

ZooKeeper分布式配置——看这篇就够了
ZooKeeper 的由来
PS:这一节不重要, 不感兴趣的小伙伴可以跳过
ZooKeeper 最早起源于雅虎研究院的一个研究小组,在当时,研究人员发现,在雅虎内部有很多的大型系统基本上都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点的问题,所有雅虎的开发人员就尝试开发了一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。关于"ZooKeeper"这个项目的名字。也有一个故事,在项目开始初期,因为考虑到内部的很多项目都是用动物的名字来命名的(例如:Pig项目),所以雅虎的工程师也希望给这个项目也取一个动物的名字,这个时候担任研究院的首席科学家 Raghu Ramakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园”,此话一出,大家纷纷表示就叫动物园管理员吧,因为各个以动物命名的分布式组件放在一起,这个分布式系统看上去就像一个大型的动物园了,而ZooKeeper 正好要用来进行分布式环境的协调,于是ZooKeeper 的名字也就由此诞生了。
来源:《从 Paxos 到 ZooKeeper 》
分布式配置中心
在上一期中我们讲解了 ZooKeeper集群的配置和安装,ZooKeeper集群 主要是帮我们做分布式协调的,今天我们用ZK实现分布式配置。关于ZooKeeper 集群的配置大家可以参考上一篇文章《Zookeeper 集群部署的那些事儿》。
为什么需要分布式配置中心
对于刚开始的时候,很多公司的服务器可能是由单个组成,但是随着业务的发展,单一节点的服务无法满足业务的飞速发展,后面就出现了分布式、集群的概念,到了现在形成的微服务,技术的改进能够更好的满足业务的需要。
假设我们线上有很多个微服务分布在不同的服务器上,其中一个微服务,我们就叫它 goods-service,当 goods-service的IP地址需要变更的时候,但是 goods-service又对很多其他的程序提供了服务,这个时候如果没有一个统一配置的东西,每一个应用到 goods-service的应用程序都要做相应的IP地址修改,这是一个很麻烦的事情!
如果使用ZooKeeper来做分布式配置的话,是可以解决这个问题的。

注册中心对比
| 功能点 | Consul | ZooKeeper | etcd | Eureka | Nacos |
|---|---|---|---|---|---|
| 服务健康检查 | TCP/HTTP/gRPC/Cmd | Keepalive | 连接心跳 | Client Beat | TCP/HTTP/MySql/Clint Beat |
| 多数据中心 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| KV存储服务 | 支持 | 支持 | 支持 | —— | —— |
| 一致性算法 | Raft | Paxos | Raft | —— | Raft |
| cap | CP模型 | CP模型 | CP模型 | AP模型 | 支持AP和CP模型 |
| 访问协议 | HTTP/DNS | TCP | HTTP/GRPC | HTTP | HTTP/DNS |
| watch支持 | 全量/支持long polling | 支持 | 支持long polling | 支持long polling/大部分增量 | 支持long polling |
| 自身监控 | metrics | —— | metrics | metrics | metrics |
| 安全 | ACL/HTTPS | ACL | HTTP支持 | —— | —— |
| springCloud继承 | 支持 | 支持 | 支持 | 支持 | 支持 |
如果我们只考虑服务治理的话,Eureka是比较合适的,Eureka是比较纯粹的注册中心了,和Eureka不同Apache ZooKeeper 在设计的时候就遵循 CP原则,任何时候对 ZooKeeper 的访问请求都能得到一致的数据结果,同事系统对网络分割具有容错性,今天我们讲解的就是关于ZooKeeper 的注册发现。
配置中心的核心
-
低延迟: 配置改变(
create/update/delete)后能够最快的把最新的配置同步到其他节点中 -
高可用: 配置中心可以稳定的对外提供服务
其中 低延迟 我们可以通过 ZooKeeper 的 Watcher 机制来实现(等下会讲到Watcher机制)。约定一个节点用来存放配置信息,每个客户端都来监听这个节点的NodeDataChanged事件,当配置发生改变时将最新的配置更新到这个节点上,谁更新无所谓,任何节点都可以更新,当这个节点触发 NodeDataChanged 事件后,在去通知所有监听这个节点的客户端去获取这个节点的最新信息,因为watcher 是一次性的,所以当我们在获取最新信息的时候需要设置监听事件,大部分查询信息都是具有原子性的,所以ZooKeeper中的 getData 也是具有原子性操作,能够保证我们取得的信息是最新的。
对于 高可用 我们首先需要保证的多集群操作来进行ZooKeeper进行部署,在代码层不太需要做过多的工作。

Watch 机制
Watch 是 ZooKeeper 针对节点的一次性观察者机制,就如同我们上面 ** 低延迟** 中讲到的,一次触发后就失效,需要手工重新创建Watch。
当Watch监视的数据发生变化的时候,就会通知设置了 Watch 的客户端,就是我们API中的Watcher,Watcher机制就是为了监听Znode节点发生了哪些变化,所以会有对应的事件类型和状态类型,用过代码中switch进行监听,一个客户端可以链接多个节点,只要Znode节点发生变化就会执行 process(WatchedEvent event)。
如下图所示:

从上图中我们可以看到,在ZooKeeper中,Watch采用的是推送机制,而不是客户端轮询,有些中间件采用的是拉取的模式,例如:KafKa。
Watch有两种监听模式,分别为 事件类型和状态类型 :
事件类型:Znode 节点关联,主要是针对节点的操作
- 创建节点:EventType.NodeCreated
- 节点数据发生变化:EventType.NodeDataChanged
- 当前节点的子节点发生变化:EventType.NodeChildrenChanged
- 删除节点:EventType.NodeDeleted
状态类型:客户端关联,主要是针对于ZooKeeper集群和应用服务之间的状态的变更
- 未连接:KeeperState.Disconnected
- 已连接:KeeperState.SyncConnected
- 认证失败:KeeperState.AuthFailed
- 过期:KeeperState.Expired
- 客户端连接到只读服务器:KeeperState.ConnectedReadOnly
watch的特性
一次性触发: 对于ZooKeeper的Watcher事件,是一次性触发的,当 Watch 监视的数据发生变化的时候,通知设置当前Watch 的 Client,就是我们对应的 Watcher,因为ZooKeeper 的监控都是一次性的,所以我们需要在每次触发后设置监控。
客户端串行执行: 客户端Watcher回调的过程是一个串行同步的过程,可以为我们保证顺序的执行。
轻量级: WatchedEvent是ZooKeeper整个Watcher通知机制的最小通知单元,总共包含三个部分(通知状态、事件类型和节点路径),Watcher通知,只会告诉客户端发生事件而不会告知具体内容,需要客户端主动去进行获取,比如 当监听到 WatchedEvent.NodeDataChanged 信息变化的时候,只会告诉我们这个节点的数据发生了变更,你快来获取最新的值吧。
客户端设置的每个监视点与会话关联,如果会话过期,等待中的监视点将会被删除。不过监视点可以跨越不同服务端的连接而保持,例如,当一个ZooKeeper客户端与一个ZooKeeper服务端的连接断开后连接到集合中的另一个服务端,客户端会发送未触发的监视点列表,在注册监视点时,服务端将要检查已监视的znode节点在之前注册监视点之后是否已经变化,如果znode节点已经发生变化,一个监视点的事件就会被发送给客户端,否则在新的服务端上注册监视点。这一机制使得我们可以关心逻辑层会话,而非底层连接本身。
客户端注册

ZooKeeper 注册的时候会向ZooKeeper 服务端请求注册,服务端会返回请求响应,不管成功失败,都会返回响应结果,当响应成功的时候,ZooKeeper服务端会把Watcher对象放到客户端的WatchManager管理并返回响应给客户端
服务端注册

FinalRequest Processor.ProcessRequest()会判断当前请求是否需要注册Watcher
如果ZooKeeper判断当前客户端需要进行Watcher注册,会将当前的ServerCnxn 对象和数据路径传入 getData 方法中去。ServerCnxn 是ZooKeeper 客户端和服务端之间的连接接口,代表了一个客户端和服务端的连接,可以将 ServerCnxn 当做一个 Watcher 对象,因为它实现了 Watcher 的 process 接口。
- WatcherManager
WatcherManager是 ZK服务端 Watcher 的管理器,分为 WatchTable 和 Watch2Paths 两个存储结构,这两个是不同的存储结构
1)WatchTable: 从数据节点路径的颗粒度管理 Watcher
2)Watch2Paths:从Watcher的颗粒度来控制时间出发的数据节点
在服务端,DataTree 中会托管两个 WatchManager, 分别是 dataWatches (数据变更Watch) 和 childWatches(子节点变更Watch)。
- Watcher 触发逻辑
1)封装WatchedEven:将(KeeperState(通知状态),EventType(事件类型),Path(节点路径))封装成一个 WatchedEvent 对象
2)查询Watcher:根据路径取出对应的Watcher,如果存在,取出数据同时从 WatcherManager(WatchTable/Watch2Paths) 中删除
3)调用Process方法触发Watcher
4.客户端回调 Watcher
1)反序列化:字节流转换成 WatcherEvent 对象
2)处理 chrootPath:如果客户端设置了 chrootPath 属性,那么需要对服务器传过来的完整节点路径进行 chrootPath 处理,生成客户端的一个相对节点路径。比如(/mxn/app/love,经过chrootPath处理,会变成 /love)
3)还原 WatchedEvent:WatcherEvent 转换成 WatchedEvent
4)回调 Watcher:将 WatcherEvent 对象交给 EventThread 线程,在下一个轮询周期中进行 Watcher 回调
- EventThread 处理时间通知
1) SendThread 接收到服务端的通知事件后,会通过调用 EventThread.queueEvent 方法将事件传给 EventThread 线程
2)queueEvent 方法首先会根据该通知事件,从 ZKWatchManager 中取出所有相关的 Watcher 客户端识别出 事件类型 EventType 后,会从相应的 Watcher 存储 (即3个注册方法( dataWatches、existWatcher 或 childWatcher)中去除对应的 Watcher
3) 获取到相关的所有 Watcher 后,会将其放入 waitingEvents 这个队列去
代码实现
下面我们就来演示如何使用代码来实现ZooKeeper的配置
首先我们需要引入ZK的jar
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
配置类
既然我们要做的是分布式配置,首先我们需要模拟一个配置,这个配置用来同步服务的地址
/**
* @program: mxnzookeeper
* @ClassName MyConf
* @description: 配置类
* @author: muxiaonong
* @create: 2021-10-19 22:18
* @Version 1.0
**/
public class MyConfig {
private String conf ;
public String getConf() {
return conf;
}
public void setConf(String conf) {
this.conf = conf;
}
}
Watcher
创建ZooKeeper的时候,我们需要一个Watcher进行监听,后续对Znode节点操作的时候,我们也需要使用到Watcher,但是这两类的功能不一样,所以我们需要定义一个自己的watcher类,如下所示:
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import java.util.concurrent.CountDownLatch;
/**
* @program: mxnzookeeper
* @ClassName DefaultWatch
* @description:
* @author: muxiaonong
* @create: 2021-10-19 22:02
* @Version 1.0
**/
public class DefaultWatch implements Watcher {
CountDownLatch cc;
public void setCc(CountDownLatch cc) {
this.cc = cc;
}
@Override
public void process(WatchedEvent event) {
System.out.println(event.toString());
switch (event.getState()) {
case Unknown:
break;
case Disconnected:
break;
case NoSyncConnected:
break;
case SyncConnected:
System.out.println("连接成功。。。。。");
//连接成功后,执行countDown,此时便可以拿zk对象使用了
cc.countDown();
break;
case AuthFailed:
break;
case ConnectedReadOnly:
break;
case SaslAuthenticated:
break;
case Expired:
break;
case Closed:
break;
}
}
}
由于是异步进行操作的,我们创建一个ZooKeeper对象之后,如果不进行阻塞操作的话,有可能还没有连接完成就执行后续的操作,所以这里我们用 CountDownLatch进行阻塞操作,当监测连接成功后,进行 countDown放行,执行后续的ZK的动作。
当我们连接成功 ZooKeeper 之后,我们需要通过 exists判断是否存在节点,存在就进行 getData操作。这里我们创建一个 WatchCallBack因为exists和getData都需要一个callback,所以除了实现Watcher以外还需要实现节点状态:AsyncCallback.StatCallback 数据监听:AsyncCallback.DataCallback
import org.apache.zookeeper.AsyncCallback;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
/**
* @program: mxnzookeeper
* @ClassName WatchCallBack
* @description:
* @author: muxiaonong
* @create: 2021-10-19 22:13
* @Version 1.0
**/
public class WatchCallBack implements Watcher, AsyncCallback.StatCallback, AsyncCallback.DataCallback {
ZooKeeper zk ;
MyConfig conf ;
CountDownLatch cc = new CountDownLatch(1);
public MyConfig getConf() {
return conf;
}
public void setConf(MyConfig conf) {
this.conf = conf;
}
public ZooKeeper getZk() {
return zk;
}
public void setZk(ZooKeeper zk) {
this.zk = zk;
}
public void aWait(){
//exists的异步实现版本
zk.exists(ZKConstants.ZK_NODE,this,this ,"exists watch");
try {
cc.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/** @Author mxn
* @Description //TODO 此回调用于检索节点的stat
* @Date 21:24 2021/10/20
* @param rc 调用返回的code或结果
* @param path 传递给异步调用的路径
* @param ctx 传递给异步调用的上下文对象
* @param stat 指定路径上节点的Stat对象
* @return
**/
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
if(stat != null){
//getData的异步实现版本
zk.getData(ZKConstants.ZK_NODE,this,this,"status");
}
}
/** @Author mxn
* @Description //TODO 此回调用于检索节点的数据和stat
* @Date 21:23 2021/10/20
* @param rc 调用返回的code或结果
* @param path 传递给异步调用的路径
* @param ctx 传递给异步调用的上下文对象
* @param data 节点的数据
* @param stat 指定节点的Stat对象
* @return
**/
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
if(data != null ){
String s = new String(data);
conf.setConf(s);
cc.countDown();
}
}
/** @Author mxn
* @Description //TODO Watcher接口的实现。
* Watcher接口指定事件处理程序类必须实现的公共接口。
* ZooKeeper客户机将从它连接到的ZooKeeper服务器获取各种事件。
* 使用这种客户机的应用程序通过向客户机注册回调对象来处理这些事件。
* 回调对象应该是实现监视器接口的类的实例。
* @Date 21:24 2021/10/20
* @Param watchedEvent WatchedEvent表示监视者能够响应的ZooKeeper上的更改。
* WatchedEvent包含发生了什么,
* ZooKeeper的当前状态,以及事件中涉及的znode的路径。
* @return
**/
@Override
public void process(WatchedEvent event) {
switch (event.getType()) {
case None:
break;
case NodeCreated:
//当一个node被创建后,获取node
//getData中又会触发StatCallback的回调processResult
zk.getData(ZKConstants.ZK_NODE,this,this,"sdfs");
break;
case NodeDeleted:
//节点删除
conf.setConf("");
//重新开启CountDownLatch
cc = new CountDownLatch(1);
break;
case NodeDataChanged:
//节点数据被改变了
//触发DataCallback的回调
zk.getData(ZKConstants.ZK_NODE,this,this,"sdfs");
break;
//子节点发生变化的时候
case NodeChildrenChanged:
break;
}
}
}
当前面准备好了之后,我们可以编写测试用例了:
ZKUtils 工具类
import org.apache.zookeeper.ZooKeeper;
import java.util.concurrent.CountDownLatch;
/**
* @program: mxnzookeeper
* @ClassName ZKUtils
* @description:
* @author: muxiaonong
* @create: 2021-10-19 21:59
* @Version 1.0
**/
public class ZKUtils {
private static ZooKeeper zk;
//192.168.5.130:2181/mxn 这个后面/mxn,表示客户端如果成功建立了到zk集群的连接,
// 那么默认该客户端工作的根path就是/mxn,如果不带/mxn,默认根path是/
//当然我们要保证/mxn这个节点在ZK上是存在的
private static String address ="192.18.5.129:2181,192.168.5.130:2181,192.168.5.130:2181/mxn";
private static DefaultWatch watch = new DefaultWatch();
private static CountDownLatch init = new CountDownLatch(1);
public static ZooKeeper getZK(){
try {
//因为是异步的,所以要await,等到连接上zk集群之后再进行后续操作
zk = new ZooKeeper(address,1000,watch);
watch.setCc(init);
init.await();
} catch (Exception e) {
e.printStackTrace();
}
return zk;
}
}
测试类:
import org.apache.zookeeper.ZooKeeper;
import org.junit.Before;
import org.junit.Test;
/**
* @program: mxnzookeeper
* @ClassName TestConfig
* @description:
* @author: muxiaonong
* @create: 2021-10-19 22:04
* @Version 1.0
**/
public class TestConfig {
ZooKeeper zk;
@Before
public void conn(){
zk = ZKUtils.getZK();
}
/** @Author mxn
* @Description //TODO 关闭ZK
* @Date 21:16 2021/10/20
* @Param
* @return
**/
public void close(){
try {
zk.close();
}catch (Exception e){
e.printStackTrace();
}
}
@Test
public void getConf(){
WatchCallBack watchCallBack = new WatchCallBack();
watchCallBack.setZk(zk);
MyConfig myConfig = new MyConfig();
watchCallBack.setConf(myConfig);
//阻塞等待
watchCallBack.aWait();
while(true){
if(myConfig.getConf().equals("")){
System.out.println("zk node 节点丢失了 ......");
watchCallBack.aWait();
}else{
System.out.println(myConfig.getConf());
}
//
try {
//每隔500毫秒打印一次
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
运行测试
首先我们要知道,因为我们连接IP的时候加上了 /mxn这个目录结构,所以我们在服务器初始状态就必须要有这个节点:
集群初始状态:
[zk: localhost:2181(CONNECTED) 7] ls /
[mxn, zookeeper]
我们启动程序看看
连接成功

ZooKeeper 下 /mxn 现在也是空
[zk: localhost:2181(CONNECTED) 9] ls /mxn
[]
[zk: localhost:2181(CONNECTED) 10]
现在我们来创建一个/mxn/myZNode节点数据
[zk: localhost:2181(CONNECTED) 10] create /mxn/myZNode "muxiaonong666"
Created /mxn/myZNode
可以看到,创建完成之后,程序马上给出响应,打印出了我配置的值,muxiaonong666
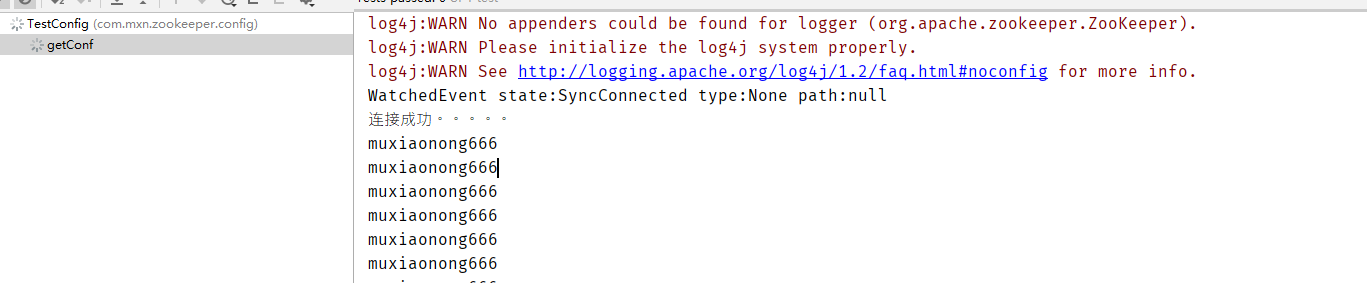
此时,再设置/mxn/myZNode的值为 muxiaonong6969
啪,很快啊!!!我们就可以看到值瞬间改变了

这个时候我们如果删除/mxn/myZNode节点,会发生什么呢,前面我们已经写了watch,如果Znode被删除了,,watch and callback执行
case NodeDeleted:
//节点删除
conf.setConf("");
//重新开启CountDownLatch
cc = new CountDownLatch(1);
break;
if(myConfig.getConf().equals("")){
System.out.println("zk node 节点丢失了 ......");
////此时应该阻塞住,等待着node重新创建
watchCallBack.aWait();
}
删除/mxn/myZNode节点
delete /mxn/myZNode
我们可以看到前面还在打印数据,后面就提示丢失。
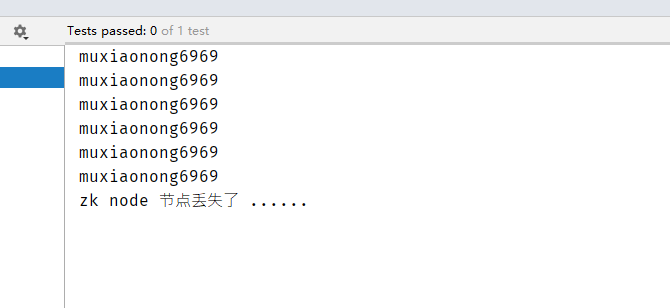
但是这个时候我们客户端没有关闭,而是还在等待数据的更新,如果这个时候当重新进行创建/mxn/myZNode节点的时候,程序又会继续疯狂输出。
create /mxn/myZNode "muxiaonong666"
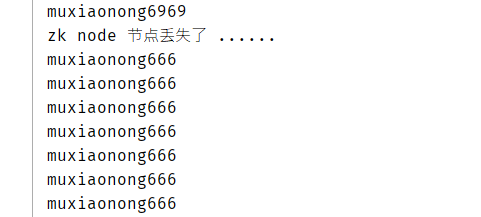
程序正常运行,并且成功获取到了zk配置的最新数据,到这里基本上就实现了,ZooKeeper的分布式配置中心功能了
在这里我测试用的是
getData,但是在项目实战用可能用的更多的是 子节点的操作getChildren
总结
到这里我们这篇 ZooKeeper分布式配置注册发现 就讲完了,如果有疑问的地方欢迎进行讨论,ZooKeeper 可以作为分布式配置中心,也可以用来当然微服务的注册,不过现在微服务都有自己的一套服务发现,对于了解ZooKeeper可以我们方便我们在进行技术选型的时候更好的去抉择, ZooKeeper 的高可用和最终一致性也是比较稳定,
本文代码地址:
https://github.com/muxiaonong/ZooKeeper/tree/master/mxnzookeeper
如果对你有帮助,请帮忙star,感谢!
我是牧小农,如果对你有帮助的话,记得一键三连啊,怕什么真理无穷,进一步有一步的欢喜,大家加油 ~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号