
Python函数单元测试以及爬虫的基本实现
一.Python程序函数的测试
Python中有一个自带的单元测试框架是unittest模块,用它来做单元测试,它里面封装好了一些校验返回的结果方法和一些用例执行前的初始化操作。
在说unittest之前,先说几个概念:
TestCase 也就是测试用例
TestSuite 多个测试用例集合在一起,就是TestSuite
TestLoader是用来加载TestCase到TestSuite中的
TestRunner是来执行测试用例的,测试的结果会保存到TestResult实例中,包括运行了多少测试用例,成功了多少,失败了多少等信息
接下来我们就选出一部分代码来进行一个简单的测试
这是一个简单的比赛结束函数,下面我们来测试它是否可用
def gameOver(a,b): if a>=10 and b>=10: if abs(a-b)==2: return True if a<10 or b<10: if a==11 or b==11: return True else: return False
首先我们编写一个
Game.py
class Game(): def __init__(self,a,b): self.a = a self.b = b
再编写一个测试代码
Testgame.py
import unittest from game import Game class GameTest(unittest.TestCase): #一个测试用例 def test_gameOver(self): self = Game('15','13') #要测试的函数 def gameOver(a,b): if a>=10 and b>=10: if abs(a-b)==2: return True if a<10 or b<10: if a==11 or b==11: return True else: return False #运行测试代码 unittest.main()
效果如下
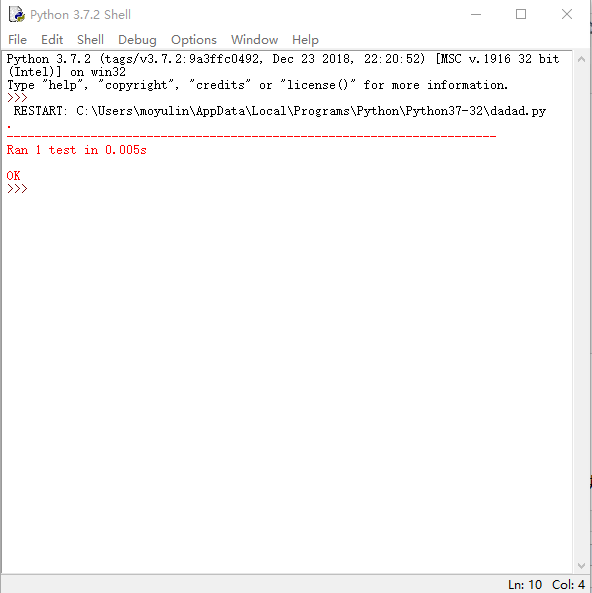
完美运行,此函数无问题。
二.requests库的运用
1.爬虫的基本框架是获取HTML页面信息,解析页面信息,保存结果,requests模块是用于第一步获取HTML页面信息; requests库用于爬取HTML页面,提交网络请求,基于urllib,但比urllib更方便。
2.安装requests库
打开命令行,输入
pip install requests
即可安装
3.下面介绍一些requests库的基本用法
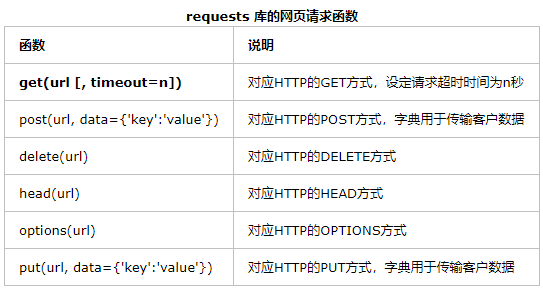
get方法,它能够获得url的请求,并返回一个response对象作为响应。
常见的HTTP状态码:200 - 请求成功,301 - 资源(网页等)被永久转移到其它URL,404 - 请求的资源(网页等)不存在,500 - 内部服务器错误。

4.实例
我们现在用requests库访问搜狗主页20次,并获取一些信息
import requests for i in range(20): r = requests.get("https://www.sogou.com")#搜狗主页 print("网页返回状态:{}".format(r.status_code)) print("text内容为:{}".format(r.text)) print("\n") print("text内容长度为:{}".format(len(r.text))) print("content内容长度为:{}".format(len(r.content)))
代码运行后结果如下

三.BeautifulSoup库的运用
安装方式:
打开命令行,输入
pip install BeautifulSoup4
1.简介
beautifulsoup是一个非常强大的工具,爬虫利器。
beautifulSoup “美味的汤,绿色的浓汤”
一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
2.常用解析库
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,
如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
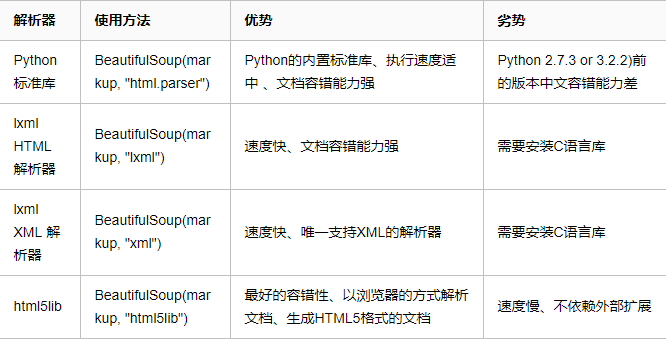
3.基本使用
# BeautifulSoup入门 from bs4 import BeautifulSoup html = ''' <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> ''' soup = BeautifulSoup(html,'lxml') # 创建BeautifulSoup对象 print(soup.prettify()) # 格式化输出 print(soup.title) # 打印标签中的所有内容 print(soup.title.name) # 获取标签对象的名字 print(soup.title.string) # 获取标签中的文本内容 == soup.title.text print(soup.title.parent.name) # 获取父级标签的名字 print(soup.p) # 获取第一个p标签的内容 print(soup.p["class"]) # 获取第一个p标签的class属性 print(soup.a) # 获取第一个a标签 print(soup.find_all('a')) # 获取所有的a标签 print(soup.find(id='link3')) # 获取id为link3的标签 print(soup.p.attrs) # 获取第一个p标签的所有属性 print(soup.p.attrs['class']) # 获取第一个p标签的class属性 print(soup.find_all('p',class_='title')) # 查找属性为title的p # 通过下面代码可以分别获取所有的链接以及文字内容 for link in soup.find_all('a'): print(link.get('href')) # 获取链接 print(soup.get_text())获取文本
(1):标签选择器
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通过这种soup.标签名 我们就可以获得这个标签的内容
这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容。
(2):获取名称
当我们通过soup.title.name的时候就可以获得该title标签的名称,即title。
(3):获取属性
print(soup.p.attrs['name'])
print(soup.p['name'])
上面两种方式都可以获取p标签的name属性值
(4):获取内容
print(soup.p.string)
结果就可以获取第一个p标签的内容。
(5):嵌套选择
我们直接可以通过下面嵌套的方式获取
print(soup.head.title.string)
(6):标准选择器
find_all
find_all(name,attrs,recursive,text,**kwargs)
可以根据标签名,属性,内容查找文档
1.name
html=''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.find_all('ul')) # 找到所有ul标签 print(type(soup.find_all('ul')[0])) # 拿到第一个ul标签 # find_all可以多次嵌套,如拿到ul中的所有li标签 for ul in soup.find_all('ul'): print(ul.find_all('li'))
2.attrs
html=''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.find_all(attrs={'id': 'list-1'})) # 找到id为ilist-1的标签 print(soup.find_all(attrs={'name': 'elements'})) # 找到name属性为elements的标签
注意:attrs可以传入字典的方式来查找标签,但是这里有个特殊的就是class,因为class在python中是特殊的字段,所以如果想要查找class相关的可以更改attrs={'class_':'element'}或者soup.find_all('',{"class":"element}),特殊的标签属性可以不写attrs,例如id。
实例
代码如下
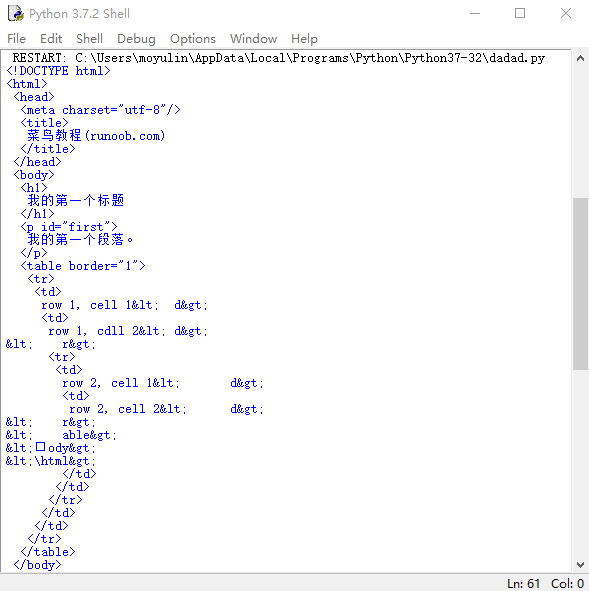
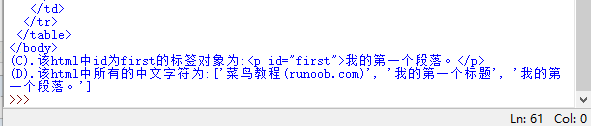
# -*- coding: utf-8 -*- """ Created on Mon May 20 19:33:22 2019 @author: moyulin """ import re from bs4 import BeautifulSoup html = """ <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> <table border="1"> <tr> <td>row 1, cell 1<\td> <td>row 1, cdll 2<\td> <\tr> <tr> <td>row 2, cell 1<\td> <td>row 2, cell 2<\td> <\tr> <\table> <\body> <\html> """ soup = BeautifulSoup(html,"html.parser") print(soup.prettify()) print("(A).该html的head标签内容为\n{}\n03".format(soup.head.prettify())) print("\n") print("(B).该html的body标签内容为\n{}".format(soup.body.prettify())) print("(C).该html中id为first的标签对象为:{}".format(soup.find(id="first"))) print("(D).该html中所有的中文字符为:{}".format(soup.find_all(string = re.compile('[^\x00-\xff]'))))#这里用到正则表达式来找出中文字符串
运行结果为


 浙公网安备 33010602011771号
浙公网安备 33010602011771号