Kaggle系列-房价预测-EDA
Kaggle系列
接触数据科学领域一段时间了,最近开始kaggle之旅,这系列博客主要是记录自己的学习过程,由于还是大二,属于初学者,能力有限,参考了很多大佬的优秀notebook。欢迎志同道合的朋友在评论席留言一同组队学习。
数据链接下面是kaggle房价预测的一个EDA
# 导入基本的库
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as stats
import sklearn.linear_model as linear_model
import seaborn as sns
import xgboost as xgb
from sklearn.model_selection import KFold
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from IPython.display import HTML, display
pd.options.display.max_rows = 1000 # 设置最大可见行1000
pd.options.display.max_columns = 20 # 设置最大可见列20
数据导入
# 读取数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()

将数据进行分类
# 数值型
quantitative = [f for f in train.columns if train.dtypes[f] != 'object'] # 通过列表推导式来接受数值型数据和类别型数据
quantitative.remove('SalePrice')
quantitative.remove('Id')
# category
qualitative = [f for f in train.columns if train.dtypes[f] == 'object']
print(train.shape)
print(len(quantitative))
print(len(qualitative))
结果表明
有1460个训练数据实例和1460个测试数据实例。
特征总数等于81,其中36个是定量特征,43个是分类+ Id和SalePrice。
查看缺失数据和异常
missing = train.isnull().sum()
missing = missing[missing>0]
missing.sort_values(inplace=True)
missing.plot.bar()
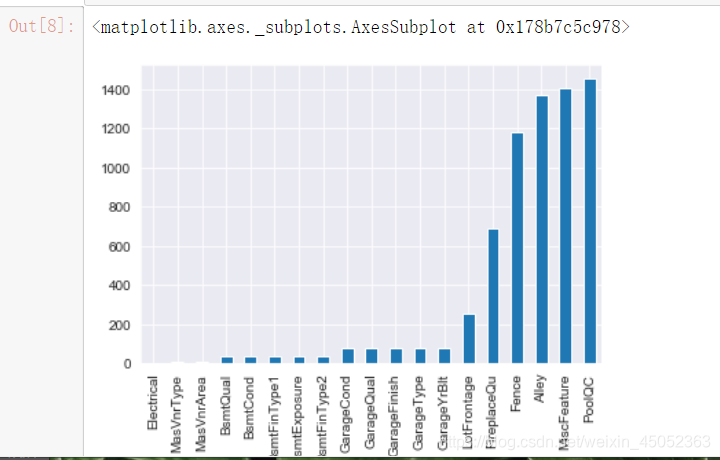
19个属性的值缺失,其中4个超过50%。
大多数情况下,NA意味着缺少按属性描述的主题,例如缺少游泳池,围墙,没有车库和地下室。
观察saleprice分布
import scipy.stats as st
y = train['SalePrice']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Norm')
sns.distplot(y, kde=False, fit=st.lognorm)
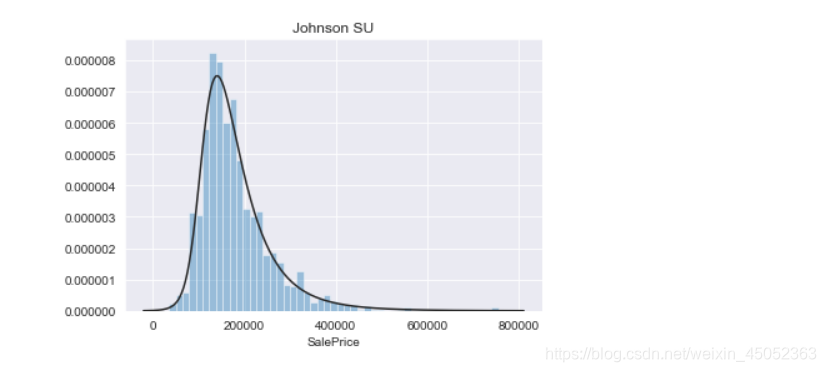


显然,SalePrice不遵循正态分布,因此在执行回归之前必须先对其进行转换。
虽然对数转换做得很好,但最合适的方法是无限的Johnson分布。
下面对特征进行正态性检验
test_normality = lambda x: stats.shapiro(x.fillna(0))[1] < 0.01
normal = pd.DataFrame(train[quantitative])
normal = normal.apply(test_normality)
print(not normal.all())
结果为False
说明所有的特征都不符合正态分布
对于category数据
- 使用定性变量,我们可以实现两种方法。
第一个是检查SalePrice关于变量值的分布并枚举它们。
其次,为每个可能的类别创建虚拟变量。
# 通过这些category的数据对saleprice的影响可视化分析
for c in qualitative:
train[c] = train[c].astype('category')
if train[c].isnull().any():
train[c] = train[c].cat.add_categories(['MISSING'])
train[c] = train[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(train, id_vars=['SalePrice'], value_vars=qualitative )
g = sns.FacetGrid(f, col='variable', col_wrap=2, sharex=False, sharey=False, height=5)
g = g.map(boxplot, 'value', 'SalePrice')

关于SalePrice,某些类别似乎比其他类别更为多样化。
街道对房价产生很大影响。
最高的似乎是Partial SaleCondition。
所拥有的财富似乎大大提高了价格。
类别值之间的差异也有所不同。
进行方差分析
- 不同总体直接的均值是否存在差异,原假设是 h 0 : a 1 = a 2 = a 3 h0:a1=a2=a3 h0:a1=a2=a3
def anova(frame):
anv = pd.DataFrame()
anv['feature'] = qualitative
pvals = []
for c in qualitative:
samples = []
for cls in frame[c].unique():
s = frame[frame[c] == cls]['SalePrice'].values
samples.append(s)
pval = stats.f_oneway(*samples)[1]
pvals.append(pval)
anv['pval'] = pvals
return anv.sort_values('pval')
a = anova(train)
a['disparity'] = np.log(1./a['pval'].values)
sns.barplot(data=a, x='feature', y='disparity')
x=plt.xticks(rotation=90)
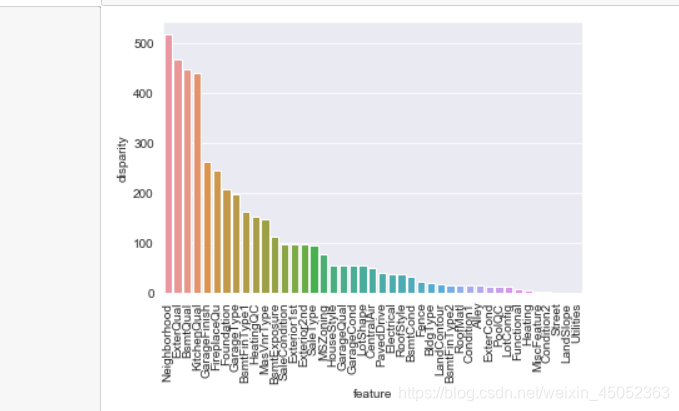
这是类别变量对SalePrice的影响的快速估计。对于每个变量,SalePrices根据类别值划分为不同的集合。然后使用方差分析测试集是否具有相似的分布。如果变量的影响较小,则设定均值应相等。pval的减少是分区多样性增加的标志。
相关性分析
- 减少冗余问题,或者避免多重共线性的影响,我们一般选取特征的时候选取不相关的
def spearman(frame, features):
spr = pd.DataFrame()
spr['feature'] = features
spr['spearman'] = [frame[f].corr(frame['SalePrice'], 'spearman') for f in feartures]
spr = spr.sort_values('spearman')
plt.figure(figsize=(6, 0.25*len(feartures)))
sns.barplot(data=spr, y='feature', x='spearman', orient='h')
feartures = quantitative + qual_encoded
spearman(train, feartures)
在本题情况下,使用Spearman相关性更好,因为即使它们是非线性的,它也可以获取变量之间的关系。综合质量是制定房价的主要标准。街道影响很大,部分本身具有内部价值,但某些地区的房屋也倾向于具有相同的特征,从而导致相似的估值。
斯皮尔曼相关系数和皮尔逊相关系数区别如下
- 1连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以,效率没有pearson相关系数高。
- 2上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
- 3两个定序测量数据(顺序变量)之间也用spearman相关系数,不能用pearson相关系数。
- 4Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
- 上述因为数据不满足正态分布,且存在一部分的定类数据因此我们使用spearman相关系数
接下来观察数值型数据和category数据不同特征之间的相关性
plt.figure(1)
corr = train[quantitative+['SalePrice']].corr()
sns.heatmap(corr)
plt.figure(2)
corr = train[qual_encoded+['SalePrice']].corr()
sns.heatmap(corr)


变量之间有许多强相关性。车库似乎与房屋建于同一年,地下室的面积通常与一楼相同,这是显而易见的。车库面积与汽车数量密切相关。邻居与许多其他变量相关联,这证实了同一地区的房屋具有相同特征的想法。居住类型与高等级的厨房呈负相关。
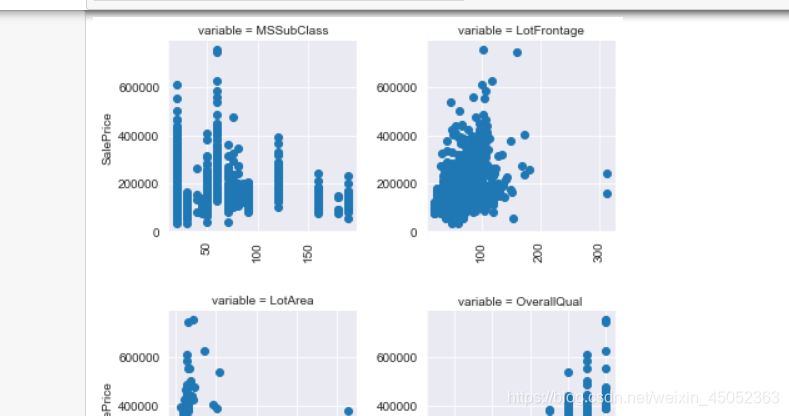
Pairplots
- 看每一个特征与y的关系
def pairplot(x, y, **kwargs):
ts = pd.DataFrame({'time': x, 'val': y})
plt.scatter(ts['time'], ts['val'])
plt.xticks(rotation=90)
f = pd.melt(train, id_vars=['SalePrice'], value_vars=quantitative+qual_encoded)
g = sns.FacetGrid(f, col='variable', col_wrap=2, sharex=False, sharey=False)
g = g.map(pairplot, 'value', 'SalePrice')
参考资料
邮箱:ypj1981834607@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号