




第7章 反向传播算法
反向传播算法的三个阶段:
- 1.前向传播求原函数值
- 2.反向传播根据输出层误差求梯度
- 3.根据梯度信息进行优化
反向传播算法本质上解决的问题:帮助机器快速的从参数空间里找到较好的参数组合。
7.3 激活函数导数
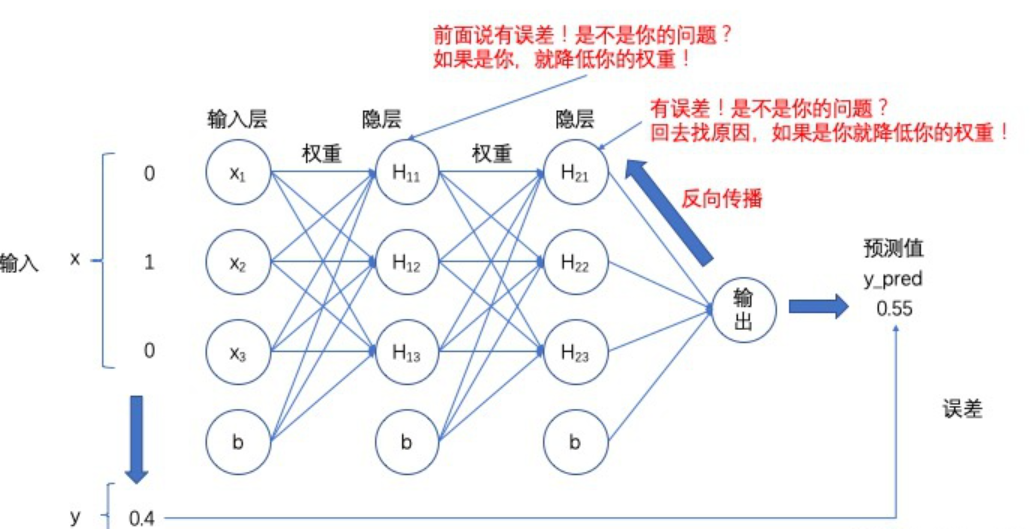
7.3.1 Sigmoid 函数导数
Sigmoid 函数也叫Logistic函数,定义为
Sigmoid函数的导数表达式:
在神经网络的梯度计算中,通过缓存每层的 Sigmoid 函数输出值,即可在需要的时候计算出其导数。
7.3.2 ReLU函数导数
ReLU 函数定义 :
它的导数推导非常简单,直接可得 :
在反向传播的时候,它既不会放大梯度,造成梯度爆炸(Gradient exploding); 也不会缩小梯度,造成梯度弥散(Gradient vanishing)。

7.3.3 LeakyReLU 函数导数
LeakyReLU 函数的表达式:
它的导数推导为
p 一般设置为一个较小的数值,如 0.01 或 0.02
7.3.4 Tanh函数梯度
tanh 函数的表达式:
它的导数推导为 :

7.4 损失函数梯度
7.4.1 均方差函数梯度
均方差损失函数表达式为:
均方差的导数推导为:
7.4.2 交叉熵函数梯度
在计算交叉熵损失函数时,一般将 Softmax 函数与交叉熵函数统一实现。我们先推导Softmax 函数的梯度,再推导交叉熵函数的梯度。
Softmax 梯度
Softmax函数表达式:
-
当
i=j时Softmax 函数的偏导数可以推导为 :\(p_i(1-p_j)\)
-
当
i≠j时
Softmax 函数的偏导数可以推导为:
交叉熵梯度
交叉熵损失函数的表达式:
交叉熵的偏导数可以进一步简化为
7.5 全连接层梯度
7.5.1 单个神经元梯度
采用均方差函数,单个神经元只有一个输出\(o_1^1\),损失函数可以表达为
其中𝑡为真实标签值 ,一权值链接的第j号节点的权值\(w_{j1}\)为例,考虑损失函数L对其的偏导数$\frac{\partial L}{\partial w_{j1}} $:
从上式可以看到, 误差对权值\(w_{j1}\)的偏导数只与输出值\(o_1\)、 真实值𝑡以及当前权值连接的输入\(x_j\)有关。
7.5.2 全连接层梯度
多输出的全连接网络层模型与单个神经元模型不同之处在于, 它多了很多的输出节点\(o_1^1,o_2^1,o_3^1,...o_k^1\) ,每个输出节点分别对应到真实标签\(t_1,t_2,...,t_k\)。
最终可得
由此可以看到, 某条连接\(w_{jk}\)上面的连接,只与当前连接的输出节点\(o_k^1\), 对应的真实值节点的标签\(t_k^1\) ,以及对应的输入节点\(x_j\)有关。
7.7反向传播算法

每层的偏导数的计算公式
**输出层: **
倒数第二层:
倒数第三层:
其中\(o_n\)为倒数第三层的输入,即倒数第四层的输出。
依照此规律,只需要循环迭代计算每一层每个节点的𝛿𝑘𝐾, 𝛿 , 𝛿𝑖𝐼, …等值即可求得当前层的偏导数,从而得到每层权值矩阵 W 的梯度,再通过梯度下降算法迭代优化网络参数即可。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号