事后观察经验回放 Hindsight Experience Replay (HER)
事后观察经验回放。OpenAI的论文。
1707.01495
摘要:
处理稀疏奖励。提出了Hindsight Experience Replay新技术,使得可以从稀疏二元的奖励中进行有效的学习。可以与任意off-policy的强化学习算法结合。可以看作一种implicit curriculum。
在用机械臂操作物件的任务进行了演示。在3个不同的任务上进行了实验:pushing, sliding, and pick-and-place。在每一个任务中只使用了表示任务是否完成的二元奖励。消解实验表明Hindsight Experience Replay对在这些具有挑战性的环境里进行有效训练是至关重要的组分。在物理仿真的训练可以部署到物理机器人上并完成任务。实验视频地址https://goo.gl/SMrQnI
关键观察:
不同于当前的model-free RL算法,人有一种能力,可以从不符合期待的结果里学习,如同从符合期待的结果里学习。想象你在学习曲棍球,试图把一个球饼打进一个网里。你打了一下球饼,球饼没入网,从网的右边过去了。在这种情况下,标准的强化学习算法会把这个过程的一系列动作看作一次不成功的打击,而几乎不会从中学习到什么。但是我们可以从中得出另外一个结论,就是说,这一系列动作可能是成功的,如果球网在再过去右边一点。
Hindsight Experience Replay (HER) 适用于多目标的情况,如:到达每一个系统的状态可以当作一个独立的目标。HER基于训练universal policies (Schaul et al., 2015a) 。universal policies不仅把当前状态作为输入,而且目标状态作为输入。HER背后的核心点是用一个其它的目标去替换智能体试图达成的目标。
(UVFA)
Universal Value Function Approximators (UVFA) (Schaul et al., 2015a) is an extension of DQN to the setup where there is more than one goal we may try to achieve. 每一个episode不仅与(s, a)相关,而且与g也相关。在一个episode里, g选定以后就保持不变。策略和Q函数不仅与(s, a)相关,而且与g也相关。
A motivating example

标准RL失效,improving exploration,count-based exploration,bootstrapped DQN都失效。reward shaping有效,需要提供领域知识。
HER方法背后的核心点是用另外一个目标重新评估行动轨迹——这个行动轨迹虽然不同帮助我们学习怎么到达目标状态g,但是它确定可以告诉我们怎么样到达状态sT。这种信息可以通过使用off-policy RL算法来获取,在其时我们把经验回放里的目标状态从g修改到sT。另外,我们可以在回放里保留原来目标g。通过这种修改,至少有一半的行动轨迹有不同于-1的奖励。这样的话,学习就变得更容易了。
DQN without HER can only solve the task for n ≤ 13 while DQN with HER easily solves the task for n up to 50.
HER Algorithm
为了使用HER,一个必须要做的事情是选择一个额外目标集合。最简单的一个版本是给每一个行动轨迹一个目标m(sT),即轨迹最终状态所获取的目标。

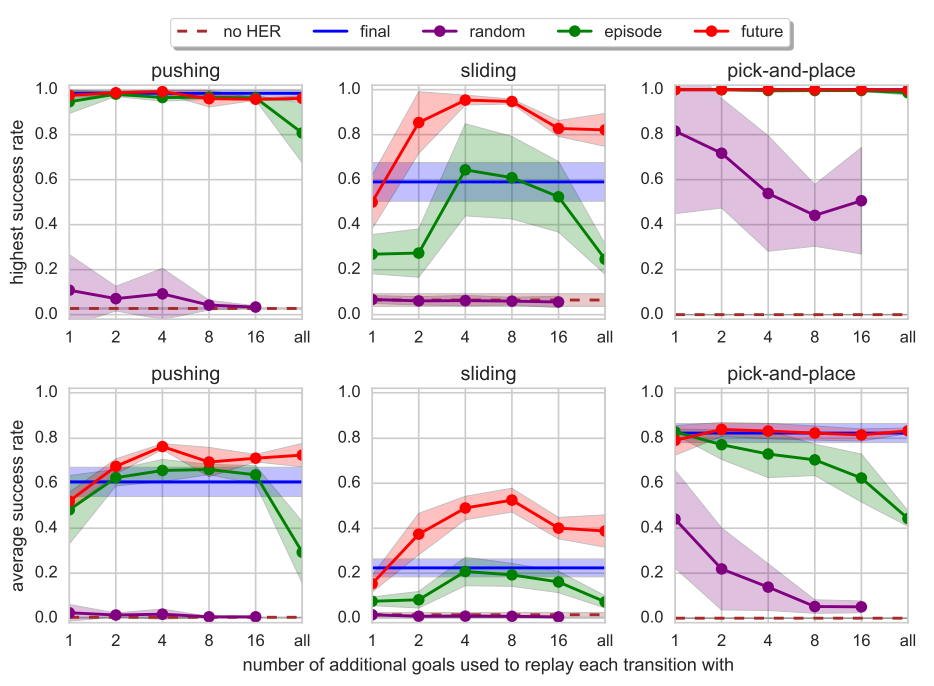
How many goals should we replay each trajectory with and how to choose them?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号