
软件工程第二次作业——个人项目
1. Github项目地址:
https://github.com/hym980417/personal-project
2. PSP表格。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 720 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 30 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 60 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 400 |
| Reporting | 报告 | 120 | 200 |
| · Test Repor | · 测试报告 | 15 | 60 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 1645 | 1955 |
3. 解题思路描述
(1).本题目的任务是按照相关要求统计指定输入文本中的字符数,行数,单词数,以及词频。
(2).对于统计字符,题目中所指的字符为Ascii码,所以我采用了按字符读入的方法,每读入一个Ascii码,count即加1。
(3).对于统计行数,题目中要求统计所有非空行数,在这里我设置了一个布尔变量line_value,若读到非空字符,则置该变量为True,当读到换行符‘\n’时,若该变量为True,则使count加1,同时使line_value为false。直到读完所有字符。若最后的line_value为True,则再使count加1。
(4).对于统计单词数,题目中要求单词为前四个字符为字母的串为有效单词(正则表达式),在这里我直接判定读入的串是否符合前四个是字母,符合的话就不考虑后面的字符,将count加1。
(5).对于统计词频,在这里我使用了unordered_map结构,将(4)中判定为有效的串作为KEY,每出现一次就对该KEY对应的VALUE加1,统计完之后,将unordered_map中键值对以pair<string,int>插入vector,通过sort对vector按照VALUE进行排序,在这里我使用的全排序,如果在有效单词数较少的情况下,全排的效率较高,多则反之。
4. 设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
流程图:
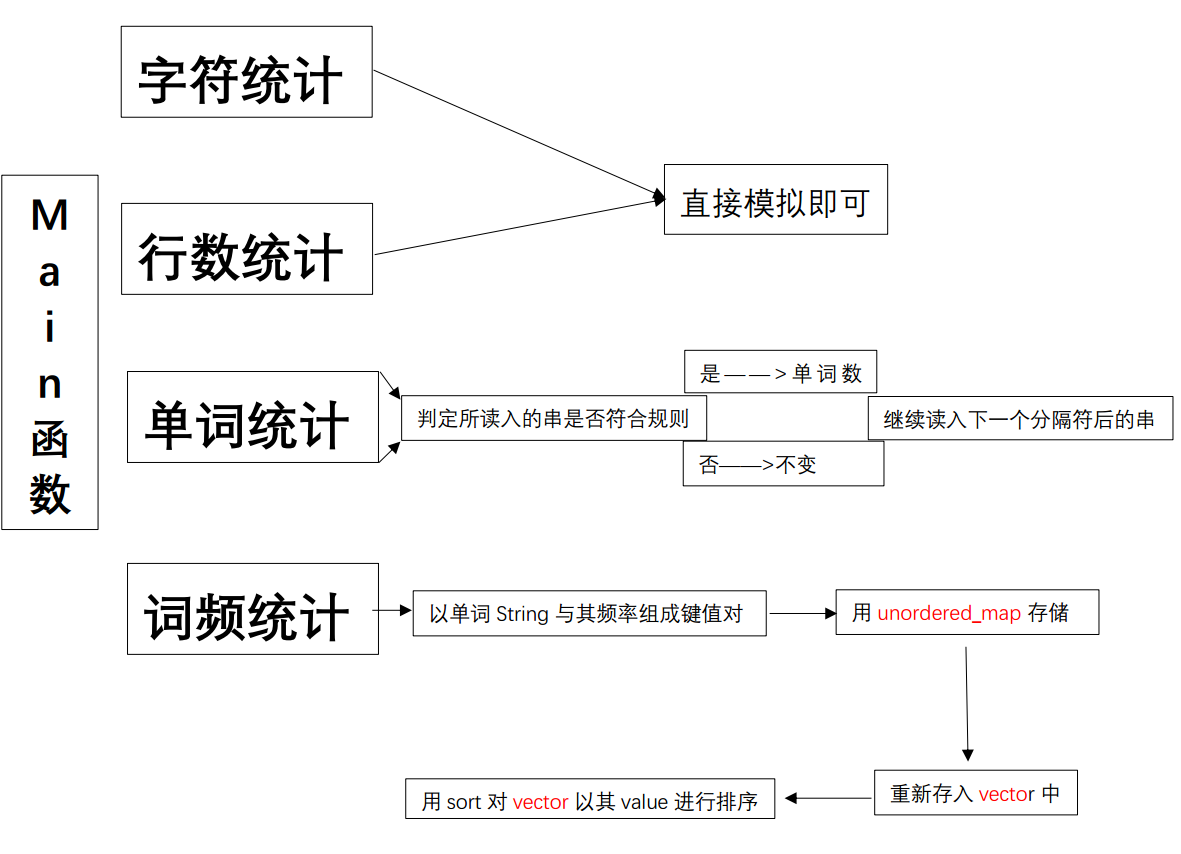
(PS:在后面的改进中将sort全排序改成了遍历十次取最十个大值)
对于该任务,我分为了四个函数 ,分别用来统计字符数,单词数,行数,词频
其中统计字符数直接用fin方法即可,统计行数判断“\",并对当前行是否有效进行判断
单词数则是按照要求对串进行筛选,词频的话用unordered_map进行存储,并且最后遍历10次找出top10(后来改进的方法)
单元测试:
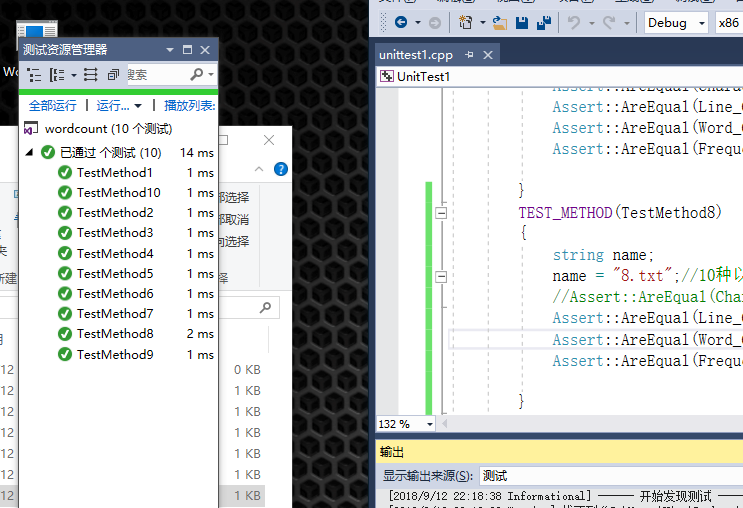
| 单元测试名称 | 测试内容 |
| TestMethod1 | 全空文本 |
| TestMethod2 | 错误的文件名 |
| TestMethod3 | 只含有换行符*5 |
| TestMethod4 | 最高单词频率为4 |
| TestMethod5 | 有效行与无效行组合 |
| TestMethod6 | 无效串 |
| TestMethod7 | 单个长串 |
| TestMethod8 | 10种以上有效词 |
| TestMethod9 | 只有数字 |
| TestMethod10 | 空格行*5 |
这里我一共进行了10个测试,包括空值,错误文件名等各种特殊情况,但代码覆盖率这边,我看了大佬们的博客,下载了opencppcoverage这个插件并安装,可是怎么用怎么报错,教程也看了许多,可能和机器配置的环境有一定问题,改日重装个系统再试!
PS:单元测试这里花了很多时间,不知道该如何去进行单元测试,在网上查了许多教程才勉强学会
附代码
#include"stdafx.h" #include"targetver.h" #include"../WordCount/LineCount.h" #include"../WordCount/CharacterCount.h" #include"../WordCount/WordCount.h" #include"../WordCount/WordFrequency.h" #include <iostream> #include <fstream> #include <string> #include <vector> #include <unordered_map> #include <algorithm> using namespace Microsoft::VisualStudio::CppUnitTestFramework; namespace UnitTest1 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { string name; name = "1.txt";//全空文本 Assert::AreEqual(Character_Count(name), 0); Assert::AreEqual(Line_Count(name), 0); Assert::AreEqual(Word_Count(name), 0); } TEST_METHOD(TestMethod2) { string name; name = "000";//错误的文件名 Assert::AreEqual(Character_Count(name), -1); Assert::AreEqual(Line_Count(name), -1); Assert::AreEqual(Word_Count(name), -1); Assert::AreEqual(Frequency_Count(name), -1); } TEST_METHOD(TestMethod3) { string name; name = "3.txt";//只含有换行符*5 Assert::AreEqual(Character_Count(name), 5); Assert::AreEqual(Line_Count(name), 0); Assert::AreEqual(Word_Count(name), 0); Assert::AreEqual(Frequency_Count(name), 0); } TEST_METHOD(TestMethod4) { string name; name = "4.txt";//最高频率为4 //Assert::AreEqual(Character_Count(name), 30); Assert::AreEqual(Line_Count(name), 2); Assert::AreEqual(Word_Count(name), 11); Assert::AreEqual(Frequency_Count(name), 4); } TEST_METHOD(TestMethod5) { string name; name = "5.txt";//有效行与无效行相组合 //Assert::AreEqual(Character_Count(name), 76); Assert::AreEqual(Line_Count(name), 2); Assert::AreEqual(Word_Count(name), 1); Assert::AreEqual(Frequency_Count(name), 1); } TEST_METHOD(TestMethod6) { string name; name = "6.txt";//无效串 //Assert::AreEqual(Character_Count(name), 76); Assert::AreEqual(Line_Count(name), 1); Assert::AreEqual(Word_Count(name), 0); Assert::AreEqual(Frequency_Count(name), 0); } TEST_METHOD(TestMethod7) { string name; name = "7.txt";//单个长串 Assert::AreEqual(Character_Count(name), 260); Assert::AreEqual(Line_Count(name), 1); Assert::AreEqual(Word_Count(name), 1); Assert::AreEqual(Frequency_Count(name), 1); } }; }
5.程序性能分析及改进:
在这里我用了一个大小4M+的测试文本,以下是输出
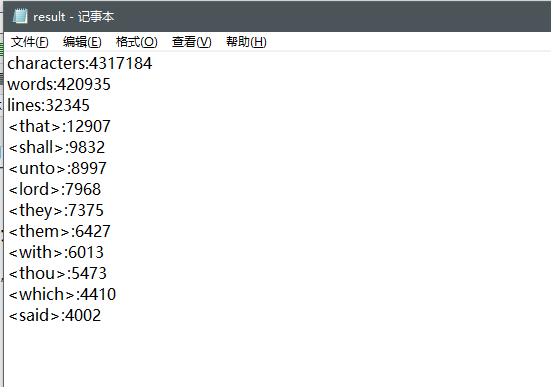
利用VS2017的性能测试功能进行测试
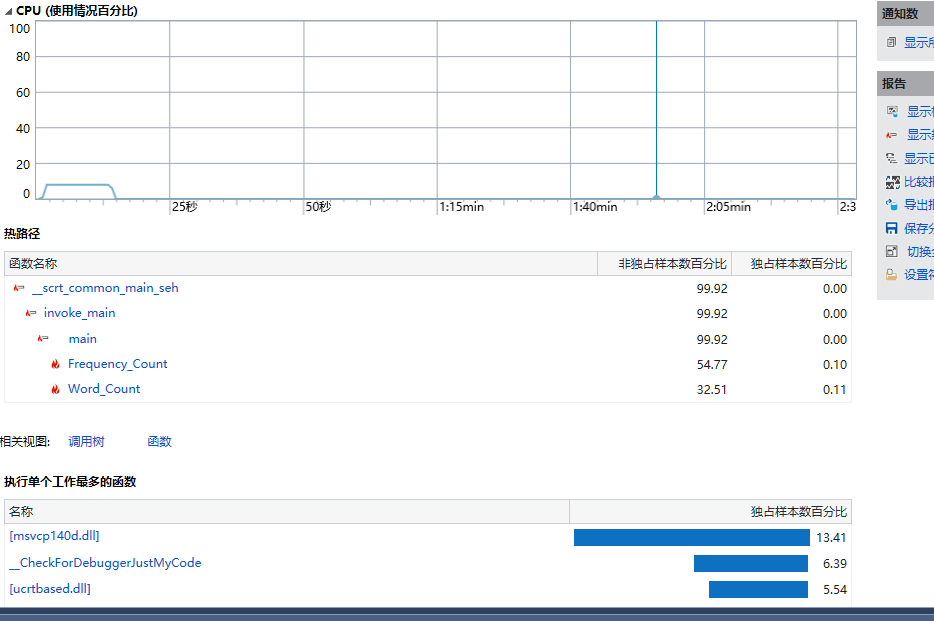
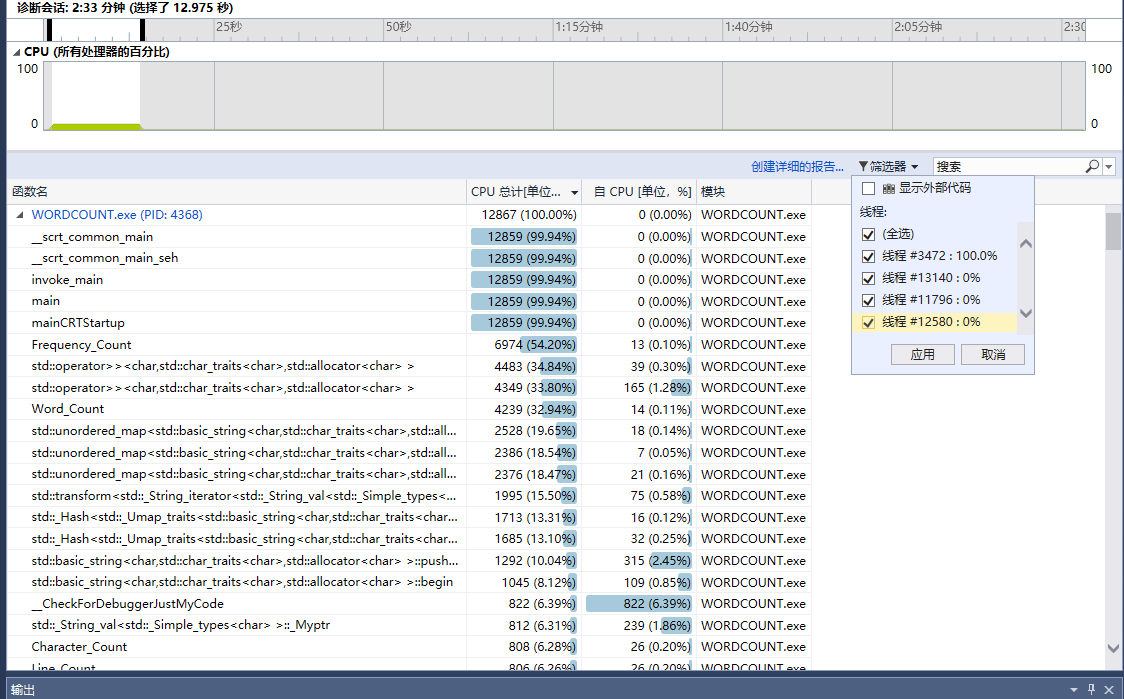
可以看到,对于这个测试文本来说,大约运行了13s的时间,可以看到Frequency_Count这个函数占据了54.20%的时间。
在对词频进行统计时,我直接使用了sort函数对value进行全排,时间复杂度为O(n*lgn),而题中并不需要所有的词频,只需要前TOP10,所以除了前10,剩下的都浪费了。
所以我在此处对代码进行了改进,(改完之后发现两者只差了0.5S),改为将value遍历N次(此题中N为10),时间复杂度为O(N*n)。
以下是原代码:
void Frequency_Count(string filename) { const char *k; int i, sign = 0; ifstream fin(filename.c_str()); if (!fin) { cout << "Can't open file" << endl; return; } string temp; unordered_map<string, int> wmap; while (fin >> temp) { transform(temp.begin(), temp.end(), temp.begin(), ::tolower); k = temp.c_str(); sign = 0; if (temp.length() >= 4) { for (i = 0; i < 4; i++) { if (k[i] <= 'z'&&k[i] >= 'a') sign += 1; } if (sign == 4) wmap[temp]++; } } vector<pair<string, int> > tVector; Map_Sort(wmap, tVector); for (int i = 0;i < tVector.size() && i < 10;i++) cout << tVector[i].first << ": " << tVector[i].second << endl; }
其中用到的Map_Sort函数:
int Compare(const pair <string, int> & x, const pair<string, int>& y) { return x.second > y.second; } void Map_Sort(unordered_map<string, int>& tMap, vector<pair<string, int> >& tVector) { for (unordered_map<string, int>::iterator curr = tMap.begin(); curr != tMap.end(); curr++) tVector.push_back(make_pair(curr->first, curr->second)); sort(tVector.begin(), tVector.end(), Compare); }
新代码:
void Frequency_Count(string filename) { const char *k; int i, sign = 0; ifstream fin(filename.c_str()); if (!fin) { cout << "Can't open file" << endl; return; } string temp; unordered_map<string, int> wmap; unordered_map<string, int>::iterator iter; while (fin >> temp) { transform(temp.begin(), temp.end(), temp.begin(), ::tolower); k = temp.c_str(); sign = 0; if (temp.length() >= 4) { for (i = 0; i < 4; i++) { if (k[i] <= 'z'&&k[i] >= 'a') sign += 1; } if (sign == 4) wmap[temp]++; } } string max1; int max2; int j; for (j = 0;j < 10;j++) { max2 = 0; for (iter = wmap.begin(); iter!= wmap.end(); iter++) { if (max2 < iter->second) { max2 = iter->second; max1 = iter->first; } } cout << max1 << ":" << max2 << endl; wmap[max1] = -1; } }
改进后的代码的性能测试:

“改进”后的代码比之前的快了那么一点(0.5s左右),Frequency_Count函数的时间占比稍微小了一些,可能还有更好的算法吧,等会儿去看看大佬们的博客。
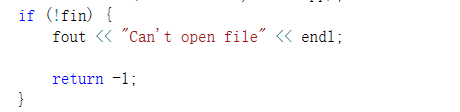
6.异常处理
异常处理这块我弄得很简单,只是打开文件出错这里设置了。
7.总结与心得
收获:勉强学会使用VS(第一次用),学会如何进行单元测试,复习或掌握部分数据结构(map,vector等),复习部分输入输出流,勉强学会使用GitHub等等,还有许多。
说实话,这次作业里的任何一项几乎对于我来说都是第一次,第一次用github(一开始没仔细看作业,代码最后才提交的),第一次用VS2017,第一次写流程式的博客(我觉得是一种另类的实验报告),其中查了好久的资料,学习怎么用VS,还有一些c++的函数方法,尽管如此,欠缺仍有许多,看了些大佬的博客,有种高下立判的感觉。
这篇博客也总算是写完了,虽说花在代码上的时间要远比写博客查资料等得少,但也深知自己coding功夫不足,有些以前欠下得债,现在到了还得时候了(面向对象 数据结构),但这未尝不是一件好事,也算是把以前学的都复习一遍,或许说成再学一遍更恰当吧!
这算是真正意义上得软工实践第一次作业,收获颇丰,虽饱经坎坷,但也算勉强完成(自我感觉完成得不咋地,和大佬的相差甚远),后面的会更具挑战,更加艰难,尽力在后面也保持这般热情吧!

