ELK之使用kafka作为消息队列收集日志
参考:https://www.cnblogs.com/fengjian2016/p/5841556.html
https://www.cnblogs.com/hei12138/p/7805475.html
https://blog.csdn.net/lhmood/article/details/79099615
https://www.cnblogs.com/Orgliny/p/5730381.html
ELK可以使用redis作为消息队列,但redis作为消息队列不是强项而且redis集群不如专业的消息发布系统kafka,以下使用ELK结合kafka作为消息队列进行配置
本次配置拓扑图
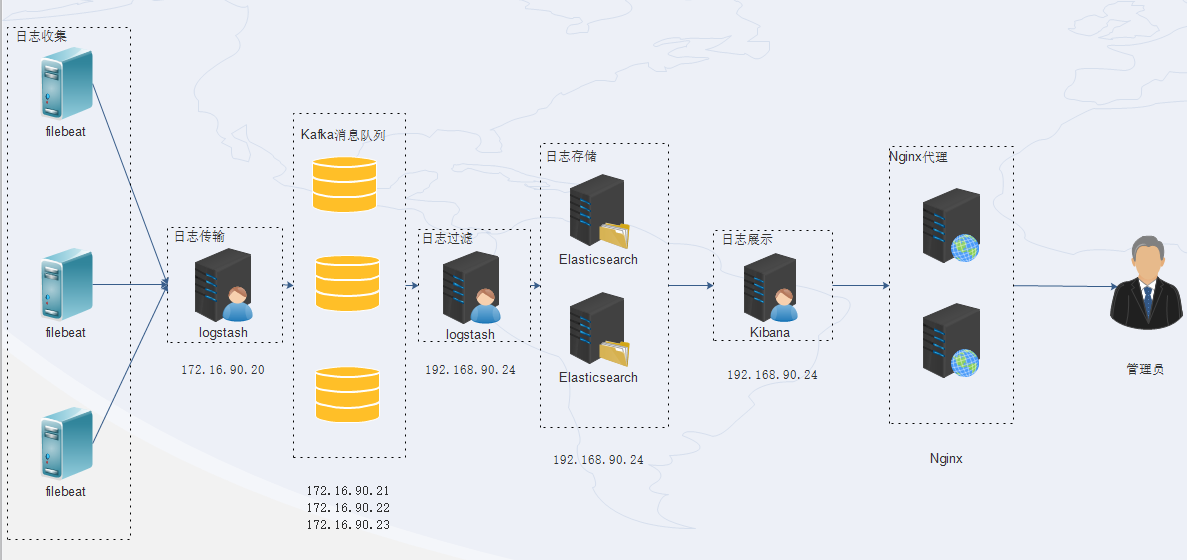
主机角色
| 主机名 | IP | 系统 | 角色 |
| prd-elk-logstash-01 | 172.16.90.20 | CentOS7.5 | logstash日志传输 |
| prd-elk-kafka-01 | 172.16.90.21 | CentOS7.5 | 日志消息队列kafka01 |
| prd-elk-kafka-02 | 172.16.90.22 | CentOS7.5 | 日志消息队列kafka02 |
| prd-elk-kafka-03 | 172.16.90.23 | CentOS7.5 | 日志消息队列kafka03 |
| prd-elk-logstash-02 | 172.16.90.24 | CentOS7.5 | logstash日志过滤,存储 |
软件选用
JKD 1.8.0_171 elasticsearch 6.5.4 logstash 6.5.4 kibana 6.5.4 kafka 2.11-2.1.1
172.16.90.20安装logstash和filebeat
rpm -ivh logstash-6.5.4.rpm rpm -ivh filebeat-6.5.4-x86_64.rpm
修改filebeat配置文件收集系统messages日志
/etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages #需收集日志路径
tags: ["messages"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["172.16.90.20:5044"] #输出至logstash
processors:
- add_host_metadata:
- add_cloud_metadata:
- drop_fields:
fields: ["beat", "input", "source", "offset", "prospector","host"] #删除无用的参数
修改logstash先标准输出至屏幕
/etc/logstash/conf.d/filebeat-logstash.conf
input{
beats {
port => 5044
}
}
output{
if "messages" in [tags]{
stdout{
codec => rubydebug
}
}
}
运行logstash查看输出
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/filebeat-logstash.conf
输出如下
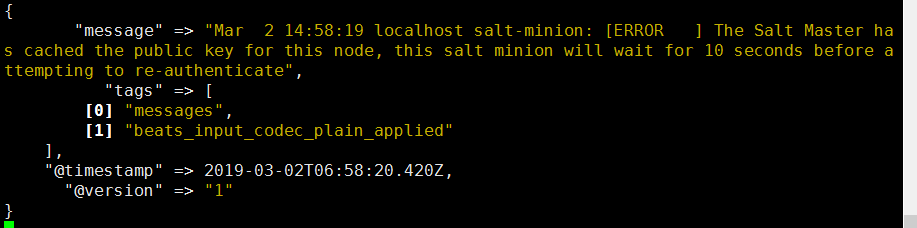
172.16.90.24安装logstash,elasticsearch,kibana安装配置过程不详叙,通过172.16.90.20收集的日志信息可以直接传递至172.16.90.24的logstash进行过滤及es存储,规模不大可以使用这种方式,下面安装配置kafka集群
Kafka集群安装配置
在搭建kafka集群之前需要提前安装zookeeper集群,kafka压缩包只带zookeeper程序,只需要解压配置即可使用
获取软件包,官方网站 http://kafka.apache.org/

PS:不要下载src包,运行会报错
解压拷贝至指定目录
tar -xf kafka_2.11-2.1.1.tgz cp -a kafka_2.11-2.1.1 /usr/local/ cd /usr/local/ ln -s kafka_2.11-2.1.1/ kafka
修改配置文件zookeeper配置文件
/usr/local/kafka/config/zookeeper.properties #数据路径 dataDir=/data/zookeeper # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=0 #tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 tickTime=2000 initLimit=20 syncLimit=10 #2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口; #3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口 server.1=172.16.90.21:2888:3888 server.2=172.16.90.22:2888:3888 server.3=172.16.90.23:2888:3888
创建数据目录并创建myid文件,文件为数字,用于标识唯一主机,必须有这个文件否则zookeeper无法启动
mkdir /data/zookeeper -p echo 1 >/data/zookeeper/myid
修改kafka配置/usr/local/kafka/config/server.properties
#唯一数字分别为1,2,2 broker.id=1 #这个broker监听的端口 prot=9092 #唯一填服务器IP host.name=172.16.90.21 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 #kafka日志路径,不需要提前创建,启动kafka时创建 log.dirs=/data/kafka-logs #分片数,需要配置较大,分片影响读写速度 num.partitions=16 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 #zookpeer集群 zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
把配置拷贝至其他kafka主机,zookeeper.properties配置一样 ,server.properties配置一下两处不一样,myid也不一样
broker.id=2 host.name=172.16.90.22 broker.id=3 host.name=172.16.90.23
配置完三台主机,启动zookeeper启动顺序为服务器1 2 3
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
启动过程中提示拒绝连接不用理会,由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。其他节点也可能会出现类似的情况,属于正常

检测是否启动
netstat -ntalp|grep -E "2181|2888|3888"

启动kafka 启动顺序也是1 2 3
nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
启动成功会启动9092端口

PS:如果系统有问题会导致日志不停输出
三台主机启动完毕,下面来检测一下
在kafka01创建一个主题,主题名为sumer
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 172.16.90.21:2181 --replication-factor 3 --partitions 1 --topic summer

查看summer主题详情
/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 172.16.90.21:2181 --topic summer
Topic:summer PartitionCount:1 ReplicationFactor:3 Configs: Topic: summer Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 #主题名称:summer #Partition:只有一个从0开始 #leader:id为2的broker #Replicas: 副本存在id为 2 3 1的上面 #Isr:活跃状态的broker
删除主题
/usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper 172.16.90.21:2181 --topic summer
使用kafka01发送消息,这里是生产者角色
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 172.16.90.21:9092 --topic summer
出现命令行需要手动输入消息
使用kafka02接收消息,这里是消费者角色
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 172.16.90.22:9092 --topic summer --from-beginning
在kafka01输入消息然后会在kafka02接收到该消息


下面将logstash-01的输出从标准输出改到kafka中,修改配置文件
/etc/logstash/conf.d/filebeat-logstash.conf
input{
beats {
port => 5044
}
}
output{
if "messages" in [tags]{
kafka{
#输出至kafka
bootstrap_servers => "172.16.90.21:9092,172.16.90.22:9092,172.16.90.23:9092"
#主题名称,将会自动创建
topic_id => "system-messages"
#压缩类型
compression_type => "snappy"
}
stdout{
codec => rubydebug
}
}
}
启动logstash输出测试
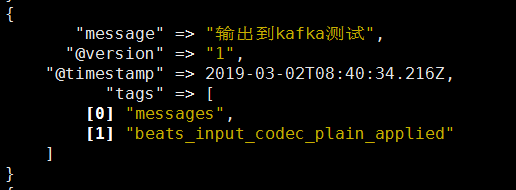
kafka01查看是否生成这个主题
/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 172.16.90.21:2181 --topic system-messages
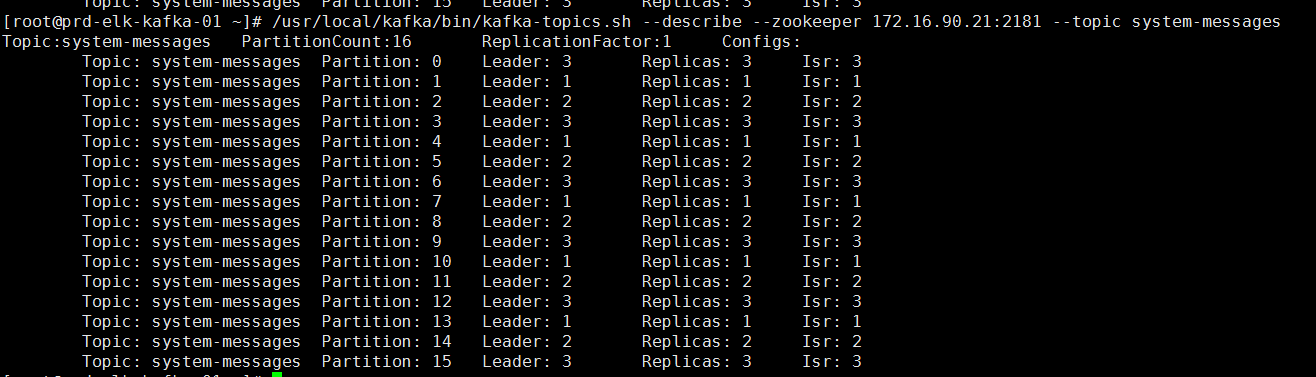
可以看出,这个主题生成了16个分区,每个分区都有对应自己的Leader,但是我想要有10个分区,3个副本如何办?还是跟我们上面一样命令行来创建主题就行,当然对于logstash输出的我们也可以提前先定义主题,然后启动logstash 直接往定义好的主题写数据就行啦,命令如下
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 172.16.90.21:2181 --replication-factor 3 --partitions 10 --topic TOPIC_NAME
经过以上步骤已经通过完成了 filebeat-logstash01-kafka过程,下面配置logstash02接收消费kafka消息
logstash02需要安装logstash,elasticsearch,kibana
rpm -ivh elasticsearch-6.5.4.rpm rpm -ivh kibana-6.5.4-x86_64.rpm rpm -ivh logstash-6.5.4.rpm
修改logstash配置先进行标准输出测试
input{
kafka {
#kafka输入
bootstrap_servers => "172.16.90.21:9092,172.16.90.22:9092,172.16.90.23:9092"
codec => plain
#主题
topics => ["system-messages"]
consumer_threads => 5
decorate_events => false
auto_offset_reset => "earliest"
#定义type方便后面选择过滤及输出
type => "system-messages"
}
}
output{
if "system-messages" in [type] {
# elasticsearch{
# hosts => ["172.16.90.24:9200"]
# index => "messages-%{+YYYY.MM}"
# }
stdout{
codec => rubydebug
}
}
}
对比logstash01和logstash02输出可以发现经过kafka的输出message会有所不同
原始message
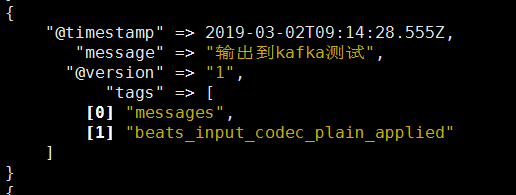
经过kafka输出message如下

logstash-kafka 插件输入和输出默认 codec 为 json 格式。在输入和输出的时候注意下编码格式。消息传递过程中 logstash 默认会为消息编码内加入相应的时间戳和 hostname 等信息。如果不想要以上信息(一般做消息转发的情况下),可以修改logstash01配置增加配置 codec => plain{ format => "%{message}"}
input{
beats {
port => 5044
}
}
output{
if "messages" in [tags]{
kafka{
#输出至kafka
bootstrap_servers => "172.16.90.21:9092,172.16.90.22:9092,172.16.90.23:9092"
#主题名称,将会自动创建
topic_id => "system-messages"
#压缩类型
compression_type => "snappy"
#定义消息通过kafaka传递后格式不变
codec => plain{ format => "%{message}"}
}
stdout{
codec => rubydebug
}
}
}
PS:使用配置codec => plain{ format => "%{message}"} 后传递给kafka的消息仅仅剩下源messages信息,可以在kafka查看
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 172.16.90.21:9092 --topic nginx-prod-log --from-beginning
源信息为

kafka消息队列输出

后端过滤的logstash输出

启动logstahs再次对比前后输出
原message
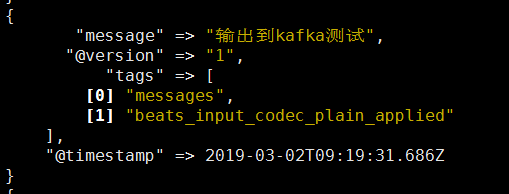
经过kafka后的message
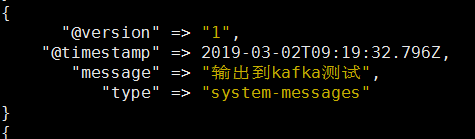
停止任意两个kafka只有有一台kafka主机在运行就能保障日志正常输出
把标准输出删除写入到elasticsearch即可
2024-04-10补充
设置开机自启动
三台主机均操作
设置service文件
zookeeper
# cat /usr/lib/systemd/system/zookeeper.service [Unit] Description=Zookeeper service After=network.target [Service] Type=simple Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" User=root Group=root ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-failure [Install] WantedBy=multi-user.target
kafka
# cat /usr/lib/systemd/system/kafka.service [Unit] Description=Apache Kafka server (broker) After=network.target zookeeper.service [Service] Type=simple Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" User=root Group=root ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh Restart=on-failure [Install] WantedBy=multi-user.target
设置开机自启动
systemctl daemon-reload systemctl enable zookeeper systemctl enable kafka

 浙公网安备 33010602011771号
浙公网安备 33010602011771号