数据挖掘基础-基本流程
建模与问题解决流程
- 1 赛题理解
- 2 数据分析(EDA)
- 3 特征工程
- 4 模型选择
- 5 模型融合
机器学习基本算法
主要分为监督学习、无监督学习、半监督学习
1.监督学习
- Regression
linear
Polynomial - decision Tree
- random forest
- classfication
KNN
Trees
logistices
svm
naive-bayes
2.无监督学习
- 聚类和降维
SVD
PCA
K-means - 关联分析
Apriori
FP-growth - 隐马尔可夫模型
1 数据分析
- 特征类型分析
- 缺失值分析
- 异常值分析
- 目标分布情况
- 特征分布情况
- 特征与目标的相关性
- 特征与特征之间的相关性
…
具体可参考我的上一篇博客EDA
2.特征工程
2.1 特征处理
-
数值型
特征缩放
归一化
多项式
异常值
缺失值填充
数据转换(取log等) -
类别型
One-hot 编码 -
时间类
将其分成间隔型将其进行组合:例如某个顾客周末上淘宝的次数
将其离散化:例如周末设置为1,周内设置为0
-
文本型
bag of words, TF-IDF
2.2特征选择
- 1 过滤型
- 2 包裹型
- 3 嵌入型: 这里使用L1正则化,使用之后会有一部分特征的权重变为0
使用scikit-learn库进行特征处理
3.模型选择
3.1交叉验证
我们根据不同的问题训练多个模型后,该如何选择呢?我们比较常用的方法就是进行交叉验证,选择泛化能力最好的模型
这里选取K折交叉验证,将训练集分为N份,每次选取其中的一份作为验证集,剩下的作为训练集。通过模型在验证集上泛化能力的表现来进行选择

3.2gridsearch:调整超参数
在我们选择好模型之后,我们可以通过gridsearch来调整超参数

3.3模型评估
当我们的模型进行过上述操作的时候,我们如何来评估呢,
一般模型可能会出现过过拟合和欠拟合两种问题,主要导致的原因是variance 和 vias,我们通过learning curve(学习曲线)来对其进行评估
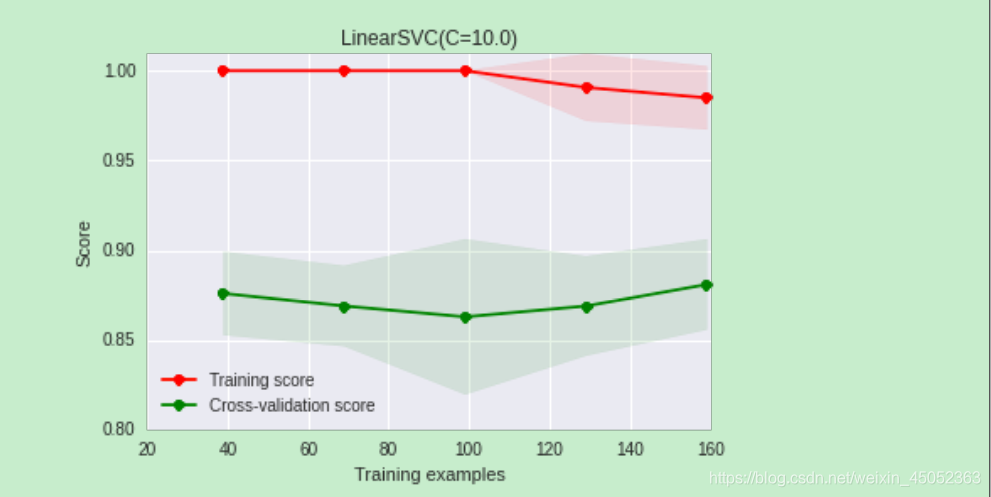
4.模型融合
1.简单加权融合:
- 回归(分类概率):算术平均融合,集合平均融合
- 分类(Voting)
- 综合(排序融合),log融合
2.stacking
- 构建多层模型,前面的模型预测结果作为输入在进行训练,有点类似神经网络
3.blending
- 将多个模型融合
4.bagging
- 使用boostrap的方法,得到多个不同的样本
5.boosting
- 多树的提升方法
下面展示使用stacking进行模型融合的效果
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 使用iris()位置的鸢尾花数据集
iris = datasets.load_iris()
# 选取两个特征来训练
X, y = iris.data[:, 1:3], iris.target
# 我们训练以下三个模型
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
# 使用stacking融合的模型
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
# 模型进行可视化
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(label)
plt.show()
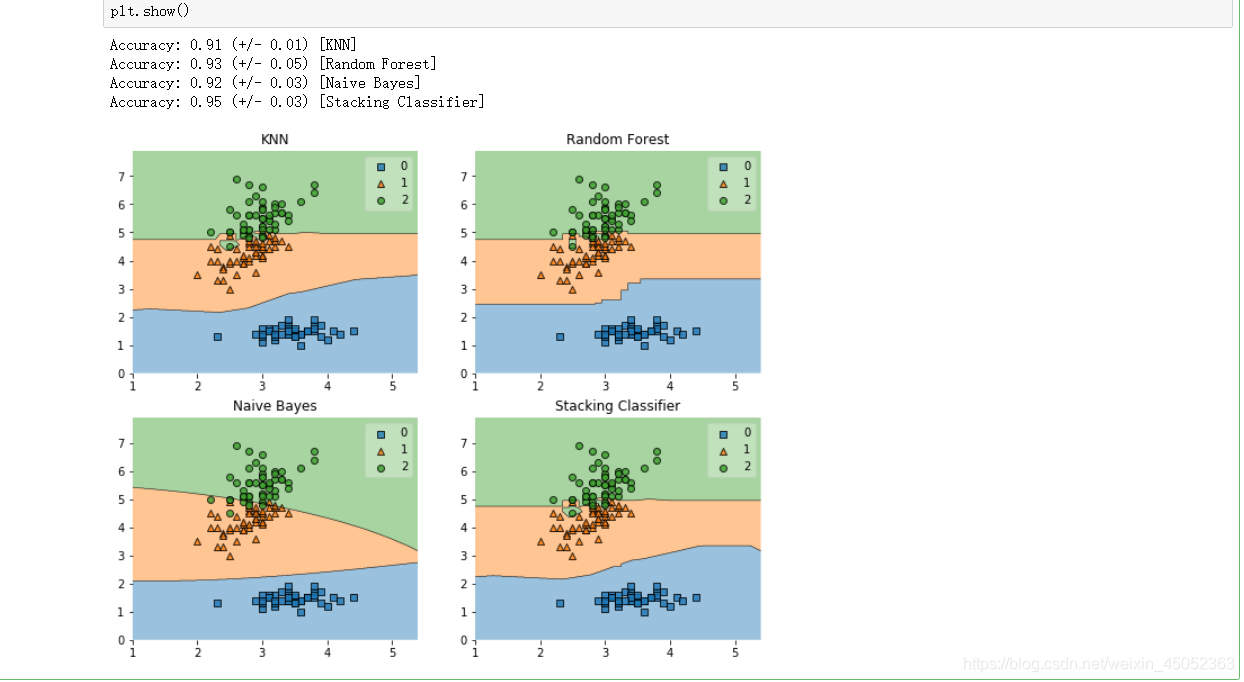
我们发现stacking的accuracy最高,说明了使用模型融合的方法提高了我们模型的准确度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号