Ceph分层存储分析
最近弄Ceph集群考虑要不要加入分层存储 因此花了点时间研究了下
1,首先肯定要弄清Ceph分层存储的结构 ,结构图大概就是下图所示
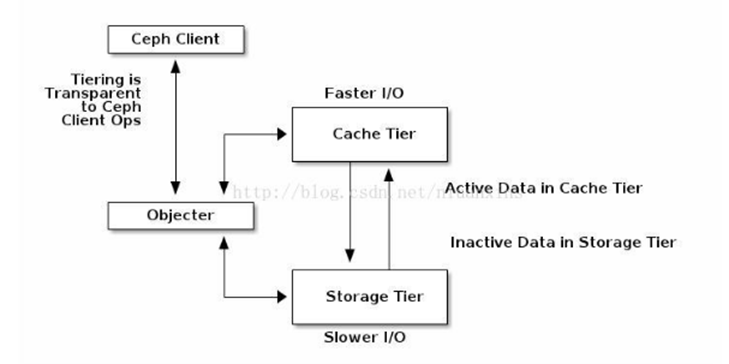
缓存层(A cache tier)为Ceph客户端提供更好的I/O性能,而数据存储在存储层(a backing storage tier)。用相对快速/昂贵的设备(比如SSD)创建pool作为缓存层(A cache tier),用纠删码池或者相对慢速/便宜的设备创建pool作为经济的存储池。Ceph(The Ceph objecter)负责对象存放的位置,分层代理(the tiering agent)确定什么时候把数据对象从缓存层(the cache)存储到存储层(the backing storage tier)。因此对Ceph客户端而言缓存层(the cache tier)和存储层(the backing storage tier)是完全透明的。
2,了解了结构图和基本概念 看到一个关键词 分层代理
所谓分层代理其实就是分层存储数据迁移方案,缓存分层代理负责在缓存层与存储层间的数据的自动迁移,然而管理员有权利配置数据如何迁移 有两种数据迁移模式 在下面附上自己见解
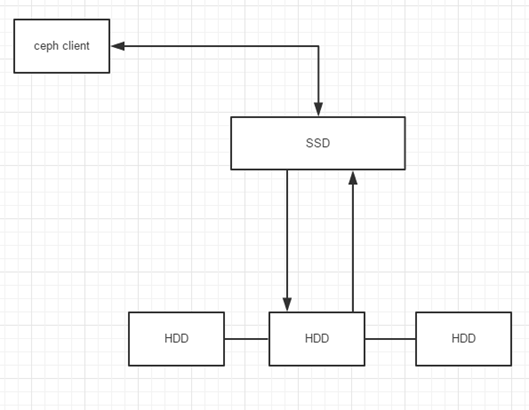
回写模式 :如果管理员配置缓存层为回写模式,CEPH客户端把数据写入缓存层,并且收到缓存层的ACK,写入缓存层的数据随后迁移到存储层,然后从缓存层清除,读取的话如果客户端要读取的数据在存储层,代理会把数据先迁移到缓存层,后再发往客户端,客户端与缓存层进行IO 大概流程如下所示
只读模式:客户端写数据到存储层,读数据的时候,ceph从存储层拷贝需要的数据到缓存层,根据定义好的规则,旧数据从缓存层删除 配上自己大概流程图
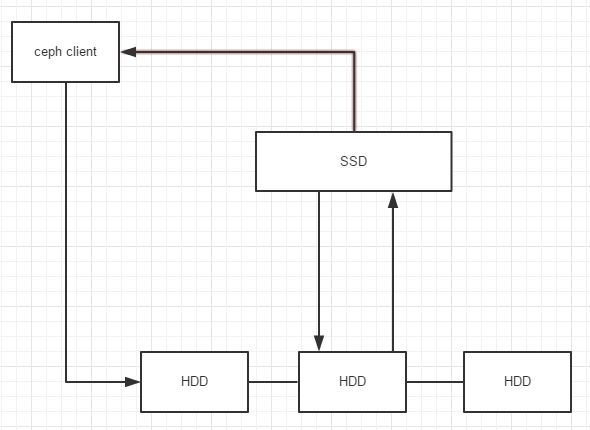
仔细分析两种模式 可以得知 第一种模式客户端只与缓存层进行交互 第二种模式客户端写入时直接与存储层进行交互
为什么进行这种设计,肯定是有不同的应用场景,第一种回写模式主要用于经常变动的数据,第二种只读模式主要用于不经常变动的数据,因为数据是从缓存层读取的,因此数据可能是过时的数据,换一句话说数据是弱一致的,因为客户端写入的时候是不经过缓存层的,缓存层并不能保证数据是最新的 而第一种模式可以保证这一点
3,分层存储的目的和缺点
无疑分层存储的目的在于更好的利用磁盘资源,可以将SSD作为缓冲层,HDD作为后端存储,这样热数据可以在SSD上被快读的读取,大量的冷数据在HDD上存储
个人认为有以下缺点(本人水平为在校研究生 不足之处请指正但请勿喷):
1:使用分层存储可能会引起性能的下降,因为数据要经常移出或读进缓冲,这会增加读取时间,缓冲 的有效应用场景应该是针对大文件,经常读而少写的数据。而且缓存需要足够大。(我们的应用场景是需要经常性频繁的读写小文件,因此觉得这可能不适用)
2:添加缓存层容易引起机制复杂性
3:进行性能测试时会显示出比较差的性能(确定真正的热数据需要昂贵的代价)
因为项目的原因自己有阅读深信服的技术白皮书 看了CEPH的分层存储方案 在这里对深信服的存储技术是怎么做的做一个介绍
1,整体结构
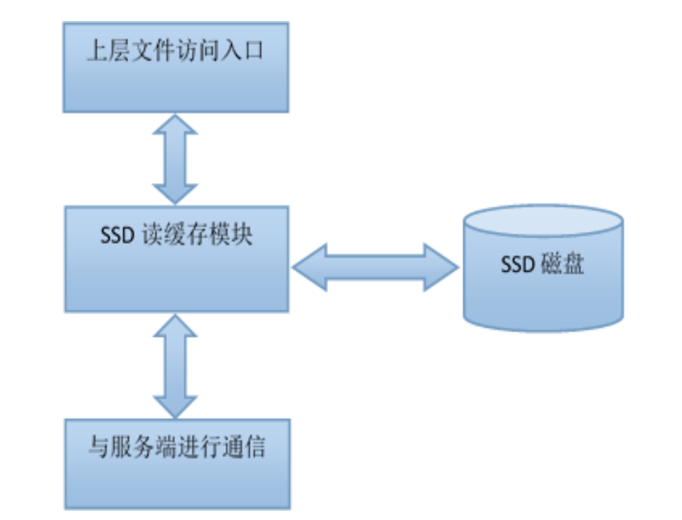

2,首次文件读操作


3,二次文件读操作
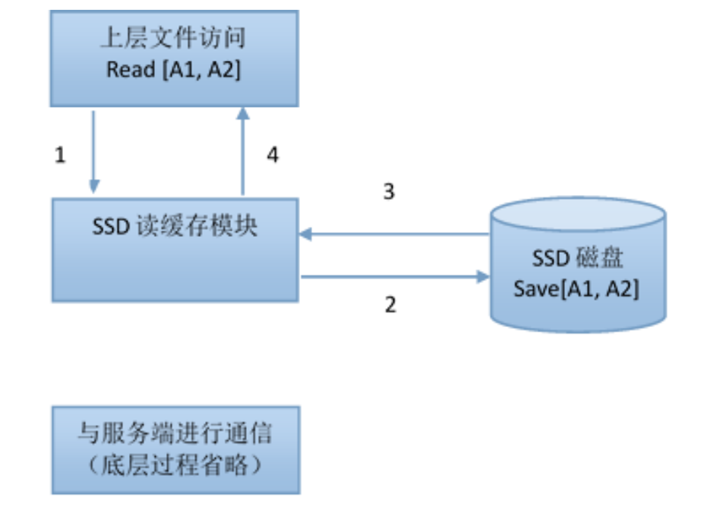

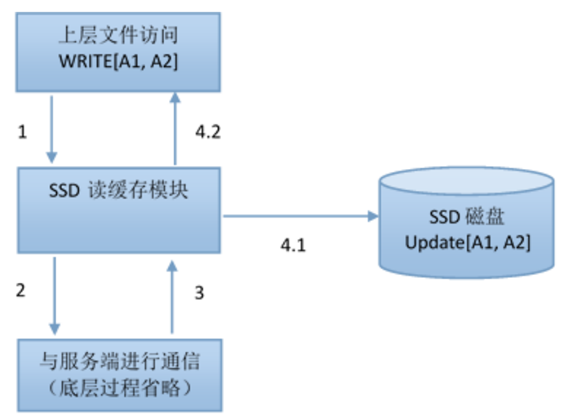
4,文件块首次写预缓存


5,文件块二次写更新缓存

看完深信服的存储方案,自己学习到了很多,无疑它的存储方案更加适用 贴上上述技术纯属分享 如有违权 请联系我我会及时删除 以上内容为自己心得 转载请注明出处


 浙公网安备 33010602011771号
浙公网安备 33010602011771号