专用应用器线程会检测到这个变化,然后获取锁,按顺序应用索引 4 和 5 的条目到状态机,然后将lastApplied设置为 5。在此期间,即使有新的 RPC 到来并更新了commitIndex到 6,应用器也会在下一次循环中处理它,而不会导致条目 4 和 5 被应用两次或应用过程被中断。
2. 检查应用时机的策略
- 规则:必须在
commitIndex更新后立即检查是否需要应用,或者定期检查。不能依赖于其他偶然事件。 - 原因:如果只在发送
AppendEntriesRPC 时顺带检查,可能会产生延迟。例如,领导者发送条目 X 并收到响应,commitIndex因此更新。但如果此时没有新的客户端请求来触发下一次 RPC 发送,已提交的条目 X 就会延迟应用,从而延迟对客户端的响应。 - 正确实现方案:
- 在每次更新
commitIndex后(例如,在AppendEntries响应处理逻辑中更新matchIndex并重新计算commitIndex之后),显式触发一次应用检查(例如,通知专用应用器线程)。 - 实现一个周期性的检查(例如,每 10ms 一次),作为安全网。
- 在每次更新
- 例子:领导者收到多数节点的响应,确认条目 10 已复制,于是将
commitIndex从 9 更新为 10。更新后,它应立即通知应用器线程。应用器线程随即应用条目 10,并可以唤醒正在等待该条目执行结果的客户端处理程序。
3. 处理因任期过时而拒绝的 RPC
- 规则:如果领导者发出的
AppendEntriesRPC 被拒绝,并且拒绝原因不是日志不一致(即图 2 中的步骤 2 失败),而是因为响应中的term > currentTerm(即规则 2),那么领导者必须立即下台转为追随者,并且绝不能更新nextIndex。 - 原因:这种拒绝意味着接收方发现了任期更高的领导者。原领导者已经失效。此时更新
nextIndex是基于过时身份做出的错误操作。如果原领导者很快又当选(在更高任期),它之前错误更新的nextIndex会与重置值产生竞争,导致日志复制混乱。 - 例子:
- 领导者 S1(任期 3)向 S2 发送
AppendEntries。 - 此时 S3 已当选为新领导者(任期 4),并通知了 S2。
- S2 收到 S1 的 RPC,发现任期 3 < 4,于是回复
false并在响应中包含term=4。 - S1 收到响应,首先根据规则 2,设置
currentTerm=4并转为追随者状态。 - 然后,作为追随者,它处理这个响应:发现任期不匹配,直接丢弃,不再执行任何领导者逻辑(如更新
nextIndex)。 - 如果 S1 错误地更新了
nextIndex,然后突然又当选为任期 5 的领导者,它就会基于错误的nextIndex发送日志,导致问题。
- 领导者 S1(任期 3)向 S2 发送
4. 领导者提交限制(Leader Committing Restriction)
- 规则:领导者绝对不允许将
commitIndex推进到其当前任期之前的旧任期条目。它只能提交自己任期内的条目(log[N].term == currentTerm),或者通过提交自己任期的条目来间接提交之前的条目。 - 原因:这是 Raft 安全性的核心。论文图 8 完美诠释了原因。一个来自旧任期的条目,即使已经被复制到多数节点,也可能被新领导人的日志覆盖。只有当前任期的条目被复制到多数节点,才能保证该条目(以及所有之前的条目)是真正提交的、不可更改的。
- 例子(参考图 8):
- 时刻 (a):S1 是任期 2 的领导者,将条目
(2, index=2)复制到 S1 和 S2(多数)。 - 时刻 (b):S1 崩溃,S5 当选为任期 3 的领导者(获得 S3, S4, S5 的投票),并收到一个新请求,添加了条目
(3, index=2)。注意:S5 覆盖了 S1 在索引 2 的条目! - 时刻 (c):S5 崩溃,S1 重启并当选为任期 4 的领导者(日志最完整)。
- 问题:如果 S1 在任期 4 试图直接提交旧任期 2 的条目(索引 2),它将把
commitIndex设为 2。 - 后果:S1 随后将条目
(2, index=2)应用到状态机并回复客户端。但这个条目已经被 S5 的条目(3, index=2)覆盖了,并未真正持久化! 这导致了状态机不一致。 - 正确做法:S1 必须先复制一条自己任期(任期 4)的新条目到索引 3。当这条新条目被多数节点复制时,
commitIndex可以被推进到 3。此时,索引 2 的条目也被间接提交了,因为它是索引 3 条目的前驱。这才是安全的。
- 时刻 (a):S1 是任期 2 的领导者,将条目
5. nextIndex与 matchIndex的根本区别
这是一个非常关键的概念,其区别如下表所示:
| 特性 | nextIndex(下一个索引) |
matchIndex(匹配索引) |
|---|---|---|
| 目的 | 性能优化:减少不必要的数据传输。 | 安全保证:准确计算提交索引。 |
| 语义 | 乐观猜测:领导者认为该追随者接下来需要的日志索引。 | 保守确认:领导者确切知道的、与该追随者一致的最高日志索引。 |
| 初始化 | leader.lastLogIndex + 1(认为追随者缺少所有日志)。 |
-1(或 0),表示无已知匹配。 |
| 更新时机 | 后退:在收到追随者的否定响应(日志不一致)时。 | 前进:仅在收到追随者对 AppendEntries的成功响应时。 |
| 更新方式 | 通常被设置为一个更小的值(回溯)。 | 被设置为一个精确值(prevLogIndex + len(entries[]))。 |
| 风险 | 可以设置得过高(乐观),这没关系,下次 RPC 会失败并修正它。 | 绝不能设置得过高,否则会导致 commitIndex错误推进,破坏安全性。 |
- 例子:
- 领导者刚当选时,对所有追随者:
nextIndex = 5(假设自身日志最后索引是 4),matchIndex = -1。 - 领导者向 S2 发送
AppendEntries (prevLogIndex=4, ...)。S2 只有 3 条日志,回复失败。 - 领导者降低
nextIndex[S2]为 4(然后会尝试prevLogIndex=3)。 - 领导者再次发送
AppendEntries (prevLogIndex=3, ...)。这次 S2 的日志匹配,回复成功。 - 此时,领导者更新
matchIndex[S2] = 3 + len(entries) = 4。这是一个安全、确切的知识:S2 的日志在索引 4 及之前与领导者一致。 - 领导者现在可以用所有
matchIndex来安全地计算commitIndex。如果只依赖nextIndex(nextIndex-1),若在收到响应后nextIndex又被其他事件修改,计算就会出错。
- 领导者刚当选时,对所有追随者:
总结:nextIndex是用于优化的工作变量,可以频繁调整;而 matchIndex是用于安全性的真相来源,必须准确无误地更新。
任期混淆(Term confusion)
任期混淆是指服务器被来自旧任期的 RPC 搞糊涂。通常,在接收 RPC 时这不是问题,因为图 2 中的规则确切地说明了当你看到旧任期时应该做什么。然而,图 2 通常不讨论当你收到旧的 RPC 回复时应该做什么。根据经验,我们发现迄今为止最简单的方法是首先记录回复中的任期(它可能比你当前的任期高),然后将当前任期与你原始 RPC 中发送的任期进行比较。如果两者不同,则丢弃回复并返回。只有两者相同时,你才应继续处理回复。通过一些巧妙的协议推理,这里可能还有进一步的优化空间,但这种方法似乎很有效。不这样做会导致漫长、曲折的血、汗、泪和绝望之路。
一个相关但不完全相同的问题是假设你的状态在你发送 RPC 和收到回复之间没有改变。一个很好的例子是在收到 RPC 响应时设置 matchIndex = nextIndex - 1或 matchIndex = len(log)。这是不安全的,因为这两个值自你发送 RPC 以来可能已经更新。相反,正确的做法是将 matchIndex更新为你最初在 RPC 参数中发送的 prevLogIndex + len(entries[])。
注:
问题本质:网络延迟导致的过时 RPC
在分布式系统中,RPC 请求和响应在网络中可能被严重延迟。当节点收到响应时,集群的状态(如任期、节点角色)可能已发生本质变化。忽略这种变化会破坏协议一致性。
1. 老任期响应的处理:最简安全策略
危险场景
-
•
Leader A 在
Term=3时发送AppendEntries请求。 -
•
请求在网络中延迟,期间集群选出新 Leader B (
Term=4),A 退化为 Follower。 -
•
现在 A(降级后)突然收到
Term=3的响应。
错误处理
若 A 仍按 Term=3的上下文处理此响应:
-
•
可能更新已失效的
nextIndex/matchIndex。 -
•
干扰新 Leader B 的日志复制。
正确做法(必须严格执行)
func (r *Raft) handleAppendEntriesReply(reply AppendEntriesReply) {
r.mutex.Lock()
defer r.mutex.Unlock()
// 关键检查:响应是否来自当前上下文的同任期RPC?
if reply.Term != r.currentTerm { // <-- 响应中的任期 != 当前任期?
return // 丢弃过期响应!
}
// 仅当任期匹配时,继续处理响应(更新nextIndex等)
...
}
原理:每个 RPC 绑定发送时的任期。响应到达时,若当前任期已变更,说明此响应属于已废弃的集群状态,必须丢弃。
2 核心问题:状态变化的异步性
- 背景:在 Raft 中,领导者发送 RPC 请求与收到响应是异步操作(可能存在延迟)。
- 错误假设:在处理 RPC 响应时,假设本地状态(如日志长度
len(log)或nextIndex)自发送 RPC 后未发生变化。 - 风险:在等待响应期间,领导者的本地状态可能已被更新(如收到新请求追加日志),导致用错误的索引更新关键状态(如
matchIndex)。
示例场景说明
假设条件:
- 领导者初始日志:
[1:10, 2:20](索引:任期) nextIndex追随者 F1 初始值:3(领导者认为 F1 需要从索引 3 同步)
leader时序流程:
-
T0: 领导者向 F1 发送 AppendEntries RPC
args = { prevLogIndex: 2, // 最后匹配索引(假设存在) prevLogTerm: 20, // 索引2的任期 entries: [3:30], // 要同步的新条目 leaderCommit: ... }-
•
此时日志长度 = 3(含新条目 3:30)
-
-
T1 (等待响应期间): 新客户端请求到达
-
•
领导者追加新条目:
4:40 -
•
日志更新为:
[1:10, 2:20, 3:30, 4:40] -
•
日志长度变为 4
-
-
T2: 收到 F1 对 T0 RPC 的成功响应
-
•
❌ 错误做法:
// 用当前状态更新(日志长度=4) matchIndex[F1] = len(log) // = 4 (错误!)结果:错误认为 F1 已同步到索引4(实际只到索引3)。
-
•
✅ 正确做法:
// 用原始RPC参数计算 matchIndex[F1] = args.prevLogIndex + len(args.entries) // 2 + 1 = 3结果:准确记录 F1 匹配到索引3。
-
关于优化的一点说明
Raft 论文包含一些值得关注的可选功能。在 6.824 中,我们要求学生实现其中两个:日志压缩(第 7 节)和加速日志回溯(第 8 页左上角)。前者对于避免日志无限增长是必要的,后者对于快速使过时的追随者更新非常有用。
这些功能不是“核心 Raft”的一部分,因此在论文中没有像主共识协议那样受到太多关注。日志压缩覆盖得相当彻底(在图 13 中),但遗漏了一些如果你读得太随意可能会忽略的设计细节:
- •对应用程序状态进行快照时,你需要确保应用程序状态对应于 Raft 日志中某个已知索引之后的状态。这意味着应用程序要么需要通知 Raft 快照对应的索引,要么 Raft 需要延迟应用额外的日志条目,直到快照完成。
- •文本没有讨论服务器崩溃并恢复时的恢复协议,现在涉及快照。特别是,如果 Raft 状态和快照是分开提交的,服务器可能会在持久化快照和持久化更新的 Raft 状态之间崩溃。这是一个问题,因为图 13 中的步骤 7 规定必须丢弃快照覆盖的 Raft 日志。
- •如果服务器重新启动时读取了更新的快照,但过时的日志,它最终可能会应用一些已经包含在快照中的日志条目。这是因为
commitIndex和lastApplied没有被持久化,所以 Raft 不知道那些日志条目已经被应用。对此的修复方法是向 Raft 引入一个持久状态,记录 Raft 持久化日志中第一个条目对应的“真实”索引。然后可以将其与加载的快照的lastIncludedIndex进行比较,以确定要丢弃的日志头部的哪些元素。
- •如果服务器重新启动时读取了更新的快照,但过时的日志,它最终可能会应用一些已经包含在快照中的日志条目。这是因为
- •加速日志回溯优化非常不明确,可能是因为作者认为它对大多数部署来说不是必需的。从文本中不清楚客户端返回的冲突索引和任期应如何由领导者用来确定使用什么
nextIndex。我们相信作者可能希望你遵循的协议是:- •如果追随者的日志中没有
prevLogIndex,它应该返回conflictIndex = len(log)和conflictTerm = None。 - •如果追随者的日志中有
prevLogIndex,但任期不匹配,它应该返回conflictTerm = log[prevLogIndex].Term,然后搜索其日志中第一个条目任期等于conflictTerm的索引。 - •收到冲突响应后,领导者应首先在其日志中搜索
conflictTerm。如果它在日志中找到具有该任期的条目,它应将nextIndex设置为其日志中该任期最后一个条目索引之后的一个。 - •如果它没有找到具有该任期的条目,它应设置
nextIndex = conflictIndex。 - •一个折中的解决方案是只使用
conflictIndex(而忽略conflictTerm),这简化了实现,但有时领导者最终会向追随者发送比严格必要更多的日志条目以使其更新。
- •如果追随者的日志中没有
基于 Raft 的应用程序
在 Raft 之上构建服务时(例如第二个 6.824 Raft 实验中的键/值存储),服务与 Raft 日志之间的交互可能很难正确处理。本节详细介绍了开发过程中你可能会发现有用的某些方面。
应用客户端操作
你可能会困惑如何用一个复制的日志来实现一个应用程序。你可能会开始时让你的服务在收到客户端请求时,将该请求发送给领导者,等待 Raft 应用某些内容,执行客户端请求的操作,然后返回给客户端。虽然这在单客户端系统中没问题,但它不适用于并发客户端。
相反,服务应构建为一个状态机,客户端操作使机器从一种状态转换到另一种状态。你应该在某个地方有一个循环,一次接受一个客户端操作(在所有服务器上顺序相同——这就是 Raft 的用武之地),并按顺序将每个操作应用到状态机。这个循环应该是你代码中唯一触及应用程序状态的部分(在 6.824 中是键/值映射)。这意味着你面向客户端的 RPC 方法应该简单地将客户端的操作提交给 Raft,然后等待这个“应用器循环”应用该操作。只有当客户端的命令出现时,它才被执行,并读出任何返回值。注意,这包括读请求!
这引出了另一个问题:你如何知道客户端操作何时完成?在没有故障的情况下,这很简单——你只需等待你放入日志的东西回来(即,被传递给 apply())。当这种情况发生时,你将结果返回给客户端。然而,如果有故障会发生什么?例如,当客户端最初联系你时,你可能是领导者,但此后其他人当选,并且你放入日志的客户端请求已被丢弃。显然你需要让客户端重试,但你如何知道何时告诉他们错误?
解决这个问题的一个简单方法是记录客户端操作插入时在 Raft 日志中的位置。一旦该索引处的操作被发送到 apply(),你就可以根据该索引出现的操作是否确实是你放入的操作来判断客户端的操作是否成功。如果不是,则发生了故障,可以向客户端返回错误。
重复检测
一旦你有客户端在遇到错误时重试操作,你就需要某种重复检测方案——如果客户端向你的服务器发送 APPEND,没有收到回复,并重新发送给下一个服务器,你的 apply()函数需要确保 APPEND 不会被执行两次。为此,你需要为每个客户端请求提供某种唯一标识符,以便你能够识别过去是否已经看到,更重要的是,应用过某个特定操作。此外,这个状态需要成为你状态机的一部分,以便你所有的 Raft 服务器消除相同的重复。
分配此类标识符的方法有很多。一种简单且相当高效的方法是给每个客户端一个唯一标识符,然后让他们用单调递增的序列号标记每个请求。如果客户端重新发送请求,它会重用相同的序列号。你的服务器跟踪每个客户端看到的最新序列号,并简单地忽略任何已经见过的操作。
棘手的极端情况(Hairy corner-cases)
如果你的实现遵循上面给出的大纲,你至少可能会遇到两个微妙的问题,如果没有一些认真的调试,可能很难识别。为了节省你的时间,它们如下:
-
重新出现的索引(Re-appearing indices):假设你的 Raft 库有某种
Start()方法,它接受一个命令,并返回该命令放置在日志中的索引(这样你就知道何时返回给客户端,如上所述)。你可能会假设你永远不会看到Start()两次返回相同的索引,或者至少,如果你看到相同的索引再次出现,第一次返回该索引的命令一定失败了。事实证明,即使没有服务器崩溃,这两件事都不是真的。- •考虑一个有五台服务器 S1 到 S5 的场景。最初,S1 是领导者,其日志为空。
- •两个客户端操作(C1 和 C2)到达 S1。
- •
Start()为 C1 返回 1,为 C2 返回 2。 - S1 向 S2 发送包含 C1 和 C2 的
AppendEntries,但其所有其他消息都丢失了。 - •S3 作为候选人站出来。
- •S1 和 S2 不会投票给 S3,但 S3、S4 和 S5 都会,所以 S3 成为领导者。
- •另一个客户端请求 C3 到达 S3。
- •S3 调用
Start()(返回 1)。 - •S3 向 S1 发送
AppendEntries,S1 从其日志中丢弃 C1 和 C2,并添加 C3。 - •S3 在向任何其他服务器发送
AppendEntries之前失败。 - •S1 站出来,因为其日志是最新的,它当选为领导者。
- •另一个客户端请求 C4 到达 S1。
- •S1 调用
Start(),返回 2(这也是Start(C2)返回的值)。 - •S1 的所有
AppendEntries都被丢弃,S2 站出来。 - •S1 和 S3 不会投票给 S2,但 S2、S4 和 S5 都会,所以 S2 成为领导者。
- •客户端请求 C5 到达 S2。
- •S2 调用
Start(),返回 3。 - •S2 成功向所有服务器发送
AppendEntries,S2 通过在下一个心跳中包含更新的leaderCommit = 3报告给服务器。 - •由于 S2 的日志是 [C1 C2 C5],这意味着在索引 2 处提交(并在所有服务器,包括 S1 应用)的条目是 C2。尽管 C4 是最后一个在 S1 返回索引 2 的客户端操作。
- •考虑一个有五台服务器 S1 到 S5 的场景。最初,S1 是领导者,其日志为空。
-
四向死锁(The four-way deadlock):发现这个问题的全部功劳归于 Steven Allen,另一位 6.824 助教。他发现了以下 nasty 的四向死锁,在 Raft 之上构建应用程序时很容易陷入。
-
•
你的 Raft 代码,无论其结构如何,可能都有一个类似
Start()的函数,允许应用程序向 Raft 日志添加新命令。它可能还有一个循环,当commitIndex更新时,为lastApplied和commitIndex之间的每个元素调用应用程序的apply()。这些例程可能都持有某个锁a。在你的基于 Raft 的应用程序中,你可能在 RPC 处理程序中的某个地方调用 Raft 的Start()函数,并且在其他地方有一些代码在 Raft 应用新日志条目时被通知。由于这两者需要通信(即,RPC 方法需要知道它放入日志的操作何时完成),它们可能都持有某个锁b。 -
•
在 Go 中,这四段代码可能看起来像这样:
func (a *App) RPC(args interface{}, reply interface{}) { // ... a.mutex.Lock() i := a.raft.Start(args) // update some data structure so that apply knows to poke us later a.mutex.Unlock() // wait for apply to poke us return } func (r *Raft) Start(cmd interface{}) int { r.mutex.Lock() // do things to start agreement on this new command // store index in the log where cmd was placed r.mutex.Unlock() return index } func (a *App) apply(index int, cmd interface{}) { a.mutex.Lock() switch cmd := cmd.(type) { case GetArgs: // do the get // see who was listening for this index // poke them all with the result of the operation // ... } a.mutex.Unlock() } func (r *Raft) AppendEntries(...) { // ... r.mutex.Lock() // ... for r.lastApplied < r.commitIndex { r.lastApplied++ r.app.apply(r.lastApplied, r.log[r.lastApplied]) } // ... r.mutex.Unlock() } -
•现在考虑如果系统处于以下状态:
- •
App.RPC刚刚获取了a.mutex并调用了Raft.Start。 - •Raft.Start
正在等待r.mutex`。 - •Raft.AppendEntries
持有r.mutex,并刚刚调用了App.apply`。
- •
-
•现在我们有一个死锁,因为:
- •Raft.AppendEntries
在App.apply`返回之前不会释放锁。 - •App.apply
在获取a.mutex`之前无法返回。 - •a.mutex
在App.RPC`返回之前不会被释放。 App.RPC在Raft.Start返回之前不会返回。Raft.Start在获取r.mutex之前无法返回。Raft.Start必须等待Raft.AppendEntries。
- •Raft.AppendEntries
-
•有几种方法可以解决这个问题。最简单的方法是在
App.RPC中调用a.raft.Start之后再获取a.mutex。然而,这意味着App.apply可能会在App.RPC有机会记录它希望被通知的事实之前,就被调用处理App.RPC刚调用Raft.Start的操作。另一种可能产生更简洁设计的方案是让一个单独的、专用的线程从 Raft 调用r.app.apply。这个线程可以在每次commitIndex更新时被通知,然后就不需要为了应用而持有锁,从而打破死锁。
-
好的,这是MIT 6.5840分布式系统课程Lab 3: Raft实验指导的中文翻译,代码部分保留原样:
介绍 (Introduction)
这是构建容错键值存储系统系列实验中的第一个实验。在本实验中,你将实现 Raft,一个复制状态机协议。在下一个实验中,你将在 Raft 之上构建一个键值服务。然后,你将把你的服务“分片”(shard)到多个复制的状态机上以获得更高的性能。
一个复制的服务通过将其状态(即数据)的完整副本存储在多个副本服务器上来实现容错。复制允许服务即使在其部分服务器发生故障(崩溃或网络中断/不稳定)时也能继续运行。挑战在于故障可能导致副本持有不同的数据副本。
Raft 将客户端请求组织成一个称为日志(log)的序列,并确保所有副本服务器看到相同的日志。每个副本按日志顺序执行客户端请求,将其应用到服务状态的本地副本上。由于所有存活的副本看到相同的日志内容,它们都以相同的顺序执行相同的请求,从而继续保持相同的服务状态。如果一个服务器发生故障但稍后恢复,Raft 会负责使其日志更新到最新状态。只要至少多数(majority)服务器存活并且可以相互通信,Raft 就会继续运行。如果没有这样的多数派,Raft 将无法取得进展,但一旦多数派可以再次通信,它将从中断处继续运行。
在本实验中,你将 Raft 实现为一个带有相关方法的 Go 对象类型,旨在作为更大服务中的一个模块使用。一组 Raft 实例通过 RPC 相互通信以维护复制的日志。你的 Raft 接口将支持一个无限序列的编号命令,也称为日志条目(log entries)。条目使用索引号编号。具有给定索引的日志条目最终将被提交(committed)。此时,你的 Raft 应将日志条目发送给更大的服务以执行它。
你应该遵循扩展 Raft 论文中的设计,特别注意图 2(Figure 2)。你将实现论文中的大部分内容,包括保存持久状态(persistent state)以及在节点故障后重启时读取它。你将不实现集群成员变更(第 6 节)。
本实验分为四个部分提交。你必须在相应的截止日期前提交每个部分。
开始 (Getting Started)
执行 git pull以获取最新的实验软件。
如果你已经完成了 Lab 1,那么你已经有了实验源代码的副本。如果没有,你可以在 Lab 1 的说明中找到通过 git 获取源代码的说明。
我们为你提供了骨架代码 src/raft1/raft.go。我们还提供了一组测试,你应该使用这些测试来驱动你的实现工作,并且我们将使用它们来给你的提交评分。测试位于 src/raft1/raft_test.go。
当我们给你的提交评分时,我们将不带 -race标志运行测试。但是,在开发解决方案时,你应该通过使用 -race标志运行测试来确保你的代码没有竞态条件(races)。
要开始运行,请执行以下命令。别忘了 git pull来获取最新的软件。
$ cd ~/6.5840
$ git pull
...
$ cd src/raft1
$ go test
Test (3A): initial election (reliable network)...
Fatal: expected one leader, got none
--- FAIL: TestInitialElection3A (4.90s)
Test (3A): election after network failure (reliable network)...
Fatal: expected one leader, got none
--- FAIL: TestReElection3A (5.05s)
...
$
代码 (The code)
通过向 raft/raft.go添加代码来实现 Raft。在该文件中,你将找到骨架代码,以及如何发送和接收 RPC 的示例。
你的实现必须支持以下接口,测试程序以及(最终)你的键值服务器将使用该接口。你可以在 raft.go的注释中找到更多细节。
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester).
type ApplyMsg
服务调用 Make(peers,me,…)来创建一个 Raft 节点(peer)。peers参数是 Raft 节点(包括自身)的网络标识符数组,用于 RPC。me参数是该节点在 peers数组中的索引。Start(command)请求 Raft 开始处理以将命令附加到复制的日志中。Start()应该立即返回,而不等待日志附加完成。服务期望你的实现在每个新提交的日志条目时,向 Make()的 applyCh通道参数发送一个 ApplyMsg。
raft.go包含发送 RPC (sendRequestVote()) 和处理传入 RPC (RequestVote()) 的示例代码。你的 Raft 节点应使用 labrpcGo 包(源代码在 src/labrpc)交换 RPC。测试程序可以指示 labrpc延迟 RPC、重新排序 RPC 和丢弃 RPC 以模拟各种网络故障。虽然你可以临时修改 labrpc,但请确保你的 Raft 能在原始的 labrpc下工作,因为我们将使用它来测试和评分你的实验。你的 Raft 实例只能通过 RPC 进行交互;例如,不允许使用共享的 Go 变量或文件进行通信。
后续实验建立在本实验之上,因此给自己足够的时间编写健壮的代码非常重要。
第 3A 部分:领导者选举 (中等难度) (Part 3A: leader election (moderate))
实现 Raft 领导者选举和心跳(不带日志条目的 AppendEntries RPC)。Part 3A 的目标是选出一个单一的领导者,如果没有故障,领导者保持领导地位,如果旧领导者失败或与旧领导者之间的数据包丢失,则新领导者接管。运行 go test -run 3A来测试你的 3A 代码。
你不能直接运行你的 Raft 实现;而是应该通过测试器来运行,即 go test -run 3A。
遵循论文中的图 2。此时,你需要关心发送和接收 RequestVote RPC、与选举相关的服务器规则,以及与领导者选举相关的状态。
将图 2 中领导者选举的状态添加到 raft.go中的 Raft 结构体中。你还需要定义一个结构体来保存每个日志条目的信息。
填写 RequestVoteArgs和 RequestVoteReply结构体。修改 Make()函数,创建一个后台 goroutine,当一段时间没有听到其他对等体的消息时,定期发送 RequestVote RPC 来启动领导者选举。实现 RequestVote()RPC 处理程序,以便服务器相互投票。
为了实现心跳,定义一个 AppendEntries RPC 结构体(虽然你可能不需要所有参数),并让领导者定期发送它们。编写一个 AppendEntriesRPC 处理方法。
测试器要求领导者发送心跳 RPC 的频率不超过每秒十次。
测试器要求你的 Raft 在旧领导者失败后的五秒内选出新领导者(如果大多数对等体仍然可以通信)。
论文的第 5.2 节提到了选举超时时间在 150 到 300 毫秒之间。这样的范围只有在领导者发送心跳的频率远高于每 150 毫秒一次(例如,每 10 毫秒一次)时才有意义。因为测试器限制你每秒最多发送十次心跳,所以你必须使用比论文中 150 到 300 毫秒更大的选举超时时间,但也不能太大,否则你可能无法在五秒内选出领导者。
你可能会发现 Go 的 rand包有用。
你需要编写代码来定期或延迟执行操作。最简单的方法是创建一个 goroutine,其中包含一个调用 time.Sleep()的循环;参考 Make()中为此目的创建的 ticker()goroutine。不要使用 Go 的 time.Timer或 time.Ticker,这些难以正确使用。
如果你的代码在通过测试时遇到问题,请再次阅读论文的图 2;领导者选举的完整逻辑分布在图的多个部分。
不要忘记实现 GetState()。
测试器在永久关闭一个实例时会调用你的 Raft 的 rf.Kill()。你可以使用 rf.killed()来检查 Kill()是否被调用。你可能希望在所有循环中都这样做,以避免死掉的 Raft 实例打印令人困惑的消息。
Go RPC 只发送名称以大写字母开头的结构体字段。子结构也必须具有大写的字段名(例如,数组中日志记录的字段)。labgob包会警告你这一点;不要忽略这些警告。
本实验最具挑战性的部分可能是调试。花点时间使你的实现易于调试。参考指南页面获取调试技巧。
如果你未能通过测试,测试器会生成一个文件,可视化时间线,其中标记了事件,包括网络分区、崩溃的服务器和执行的检查。这是可视化的一个例子。此外,你可以通过编写例如 tester.Annotate("Server 0", "short description", "details")来添加自己的注释。这是我们今年添加的新功能,因此如果你对可视化器有任何反馈(例如,错误报告、你认为可能有用的注释 API、你希望可视化器显示的信息等),请告诉我们!
确保在提交第 3A 部分之前通过 3A 测试,这样你会看到类似这样的输出:
$ go test -run 3A
Test (3A): initial election (reliable network)...
... Passed -- 3.6 3 106 0
Test (3A): election after network failure (reliable network)...
... Passed -- 7.6 3 304 0
Test (3A): multiple elections (reliable network)...
... Passed -- 8.4 7 954 0
PASS
ok 6.5840/raft1 19.834s
$
每个 "Passed" 行包含五个数字;这些是测试花费的时间(秒)、Raft 节点数、测试期间发送的 RPC 数量、RPC 消息中的总字节数以及 Raft 报告已提交的日志条目数。你的数字会与这里显示的不同。如果你愿意,可以忽略这些数字,但它们可能有助于你检查你的实现发送的 RPC 数量。对于所有实验 3、4 和 5,如果所有测试(go test)花费超过 600 秒,或者任何单个测试花费超过 120 秒,评分脚本将使你的解决方案失败。
当我们给你的提交评分时,我们将不带 -race标志运行测试。但是,你应该确保你的代码在使用 -race标志时能持续通过测试。
第 3B 部分:日志 (困难) (Part 3B: log (hard))
实现领导者和跟随者代码以附加新的日志条目,以便 go test -run 3B测试通过。
运行 git pull以获取最新的实验软件。
Raft 日志是 1 索引的(1-indexed),但我们建议你将其视为 0 索引的(0-indexed),并以一个 term 为 0 的条目(索引=0)开始。这允许第一个 AppendEntriesRPC 包含 0 作为 PrevLogIndex,并且是日志中的一个有效索引。
你的第一个目标应该是通过 TestBasicAgree3B()。首先实现 Start(),然后编写代码通过 AppendEntriesRPC 发送和接收新的日志条目,遵循图 2。在每个节点上,将每个新提交的条目发送到 applyCh。
你将需要实现选举限制(论文第 5.4.1 节)。
你的代码可能有循环重复检查某些事件。不要让这些循环连续执行而不暂停,因为这会减慢你的实现速度,导致测试失败。使用 Go 的条件变量(condition variables),或者在每次循环迭代中插入 time.Sleep(10 * time.Millisecond)。
为了未来的实验,请编写(或重写)干净清晰的代码。有关想法,请重新访问我们的指导页面(Guidance page),其中包含有关如何开发和调试代码的技巧。
如果你未能通过测试,请查看 raft_test.go并从那里追踪测试代码以了解正在测试的内容。
即将进行的实验的测试可能会因为你的代码运行太慢而失败。你可以使用 time命令检查你的解决方案使用了多少实际时间和 CPU 时间。以下是典型输出:
$ time go test -run 3B
Test (3B): basic agreement (reliable network)...
... Passed -- 1.3 3 18 0
Test (3B): RPC byte count (reliable network)...
... Passed -- 2.8 3 56 0
Test (3B): test progressive failure of followers (reliable network)...
... Passed -- 5.3 3 188 0
Test (3B): test failure of leaders (reliable network)...
... Passed -- 6.4 3 378 0
Test (3B): agreement after follower reconnects (reliable network)...
... Passed -- 5.9 3 176 0
Test (3B): no agreement if too many followers disconnect (reliable network)...
... Passed -- 4.3 5 288 0
Test (3B): concurrent Start()s (reliable network)...
... Passed -- 1.5 3 32 0
Test (3B): rejoin of partitioned leader (reliable network)...
... Passed -- 5.3 3 216 0
Test (3B): leader backs up quickly over incorrect follower logs (reliable network)...
... Passed -- 12.1 5 1528 0
Test (3B): RPC counts aren't too high (reliable network)...
... Passed -- 3.1 3 106 0
PASS
ok 6.5840/raft1 48.353s
go test -run 3B 1.37s user 0.74s system 4% cpu 48.865 total
$
"ok 6.5840/raft 35.557s" 表示 Go 测量到 3B 测试花费了 35.557 秒的实际(挂钟)时间。"user 0m2.556s" 表示代码消耗了 2.556 秒的 CPU 时间,即实际执行指令所花费的时间(而不是等待或睡眠)。如果你的解决方案在 3B 测试中使用了远超过一分钟的实际时间,或者远超过 5 秒的 CPU 时间,你以后可能会遇到麻烦。寻找花费在睡眠或等待 RPC 超时上的时间、不睡眠或不等待条件或通道消息而运行的循环,或者发送的大量 RPC。
第 3C 部分:持久化 (困难) (Part 3C: persistence (hard))
如果基于 Raft 的服务器重新启动,它应该从中断处恢复服务。这要求 Raft 保留在重启后能够存活的持久状态(persistent state)。论文图 2 提到了哪些状态应该是持久的。
一个真实的实现会在每次 Raft 的持久状态发生变化时将其写入磁盘,并在重启后从磁盘读取状态。你的实现不会使用磁盘;相反,它将从一个 Persister对象(参见 persister.go)保存和恢复持久状态。调用 Raft.Make()的人提供一个 Persister,该对象最初保存 Raft 最近持久化的状态(如果有)。Raft 应该从该 Persister初始化其状态,并且应该在每次状态更改时使用它来保存其持久状态。使用 Persister的 ReadRaftState()和 Save()方法。
通过在 raft.go中添加代码来保存和恢复持久状态,完成 persist()和 readPersist()函数。你需要将状态编码(或“序列化”)为一个字节数组,以便将其传递给 Persister。使用 labgob编码器;请参阅 persist()和 readPersist()中的注释。labgob类似于 Go 的 gob编码器,但如果你尝试编码具有小写字段名的结构,它会打印错误消息。目前,将 nil作为第二个参数传递给 persister.Save()。在你的实现更改持久状态的点插入对 persist()的调用。完成此操作后,如果你的实现的其余部分是正确的,你应该通过所有 3C 测试。
你可能需要一次备份多个条目的 nextIndex的优化。查看扩展 Raft 论文第 7 页底部和第 8 页顶部(由灰线标记)。论文对细节描述模糊;你需要填补空白。一种可能性是让拒绝消息包含:
XTerm: 冲突条目的任期(如果有)
XIndex: 具有该任期的第一个条目的索引(如果有)
XLen: 日志长度
然后领导者的逻辑可以是这样的:
情况 1:领导者没有 XTerm:
nextIndex = XIndex
情况 2:领导者有 XTerm:
nextIndex = (领导者最后一个具有 XTerm 的条目的索引) + 1
情况 3:跟随者的日志太短:
nextIndex = XLen
其他一些提示:
运行 git pull以获取最新的实验软件。
3C 测试比 3A 或 3B 的测试要求更高,失败可能是由 3A 或 3B 代码中的问题引起的。
你的代码应该通过所有 3C 测试(如下所示),以及 3A 和 3B 测试。
$ go test -run 3C
Test (3C): basic persistence (reliable network)...
... Passed -- 6.6 3 110 0
Test (3C): more persistence (reliable network)...
... Passed -- 15.6 5 428 0
Test (3C): partitioned leader and one follower crash, leader restarts (reliable network)...
... Passed -- 3.1 3 50 0
Test (3C): Figure 8 (reliable network)...
... Passed -- 33.7 5 654 0
Test (3C): unreliable agreement (unreliable network)...
... Passed -- 2.1 5 1076 0
Test (3C): Figure 8 (unreliable) (unreliable network)...
... Passed -- 31.9 5 4400 0
Test (3C): churn (reliable network)...
... Passed -- 16.8 5 4896 0
Test (3C): unreliable churn (unreliable network)...
... Passed -- 16.1 5 7204 0
PASS
ok 6.5840/raft1 126.054s
$
在提交之前多次运行测试并检查每次运行都打印 PASS 是一个好主意。
$ for i in {0..10}; do go test; done
第 3D 部分:日志压缩 (困难) (Part 3D: log compaction (hard))
就目前情况而言,重新启动的服务器会重放完整的 Raft 日志以恢复其状态。然而,对于一个长期运行的服务来说,永远记住完整的 Raft 日志是不切实际的。相反,你将修改 Raft 以与服务协作,这些服务会不时地持久存储其状态的“快照”(snapshot),此时 Raft 会丢弃快照之前的日志条目。结果是更少的持久数据和更快的重启。然而,现在有可能一个跟随者落后太多,以至于领导者已经丢弃了它赶上所需的日志条目;领导者必须发送快照以及从快照时间点开始的日志。扩展 Raft 论文的第 7 节概述了该方案;你需要设计细节。
你的 Raft 必须提供以下函数,服务可以调用它并传递其状态的序列化快照:
Snapshot(index int, snapshot []byte)
在 Lab 3D 中,测试程序会定期调用 Snapshot()。在 Lab 4 中,你将编写一个调用 Snapshot()的键值服务器;快照将包含完整的键/值对表。服务层在每个节点(不仅仅是领导者)上调用 Snapshot()。
index参数表示快照中反映的最高日志条目。Raft 应丢弃该点之前的日志条目。你需要修改你的 Raft 代码,使其在仅存储日志尾部的情况下运行。
你需要实现论文中讨论的 InstallSnapshotRPC,它允许 Raft 领导者告诉落后的 Raft 节点用快照替换其状态。你可能需要思考 InstallSnapshot应如何与图 2 中的状态和规则交互。
当一个跟随者的 Raft 代码收到 InstallSnapshotRPC 时,它可以使用 applyCh将快照发送给服务,放在一个 ApplyMsg中。ApplyMsg结构定义已经包含了你将需要的字段(也是测试程序期望的字段)。注意这些快照只能推进服务的状态,而不能导致其回退。
如果服务器崩溃,它必须从持久化的数据重新启动。你的 Raft 应该同时持久化 Raft 状态和相应的快照。使用 persister.Save()的第二个参数保存快照。如果没有快照,将 nil作为第二个参数传递。
当服务器重新启动时,应用层读取持久化的快照并恢复其保存的状态。
实现 Snapshot()和 InstallSnapshotRPC,以及支持这些功能的 Raft 更改(例如,使用修剪后的日志进行操作)。当你的解决方案通过 3D 测试(以及所有之前的 Lab 3 测试)时,它就完成了。
运行 git pull以确保你拥有最新的软件。
一个好的起点是修改你的代码,使其能够仅存储从某个索引 X 开始的日志部分。最初你可以将 X 设置为零并运行 3B/3C 测试。然后让 Snapshot(index)丢弃索引之前的日志,并将 X 设置为等于索引。如果一切顺利,你现在应该通过第一个 3D 测试。
未能通过第一个 3D 测试的一个常见原因是跟随者花费太长时间才能赶上领导者。
接下来:如果领导者没有所需的日志条目来使跟随者跟上进度,则让领导者发送 InstallSnapshotRPC。
在单个 InstallSnapshotRPC 中发送整个快照。不要实现图 13 的分割快照的偏移机制。
Raft 必须以允许 Go 垃圾收集器释放和重用内存的方式丢弃旧的日志条目;这要求没有对丢弃日志条目的可达引用(指针)。
在没有 -race的情况下,完成整套 Lab 3 测试(3A+3B+3C+3D)消耗的合理时间是 6 分钟实际时间和 1 分钟 CPU 时间。使用 -race运行时,大约是 10 分钟实际时间和 2 分钟 CPU 时间。
你的代码应该通过所有 3D 测试(如下所示),以及 3A、3B 和 3C 测试。
$ go test -run 3D
Test (3D): snapshots basic (reliable network)...
... Passed -- 3.3 3 522 0
Test (3D): install snapshots (disconnect) (reliable network)...
... Passed -- 48.4 3 2710 0
Test (3D): install snapshots (disconnect) (unreliable network)...
... Passed -- 56.1 3 3025 0
Test (3D): install snapshots (crash) (reliable network)...
... Passed -- 33.3 3 1559 0
Test (3D): install snapshots (crash) (unreliable network)...
... Passed -- 38.1 3 1723 0
Test (3D): crash and restart all servers (unreliable network)...
... Passed -- 11.2 3 296 0
Test (3D): snapshot initialization after crash (unreliable network)...
... Passed -- 4.3 3 84 0
PASS
ok 6.5840/raft1 195.006s
lab4
(保留代码和格式,仅翻译文本内容)
请注意:现在是东八区北京时间 2025 年 9 月 21 日 17 时 20 分 00 秒,星期日。
介绍
在本实验中,你将使用 Lab 3 中的 Raft 库构建一个容错的键/值存储服务。对于客户端而言,该服务看起来与 Lab 2 的服务器类似。然而,该服务并非由单个服务器组成,而是由一组使用 Raft 来帮助维护相同数据库的服务器组成。只要多数服务器存活且能够通信,即使发生其他故障或网络分区,你的键/值服务也应继续处理客户端请求。完成 Lab 4 后,你将实现 Raft 交互图中所示的所有部分(Clerk、Service 和 Raft)。
客户端将通过 Clerk 与你的键/值服务交互,就像在 Lab 2 中一样。Clerk 实现了与 Lab 2 语义相同的 Put 和 Get 方法:Puts 是至多一次(at-most-once)的,并且 Puts/Gets 必须形成一个线性化历史(linearizable history)。
对于单个服务器来说,提供线性化相对容易。如果服务是复制的,则会更加困难,因为所有服务器必须为并发请求选择相同的执行顺序,必须避免使用过时的状态回复客户端,并且必须在故障后以一种保留所有已确认客户端更新的方式恢复其状态。
本实验分为三个部分。在 A 部分,你将使用你的 raft 实现来构建一个复制状态机包 rsm;rsm 对其复制的请求是不可知的(agnostic)。在 B 部分,你将使用 rsm 实现一个复制的键/值服务,但不使用快照。在 C 部分,你将使用 Lab 3D 中的快照实现,这将允许 Raft 丢弃旧的日志条目。请在各自的截止日期前提交每个部分。
你应该复习扩展的 Raft 论文,特别是第 7 节(但不包括第 8 节)。为了更广阔的视角,可以看看 Chubby、Paxos Made Live、Spanner、Zookeeper、Harp、Viewstamped Replication 和 Bolosky 等人的论文。
请尽早开始。
开始
我们在 src/kvraft1中为你提供了骨架代码和测试。骨架代码使用骨架包 src/kvraft1/rsm来复制服务器。服务器必须实现 rsm 中定义的 StateMachine 接口,以便使用 rsm 复制自身。你的大部分工作将是实现 rsm 以提供与服务器无关的复制。你还需要修改 kvraft1/client.go和 kvraft1/server.go来实现服务器特定的部分。这种拆分允许你在下一个实验中重用 rsm。你也许可以重用一些 Lab 2 的代码(例如,通过复制或导入 "src/kvsrv1" 包来重用服务器代码),但这不是必须的要求。
要开始运行,请执行以下命令。不要忘记 git pull来获取最新的软件。
$ cd ~/6.5840
$ git pull
..
A 部分:复制状态机 (RSM) (中等/困难)
$ cd src/kvraft1/rsm
$ go test -v
=== RUN TestBasic
Test RSM basic (reliable network)...
..
config.go:147: one: took too long
在使用 Raft 进行复制的常见客户端/服务器服务场景中,服务通过两种方式与 Raft 交互:服务领导者通过调用 raft.Start()提交客户端操作,所有服务副本通过 Raft 的 applyCh接收已提交的操作并执行它们。在领导者上,这两项活动会相互作用。在任何给定时间,一些服务器 goroutine 正在处理客户端请求,已经调用了 raft.Start(),并且每个都在等待其操作提交并找出执行操作的结果。当已提交的操作出现在 applyCh上时,每个操作都需要由服务执行,并且需要将结果交给调用 raft.Start()的 goroutine,以便它可以向客户端返回结果。
rsm 包封装了上述交互。它作为服务(例如键/值数据库)和 Raft 之间的一个层。在 rsm/rsm.go中,你需要实现一个读取 applyCh的 "reader" goroutine,以及一个 rsm.Submit()函数,该函数为客户端操作调用 raft.Start(),然后等待 reader goroutine 将执行该操作的结果交给它。
使用 rsm 的服务对 rsm reader goroutine 来说表现为一个提供 DoOp()方法的 StateMachine 对象。reader goroutine 应该将每个已提交的操作交给 DoOp();DoOp()的返回值应该交给相应的 rsm.Submit()调用以供其返回。DoOp()的参数和返回值类型为 any;实际值应具有与服务传递给 rsm.Submit()的参数和返回值相同的类型。
服务应将每个客户端操作传递给 rsm.Submit()。为了帮助 reader goroutine 将 applyCh消息与等待的 rsm.Submit()调用匹配,Submit()应该将每个客户端操作包装在一个带有唯一标识符的 Op 结构中。然后,Submit()应等待操作提交并执行完毕,然后返回执行结果(DoOp()返回的值)。如果 raft.Start()指示当前对等体不是 Raft 领导者,Submit()应返回一个 rpc.ErrWrongLeader错误。Submit()应检测并处理在其调用 raft.Start()后领导权刚刚发生变化的情况,这可能导致操作丢失(从未提交)。
对于 A 部分,rsm 测试程序充当服务,提交它解释为对由单个整数组成的状态进行递增的操作。在 B 部分,你将使用 rsm 作为实现 StateMachine(和 DoOp())的键/值服务的一部分,并调用 rsm.Submit()。
如果一切顺利,客户端请求的事件序列是:
- 客户端向服务领导者发送请求。
- 服务领导者使用请求调用
rsm.Submit()。 rsm.Submit()使用请求调用raft.Start(),然后等待。- Raft 提交请求并将其发送到所有对等体的
applyCh上。 - 每个对等体上的 rsm reader goroutine 从
applyCh读取请求并将其传递给服务的DoOp()。 - 在领导者上,rsm reader goroutine 将
DoOp()返回值交给最初提交请求的Submit()goroutine,然后Submit()返回该值。
你的服务器不应直接通信;它们应仅通过 Raft 相互交互。
实现 rsm.go:Submit()方法和一个 reader goroutine。如果你通过了 rsm 4A 测试,则完成了此任务:
$ cd src/kvraft1/rsm
$ go test -v -run 4A
=== RUN TestBasic4A
Test RSM basic (reliable network)...
... Passed -- 1.2 3 48 0
--- PASS: TestBasic4A (1.21s)
=== RUN TestLeaderFailure4A
... Passed -- 9223372036.9 3 31 0
--- PASS: TestLeaderFailure4A (1.50s)
PASS
ok 6.5840/kvraft1/rsm 2.887s
- 你不需要向 Raft ApplyMsg 或 Raft RPC(如 AppendEntries)添加任何字段,但允许你这样做。
- 你的解决方案需要处理以下情况:rsm 领导者已为通过
Submit()提交的请求调用了Start(),但在请求提交到日志之前失去了领导权。一种方法是让 rsm 检测到它已失去领导权,通过注意到 Raft 的任期已更改或在Start()返回的索引处出现了不同的请求,并从Submit()返回rpc.ErrWrongLeader。如果前领导者自身被分区,它将不会知道新的领导者;但是同一分区中的任何客户端也将无法与新领导者通信,因此在这种情况下,服务器无限期等待直到分区修复是可以的。 - 测试程序在关闭对等体时会调用你的 Raft 的
rf.Kill()。Raft 应关闭applyCh,以便你的 rsm 得知关闭,并可以退出所有循环。
B 部分:无快照的键/值服务 (中等)
$ cd src/kvraft1
$ go test -v -run TestBasic4B
=== RUN TestBasic4B
Test: one client (4B basic) (reliable network)...
kvtest.go:62: Wrong error
$
现在你将使用 rsm 包来复制一个键/值服务器。每个服务器("kvservers")将有一个关联的 rsm/Raft 对等体。Clerk 向其关联的 Raft 是领导者的 kvserver 发送 Put()和 Get()RPC。kvserver 代码将 Put/Get 操作提交给 rsm,rsm 使用 Raft 复制它并在每个对等体调用你的服务器的 DoOp,这应将操作应用到对等体的键/值数据库;目的是让服务器维护相同的键/值数据库副本。
Clerk 有时不知道哪个 kvserver 是 Raft 领导者。如果 Clerk 向错误的 kvserver 发送 RPC,或者无法连接到 kvserver,Clerk 应通过发送到不同的 kvserver 来重试。如果键/值服务将操作提交到其 Raft 日志(从而将操作应用到键/值状态机),领导者通过响应其 RPC 向 Clerk 报告结果。如果操作未能提交(例如,如果领导者被替换),服务器报告错误,Clerk 使用其他服务器重试。
你的 kvservers 不应直接通信;它们应仅通过 Raft 相互交互。
你的第一个任务是实现一个在没有消息丢失和服务器故障时有效的解决方案。
可以随意将你的 Lab 2 客户端代码(kvsrv1/client.go)复制到 kvraft1/client.go中。你需要添加逻辑来决定向哪个 kvserver 发送每个 RPC。
你还需要在 server.go中实现 Put()和 Get()RPC 处理程序。这些处理程序应使用 rsm.Submit()将请求提交给 Raft。当 rsm 包从 applyCh读取命令时,它应调用 DoOp方法,你必须在 server.go中实现该方法。
当你可靠地通过测试套件中的第一个测试 go test -v -run TestBasic4B时,你就完成了此任务。
如果 kvserver 不属于多数派(以便它不提供过时数据),它不应完成 Get()RPC。一个简单的解决方案是使用 Submit()将每个 Get()(以及每个 Put())输入到 Raft 日志中。你不必实现第 8 节中描述的用于只读操作的优化。
最好从一开始就添加锁,因为避免死锁的需要有时会影响整体代码设计。使用 go test -race检查你的代码是否存在竞争条件。
现在你应该修改你的解决方案,以在网络和服务器故障面前继续工作。你将面临的一个问题是,Clerk 可能必须多次发送 RPC,直到找到一个肯定回复的 kvserver。如果领导者在将条目提交到 Raft 日志后立即发生故障,Clerk 可能收不到回复,因此可能将请求重新发送给另一个领导者。每个 Clerk.Put()调用应仅导致特定版本号的一次执行。
添加代码来处理故障。你的 Clerk 可以使用与 lab 2 中类似的重试计划,包括如果重试的 Put RPC 响应丢失则返回 ErrMaybe。当你的代码可靠地通过所有 4B 测试 go test -v -run 4B时,你就完成了。
回想一下,rsm 领导者可能会失去其领导权并从 Submit()返回 rpc.ErrWrongLeader。在这种情况下,你应该安排 Clerk 将请求重新发送到其他服务器,直到找到新的领导者。
你可能需要修改你的 Clerk,以记住最后一个 RPC 的领导者是哪台服务器,并首先将下一个 RPC 发送到该服务器。这将避免在每个 RPC 上浪费时间寻找领导者,这可能帮助你足够快地通过一些测试。
你的代码现在应该通过 Lab 4B 测试,如下所示:
$ cd kvraft1
$ go test -run 4B
Test: one client (4B basic) ...
... Passed -- 3.2 5 1041 183
Test: one client (4B speed) ...
... Passed -- 15.9 3 3169 0
Test: many clients (4B many clients) ...
... Passed -- 3.9 5 3247 871
Test: unreliable net, many clients (4B unreliable net, many clients) ...
... Passed -- 5.3 5 1035 167
Test: unreliable net, one client (4B progress in majority) ...
... Passed -- 2.9 5 155 3
Test: no progress in minority (4B) ...
... Passed -- 1.6 5 102 3
Test: completion after heal (4B) ...
... Passed -- 1.3 5 67 4
Test: partitions, one client (4B partitions, one client) ...
... Passed -- 6.2 5 958 155
Test: partitions, many clients (4B partitions, many clients (4B)) ...
... Passed -- 6.8 5 3096 855
Test: restarts, one client (4B restarts, one client 4B ) ...
... Passed -- 6.7 5 311 13
Test: restarts, many clients (4B restarts, many clients) ...
... Passed -- 7.5 5 1223 95
Test: unreliable net, restarts, many clients (4B unreliable net, restarts, many clients ) ...
... Passed -- 8.4 5 804 33
Test: restarts, partitions, many clients (4B restarts, partitions, many clients) ...
... Passed -- 10.1 5 1308 105
Test: unreliable net, restarts, partitions, many clients (4B unreliable net, restarts, partitions, many clients) ...
... Passed -- 11.9 5 1040 33
Test: unreliable net, restarts, partitions, random keys, many clients (4B unreliable net, restarts, partitions, random keys, many clients) ...
... Passed -- 12.1 7 2801 93
PASS
ok 6.5840/kvraft1 103.797s
每个 Passed 后面的数字是实时(秒)、对等体数量、发送的 RPC 数量(包括客户端 RPC)和执行的键/值操作数量(Clerk Get/Put 调用)。
C 部分:带快照的键/值服务 (中等)
就目前情况而言,你的键/值服务器不会调用你的 Raft 库的 Snapshot()方法,因此重新启动的服务器必须重放完整的持久化 Raft 日志才能恢复其状态。现在你将修改 kvserver 和 rsm,与 Raft 协作以节省日志空间并减少重启时间,使用 Lab 3D 中的 Raft 的 Snapshot()。
测试程序将 maxraftstate传递给你的 StartKVServer(),后者将其传递给 rsm。maxraftstate表示你的持久化 Raft 状态(包括日志,但不包括快照)允许的最大大小(字节)。你应该将 maxraftstate与 rf.PersistBytes()进行比较。每当你的 rsm 检测到 Raft 状态大小接近此阈值时,它应通过调用 Raft 的 Snapshot来保存快照。rsm 可以通过调用 StateMachine 接口的 Snapshot方法来创建此快照,以获取 kvserver 的快照。如果 maxraftstate为 -1,则不需要快照。maxraftstate限制适用于你的 Raft 作为第一个参数传递给 persister.Save()的 GOB 编码字节。
你可以在 tester1/persister.go中找到 persister 对象的源代码。
修改你的 rsm,使其检测到持久化的 Raft 状态何时变得过大,然后将快照交给 Raft。当 rsm 服务器重新启动时,它应使用 persister.ReadSnapshot()读取快照,如果快照的长度大于零,则将快照传递给 StateMachine 的 Restore()方法。如果你在 rsm 中通过 TestSnapshot4C,则完成了此任务。
$ cd kvraft1/rsm
$ go test -run TestSnapshot4C
=== RUN TestSnapshot4C
... Passed -- 9223372036.9 3 230 0
--- PASS: TestSnapshot4C (3.88s)
PASS
ok 6.5840/kvraft1/rsm 3.882s
- 思考 rsm 应在何时快照其状态,以及除了服务器状态之外,快照中还应包含什么。Raft 使用
Save()将每个快照与相应的 Raft 状态一起存储在 persister 对象中。你可以使用ReadSnapshot()读取最新存储的快照。 - 将存储在快照中的结构的所有字段首字母大写。
- 实现 rsm 调用的
kvraft1/server.go中的Snapshot()和Restore()方法。修改 rsm 以处理包含快照的applyCh消息。
你的 Raft 和 rsm 库中可能存在此任务暴露的错误。如果你对 Raft 实现进行了更改,请确保它继续通过所有 Lab 3 测试。
完成 Lab 4 测试的合理时间是 400 秒实时和 700 秒 CPU 时间。
你的代码应通过 4C 测试(如此处示例所示)以及 4A+B 测试(并且你的 Raft 必须继续通过 Lab 3 测试)。
$ go test -run 4C
Test: snapshots, one client (4C SnapshotsRPC) ...
Test: InstallSnapshot RPC (4C) ...
... Passed -- 4.5 3 241 64
Test: snapshots, one client (4C snapshot size is reasonable) ...
... Passed -- 11.4 3 2526 800
Test: snapshots, one client (4C speed) ...
... Passed -- 14.2 3 3149 0
Test: restarts, snapshots, one client (4C restarts, snapshots, one client) ...
... Passed -- 6.8 5 305 13
Test: restarts, snapshots, many clients (4C restarts, snapshots, many clients ) ...
... Passed -- 9.0 5 5583 795
Test: unreliable net, snapshots, many clients (4C unreliable net, snapshots, many clients) ...
... Passed -- 4.7 5 977 155
Test: unreliable net, restarts, snapshots, many clients (4C unreliable net, restarts, snapshots, many clients) ...
... Passed -- 8.6 5 847 33
Test: unreliable net, restarts, partitions, snapshots, many clients (4C unreliable net, restarts, partitions, snapshots, many clients) ...
... Passed -- 11.5 5 841 33
Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (4C unreliable net, restarts, partitions, snapshots, random keys, many clients) ...
... Passed -- 12.8 7 2903 93
PASS
ok 6.5840/kvraft1 83.543s
lab5
介绍
您可以选择基于自己的想法完成一个最终项目,或者完成这个实验。
在本实验中,您将构建一个键/值存储系统,该系统将键"分片"(或分区)到一组基于Raft复制的键/值服务器组(shardgrps)上。分片是键/值对的子集;例如,所有以"a"开头的键可能是一个分片,所有以"b"开头的键是另一个分片,等等。分片的原因是性能。每个shardgrp只处理几个分片的puts和gets,并且shardgrps并行操作;因此系统总吞吐量(单位时间的puts和gets)随着shardgrps数量的增加而增加。
分片键/值设计
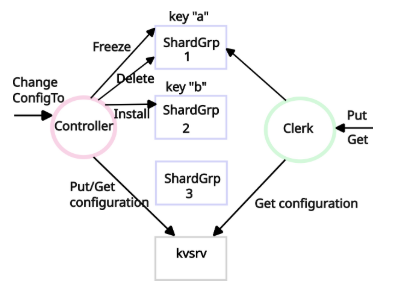
分片键/值服务具有如上图所示的组件。Shardgrps(用蓝色方块表示)存储带有键的分片:shardgrp 1持有存储键"a"的分片,shardgrp 2持有存储键"b"的分片。分片键/值服务的客户端通过一个clerk(用绿色圆圈表示)与服务交互,该clerk实现Get和Put方法。为了找到传递给Put/Get的键对应的shardgrp,clerk从kvsrv(用黑色方块表示)获取配置,这是您在实验2中实现的。配置(未显示)描述了从分片到shardgrps的映射(例如,分片1由shardgrp 3服务)。
管理员(即测试程序)使用另一个客户端,即控制器(用紫色圆圈表示),来添加/从集群中移除shardgrps,并更新哪个shardgrp应该服务一个分片。控制器有一个主要方法:ChangeConfigTo,它以新配置作为参数,并将系统从当前配置更改为新配置;这涉及将分片移动到加入系统的新shardgrps,并将分片从离开系统的shardgrps移走。为此,控制器1)向shardgrps发出RPC(FreezeShard、InstallShard和DeleteShard),2)更新存储在kvsrv中的配置。
需要控制器的原因是分片存储系统必须能够在shardgrps之间移动分片。一个原因是一些shardgrps可能比其他shardgrps负载更重,因此需要移动分片以平衡负载。另一个原因是shardgrps可能会加入和离开系统:可以添加新的shardgrps以增加容量,或者现有的shardgrps可能因修复或退役而离线。
本实验的主要挑战是确保Get/Put操作的线性izability,同时处理1)分片到shardgrps的分配变化,以及2)从在ChangeConfigTo期间失败或分区的控制器中恢复。
ChangeConfigTo将分片从一个shardgrp移动到另一个shardgrp。一个风险是一些客户端可能使用旧的shardgrp,而其他客户端使用新的shardgrp,这可能会破坏线性izability。您需要确保在任何时候最多只有一个shardgrp为每个分片服务请求。
如果ChangeConfigTo在重新配置期间失败,一些分片可能无法访问,如果它们已经开始但尚未完成从一个shardgrp移动到另一个shardgrp。为了取得进展,测试程序启动一个新的控制器,您的任务是确保新的控制器完成前一个控制器开始的重新配置。
本实验使用"配置"来指代分片到shardgrps的分配。这与Raft集群成员变更不同。您不需要实现Raft集群成员变更。
一个shardgrp服务器仅是一个shardgrp的成员。给定shardgrp中的服务器集合永远不会改变。
只有RPC可以用于客户端和服务器之间的交互。例如,不允许您的服务器的不同实例共享Go变量或文件。
在A部分,您将实现一个工作的shardctrler,它将在kvsrv中存储和检索配置。您还将实现shardgrp,使用您的Raft rsm包进行复制,以及相应的shardgrp clerk。shardctrler与shardgrp clerks通信以在不同组之间移动分片。
在B部分,您将修改您的shardctrler以处理配置更改期间的故障和分区。在C部分,您将扩展您的shardctrler以允许多个控制器同时运行而不会相互干扰。最后,在D部分,您将有机会以任何您喜欢的方式扩展您的解决方案。
本实验的分片键/值服务遵循与Flat Datacenter Storage、BigTable、Spanner、FAWN、Apache HBase、Rosebud、Spinnaker等相同的一般设计。然而,这些系统在细节上与本实验有许多不同,并且通常更复杂和强大。例如,本实验不会发展每个Raft组中的对等点集合;其数据和查询模型简单;等等。
实验5将使用您来自实验2的kvsrv,以及您来自实验4的rsm和Raft。您的实验5和实验4必须使用相同的rsm和Raft实现。
您可以为A部分使用延迟小时,但不能为B-D部分使用延迟小时。
对上述内容解析
核心设计理念
这个系统的核心思想是 分而治之。通过将整个键空间划分为多个分片(Shard),并将这些分片分配给不同的、可独立运行的服务器组(Shard Group),系统能够实现:
- 水平扩展(Scalability): 吞吐量随着服务器组数量的增加而(近乎)线性增长。
- 故障隔离(Fault Isolation): 一个服务器组的故障不会影响其他分片的数据服务。
- 灵活管理(Manageability): 可以动态地调整分片与服务器组的映射关系,以应对负载变化、机器增减等情况。
系统组件详解
图中的每个组件都扮演着至关重要的角色:
1. 分片组(ShardGrp - 蓝色方块)
- 是什么: 一个复制状态机(Replicated State Machine) 集群。本质上,它就是你在Lab 4中构建的一个键值服务器集群(kvraft),但有一个关键区别:它不再负责所有的键,而只负责被分配给它的一组分片(Shard)。
- 核心职责: 对其负责的分片内的键(例如,所有以 'a' 开头的键)执行
Get和Put操作。 使用 Raft 协议在组内多个副本之间复制日志,保证一致性。 响应控制器的FreezeShard,InstallShard,DeleteShardRPC 调用,以配合分片迁移。
2. 客户端(Clerk - 绿色圆圈)
- 是什么: 应用程序用来与分片存储系统交互的接口。
- 核心职责: 接收应用程序的
Get(key)和Put(key, value)请求。 关键步骤: 它自己不知道key在哪个分片组。它需要先查询配置服务(kvsrv),获取当前的配置(Config)。 根据配置,计算出key属于哪个分片(例如,hash(key) % N),再查配置知道这个分片由哪个分片组(GID)负责。 最后,它知道这个分片组的所有服务器地址,创建一个到该分片组的 RPC 客户端,将请求发送过去。 如果收到ErrWrongGroup错误(说明配置已变更,这个组不再负责此分片),它会重新查询配置并重试。
3. 配置服务(kvsrv - 黑色方块)
- 是什么: 一个独立的、高可用的键值存储服务。这就是你在 Lab 2 中构建的服务。它在这里的唯一用途就是存储一个特殊的键,比如
"config",其对应的值就是当前的配置(Config)。 - 核心职责: 存储并提供最新的配置信息。它是一个“真理之源”(Source of Truth)。
4. 配置(Config - 未画出,但至关重要)
- 是什么: 一个数据结构(在
shardcfg包中定义),通常包含:ConfigNum: 配置的版本号,单调递增。Shards [NShards]GID: 一个数组,下标是分片编号(0-9),值是负责该分片的分片组ID(GID)。Groups map[GID][]string: 一个映射,key 是分片组ID(GID),value 是该分片组所有服务器的网络地址(如["server1:port", "server2:port"])。 - 示例:
Config{Num: 1, Shards: [10]GID{1,1,1,1,1,1,1,1,1,1}, Groups: map[1:["s1","s2","s3"]]}表示所有10个分片都由唯一的分片组GID=1负责,该组有3台服务器。
5. 控制器(Controller - 紫色圆圈)
- 是什么: 一个管理工具(类似于
kubectl之于 Kubernetes)。由系统管理员(在实验中是测试程序)运行。它不是一个常驻服务,而是一个命令行工具,执行完一个管理命令(如ChangeConfigTo)后就退出。 - 核心职责: 执行
ChangeConfigTo(newConfig)命令。这是最复杂的过程,其工作流如下图所示:
flowchart TD
A[控制器读取当前Config] --> B[计算新Config<br>如加入GID2或移除GID1]
B --> C[将新Config作为next配置写入kvsrv]
C --> D[遍历所有需要迁移的分片]
subgraph D[分片迁移流程]
direction TB
D1[FreezeShard<br>冻结旧组上的分片] --> D2[InstallShard<br>将分片数据安装到新组] --> D3[DeleteShard<br>删除旧组上的分片数据]
end
D --> E[所有分片迁移完成]
E --> F[将新Config提升为当前配置]
F --> G[客户端读取新配置<br>后续请求发往新组]
关键挑战与解决方案
- 线性一致性(Linearizability) during Migration: 问题: 在分片从组A迁移到组B的过程中,如果客户端C1从组A读,客户端C2向组B写,就会破坏线性一致性。 解决方案: 采用 “冻结(Freeze)” 机制。一旦一个分片被冻结,原分片组会拒绝所有对该分片的读写操作(返回
ErrWrongGroup),迫使客户端去查询最新配置并重试到新的分片组。这确保了在任何一个时间点,最多只有一个组能对某个分片进行写操作。 - 控制器故障恢复: 问题: 如果控制器在迁移过程中崩溃(例如,在安装了3个分片后崩溃),系统会处于一个中间状态,部分分片不可用。 解决方案(Part B): 控制器将迁移过程设计为幂等的。它将目标配置(
nextConfig)持久化在kvsrv中。新的控制器启动后,会检查是否存在未完成的nextConfig,如果有,则继续完成迁移流程。由于FreezeShard,InstallShard,DeleteShard等RPC都包含了ConfigNum,分片组可以拒绝旧配置的重复RPC,因此重复执行是安全的。 - 并发控制器: 问题: 如果网络分区导致两个控制器都认为自己是主控制器,并同时执行
ChangeConfigTo,它们可能会相互覆盖配置,造成混乱。 解决方案(Part C): 使用 kvsrv 的 版本化控制(如 Lab 2 的Put的Version参数) 来实现一个简单的分布式锁或条件更新。例如,控制器在更新nextConfig时,必须提供当前配置的版本号。如果版本号不匹配(说明已被其他控制器修改),则更新失败。这确保了只有一个控制器的配置更新能成功。
总结
这个设计是一个经典、优雅且功能强大的分布式系统架构。它清晰地分离了数据平面(ShardGrp 处理读写请求)和控制平面(Controller 和 kvsrv 管理元数据),并通过幂等性、版本号和冻结状态等机制,巧妙地解决了分布式环境下最棘手的状态变更和故障恢复问题。完成这个实验意味着你真正理解和实践了构建可扩展、强一致、高可用的分布式存储系统的核心模式。
开始
执行git pull以获取最新的实验软件。
我们在src/shardkv1中为您提供测试和骨架代码:
client.go 用于 shardkv clerk
shardcfg 包用于计算分片配置
shardgrp 包:用于 shardgrp clerk 和服务器。
shardctrler 包,其中包含 shardctrler.go,具有控制器更改配置(ChangeConfigTo)和获取配置(Query)的方法
要启动并运行,请执行以下命令:
$ cd ~/6.5840
$ git pull
...
$ cd src/shardkv1
$ go test -v
=== RUN TestInitQuery5A
Test (5A): Init and Query ... (reliable network)...
shardkv_test.go:46: Static wrong null 0
...
A部分:移动分片(困难)
您的第一个任务是在没有故障的情况下实现shardgrps以及InitConfig、Query和ChangeConfigTo方法。我们已经为您提供了描述配置的代码,在shardkv1/shardcfg中。每个shardcfg.ShardConfig都有一个唯一的标识号,一个从分片号到组号的映射,以及一个从组号到复制该组的服务器列表的映射。通常分片比组多(因此每个组服务多个分片),以便可以相当精细地调整负载。
在shardctrler/shardctrler.go中实现这两个方法:
InitConfig方法接收第一个配置,测试程序将其作为shardcfg.ShardConfig传递。InitConfig应将配置存储在实验2的kvsrv实例中。
Query方法返回当前配置;它应从kvsrv读取配置,之前由InitConfig存储在那里。
实现InitConfig和Query,并将配置存储在kvsrv中。当您的代码通过第一个测试时,您就完成了。注意这个任务不需要任何shardgrps。
$ cd ~/6.5840/src/shardkv1
$ go test -run TestInitQuery5A
Test (5A): Init and Query ... (reliable network)...
... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
PASS
ok 6.5840/shardkv1 0.197s
$
通过从kvsrv存储和读取初始配置来实现InitConfig和Query:使用ShardCtrler.IKVClerk的Get/Put方法与kvsrv通信,使用ShardConfig的String方法将ShardConfig转换为可以传递给Put的字符串,并使用shardcfg.FromString()函数将字符串转换为ShardConfig。
通过在shardkv1/shardgrp/server.go中实现shardgrp的初始版本,并在shardkv1/shardgrp/client.go中实现相应的clerk,通过从您的实验4 kvraft解决方案复制代码。
在shardkv1/client.go中实现一个clerk,使用Query方法找到键的shardgrp,然后与该shardgrp通信。当您的代码通过Static测试时,您就完成了。
$ cd ~/6.5840/src/shardkv1
$ go test -run Static
Test (5A): one shard group ... (reliable network)...
... Passed -- time 5.4s #peers 1 #RPCs 793 #Ops 180
PASS
ok 6.5840/shardkv1 5.632s
$
从您的kvraft client.go和server.go复制Put和Get的代码,以及您从kvraft需要的任何其他代码。
shardkv1/client.go中的代码为整个系统提供Put/Get clerk:它通过调用Query方法找出哪个shardgrp持有所需键的分片,然后与持有该分片的shardgrp通信。
实现shardkv1/client.go,包括其Put/Get方法。使用shardcfg.Key2Shard()找到键的分片号。测试程序在shardkv1/client.go中的MakeClerk中传递一个ShardCtrler对象。使用Query方法检索当前配置。
要从shardgrp put/get一个键,shardkv clerk应该通过调用shardgrp.MakeClerk为shardgrp创建一个shardgrp clerk,传入配置中找到的服务器和shardkv clerk的ck.clnt。使用ShardConfig的GidServers()方法获取分片的组。
shardkv1/client.go的Put必须在回复可能丢失时返回ErrMaybe,但这个Put调用shardgrp的Put与特定的shardgrp通信。内部的Put可以用错误信号通知这一点。
创建时,第一个shardgrp(shardcfg.Gid1)应该初始化自己以拥有所有分片。
现在您应该通过实现ChangeConfigTo方法来支持分片在组之间的移动,该方法从旧配置更改为新配置。新配置可能包括旧配置中不存在的新shardgrps,并且可能排除旧配置中存在的shardgrps。控制器应该移动分片(键/值数据),以便每个shardgrp存储的分片集与新配置匹配。
我们建议移动分片的方法是让ChangeConfigTo首先"冻结"源shardgrp处的分片,导致该shardgrp拒绝移动分片中键的Put。然后,将分片复制(安装)到目标shardgrp;然后删除冻结的分片。最后,发布一个新配置,以便客户端可以找到移动的分片。这种方法的一个好属性是它避免了shardgrps之间的任何直接交互。它还支持服务不受正在进行的配置更改影响的分片。
为了能够对配置的更改进行排序,每个配置都有一个唯一的编号Num(参见shardcfg/shardcfg.go)。A部分中的测试程序顺序调用ChangeConfigTo,并且传递给ChangeConfigTo的配置的Num将比前一个大1;因此,具有较高Num的配置比具有较低Num的配置新。
网络可能会延迟RPC,并且RPC可能乱序到达shardgrps。为了拒绝旧的FreezeShard、InstallShard和DeleteShard RPC,它们应该包括Num(参见shardgrp/shardrpc/shardrpc.go),并且shardgrps必须记住它们为每个分片看到的最大Num。
实现ChangeConfigTo(在shardctrler/shardctrler.go中)并扩展shardgrp以支持冻结、安装和删除。ChangeConfigTo在A部分应该总是成功,因为测试程序在这一部分不会引起故障。您将需要使用shardgrp/shardrpc包中的RPC在shardgrp/client.go和shardgrp/server.go中实现FreezeShard、InstallShard和Delete,并基于Num拒绝旧的RPC。您还需要修改shardkv clerk在shardkv1/client.go中以处理ErrWrongGroup,如果shardgrp不对分片负责,则应返回该错误。
当您通过JoinBasic和DeleteBasic测试时,您就完成了这个任务。这些测试专注于添加shardgrps;您还不必担心shardgrps离开。
shardgrp应该对客户端Put/Get的键(即,其分片未分配给shardgrp的键)响应ErrWrongGroup错误。您将不得不修改shardkv1/client.go以重新读取配置并重试Put/Get。
注意,您将不得不通过您的rsm包运行FreezeShard、InstallShard和DeleteShard,就像Put和Get一样。
您可以在RPC请求或回复中发送整个映射作为您的状态,这可能有助于保持分片传输代码的简单性。
如果您的RPC处理程序在其回复中包含作为服务器状态一部分的映射(例如键/值映射),您可能会由于竞争而得到错误。RPC系统必须读取映射才能将其发送给调用者,但它没有持有覆盖映射的锁。然而,您的服务器可能会在RPC系统读取相同映射时继续修改它。解决方案是RPC处理程序在回复中包含映射的副本。
扩展ChangeConfigTo以处理离开的shard groups;即,当前配置中存在但新配置中不存在的shardgrps。您的解决方案现在应该通过TestJoinLeaveBasic5A。(您可能已经在先前的任务中处理了这个场景,但先前的测试没有测试shardgrps离开。)
使您的解决方案通过所有A部分测试,这些测试检查您的分片键/值服务支持许多组加入和离开,shardgrps从快照重新启动,在处理一些分片离线或参与配置更改时处理Gets,以及当许多客户端与服务交互而测试程序同时调用控制器的ChangeConfigTo以重新平衡分片时的线性izability。
$ cd ~/6.5840/src/shardkv1
$ go test -run 5A
Test (5A): Init and Query ... (reliable network)...
... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
Test (5A): one shard group ... (reliable network)...
... Passed -- time 5.1s #peers 1 #RPCs 792 #Ops 180
Test (5A): a group joins... (reliable network)...
... Passed -- time 12.9s #peers 1 #RPCs 6300 #Ops 180
Test (5A): delete ... (reliable network)...
... Passed -- time 8.4s #peers 1 #RPCs 1533 #Ops 360
Test (5A): basic groups join/leave ... (reliable network)...
... Passed -- time 13.7s #peers 1 #RPCs 5676 #Ops 240
Test (5A): many groups join/leave ... (reliable network)...
... Passed -- time 22.1s #peers 1 #RPCs 3529 #Ops 180
Test (5A): many groups join/leave ... (unreliable network)...
... Passed -- time 54.8s #peers 1 #RPCs 5055 #Ops 180
Test (5A): shutdown ... (reliable network)...
... Passed -- time 11.7s #peers 1 #RPCs 2807 #Ops 180
Test (5A): progress ... (reliable network)...
... Passed -- time 8.8s #peers 1 #RPCs 974 #Ops 82
Test (5A): progress ... (reliable network)...
... Passed -- time 13.9s #peers 1 #RPCs 2443 #Ops 390
Test (5A): one concurrent clerk reliable... (reliable network)...
... Passed -- time 20.0s #peers 1 #RPCs 5326 #Ops 1248
Test (5A): many concurrent clerks reliable... (reliable network)...
... Passed -- time 20.4s #peers 1 #RPCs 21688 #Ops 10500
Test (5A): one concurrent clerk unreliable ... (unreliable network)...
... Passed -- time 25.8s #peers 1 #RPCs 2654 #Ops 176
Test (5A): many concurrent clerks unreliable... (unreliable network)...
... Passed -- time 25.3s #peers 1 #RPCs 7553 #Ops 1896
PASS
ok 6.5840/shardkv1 243.115s
$
您的解决方案必须继续服务不受正在进行的配置更改影响的分片。
B部分:处理失败的控制器(简单)
控制器是一个短命的命令,由管理员调用:它移动分片然后退出。但是,它可能在移动分片时失败或失去网络连接。本实验部分的主要任务是从未能完成ChangeConfigTo的控制器中恢复。测试程序在分区第一个控制器后启动一个新的控制器并调用其ChangeConfigTo;您必须修改控制器,以便新的控制器完成重新配置。测试程序在启动控制器时调用InitController;您可以修改该函数以检查是否需要完成中断的配置更改。
允许控制器完成前一个控制器开始的重新配置的一个好方法是保持两个配置:一个当前配置和一个下一个配置,都存储在控制器的kvsrv中。当控制器开始重新配置时,它存储下一个配置。一旦控制器完成重新配置,它使下一个配置成为当前配置。修改InitController以首先检查是否有存储的下一个配置,其配置号比当前配置高,如果有,完成重新配置到下一个配置所需的分片移动。
修改shardctrler以实现上述方法。一个从失败控制器接手工作的控制器可能会重复FreezeShard、InstallShard和Delete RPC;shardgrps可以使用Num检测重复并拒绝它们。如果您的解决方案通过B部分测试,您就完成了这个任务。
$ cd ~/6.5840/src/shardkv1
$ go test -run 5B
Test (5B): Join/leave while a shardgrp is down... (reliable network)...
... Passed -- time 9.2s #peers 1 #RPCs 899 #Ops 120
Test (5B): recover controller ... (reliable network)...
... Passed -- time 26.4s #peers 1 #RPCs 3724 #Ops 360
PASS
ok 6.5840/shardkv1 35.805s
$
测试程序在启动控制器时调用InitController;您可以在shardctrler/shardctrler.go中的该方法中实现恢复。
C部分:并发配置更改(中等)
在本实验部分,您将修改控制器以允许多个控制器同时运行。当控制器崩溃或分区时,测试程序将启动一个新的控制器,该控制器必须完成旧控制器可能正在进行的工作(即,像B部分一样完成移动分片)。这意味着几个控制器可能同时运行并向shardgrps和存储配置的kvsrv发送RPC。
主要挑战是确保这些控制器不会相互干扰。在A部分,您已经用Num隔离了所有shardgrp RPC,以便旧的RPC被拒绝。即使几个控制器同时接手旧控制器的工作,其中一个成功而其他重复所有RPC,shardgrps也会忽略它们。
因此,剩下的挑战性情况是确保只有一个控制器更新下一个配置,以避免两个控制器(例如,一个分区的控制器和一个新的控制器)在下一個配置中放入不同的配置。为了强调这个场景,测试程序同时运行几个控制器,每个控制器通过读取当前配置并更新它以处理离开或加入的shardgrp来计算下一个配置,然后测试程序调用ChangeConfigTo;因此多个控制器可能使用具有相同Num的不同配置调用ChangeConfigTo。您可以使用键的版本号和版本化Puts来确保只有一个控制器更新下一个配置,而其他调用返回而不执行任何操作。
修改您的控制器,以便只有一个控制器可以为配置Num发布下一个配置。测试程序将启动许多控制器,但只有一个应该为新的配置启动ChangeConfigTo。如果您通过C部分的并发测试,您就完成了这个任务:
$ cd ~/6.5840/src/shardkv1
$ go test -run TestConcurrentReliable5C
Test (5C): Concurrent ctrlers ... (reliable network)...
... Passed -- time 8.2s #peers 1 #RPCs 1753 #Ops 120
PASS
ok 6.5840/shardkv1 8.364s
$ go test -run TestAcquireLockConcurrentUnreliable5C
Test (5C): Concurrent ctrlers ... (unreliable network)...
... Passed -- time 23.8s #peers 1 #RPCs 1850 #Ops 120
PASS
ok 6.5840/shardkv1 24.008s
$
参见test.go中的concurCtrler以了解测试程序如何同时运行控制器。
在这个练习中,您将把旧控制器的恢复与新控制器结合起来:新控制器应该执行B部分的恢复。如果旧控制器在ChangeConfigTo期间被分区,您必须确保旧控制器不会干扰新控制器。如果所有控制器的更新都已经用B部分的Num检查 properly fenced,您不需要编写额外的代码。如果您通过Partition测试,您就完成了这个任务。
$ cd ~/6.5840/src/shardkv1
$ go test -run Partition
Test (5C): partition controller in join... (reliable network)...
... Passed -- time 7.8s #peers 1 #RPCs 876 #Ops 120
Test (5C): controllers with leased leadership ... (reliable network)...
... Passed -- time 36.8s #peers 1 #RPCs 3981 #Ops 360
Test (5C): controllers with leased leadership ... (unreliable network)...
... Passed -- time 52.4s #peers 1 #RPCs 2901 #Ops 240
Test (5C): controllers with leased leadership ... (reliable network)...
... Passed -- time 60.2s #peers 1 #RPCs 27415 #Ops 11182
Test (5C): controllers with leased leadership ... (unreliable network)...
... Passed -- time 60.5s #peers 1 #RPCs 11422 #Ops 2336
PASS
ok 6.5840/shardkv1 217.779s
$
您已经完成了一个高可用的分片键/值服务的实现,具有许多分片组以实现可扩展性,重新配置以处理负载变化,以及具有容错控制器;恭喜!
重新运行所有测试以检查您最近对控制器的更改是否破坏了先前的测试。
Gradescope将在您的提交上重新运行实验3A-D和实验4A-C的测试,以及5C测试。在提交之前,仔细检查您的解决方案是否有效:
$ go test ./raft1
$ go test ./kvraft1
$ go test ./shardkv1
D部分:扩展您的解决方案
在实验的最后部分,您可以以任何您喜欢的方式扩展您的解决方案。您将不得不为您选择实现的任何扩展编写自己的测试。
实现以下想法之一或提出您自己的想法。在文件extension.md中写一段描述您的扩展,并将extension.md上传到Gradescope。如果您想做一个更难的、开放式的扩展,请随时与班上的另一个学生合作。
以下是一些可能的扩展想法(前几个容易,后面的更开放):
(容易)更改测试程序以使用kvraft而不是kvsrv(即,用kvraft.StartKVServer替换test.go中的kvsrv.StartKVServer),以便控制器使用您的kvraft存储其配置。编写一个测试,检查控制器可以在其中一个kvraft对等点关闭时查询和更新配置。测试程序的现有代码分布在src/kvtest1、src/shardkv1和src/tester1中。
(中等)更改kvsrv以实现Put/Get的 exactly-once 语义,如去年的实验2(参见丢弃消息部分)。您可能能够从2024年移植一些测试,而不是从头开始编写自己的测试。在您的kvraft中也实现 exactly-once。
(中等)更改kvsrv以支持Range函数,该函数返回从低键到高键的所有键。实现Range的懒惰方法是迭代服务器维护的键/值映射;更好的方法是使用支持范围搜索的数据结构(例如,B树)。包括一个测试,该测试在懒惰解决方案上失败,但在更好的解决方案上通过。
(困难)修改您的kvraft实现以允许领导者服务Gets而不通过rsm运行Get。也就是说,实现raft论文第8节末尾描述的优化,包括租约,以确保kvraft保持线性izability。您的实现应该通过现有的kvraft测试。您还应该添加一个测试,检查您的优化实现更快(例如,通过比较RPC的数量)和一个测试,检查术语切换更慢,因为新领导者必须等待租约到期。
(困难)在kvraft中支持事务,以便开发人员可以原子地执行多个Put和Gets。一旦您有了事务,您就不再需要版本化Puts;事务包含版本化Puts。查看etcd的事务以获取示例接口。编写测试以证明您的扩展有效。
(困难)修改shardkv以支持事务,以便开发人员可以跨分片原子地执行多个Puts和Gets。这需要实现两阶段提交和两阶段锁定。编写测试以证明您的扩展有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号