【2022.12.28】kaggle上泰坦尼克号的实操(上)
前言
经过一系列的学习,现在想入门kaggle上面的实操,多为模仿
参考链接:机器学习入门:Kaggle -titanic(泰坦尼克)生存预测
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 忽略部分版本警告
warnings.filterwarnings('ignore')
#设置sns样式
sns.set(style='white',context='notebook',palette='muted')
#导入数据
train=pd.read_csv('/kaggle/input/titanic/train.csv')
test=pd.read_csv('/kaggle/input/titanic/test.csv')
使用info可以了解到如下信息
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64 # 乘客ID
1 Survived 891 non-null int64 # 是否存活
2 Pclass 891 non-null int64 # 客舱等级(1/2/3等舱位)
3 Name 891 non-null object # 乘客姓名
4 Sex 891 non-null object # 性别
5 Age 714 non-null float64 # 年龄
6 SibSp 891 non-null int64 # 兄弟姐妹数/配偶数
7 Parch 891 non-null int64 # 父母数/子女数
8 Ticket 891 non-null object # 船票编号
9 Fare 891 non-null float64 # 船票价格
10 Cabin 204 non-null object # 客舱号
11 Embarked 889 non-null object # 登船港口
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
其中可以看到,有一些年龄和客舱号是空缺的(不足891)
而在test.info()之中,可以看到只有11列,去掉了存活
seaborn画图
# 计算不同类型embarked的乘客,其生存率为多少
print('Embarked为"S"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'S'].value_counts(normalize=True)[1])
print('Embarked为"C"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'C'].value_counts(normalize=True)[1])
print('Embarked为"Q"的乘客,其生存率为%.2f' % full['Survived'][full['Embarked'] == 'Q'].value_counts(normalize=True)[1])
###
Embarked为"S"的乘客,其生存率为0.34
Embarked为"C"的乘客,其生存率为0.55
Embarked为"Q"的乘客,其生存率为0.39
###
sns.catplot分类型数据作坐标轴画图
sns.catplot('Pclass', col='Embarked', data=train, kind='count', height=3)
这句话的意思是 根据Pclass和Embarked分类表格,并统计Pclass的数据
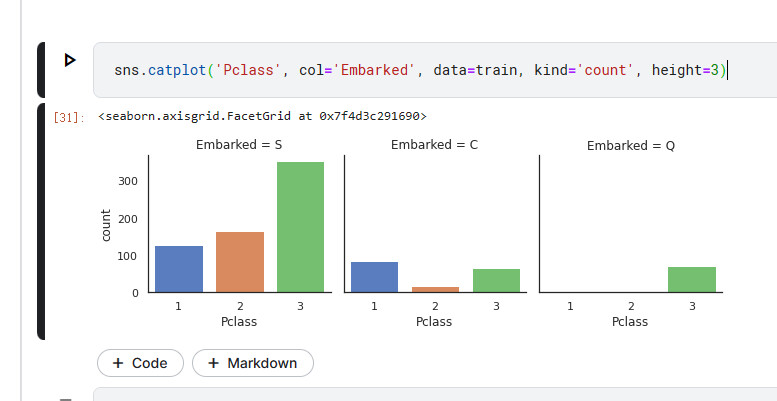
S是英国,C是法国,Q是新西兰
法国登船乘客生存率较高原因可能与其头等舱乘客比例较高有关。
sns.barplot柱状图
# Sex与Survived:女性的生存率远高于男性
sns.barplot(data=train, x='Sex', y='Survived')
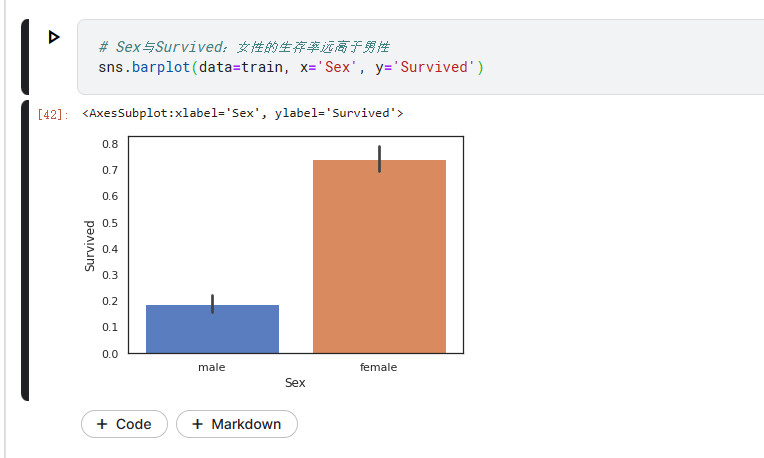
其中每个柱条的黑色的线条为误差线
误差线源于统计学,表示数据误差(或不确定性)范围,以更准确的方式呈现数据。误差线可以用标准差(standard deviation,SD)、标准误(standard error,SE)和置信区间表示,使用时可选用任意一种表示方法并作相应说明即可。当误差线比较“长”时,一般要么是数据离散程度大,要么是数据样本少。
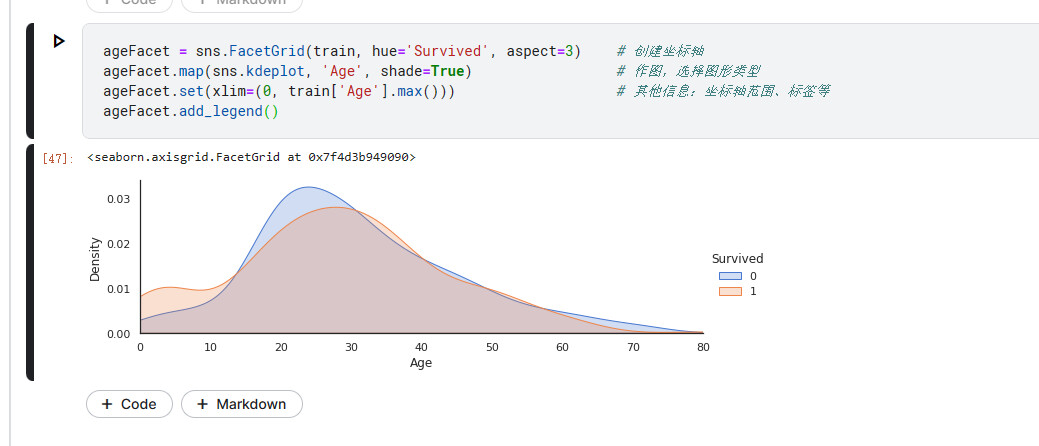
sns.FacetGrid
ageFacet = sns.FacetGrid(train, hue='Survived', aspect=3) # 创建坐标轴
ageFacet.map(sns.kdeplot, 'Age', shade=True) # 作图,选择图形类型
ageFacet.set(xlim=(0, train['Age'].max())) # 其他信息:坐标轴范围、标签等
ageFacet.add_legend()
Age与Survived:当乘客年龄段在0-10岁期间时生存率会较高。
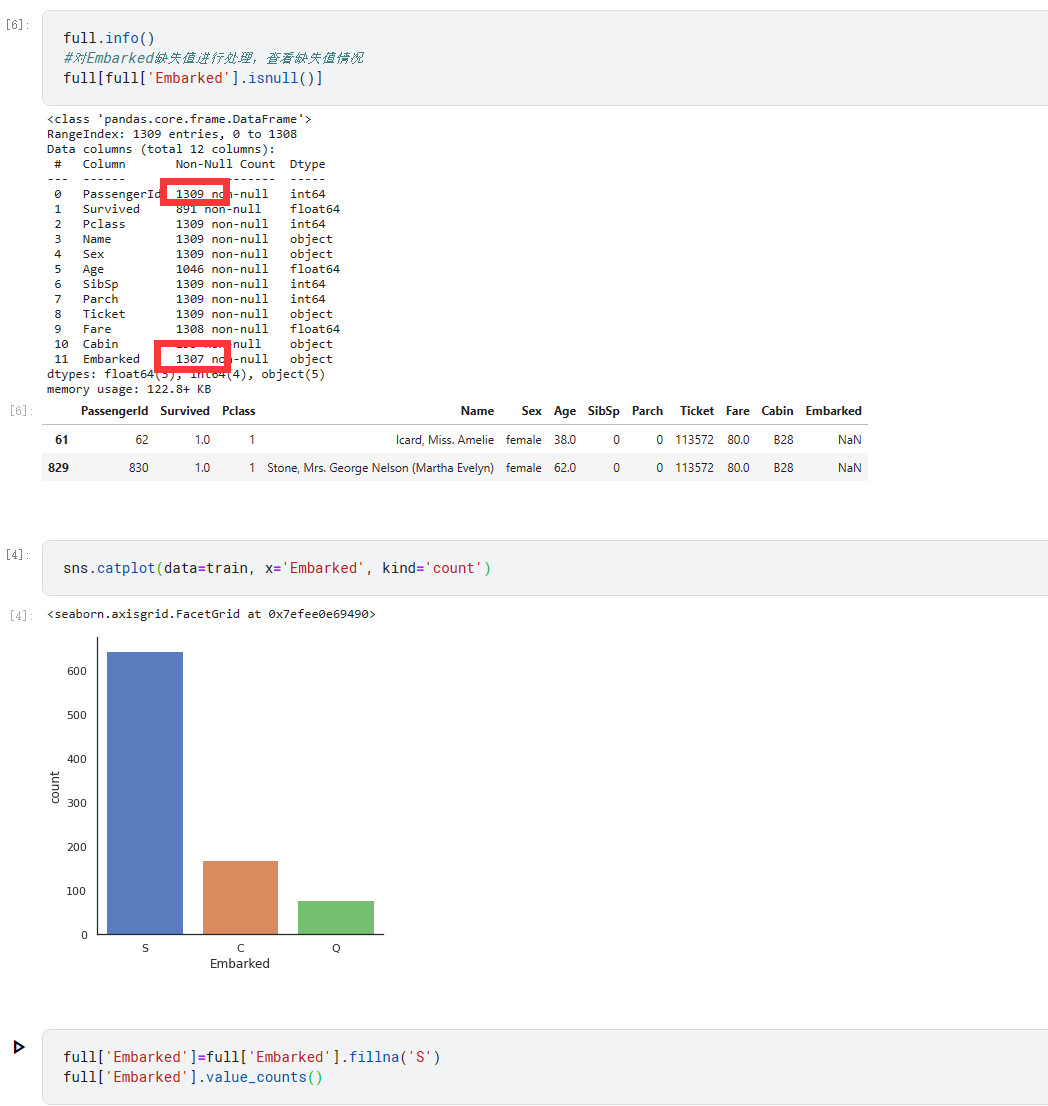
数据预处理
先对表格的缺失值进行处理
字符类处理
其中有两个人没有进站数据,经过绘图我们可以知道大部分人都是S站上船的
因此我们直接填入S
因为cabin的数据量太少,因此将空缺的地方直接填入Unknown
full['Cabin']=full['Cabin'].fillna('Unknown')
full['Embarked']=full['Embarked'].fillna('S')
数值类处理
有一个人没有票价,因此填入平均值
full[full['Fare'].isnull()]
# 查询可知
#PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
#1043 1044 NaN 3 Storey, Mr. Thomas male 60.5 0 0 3701 NaN Unknown S
# 利用3等舱,登船港口为英国,舱位未知旅客的平均票价来填充缺失值。
full['Fare']=full['Fare'].fillna( full[(full['Pclass']==3)&(full['Embarked']=='S')&(full['Cabin']=='Unknown')]['Fare'].mean())
而age没有填入数值,但是这个数据很大概率影响到存活率,这个放到下面的特征工程讲
特征工程
身份头衔特征
合并一些有相同特征的标签,“暴力更改”部分标签,在泰坦尼克的数据中,姓名头衔可以很好反应这一点。比如有的人是Dr,Mrs等
#构造新特征Title
full['Title']=full['Name'].map(lambda x:x.split(',')[1].split('.')[0].strip())
#查看title数据分布
full['Title'].value_counts()
新建新的特征Title,分割出逗号和句号之间的身份
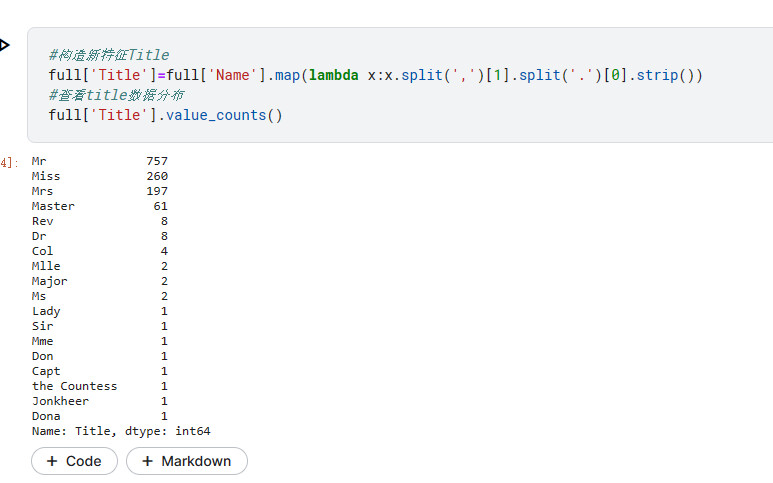
其中有的是头衔,有的并不是头衔,Capt这类就是船长啥的,因此我们要将一些特征合并在一起,可以采用上面的方法对数据进行修改,也可以采用词典的方法对结果进行整合
TitleDict={}
TitleDict['Mr']='Mr'
TitleDict['Mlle']='Miss'
TitleDict['Miss']='Miss'
TitleDict['Master']='Master'
TitleDict['Jonkheer']='Master'
TitleDict['Mme']='Mrs'
TitleDict['Ms']='Mrs'
TitleDict['Mrs']='Mrs'
TitleDict['Don']='Royalty'
TitleDict['Sir']='Royalty'
TitleDict['the Countess']='Royalty'
TitleDict['Dona']='Royalty'
TitleDict['Lady']='Royalty'
TitleDict['Capt']='Officer'
TitleDict['Col']='Officer'
TitleDict['Major']='Officer'
TitleDict['Dr']='Officer'
TitleDict['Rev']='Officer'
full['Title']=full['Title'].map(TitleDict)
再次使用value_counts()时,可以得到以下整合后的效果
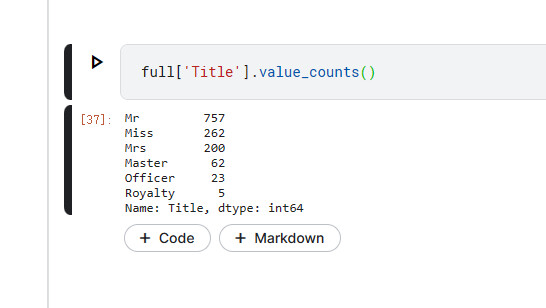
观察结果
# 观察新特征与标签之间的关系
sns.barplot(data=full,x='Title',y='Survived')
# 头衔为'Mr'及'Officer'的乘客,生存率明显较低。
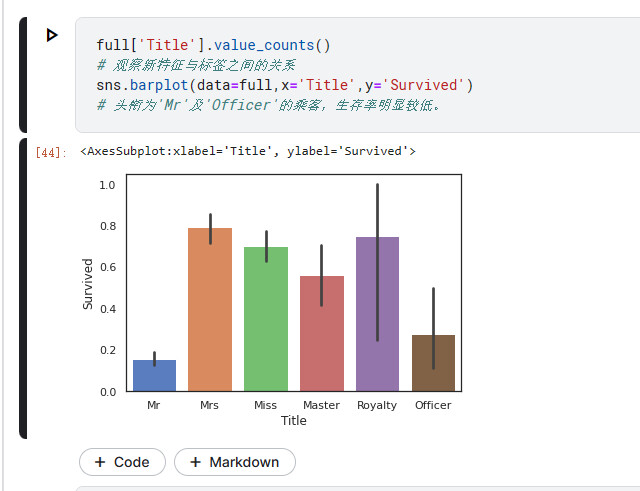
贵族和女士的生存率较高
家庭成员特征
拖家带口和独自一人的存活率可能会有差异,可以通过数据表体现出来
full['familyNum']=full['Parch']+full['SibSp']+1
# 查看familyNum与Survived
sns.barplot(data=full,x='familyNum',y='Survived')
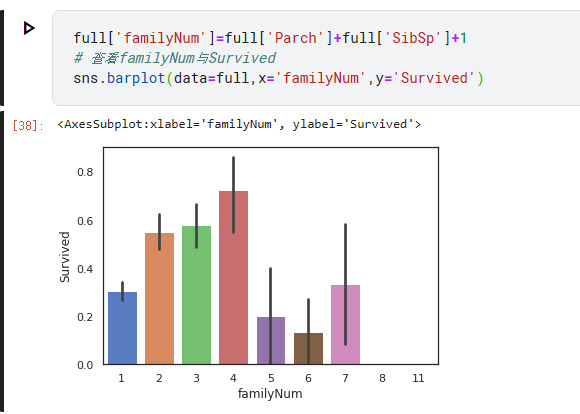
可以看出8,11人的家庭没有存活,4人口的存活率最高
可以将家庭分为小中大三类
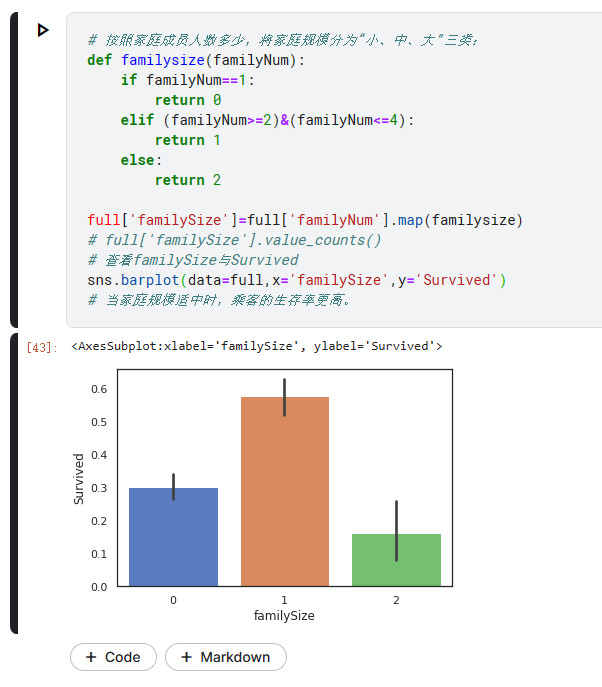
# 按照家庭成员人数多少,将家庭规模分为“小、中、大”三类:
def familysize(familyNum):
if familyNum==1:
return 0
elif (familyNum>=2)&(familyNum<=4):
return 1
else:
return 2
full['familySize']=full['familyNum'].map(familysize)
full['familySize'].value_counts()
'''
0 790
1 437
2 82
Name: familySize, dtype: int64
'''
# 查看familySize与Survived
sns.barplot(data=full,x='familySize',y='Survived')
# 当家庭规模适中时,乘客的生存率更高。
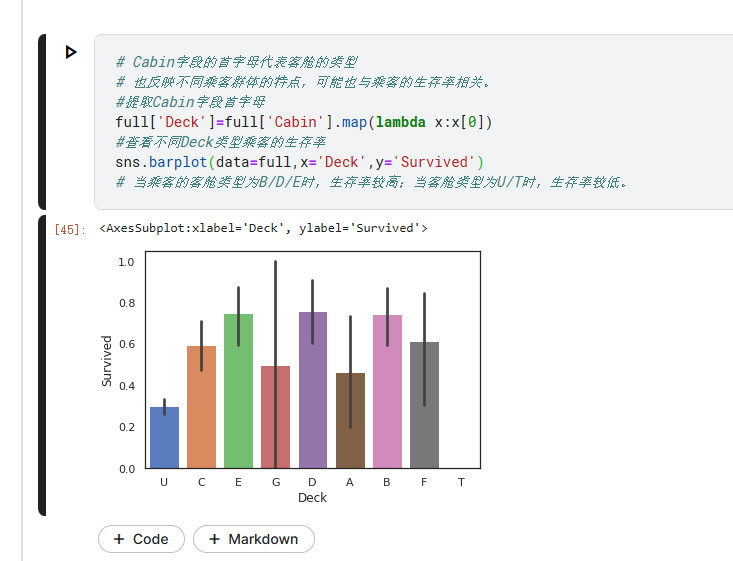
船舱类型特征
# Cabin字段的首字母代表客舱的类型
# 也反映不同乘客群体的特点,可能也与乘客的生存率相关。
#提取Cabin字段首字母
full['Deck']=full['Cabin'].map(lambda x:x[0])
#查看不同Deck类型乘客的生存率
sns.barplot(data=full,x='Deck',y='Survived')
# 当乘客的客舱类型为B/D/E时,生存率较高;当客舱类型为U/T时,生存率较低。
# Unknown的生存率较低
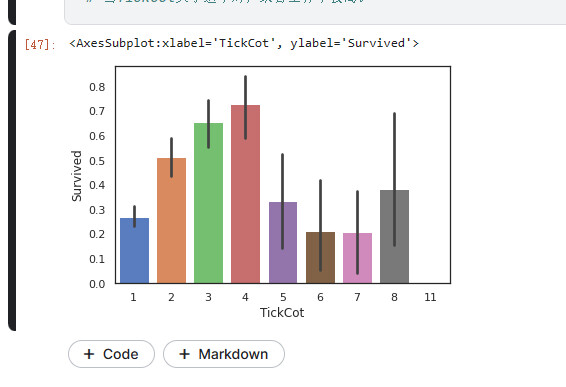
共票号乘客特征
# 同一票号的乘客数量可能不同,可能也与乘客生存率有关系。
# 提取各票号的乘客数量
TickCountDict={}
TickCountDict=full['Ticket'].value_counts()
TickCountDict.head()
#将同票号乘客数量数据并入数据集中
full['TickCot']=full['Ticket'].map(TickCountDict)
full['TickCot'].value_counts()
# 查看TickCot与Survived之间关系
sns.barplot(data=full,x='TickCot',y='Survived')
# 当TickCot大小适中时,乘客生存率较高。
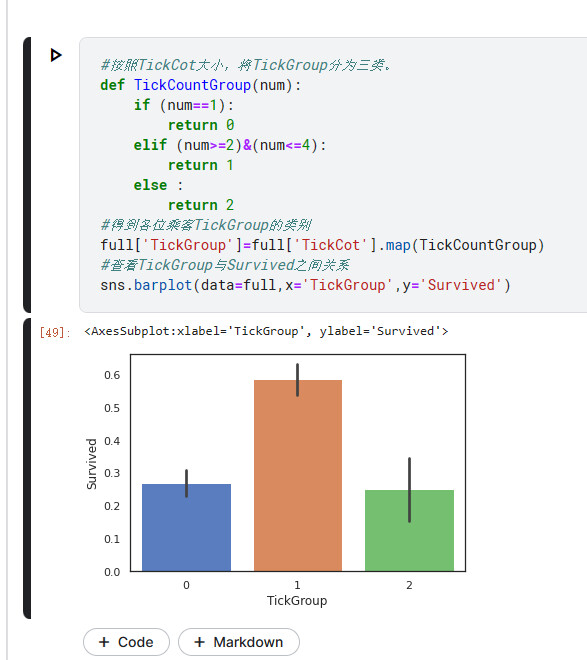
#按照TickCot大小,将TickGroup分为三类。
def TickCountGroup(num):
if (num==1):
return 0
elif (num>=2)&(num<=4):
return 1
else :
return 2
#得到各位乘客TickGroup的类别
full['TickGroup']=full['TickCot'].map(TickCountGroup)
#查看TickGroup与Survived之间关系
sns.barplot(data=full,x='TickGroup',y='Survived')
数值分析方法
One-hot编码
get_dummies方法可以用one-hot编码,将原来的值加在原来的分类之后,比如以下的demo
import pandas as pd
df = pd.DataFrame([
['green', 'A'],
['red', 'B'],
['blue', 'A']])
df.columns = ['color', 'class']
print(df)
'''
color class
0 green A
1 red B
2 blue A
'''
df=pd.get_dummies(df,columns=["color"])
print(df)
# 将color的值加在color后面,形成一项特征
'''
class color_blue color_green color_red
0 A 0 1 0
1 B 0 0 1
2 A 1 0 0
'''

pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
参数说明
data : array-like, Series, or DataFrame
输入的数据
prefix : string, list of strings, or dict of strings, default None
get_dummies转换后,列名的前缀
columns : list-like, default None
指定需要实现类别转换的列名
dummy_na : bool, default False
增加一列表示空缺值,如果False就忽略空缺值
drop_first : bool, default False
获得k中的k-1个类别值,去除第一个
DataFrame
DataFrame这里参考了Pandas DataFrame入门教程(图解版) (biancheng.net)
corr()与热力图
这里参照了【Python-数据分析】相关关系(矩阵)的3种展示技巧:corr()-热力图-条形图 - 知乎 (zhihu.com)
预测数据
进行以上数据处理和特征工程后,数据变得很完整,就可以着手预测年龄了
相关系数
先用热力图看看,什么数据与年龄相关性较大
只能与数据进行比对,不能与字符串等比对,因此
plt.figure(figsize=(8,8))
sns.heatmap(full[['Age','Parch','Pclass','SibSp','Title','familyNum','TickCot','Fare']].corr(),cmap='BrBG',annot=True,
linewidths=.5)
# 选用TickCot是不分类的原数据,而不是分类后的TickGroup,同理familyNum与familySize
可以得到如下热力图
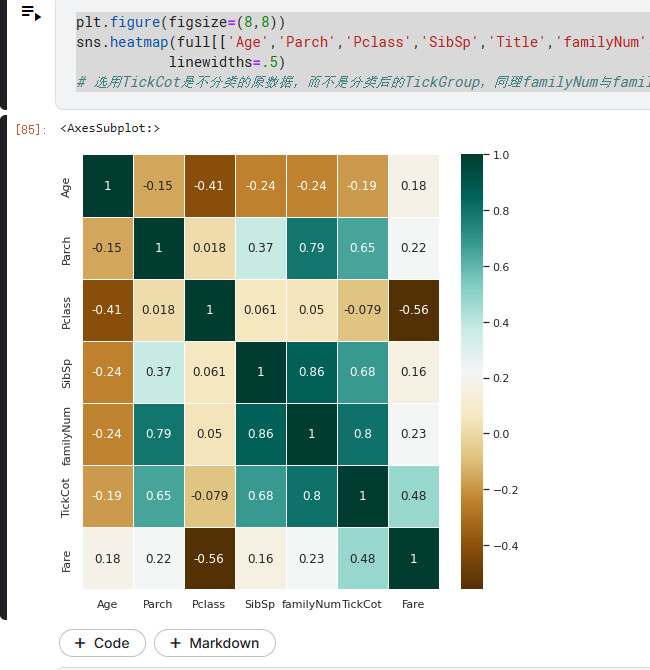
我们看age那一行/列,可以发现fare与age的相关性较大,但是在原博客之中没对fare进行相关系数处理,因此在这里先略过
以上热力图也可以通过下方代码进行筛选数据
#筛选数据集
AgePre=full[['Age','Parch','Pclass','SibSp','Title','familyNum','TickCot']]
#进行one-hot编码
AgePre=pd.get_dummies(AgePre)
ParAge=pd.get_dummies(AgePre['Parch'],prefix='Parch')
SibAge=pd.get_dummies(AgePre['SibSp'],prefix='SibSp')
PclAge=pd.get_dummies(AgePre['Pclass'],prefix='Pclass')
#查看变量间相关性
AgeCorrDf=pd.DataFrame()
AgeCorrDf=AgePre.corr()
AgeCorrDf['Age'].sort_values()
'''
Pclass -0.408106
Title_Master -0.385380
Title_Miss -0.282977
SibSp -0.243699
familyNum -0.240229
TickCot -0.185284
Parch -0.150917
Title_Royalty 0.057337
Title_Officer 0.166771
Title_Mr 0.183965
Title_Mrs 0.215091
Age 1.000000
Name: Age, dtype: float64
'''
#拼接数据
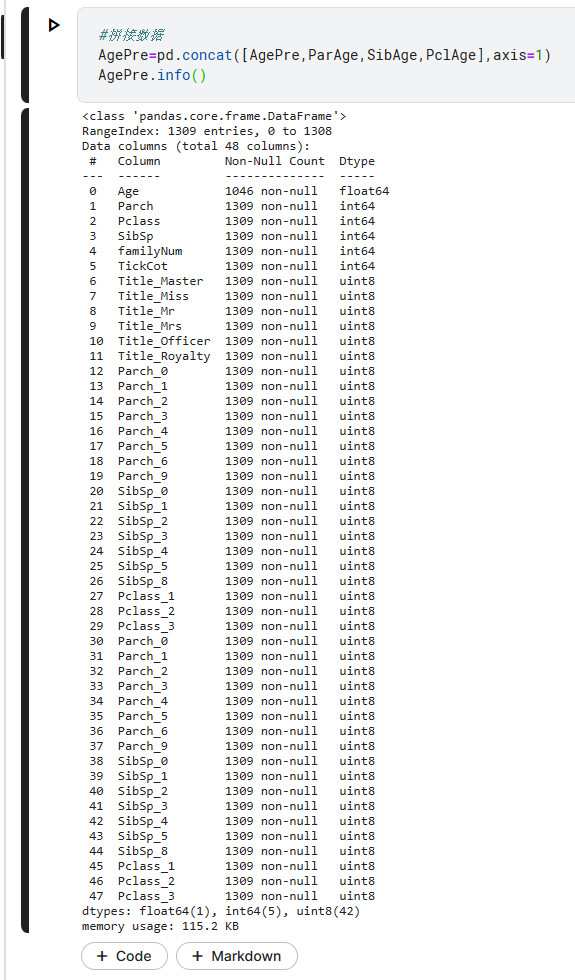
AgePre=pd.concat([AgePre,ParAge,SibAge,PclAge],axis=1)
AgePre.head()
ParAge、SibAge、PclAge都是用onehot编码得到的,由此我们可以得到这么一个很长的column
生成数据
#拆分实验集和预测集
AgeKnown=AgePre[AgePre['Age'].notnull()]
AgeUnKnown=AgePre[AgePre['Age'].isnull()]
#生成实验数据的特征和标签
AgeKnown_X=AgeKnown.drop(['Age'],axis=1)
AgeKnown_y=AgeKnown['Age']
#生成预测数据的特征
AgeUnKnown_X=AgeUnKnown.drop(['Age'],axis=1)
#利用随机森林构建模型
rfr=RandomForestRegressor(random_state=None,n_estimators=500,n_jobs=-1)
rfr.fit(AgeKnown_X,AgeKnown_y)
其中RandomForestRegressor的函数在sklearn.ensemble.RandomForestRegressor-scikit-learn中文社区
可以找到该部分的代码
fit部分的代码意义为fit(X, y[, sample_weight]) 从训练集(X, y)构建一个树的森林。
验证一下
full.info()
'''
Age一共有1046个notnull
5 Age 1046 non-null float64
'''
AgeKnown.info()
'''
可以得到所有的行数都是1046
AgeKnown_X则是除了Age那一列以外的AgeKnown所有数据
AgeKnown_y是对应的只有Age那一列的数据
0 22.0
1 38.0
...
1305 39.0
1306 38.5
Name: Age, Length: 1046, dtype: float64
'''
score的方法为score(X, y[, sample_weight]) 返回预测的决定系数R^2
利用模型进行预测并填入源数据集
#模型得分
rfr.score(AgeKnown_X,AgeKnown_y)
#预测年龄
AgeUnKnown_y=rfr.predict(AgeUnKnown_X)
#填充预测数据
full.loc[full['Age'].isnull(),['Age']]=AgeUnKnown_y
full.info() #此时已无缺失值
同组识别
说实话并没看懂这部分为什么要这么做,那我先把源码照搬过来吧
原因
虽然通过分析数据已有特征与标签的关系可以构建有效的预测模型,但是部分具有明显共同特征的用户可能与整体模型逻辑并不一致。如果将这部分具有同组效应的用户识别出来并对其数据加以修正,就可以有效提高模型的准确率。在Titancic案例中,我们主要探究相同姓氏的乘客是否存在明显的同组效应。提取两部分数据,分别查看其“姓氏”是否存在同组效应。因为性别和年龄与乘客生存率关系最为密切,因此用这两个特征作为分类条件
12岁以上男性:找出男性中同姓氏均获救的部分
#提取乘客的姓氏及相应的乘客数
full['Surname']=full['Name'].map(lambda x:x.split(',')[0].strip())
SurNameDict={}
SurNameDict=full['Surname'].value_counts()
full['SurnameNum']=full['Surname'].map(SurNameDict)
#将数据分为两组
MaleDf=full[(full['Sex']=='male')&(full['Age']>12)&(full['familyNum']>=2)]
FemChildDf=full[((full['Sex']=='female')|(full['Age']<=12))&(full['familyNum']>=2)]
MSurNamDf=MaleDf['Survived'].groupby(MaleDf['Surname']).mean()
MSurNamDf.head()
MSurNamDf.value_counts()
'''
0.0 89
1.0 19
0.5 3
Name: Survived, dtype: int64
'''
大多数同姓氏的男性存在“同生共死”的特点,因此利用该同组效应,对生存率为1的姓氏里的男性数据进行修正,提升其预测为“可以幸存”的概率。
MSurNamDict={}
MSurNamDict=MSurNamDf[MSurNamDf.values==1].index
MSurNamDict
'''
Index(['Beane', 'Beckwith', 'Bishop', 'Cardeza', 'Chambers', 'Dick',
'Duff Gordon', 'Frauenthal', 'Frolicher-Stehli', 'Goldenberg',
'Greenfield', 'Harder', 'Hoyt', 'Kimball', 'Lindqvist', 'McCoy',
'Nakid', 'Persson', 'Taylor'],
dtype='object', name='Surname')
'''
女性以及年龄在12岁以下儿童:找出女性及儿童中同姓氏均遇难的部分。
#分析女性及儿童同组效应
FCSurNamDf=FemChildDf['Survived'].groupby(FemChildDf['Surname']).mean()
FCSurNamDf.head()
FCSurNamDf.value_counts()
'''
1.000000 115
0.000000 27
0.750000 2
0.333333 1
0.142857 1
Name: Survived, dtype: int64
'''
与男性组特征相似,女性及儿童也存在明显的“同生共死”的特点,因此利用同组效应,对生存率为0的姓氏里的女性及儿童数据进行修正,提升其预测为“并未幸存”的概率。
#获得生存率为0的姓氏
FCSurNamDict={}
FCSurNamDict=FCSurNamDf[FCSurNamDf.values==0].index
FCSurNamDict
然后对其进行修改
#对数据集中这些姓氏的男性数据进行修正:1、性别改为女;2、年龄改为5。
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(MSurNamDict))&(full['Sex']=='male'),'Age']=5
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(MSurNamDict))&(full['Sex']=='male'),'Sex']='female'
#对数据集中这些姓氏的女性及儿童的数据进行修正:1、性别改为男;2、年龄改为60。
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(FCSurNamDict))&((full['Sex']=='female')|(full['Age']<=12)),'Age']=60
full.loc[(full['Survived'].isnull())&(full['Surname'].isin(FCSurNamDict))&((full['Sex']=='female')|(full['Age']<=12)),'Sex']='male'
筛选子集
在对数据进行处理的时候,比如采用one-hot编码的时候,难免会导致维度上升,为了提升数据的有效性,那么就必须对数据进行降维处理
通过找出与乘客生存率“Survived”相关性更高的特征,剔除重复的且相关性较低的特征,从而实现数据降维。
# 先删除没有用的数据,大多是字符串类型的
fullSel=full.drop(['Cabin','Name','Ticket','PassengerId','Surname','SurnameNum'],axis=1)
#查看各特征与标签的相关性
corrDf=pd.DataFrame()
corrDf=fullSel.corr()
corrDf['Survived'].sort_values(ascending=True)
'''
Pclass -0.338481
Age -0.059547
SibSp -0.035322
familyNum 0.016639
TickCot 0.064962
Parch 0.081629
familySize 0.108631
TickGroup 0.151702
Fare 0.257307
Survived 1.000000
Name: Survived, dtype: float64
'''
检查一下数据
生成热力图
# 通过热力图,查看Survived与其他特征间相关性大小。
# 热力图,查看Survived与其他特征间相关性大小
plt.figure(figsize=(8,8))
sns.heatmap(fullSel[['Survived','Age','Embarked','Fare','Parch','Pclass',
'Sex','SibSp','Title','familyNum','familySize','Deck',
'TickCot','TickGroup']].corr(),cmap='BrBG',annot=True,
linewidths=.5)
# plt.xticks(rotation=45)
因为TickGroup我与博主的的分类不一致,所以会有那么一点不同
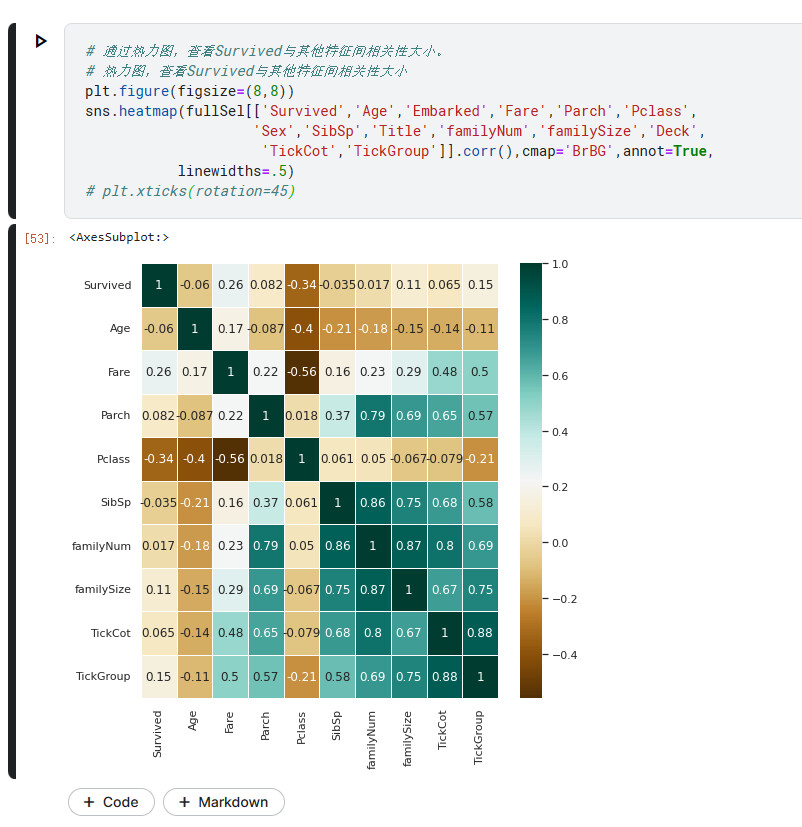
生成one-hot编码
相当于将字符串转化为数值
# 先人工初步筛除与标签预测明显不相关或相关度很低的特征
# 再查看剩余特征与标签之间的相关性大小做进一步降维。
fullSel=fullSel.drop(['familyNum','SibSp','TickCot','Parch'],axis=1)
#one-hot编码
fullSel=pd.get_dummies(fullSel)
PclassDf=pd.get_dummies(full['Pclass'],prefix='Pclass')
TickGroupDf=pd.get_dummies(full['TickGroup'],prefix='TickGroup')
familySizeDf=pd.get_dummies(full['familySize'],prefix='familySize')
fullSel=pd.concat([fullSel,PclassDf,TickGroupDf,familySizeDf],axis=1)
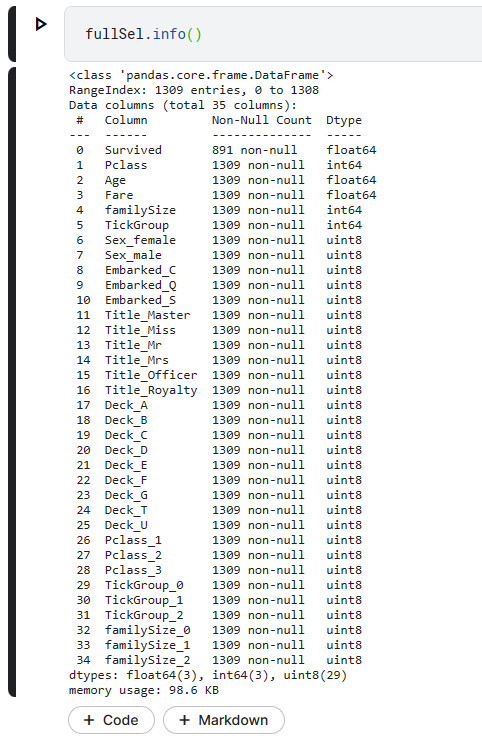
使用info检查
参考链接
Pandas DataFrame入门教程(图解版) (biancheng.net)
【Python-数据分析】相关关系(矩阵)的3种展示技巧:corr()-热力图-条形图 - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号