
TextRank算法详细讲解与代码实现(完整)
参考文章:https://www.cnblogs.com/Luv-GEM/p/10884493.html
PageRank
在TextRank之前我们需要先了解一下PageRank算法。事实上它启发了TextRank!PageRank主要用于对在线搜索结果中的网页进行排序。
PageRank对于每个网页页面都给出一个正实数,表示网页的重要程度,PageRank值越高,表示网页越重要,在互联网搜索的排序中越可能被排在前面。
假设整个互联网是一个有向图,节点是网页,每条边是转移概率。网页浏览者在每个页面上依照连接出去的超链接,以等概率跳转到下一个网页,并且在网页上持续不断地进行这样的随机跳转,这个过程形成了一阶马尔科夫链,比如下图:

每个笑脸是一个网页,既有其他网页跳转到该网页,该网页也会跳转到其他网页。在不断地跳转之后,这个马尔科夫链会形成一个平稳分布,而PageRank就是这个平稳分布,每个网页的PageRank值就是平稳概率。
PageRank的核心公式是PageRank值的计算公式。公式如下:
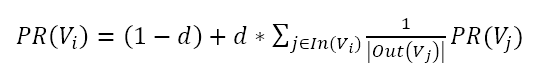
其中,PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合。
这个公式来自于《统计学习方法》,等号右边的平滑项(通过某种处理,避免一些突变的畸形值,尽可能接近实际情况)不是(1-d),而是(1-d)/n。
阻尼系数d(damping factor)的意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。1-d就是用户停止点击,随机跳到新URL的概率。
加平滑项是因为有些网页没有跳出去的链接,那么转移到其他网页的概率将会是0,这样就无法保证存在马尔科夫链的平稳分布。
于是,我们假设网页以等概率(1/n)跳转到任何网页,再按照阻尼系数d,对这个等概率(1/n)与存在链接的网页的转移概率进行线性组合,那么马尔科夫链一定存在平稳分布,一定可以得到网页的PageRank值。
所以PageRank的定义意味着网页浏览者按照以下方式在网上随机游走:以概率d按照存在的超链接随机跳转,以等概率从超链接跳转到下一个页面;或以概率(1-d)进行完全随机跳转,这时以等概率(1/n)跳转到任意网页。
PageRank的计算是一个迭代过程,先假设一个初始的PageRank分布,通过迭代,不断计算所有网页的PageRank值,直到收敛为止,也就是:

这篇文章里有详细的例子:https://www.cnblogs.com/cuiyubo/p/10175268.html
TextRank
两种算法的相似之处:
- 用句子代替网页
- 任意两个句子的相似性等价于网页转换概率
- 相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
不过公式有些小的差别,那就是用句子的相似度类比于网页转移概率,用归一化的句子相似度代替了PageRank中相等的转移概率,这意味着在TextRank中,所有节点的转移概率不会完全相等。

TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
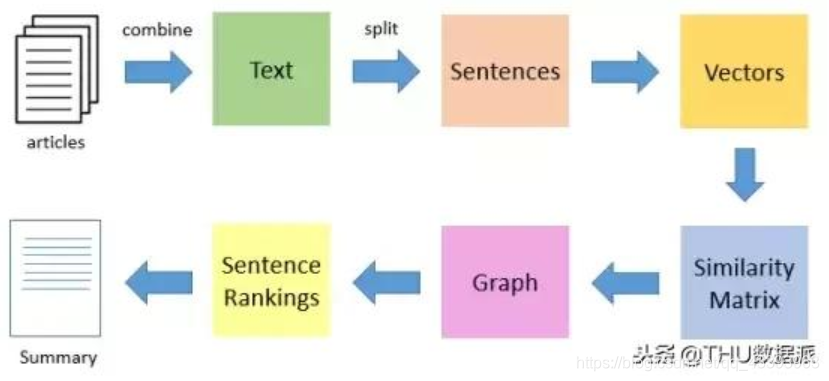
代码实现
1.爬取中国党员网上一篇文章并保存
import requests
from lxml import html
etree=html.etree
url='http://news.12371.cn/2013/01/28/ARTI1359357184590944.shtml'
data=requests.get(url)
data.encoding='utf-8'
#print(data)
s=etree.HTML(data.text)
text1=s.xpath('//*[@id="font_area"]/p/text()')#得到的文本是一个列表,里面有6项,代表6个自然段
title=s.xpath('/html/head/title/text()')[0].strip()#[0]是取标题的第一项,trip()去掉首尾空格
print("爬取文本:\n","标题:",title,"\n正文:",text1)
text=""
# 将得到的文本写入文件
for i in range(0,len(text1)-1):
text+=text1[i]
sentence_list=[]
print(text)
title=title+'.txt'
with open(title, 'w', encoding='utf-8') as f:
f.writelines(text)
2.打开文件:
import numpy as np
import re,jieba
from itertools import chain
#打开文件
sentences_list = []
file_path='吴邦国重申:中国坚持和平发展道路不会因国力地位变化而改变.txt'
fp = open(file_path,'r',encoding="utf8")
for line in fp.readlines():
if line.strip():
# 把元素按照[。!;?]进行分隔,得到句子。
line_split = re.split(r'[。!;?]',line.strip())
# [。!;?]这些符号也会划分出来,把它们去掉。
line_split = [line.strip() for line in line_split if line.strip() not in ['。','!','?',';'] and len(line.strip())>1]
sentences_list.append(line_split)
sentences_list = list(chain.from_iterable(sentences_list))
print("前10个句子为:\n")
print(sentences_list[:10])
print("句子总数:", len(sentences_list))
输出:
前10个句子为:
['亚太地区影响最大的议会间组织——亚太议会论坛28日召在符拉迪沃斯托克召开年会', '中国全国人大常委会委员长吴邦国在与会发言中重申,坚持和平发展道路是中国基于时代发展潮流和自身根本利益作出的战略抉择,不会因为综合国力和国际地位的变化而改变', '亚太议会论坛成立于1993年,拥有中国、俄罗斯、美国等27个成员国', '年会是这个论坛的最高决策机构,每年轮流在太平洋两岸举行', '据了解,本届年会为期3天,与会代表将围绕地区安全、经济贸易、区域合作等议题进行坦诚对话', '吴邦国在年会主旨发言中阐述了中方在事关亚太地区和平发展重大问题上的原则主张', '他指出,促进亚太地区和平合作发展,是亚太各国的共同责任,各方要从战略高度审视地区形势和彼此关系,努力扩大共识、付诸行动', '“我们要摒弃冷战思维和零和博弈观念,相互尊重彼此主权和核心利益,推动建立公平有效的地区安全机制', '要积极推动高新技术、先进制造、节能环保、能源资源、现代农业等领域务实合作,反对各种形式的保护主义,推动贸易和投资自由化、区域经济一体化', '要尊重文明多样性,尊重各国人民自主选择的发展道路,促进不同文明和社会制度相互交流借鉴,推动亚太多元文明共同进步']
句子总数: 19
3.分词,这里的停用词用的网上的,很容易搜到
#加载停用词
stoplist= [word.strip() for word in open('stopwords.txt',encoding='utf-8').readlines()]
# print(stoplist)
# 对句子进行分词
def seg_depart(sentence):
# 去掉非汉字字符
sentence = re.sub(r'[^\u4e00-\u9fa5]+','',sentence)
sentence_depart = jieba.cut(sentence.strip())
word_list = []
for word in sentence_depart:
if word not in stoplist:
word_list.append(word)
# 如果句子整个被过滤掉了,如:'02-2717:56'被过滤,那就返回[],保持句子的数量不变
return word_list
sentence_word_list = []
for sentence in sentences_list:
line_seg = seg_depart(sentence)
sentence_word_list.append(line_seg)
print("一共有",len(sentences_list),'个句子。\n')
print("前10个句子分词后的结果为:\n",sentence_word_list[:10])
# 保证处理后句子的数量不变,我们后面才好根据textrank值取出未处理之前的句子作为摘要。
if len(sentences_list) == len(sentence_word_list):
print("\n数据预处理后句子的数量不变!")
输出:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\To\AppData\Local\Temp\jieba.cache
Loading model cost 0.990 seconds.
Prefix dict has been built succesfully.
一共有 19 个句子。
前10个句子分词后的结果为:
[['亚太地区', '影响', '议会', '间', '组织', '亚太', '议会', '论坛', '日召', '符拉迪沃斯托克', '年会'], ['中国', '全国人大常委会', '委员长', '吴邦国', '与会', '发言', '中', '重申', '和平', '发展', '道路', '中国', '时代', '发展', '潮流', '根本利益', '作出', '战略', '抉择', '综合国力', '国际', '地位', '变化', '改变'], ['亚太', '议会', '论坛', '成立', '拥有', '中国', '俄罗斯', '美国', '成员国'], ['年会', '论坛', '决策机构', '轮流', '太平洋', '两岸'], ['本届', '年会', '为期', '天', '与会代表', '围绕', '地区', '经济', '贸易', '区域合作', '议题', '坦诚', '对话'], ['吴邦国', '主旨', '发言', '中', '阐述', '中方', '事关', '亚太地区', '和平', '发展', '原则'], ['指出', '亚太地区', '和平', '合作', '发展', '亚太', '各国', '责任', '各方', '战略', '高度', '审视', '地区', '形势', '关系', '努力', '共识', '付诸行动'], ['摒弃', '冷战', '思维', '博弈', '观念', '相互尊重', '主权', '核心', '利益', '推动', '建立', '公平', '地区', '机制'], ['推动', '高新技术', '先进', '制造', '节能', '环保', '能源', '资源', '现代农业', '领域', '务实', '合作', '反对', '形式', '保护主义', '推动', '贸易', '投资', '自由化', '区域', '经济', '一体化'], ['尊重', '文明', '多样性', '尊重', '各国', '自主', '选择', '发展', '道路', '文明', '社会制度', '相互', '交流', '借鉴', '推动', '亚太', '多元', '文明', '共同进步']]
数据预处理后句子的数量不变!
4.利用word2vec生成词向量
Word2Vec之类的模型,准确来说应该是“自监督”的,它事实上训练了一个语言模型,通过语言模型来获取词向量。
所谓语言模型,就是通过前个字预测下一个字的概率,就是一个多分类器而已,我们输入one hot,然后连接一个全连接层,然后再连接若干个层,最后接一个softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是字、词向量表,当然,Word2Vec还做了大量的简化,但是那都是在语言模型本身做的简化,它的第一层还是全连接层,全连接层的参数就是字、词向量表。
#求句子最大长度
maxLen=0
for sentence in sentences_list:
length=0
for wd in sentence:
length=length+1
if (length>maxLen):maxLen=length
#fit_on_texts函数可以将输入的文本中的每个词编号,
#编号是根据词频的,词频越大,编号越小
from keras.preprocessing.text import Tokenizer
tokenizer=Tokenizer()
tokenizer.fit_on_texts(sentence_word_list)
vocab = tokenizer.word_index # 得到每个词的编号
print(vocab)
输出:
{'发展': 1, '中国': 2, '议会': 3, '和平': 4, '推动': 5, '亚太': 6, '吴邦国': 7, '战略': 8,
'国家': 9, '亚太地区': 10, '论坛': 11, '年会': 12, '中': 13, '道路': 14, '地区': 15,
'努力': 16, '领域': 17, '文明': 18, '间': 19, '发言': 20, '时代': 21, '潮流': 22,
'根本利益': 23, '作出': 24, '抉择': 25, '综合国力': 26, '国际': 27, '地位': 28, '变化': 29,
'改变': 30, '经济': 31, '贸易': 32, '对话': 33, '合作': 34, '各国': 35, '关系': 36,
'主权': 37, '尊重': 38, '交流': 39, '发挥': 40, '作用': 41, '互利': 42, '外交政策': 43,
'对外开放': 44, '解决': 45, '始终不渝': 46, '奉行': 47, '影响': 48, '组织': 49,
'日召': 50, '符拉迪沃斯托克': 51, '全国人大常委会': 52, '委员长': 53, '与会': 54,
'重申': 55, '成立': 56, '拥有': 57, '俄罗斯': 58, '美国': 59, '成员国': 60,
'决策机构': 61, '轮流': 62, '太平洋': 63, '两岸': 64, '本届': 65, '为期': 66,
'天': 67, '与会代表': 68, '围绕': 69, '区域合作': 70, '议题': 71, '坦诚': 72,
'主旨': 73, '阐述': 74, '中方': 75, '事关': 76, '原则': 77, '指出': 78, '责任': 79,
'各方': 80, '高度': 81, '审视': 82, '形势': 83, '共识': 84, '付诸行动': 85,
'摒弃': 86, '冷战': 87, '思维': 88, '博弈': 89, '观念': 90, '相互尊重': 91,
'核心': 92, '利益': 93, '建立': 94, '公平': 95, '机制': 96, '高新技术': 97,
'先进': 98, '制造': 99, '节能': 100, '环保': 101, '能源': 102, '资源': 103,
'现代农业': 104, '务实': 105, '反对': 106, '形式': 107, '保护主义': 108,
'投资': 109, '自由化': 110, '区域': 111, '一体化': 112, '多样性': 113, '自主': 114,
'选择': 115, '社会制度': 116, '相互': 117, '借鉴': 118, '多元': 119, '共同进步': 120,
'政治': 121, '生活': 122, '成员': 123, '应': 124, '敦促': 125, '支持': 126, '本国': 127,
'政府': 128, '实施': 129, '有利于': 130, '赢': 131, '各层次': 132, '交往': 133,
'建设性': 134, '力量': 135, '推进': 136, '成就': 137, '举世瞩目': 138, '面临': 139,
'矛盾': 140, '挑战': 141, '世所': 142, '罕见': 143, '关键': 144, '一心一意': 145,
'谋发展': 146, '共赢': 147, '开放': 148, '广': 149, '高层次': 150, '走': 151, '坚定': 152,
'独立自主': 153, '这是': 154, '大小': 155, '强弱': 156, '贫富': 157, '一律平等': 158,
'干涉': 159, '别国': 160, '内政': 161, '永不': 162, '称霸': 163, '和平谈判': 164,
'方式': 165, '周边': 166, '邻国': 167, '历史': 168, '遗留': 169, '陆地': 170,
'边界问题': 171, '妥善处理': 172, '岛屿': 173, '海洋权益': 174, '争端': 175,
'和平解决': 176, '国际争端': 177, '热点问题': 178, '负责': 179, '大国': 180}
简要介绍一下word2vec模型参数含义
-
sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
-
size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
-
window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
-
sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
-
hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
-
negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
-
cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
-
min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
-
iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
-
alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
-
min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
word2vec的训练:
# 设置词语向量维度
num_featrues = 300
# 保证被考虑词语的最低频度,对于小语料,设置为1才可能能输出所有的词,因为有的词可能在每个句子中只出现一次
min_word_count = 1
# 设置并行化训练使用CPU计算核心数量
num_workers =4
# 设置词语上下文窗口大小
context = 5
#开始训练
model = word2vec.Word2Vec(sentence_word_list, workers=num_workers, size=num_featrues, min_count=min_word_count, window=context)
model.init_sims(replace=True)
'''
# 如果有需要的话,可以输入一个路径,保存训练好的模型
model.save("w2vModel1")
print(model)
#加载模型
model = word2vec.Word2Vec.load("w2vModel1")
'''
5.利用训练后的word2vec自定义Embedding
word_embeddings = {}
count=0
for word, i in vocab.items():
try:
# model.wv[word]存的就是这个word的词向量
word_embeddings[word] =model.wv[word]
except KeyError:
continue
print('输出了:',count,'个词')
6.得到词语的embedding,用WordAVG作为句子的向量表示
sentence_vectors = []
for line in sentence_word_list:
if len(line)!=0:
# 如果句子中的词语不在字典中,那就把embedding设为300维元素为0的向量。
# 得到句子中全部词的词向量后,求平均值,得到句子的向量表示
#TypeError: type numpy.ndarray doesn't define __round__ method,将round改为np.round
v = np.round(sum(word_embeddings.get(word, np.zeros((300,))) for word in line)/(len(line)))
else:
# 如果句子为[],那么就向量表示为300维元素为0个向量。
v = np.zeros((300,))
sentence_vectors.append(v)
7.开始干正事
#计算句子之间的余弦相似度,构成相似度矩阵
sim_mat = np.zeros([len(sentences_list), len(sentences_list)])
from sklearn.metrics.pairwise import cosine_similarity
for i in range(len(sentences_list)):
for j in range(len(sentences_list)):
if i != j:
sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,300), sentence_vectors[j].reshape(1,300))[0,0]
print("句子相似度矩阵的形状为:",sim_mat.shape)
#迭代得到句子的textrank值,排序并取出摘要"""
import networkx as nx
# 利用句子相似度矩阵构建图结构,句子为节点,句子相似度为转移概率
nx_graph = nx.from_numpy_array(sim_mat)
# 得到所有句子的textrank值
scores = nx.pagerank(nx_graph)
# 根据textrank值对未处理的句子进行排序
ranked_sentences = sorted(((scores[i],s) for i,s in enumerate(sentences_list)), reverse=True)
# 取出得分最高的前3个句子作为摘要
sn = 3
for i in range(sn):
print("第"+str(i+1)+"条摘要:\n\n",ranked_sentences[i][1],'\n')
输出:
第1条摘要:
要积极推动高新技术、先进制造、节能环保、能源资源、现代农业等领域务实合作,反对各种形式的保护主义,推动贸易和投资自由化、区域经济一体化
第2条摘要:
要尊重文明多样性,尊重各国人民自主选择的发展道路,促进不同文明和社会制度相互交流借鉴,推动亚太多元文明共同进步
第3条摘要:
推动和平解决国际争端和热点问题,发挥负责任大国作用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号