二叉树概念和操作
二叉树定义
二叉树(Binary Tree)是n(n >= 0)个结点所构成的集合,它或为空树(n=0);或为非空树,对于非空树\(T\):
- 有且仅有一个称之为根的结点
- 除根节点以外的其余结点分为两个互不相交的子集\(T_1\)和\(T_2\),分别称为\(T\)的左子树和右子树,且\(T_1\)和\(T_2\)本身又是二叉树
二叉树性质及存储结构
通过上面的二叉树定义我们知道,二叉树的每个结点最多有两个子结点,同时具有递归性质。递归在二叉树的一些操作中使用非常频繁,对此不熟悉的同学请参考:递归、尾递归和使用Stream延迟计算优化尾递归。接下来我们来看看二叉树的一些概念:
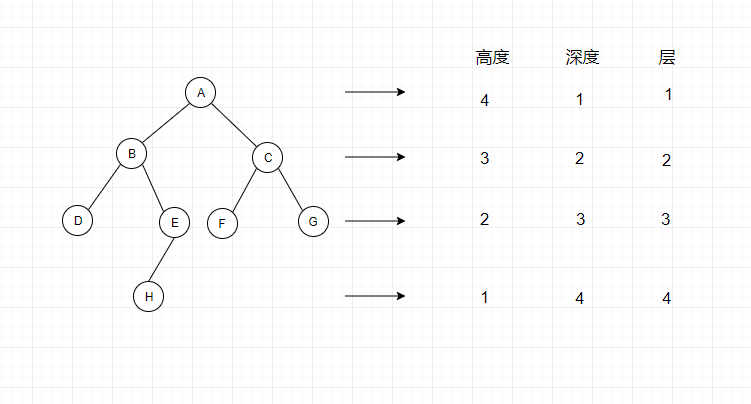
- 结点的高度:结点到叶子结点的最长路径(边数) + 1
- 结点的深度:根结点到这个节点所经历的的边的个数 + 1
- 结点的层数:结点的深度
- 结点的度:结点拥有的子树数量称为结点的度
- 树的高度:根结点的高度
下面是一个二叉树及上面属性的具体值,就不解释了,比较简单。
二叉树具有以下重要特性:
- 性质1:在二叉树的第i层上最多有\(2^{i-1}\)个结点(i>=1)
- 性质2:深度为k的二叉树至多有\(2^k-1\)个结点
- 性质3:具有n个结点的完全二叉树的深度为\([log_2n] + 1\)
二叉树既可以用数组来存储,又可以用链式结构来存储。
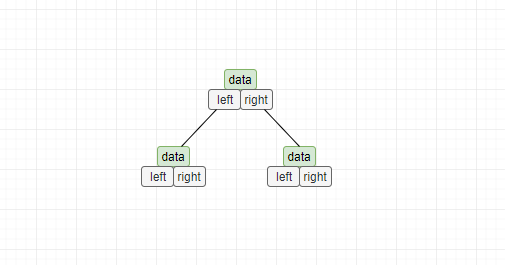
其中用链式结构来存储二叉树我们平时用的比较多,也好理解,我们可以把树的结点看个一个对象结点,其中有三个属性,数据区域、左孩子指针和右孩子指针,我们只需要根据根结点就可以利用结点的左右指针将整个树串起来。
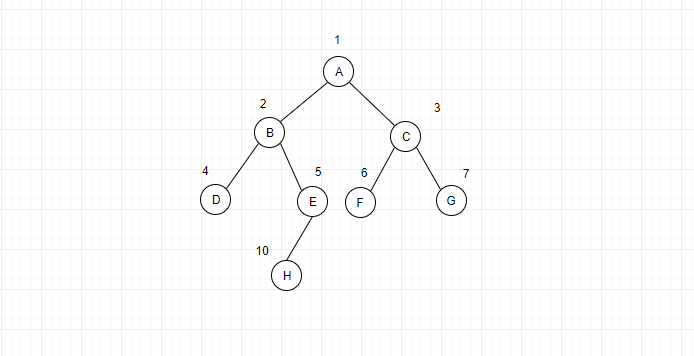
对于用数组存储来说,我们需要将数组的第一位空出来,把根结点存储在下标为1的位置,对于任意一个结点,它在数组的存储位置为i,那么它的左结点存储的位置为2i,右结点为2i + 1。这样就可以将整个二叉树存储在数组中了。不过从上面的逻辑来看,用数组来存储二叉树会有空间的浪费,因为同一层有些结点有子结点,有些没有,这样就会浪费空间。
满二叉树和完全二叉树
从上面二叉树的性质来看,二叉树完全是多种多样,变化多端,有没有一些比较特殊的二叉树呢?下面我们来了解下满二叉树和完全二叉树。
满二叉树:
深度为k且含有\(2^k-1\)个结点的二叉树。
直白点就是叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个孩子,下面是一个满二叉树的示例:
完全二叉树:
深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
上面的定义我们听着完全云里雾里,不知所云,我们简单总结下,就是完全二叉树有以下特性:
- 除了最后一层,其他层必须是满二叉树
- 叶子结点只可能在层次最大的两层上出现
- 最后一层的叶子节点靠左排列
- 对任一结点,若其右分支下的子孙的最大层次为\(l\),则其左分支下的子孙的最大层次为\(l\) 或 \(l + 1\)
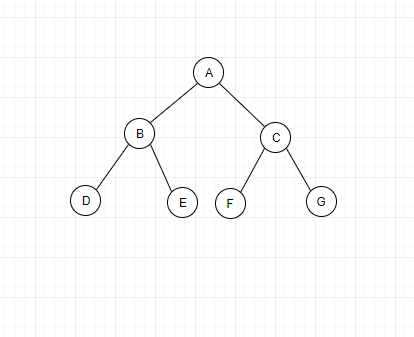
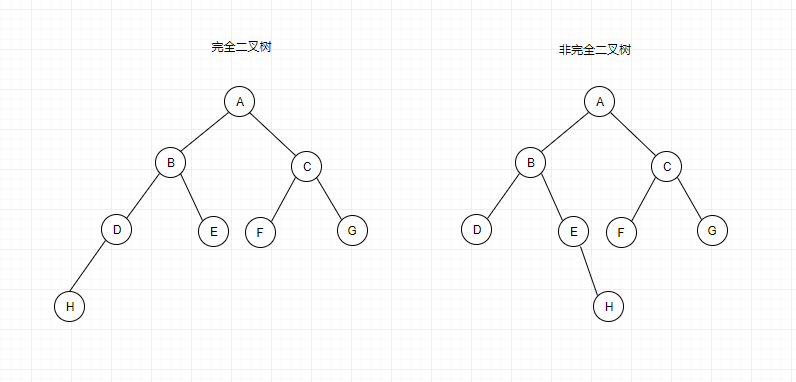
下图中左边的是完全二叉树,右边的则不是:
二叉树操作
遍历
二叉树的概念和存储方式我们了解过了,那么对于二叉树而言,最重要的操作莫过于对其的遍历。在数据结构这门课上,我们学过对二叉树的遍历方式有三种:前序遍历、中序遍历以及后序遍历,其中,前、中、后序,表示的是节点与它的左右子树节点遍历打印的先后顺序。
- 前序遍历:对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印右子树
- 中序遍历:对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印右子树
- 后序遍历:对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印它本身
从上面三种遍历方式来看,前、中和后序遍历其实是递归的过程,下面是三种遍历的递推公式:
前序遍历的递推公式:
preOrder(r) = print r->preOrder(r->left)->preOrder(r->right)
中序遍历的递推公式:
inOrder(r) = inOrder(r->left)->print r->inOrder(r->right)
后序遍历的递推公式:
postOrder(r) = postOrder(r->left)->postOrder(r->right)->print r
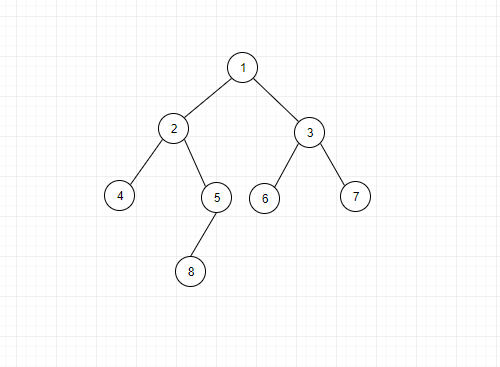
接下来我们来仔细分析下这三种遍历的递归和非递归的方式。依下面的二叉树来分析:
下面是代表二叉树的节点的Node类:
public static class Node<E extends Comparable<E>> {
E item;
Node<E> parent;
Node<E> left;
Node<E> right;
public Node (Node<E> parent, E item) {
this.parent = parent;
this.item = item;
}
@Override
public String toString() {
return "item=" + item + " parent=" + ((parent != null) ? parent.item : "NULL") + " left="
+ ((left != null) ? left.item : "NULL") + " right=" + ((right != null) ? right.item : "NULL");
}
}
前序遍历
前序遍历方式:对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印右子树。
我们先以递归的方式来思考整个遍历过程:
- 输出1,接着左孩子
- 输出2,接着左孩子
- 输出4,左孩子为空,右孩子为空,此时2的左子树全部输出,接着输出2的右子树
- 输出5,接着左孩子
- 输出8,左孩子为空,右孩子为空,此时1的左子树全部输出完了,接着输出1的右子树
- 输出3,接着左孩子
- 输出6,左孩子为空,右孩子为空,3的左子树全部输出完了,接着输出3的右子树
- 输出7,7的左孩子为空,右孩子为空,此时整个树输出完毕
递归代码比较简单,如下所示:
/**
* 前序遍历:
*
* 对于当前结点,先输出该结点,然后输出它的左孩子,最后输出它的右孩子
*/
/**
* 前序遍历(递归)
*
* @param node
*/
public void preOrderRec(Node node) {
if (node == null) {
return;
}
System.out.println(node); // 先输出该结点
preOrderRec(node.left); // 输出它的左孩子
preOrderRec(node.right); // 输出它的右孩子
}
对于非递归的实现来说,其实就是模拟上面递归入栈出栈过程,在写代码之前,我们先牢记前序遍历的原则:对于当前结点,先输出该结点,然后输出它的左孩子,最后输出它的右孩子。所以对任意节点,我们都可以先把它看成父结点,输出该结点后,我们需要先把右子树入栈,然后左子树入栈,然后重新循环即可。
好了,这里总结一下,主要有三个步骤:
- 先访问树的根节点
- 将右子孩子入栈
- 将左子孩子入栈
- 重复1, 2, 3步,直至栈为空
此时二叉树输出完毕,代码如下:
/**
* 先序遍历(非递归)<br/>
*
* <ul>
* <li>1. 先访问树的根节点</li>
* <li>2. 将右子孩子入栈</li>
* <li>3. 将左子孩子入栈</li>
* <li>4. 重复1, 2, 3步,直至栈为空</li>
* </ul>
*
* @param node
*/
public void preOrderNonRec(Node<E> node) {
if (node == null) {
return;
}
Stack<Node<E>> stack = new Stack<>();
stack.push(node);
while (!stack.isEmpty()) {
Node<E> eNode = stack.pop();
System.out.println(eNode);
if (eNode.getRight() != null) {
stack.push(eNode.getRight());
}
if (eNode.getLeft() != null) {
stack.push(eNode.getLeft());
}
}
}
中序遍历
中序遍历方式:对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印右子树。
我们先以递归的方式来思考整个遍历过程:
- 从1开始,遍历节点的左子树,遍历到4,4的左孩子为空,右孩子为空
- 输出4, 接着父结点
- 输出2,接着右孩子,不为空,遍历5的左子树,遍历到8,8的左孩子为空,右孩子为空
- 输出8,接着父结点
- 输出5,5的右结点为空,回到2,2的所有子树输出完毕,接着2的父结点
- 输出1,接着1的右孩子
- 遍历3的左子树,遍历到6,6的左孩子为空,右孩子为空
- 输出6,接着父结点
- 输出3,接着右孩子
- 输出7,7的左孩子为空,右孩子为空,此时整个树输出完毕
递归代码:
/**
* 中序遍历(递归)
*
* @param node
*/
public void inOrderRec(Node node) {
if (node == null) {
return;
}
inOrderRec(node.left);
System.out.println(node);
inOrderRec(node.right);
}
非递归逻辑就是用栈模拟上述递归调用的过程,经过前序非递归实现的思考过程,相信我们对于中序遍历的非递归实现已经胸有成竹了,下面还是仔细分析一波。我们还是牢记中序遍历的原则:对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印右子树。
对于任意节点都可以把它看成父结点,由于中序遍历是先输出结点的左子树,所以我们就可以遍历,将遍历的轨迹记录到栈内,直至结点为空,我们就可以写出如下代码(代码片段Ⅲ):
while (node != null) { // 判断当前结点点是否为空
stack.push(node); // 当前结点入栈
node = node.left; // 访问其左孩子
}
当遍历结束后,和前序遍历一样,也会出现两种情况:
- 当前结点的左孩子为空,但右孩子不为空
- 当前结点的左右孩子都为空
情况1如下图所示:
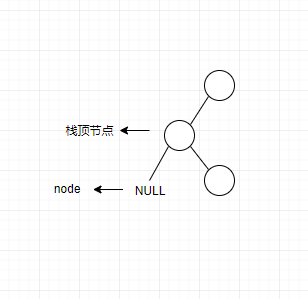
从上面图中可以看出,此时node指向为空,我们需要将栈顶元素出栈并赋值为node,此时node的左孩子为空,我们无法输出,所以我们就输出当前节点node,然后访问当前节点的右孩子,如果右孩子有左孩子,继续重复上面的步骤,代码(代码片段Ⅳ)如下:
node = stack.pop(); // 栈顶结点出栈
System.out.println(node); // 打印栈顶结点
node = node.right; // 访问其右孩子
情况2如下图所示:
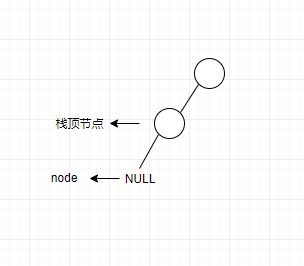
对于情况2,当访问的结点为空时,我们就和情况1一样将栈顶元素出栈并赋值给node,将其输出,接着我们访问当前节点node的右孩子,发现右孩子为空,此时该怎么办呢?有了前序遍历的经验,我们继续将栈顶元素出栈,并赋值给node,注意此时node的左子树输出完毕了,输出该节点,继续访问node的右孩子:
node = stack.pop(); // 栈顶结点出栈
System.out.println(node); // 打印栈顶结点
node = node.right; // 访问其右孩子
node = stack.pop(); // 右孩子为空,栈顶元素继续出栈
System.out.println(node); // 打印栈顶元素
node = node.right; // 继续访问其右孩子
我檫,我们又发现重复,根据我们的经验,凡是重复的代码都不是最优代码,其实造成重复的原因是当前节点的右孩子为空,没法继续访问了,只能继续将栈顶结点出栈,此时的栈顶的结点的左子树已经输出完了,输出自己后,再访问其右孩子。这个判空在代码片段Ⅲ中。
好了,不分析了,此时我们可以写出如下代码:
while (node != null || !stack.isEmpty()) {
while (node != null) {
stack.push(node);
node = node.left;
}
node = stack.pop();
System.out.println(node);
node = node.right;
}
总结一下,考虑以下三点:
- 对于任何结点node,如果该结点不为空,将当前结点的左子结点赋值给node,直至node为null
- 若左子结点为空,栈顶结点出栈,输出该结点后将该结点的右子结点赋值给node
- 重复1,2操作
代码如下:
/**
* 中序遍历(非递归)
*
* <ul>
* <li>1. 对于任何结点node,如果该结点不为空,将当前结点的左子结点赋值给node,直至node为null</li>
* <li>2. 若左子结点为空,栈顶节点出栈,输出该结点后将该结点的右子结点置为node</li>
* <li>3. 重复1,2操作</li>
* </ul>
*
* @param node
*/
public void inOrderNonRec(Node node) {
if (node == null) {
return;
}
Stack<Node> stack = new Stack<>();
stack.push(node);
node = node.left;
while (node != null || !stack.isEmpty()) {
while (node != null) {
stack.push(node);
node = node.left;
}
node = stack.pop();
System.out.println(node);
node = node.right;
}
}
后序遍历
后序遍历:对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印它本身。
我们先以递归的方式来思考整个遍历过程:
- 从1开始,遍历节点的左子树,遍历到4,4的左孩子为空,右孩子为空
- 输出4, 接着寻找2的右子树,找到5
- 遍历5的左子树,遍历到8,8的的左孩子为空,右孩子为空
- 输出8,寻找5的右孩子,发现为空,接着父结点
- 输出5,接着5的父结点2,2的左右子树输出完毕
- 输出2,接着2的父结点,此时2的左子树输出完毕,接着2的右子树,找到3
- 遍历3的左子树,找到6,6的左孩子为空,右孩子为空
- 输出6,接着3的右孩子
- 输出7,接着7的父结点
- 输出3,接着3的父结点,此时1的左右子树输出完毕
- 输出1,此时整个树输出完毕
递归代码非常简单,如下代码:
/**
* 后序遍历(递归)
*
* @param node
*/
public void postOrderRec(Node node) {
if (node == null) {
return ;
}
postOrderRec(node.left);
postOrderRec(node.right);
System.out.println(node);
}
** 非递归实现是比上面前中非递归遍历要复杂一点,现在还是考虑后序遍历的原则:对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印它本身。**
对于任意结点,总是先遍历其左孩子,再遍历右孩子,最后再遍历父结点,仔细思考这个过程和前中遍历有什么不同呢?对于前序遍历,父结点首先被访问到;对于中序遍历,当访问完左孩子,就可以访问父结点了;对于后序遍历,访问完左孩子,要去访问右孩子,注意,此时这个右孩子如果还有左孩子,那么还要继续遍历下去。说到这里我们就知道问题了,最初左孩子的父结点啥时候访问呢?就是最初的右孩子的左右子树都访问完了,再访问这个右孩子,最后才会访问到这个父结点。
所以根据以上分析,我们需要判断上次访问的结点是位于左子树,还是右子树。如果是左子树,那么需要跳过父结点,去访问右孩子;如果上次是访问的右孩子,我们就可以访问父结点了。
总结来说,对于任意结点,只有它既没有左孩子也没有右孩子或者它有孩子但是它的孩子已经被输出,才会输出这个结点,所以我们可以整一个变量(pre)来记录上次访问的是哪一个结点。若非上述两种情况,则将该结点的右孩子和左孩子依次入栈,这样就保证了每次取栈顶元素的时候, 先依次遍历左子树和右子树。代码如下:
if ((node.left == null && node.right == null) ||
(node.right == null && pre == node.left) || (pre == node.right)) {
System.out.println(node);
pre = node;
stack.pop();
} else {
// 右孩子先入栈,才会先访问结点的左孩子
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
总结以上,pre首先赋初值为二叉树的根结点,栈初始值也为二叉树的根结点,所以在栈不为空的情况下,进行以上判断操作。所以完整代码如下:
/**
* 后序遍历(非递归)
*
* 对于结点node,可分三种情况考虑:
*
* 1. node如果是叶子结点,直接输出
* 2. node如果有孩子,且孩子没有被访问过,则按照右孩子,左孩子的顺序依次入栈
* 3. node如果有孩子,而且孩子都已经访问过,则访问node节点
*
* 注意结点的右孩子先入栈,左孩子再入栈,这样才会先访问左孩子
*
* @param node
*/
public void postOrderNonRec(Node node) {
if (node == null) {
return ;
}
Stack<Node> stack = new Stack<>();
Node pre = root;
stack.push(node);
while (!stack.isEmpty()) {
node = stack.peek();
if ((node.left == null && node.right == null) ||
(node.right == null && pre == node.left) || (pre == node.right)) {
System.out.println(node);
pre = node;
stack.pop();
} else {
// 右孩子先入栈,才会先访问结点的左孩子
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
}
}
层次遍历
所谓层次遍历就是按照二叉树中的层的概念一层一层地从左往右遍历,比如就拿我们最初给出的二叉树例子,首先访问1,接着访问第二层,输出2,3,接着访问第三层,输出4,5,6,7,最后输出8。我们仔细观察发现,它们是依次入队的,所以我们可以利用队列来实现层次遍历,比较简单,就不分析了,下面是代码:
/**
* 层次遍历
*
* @param node 根结点
*/
public void levelTraverse(Node node) throws InterruptedException {
if(node == null) {
return;
}
BlockingQueue<Node> queue = new LinkedBlockingQueue<>();
queue.add(node);
while (!queue.isEmpty()) {
Node item = queue.take();
System.out.println(item);
if (item.left != null) {
queue.add(item.left);
}
if (item.right != null) {
queue.add(item.right);
}
}
}
计算二叉树的深度
现在我们知道二叉树结点的最大层次称为树的深度,所以我们只需计算树中结点的层次最大值。根结点的深度为1,根结点的左孩子深度为2,右孩子深度也为2,注意此时左右孩子当有一个为空时,此时当前结点所在的层次以存在的结点为值,就这样一直向下遍历,计数递增,直至结点的左右孩子都为空。所以可以用递归求解:
递归公式如下:
getDepth(node) = getDepth(node.left) > getDepth(node.right) ? getDepth(node.left) + 1 : getDepth(node.right) + 1
递归终止条件:
if (node == null) return 0;
代码如下:
/**
* 计算二叉树的深度
* @param node 当前结点点
* @return 二叉树的深度
*/
public int getDepth(Node node) {
if (node == null)
return 0;
int m = getDepth(node.left);
int n = getDepth(node.right);
return m > n ? m + 1 : n + 1;
}
计算二叉树的结点数量
在二叉树中,任意结点的总结点数量包括其左子树的节点的数量和右子树的节点情况和其自身,所以直接用递归求解:
递归公式如下:
countNode(node) = countNode(node.left) + countNode(node.right) + 1
递归终止条件:
if (node == null) return 0;
代码如下:
/**
* 计算结点的数量
*
* @param node 当前结点
* @return 结点的数量
*/
public int countNode(Node node) {
if (node == null)
return 0;
return countNode(node.left) + countNode(node.right) + 1;
}
计算二叉树的叶子结点数量
所谓叶子结点,就是它的度是0,没有左子树和右子树,所以这是计算叶子结点的条件,也是表示叶子结点的关键。我们依然可以用递归来解:
递归公式:
countLeafNode(node) = countLeafNode(node.left) + countLeafNode(node.right)
终止条件有两个:
- 当前结点为空,返回0;
- 当前结点的左孩子和右孩子都为空,代表是叶子结点,返回1。
if (node == null)
return 0;
if (node.left == null && node.right == null) {
return 1;
}
代码如下:
/**
* 计算叶子结点的数量
*
* @param node 当前结点
* @return 结点的数量
*/
public int countLeafNode(Node node) {
if (node == null)
return 0;
if (node.left == null && node.right == null) {
return 1;
}
return countLeafNode(node.left) + countLeafNode(node.right);
}
计算二叉树第k层结点的数量
对于二叉树,我们怎么样知道处于某一层的结点的总数量呢?举个例子,就拿上面我们使用的二叉树来说,想知道第三层结点的总数量,我们只要知道第二层所有结点的左右孩子数量之和,这个值不就是第三层结点的数量吗?(我真是太聪明了),依次类推,直至到根结点,为第一层,结点数量为1。所以我们可以用递归来解决:
递归公式:
countKLevelNode(node, k) = countKLevelNode(node.left, k - 1) + countKLevelNode(node, k - 1)
终止条件:
当为第一层时,只有一个根结点,返回1。
if (k == 1) {
return 1;
}
代码如下:
/**
* 获取二叉树第k层结点的数量
*
* @param node 根结点
* @param k 第k层
* @return 结点的数量
*/
public int countKLevelNode(Node node, int k) {
if (node == null || k <= 0) {
return 0;
}
if (k == 1) {
return 1;
}
return countKLevelNode(node.left, k - 1) + countKLevelNode(node.right, k - 1);
}
对于非递归算法,我们可以采用层次遍历的方式来遍历二叉树,只不过有一个问题需要解决,就是如何标识每一层呢?就是在代码中,我们如何知道队列中的元素正好是某一层的结点呢?所以我们需要有一个计数器,来记录当前层结点的数目,对于层次遍历而言,由于层次遍历就是一层一层依次入队的,我们只要保证在计算层次之前,当前队列里的结点是该层的全部结点即可。代码如下:
/**
* 获取二叉树第k层结点的数量 - 非递归
*
* @param node 根结点
* @param k 第k层
* @return 结点的数量
*/
public int countKLevelNodeNonRec(Node node, int k) throws InterruptedException {
if(node == null) {
return 0;
}
int level = 0; // 当前层计数器
int cntNode = 0; // 当前层节点数计数器
int curLevelNodesTotal = 0; // 当前层节点总数
BlockingQueue<Node> queue = new LinkedBlockingQueue<>();
queue.add(node);
while (!queue.isEmpty()) {
++level;
cntNode = 0; // 当前层节点数计数器归0
curLevelNodesTotal = queue.size();// 当前层的节点总数
if (level == k)// 如果层数已等于指定层数,则退出
break;
while (cntNode < curLevelNodesTotal) {
++cntNode;// 记录当前层的节点数
node = queue.take();
// 将当前层节点的左右结点均入队,即将下一层节点入队
if(node.left != null)
queue.add(node.left);
if(node.right != null)
queue.add(node.right);
}
}
while(!queue.isEmpty())
queue.clear();//清空队列
if(level == k)
return curLevelNodesTotal;
return 0;
}
计算二叉树第k层叶子结点的数量
上面为什么要用非递归算法来计算二叉树第k层结点的数量 呢?费了老大劲,主要是为计算二叉树第k层叶子结点的数量提供思路。正如前面所说,我们可以提供一个计算器来统计该层结点的数量,如果可以精确到具体层的具体结点,那么这个计算过程就没有难度了,在到达当前层时,只需要将该层遍历,将叶子结点筛选出来(所谓叶子结点就是没有左右子树的结点),统计下其数量即可,这个算法和非递归算法来计算二叉树第k层结点的数量算法只是增加了统计指定层叶子结点的过程,无须赘述。
/**
* 获取二叉树第k层叶子结点的个数
*
* @param node 根结点
* @param k 第k层
* @return 结点的数量
*/
public int countKLevelLeafNode(Node node, int k) throws InterruptedException {
if(node == null) {
return 0;
}
int level = 0; //当前层计数器
int cntNode = 0; //当前层节点数计数器
int curLevelNodesTotal = 0; //当前层节点总数
BlockingQueue<Node> queue = new LinkedBlockingQueue<>();
queue.add(node);
while (!queue.isEmpty()) {
++level;
cntNode = 0; //当前层节点数计数器归0
curLevelNodesTotal = queue.size();//当前层的节点总数
// 如果层数等于指定层数,遍历该层的结点,判断叶子结点
if(level == k) {
int leafCount = 0;
while(!queue.isEmpty()) {
node = queue.take();
if (node.left == null && node.right == null) {
++leafCount;
}
}
return leafCount;
}
while (cntNode < curLevelNodesTotal) {
++cntNode;//记录当前层的节点数
node = queue.take();
//将当前层节点的左右结点均入队,即将下一层节点入队
if(node.left != null)
queue.add(node.left);
if(node.right != null)
queue.add(node.right);
}
}
return 0;
}
判断一个结点是否在二叉树内
对于一个给定的二叉树,如何判断一个结点是否在二叉树内,相对来说比较简单,因为对于二叉树的任意结点,都可以把其当做父结点,先判断结点是否与该结点相同,如果不同,再判断其左右孩子,依次类推,所以我们又可以用递归了。
递归公式:
isNodeInTree(root, node) = (root != node) -> (!isNodeInTree(root.left, node)) -> (isNodeInTree(root.right, node))
终止条件有两个:
- 检测的结点与父结点相等
- 检测的结点与左孩子或者右孩子相等
if (root.item == node.item) {
return true;
}
if (isNodeInTree(root.left, node) || isNodeInTree(root.right, node)) {
return true;
}
递归代码:
/**
* 判断一个结点是否在二叉树内
*
* @param root 根结点
* @param node 要检测的结点
* @return 返回{@code true},在;返回{@code false},不在
*/
public boolean isNodeInTree(Node root, Node node) {
if (root == null || node == null) {
return false;
}
if (root.item == node.item) {
return true;
}
if (isNodeInTree(root.left, node) || isNodeInTree(root.right, node)) {
return true;
}
return false;
}
获取一个结点的父结点
对于一个任意二叉树,如果结点中没有记录当前结点的父结点,我们就无非直接知道一个结点的父结点了,所以我们需要采取遍历的方式来查找:
/**
* 获取给定结点的父结点
*
* @param root 根结点
* @param curr 给定结点
* @return 给定结点的父结点
*/
public Node getParent(Node root, Node curr) {
if (root == null || curr == null) {
return null;
}
if (root == curr) {
return null;
}
Stack<Node> stack = new Stack<>();
stack.push(root);
root = root.left;
while (root != null || !stack.isEmpty()) {
while (root != null) {
if (root.left.item == curr.item || root.right.item == curr.item) {
return root;
}
stack.push(root); // 入栈
root = root.left; // 遍历左孩子
}
root = stack.pop();
root = root.right;
}
return null;
}
求二叉树镜像
对于二叉树的任意结点,如果我们让它们的左右孩子交换,最终得出的新二叉树就是原二叉树的镜像。下面是个例子:
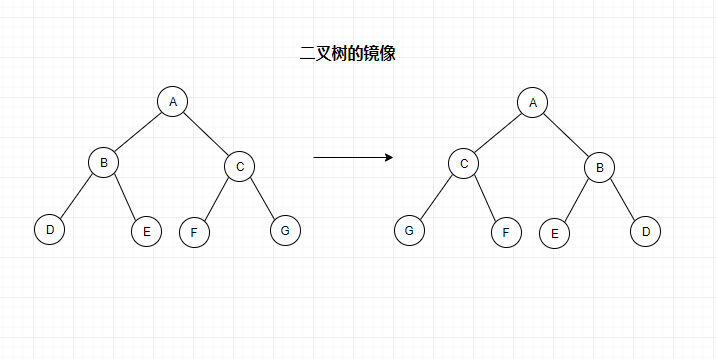
这个比较简单,因为我们前面说过,对于任意结点,都可以看成父结点,所以我们用递归解决即可:
递归公式:
mirror(node) = (node.left = node.right) -> (node.right = node.left) -> mirror(node.left) -> mirror(node.right)
终止条件:
if (node == null) return;
递归代码:
/**
* 二叉树的镜像 - 递归
*
* @param node 根结点
*/
public void mirrorRec(Node node) {
if (node == null) {
return;
}
// 交换左右子树
Node temp = node.left;
node.left = node.right;
node.right = temp;
// 对交换后的左右子树继续进行镜像处理
mirrorRec(node.left);
mirrorRec(node.right);
}
对于非递归来求解,也是十分简单的,只要前面我们学会如何使用非递归遍历二叉树,这里直接拿到用就可以了,下面采用先序遍历来获取二叉树的镜像:
/**
* 二叉树的镜像 - 非递归,采用先序遍历
*
* @param node 根结点
*/
public void mirrorNonRec(Node node) {
if (node == null) {
return;
}
// 交换左右子树
swap(node);
Stack<Node> stack = new Stack<>();
stack.push(node);
node = node.left;
while (node != null || !stack.isEmpty()) {
while (node != null) {
// 交换左右子树
swap(node);
stack.push(node); // 入栈
node = node.left; // 遍历左孩子
}
node = stack.pop();
node = node.right;
}
}
private void swap(Node node) {
// 交换左右子树
Node temp = node.left;
node.left = node.right;
node.right = temp;
}
求两个结点的最低公共祖先结点
最低公共祖先,即LCA(Lowest Common Ancestor),依下面的图为例,4和8的LCA为2,4和7的LCA为1:
常规二叉树
对于常见的二叉树来说,假设二叉树的结点没有保存父结点的引用,即给定一个结点不能直接直到它的父结点是谁,这时我们需要从根结点开始找起。对于任意二叉树,两个结点的最低公共祖先结点有以下特性:
- 如果一个结点为根结点,它们的最低公共祖先为根结点;
- 如果一个结点在(根结点来说)左树,另一个结点在右树,那么它的最低公共祖先一定是根节点;
- 如果两个结点都在左树,在左树查找;
- 如果两个结点都在右树,在右树查找。
递归公式:
findLCA(root, node1, node2) = findLCA(root.left, node1, node2) == null => findLCA(root.right, node1, node2)
终止条件:
if (root == null) {
return null;
}
if (node1 == root || node2 == root) {
return root;
}
代码:
/**
* 最低公共祖先,即LCA(Lowest Common Ancestor),此种情况假设节点没有父结点的指针
*
*
* @param root 根结点
* @param node1 节点1
* @param node2 节点2
* @return 最低公共祖先
*/
public Node findLCA(Node root, Node node1, Node node2) {
if (root == null) {
return null;
}
// 判断两个节点有没有与根结点相等
if (node1 == root || node2 == root) {
return root;
}
Node temp1 = findLCA(root.left, node1, node2); // 左子树
Node temp2 = findLCA(root.right, node1, node2); // 右子树
if (temp1 != null && temp2 != null) { // 左右子树都不为空,那么它的最低公共祖先一定是根节点
return root;
}
return temp1 != null ? temp1 : temp2; // 判断在左子树还是右子树
}
二叉树的结点保存父结点的引用
现在假设二叉树的任何结点都保存有父结点的引用,此时我们就不必再从根结点开始进行查找了,我们可以通过当前结点来获取该结点的父结点,存入到链表中,一直遍历到根结点为止,对于另一个结点也是如此操作,这样就形成了两个链表,接下来我们只需寻找这两个链表第一个相同的元素即可,该值就是LCA。代码如下:
/**
* 最低公共祖先,即LCA(Lowest Common Ancestor),此种情况假设节点拥有父结点的指针
*
*
* @param root 根结点
* @param node1 节点1
* @param node2 节点2
* @return 最低公共祖先
*/
public Node findLCA2(Node root, Node node1, Node node2) {
if (root == null) {
return null;
}
if (node1 == root || node2 == root) {
return root;
}
List<Node> queue1 = new LinkedList<>();
while (node1.parent != null) {
node1 = node1.parent;
queue1.add(node1);
}
List<Node> queue2 = new LinkedList<>();
while (node2.parent != null) {
node2 = node2.parent;
queue2.add(node2);
}
for (int i = 0; i < queue1.size(); i++) {
for (int j = 0; j < queue1.size(); j++) {
if (queue1.get(i) == queue2.get(j)) {
return queue1.get(i);
}
}
}
return null;
}
References:
- 严蔚敏,《数据结构(C语言)第二版》
- 二叉树基础(上):什么样的二叉树适合用数组来存储?
- 二叉树的各种操作
- 二叉树的后序遍历--非递归实现
- 二叉树前序、中序、后序遍历非递归写法的透彻解析
- 二叉树系列 - 求两节点的最低公共祖先
- 关于快慢指针的若干应用详解
- 二叉树的层次遍历+每一层单行输出
title: 二叉树概念和操作
tags: [数据结构, 二叉树]
author: Mingshan
categories: [数据结构, 二叉树]
date: 2019-03-17
mathjax: true
本文来自博客园,作者:mingshan,转载请注明原文链接:https://www.cnblogs.com/mingshan/p/17793504.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号