论文阅记 MobileNet V1
论文题目:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
文献地址:https://arxiv.org/abs/1704.04861?context=cs
(非官方)源码地址:
(1)Pytorch实现:https://github.com/rwightman/pytorch-image-models
(2)Caffe实现:https://github.com/shicai/MobileNet-Caffe
(3)TensorFlow实现MobileNet - YOLOV3: https://github.com/GuodongQi/yolo3_tensorflow
MobileNet V1中提到的轻量级深度分离卷积的思想在MobileNet V2,MnasNet,MobileNet V3,以及单目标追踪算法SiamMask中均得以运用。虽然单独使用MobileNet V1的场景不多,但是了解其思想,对于后续论文的理解有铺垫性的作用。
移动端神经网络现状
MobileNet的提出是针对移动或者嵌入式的应用场景。大而复杂的模型是难以在嵌入式、FPGA等移动端使用的。视觉模型在移动端使用有两大难题:
- 模型过于庞大,容易造成硬件内存不足的问题;
- 大多场景要求低延迟、响应速度快。【自动驾驶的行人检测如果响应速度慢,则会发生比较可怕的事情】
因此,研究小而精确的模型对于现实的应用场景十分重要。
目前的两大解决策略:
- 对训练好的复杂模型进行压缩得到小模型; ☆☆☆☆☆
- 直接对小模型进行训练;
保证模型的性能,降低模型的大小,提升模型的速度。
MobileNet属于后者,其使用了Depth wise separable convolutions。降低了卷积运算的参数量和运算量。
其可以用于目标检测,提出的核心思想是轻量级的卷积运算。在实际应用中,通常会有人选择其升级版MobileNet V2 作为一个快速目标识别的网络,用于获取patch给追踪算法。
核心思想
MobileNet最核心的层就是深度可分离卷积的设计【depth wise separable convolutions】。
深度可分离卷积是将普通卷积分离为深度卷积和1*1卷积。
深度卷积的意思就是针对每个输入通道采用不同的卷积核,一个卷积核对应一个输入通道,也就是说,虽然有M个卷积核,但总共只有标准卷积的1个卷积核的大小。【一个卷积核是单通道的,M个卷积核相当于对输入的每一个通道,每一个通道对应一个1通道的卷积核。M个卷积核也就是一个与输入feature map 相同通道数量的卷积核。】其实可以理解,为什么要将标准卷积层换分为两个部分:
☐ depth wise 的卷积是每一个通道对应一个一层的卷积核,每个通道都对应一个卷积核,这样经过卷积运算后,通道数量不会发生变化。 所以需要1*1卷积进行通道数量的调整。
【深度卷积:depthwise convolution; 1*1卷积: pointwise convolution】
- 下图(a)中是标准的卷积操作,输入feature map的通道数量为M,则N个卷积核的通道数量均为M;
- 图(b)中是深度可分离卷积操作,输入feature map的通道数量为M,每一个通道对应一个卷积核,这样M个卷积核的参数量相当于只有标准卷积操作一个卷积核;
- 图(c)中是N个通道数量M的1*1卷积操作,由于图(b)中的输出结果的通道数量不会发生变化,也为M,因此,需要1*1卷积进行通道数量的调整。
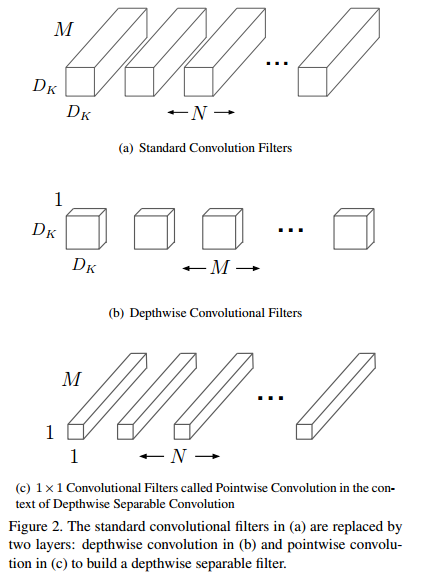
情形:对于输入feature map F[维度为Df * Df * M] ,输出的feature map G[维度为Dg * Dg * N]
- 标准卷积的卷积核的参数量为 Dk * Dk * M * N [Dk表示卷积核的尺寸]。
如果步长为1,padding也为1,则其对应的计算:
![]()
将会对应计算量为:
![]()
- 深度可分离卷积:
深度卷积计算形式:
![]()
运算量 (从结构图中也可以看出,运算量少N-1个卷积核的操作):
![]()
深度分离卷积运算量:
![]()

一般情况下 N 比较大,那么如果采用3x3卷积核,depthwise separable convolution相较于标准卷积可以降低大约9倍的计算量。
网络结构
在实际应用中会添加BN和ReLU层。



The full architecture of MobileNet V1 consists of a regular 3×3 convolution as the very first layer, followed by 13 times the above building block.
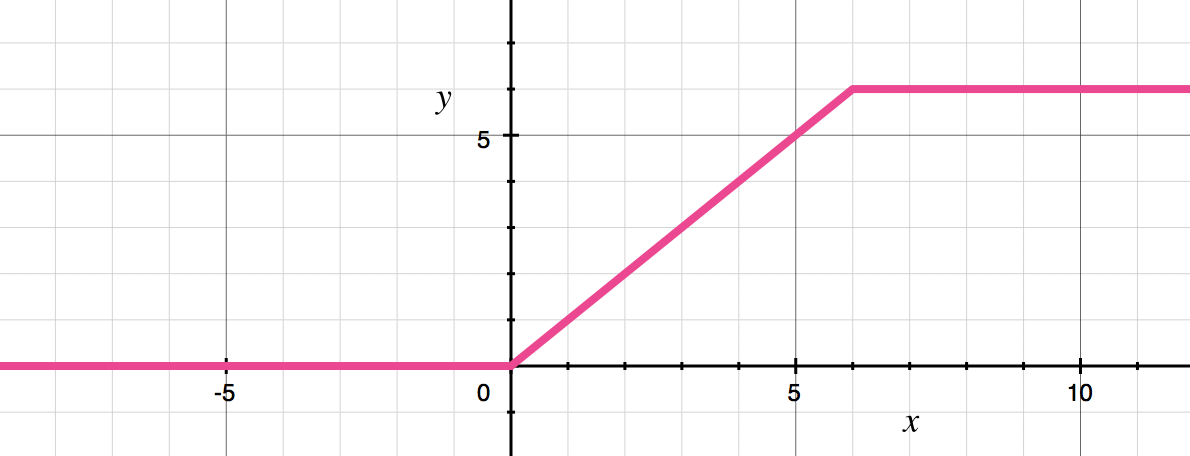
整体的网络结构中,包含一个常规的3*3卷积作为第一层,之后包含了13个上述的Depthwise Separable Convolutional block。 Depthwise Separable Convolutional block中没有池化层,而是使用步长为2的DW操作进行下采样。PW操作会2倍放大通道数量。如果输入图像的尺寸为 224×224×3,最终网络的输出则为7×7×1024。激活函数使用ReLU6。
y = min(max(0, x), 6)
最后呢,还会再加上一个平均池化操作和全连接层,全连接层使用softmax激活函数。
总结
MobileNet V1版本结构其实非常简单,从网络结构上看,其结构是一个非常复古的直筒结构,类似于VGG。这种结构性价比不高,后续一系列的ResNet、DenseNet等结构已经证明通过复用图像特征,使用concat/eltwise+等操作进行特征融合,能极大提升网络的性价比。
MobileNet V1版本中,Depthwise Conv确实是大大减少了参数量,也降低了计算量。而且N×N 的DW + 1×1的PW的结构在性能上也能接近N × N 的Conv。但是在实际使用中会发现,Depthwise (DW)部分的Kernel容易训练废掉: 即训练之后发现depthwise训练出来的kernel有不少是空的。depthwise每个kernel dim 相对于vanilla conv要小得多, 过小的kernel_dim, 加上ReLU的激活影响下, 使得神经元输出很容易变为0, 所以就学废了。 ReLU对于0的输出的梯度为0, 所以一旦陷入了0输出, 就没法恢复了。
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
 浙公网安备 33010602011771号
浙公网安备 33010602011771号