压缩 70% 下载流量 - 记一次店铺优化专项
一、名词解释
- ISV(Independent Software Vendors),独立软件开发商。一般是独立的第三方公司,公司有专业的设计师和程序员,为付费的商家提供一对一的定制化开发。
- imageX(图床):公司提供的图片存储、CDN 分发和图片动态处理的云服务,返回一个图片 url,可以在 url 上增加参数实现图片的实时转码、裁切、缩放等功能。社区也有一些图片托管商提供类似的服务。
- TOS(Tinder Object Storage):公司提供的一个对象存储服务。社区也有一些类似的解决方案,如 OSS。
- DevBox:公司给员工提供的一台 linux 服务器,可以通过内网 ssh 访问。
- B 端:指商家操作的后台,PC 端网页,基本 Chromium-only。
- C 端:指消费者浏览的页面,在手机 App 内运行。
二、背景
店铺开放 ISV 链路后,随着头部商家的全页定制化的增加,性能问题受到越来越多的关注,我们针对 ISV 开发的页面,做了系统性的诊断,并沉淀出一系列优化 TODO,本文主要介绍图片优化子项目(一定要看到最后,相信一定有收获)。
1. 优化前后对比
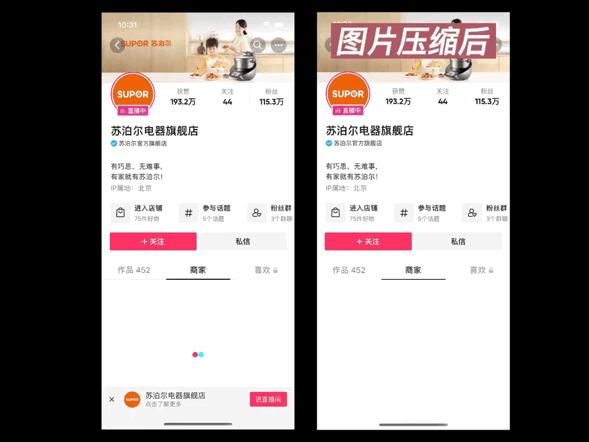
可以看到,在图片的首次加载时,优化效果比较明显。
2. 图片对比
我们随机抽取了几张线上图片做对比:
以下图片是无损 PNG 截图效果,以便准确对比。

可以看到,对原图转 JPG 有明显的收益,转 WebP 收益更大。离线压缩收益比在线转 JPG 略高,对离线压缩后的图片再进行在线转 WebP 仍能得到压缩收益。
三、各方案对比
1. 为什么会存在大体积图片?
- 这个是产品形态的原因,我们一直反对在上传侧对用户做各种反人类的限制。粗暴地限制不得大于 xxKB ,会造成用户好不容易导出一张图片,最后告诉用户无法上传,流程被粗暴打断。商家负责运营的同学和设计师可能是不同角色。运营处理图片,可能发生不专业的事,文章后面会讲到。另外针对不同大小的图片,使用统一的体积限制也不科学。
2. 为什么不直接使用 WebP?
- 我们可以看到,对于原图,直接拼 .png 后缀压缩率没有明显优化,由于要考虑到原图可能有透明通道,不能直接转 JPG。但拼 .webp 后缀后,优化已经很明显。但为什么我们不直接使用 WebP 图片呢,主要以下几个原因:
- 兼容性问题,需要做成运行时。 WebP 有一定的兼容性问题,我们必须做成运行时 SDK 在端上判断,才能决定是否启用 WebP。这个 SDK 我们有提供给 ISV SDK,但并没有很高的覆盖率。

- 历史原因,早期图床使用 TOS。 早期我们的图片存储在 tos 上,并不支持 imageX,后期才支持 imageX。由于早期并没有接入 imageX,所以早期 SDK 版本也没有实现动态转 WebP。自然地一开始也没有让 ISV 强行接入我们的图片加载 SDK。
- 存量版本的碎片化问题。 从一开始的开放链路架构设计上,我们就设计了需要一定程度容忍 ISV 模块版本的碎片化问题。因为我们需要把风险降低到最小,没法保证所有 ISV 开发的模块都有健壮的向后兼容能力,故不能在商家不预览验证的情况下一键升级全量商家的线上模块。这使得我们线上不同商家可能使用的同一模块的不同版本。技术上,我们也无法入侵早期的模块版本,通过字符串替换的方式,把图片都包上我们的图片加载 SDK。
3. 为什么不使用端拦截方案?
- 端上需要对每一个图片请求进行拦截,这个会劣化所有的图片网络请求。
- 另外随端发版的问题,会让这个功能变得碎片化,对于存量的老版本客户端感受不到收益,对于前端来说,会成为历史包袱,需要长期考虑向后兼容问题。
4. 为什么不在 C 端后端接口下发时对图片进行 WebP 链接替换?
- C 端的接口在返回时的确可以知道端上是否支持 WebP,但下图是我们的数据结构,我们允许 ISV 自定义 JSON 结构,这个对于 C 端是只能作为字符串理解的,无法替换里面的图片:

- 这个也不能使用正则进行替换,下文会讲到。
5. 为什么不在 B 端创建页面的时候进行图片替换?
- B 端装修时是可以感知到这个结构的,理论上是可以做替换的,这个也是我们后面对增量图片进行优化会做的方案。现阶段,我们要解决存量图片的问题,这个方案需要商家重新发布,优化覆盖率上不去。
四、结论
综上,我们最终决定对于存量和增量图片分别进行处理。首页我们要解决存量的问题,提升整个大盘的水位,再解决增量问题,保持优化效果。
对于存量图片, 我们的结论是进行数据库替换,遍历所有数据库里的图片,进行下载、离线压缩、上传、得到新 url 再回写回数据库。
对于增量图片, 先做临时性卡口,和产品达成一致,先做粗暴的体积限制,不准商家上传大于 500Kb 的图片。如果不做这样的卡口,就会一边出水一边放水,永远动态清不了零了。在后续上线了 B 端创建页面时对图片进行压缩能力后,再把临时卡口放开。
五、具体方案与踩坑总结
离线清洗数据说起来简单,但其实是个高风险的操作。本着追求极致和务实敢为的态度,我们最终还是决定尝试一下。这个我们和后端同学进行了详细的技术评审,并设计了周全的预案以保万无一失。本文主要说下这里面遇到的问题和解法:
原理并不复杂,主链路只有以下四步,不过坑倒是有不少。
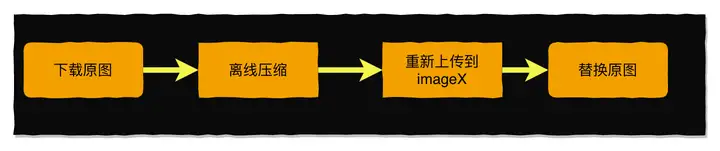
1. 数据结构的设计
为什么要设计数据结构?因为要防止图片被二次压缩导致失真,需要把图片压缩的相关信息存储。在这里我们定义了一个简单的数据结构。这里有三个 md5 的 hash 值,便于将图片作为 url 或本地文件查询时快速找到对应的压缩数据。
interface IImageMinyfyMappingJSON {
width: number // 图片宽度
height: number // 图片高度
hash: string // 图片 url 的 hash,md5(rawUrl)
rawExtname: '.jpg' | '.png' | '.gif' // 压缩前图片扩展名
rawImageHash: string // 压缩前图片 md5 值
rawSize: number // 压缩前图片大小(字节)
rawUrl: string // 原图片 url
newExtname: '.jpg' | '.png' | '.gif' // 压缩后图片扩展名
newImageHash: string // 压缩后图片体积
newSize: number // 压缩后图片大小(字节)
newUrl: string // 压缩后图片地址
}数据存储在 tos 上,没有使用数据库是因为这是一个低频操作,tos 具有更好的稳定性,也不用自己考虑负载问题。
2. 下载图片
这是一张 imageX 返回的图片地址:
我们可以看到 imageX 的图片都是不带扩展名的,都叫 .image,这使得下载时无法提前知道图片类型(其实也能通过 HTTP Header 的 MIME 信息,但这要多一次 header 请求,得不尝失)。所以这里使用的下载方式是先以随机数命名,再使用 md5(rawUrl) + rawExtname 重命名。
export const downloadImage = async (httpUrl: string, outputDir: string):Promise<string> => {
const tmpPath = path.join(outputDir, `.tmp_${Date.now()}${Math.random()}${Math.random()}${Math.random()}`)
try {
fs.ensureDirSync(outputDir)
spawnSync(`wget -O ${tmpPath} ${httpUrl}`, { stdio: 'inherit', shell: true })
const imageHash = md5(fs.readFileSync(tmpPath))
const { ext } = await fileTypeFromFile(tmpPath) as FileTypeResult
const dest = path.join(outputDir, imageHash + '.' + ext)
// 允许同名覆盖,有可能同一张图片多次在不同场景下上传,这时 md5 算出来是一样的。另外,确保函数多次执行是幂等的
fs.moveSync(tmpPath, dest, { overwrite: true })
return dest
} catch (e) {
fs.removeSync(tmpPath)
throw e // 抛错很重要,不要随便把错误吃掉,后面会说
}
}- 这里踩到一个坑:一开始直接以 Math.random() 作为临时文件名,但这个在多次独立执行后是有可能碰撞到相同的随机数的,详见 JS 随机数生成算法(关键这篇文章也是我写的,允悲,还是太自信 V8 的伪随机生成了)。后来加了时间戳和 3 个随机数降低碰撞。更科学的方式应该使用标准的 uuid 生成库,它还会考虑机器 mac 地址等信息,进一步减少多机器独立事件的碰撞概率。
- 图片扩展名推断使用了 file-type 库。
- 使用 wget 下载图片是因为 wget 支持同步下载(node 里没有同步网络 io 的方法),最主要的是 wget 支持断点续传和进度展示。
3. 压缩算法的选择
对于不同图片,使用的压缩算法是需要不同的,这里对比了几种不同的压缩算法,最终如下:
以下图片是无损 PNG 截图效果,以便准确对比。
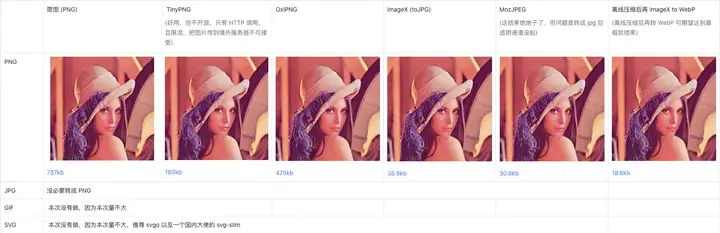
综上调研,我们决定压缩逻辑如下:
- JPG 直接用 MozJPEG 压缩
- PNG 如果 含有透明通道,使用 OxiPNG,否则使用 MozJPEG
- 如果压缩后的图片比原图大,放弃,使用原图
- 其他图片,跳过
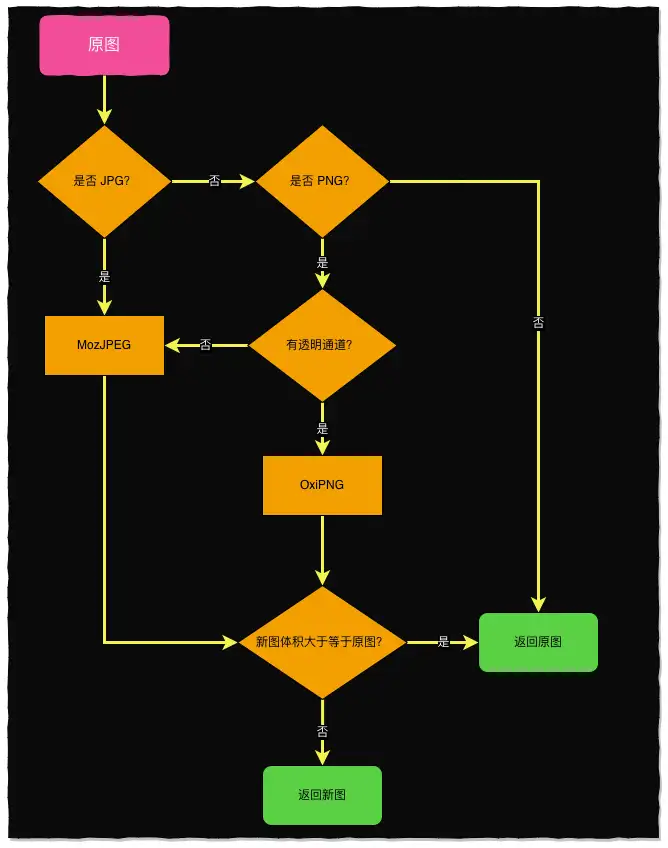
综上,核心的优化点是把无透明通道的 PNG 转成 JPG。这里不得不研究下 PNG 图片的详细定义:(摘自维基百科)
便携式网络图形(英语:Portable Network Graphics,PNG)是一种支持无损压缩的位图图形格式,支持索引、灰度、RGB 三种颜色方案以及 Alpha 通道等特性。PNG 的开发目标是改善并取代 GIF 作为适合网络传输的格式而不需专利许可,所以被广泛应用于互联网及其他方面上。
PNG 另一个非正式的名称来源为递归缩写:“PNG is Not GIF”。PNG 的官方念法是“平”(/pɪŋ/),但是多数人是当成三个英文字母分开读。
PNG 图片大多数都使用PNG作为扩展名,其互联网媒体类型为image/png。PNG 于 1997 年 3 月作为知识性 RFC 2083 发布,于 2004 年作为 ISO/IEC 标准发布。
PNG 图片主要由三种类型存储:
- PNG 8:图片使用 8 bits 来存储,可以用 2 的 8 次方大小个种类颜色来存储一张黑白的图片。也就是说 PNG 8 能存储 256 中颜色,因为颜色少,文件体积也非常小,一张图片如果颜色简单,将它设置成 PNG 8 得图片是非常省空间合适的。
- PNG 24:图片使用 24bits 来存储,用三个 8bits 分别去表示 R(红)、G(绿)、B(蓝)三个通道(Channel)的数值。可以表达 256 乘以 256 乘以 256=16777216 种颜色的图片,色彩丰富度更高,但相对的所占用的空间也就更大了。
- PNG 32:图片使用 32bits 来存储,相当于 PNG 24 加上 8bits 的透明颜色通道,总共有 R(红)、G(绿)、B(蓝)、A(透明)四个通道。图片能表示的色彩跟 PNG 24 一样多,并且还支持 256 种透明度,能让图片色彩更加丰富。
注意这里一簇叫 APNG,扩展名通常也以 .png 结尾,这类图片不能用 OxiPNG 压缩,会丢失动画。使用 imageX 也不能转换成 WebP,同样会丢失动画。

注意这张图原图是 APNG , 但知乎文章里不支持展示,这里实际放的是 GIF 录屏(「萌」混过关 ),查看原图可以复制以下链接到浏览器:https://p1-ecom-qualification.byteimg.com/tos-cn-i-tsivw11p2g/545cb9abb2ee4256a13235a5e6dfd3e1~tplv-tsivw11p2g-image.png
好在 file-type 库会把它识别成扩展名 apng

所以对 PNG 的处理逻辑是:
- 如果是 APNG,跳过,返回原图
- 再检测是否含有透明通道,决定能不能转 JPG
const isTransparentPng = (pngPath: string, limit = 255) => {
if (path.extname(pngPath) !== '.png') return false
if (cache[pngPath]) return cache[pngPath]
const buffer = fs.readFileSync(pngPath)
// 图片的宽度存在buffer的第17到20个字节
const width = buffer.readUInt32BE(16)
// 图片的宽度存在buffer的第21到24个字节
const height = buffer.readUInt32BE(20)
const pngCanvas = canvas.createCanvas(width, height)
const context = pngCanvas.getContext('2d')
const img = new canvas.Image()
img.src = buffer
// node 端实际同步的,使不使用 onload 回调没有区别
context.drawImage(img, 0, 0, width, height)
// 获取 PNG 图片的数据的像素数据
const res = context.getImageData(0, 0, width, height)
const imgData = res.data
const piexCount = imgData.length / 4
let isOpacity = false
for (let i = 0; i < piexCount; i++) {
const opacity = imgData[i * 4 + 3]
if (opacity < limit) {
// 如果小于limit,则存在透明像素,退出
isOpacity = true
break
}
}
cache[pngPath] = isOpacity
return isOpacity
}判断透明度这里用的 node-canvas 库,比较慢(比起网络 io,这真算不上啥了),传原我厂大佬的 rust-canvas 有更好的性能,这里没来得及尝试,考虑到成熟度风险还是用了比较主流的库。
4. 上传图片
这里没有太多可说的,主要调用 imageX 的 HTTP 接口进行的上传。同时,还会上传一份流程 1 中产出的 mapping 到 TOS。
5. 数据回写
回写数据库是一个高风险且复杂的事。先看我们的数据库里的结构:

- 商家搭建页面的每一个楼层,在我们这里是一条物料数据,一个物料由多个原子组件构成。对于后端来说是一个 string,入库前有结构体检测,但落库后存储在数据库里是一个 JSON string,对这个数据,后端无法直接进行回写。
- 目前我们有 20 多种原子组件类型。如果针对每一种原子组件类型进行入库逻辑编写,会使这个洗数据的工作量变得过于浩大。
- 高阶 JSON: 我们允许 ISV 自定义复杂的数据结构,对平台来说是一个 string 类型,这造成了我们物料里有二阶、三阶 JSON(即 JSON string 里还有 JSON string)。前面说到 C 端的后端不能直接正则替换也是这个原因,有可能造成转译符不匹配,JSON 对于字面量的完整度要求非常高。

所以这里使用了一种深度优先的遍历方式,不去理解 JSON 结构体的业务逻辑,而是逐级向下展开(JSON.parse)再逐级向上还原(JSON.stringify)。
// 核心函数,onEach 函数会返回三个形参,当前值 val,key 和父亲 parent
// 因为 js 里是址引用,直接给 val 赋值不能改变原数据,要用 parent[key] 进行修改
export const walkIsvJSONSync = (data: any, onEach?: (value: any, key: string, parent: any) => void) => {
const _walk = (data: any) => {
jsonuri.walk(data, (val, key, parent) => {
onEach?.(val, key, parent)
if (isJSONString(val)) {
const data = JSON.parse(val)
_walk(data)
parent[key] = JSON.stringify(data)
}
})
}
_walk(data)
}
// 封装后的方法调用,更换图片
export const changeImages = (data: any, imagesMap: Record<string, string>) => {
walkIsvJSONSync(data, (val, key, parent) => {
if (isImage(val)) {
const newImage = imagesMap[val]
if (isImage(newImage)) {
parent[key] = newImage
}
}
})
}
// isImage 函数
const IMAGE_REG = /^(?:https?:)?//.*.(?:image|png|jpg|jpeg|gif)$/
const isImage = (url: string) => {
if (typeof url !== 'string') return false
return IMAGE_REG.test(url)
}
// isJSONString 函数,只把[] 和{} 类型的视为 JSON
const isJSONString = (str: any) => {
if (typeof str !== 'string') return false
if (!(str.startsWith('[') || str.startsWith('{'))) return false
if (str === '{}' || str === '[]') return false // 空数据也跳过
try {
// 这里的判断比较保守
return equal(JSON.parse(str), JSON.parse(JSON.stringify(JSON.parse(str))))
} catch (e) {
return false
}
}JSONURI 是本人早年在搭建场景中抽象的一个工具库,核心逻辑是用类 linux 路径来描述数据结构,以便在遍历过程中轻松访问和操作祖先和叔侄节点。这里主要使用了里面的 jsonuri.walk 方法。
六、监控和保障
线上的数据清洗一旦出错,我估计也就领盒饭了,所以这里做了一系列保障。主要包括:
- 图片替换的安全性对比,比如把 A 商家的数据换成了 B 商家,必须不能出错。
- 图片替换质量需要能接受,不能出现不能接受的模糊和失真。
- 线上监控和快速回滚能力。
1. UI 工具,人肉比较
a. 多图对比工具
对压缩前后图片做了 ui 界面,左边是原图,右边是离线压缩后的。左右图片高度是自适应,这样如果发现两列高度不一致,就确定一定有图片压错了(充分条件)。
b. 单图对比工具

c. 图片相似度算法
没法通过肉眼对比所有图片,我还有很多 bug 要写呢。作为必要补充,加上了图片相似度检测。
这里使用的是 SSIM(Structural Similarity Index Measure)算法:
SSIM 算法源自王舟教授的一篇引用近 4w+ 的论文 《图像质量评估:从错误可见性到结构相似性》,在图像识别和广电媒体中得到了广泛应用,是很多做 CV 领域同学的必读论文。
SSIM 返回一个 0 到 1 的值,越接近 1 表示越相似。
下图中 5 张爱因斯坦图像与原图有接近的均方误差(MSE),但 SSIM 有明显的不同,SSIM 指标更接近人眼直觉。

SSIM 论文不长,硬着头皮可以啃一啃。SSIM 算法的核心原理是认为自然界的图像像素与像素之间有很强的统计相关性。

这里没有自己手撸实现,而是用了现成的 SSIM 的 JS 实现库 ssim.js,对于相似度大于 0.95 的放过。
import path from 'path'
import ssim from 'ssim.js'
import imageSize from 'image-size'
import canvas from 'canvas'
import url from 'url'
import fs from 'fs-extra'
const __dirname = url.fileURLToPath(new URL('.', import.meta.url))
const getData = async (url: string) => {
const {width = 0, height = 0} = imageSize(url)
const buffer = fs.readFileSync(url)
const cvs = canvas.createCanvas(width, height)
const context = cvs.getContext('2d')
const img = new canvas.Image()
img.src = buffer
context.drawImage(img, 0, 0, width, height)
const { data } = context.getImageData(0, 0, width, height)
return {
data,
width,
height,
}
}
;(async () => {
const [img1, img2] = await Promise.all([
getData(path.join(__dirname, '1.jpg')),
getData(path.join(__dirname, '2.jpg'))
])
const { mssim, performance } = ssim(img1, img2)
console.log(`SSIM: ${mssim} (${performance}ms)`)
})()本示例里两张图的相似度超过 99.9%
以下图片是无损 PNG 截图效果,以便准确对比。

2. 放量与回滚,最后的防线
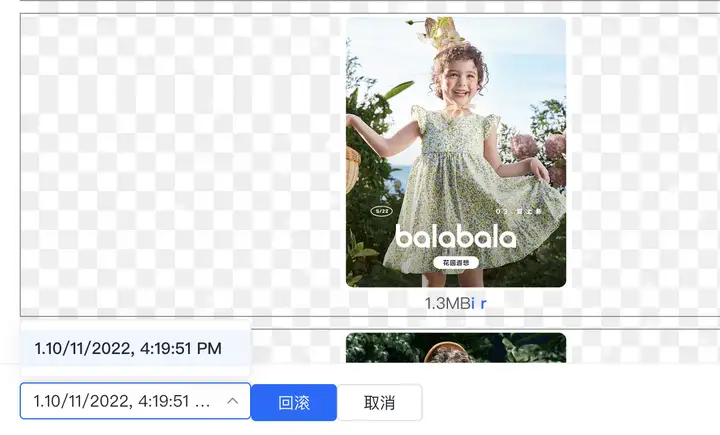
由于是直接操作数据库,线上会直接生效,所以所谓的回滚其实是用先前记录的数据再次回写数据库。
- 这里会在操作前把所有的数据存起来,并记录时间戳。
- 更新时向后端会校验时间戳,如果更新过程中恰好有商家在前台更新了数据,对比时间戳会校验失败,放弃回滚。
- 整个的放量时间较长,从国庆节前一直放到节后,较长的放量时间,使我们有更多的时间观察数据和线上 oncall。截止 9 月底至今,我们没有收到用户的负向反馈,抽样回访的 16% 店铺运行正常,样本具有置信度,整个替换过程平稳。
七、工程架构
1. 使用 client-sever 架构跑批处理

/api/minify-image 是一个 HTTP 接口,接收一个 url 参数,在服务端完成图片的下载-压缩-重传动作。在写脚本的时候,这里使用了 client-server 模式,图片的下载-压缩-重上传包装成了一个 HTTP 接口,图片的清洗触发包成了 client。使用 C-S 模式有以下几个好处:
- 便于横向扩展。 HTTP 服务可以横向部署在多台机器上。实操中用了三台机器:我的 16 寸 MBP、IT 借的一台 14 寸 MBP、以及一台 DevBox linux 开发机。图片压缩是个很耗 CPU 的工作,分开跑可以解放出我的主力 MBP。
- 便于控制并发。 只需要控制 client 的连接数,就可以很好地控制并发,尽可能榨干电脑的算力,又不至于搞死 server 端。这里推荐一个好用的控制并发的库 async ,它可以很好地确保同时跑 N 个异步任务。
- 便于控制超时。 作为前端,都有丰富的处理接口超时的经验,也有成熟的工具来处理超时。处理超时和抛错,是大批量跑脚本必须要做的事,后文会提到。
- 幂等 + 缓存。 Server 端实现成幂等的 HTTP GET 接口,访问一次和 N 次返回一致。这里有一个缓存优化:如果图片已经处理过,会跳过处理步骤。但没有分别对下载、上传的每一步都做缓存,因为每增加一级缓存,都会增加复杂度。只要保证每一步的操作出入参都是幂等的,就可以无限重放。
- 可以提前预热数据。 提前写好 curl 脚本模拟 HTTP 请求,可以提前花几天时间把数据库里的所有图片预热,节约之后的实时处理时间。
- 健壮性。 Server 端可以使用 pm2 等成熟的进程守护工具保障鲁棒性,避免由于处理某一张图片出问题而导致任务卡壳。
- 通用性。 前面说到我们做了一个 UI 网页,在网页里也可以调用这个接口。之后也可以将这个 HTTP 服务部署到线上,很多工作都可以复用了。
2. 使用 pm2 跑预热任务
前面提到 HTTP 接口使用了 pm2 做进程守护,避免了服务器的宕机。同样的,对于 client 端的任务脚本,也使用 pm2 做了守护。pm2 的 start 方法可以传 shell 脚本:
pm2 start 'pnpm vite-node scripts/trigger-minify-images.ts'这么做的目的是避免跑了半天由于某个边界条件没有处理或内存泄露导致脚本退出,一晚上的时间就浪费了。
// trigger-minify-images.ts
;(async () => {
let i = fs.readJSONSync(INDEX_PATH, { throws: false }) ?? 0
for (; i < shopIds.length; i++) {
try {
fs.outputJSONSync(INDEX_PATH, i)
await curl(`${i}....`)
...
} catch (e) {
// 跑批一定是会遇到很多你预料之外问题的,防止任务卡壳要处理好异常和超时
// 错误先记录下来,不要阻塞队列
log(e)
}
}
})()trigger 脚本里,每一轮任务都会把索引值记到文件,这样在任务崩溃并重试后不用重头再来。
这里也可以将队列每次执行前洗牌乱序,也能避免重试后跑很多重复任务。
3. 使用 puppeteer 跑 UI 任务
由于一开始就做了 Web UI 界面,并且手动测试了一批店铺没有问题。等到需要跑批量任务了,总不能都一个个人肉点啊。
这时候想跑批,自然稳妥的做法是复用这套流程,模拟人的点击操作,于是用了 puppeteer 来帮我打工。
;(async () => {
let i = fs.readJSONSync(INDEX_PATH, { throws: false }) ?? 0
const browser = await puppeteer.launch({
args: [
'--no-sandbox', // 沙盒模式
'--disable-setuid-sandbox', // uid沙盒
'--disable-dev-shm-usage', // 创建临时文件共享内存
'--disable-accelerated-2d-canvas', // canvas渲染
'--disable-gpu', // GPU硬件加速
'--disable-background-timer-throttling',
'--disable-backgrounding-occluded-windows',
'--disable-renderer-backgrounding',
'--proxy-server=http://127.0.0.1:8899', // 这里用了代理
'--window-size=1440,900'
],
// headless: true,
devtools: true
})
for (; i < shopIds.length; i++) {
fs.outputJSONSync(INDEX_PATH, i)
try {
const shopId = shopIds[i]
const item = listData.find(item => item.shop_id.toString() === shopId.toString())
...
const page = await browser.newPage()
await page.setViewport({ width: 1440, height: 0 })
// 完成登录
await page.setCookie({
url: 'https://fxg.jinritemai.com',
name: 'TOKEN',
value: cookie.match(/TOKEN=(.*?)(?:;|$)/)?.[1] ?? '',
expires: Date.now() + 86400000 * 365
})
await page.goto(pageUrl)
const button1 = '#minify-images'
const button2 = '.auxo-btn.auxo-btn-primary:nth-of-type(2)'
// 等待确定按钮出现
await page.waitForSelector(button1, { visible: true, timeout: 5 * 60 * 1000 })
// 获取 dom 节点,需要将方法发送到 page 上下文执行,这个 evaluate 的函数其实是做为字符串发送到 page 上下文的
const value = await page.evaluate(el => el?.textContent?.trim(), await page.$(button1)) ?? ''
if (value !== '压缩') { // 防御代码
continue
}
await page.click(button1)
await page.waitForSelector(button2, { visible: true })
await sleep(1)
await page.click(button2)
// 30s 后再关闭页面,确保所有请求都发送,这里没有用 await,不阻塞循环
sleep(30).then(() => {
page.close()
})
} catch (e) {
console.error(e)
log(e)
}
}
})()puppeteer 在 headless 为 false 时的坑:每次执行 page.goto 时,Chromium 都会弹到电脑最前面,打断你别的工作。网上搜了些方法都没成功,官方 issue 直接把这个问题给 close 了,close 了……
解决方法:找 IT 借了一台电脑(软件解不了就硬件解吧,哼)。
八、总结及遗留问题
- 我们已经将线上所有 ISV 商家图片进行了替换,全量商家图片总体积降低 70%。从单个商家维度来看,其中压缩率最低为 31%;压缩率最高为 97%;压缩率中位数为 73%。
- 这部分压缩率还没有算上运行时再转成 WebP 的增益。
1. 压缩率低的店铺问题诊断


- 仔细看上图左右两边的(这图真是又白又大,阿呸我真不是为了给你们谋福利)压缩前后对比,会发现原图底部有一根红线,这是故意标出来的,实际是一条 1px 高度透明像素。正是由于存在这条透明通道,导致压缩时不敢安全地转化为 JPG。
2. 商家乱改扩展名问题
- 图片命名的混乱,有些使用 .jpg,有些使用 .jpeg,有些直接把 .png 改成 .jpg 萌混过关。优秀的操作系统和浏览器则都尽可能让我们忘记扩展名和格式。文章前面提到商家运营和设计师可能不是一拨人。乱改扩展名和用扣扣截图都是基操。
- 好在 imageX 抹平了这个差异,统一使用 .image 后缀。但这又带来一个问题:运行时不能提前知道图片是什么格式,不能压缩透明通道。
- 这里有一个可行的方案,后续计划去做:在图片入库时,在图片的 url 上带上 query。形如:
https://...xxx.image#?width=200&height=100&ext=png&alpha=1
- 本身 kv 结构,方便扩展。
- 将宽高等信息带出可以在图片加载前提前占位避免抖动。
- 不用改动现有数据结构增加新的结构体。
- 放在 hash 上请求不会到达服务器,不会穿透 CDN,兼容性好。
- 使用 query 的好处:
- 有了这些信息,C 端在图片请求前就可以做一些提前优化了。
3. 超大宽度图片

存量数据中,商家传的最大的一张图片为 3200x3200 尺寸,这在移动端上完全没有必要。目前我们已经卡了新增入口,图片宽度不可大于 1125px(3 倍 375)。
对于存量图片,修改尺寸可能带来一定风险,故本次优化专项选择了保留原尺寸。
4. PNG 的滥用
这个问题前面也提到了,主要是现在很多图片软件默认导出就是 PNG。对没有透明度和极端清晰度要求的图片应当尽可能转成 JPG。这块之后会在产品层面上增加引导。
九、后续
本次项目中很多工作是可以沉淀下来的。比如压缩图片的 HTTP 接口、单图对比工具、高阶 JSON 的替换还原方法,将来都可以继续服务新增图片的生产上。
另外,压缩的底层库 MozJPEG 也支持制作成 wasm,可以利用 B 端端侧的算力进行边缘计算,降低服务端负载。
参考抖音在上传视频前,会提前在本地进行压缩,这是一个低频高收益的操作,搭建新页面时多花一些等待时间,对于商家是可以接受的。由于是使用的 client-server 架构,这个预热还可以进一步提前,比如在商家正在编辑的空闲时间做压缩预热,这样在保存发布的时候可以做到秒速压缩了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号