【服务器性能】CPU架构之NUMA和SMP
1、CPU架构之NUMA和SMP
SMP(Share Memory Mulpti Processor):称为共享内存访问CPU,也称对称型CPU架构。
NUMA(Non Uniform Access):非一致性内存访问
它们最重要的区别在于内存是否绑定在各个物理CPU上,以及CPU如何访问内存。
SMP架构的CPU内部没有绑定内存,所有的CPU争用一个总线来访问所有共享的内存,优点是资源共享,而缺点是总线争用激烈。随着PC服务 器上的CPU数量变多(不仅仅是CPU核数),总线争用的弊端慢慢越来越明显,于是Intel在Nehalem CPU上推出了NUMA架构,而AMD也推出了基于相同架构的Opteron CPU。
NUMA 最大的特点是引入了node和distance的概念,node内部有多个CPU,以及绑定的内存。每个node的CPU和内存一般是相等。distance这个概念是用来定义各个node之间调用资源的开销。NUMA架构中内存和CPU的关系如下图所示:
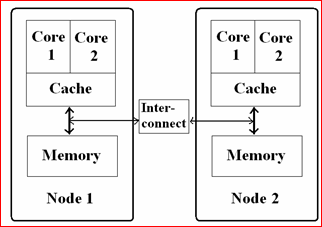
(node内部有多个CPU,node内部有内存;每两个node之间有 inter-connect)
NUMA架构的提出是为了适应多CPU,可以看到node内部的CPU对内存的访问分成了两种情况:
1)对node内部的内存的访问,一般称为 local access,显然访问速度是最快的;
2)对其它node中的内存的访问,一般称为 remote access,因为要通过 inter-connect,所以访问速度会慢一些;
因为CPU和内存是绑定而形成一个node,那么就涉及到CPU如何分配,内存如何分配的问题:
1)NUMA的CPU分配策略有cpunodebind、physcpubind
cpunodebind规定进程运行在某几个Node之上;
physcpubind可以更加精细地规定运行在哪些核上;
2)NUMA的内存分配策略有localloc、Preferred、membind、Interleave
localalloc规定进程从当前node上请求分配内存;
Preferred指定一个推荐的Node来获取内存,如果被推荐的node上没有足够的内存,进程可以尝试别的node;
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存;
Interleave规定进程从所有node上以RR算法交织地请求分配内存,达到随机均匀的从各个node中分配内存的目的。
NUMA架构导致的问题--SWAP:
因为NUMA架构的CPU,默认采用的是localalloc的内存分配策略,运行在本node内部CPU上的进程,会从本node内部的内存上分配内存,如果内存不足,则会导致swap的产生,严重影响性能!它不会向其它node申请内存。这是他最大的问题。
所以为了避免SWAP的产生,一定要将NUMA架构CPU的内存分配策略设置为:interleave; 这样设置的话,任何进程的内存分配,都会随机向各个node申请,虽然remote access会导致一点点的性能损失,但是他杜绝了SWAP导致的严重的性能损失。所以 interleave 其实是将NUMA架构的各个node中的内存,又重新虚拟成了一个共享的内存,但是和SMP不同的是,因为每两个node之间有 inter-connect ,所以又避免了SMP架构总线争用的缺陷。
2、NUMA架构下进程与CPU绑定
如果很多进程运行在CPU的某一个核心上,CPU核心都是和L1直接打交道的,而各个进程间还是切换着轮流运行的,如果L1中全部缓存了进程A的数据,那么当进程B或进程C运行时,极有可能会置换L1中的缓存数据,如果A进程没有运行完,当进程A再次执行时,还需要去置换L1中的缓存数据,这样,各个进程运行时可能每次都要置换L1中的数据,可能大部分时间都浪费在了置换缓存上,所以可以将对性能敏感的进程绑定到某一个或一组核心,将多线程的程序也绑定到某一核心,这样,将大大提高服务器性能。
1)numastat命令:
显示进程与每个NUMA节点的内存分配的统计数据和分配的成功与失败情况。
[root@localhost ~]# numastat
node0 node1
numa_hit 3620312 3672057
numa_miss 0 0
numa_foreign 0 0
interleave_hit 36004 35732
local_node 3608692 3645179
other_node 11620 26878
[root@localhost ~]#
numa_hit:为这个节点成功分配本地内存访问的内存大小
numa_miss:把内存访问分配到另一个Node节点的内存大小,这个值和另一个node的numa_foreign相对应。
numa_foreign:另一个node访问我的内存大小,与对应node的numa_miss相对应
interleave_hit:
local_node: 这个节点的进程成功在这个节点上分配 内存访问的大小
other_node:这个节点的进程,在其他节点上分配 的内存访问的大小
显然,当numa_miss和numa_foreign值越高,就要考虑绑定的问题了。
2)numastat常用参数
-c:紧凑的显示信息,将内存四舍五入到MB单位,适合节点较多时使用
[root@localhost ~]# numastat -c
Per-node numastat info (in MBs):
Node 0 Node 1 Total
------ ------ -----
Numa_Hit 14213 14404 28617
Numa_Miss 0 0 0
Numa_Foreign 0 0 0
Interleave_Hit 141 140 280
Local_Node 14168 14299 28467
Other_Node 45 105 150
-m:显示每个节点中,系统范围内使用内存的情况,可以与其他参数组合使用
[root@localhost ~]# numastat -m
Per-node system memory usage (in MBs):
Node 0 Node 1 Total
--------------- --------------- ---------------
MemTotal 49042.42 65536.00 114578.42
MemFree 47076.42 62881.62 109958.04
MemUsed 1966.00 2654.38 4620.38
Active 309.02 481.74 790.76
Inactive 211.57 528.25 739.82
Active(anon) 247.64 332.04 579.68
Inactive(anon) 9.58 24.37 33.95
Active(file) 61.38 149.70 211.08
Inactive(file) 201.99 503.88 705.88
Unevictable 0.00 0.00 0.00
Mlocked 0.00 0.00 0.00
Dirty 0.00 0.00 0.00
Writeback 0.00 0.00 0.00
FilePages 273.73 678.75 952.47
Mapped 48.25 100.99 149.25
AnonPages 244.70 331.25 575.95
Shmem 10.36 25.16 35.52
KernelStack 5.75 4.25 10.00
PageTables 18.95 17.31 36.26
NFS_Unstable 0.00 0.00 0.00
Bounce 0.00 0.00 0.00
WritebackTmp 0.00 0.00 0.00
Slab 56.42 62.99 119.41
SReclaimable 22.38 31.89 54.28
SUnreclaim 34.04 31.10 65.14
AnonHugePages 96.00 148.00 244.00
HugePages_Total 0.00 0.00 0.00
HugePages_Free 0.00 0.00 0.00
HugePages_Surp 0.00 0.00 0.00
3)numactl命令
可以将某个进程绑定到某个node或某个node上的某个或某组核心上
--show
查看当前的numa策略
[root@localhost ~]# numactl --show policy: default preferred node: current physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 cpubind: 0 1 nodebind: 0 1 membind: 0 1
-H
可显示各node中内存使用情况
[root@localhost ~]# numactl -H available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 4 5 node 0 size: 49042 MB node 0 free: 47079 MB node 1 cpus: 6 7 8 9 10 11 node 1 size: 65536 MB node 1 free: 62878 MB node distances: node 0 1 0: 10 21 1: 21 10
--membind
只从某node分配内存,如果该node内存不足,则会分配失败,格式:
numactl --membind=nodes program #nodes写你要分配的节点0或1或其他节点数 #program是在分配的进程,可以写绝对路径,也可以写服务启动脚本
--cpunodebing
将进程绑定到某节点上,格式:
numactl --cpunodebind=nodes program #nodes为节点数 #program进程
--physcpubind
把进程绑定到某核心上,格式:
numactl --physcpubind=1,2,3,4 Program #或 numactl -C 1,2,3,4 Program
--localloc
指令永远在当前节点分配内存,格式:
numactl -l program 或 numactl -i program 或 numactl -p program 或 numactl -m program #memory policy is --interleave | -i, --preferred | -p, --membind | -m, --localalloc | -l 具体见上文的内存分配策略
参考文档:
https://blog.51cto.com/hl914/1557615?source=drt
https://www.cnblogs.com/digdeep/p/4847484.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号