[数据采集与融合技术]第四次大作业
作业
作业①
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://search.dangdang.com/?key=python&act=input
关键词:学生可自由选择
输出信息:MySQL的输出信息如下

思路:
在页面请求上,本题较为简单,我们需要通过输入两个参数,确定我们爬取的内容和范围:
| 参数名 | 含义 |
| key | 查询关键字 |
| page_index | 页码数量 |
例如,下图的url就表示关键字为python的搜索页面的第二页:
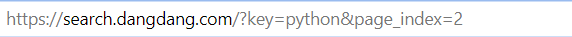
页面解析上,从通过抓包获得请求中,我们可以发现该网站使用静态渲染(虽然预览中乱码,但信息都在,交给解析层转码解析即可):
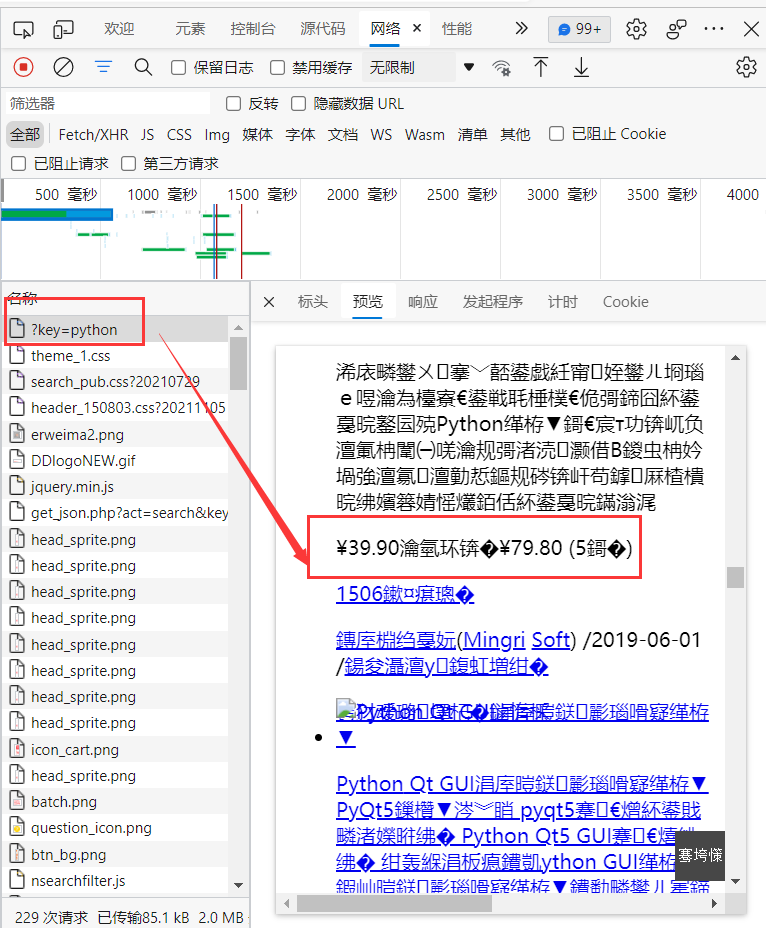
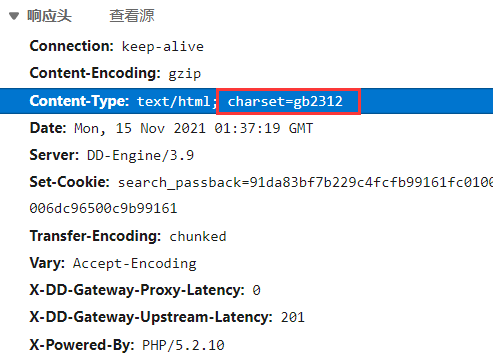
和之前不同,从响应头中可以发现该网站使用gbk编码返回,因此,在请求时,需要转换编码,否则就会得到像上面预览中一样乱码。
解析方面,可以发现图书信息是使用ul -> li的形式进行展示的。
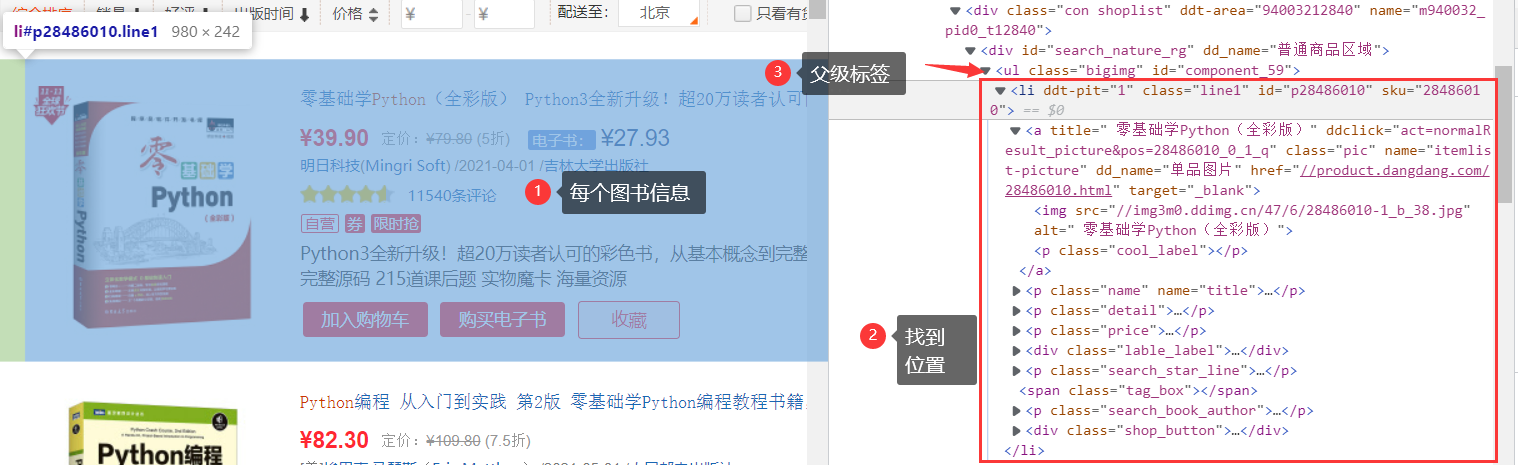
在解析时,可以先定位ul节点,然后通过遍历子节点的方式,获取所有图书信息所在的li节点,最后继续进行子查询,获得所有信息:
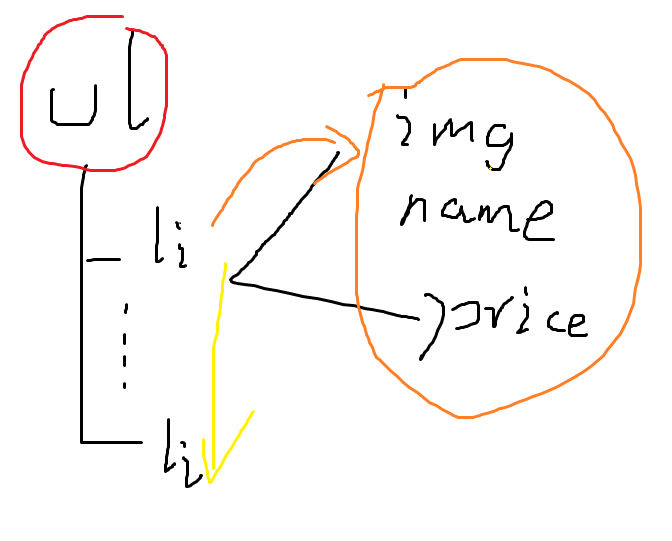
此外,有些书的简历是缺失的,不过无伤大雅:
数据库是通过item将参数传递给pipelines进行实现,前面实验已经实现多次了(代码见仓库),因此直接调用前面的代码,最终实现结果如下:
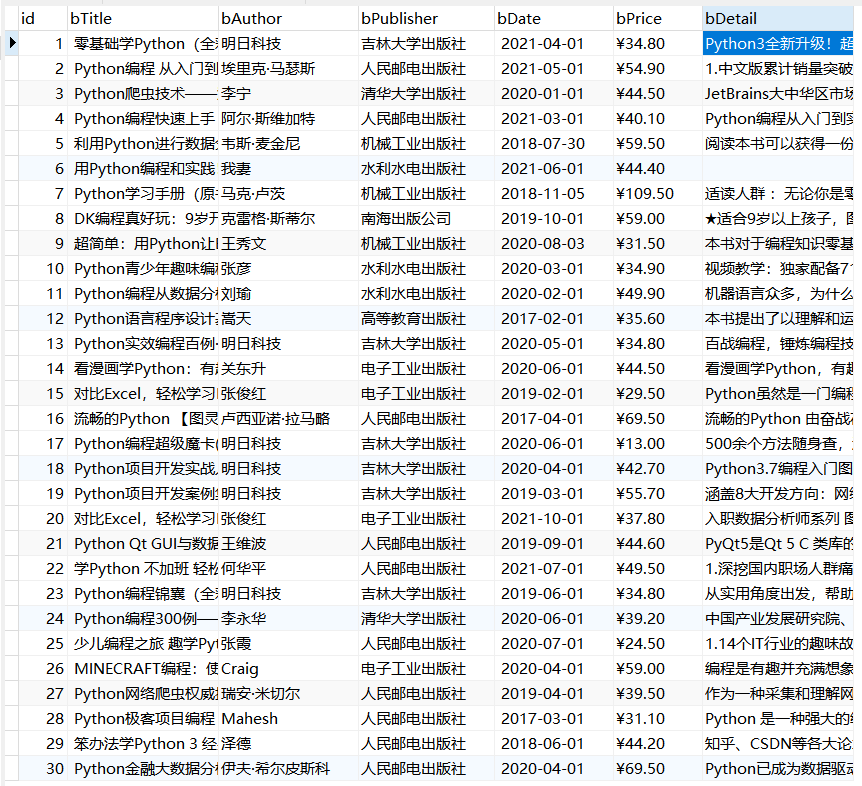
此题的日期和价格和其他字段一样也是使用varchar类型进行存储,未处理成Date和float类型(因为展示起来不好看),后续可以通过date库与字符串分割和float()强转进行类型转换。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
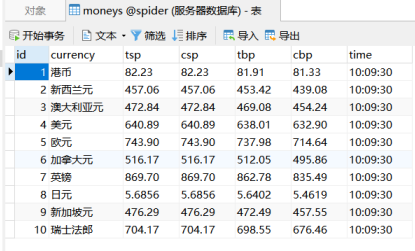
输出信息:MySQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time 1 港币 86.60 86.60 86.26 85.65 15:36:30 2......
思路:
该题的信息均保存在table中:
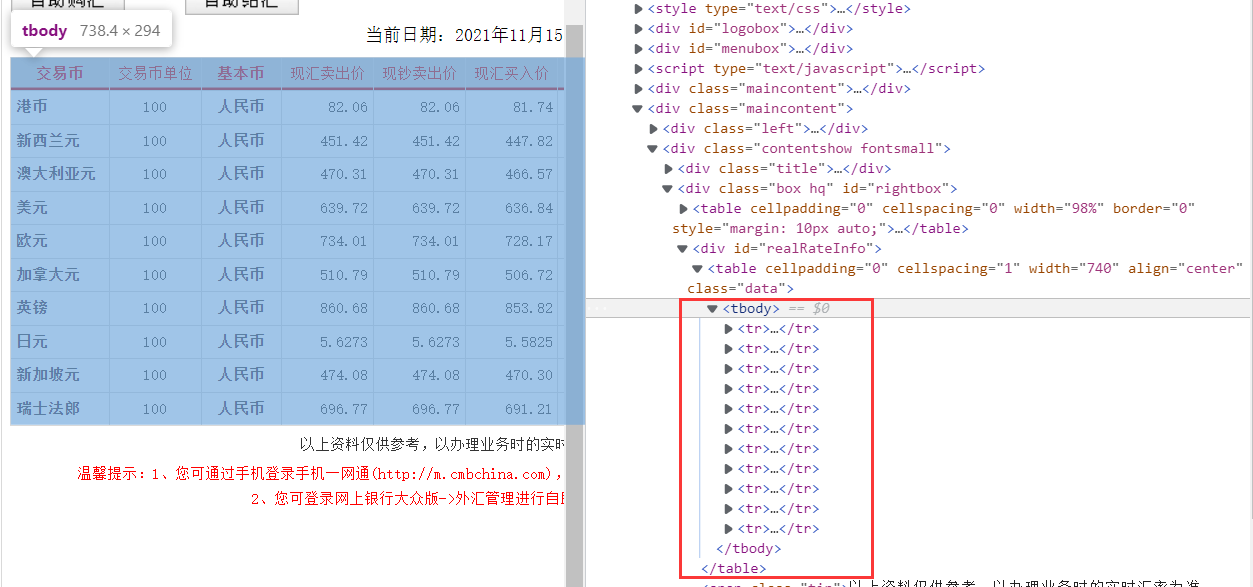
因此,我们只需要实现对此table实现定位,再通过联级关系,向子项tr进行遍历,将tr中td存储的各项信息提取出来。
要注意的是,table内首行为标题字段,在处理时需要先跳过。

一开始,我使用的是先定位table,然后定位tbody,接着对tbody内的tr进行遍历,但是输出为空,未找到任何tr行:
moneys = selector.xpath("//*[@id='realRateInfo']/table/tbody//tr") for money in moneys[1:]: item = Session2Item() ......
打印html,发现在对应位置并未出现tbody:
去掉tbody,直接对table内tr元素进行遍历,成功输出了结果:
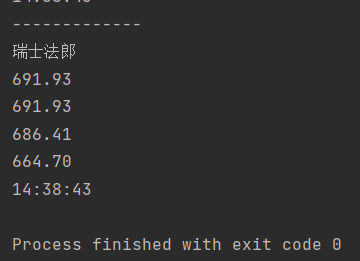
猜测是由于浏览器在处理中,自动添加了tbody,对不规范的html进行了填补。
编写html文件进行验证:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <table> <tr> <th>Month</th> <th>Savings</th> </tr> <tr> <td>January</td> <td>$100</td> </tr> </table> </body> </html>
浏览器中显示如下,发现浏览器确实自己加了一个tbody上去:

运行截图
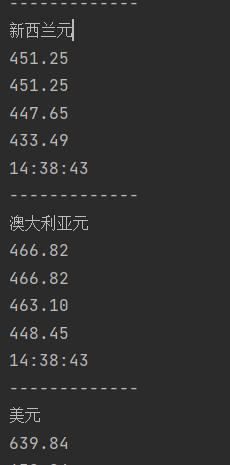
数据库
作业③
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
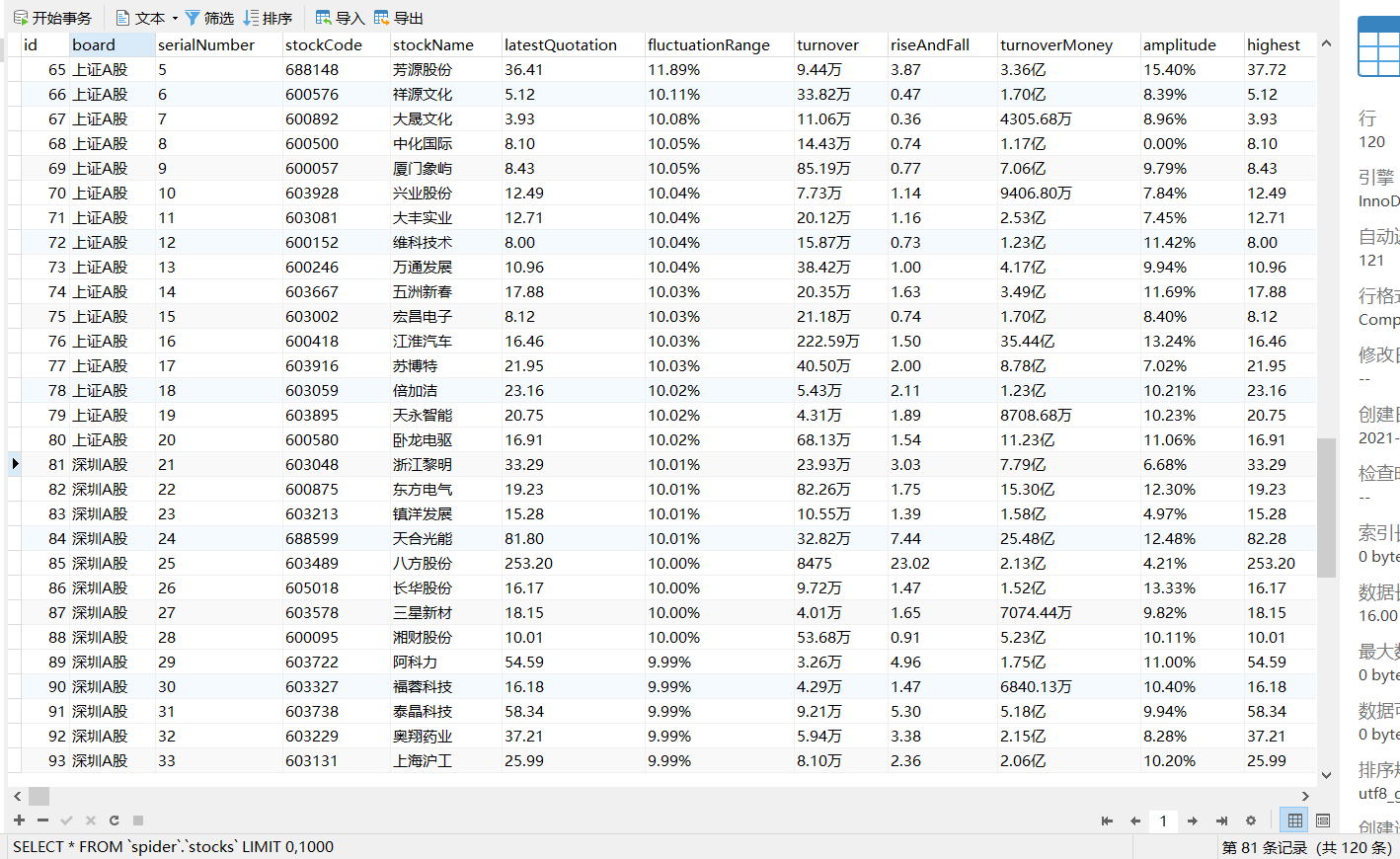
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
思路:
本题在之前使用抓包解析的方式实现过一次,当时的数据采集,包括换页等处理,都是通过解析API接口实现的,过程繁琐麻烦。
本次实验中,使用selenium库进行复现,不用进行抓包解析等操作,代码编写效率直接起飞。
在信息获取上分为单页解析和换页两部分:
单页解析
由于selenium的表格是经过渲染完的,因此可以定位到table的tbody。
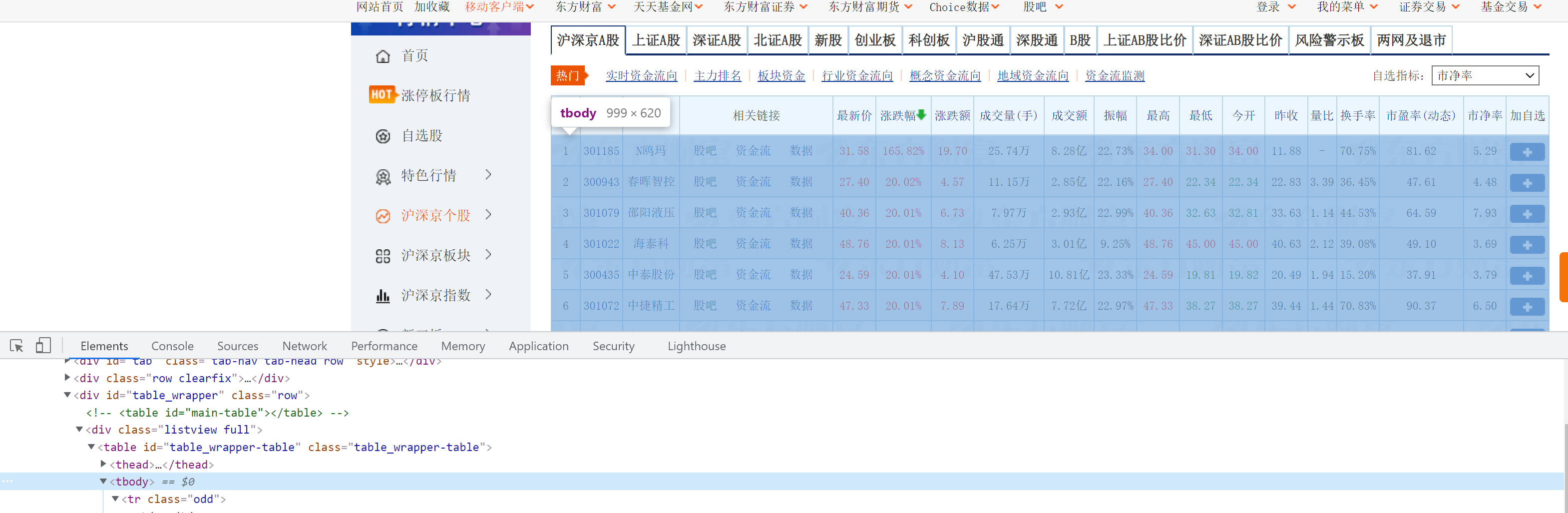
stocks = driver.find_element(By.XPATH, "//*[@id='table_wrapper-table']/tbody")
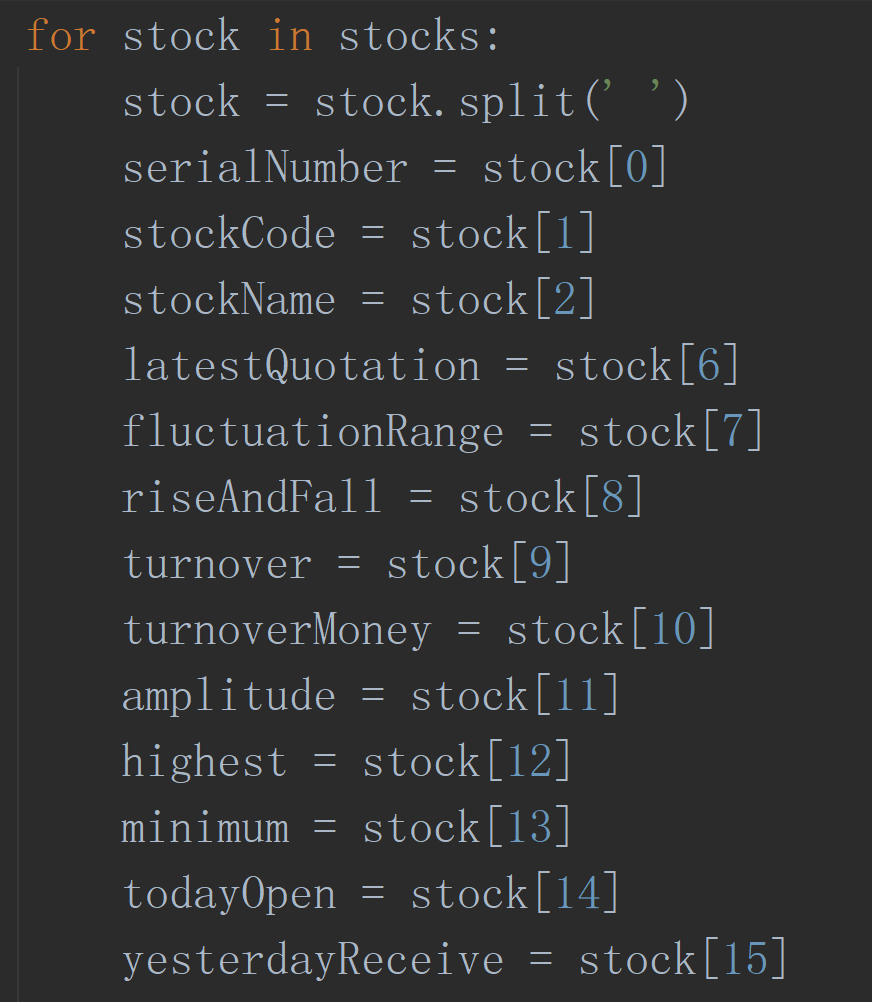
这里采用了特榆大佬发现的解析方法,直接使用类似csv文件读取的方式,采用字符串分割的方式,将表格数据按行分割:
stocks = stocks.text.split('\n')

然后对数据按空格再次分割,就实现所有数据的获取了。
换页
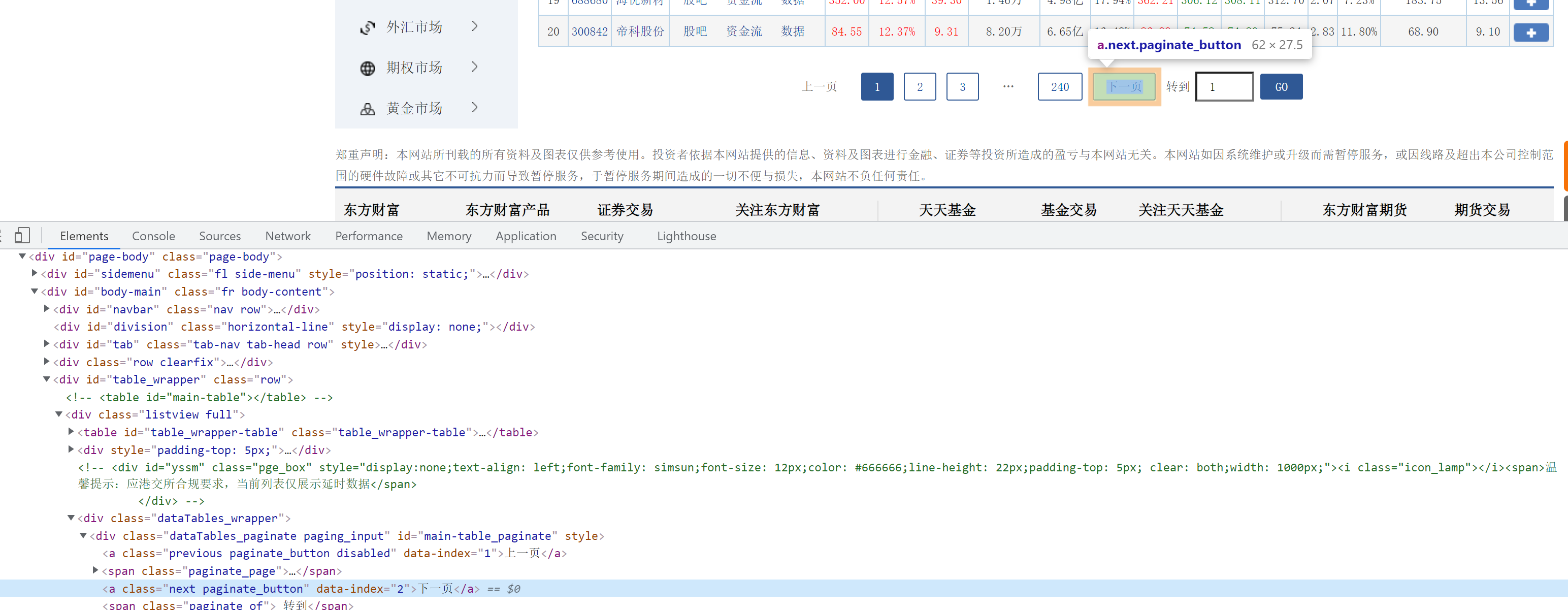
对于当前板块的翻页,可以通过点击下一页按钮实现:
driver.find_element(By.XPATH, "//*[@id='main-table_paginate']/a[2]").click()
对于切换板块,可以使用上面的标签点击实现:
但是,在测试中出现了一个问题,该网页在点击使用的是局部刷新,在切换页面后,我们的坐标会存在页面下方。
由于页面的局部更新,上方的标签丢失,因此我们需要重新对标签进行加载。
使用的方式是通过selenium模拟点击home按键,让页面回到顶部,使标签重新加载:
driver.find_element(By.XPATH, "//*[@id='nav_sh_a_board']/a").send_keys(Keys.HOME) driver.implicitly_wait(10) driver.find_element(By.XPATH, "//*[@id='nav_sh_a_board']/a").click()
为防止加载过快,导致页面未加载出来,中间需要插入一个等待,直到标签出现。
数据库
在数据库处理上,在上次实验的基础上,改了字段名,另外,将一些float类型字段改为varchat类型以兼容字符型数据。

结果截图
爬取三个模块,每个模块爬取两页,每页20条数据,共120条:
代码地址
https://gitee.com/mirrolied/spider_test
心得
1. 前两次实验均为scrapy实验,难度较之前有所下降,但是分别有一处坑点,第一题需要解决编码的问题,第二题需要解决浏览器自动补全的问题。
2. 在第三题中,使用selenium实现股票数据爬取,编码非常丝滑,比解析接口实现快了亿些。但是,在爬取速度上,selenium速度比使用接口爬取慢了很多,在实际中,还是会尽量选择其他方式实现。另外,使用selenium的数据是经过渲染的,在一些情景中,还需要重新解析(比如上面的%、万、亿等)。
3. selenium在许多情况下也是不太可行的,在实习期间了解到当前有些网站会对selenium控制的浏览器进行识别判断,导致selenium直接失效。目前针对这类“难”爬的网页,使用js注入的方式可能会更稳定些。
4. selenium在一般情况是,可以实现“可见即可爬”,如果实现小规模爬虫,还是很方便的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号