[数据采集与融合技术]第一次大作业
作业①:
- 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
- 输出信息:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
1) 、作业一实验
1、解题思路
①获取html
使用urllib.request进行Get请求:
url = "https://www.shanghairanking.cn/rankings/bcsr/2020/0812" # 获取html html = urllib.request.urlopen(url).read().decode("utf-8") # 使用缓存,防止被ban # with open('./.cache/rankings.html', 'r', encoding='utf-8') as f: # html = f.read() html = html.replace("\r", "").replace("\n", "")
为了防止被ban,并且减轻对方服务器的负担,在爬取一次后,保存html作为缓存,下次直接使用缓存文件进行解析。
②使用正则表达式提取所有的行(图中红色标注部分)

# 获取tr列表(需除去第一行标题)
trList = re.findall(r'<tr data-v-68e330ae>(.*?)</tr>', html)[1:]
③使用正则表达式提取行内标签内容
找到需要提取的数据,编写正则匹配规则,针对每一行进行匹配
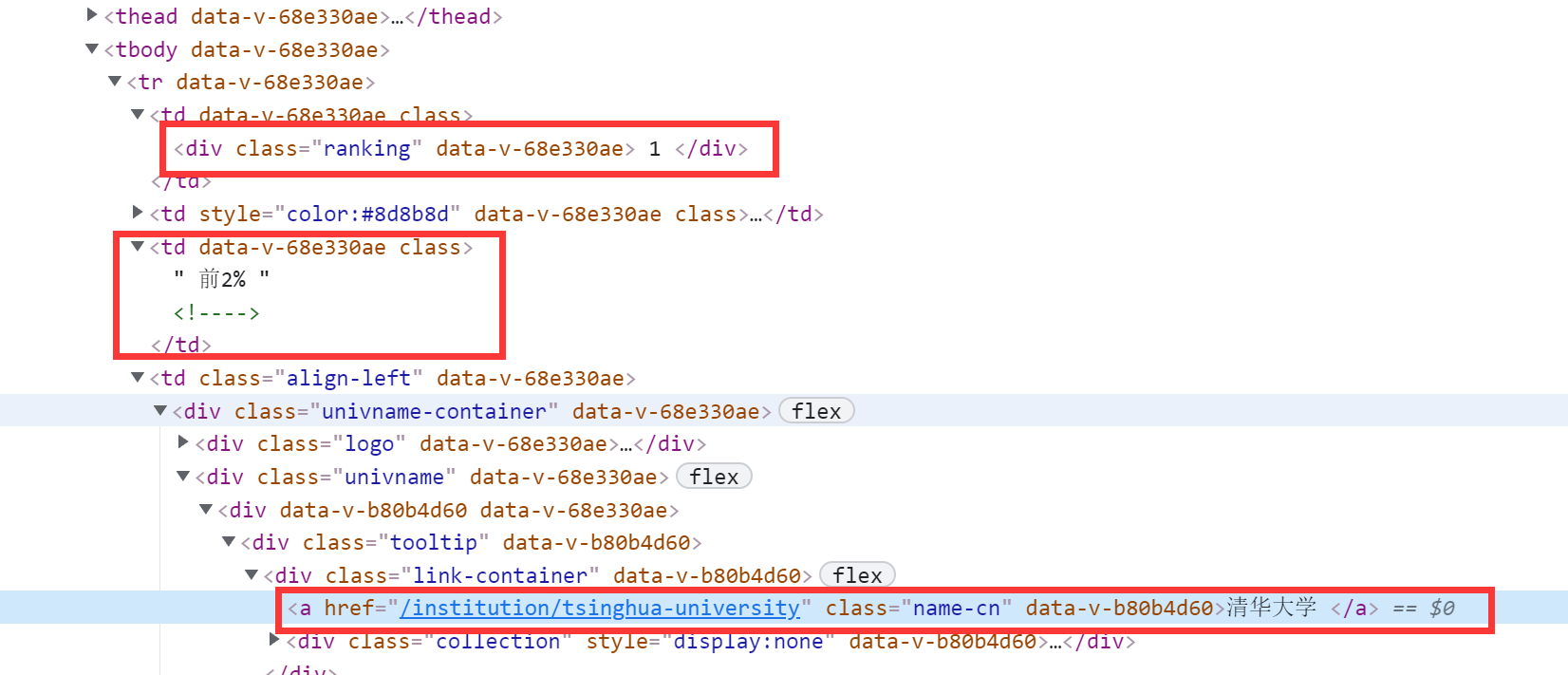
各数据匹配如下表:
| 名称 | re | 注释 |
| 2020排名 |
`<div class="ranking" data-v-68e330ae>.*?(\d*)</div>` |
匹配排名所在标签 |
| 全部层次 |
`(前\d*%)` |
由于特征比较明确,直接匹配文本 |
| 学校类型 |
`class="name-cn" data-v-b80b4d60.*?>(.*?) </a>` |
同样匹配学校类型所在标签 |
| 总分 |
`(\d*?\.0)` |
特征明确,匹配浮点数 |
2、运行结果
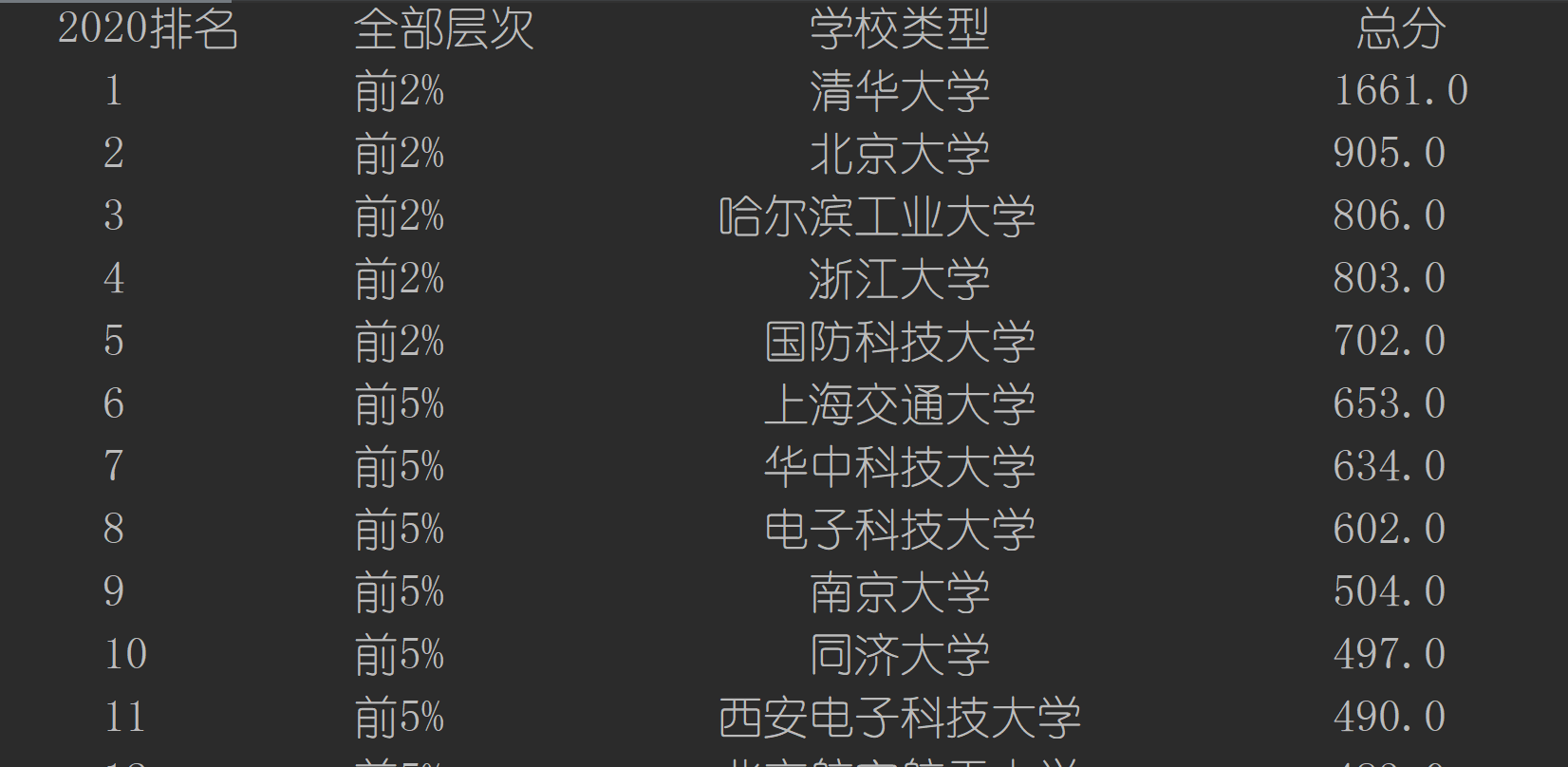
3、文件地址
https://gitee.com/mirrolied/spider_test/blob/master/lesson_1/session_1.py
2) 、心得体会
该作业是对之前bs4库解析作业,使用正则表达式的一次复现,出现了以下的问题:
- 正则表达式需要设置跨行提取或将\n \t \r 等不可见字符删除,否则出现内容跨行,将匹配失败,这里我选择了使用后者进行解决(第三题用了前者);
- 另外,就是输出对齐的问题,我使用的方法是插入chr(12288)并借助制表符\t实现对齐。
作业②:
-
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
-
输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
1) 、作业二实验
1、解题思路
①获取html
使用requests进行Get请求:
url = "https://datacenter.mee.gov.cn/aqiweb2/" response = requests.get(url) html = response.text # 使用缓存,防止被ban # with open('./.cache/aqiweb2.html', 'r', encoding='utf-8') as f: # html = f.read()
同上,添加一个缓存。
②构建soup对象,并解析表格
这里需要先解析下图中选中部分的表格:
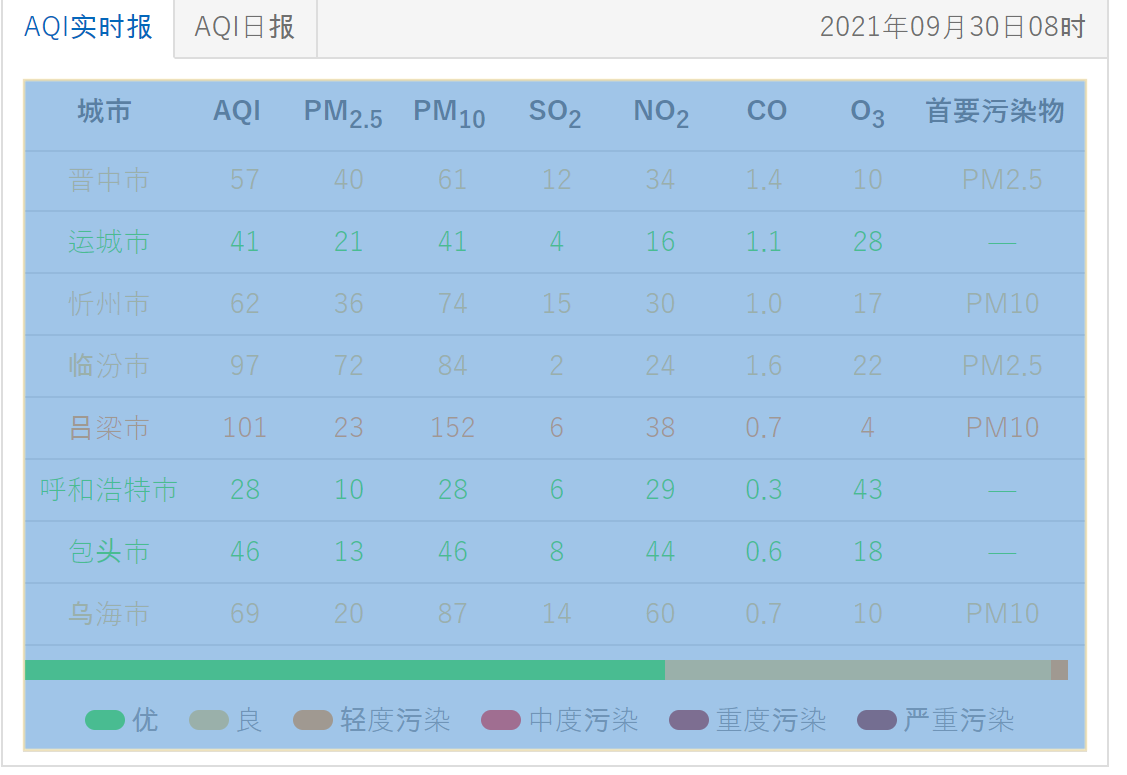
使用Beatiful Soup进行解析:
# 构建soup对象 soup = BeautifulSoup(html, "lxml") # 解析表格 table = soup.find('div', attrs={"id": "demo"}).table.tbody
③提取数据
查看该表格,发现该tbody内,tr均匀排列,且各个tr内的td内容即为需要的数据(即td.text):

因此,只需要进行两层遍历,就能提取出所有信息:
i = 0 for tr in table.find_all('tr'): print("{:^6}".format(i), end='\t') for td in tr.find_all('td'): print("{:^6}".format(strQ2B(clear_data(td.text))), end='\t') print() i += 1
2、运行结果
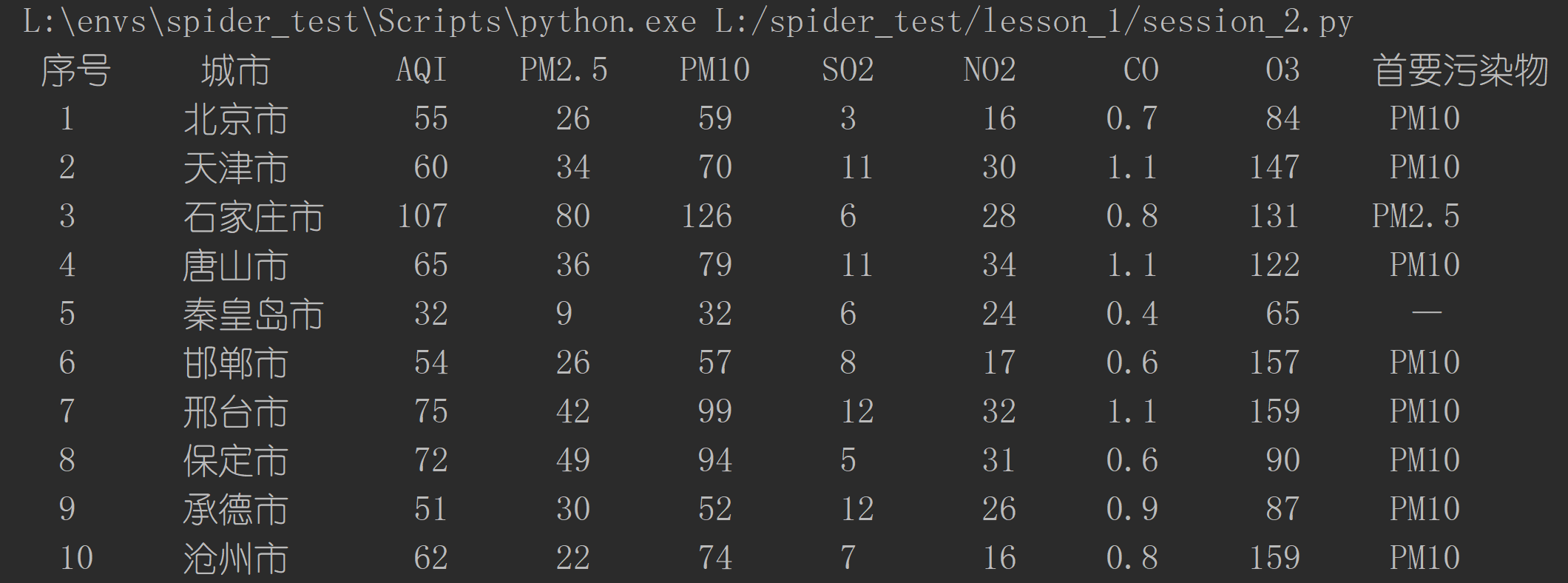
3、文件地址
https://gitee.com/mirrolied/spider_test/blob/master/lesson_2/session_2.py
2) 、心得体会
该作业使用requests进行请求,Beautiful Soup进行解析,也是前面作业的一次复现,总体来说没遇到困难的地方。
唯一要注意的就是输出存在中文,需要进行一定处理,使得输出对齐。
作业③:
- 要求:使用urllib和requests爬取(https://news.fzu.edu.cn/),并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
1) 、作业三实验
1、解题思路
①获取html
由于该题要求使用urllib.request和requests进行爬取,索性将两种方法结合缓存(即读取本地文件)整合成一个函数,由用户选择请求方法。
构建一个get_html函数,输入url以及请求方法,返回html文本:
def get_html(url: str, request_type: str) -> str: """ 获取html :param url: 访问地址 :param request_type: 请求方式: urllib.request 或 urllib.request 或相应缓存 :return: html """ if request_type == "urllib.request": # urllib.request return urllib.request.urlopen(url).read().decode("utf-8") elif request_type == "requests": # requests response = requests.get(url) return response.text else: # 读取缓存文件 with open(f'./.cache/{request_type}.html', 'r', encoding='utf-8') as f: return f.read()
②解析图片
使用正则匹配的方式,将所有的<img>标签内的src提取出来:
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
与第一题去除换行的方式不同,这里使用了设置re.S模式的方法,也能达到效果。
③图片保存
文件内容即请求图片url返回内容,使用with open创建文件管理对象,并将模式设置为wb(二进制写入模式):
resp = requests.get(img_url) with open(f'./download/{img.split("/")[-1]}', 'wb') as f: f.write(resp.content)
使用字符串分割从url中提取出文件的名称(保证后缀名无误):
img.split("/")[-1]
或以"."进行分割,仅提取后缀名,自己对文件进行标号命名。
最后使用f.write(resp.content)即可实现保存。
def get_imgs(html:str, download=True) -> None: """ 获取所有图片地址,可选择下载 :param html: 输入html :param download: 是否下载 :return: None """ imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S) print(imgList) print(f'共有{len(imgList)}张图片') if download: for i, img in enumerate(imgList): img_url = "http://news.fzu.edu.cn" + img print(f"正在保存第{i + 1}张图片 路径:{img_url}") resp = requests.get(img_url) with open(f'./download/{img.split("/")[-1]}', 'wb') as f: f.write(resp.content)
2、运行结果
保存的图片:

3、文件地址
https://gitee.com/mirrolied/spider_test/blob/master/lesson_3/session_3.py
2)、 心得体会
这题是之前商品图片爬取的简化版(删去了分页操作),有几个地方需要注意:
- 首先是正则解析换行问题,上面也出现几次了,这里总结一下解决方法:
- 使用replace()函数去除换行符(\r \n);
- 设置正则匹配模式为re.S。(推荐使用方法2,方法1的换行符可能出现在我们需要爬取的内容中,导致目标数据被修改)
- 这里使用函数进行整合逻辑上还是有些问题,为了提高拓展性以及简化后续图片保存的操作,其实应该使用class对请求进行一个对象封装,但由于作业要求的功能较为基础,出于时间因素,还是选择了函数实现;
- 该作业提取的网页使用的图片路径均为相对路径,需要添加域名才能进行成功获取。
- 该网站似乎存在访问限制,可能受并发量或访问时间影响(本人没有复现过,去年考核题目出的也是福大要闻,有学员反馈连接被拒绝的问题)。

本次作业gitee地址:https://gitee.com/mirrolied/spider_test/tree/master/lesson_1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号