

spark集群搭建
文中的所有操作都是在之前的文章scala的安装及使用文章基础上建立的,重复操作已经简写;
配置中使用了master01、slave01、slave02、slave03;
一、虚拟机中操作(启动网卡)
sh /install/initNetwork.sh
ifup eth0
二、基础配置(主机名、IP配置、防火墙及selinux强制访问控制安全系统)
vi /etc/sysconfig/network (配置磁盘中主机名字)
vi /etc/hosts (配置映射,)
hostname 主机名 (修改内存中主机名)
然后,重新链接查看是否成功;
vi /etc/sysconfig/network-scripts/ifcfg-eth0
查看内容是否设置成功:cat /etc/sysconfig/network-scripts/ifcfg-eth0

DEVICE=eth0 (设置需要重启的设备的名字) TYPE=Ethernet(以太网) ONBOOT=yes (设置为yes) NM_CONTROLLED=yes BOOTPROTO=static (设置为静态) IPADDR=192.168.238.130 (本机IP地址) NETMASK=255.255.255.0 (子网掩码) GATEWAY=192.168.238.2 (网关)(查询本机网关:route -n) DNS1=192.168.238.2 DNS2=8.8.8.8 (谷歌IP地址)
vi /etc/sysconfig/selinux
修改:SELINUX=disabled
去掉注释查看selinux内容:
grep -Ev '^#|^$' /etc/sysconfig/selinux
永久关闭防火墙:
service iptables stop
chkconfig iptables off
三、配置ssh免密登录(为root用户配置免s密码登录)
只需要master登录到salve各个节点即可,无需反向
[root@master01 ~]# ssh-keygen -t rsa 创建公匙
[root@master01 ~]# ssh-copy-id slave02 拷贝公匙
大数据学习交流群:217770236 让我我们一起学习大数据
四、搭建Spark集群
1、上传安装包到/install/目录
[root@master01 install]# ls
initNetwork.sh mytest.txt scala-2.11.8.tgz spark-2.1.1-bin-hadoop2.7.tgz
2、解压安装包并更名
[root@master01 install]# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /software/
[root@master01 software]# mv spark-2.1.1-bin-hadoop2.7/ spark-2.1.1
3、配置系统环境
[root@master01 install]# vi /etc/profile
修改如下内容:
JAVA_HOME=/software/jdk1.7.0_79 HADOOP_HOME=/software/hadoop-2.7.3 HBASE_HOME=/software/hbase-1.2.6 SCALA_HOME=/software/scala-2.11.8 SPARK_HOME=/software/spark-2.1.1 PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SCALA_HOME/bin::$SPARK_HOME/bin: export PATH JAVA_HOME HADOOP_HOME HBASE_HOME SCALA_HOME SPARK_HOME
[root@master01 install]# source /etc/profile
4、切换到hadoop用户并配置spark-env.sh
[root@master01 software]# su -l hadoop
[hadoop@master01 spark-2.1.1]$ cd /software/spark-2.1.1/conf/
[hadoop@master01 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@master01 conf]$ vi spark-env.sh
添加如下内容:
export JAVA_HOME=/software/jdk1.7.0_79 export SCALA_HOME=/software/scala-2.11.8 export HADOOP_HOME=/software/hadoop-2.7.3 export HADOOP_CONF_DIR=/software/hadoop-2.7.3/etc/hadoop export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=slave01:2181,slave02:2181,slave03:2181 -Dspark.deploy.zookeeper.dir=/spark" #export SPARK_MASTER_IP=master01 #export SPARK_WORKER_MEMORY=1500m
5、如果需要使用浏览器查看日志则需要开启历史日志服务:
[hadoop@master01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
[hadoop@master01 conf]$ vi spark-defaults.conf
添加如下内容:
spark.master spark://master01:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://ns1/sparkLog spark.yarn.historyServer.address master01:18080 spark.history.fs.logDirectory hdfs://ns1/sparkLog
6、配置Spark集群的Worker节点
[hadoop@master01 conf]$ cp slaves.template slaves
[hadoop@master01 conf]$ vi slaves
修改成如下内容:
slave01
slave02
slave03
7、分发Spark的安装目录到各个Worker节点(即原DataNode节点)
#将所有的节点全部切换到hadoop用户
[root@master01 software]# su -l hadoop
[root@slave01 ~]# su -l hadoop
[root@slave02 ~]# su -l hadoop
[root@slave03 ~]# su -l hadoop
#分发Spark的安装目录到各个Worker节点
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave01:/software/
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave02:/software/
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave03:/software/
#分发环境配置文件到各个Worker节点
[root@master01 ~]# scp -r /etc/profile slave01:/etc/
[root@master01 ~]# scp -r /etc/profile slave02:/etc/
[root@master01 ~]# scp -r /etc/profile slave03:/etc/
立即生效配置文件:
[hadoop@slave01 software]$ source /etc/profile
[hadoop@slave02 software]$ source /etc/profile
[hadoop@slave03 software]$ source /etc/profile
五、启动Spark集群
【1、在slave节点启动zookeeper集群(小弟中选个leader和follower)】
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh status && cd -
【2、master01启动HDFS集群】cd /software/ && start-dfs.sh && jps
【3、在master01节点上启动Spark集群的Master节点】
[hadoop@master01 install]$ cd /software/spark-2.1.1/sbin/ && ./start-master.sh && jps
【4、在master01节点上启动Spark集群的所有Slave节点】
[hadoop@master01 sbin]$ cd /software/spark-2.1.1/sbin/ && ./start-slaves.sh && jps
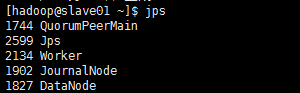
注意:Worker进程是Spark集群的Worker进程
【5、如果需要使用浏览器来查看Spark的日志则需要启动历史日志服务(同样是在master01节点上启动日志服务)】
[hadoop@master01 sbin]$ cd /software/spark-2.1.1/sbin/ && ./start-history-server.sh && jps
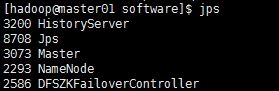
注意:HistoryServer是历史日志服务进程(该进程只会在运行此start-history-server.sh脚本的节点上启动),而Master是Spark集群的Master进程
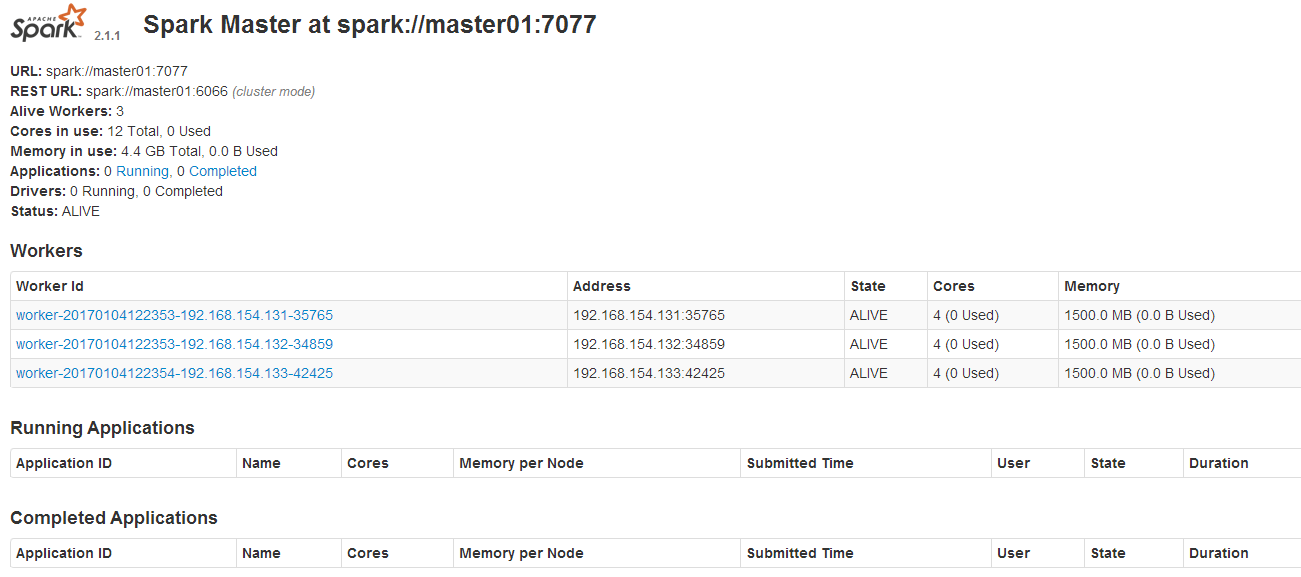
六、验证Spark集群搭建是否成功
1、使用浏览器确认Spark集群服务是否已经正常启动 http://master01的IP地址:8080/ 2、使用浏览器确认Spark日志服务是否已经正常启动(访问的端口18080来自于上面的日志服务配置) http://master01的IP地址:18080/


{kind=link}