TRUST REGION POLICY OPTIMISATION IN MULTI-AGENT REINFORCEMENT LEARNING (HAPPO)
TRUST REGION POLICY OPTIMISATION IN MULTI-AGENT REINFORCEMENT LEARNING (HAPPO)
2109.11251
ICLR 2022
摘要:
作者说信任域方法带来的单调策略改进在MARL里不能简单适用。作者说本文发现的中心内容是multi-agent advantage decomposition lemma 和 sequential policy update scheme。作者导出了Heterogeneous-Agent Trust Region Policy Optimisation (HATPRO) 和 Heterogeneous-Agent Proximal Policy Optimisation (HAPPO)算法。实验环境:Multi-Agent MuJoCo 和 StarCraft II tasks。比IPPO、MAPPO、MADDPG要好。
多智能体动作价值函数与多智能体优势函数:

MAPPO:
![]()
多智能体优势函数分解:
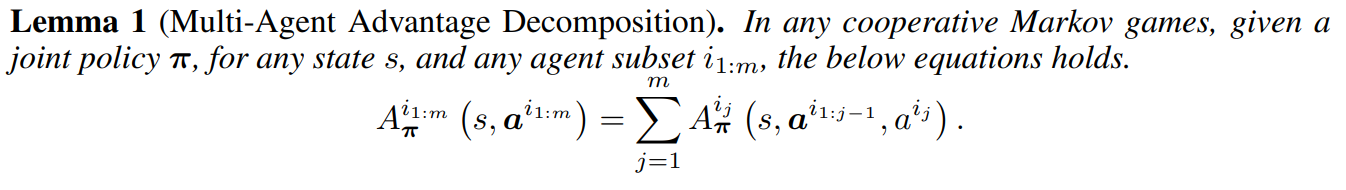
信任域优化:

多智能体策略单调改进:

单调性与存在性:

HATRPO:
复杂略过
序列化估计优势函数:
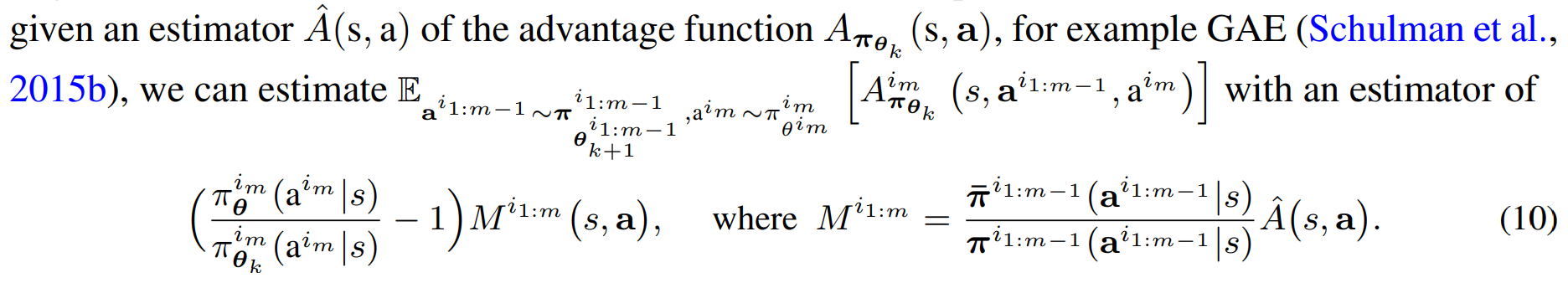
HAPPO:
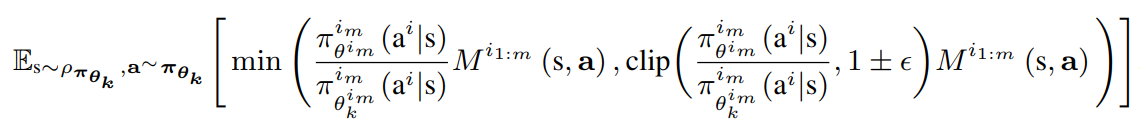
HAPPO Pseudo-code:

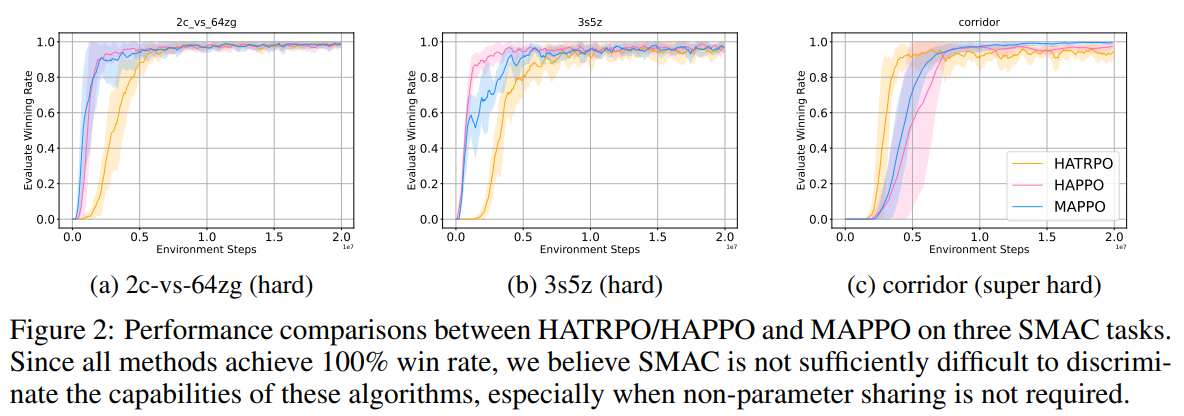
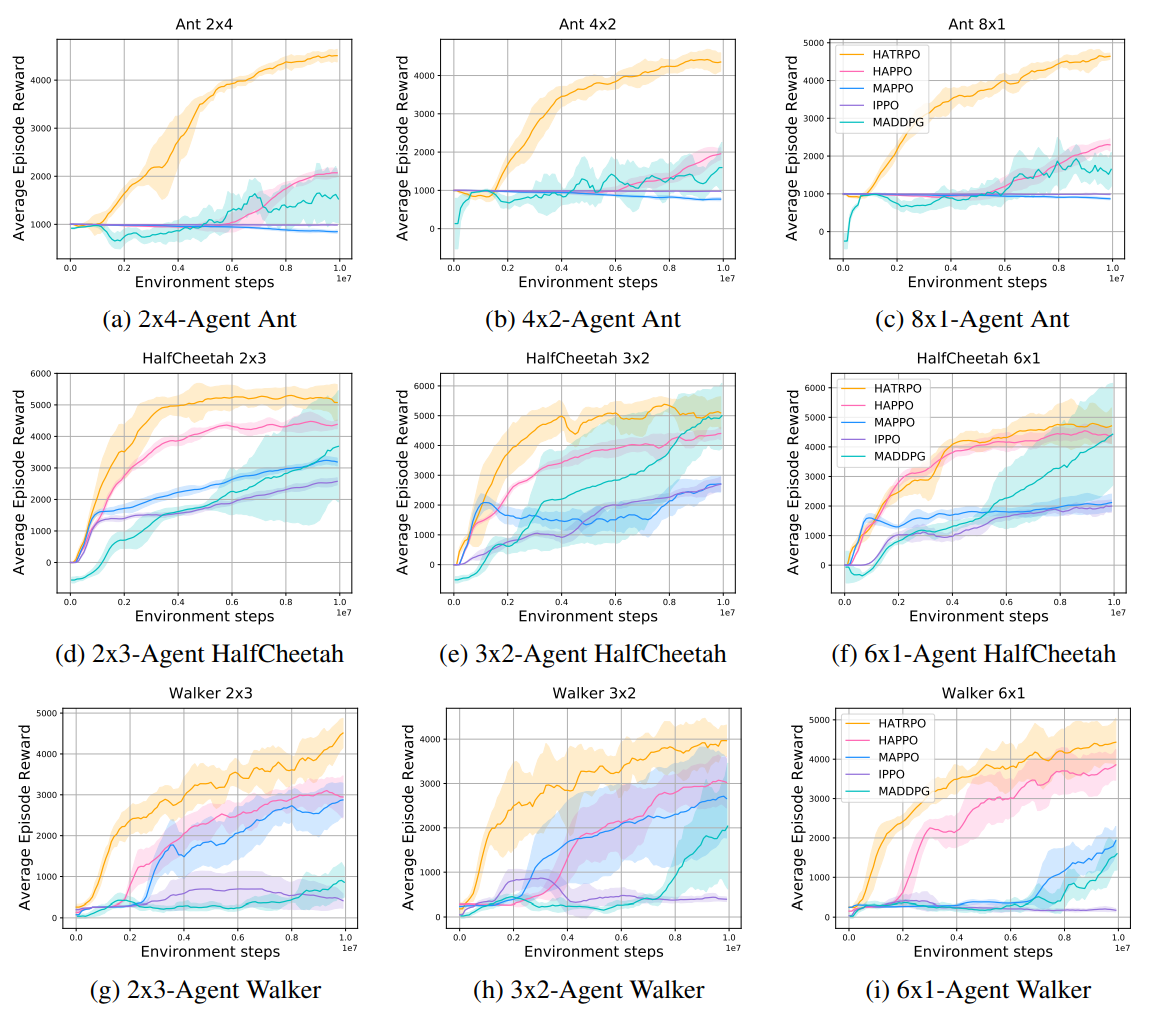
实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号