

爬虫基本原理
一.使用requests 模块 是基于urllib库
1.requests.get() 的请求
import requests # 使用requests 模块 是基于urllib # urllib python 内置的模块 也是没扣你发送http请求的库 # 模拟http请求, get post put delete # 1 get 请求 # res = requests.get('https://www.baidu.com') # # print(res) # <Response [200]> # # # 注意编码的问题 # res.encoding = 'utf-8' # print(res.text) # 百度首页的内容 》》》 响应的内容 # # with open('a.html', 'w')as f: # 百度首页登录的页面 # # f.write(res.text)
2.requests.get() 的参数和编码的问题 报错‘gbk’ 》》》
1.'gbk' 编码格式的问题
# 1 get 请求 # res = requests.get('https://www.baidu.com') # # print(res) # <Response [200]> # # # 注意编码的问题 # res.encoding = 'utf-8'
2.必传参数
# 2. get 请求携带参数 # User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 # request.get()的方法的参数 # def get(url, params=None, **kwargs): # r"""Sends a GET request. # https://www.baidu.com/s?wd=%E6%9C%80%E7%BE%8E%E9%A3%8E%E6%99%AF%E5%9B%BE # res = requests.get('https://www.baidu.com/s', # params={"wd": '最美风景图'}, # # 请求头的信息 # headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}) # # res.encoding = 'utf-8' # # print(res.text) # 请求的内容 # # <div class="timeout-title">网络不给力,请稍后重试</div> # with open('a.html', 'w')as f: # f.write(res.text) # <div class="timeout-title">网络不给力,请稍后重试</div> 无法访问的这样
3.模拟用户登录的实列 》》 华华手机
参数准备
(1)headers 中 User_Agent Referer cookie = res.cookies.get()
格式案列:
# >>>> 模拟登录网站 User_Agent: Referer cookie headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36", 'Referer': 'http://www.aa7a.cn/user.php?&ref=http%3A%2F%2Fwww.aa7a.cn%2Findex.php'} res = requests.post('http://www.aa7a.cn/user.php', headers=headers, data={ 'username': '1024359512@qq.com ', "password": 'mo1234', 'captcha': 'mkab', 'remember': 1, 'ref': 'http://www.aa7a.cn/index.php', 'act': 'act_login' } ) # 如果登录成功,cookie存在在于对象 中 cookie = res.cookies.get_dict() # 生成cookie # 向首页发送get请求 res = requests.get('http://www.aa7a.cn/user.php?&ref=http%3A%2F%2Fwww.aa7a.cn%2Fuser.php%3Fact%3Dlogout', headers=headers, cookies=cookie) # 判断 if '1024359512@qq.com' in res.text: print('登录成功') else: print('没有登录') """ "" username: koko password: mo123 captcha: nkab remember: 1 ref: http://www.aa7a.cn/ act: act_login """
3.requests.get() 爬取电影
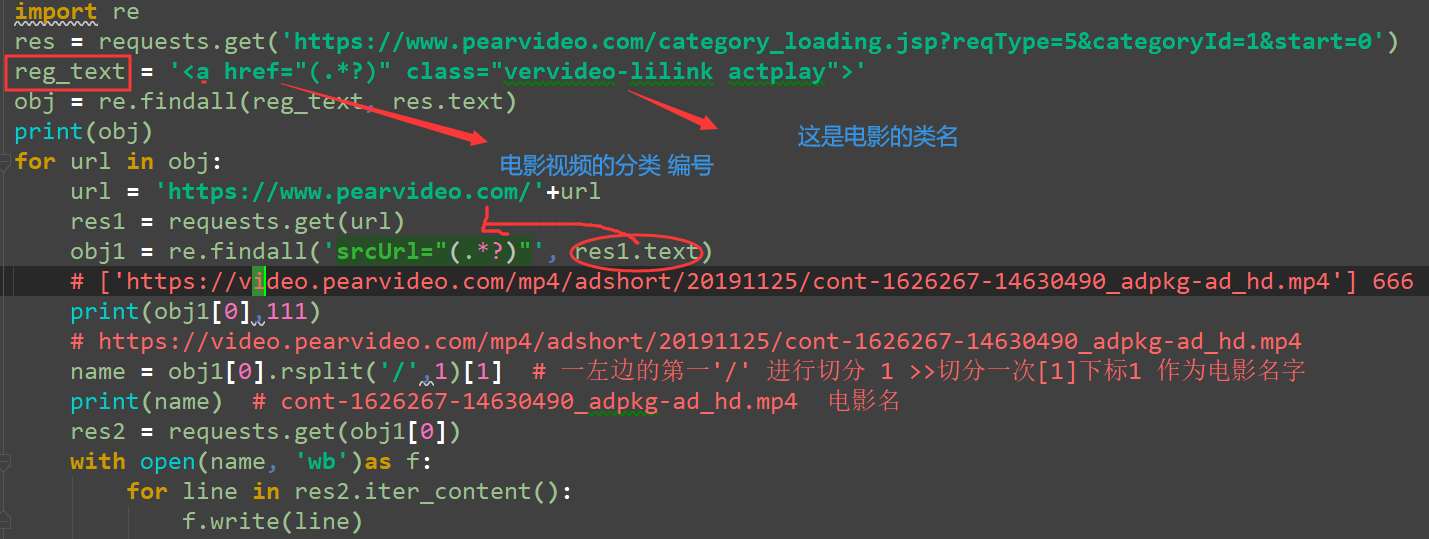
# 爬取视频 # Request URL: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=12&mrd=0.025906198752709164&filterIds=1625830,1625746,1625846,1626267,1626185,1625876,1626253,1626235,1626236,1626232,1626243,1626215,1626218,1626241,1625836 # Request URL: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0 #从第零条开始 import re res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0') reg_text = '<a href="(.*?)" class="vervideo-lilink actplay">' obj = re.findall(reg_text, res.text) print(obj) for url in obj: url = 'https://www.pearvideo.com/'+url res1 = requests.get(url) obj1 = re.findall('srcUrl="(.*?)"', res1.text) # ['https://video.pearvideo.com/mp4/adshort/20191125/cont-1626267-14630490_adpkg-ad_hd.mp4'] 666 print(obj1[0],111) # https://video.pearvideo.com/mp4/adshort/20191125/cont-1626267-14630490_adpkg-ad_hd.mp4 name = obj1[0].rsplit('/',1)[1] # 一左边的第一'/' 进行切分 1 >>切分一次[1]下标1 作为电影名字 print(name) # cont-1626267-14630490_adpkg-ad_hd.mp4 电影名 res2 = requests.get(obj1[0]) with open(name, 'wb')as f: for line in res2.iter_content(): f.write(line)
url_text

· 后端代码
4. 明天。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号