
面向对象第一单元总结
第一单元的作业是表达式化简,从第一次的单层括号表达式化简开始迭代开发,在第二次作业加入求和函数、三角函数与自定义函数,在第三次作业加入函数与括号的嵌套形式。针对输入数据的格式要求,个人的总体思路如下:读入数据→处理数据格式→解析表达式→化简表达式→输出结果。
第一次作业
结构分析
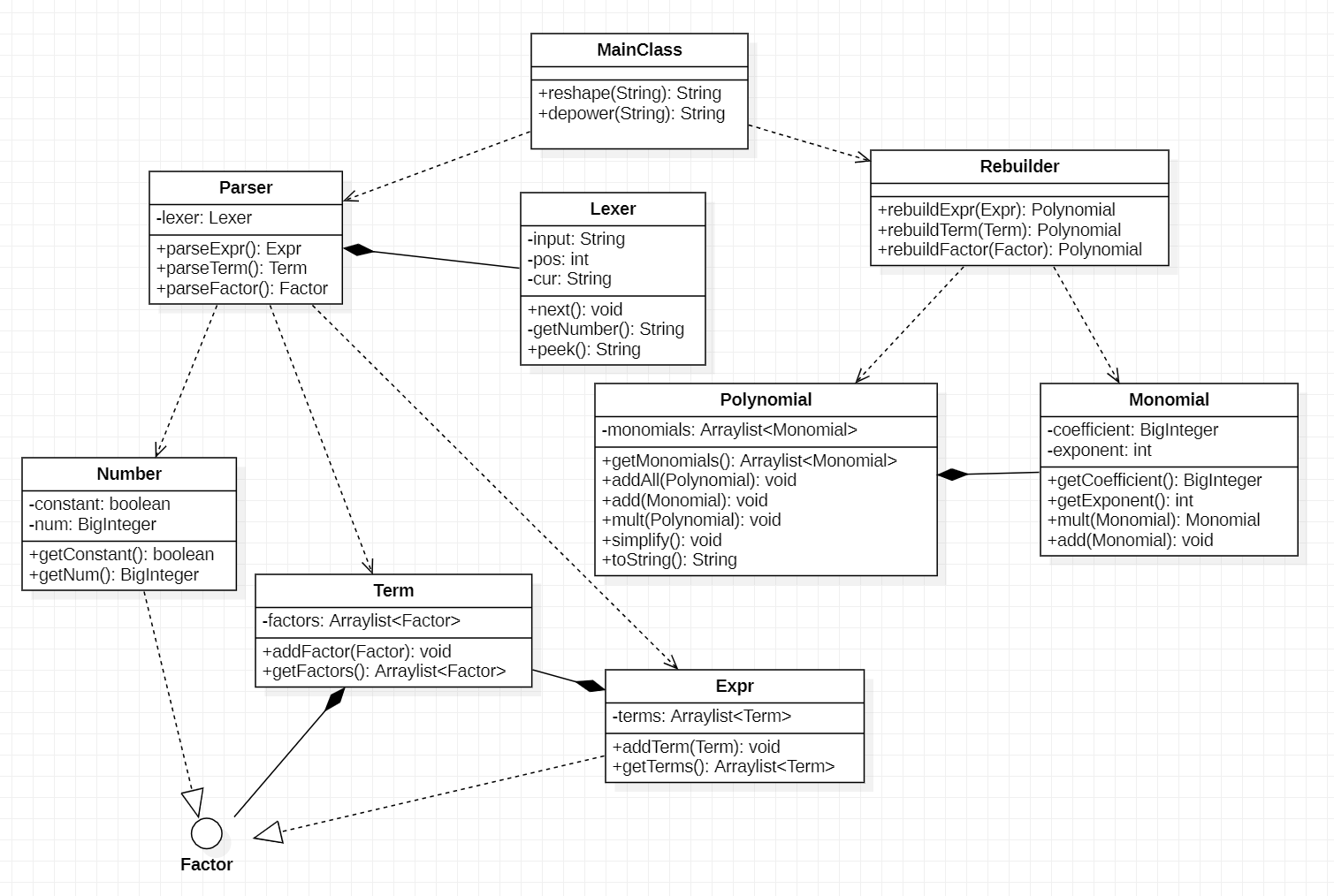
读入的数据首先进行预处理,去除空白字符,化简多重正负号,将指数拆开为若干项的积。之后便可以按照加法、乘法对表达式进行拆分,避免了空白字符处理等复杂判断。第一次作业的数据比较简单,因此通过正则表达式匹配并替换字符串便能解决问题。
我采用了训练中介绍的递归下降法来拆分表达式,将表达式逐层分解为:Expression,Term,Factor。Parser是分解表达式的工具,通过Lexer读取表达式内容,将Expression拆解为若干Term之和,将Term拆解为Factor之积,由此即可拆分表达式内容。
拆分后的表达式需要重新构建并计算、化简,最终结果是有关x的多项式,每一项为常数与幂函数之积。针对这一特点,我用Polynomial类存储多项式,用Monomial类存储单项式,并仿照Parser设计了Rebuilder:对于表达式,求出各项之和;对于项,求各因子之积。Monomial中保存该项的系数coefficient与指数exponent,因此可将加法实现为对同指数项的系数求和,将乘法实现为对系数求积、对指数求和。最后对Polynomial重写toString方法便能得到最终输出结果。
方法复杂度
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expr.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.getNumber() | 3.0 | 1.0 | 4.0 | 4.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 4.0 | 2.0 | 3.0 | 4.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.depower(String) | 10.0 | 1.0 | 3.0 | 7.0 |
| MainClass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.reshape(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Monomial.add(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.getExponent() | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.Monomial(BigInteger, int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.mult(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.setExponent(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.getconstant() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.getnum() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.Number() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.Number(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseFactor() | 4.0 | 4.0 | 4.0 | 4.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Polynomial.add(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.addAll(Polynomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.getMonomials() | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.mult(Polynomial) | 3.0 | 1.0 | 3.0 | 3.0 |
| Polynomial.simplify() | 13.0 | 7.0 | 6.0 | 7.0 |
| Polynomial.toString() | 23.0 | 4.0 | 7.0 | 12.0 |
| Rebuilder.rebuildExpr(Expr) | 1.0 | 1.0 | 2.0 | 2.0 |
| Rebuilder.rebuildFactor(Factor) | 3.0 | 2.0 | 3.0 | 3.0 |
| Rebuilder.rebuildTerm(Term) | 2.0 | 2.0 | 2.0 | 3.0 |
| Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 69.0 | 50.0 | 65.0 | 77.0 |
| Average | 1.97 | 1.43 | 1.86 | 2.2 |
类复杂度
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expr | 1.0 | 1.0 | 2.0 |
| Lexer | 1.75 | 3.0 | 7.0 |
| MainClass | 3.33 | 7.0 | 10.0 |
| Monomial | 1.0 | 1.0 | 7.0 |
| Number | 1.0 | 1.0 | 4.0 |
| Parser | 2.25 | 4.0 | 9.0 |
| Polynomial | 4.0 | 11.0 | 24.0 |
| Rebuilder | 2.67 | 3.0 | 8.0 |
| Term | 1.0 | 1.0 | 2.0 |
| Total | 73.0 | ||
| Average | 2.09 | 3.56 | 8.11 |
可以看出大部分代码的耦合度都比较低,复杂度较高的代码集中在Parser与Polynomial中,原因是Parser中使用递归下降的方法解析表达式,而Polynomial中需要在重建表达式时进行计算与化简。
Bug修复
第一次作业中的Bug正则表达式使用错误导致拆解表达式指数时错误,由前面的左括号跨过若干项匹配到后面的右括号及指数,例如当输入形式为(表达式)+(表达式)**指数时匹配范围会变成两个表达式,导致处理错误。该问题在于正则表达式使用细节掌握不够。
第二次作业
第二次作业增加了对自定义函数、三角函数与求和函数的要求。在思考本次作业的架构时,我没有进行很多思考,沿用了上一次的思路,在预处理表达式时替换自定义函数与求和函数,即在字符串层面进行处理。这种思路简单直接,但正如老师与助教所说,不利于迭代开发,并且处理起来坑点很多。这次作业中,我想办法规避了处理中潜在的问题,但无法回避迭代开发上的缺陷,也导致了我在第三次作业中不得不重构代码。但一些对函数的处理方法,则在第三次作业中得以沿用。
自定义函数
自定义函数在表达式之前读入,因此需要用函数类Func存储。函数的定义式由等号分开,后半部分表达式可直接以字符串的形式存储,前半部分包括函数名与形参,依次存储在ArrayList中。调用时,依次读取实参并替换函数表达式中的形参,由于ArrayList保留元素顺序,因此可直接将实参与形参对应。此处的坑点在于:作为形参的x会替换作为实参输入的x,对此,我在函数读入时将小写x替换为大写X,便回避了这一问题。
三角函数
为存储三角函数,我新建了三角类TriFunc,该类继承了Factor接口,可作为因子处理。TriFunc中存储函数类型(sin, cos)与内部因子,其中内部因子在本次作业中以字符串的形式直接存储,因此难以比较与化简。而在Monomial类中,也相应添加了ArrayList用于储存单项式中的三角函数。
求和函数
本次求和函数的处理比较简单:首先匹配sum字段与括号;之后将中间内容由","划分,得到下限、上限与求和表达式;最后依次用数字替换求和表达式中的"i",得到求和函数对应的表达式。与自定义函数相似,求和函数处理时可能会将正弦函数字段中的"i"替换,对此我将"sin"预先替换为了"sn"。
优缺点分析
本次作业中,我的代码结构与设计思路可以说是非常不好,因此也不作过多分析。
- 优点:思路简单直接,且为第三次作业的细节处理摸索了一些方法。
- 缺点:除以上所述外,均为缺点。
第三次作业
结构分析
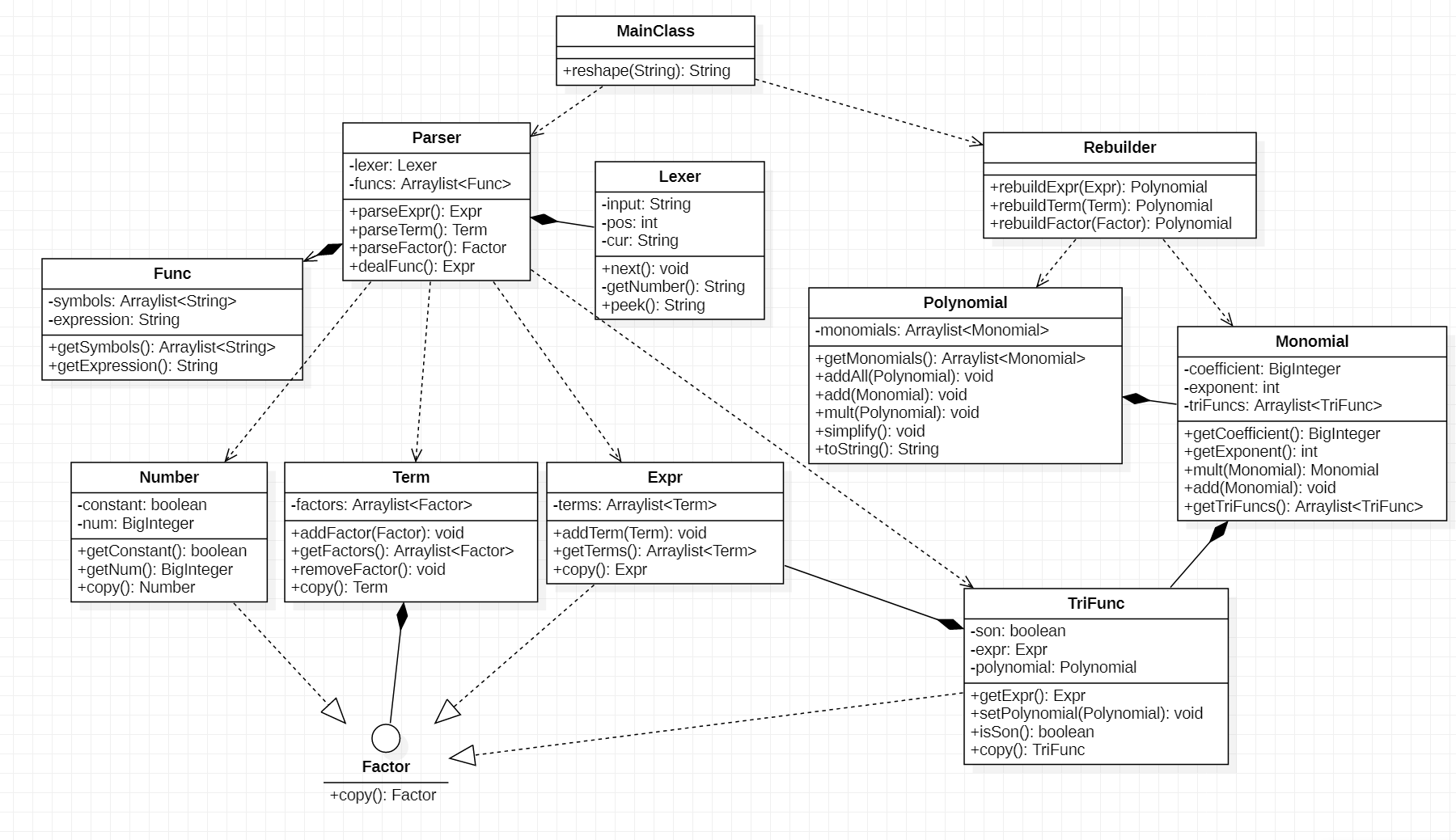
如前文所说,我抛弃了第二次作业的架构,在第一次作业的基础上完成了本次设计。与前两次作业相比,本次的设计有不少改动,一是为了实现更好的模式、改正结构上的问题,二是为了面对新的设计要求:函数与括号的嵌套使用。本次设计的主要改动如下:
1. 三角函数
本次作业的TriFunc类采用Expr类储存内部因子,实现了对其内部的解析,有别于上一次作业中直接用字符串存储而难以处理。
2. 指数
由于嵌套括号的存在,在字符串层面拆解指数将非常复杂,很容易出现问题。考虑到指数无论出现在什么位置,都作用于最近读取到的因子(表达式因子、三角函数因子与变量因子),在解析项的过程中,当读入指数时,将该项中保存的最后一个因子复制相应次数并加入项,即可实现对指数的解析。需要注意的是,复制因子需要生成新的对象,避免ArrayList中的若干元素指向同一对象,否则造成计算过程中的错误。
3. 自定义函数与求和函数
自定义函数与求和函数的处理改为在解析过程中执行。当Lexer匹配到相应因子时,用新的Parser解析替换后的内容,并将该整体作为因子加入到项中。当遇到嵌套的自定义函数时,可直接向下递归,不需要多余处理。
方法复杂度
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expr.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.copy() | 1.0 | 1.0 | 2.0 | 2.0 |
| Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.Func(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Func.getExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.getSymbols() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.getNumber() | 3.0 | 1.0 | 4.0 | 4.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 20.0 | 2.0 | 9.0 | 15.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.depower(String) | 10.0 | 1.0 | 3.0 | 7.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| MainClass.reshape(String) | 2.0 | 1.0 | 3.0 | 3.0 |
| Monomial.add(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.getExponent() | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.getTriFuncs() | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.Monomial(BigInteger, int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.Monomial(BigInteger, int, ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.Monomial(TriFunc) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.mult(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Monomial.setExponent(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.copy() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.getconstant() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.getnum() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.Number() | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.Number(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.dealFunc() | 12.0 | 8.0 | 8.0 | 9.0 |
| Parser.parseExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseFactor() | 14.0 | 8.0 | 10.0 | 10.0 |
| Parser.Parser(Lexer, ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 11.0 | 1.0 | 6.0 | 6.0 |
| Polynomial.add(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.addAll(Polynomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.getMonomials() | 0.0 | 1.0 | 1.0 | 1.0 |
| Polynomial.mult(Polynomial) | 3.0 | 1.0 | 3.0 | 3.0 |
| Polynomial.simplify() | 8.0 | 4.0 | 6.0 | 6.0 |
| Polynomial.toString() | 38.0 | 9.0 | 17.0 | 23.0 |
| Rebuilder.rebuildExpr(Expr) | 2.0 | 2.0 | 2.0 | 3.0 |
| Rebuilder.rebuildFactor(Factor) | 6.0 | 2.0 | 4.0 | 4.0 |
| Rebuilder.rebuildTerm(Term) | 2.0 | 2.0 | 2.0 | 3.0 |
| Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.copy() | 1.0 | 1.0 | 2.0 | 2.0 |
| Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.removeFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.copy() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.getExpr() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.getPolynomial() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.isSon() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.setPolynomial(Polynomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.TriFunc() | 0.0 | 1.0 | 1.0 | 1.0 |
| TriFunc.TriFunc(String, ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 136.0 | 82.0 | 122.0 | 141.0 |
| Average | 2.57 | 1.55 | 2.30 | 2.66 |
类复杂度
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expr | 1.33 | 2.0 | 4.0 |
| Func | 1.33 | 2.0 | 4.0 |
| Lexer | 3.75 | 11.0 | 15.0 |
| MainClass | 4.0 | 7.0 | 12.0 |
| Monomial | 1.0 | 1.0 | 10.0 |
| Number | 1.0 | 1.0 | 5.0 |
| Parser | 5.0 | 9.0 | 25.0 |
| Polynomial | 4.67 | 18.0 | 28.0 |
| Rebuilder | 3.33 | 4.0 | 10.0 |
| Term | 1.25 | 2.0 | 5.0 |
| TriFunc | 1.0 | 1.0 | 7.0 |
| Total | 125.0 | ||
| Average | 2.36 | 5.27 | 11.36 |
本次代码总体情况依然较好,但复杂度有所上升,有以下几个原因:
- 自定义函数与求和函数交给Parser处理,并由Lexer读取,导致二者复杂度明显上升;
- 各函数的解析需要进入下一级、创建新的Parser与Lexer对象,有别于前两次作业中交给一个Parser处理;
- Polynomial.toString方法中,判断三角函数内部是否是表达式因子时需要调用其内部Polynomial对象的toString方法,造成方法对自身的反复调用。
Bug修复
本次作业在强测与互测流程中未发现Bug。(但化简工作并不彻底)
优缺点分析
优点:
- 通过重构代码实现了更加完善的架构,解决了第二次作业中存在的重大隐患。
- 在内存容量范围内,程序可实现任意多层括号与自定义函数的嵌套,计算任意大小的系数与int范围内的非负指数。
缺点:
- 三角函数有关化简不到位,还能进一步合并,导致本次强测性能分低;
- 三角函数内表达式因子的判断造成toString方法对自身的反复调用,若改为对Polynomial的组成结构进行判断可降低耦合度;
- Parser与Lexer,Lexer与inputString之间均严格绑定,导致解析过程中需要反复生成新的Parser与Lexer对象,这一点对前两次作业没有影响,但在本次作业则有突出的体现;
- 在解析过程中处理自定义函数的设计,导致自定义函数需要通过Parser层层向下传递,处理过程不够优雅,对此尚未想到有效的解决方法。
Hack策略
在本单元的作业中,我的数据构造集中在细节与边界的处理,比如0指数、多重正负号与前导零等,进一步有将11*x化简为1x的问题。特别地,对于第三次作业,有求和上下限超过int数据范围、三角函数内表达式因子未加括号等问题。除这些以外,个人认为不同的处理方式会导致Bug出现形式的不同,例如在第三次作业的架构下,第一次作业的Bug不可能出现。因此需要尽可能尝试输入数据的每一种组合,或是认真分析代码、找到其中的漏洞。
架构设计体验
本单元的架构给我留下了深刻的印象。第一次作业中,我考虑过许多方法,包括堆栈、二叉树等。对于二叉树甚至已经设计了比较完善的计算、化简流程。而参照往年作业的迭代模式,预估第二次作业的新要求,我最终选择了训练模块中给出的递归下降法。而这个结构贯穿了我在本单元的三次作业。而第二次作业中欠下的分析过程,则带来了恶果:当其他同学只需简单修改即可提交第三次作业时,我需要回到前一步重构代码。二者的对比,凸显了架构的重要性。
心得体会
上个学期,我学习了Java程序设计课程,了解到Java是一门面向对象的语言,并完成了大作业。而经过本次训练,我才真正开始理解面向对象的含义,也开始不忍直视当初写的“面向过程”的Java代码。对于“方法不能超过60行”等格式要求,我最初有些无法接受,现在也有些理解其用意了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号