
冯琳---第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 数据采集,数据处理,数据分析展示(词云图)以及git的使用 |
| 作业源代码 | first-personal-work |
| 学号 | 211806213 |
一、时间记录
| 代码行数 | 分析时间 | 编写时间 |
|---|---|---|
| 100+ | 4h+ | 7h+ |
二、作业步骤
- 数据采集
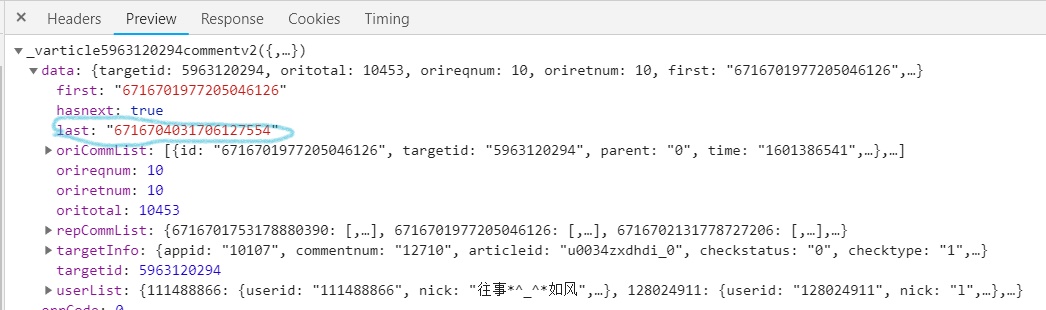
- 打开腾讯视频《在一起》的网页,利用爬虫技术正则提取评论信息。因为其网页是异步加载,因此需要找到规律。
![]()
![]()
![]()
- 可以发现二者的区别是cursor=和_=的数据会发生改变。cursor=的数值在上一次数据的last中,而_=数值每次+1。


- 使用爬虫爬取评论数据保存为json
- 代码如下
![]()

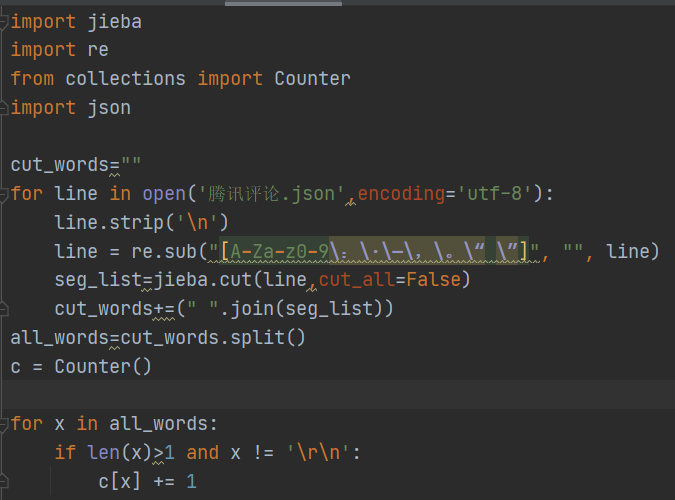
- 使用jieba分词,并统计数量
- 下载安装完jieba库之后,分词代码如下
![]()
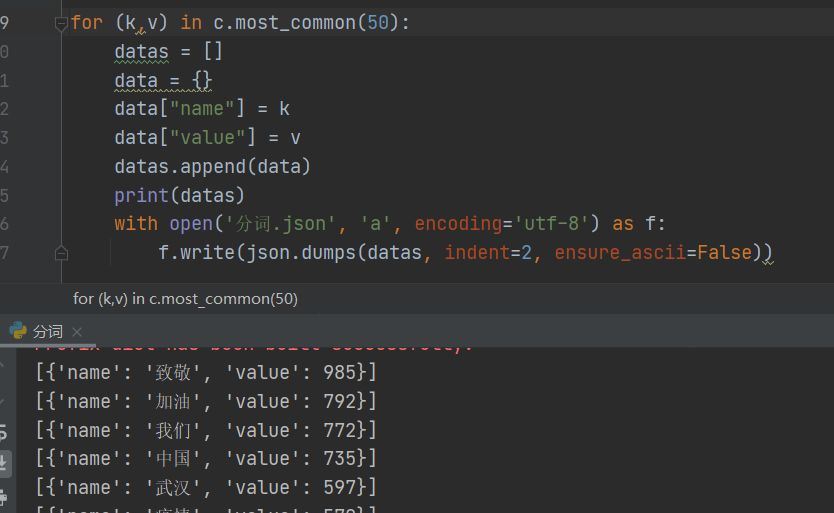
- 分词完后将结果以字典形式保存为json
![]()
- 生成词云图
- 结合js插件echarts.js和echarts-wordcloud.min.js完成index.html
![]()

三、Github
- GitHub仓库地址:first-personal-work
-
克隆仓库到本地: git clone https://github.com/mirror199976/first-personal-work.git
-
进入克隆到本地的文件夹: cd first-personal-work
-
新建分支: git switch -c crawl
-
将上传的文件复制到文件夹
-
上传文件: git add .
-
提交: git commit -m "提交信息"
-
上传: git push -u origin crawl
![]()
-
重复3-7操作完成另一分支
![]()
-
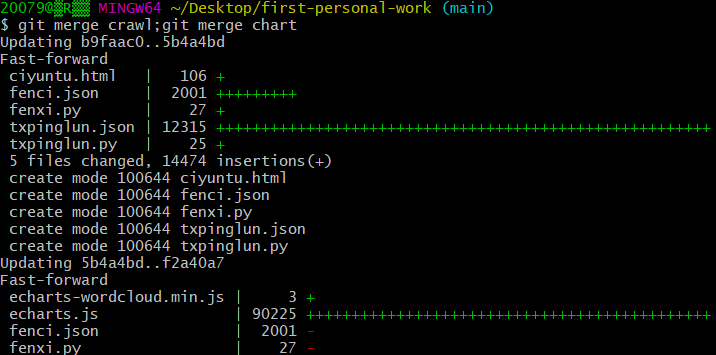
切换回主分支后合并分支: git merge crawl;git merge chart
![]()
![]()
四、经验总结
- 重温了一边爬虫基础,在数据采集与处理的地方苦恼了很久,在百度了许多资料以及大佬的帮助下,终于完成了本次实验
- 而词云图是我第一次接触,在一脸茫然的情况下四处找资料,因为安装的是python39,导致找不到匹配的wordcloud的安装包,最后也是靠着百度和大佬帮助完成的_(:з)∠)_并且git的操作也还不太熟练,中间出过一些小错误
- 感觉自己好废噗_(:з)∠)_,还需要继续学习更多知识,加强自己的编程能力。
五、参考文献
介绍一种安装python第三方库jieba库的方法
Python爬取腾讯视频评论的思路详解
python爬虫学习笔记(一)—— 爬取腾讯视频影评
利用jieba进行中文分词并进行词频统计
echarts绘制词云图及常用属性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号