第九周周四计划&&周三总结
今天由于自己的原因进度不是很大,今天整理了一下全网关联的思路流程(个人可能就是那种没自信,在思路不知道对不对的情况下不敢下手那种渣渣),和之前的一个学长讨论了一下大概思路流程,如下:
(1)使用LDA模型提取一篇新闻主题词,确定最大概率主题词;
(2)新闻追踪时使用主题与主题之间的关联(相似度比对),汉明距离在一定范围内即可认为是同一主题同一事件的主题,当然因为是词与词之间的比较,所以可能存在不准确的概率,为了提高准确率,这里提取10个主题,每个主题提取6个主题词进行比对,并且对新闻标题与新闻标题之间进行一个比对,这样主题词与标题按占比分配,进而进一步确定是否为同一主题内容。
(3)在实时爬取这里,因为有的网站是按热度排序,所以这里还没有考虑好按什么规律进行爬取,这里还得再想一下。
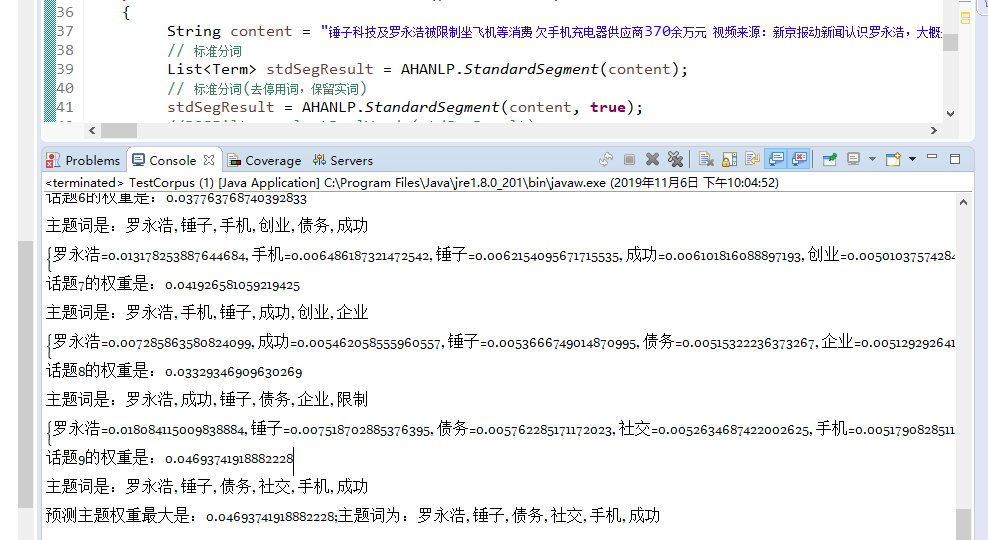
今天主要对主题词的确定流程走了一遍,找了一些停用词的词典,这里给出一个github链接,里面词典比较多:https://github.com/fighting41love/funNLP,在分词时过滤停用词并且挑选指定词性的词进行主题词挑选的环节,如图:

这里有一个小问题,添加了自定义的停用词之后需要把所有的.bin文件删除才生效,我也不知道为什么,只删除停用词的.bin文件不起作用。如图:

最终效果:
明天开始全网关联追踪!加油!
请看到这篇博客的大佬批评指正!我现在特别害怕自己思路跑偏!谢过各位了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号