[数据采集与融合技术]第五次大作业
作业①:
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
关键词:学生自由选择
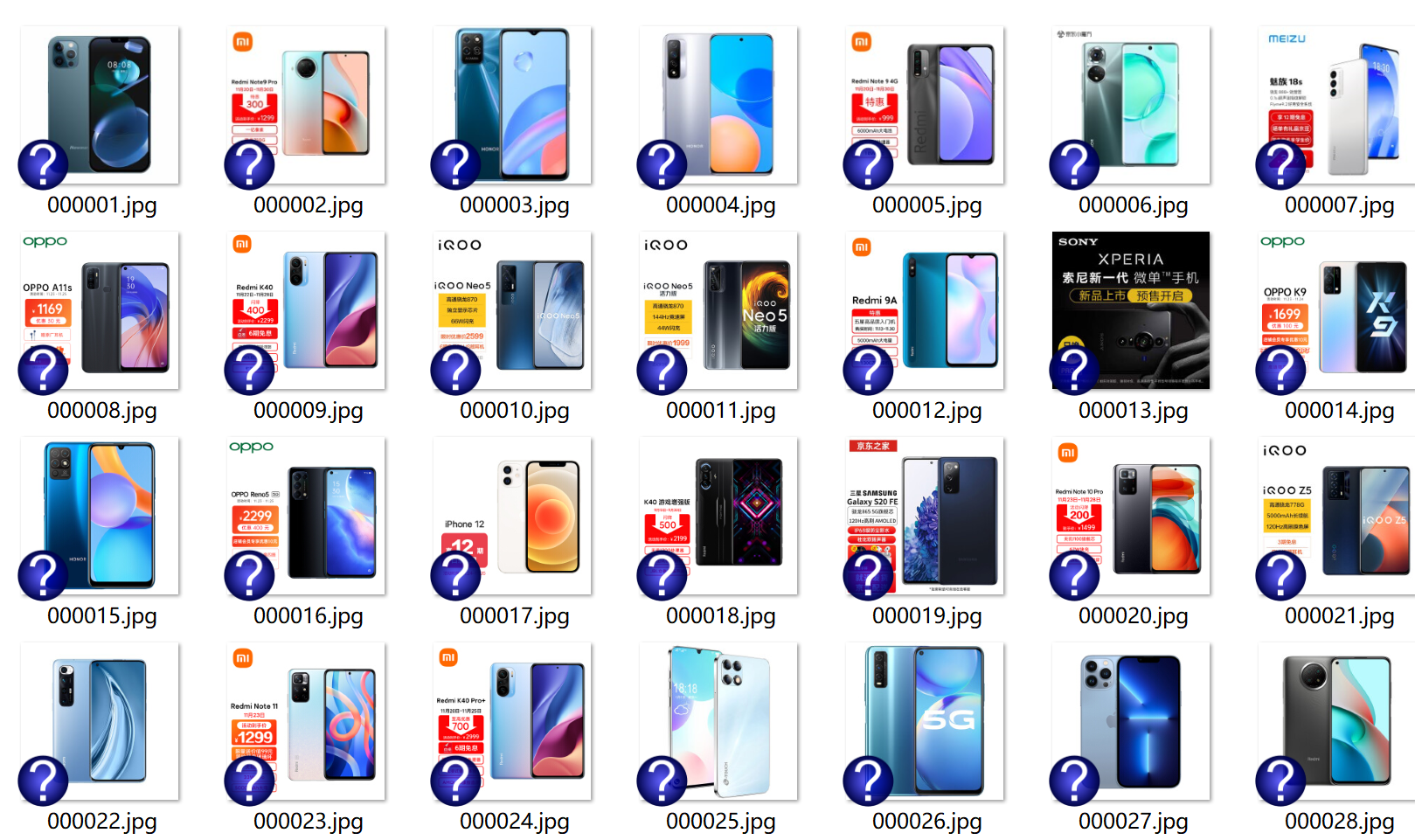
输出信息:MYSQL的输出信息如下
mNo mMark mPrice mNote mFile 000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra 5G... 000001.jpg 000002......
思路:
基础架构:
由于selenium是单页解析,因此可以将selenium的解析以页为单位进行,下面是我实现爬取京东商城的流程。
整个信息获取通过get_board()函数实现,并在其中添加了翻页与页数限制功能。
def get_board(limit=1): """ 获取当前板块信息 :param limit: 限制爬取数量 :return: """ for i in range(limit): print(f"正在爬取第{i + 1}页") parse() if i != limit - 1: # 右键切换 driver.find_element(By.XPATH, "/html/body").send_keys(Keys.ARROW_RIGHT) if __name__ == '__main__': board = "手机" url = 'https://search.jd.com/Search?keyword=' + board driver.get(url) limit_page = 2 # 手机 get_board(limit_page) driver.close()
然后这里比较有趣的是,在处理翻页操作时,发现了京东标签下有这样一行话:“使用方向键右键也可翻到下一页哦!”。
那咱们也就不客气了,连获取Xpath的步骤都剩了,直接使用方向键右键进行换页。

页面解析
数据解析方面,由于需要等待商品图片加载,因此需要用一些手段先使其加载。
这里使用的是循环方向下键的方式(视觉效果比较好,下拉比较丝滑),来等待图片加载完成。
for i in range(300): driver.find_element(By.XPATH, "/html/body").send_keys(Keys.ARROW_DOWN) if not i % 20: time.sleep(1)
解析语句使用Xpath进行,由于重复性较高,就借用了PPT中的代码:
phones = driver.find_elements(By.XPATH, "//*[@id='J_goodsList']/ul/li") print(len(phones)) for phone in phones: try: mPrice = phone.find_element_by_xpath(".//div[@class='p-price']//i").text except: mPrice = "0" try: mNote = phone.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text mMark = mNote.split(" ")[0] mNote = mNote.replace(",", "") except: mNote = "" mMark = "" try: src1 = phone.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src") except: src1 = "" try: src2 = phone.find_element_by_xpath(".//div[@class='p- img']//a//img").get_attribute("data-lazy-img") except: src2 = "" global mNo mNo = mNo + 1 no = str(mNo) while len(no) < 6: no = "0" + no if src1: src1 = urllib.request.urljoin(driver.current_url, src1) p = src1.rfind(".") mFile = no + src1[p:] elif src2: src2 = urllib.request.urljoin(driver.current_url, src2) p = src2.rfind(".") mFile = no + src2[p:] if src1 or src2: T = threading.Thread(target=download, args=(src1, src2, mFile)) T.setDaemon(False) T.start() threads.append(T) else: mFile = ""
数据库
数据库方面基本都是代码复用,没什么好说的了:
连接数据库+建表:
db = DB(db_config['host'], db_config['port'], db_config['user'], db_config['passwd']) db.driver.execute('use spider') db.driver.execute('drop table if exists phones') sql_create_table = """ CREATE TABLE `phones` ( `mNo` varchar(11) NOT NULL, `mMark` varchar(64)DEFAULT NULL, `mPrice` float DEFAULT NULL, `mNote` varchar(64) DEFAULT NULL, `mFile` varchar(64) DEFAULT NULL, PRIMARY KEY (`mNo`) )ENGINE=InnoDB DEFAULT CHARSET=utf8; """ db.driver.execute(sql_create_table)
插入:
sql_insert = f'''insert into phones(mNo, mMark, mPrice, mNote, mFile) values ("{no}", "{mMark}", "{mPrice}", "{mNote}", "{mFile}" ) ''' db.driver.execute(sql_insert) db.connection.commit()
结果截图

作业②:
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
- 候选网站:中国mooc网:
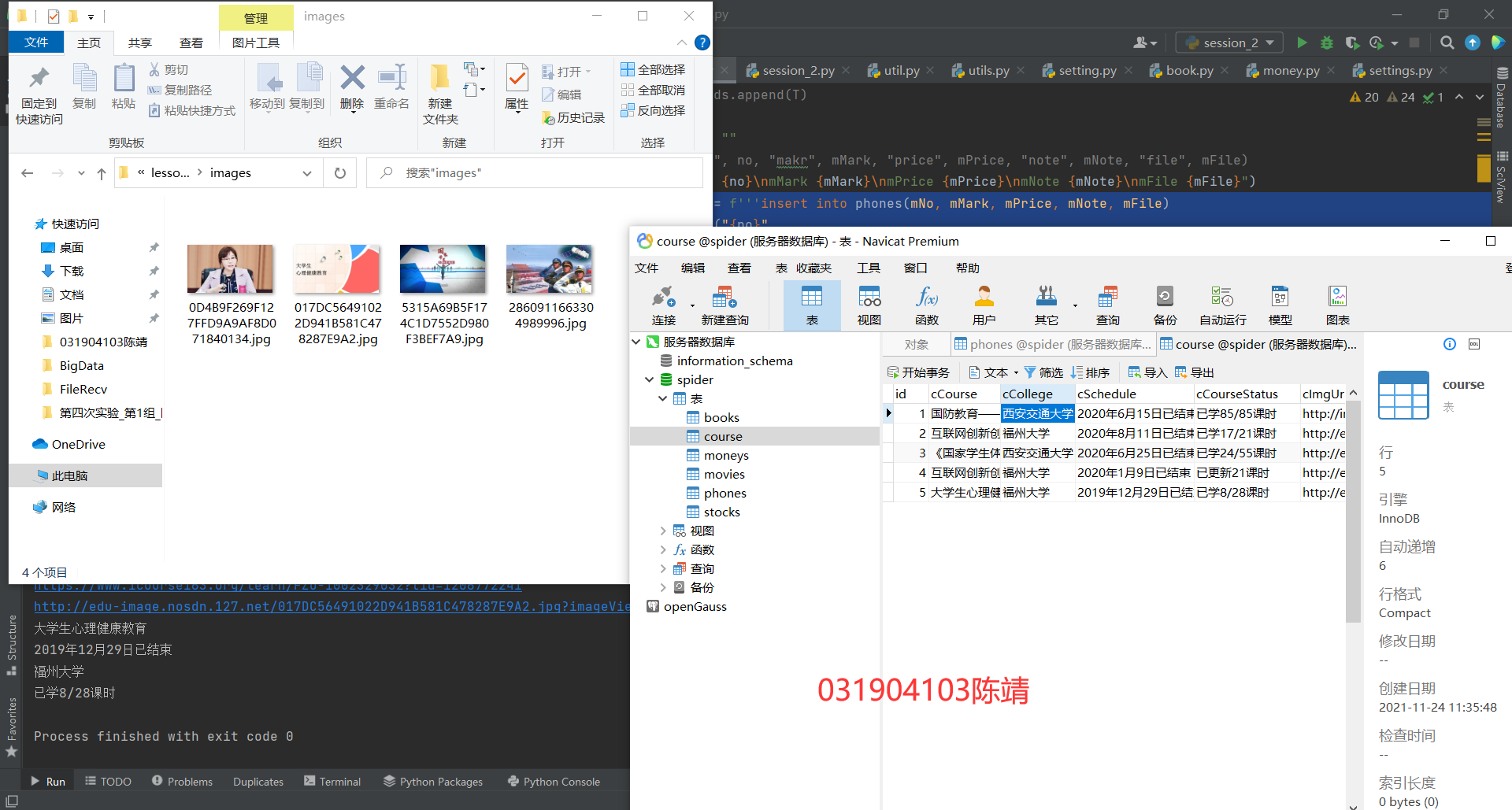
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python网络爬虫与信息提取 | 北京理工大学 | 已学3/18课时 | 2021年5月18日已结束 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
思路:
实现登录
本题的难点在于实现登录,在之前的淘宝爬虫中,是使用了等待扫码登录的方式,因为其安全等级较高,使用账密登录还是有一堆奇奇怪怪的操作。
本题中,如果不是登录过多,使用账密登录是完全没有限制的,因此在本题中,采用了账密登录的方式。
首先,需要采集账号、密码,这里采用input的方式采集(测试的时候可以直接写好,运行起来快),由操作人员手动输入:
# username = "mirrorlied@***.com" # password = "*************" username = input("请输入用户名") password = input("请输入密码")
接着,需要点击登录按钮,下图展示的两个按钮点击效果是一样的。

我这里选择的是较大的绿色按钮:
driver.find_element(By.CLASS_NAME, "_3uWA6").click()
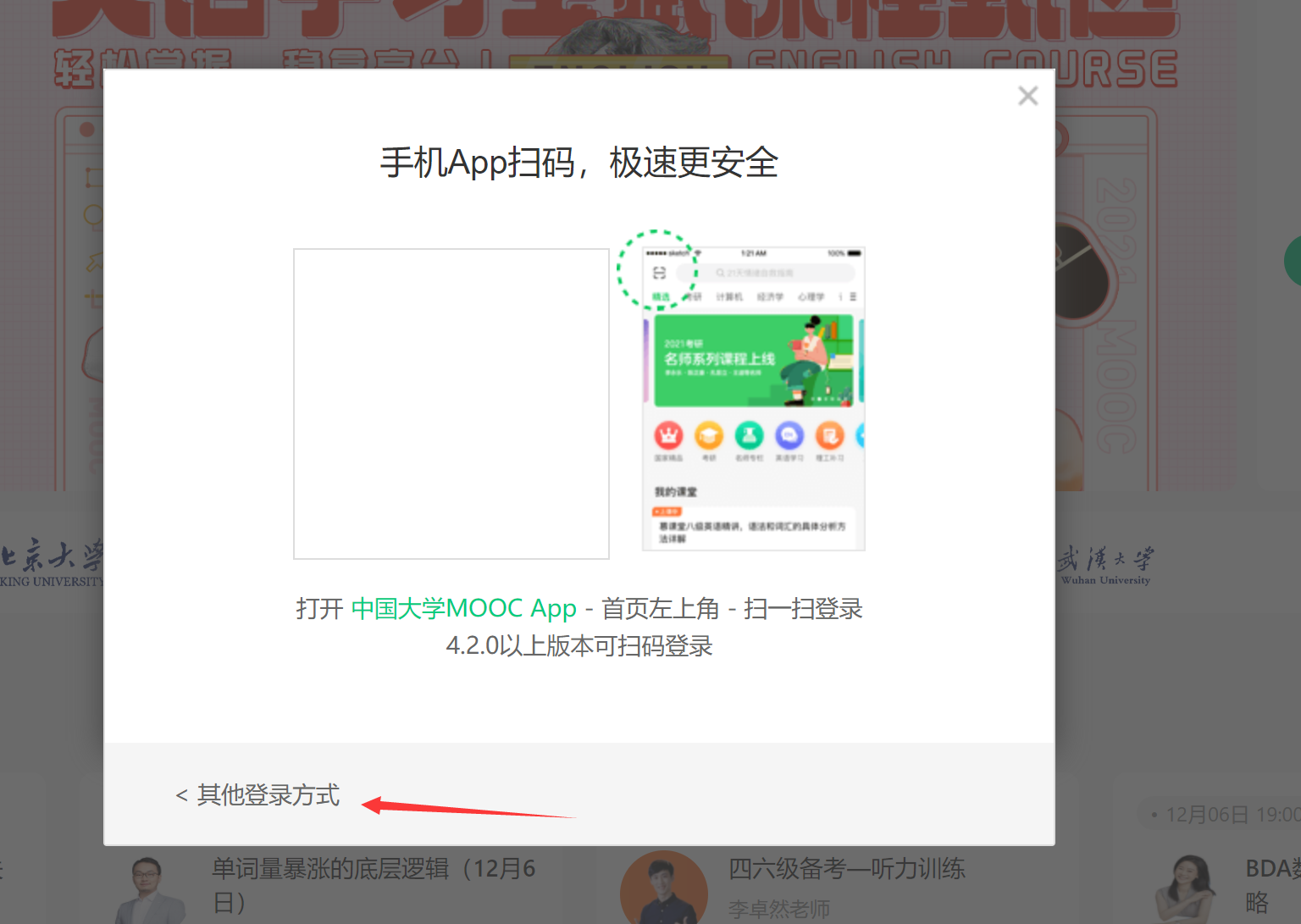
点击后跳出扫码登录框,但是我们是账密登录,需要点击其他登录方式:
driver.find_element(By.CLASS_NAME, "ux-login-set-scan-code_ft_back").click()
点进去,需要等待一会,输入框才会加载出来:

使用等待,直到输入框出现:
input_text = (By.XPATH, "//*[@data-loginname='loginEmail']") iframe = driver.find_element(By.XPATH, "/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[1]/iframe") driver.switch_to.frame(iframe) WebDriverWait(driver, 200, 0.5).until(EC.presence_of_element_located(input_text))
输入账密并键入回车进行登录:
driver.find_element(By.XPATH, "//*[@data-loginname='loginEmail']").send_keys(username) driver.find_element(By.XPATH, "//*[@name='password']").send_keys(password) driver.find_element(By.XPATH, "//*[@name='password']").send_keys(Keys.ENTER)
如果登录多次,这里会出现一个滑动验证,需要sleep进行手动处理。
登录进来后,需要点击我的课程,但是右下角会弹出一个固定大小隐私协议确认框。
凑巧的是,在浏览器分辨率较小的情况下,这个框会把“我的课程”挡住。
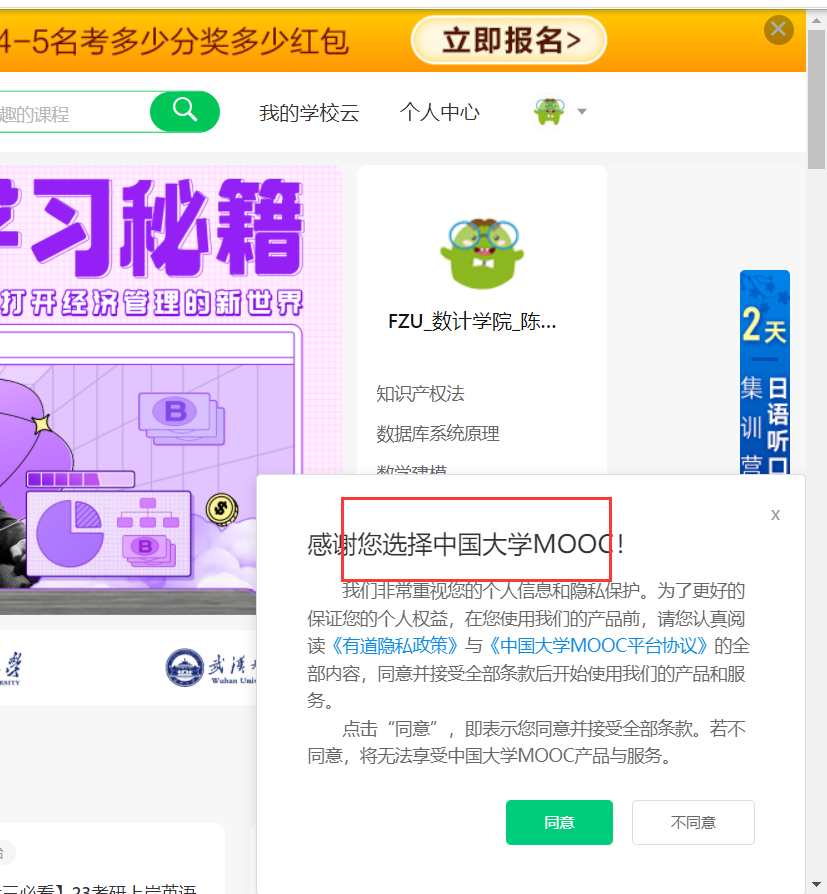
大分辨率下对比↓
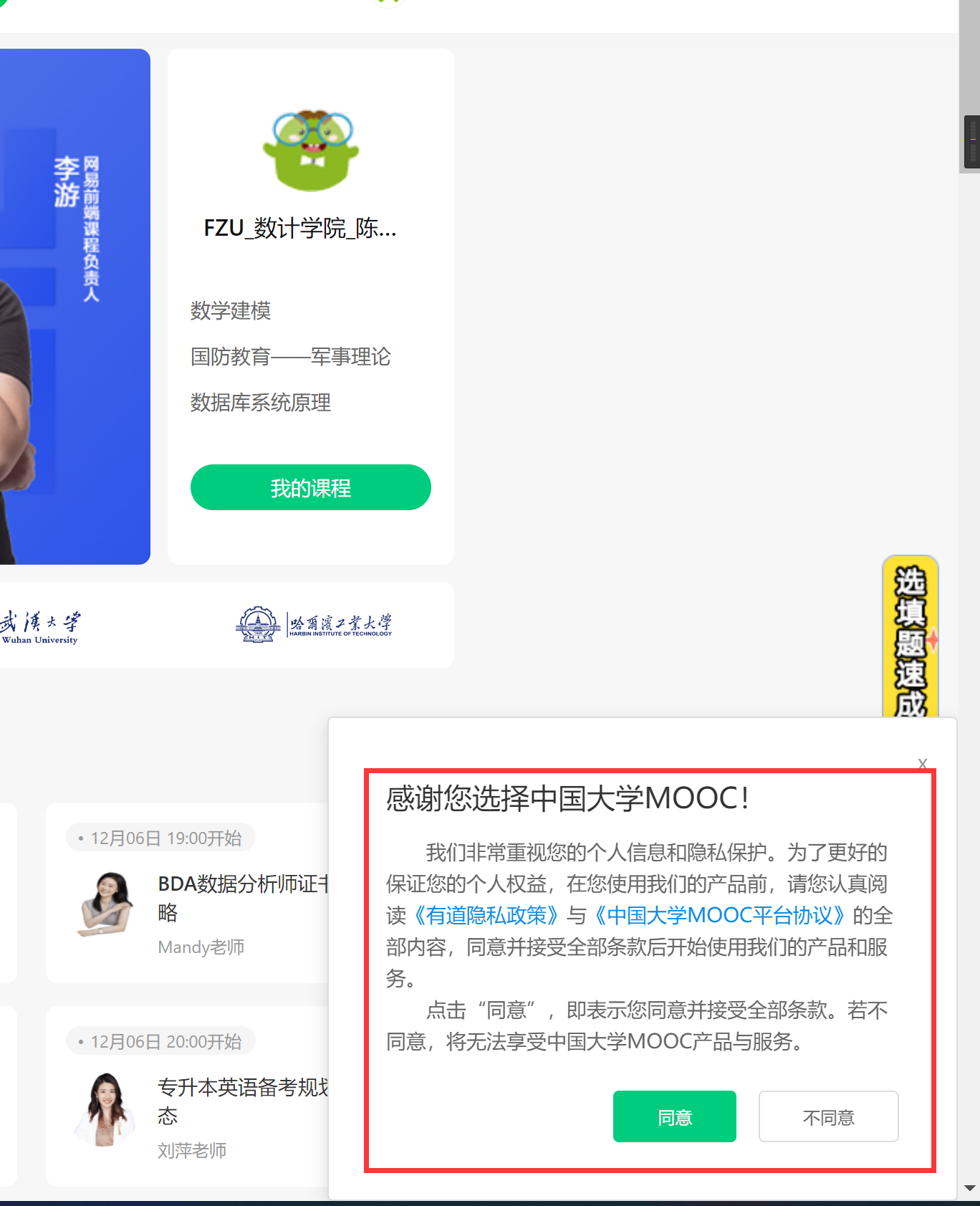
为保证爬虫正确运行,需要先点击确定把这个框关掉,然后再点击“我的课程”:
driver.find_element(By.XPATH, "/html/body/div[4]/div[3]/div[3]/button[1]").click() driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[4]/div").click()
进入后,目标信息就都读取出来了,一路平推解析即可:
courses = driver.find_elements(By.CLASS_NAME, "course-card-wrapper") print(len(courses)) for course in courses: a = course.find_element(By.XPATH, ".//div/a") href = a.get_attribute("href") img = a.find_element(By.XPATH, ".//img").get_attribute("src") name = a.find_element(By.XPATH, ".//div[@class='title']//span[@class='text']").text status = a.find_element(By.XPATH, ".//div[@class='course-status']").text school = a.find_element(By.XPATH, ".//div[@class='school']").text t = a.find_element(By.XPATH, ".//*[@class='course-progress-text-span']").text download(img)
(mooc的平台是真的不稳定,写博客的时候又崩了)
数据库
sql_insert = f'''insert into course(cCourse, cCollege, cSchedule, cCourseStatus, cImgUrl) values ("{name}", "{school}", "{status}", "{t}", "{img}" ) ''' db.driver.execute(sql_insert) db.connection.commit()
结果展示
作业③:Flume日志采集实验
- 要求:掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建
- 任务一:开通MapReduce服务
- 实时分析开发实战:
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
- 任务三:安装Flume客户端
- 任务四:配置Flume采集数据
一、按照教程进行环境搭建

二、Python脚本生成测试数据
使用scp进行脚本文件传输(对单文件来说,比ftp好用):

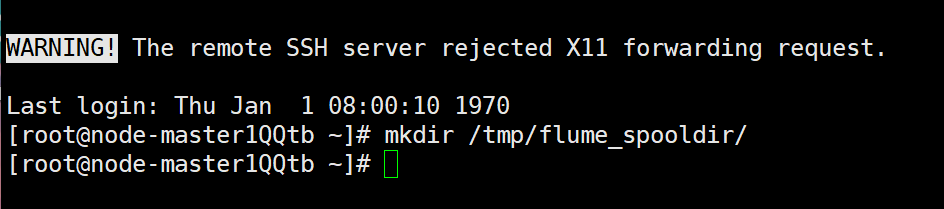
创建输出目录:
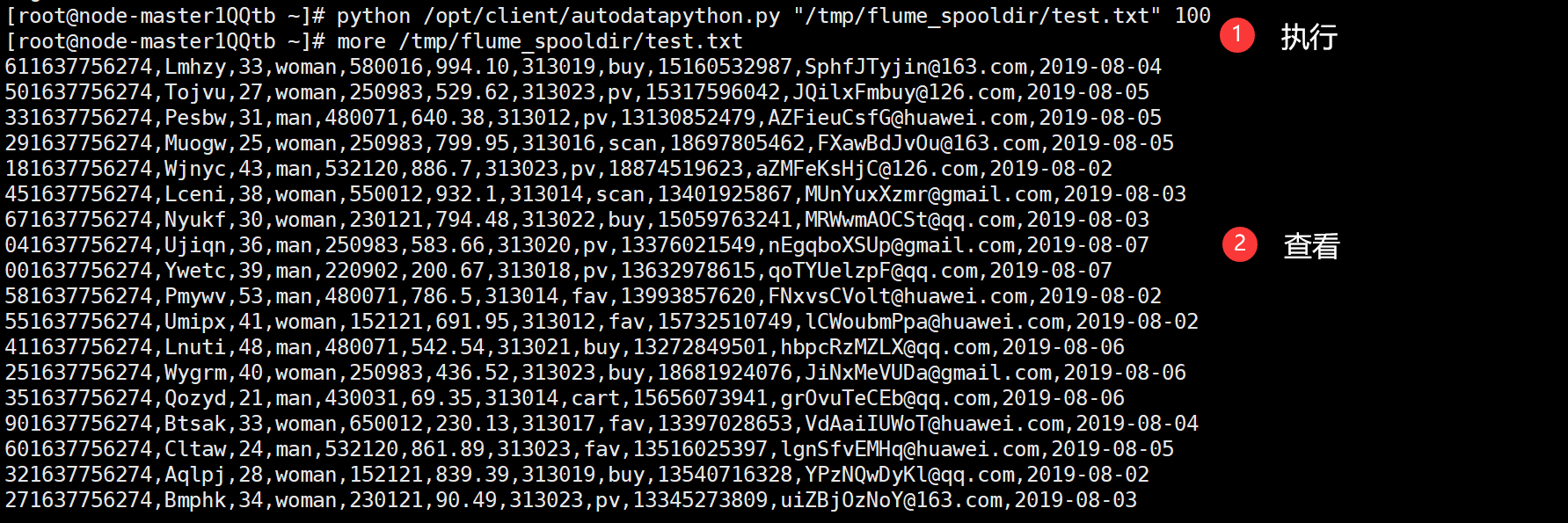
运行以及结果输出:
三、配置Kafka
按照教程案例实现,替换ip地址并执行脚本文件即可:

四、安装Flume客户端
1. 安装客户端运行环境
首先需要替换Zookeeper的IP,解压MRS_Flume_ClientConfig.tar压缩包,并执行安装脚本:
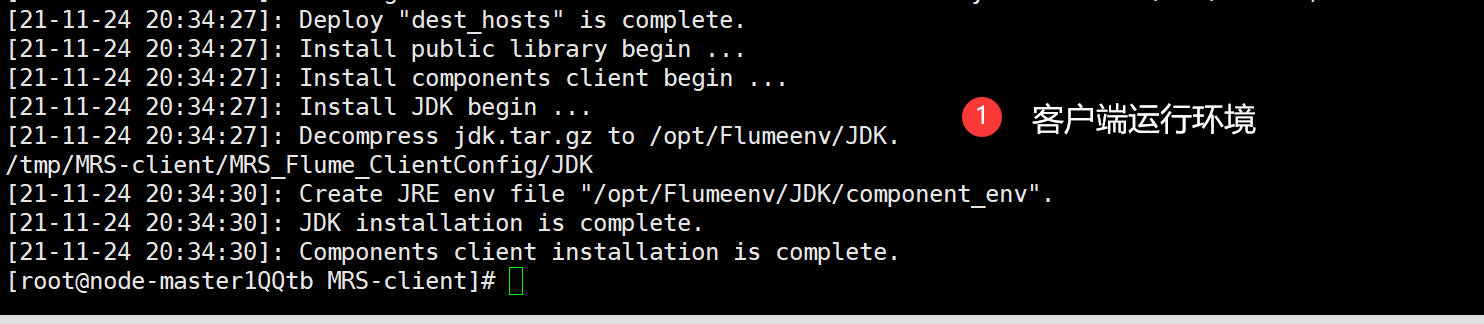
看到终端输出Components client installation is complete.
说明客户端运行环境安装成功。
2. 安装Flume客户端
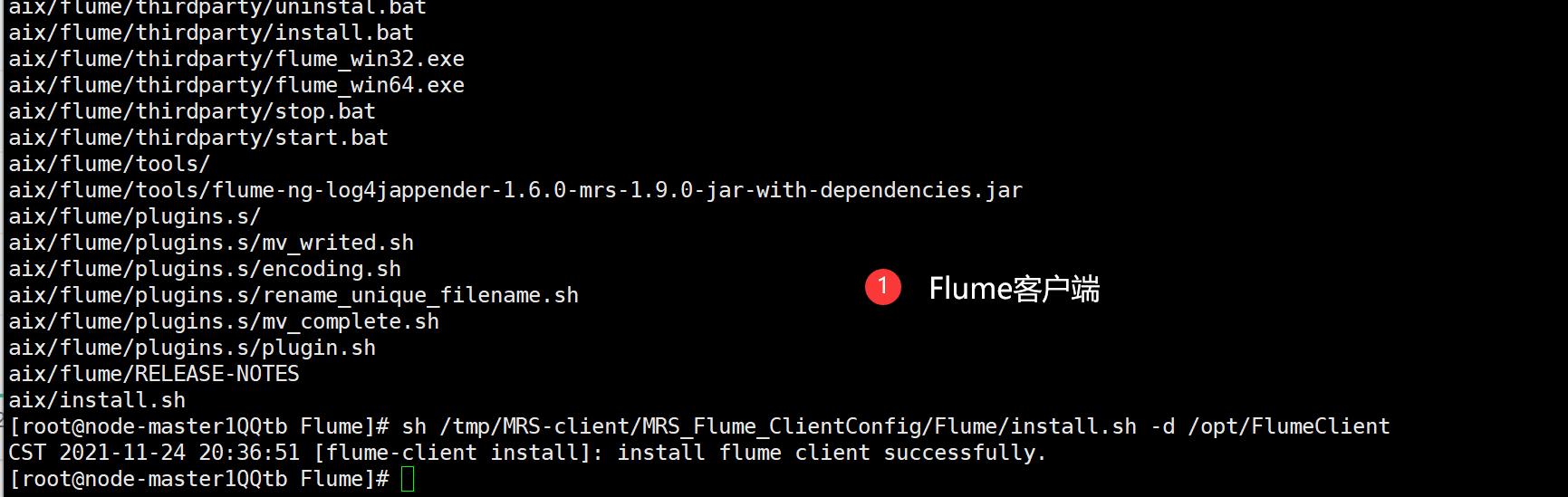
直接使用安装脚本install.sh实现安装,然后看到终端输出 install flume client successfully.
说明Flume客户端安装完成。
3. 重启服务
在安装完成后,需要进行重启服务,实现应用的配置操作:
sh bin/flume-manage.sh restart

五、配置Flume采集数据
配置Flume,我们采用本地修改完,然后丢到服务器上的方式进行实现:
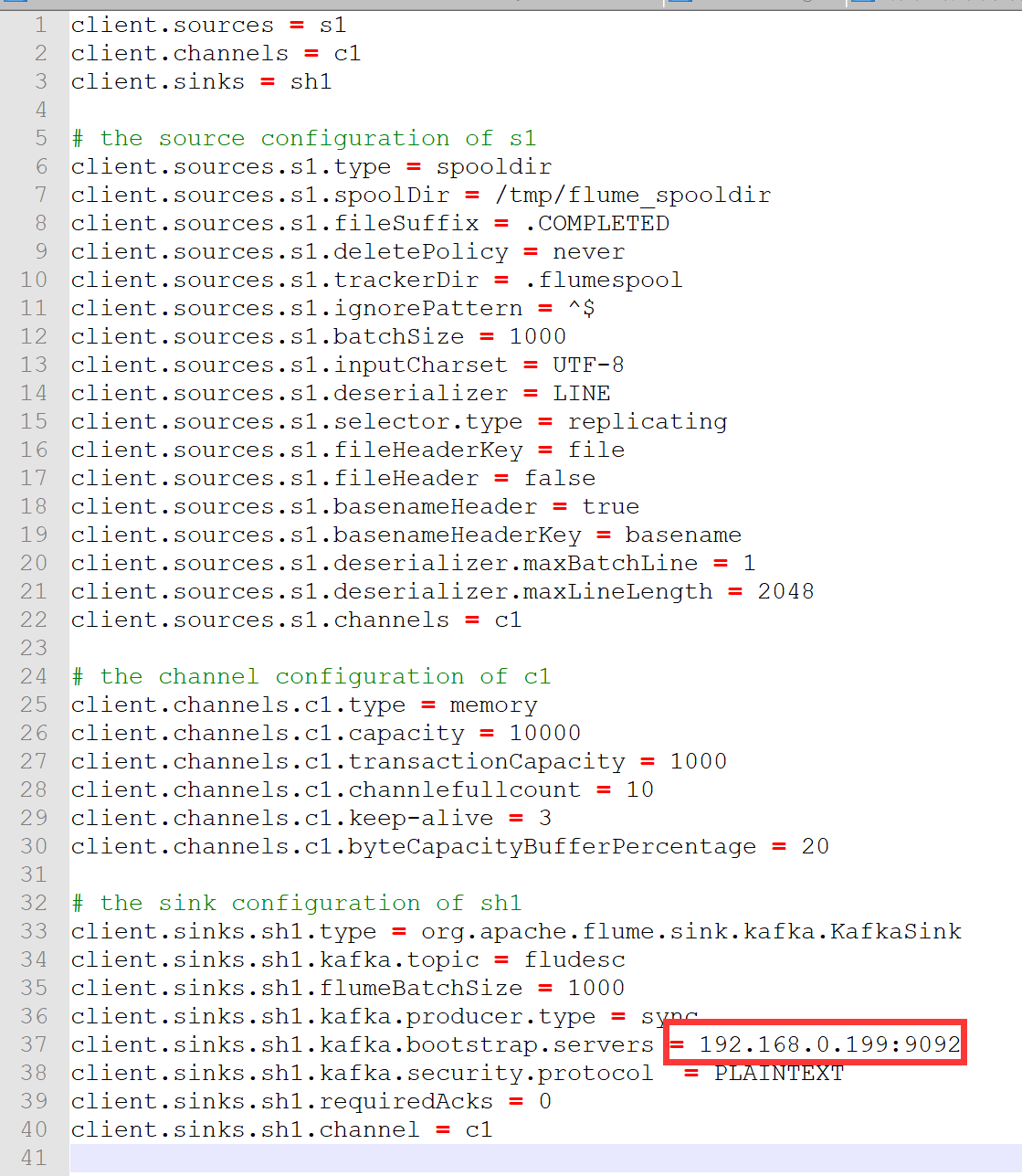
将Kafka的socket改为华为云服务器为我们分配的内网Ip地址。
然后继续通过scp的方式进行传输(在windows系统下也是默认自带的,而且使用方法一致)。
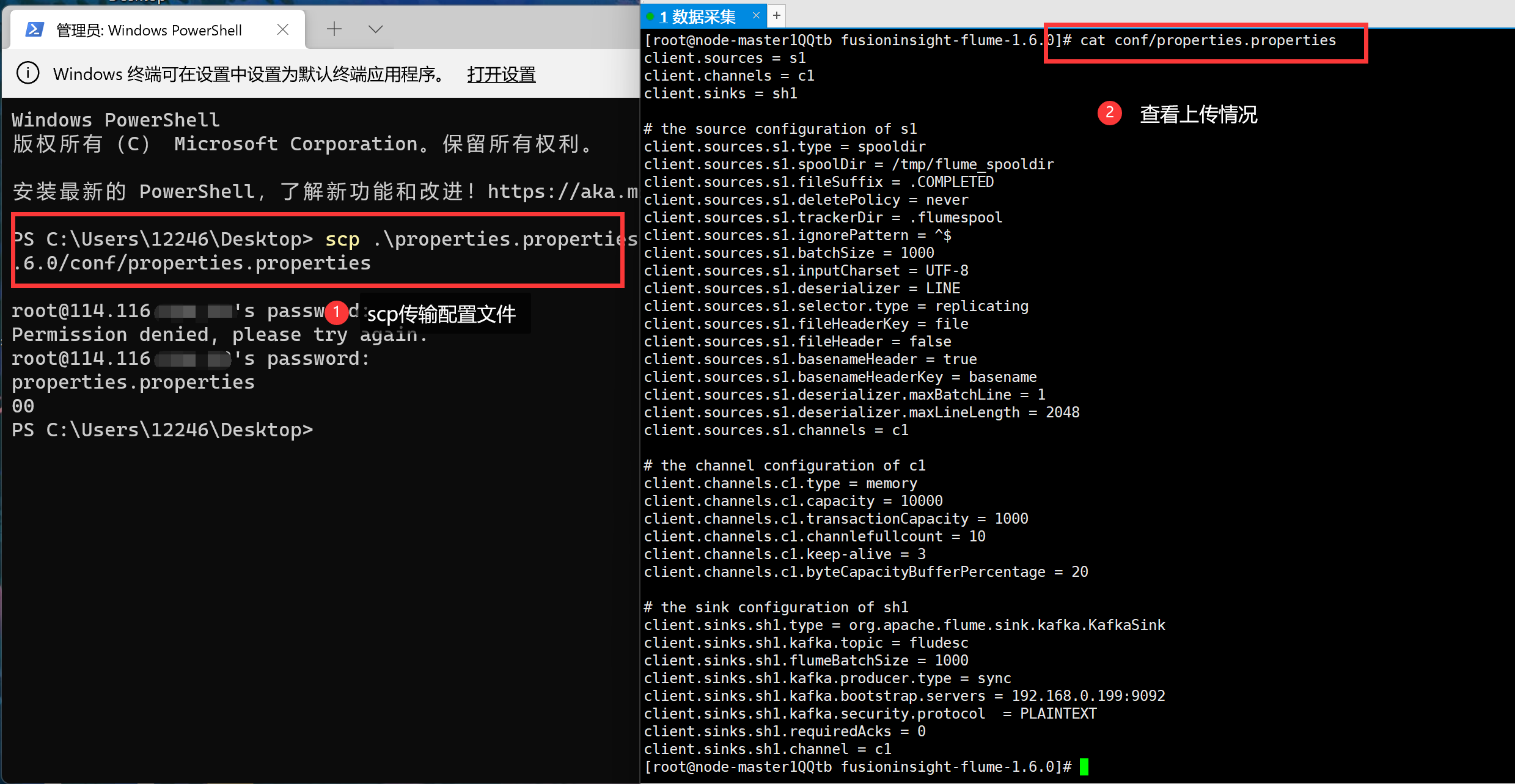
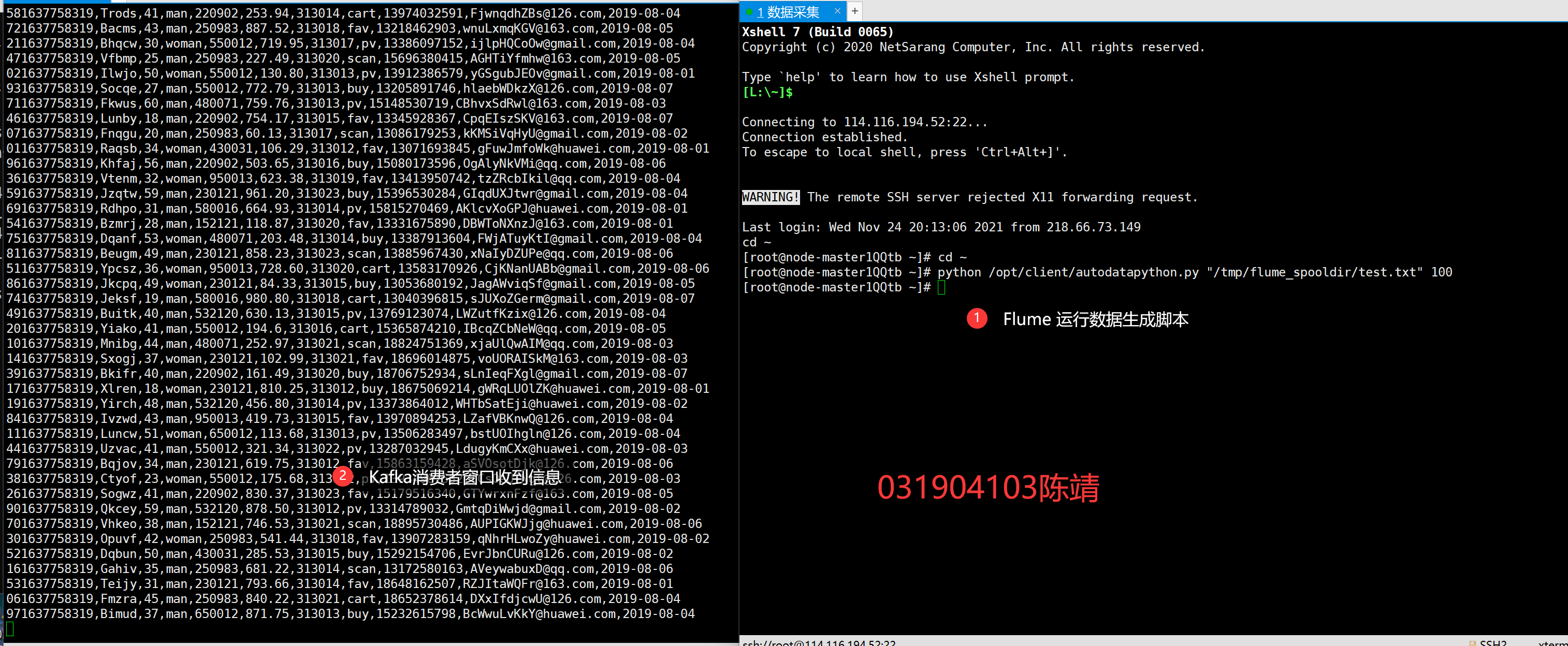
使用source应用配置后,新建一个ssh连接,再次运行python脚本可以看到在Kafaka消费者窗口中接收到了信息:
代码地址
https://gitee.com/mirrolied/spider_test
心得
1. 完整实现了一次登录流程,对selenium定位更加熟练;
2. 对Flume实时流前端数据采集有了初步的认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号