数据采集作业3
gitee链接:作业3_wzm
作业①: 使用Scrapy爬取中国气象网的图片
本次作业的目标是使用Scrapy框架,从中国气象网(http://www.weather.com.cn)爬取图片。要求实现单线程和多线程的爬取方式,并对爬取的页面数和下载的图片数量进行限制,避免对目标网站造成过大压力。
项目结构
项目结构如下:
weather_images/
├── images/ # 存储下载的图片
│ └── full/ # 图片下载后的实际存储位置
├── weather_images/ # Scrapy 项目文件夹
│ ├── spiders/ # 爬虫文件夹
│ │ ├── __init__.py # Spiders模块的初始化文件
│ │ └── weather_spider.py # 主要爬虫代码
│ ├── __init__.py # 项目初始化文件
│ ├── items.py # 定义数据模型
│ ├── middlewares.py # 中间件配置
│ ├── pipelines.py # 管道配置,用于处理下载图片
│ └── settings.py # Scrapy配置文件
└── scrapy.cfg # Scrapy全局配置文件
各文件的作用
-
images: 用于存储爬取到的图片,
full文件夹内保存所有下载完成的图片。 -
weather_images: Scrapy项目的主文件夹,包含爬虫和项目配置。
-
spiders: 该文件夹包含所有的爬虫文件。每个爬虫文件是一个Python脚本,定义了爬取逻辑。
- weather_spider.py: 此文件是核心的爬虫代码,定义了爬虫类
WeatherSpider,并包含具体的图片爬取逻辑。
- weather_spider.py: 此文件是核心的爬虫代码,定义了爬虫类
-
items.py: 定义了爬取到的图片的模型
WeatherImagesItem,包括图片URL等信息。 -
middlewares.py: 配置和定义了Scrapy中间件,通常用于请求和响应的自定义处理。
-
pipelines.py: 设置数据处理管道,负责将爬取到的数据(图片URL)进行处理并下载到指定路径。
-
settings.py: Scrapy的配置文件,用于设置项目参数,比如并发数量、下载延时等,可以在此处调整设置以实现单线程或多线程爬取。
-
-
scrapy.cfg: Scrapy的全局配置文件,用于定义项目的基本信息和默认设置。
主要爬虫代码
以下是 weather_spider.py 的详细代码,用于从目标网站爬取图片,并控制最大下载图片数量和最大爬取页面数。
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from weather_images.items import WeatherImagesItem
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn'] # 起始页面
image_count = 0
max_images = 105 # 最大下载图片数量
max_pages = 5 # 最大爬取页面数>
def parse(self, response):
if self.image_count < self.max_images:
# 提取当前页面所有图片的URL
for img in response.css('img::attr(src)').getall():
if self.image_count < self.max_images:
image_url = response.urljoin(img) # 拼接完整URL
self.image_count += 1
yield WeatherImagesItem(image_urls=[image_url])
self.log(f'Downloading image: {image_url}')
else:
break
# 继续爬取下一页
next_page = response.css('a.next::attr(href)').get()
if next_page and self.image_count < self.max_images:
next_page_url = response.urljoin(next_page)
yield scrapy.Request(next_page_url, callback=self.parse)
代码说明
- start_urls: 定义了爬虫的起始页面,爬虫从此页面开始进行爬取。
- image_count 和 max_images:
image_count用于记录当前已下载的图片数量,max_images=105则设定了最大下载数量。 - max_pages: 设置最大爬取页面数为5页,避免无限制地抓取。
- parse方法: 此方法定义了爬取和解析逻辑,使用CSS选择器提取页面中所有的图片URL,并加入下载队列。
- next_page: 如果存在下一页链接,则继续发送请求,以递归方式爬取指定页面数量。
下载图片的处理管道 (pipelines.py)
在 pipelines.py 中,我们配置了 ImagesPipeline 管道,用于处理图片的下载。
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy import Request
class WeatherImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Image Downloaded Failed")
item['image_paths'] = image_paths
return item
代码说明
- get_media_requests: 从
item中获取图片的URL并发送请求。 - item_completed: 检查下载是否成功,如果成功则保留图片路径,否则丢弃该
item。
输出信息
爬虫运行时,会在控制台输出每张图片的下载URL,示例信息如下:
Downloading image: http://www.weather.com.cn/path/to/image1.jpg
Downloading image: http://www.weather.com.cn/path/to/image2.jpg
...
下载的图片存储路径
下载的图片会存储在 images/full 文件夹中。以下是下载后的文件夹截图:

配置单线程和多线程爬取
可以通过修改 settings.py 中的 CONCURRENT_REQUESTS 参数来控制单线程和多线程爬取:
-
单线程:将
CONCURRENT_REQUESTS设置为1。CONCURRENT_REQUESTS = 1 DOWNLOAD_DELAY = 1 # 延迟设置 -
多线程:增大
CONCURRENT_REQUESTS的值(例如CONCURRENT_REQUESTS = 16),并根据需要调整DOWNLOAD_DELAY。
项目代码和文件存储链接
您可以在 Gitee 上查看完整的项目代码和图片存储:Gitee 项目链接
通过本次作业,实现了对中国气象网图片的爬取,并通过Scrapy设置了爬取页面数和图片数量的限制,确保在合规范围内进行数据采集。这种方法不仅适用于天气网站,还可以应用到其他图片资源丰富的站点,为进一步的数据分析和研究提供了数据支持。
作业②: 使用 Scrapy + MySQL 爬取东方财富网股票数据
本次作业的目标是熟练掌握 Scrapy 的 Item、Pipeline 以及数据存储的序列化输出方法,爬取东方财富网的股票相关信息,并将数据存储到 MySQL 数据库中。
项目结构
项目的基本目录结构如下:
stock_spider/
├── scrapy.cfg # Scrapy 全局配置文件
├── stock_spider/ # Scrapy 项目文件夹
│ ├── __init__.py # 初始化文件
│ ├── items.py # 定义爬取的数据结构
│ ├── middlewares.py # 中间件配置
│ ├── pipelines.py # 数据管道,处理并存储数据
│ ├── settings.py # Scrapy 项目配置
│ └── spiders/ # 爬虫文件夹
│ ├── __init__.py # 初始化文件
│ └── stock_spider.py # 核心爬虫代码
功能描述
目标是爬取东方财富网股票信息,包括以下字段:
- 股票代码
- 股票名称
- 最新报价
- 涨跌幅
- 涨跌额
- 成交量
- 成交额
- 振幅
数据存储在 MySQL 数据库中,表的字段如下:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| 最新报价 | DOUBLE | 股票当前价格 |
| 涨跌幅 | DOUBLE | 涨跌的百分比 |
| 涨跌额 | DOUBLE | 涨跌的金额 |
| 成交量 | DOUBLE | 交易量 |
| 成交额 | DOUBLE | 交易金额 |
| 振幅 | DOUBLE | 振幅百分比 |
| 股票代码 | VARCHAR | 股票代码 |
| 股票名称 | VARCHAR | 股票名称 |
代码实现
1. items.py 文件
定义数据结构 StockItem,存储爬取的数据字段:
import scrapy
class StockItem(scrapy.Item):
股票代码 = scrapy.Field()
股票名称 = scrapy.Field()
最新报价 = scrapy.Field()
涨跌幅 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量 = scrapy.Field()
成交额 = scrapy.Field()
振幅 = scrapy.Field()
2. spiders/stock_spider.py 文件
爬取股票数据的核心爬虫代码:
import scrapy
import json
from stock_spider.items import StockItem
class StockSpider(scrapy.Spider):
name = "stock_spider"
start_urls = [
'http://25.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&fields=f2,f3,f4,f5,f6,f7,f12,f14'
]
def parse(self, response):
# 解析 JSON 数据
data = json.loads(response.text)
stock_list = data.get('data', {}).get('diff', [])
for stock in stock_list:
item = StockItem(
股票代码=stock.get('f12'),
股票名称=stock.get('f14'),
最新报价=stock.get('f2'),
涨跌幅=stock.get('f3'),
涨跌额=stock.get('f4'),
成交量=stock.get('f5'),
成交额=stock.get('f6'),
振幅=stock.get('f7'),
)
yield item
3. pipelines.py 文件
将爬取的数据存储到 MySQL 数据库:
import pymysql
class StockPipeline:
def open_spider(self, spider):
# 连接 MySQL 数据库
self.connection = pymysql.connect(
host='localhost',
user='root',
password='your_password',
database='stock_db',
charset='utf8'
)
self.cursor = self.connection.cursor()
# 创建数据表
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
股票代码 VARCHAR(12) PRIMARY KEY,
股票名称 VARCHAR(32),
最新报价 DOUBLE,
涨跌幅 DOUBLE,
涨跌额 DOUBLE,
成交量 DOUBLE,
成交额 DOUBLE,
振幅 DOUBLE
)
""")
def process_item(self, item, spider):
# 插入数据到表
self.cursor.execute("""
INSERT INTO stocks (
股票代码, 股票名称, 最新报价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
最新报价=VALUES(最新报价),
涨跌幅=VALUES(涨跌幅),
涨跌额=VALUES(涨跌额),
成交量=VALUES(成交量),
成交额=VALUES(成交额),
振幅=VALUES(振幅)
""", (
item['股票代码'], item['股票名称'], item['最新报价'], item['涨跌幅'], item['涨跌额'],
item['成交量'], item['成交额'], item['振幅']
))
self.connection.commit()
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.connection.close()
4. settings.py 文件
配置 Scrapy 项目和 Pipeline:
BOT_NAME = 'stock_spider'
SPIDER_MODULES = ['stock_spider.spiders']
NEWSPIDER_MODULE = 'stock_spider.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'stock_spider.pipelines.StockPipeline': 300,
}
LOG_LEVEL = 'INFO'
运行项目
-
启动 MySQL 数据库:
确保数据库已创建:CREATE DATABASE stock_db; -
运行 Scrapy 爬虫:
在项目目录下执行命令:scrapy crawl stock_spider
输出结果
爬取的数据会存储在 MySQL 数据库 stock_db 的 stocks 表中,运行以下 SQL 查询查看结果:
SELECT * FROM stocks LIMIT 10;
输出如下:

常见问题及解决方案
-
MySQL 数据库连接失败:
- 确保数据库已启动。
- 检查用户名、密码和数据库名称是否正确。
-
爬取被 robots.txt 限制:
- 在
settings.py中设置ROBOTSTXT_OBEY = False。
- 在
通过本次作业,学习了如何使用 Scrapy 爬取东方财富网的股票信息,并将数据存储到 MySQL 数据库中。这种方法可以进一步扩展,用于实时更新和分析股票数据。
作业③:使用 Scrapy + XPath + MySQL 爬取中国银行外汇数据
本次作业目标是熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法,爬取中国银行外汇页面(中国银行外汇牌价),提取外汇汇率数据并存储到 MySQL 数据库中。
项目结构
项目的基本目录结构如下:
boc_exchange/
├── boc_exchange/ # Scrapy项目文件夹
│ ├── spiders/ # 爬虫文件夹
│ │ ├── __init__.py # 爬虫模块初始化文件
│ │ └── boc_spider.py # 核心爬虫代码
│ ├── __init__.py # Scrapy项目初始化文件
│ ├── items.py # 定义数据结构
│ ├── pipelines.py # 数据存储逻辑
│ ├── settings.py # Scrapy配置文件
├── scrapy.cfg # Scrapy全局配置文件
需求分析
爬取外汇汇率数据,并存储到数据库。目标字段如下:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| Currency | VARCHAR | 货币名称 |
| TBP (现汇买入价) | DOUBLE | 汇率 |
| CBP (现钞买入价) | DOUBLE | 汇率 |
| TSP (现汇卖出价) | DOUBLE | 汇率 |
| CSP (现钞卖出价) | DOUBLE | 汇率 |
| Time | VARCHAR | 更新时间 |
代码实现
1. items.py
定义数据模型 Work3Item,用于存储爬取到的外汇数据:
import scrapy
class Work3Item(scrapy.Item):
Currency = scrapy.Field() # 货币名称
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 更新时间
2. spiders/boc_spider.py
编写爬虫逻辑,从目标网页中提取汇率数据:
import scrapy
from boc_exchange.items import Work3Item
class BocSpider(scrapy.Spider):
name = "boc_spider"
allowed_domains = ["boc.cn"]
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 定位数据表格中的行,跳过第一行表头
rows = response.xpath('//table[@align="left"]//tr[position()>1]')
for row in rows:
item = Work3Item()
item['Currency'] = row.xpath('./td[1]/text()').get()
item['TBP'] = row.xpath('./td[2]/text()').get()
item['CBP'] = row.xpath('./td[3]/text()').get()
item['TSP'] = row.xpath('./td[4]/text()').get()
item['CSP'] = row.xpath('./td[5]/text()').get()
item['Time'] = row.xpath('./td[last()]/text()').get()
yield item
3. pipelines.py
将爬取到的数据存储到 MySQL 数据库中:
import pymysql
class Work3Pipeline:
def open_spider(self, spider):
# 连接数据库
try:
self.db = pymysql.connect(
host='127.0.0.1',
user='root',
password='your_password',
database='exchange_rates',
charset='utf8mb4'
)
self.cursor = self.db.cursor()
self._create_table()
except pymysql.MySQLError as e:
spider.logger.error(f"Database connection failed: {e}")
def _create_table(self):
# 创建表
try:
self.cursor.execute("DROP TABLE IF EXISTS rates")
self.cursor.execute("""
CREATE TABLE rates (
Currency VARCHAR(50),
TBP VARCHAR(20),
CBP VARCHAR(20),
TSP VARCHAR(20),
CSP VARCHAR(20),
Time VARCHAR(50)
)
""")
except pymysql.MySQLError as e:
print(f"Table creation error: {e}")
def process_item(self, item, spider):
# 插入数据
try:
self.cursor.execute("""
INSERT INTO rates (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
item['Currency'], item['TBP'], item['CBP'], item['TSP'], item['CSP'], item['Time']
))
self.db.commit()
except pymysql.MySQLError as e:
spider.logger.error(f"Failed to insert item: {e}")
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.db.close()
4. settings.py
配置 Scrapy 项目参数:
BOT_NAME = 'boc_exchange'
SPIDER_MODULES = ['boc_exchange.spiders']
NEWSPIDER_MODULE = 'boc_exchange.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'INFO'
# 配置 Pipeline
ITEM_PIPELINES = {
'boc_exchange.pipelines.Work3Pipeline': 300,
}
操作步骤
第一步:创建 Scrapy 项目
在命令行中运行以下命令,创建 Scrapy 项目:
scrapy startproject boc_exchange
第二步:定义数据库
登录 MySQL,创建数据库:
CREATE DATABASE exchange_rates;
第三步:编写代码
将上述代码保存到项目的对应文件中:
items.pyspiders/boc_spider.pypipelines.pysettings.py
第四步:运行爬虫
进入项目根目录,运行以下命令启动爬虫:
scrapy crawl boc_spider
第五步:查看数据
爬虫运行完成后,登录 MySQL 数据库,查询爬取到的数据:
USE exchange_rates;
SELECT * FROM rates;
数据输出
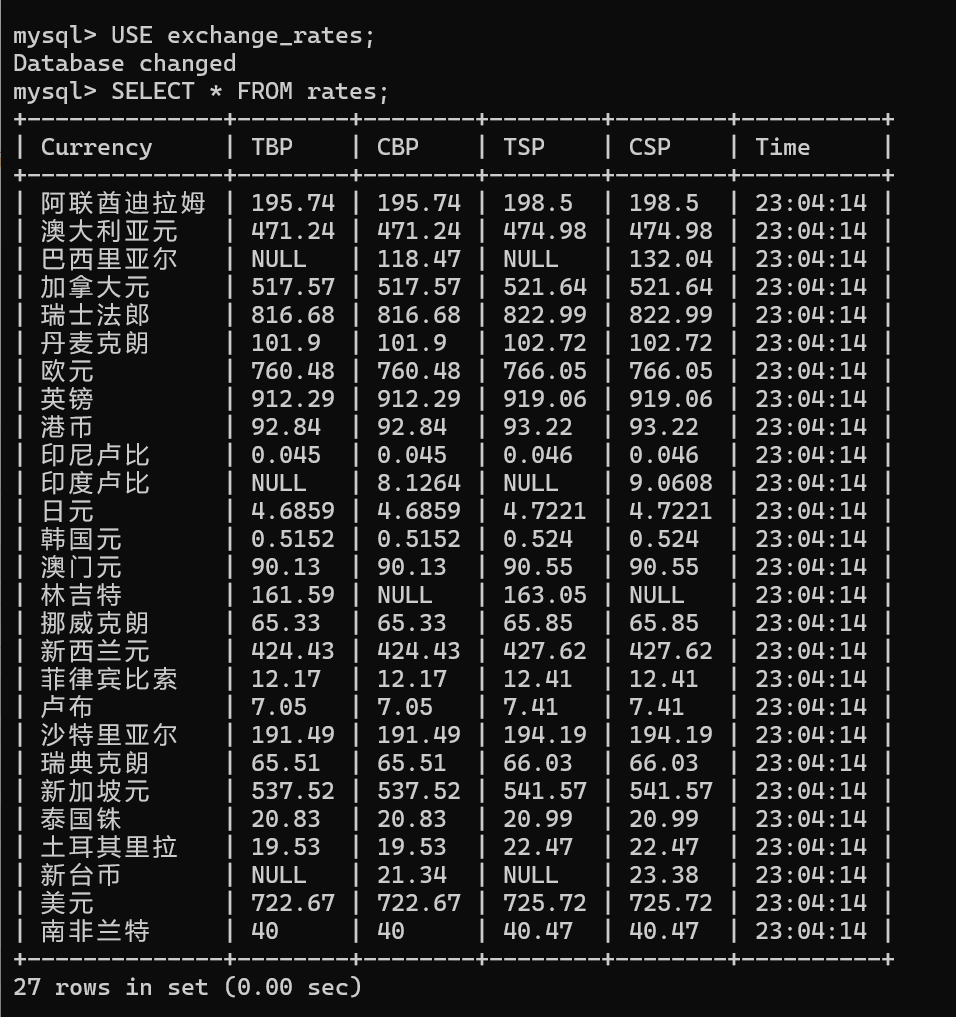
优化点
-
防止重复插入:
可以在数据库表中为Currency字段添加主键或唯一约束,并在插入时使用ON DUPLICATE KEY UPDATE。ALTER TABLE rates ADD UNIQUE (Currency); -
动态调整爬取范围:
通过传递 URL 参数控制爬取的范围或实时性。
通过本次作业,实现了从中国银行外汇牌价页面爬取汇率数据,并将其存储到 MySQL 数据库中。这种方法可以进一步扩展,用于实时监控外汇汇率数据,为数据分析和金融研究提供支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号