
【NLP之文本摘要】1-词向量技术总结
1. 背景
跟踪学习某培训平台人工智能课程之自然语言处理课程的内容,做个自己的笔记。
本讲内容老师大概讲了三个点:1.文本摘要的应用场景;2.词嵌入(word embedding)发展的进程 3.实战项目总体结合以及数据集的介绍。
2. 正文
结合老师上课的PPT以及自己的理解,大体做一下总结。
2.1 文本摘要常用的应用场景
文本摘要常用的典型应用场景:
- 舆情监测 (Mdeia Monitoring)
- 金融研究 (Financial Research)
- 智能问答 (Question Answering and Bots)
- 新闻简要 (Essay News)
- 在线学习 (E-learning and class Assignments)
- ......
参考链接:https://www.frase.io/blog/20-applications-of-automatic-summarization-in-the-enterprise/
2.2 词向量发展历程
文本摘要是针对文本处理的技术,自然绕不过语义表示、词表示等内容,结合词表示的发展历程,做一定的总结与归纳,不做具体原理的解释。
2.2.1 WordNet
WordNet 的原理并没有讲的很多,老师是通过两个例子⼩⻰⼥到了杨过⼩时候过过的地⽅,深情的说,我也想过过过过过过的⽣活、骑⻋差点摔了,幸亏⼀把把把把住了两个例子,来引出人类在探索如何表达词的含义这一问题?最早的想法就是,相似词的方式表达单词,这就是WordNet。但是这种方式有如下缺点:1. 不能表达词之间的细微差别;2. 无法表述新词;3. 表达过于主观,无法用数学的方式进行测量,量化两个词的相似性;4. 大量的人力维护;
2.2.2 One-Hot

基于上述问题,开始从离散的方式进行表示,最出名的就是one-hot。但是这种离散的方式,也存在一定的问题:1. 词表维度大;2. 难以表示相近的词;3. 不具备通用性;
2.2.3 N-gram

针对离散表达的问题,提出了分布式的表达:利用单词的上下文表达单词的含义。分布式表达最简单的的案例就是N-gram。
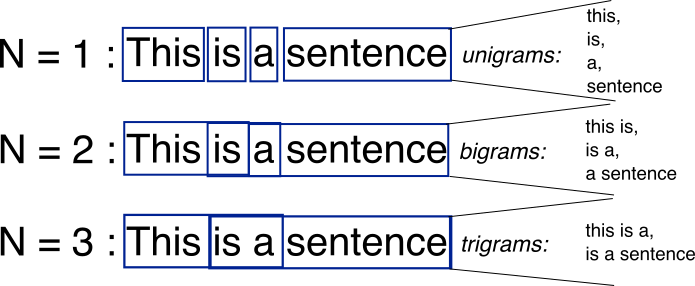

N-gram LM(Language Model)是用概率的形式表达一句话是否合理。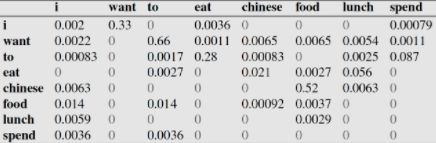
N-gram方式的问题在于:1. 数据稀疏,难免会出现OOV(Out Of Vocabulary);2. 随着n的增大,参数空间指数增长;3. 缺少长期依赖;4. 无法表达一词多义。
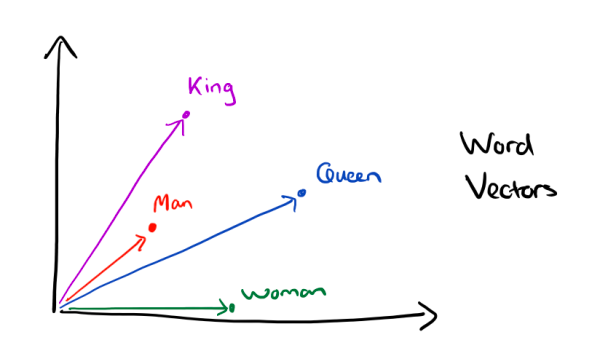
2.2.4 Word Vector
针对N-gram模型的上述缺陷,提出了Word Vector的表示。
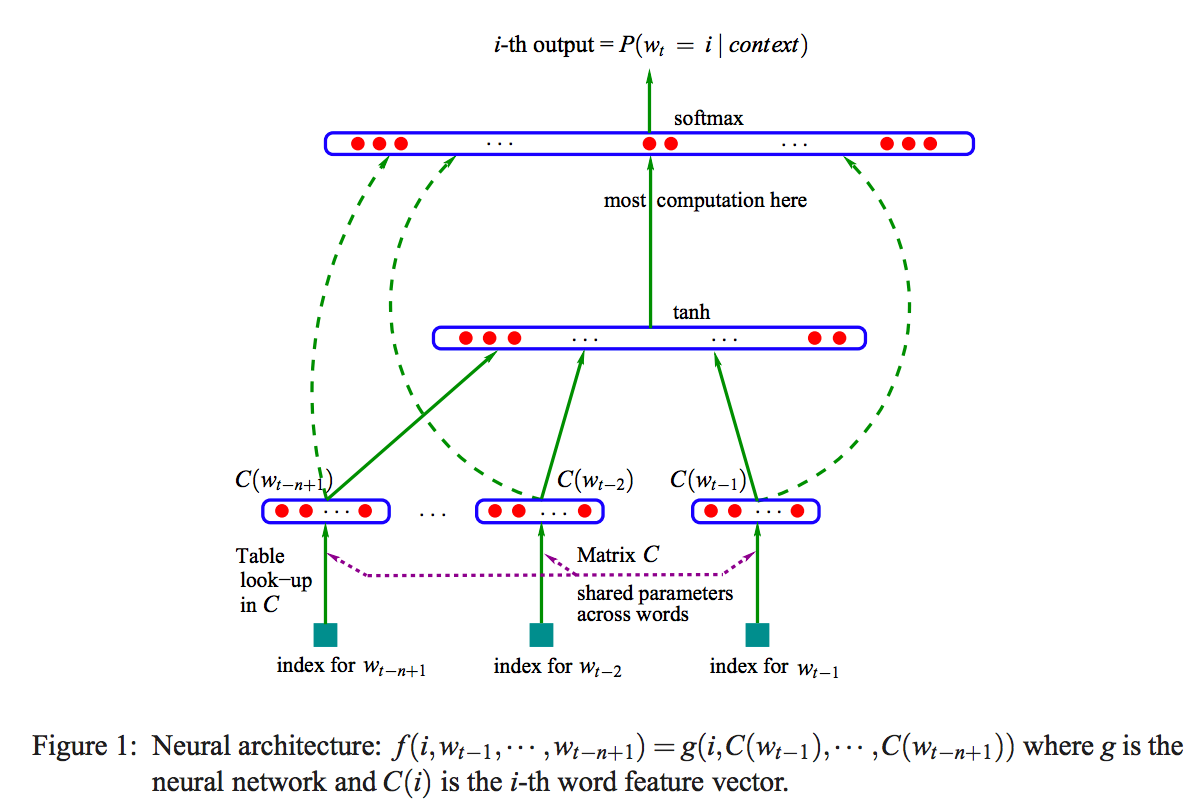
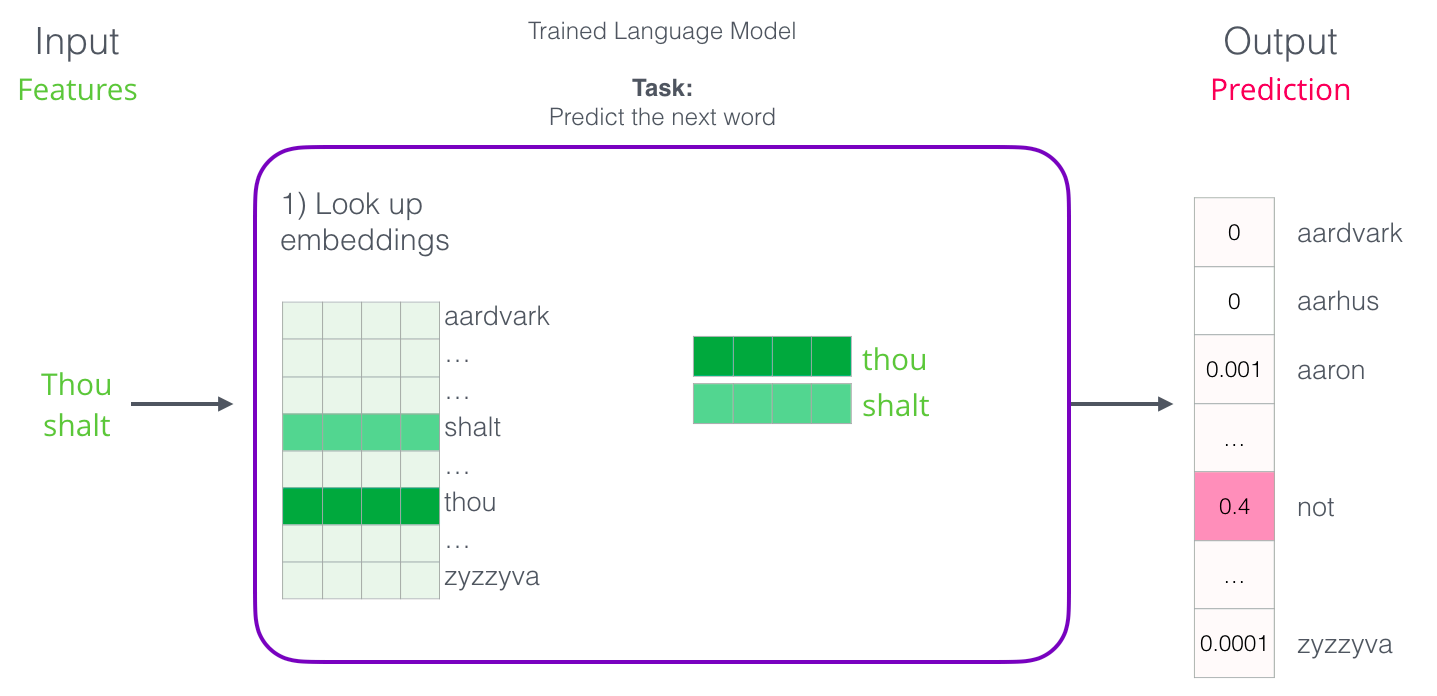
该模型(NPLM,https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)的目的是前文的单词,预测下文的单词;而模型的目的并不是得到词向量。该模型存在的问题在于:1. 有限的前文信息; 2. 计算量过大;3. 词向量只是副产品;
2.2.5 Word Matrix
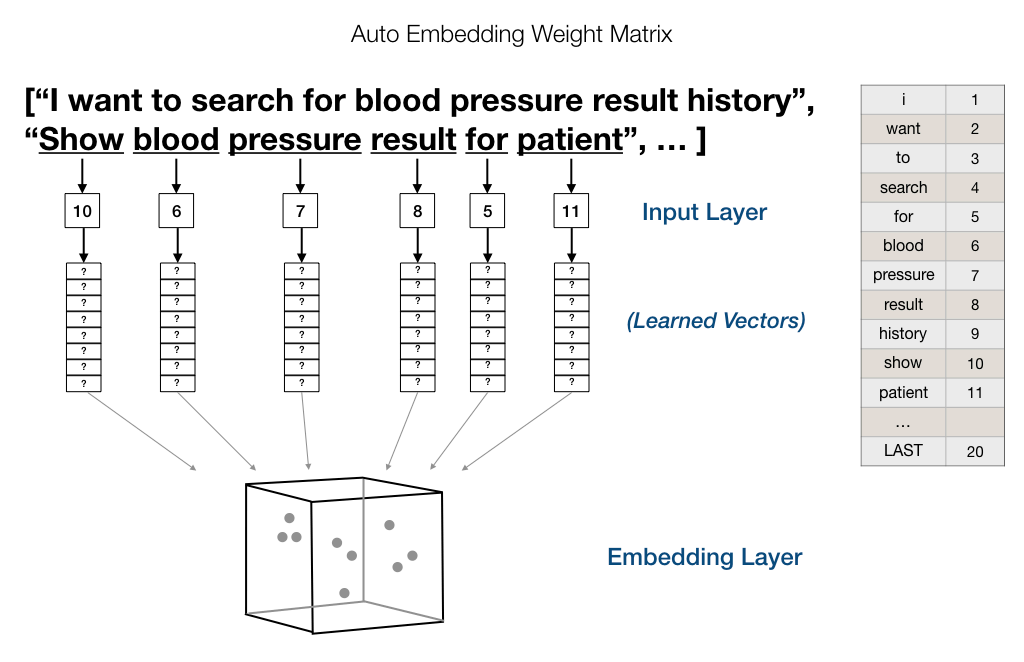
该模型是对上述模型的应用,讲上述模型中得到的词向量,构成矩阵,用于分类等任务。
2.2.6 Word2vec
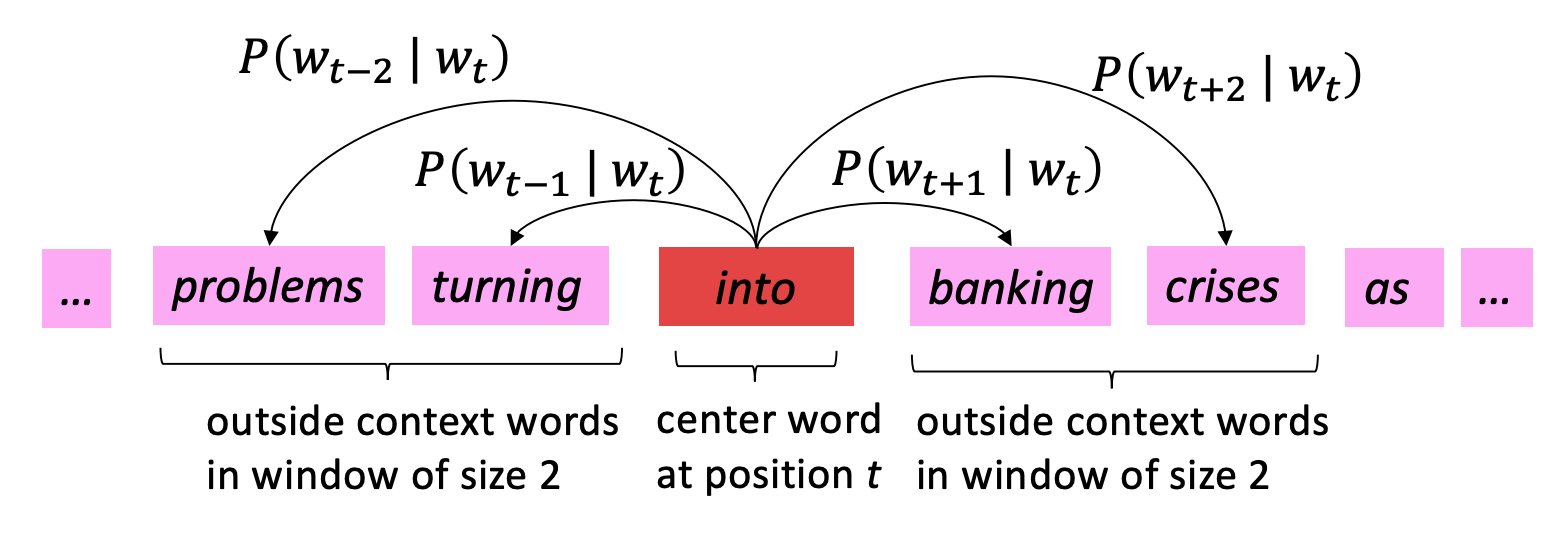
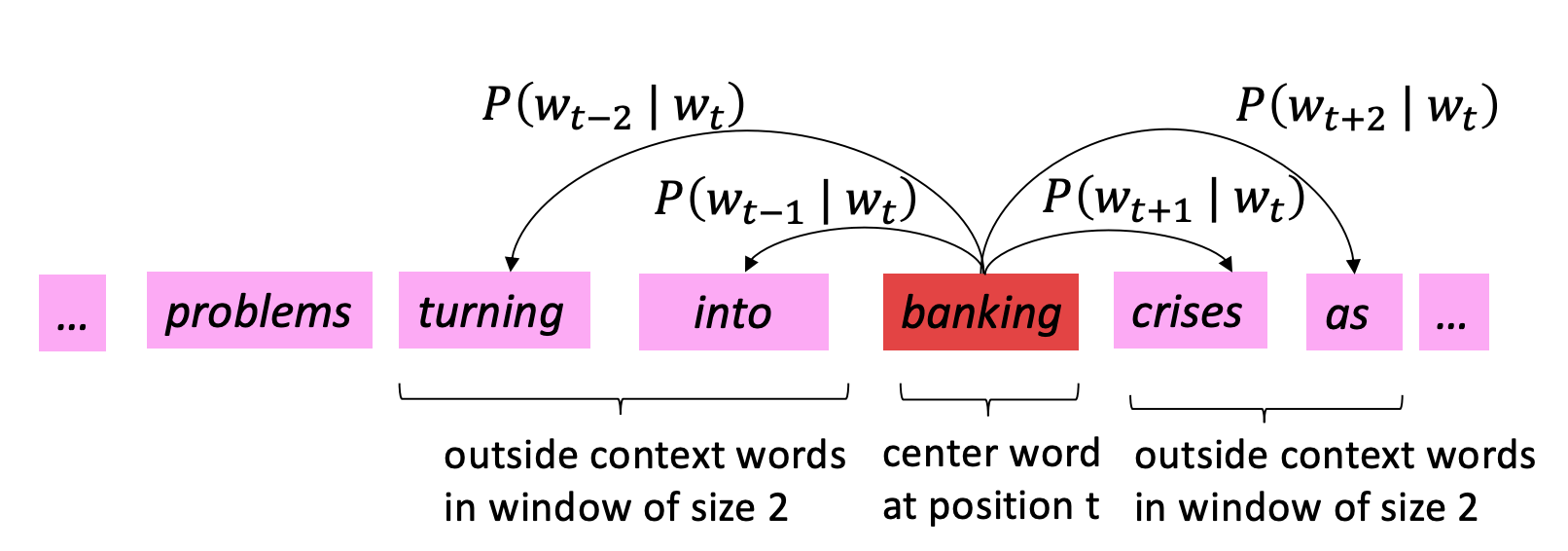
word2vec模型是上述模型的演化形式,依赖与大量的语料库。原理是希望中心词与相邻词的语义相近。
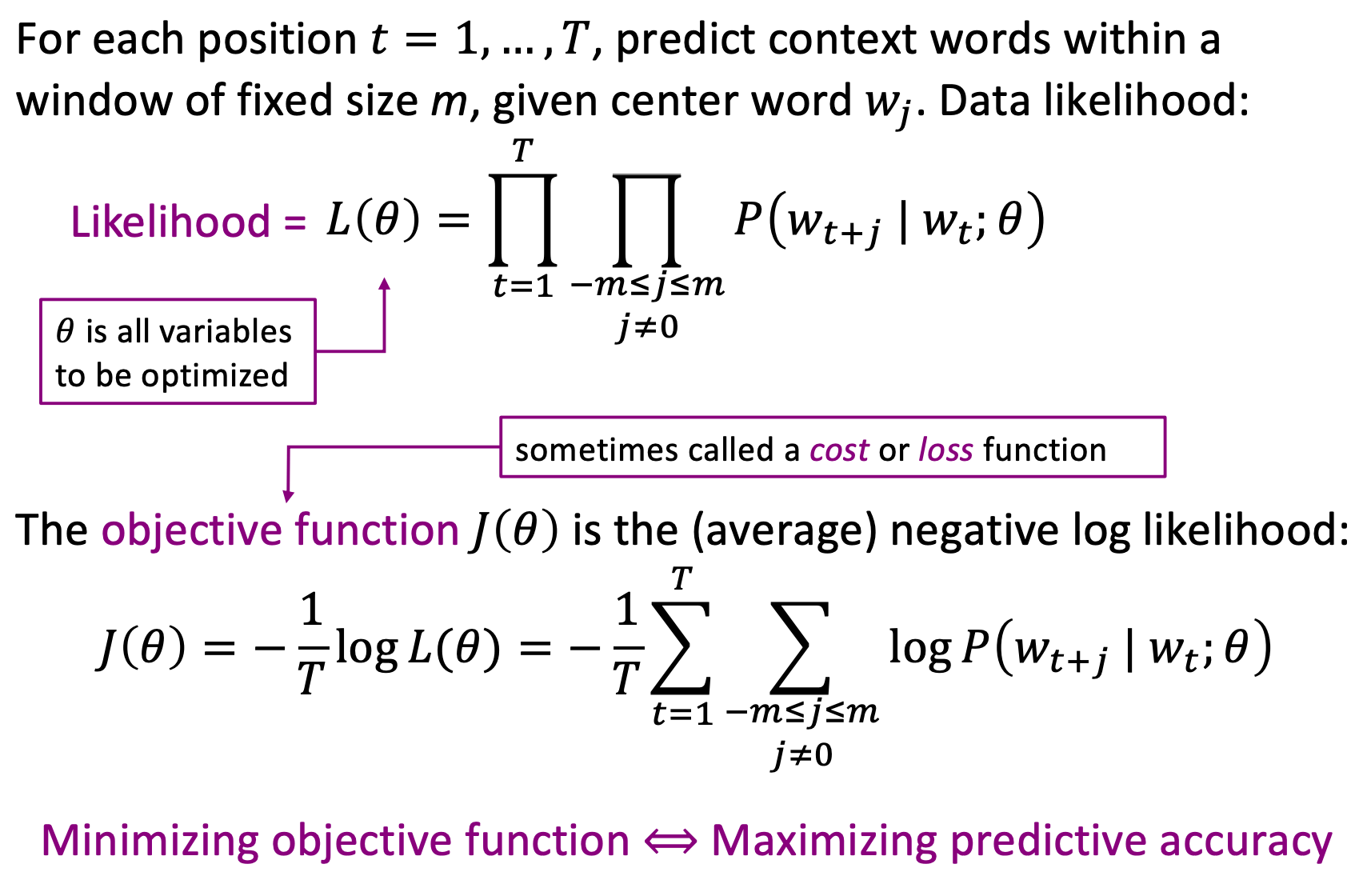

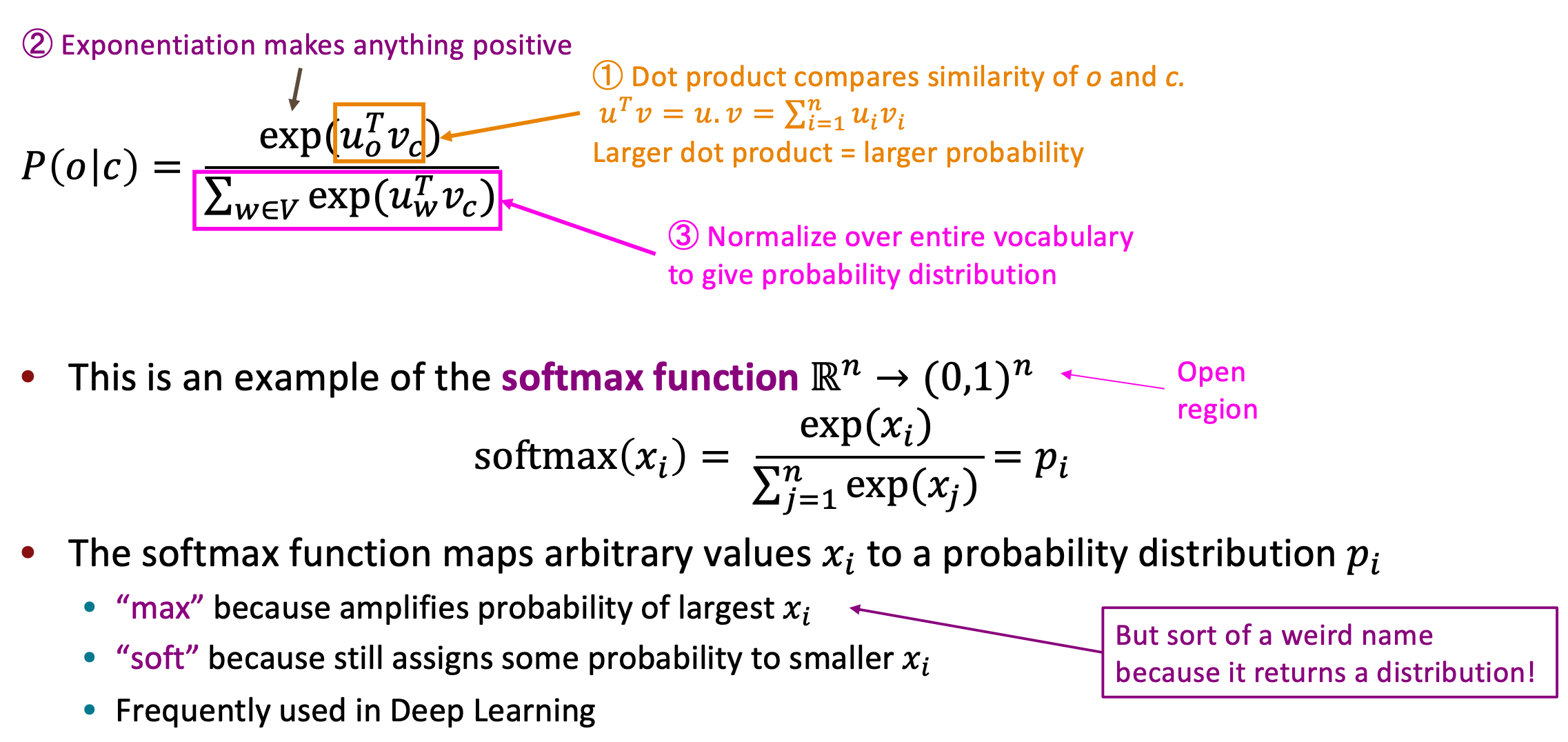
词向量模型的核心是如何表示两个词向量的相似性?文中利用的是点积的形式,点积的数学含义就是一定程度上表示两个向量的相似。结合词向量模型的原理,衍生出两种训练方式:cbow和skip-gram。
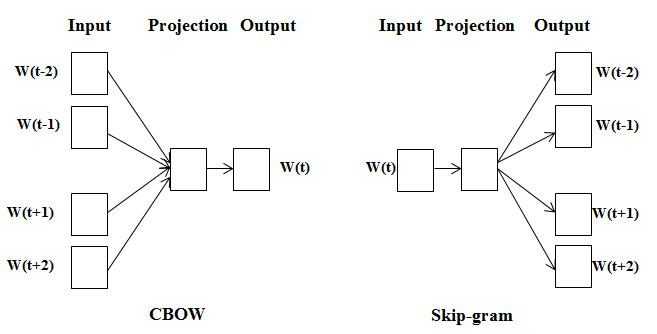
cbow:通过周边的单词,预测中心词

skip-gram:通过一个单词,预测周边的单词
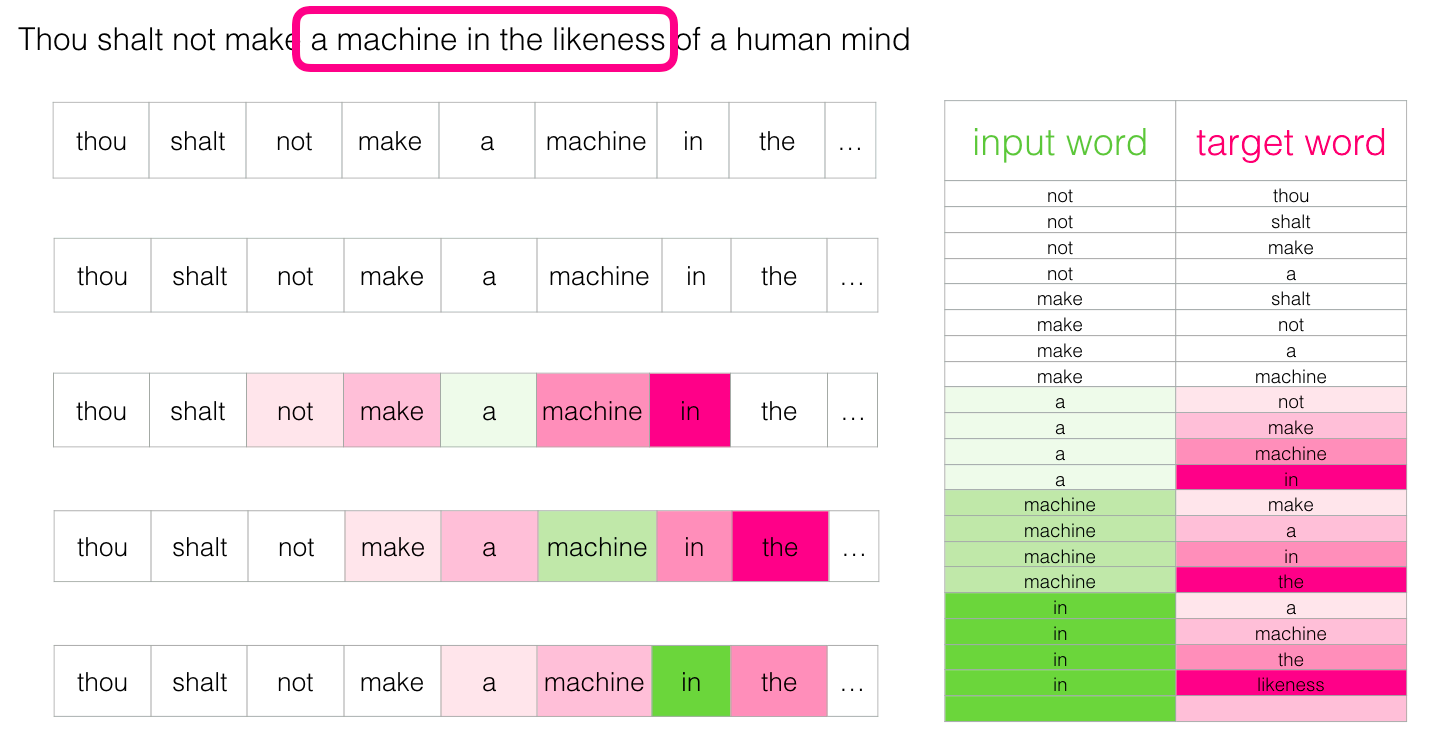
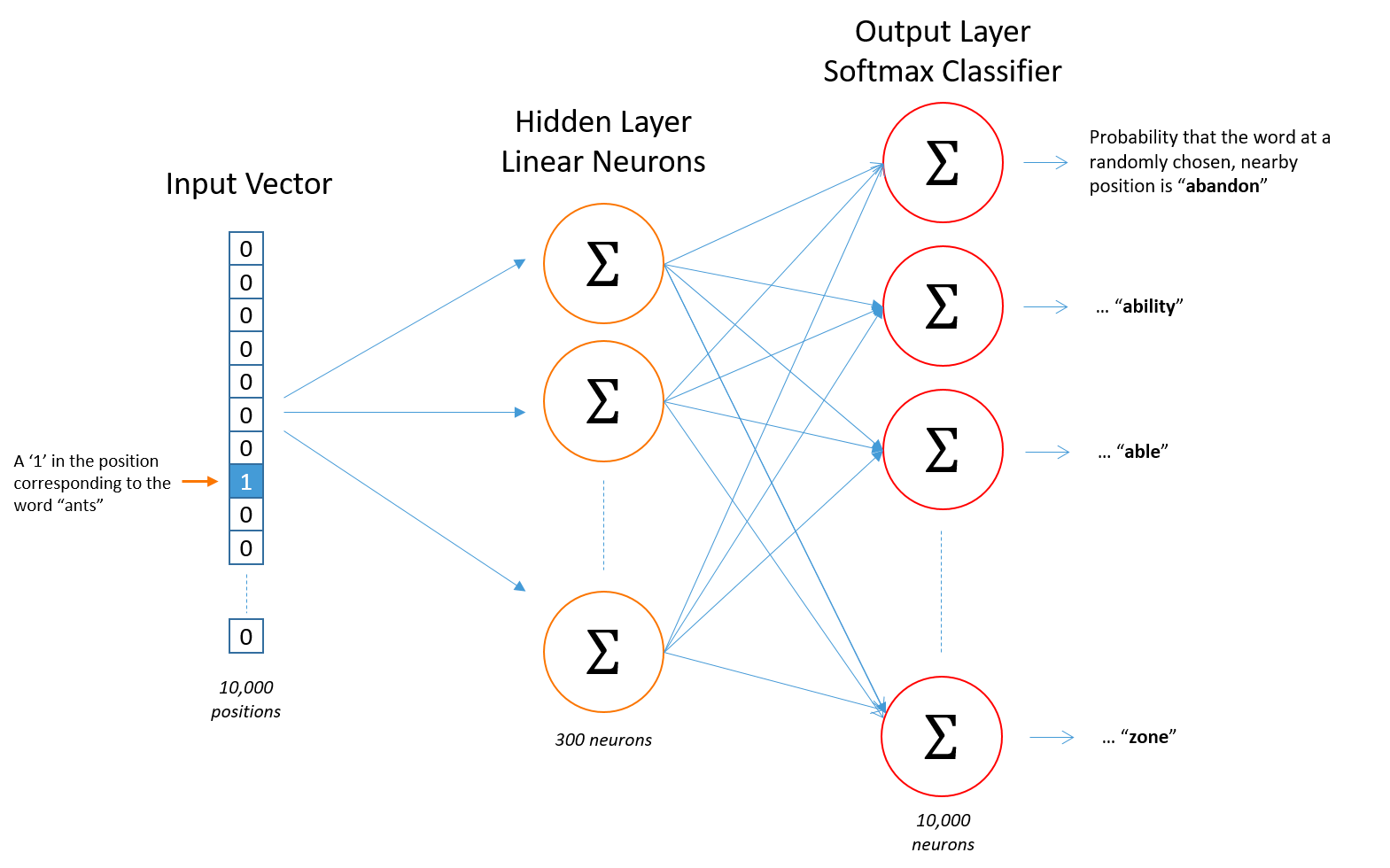
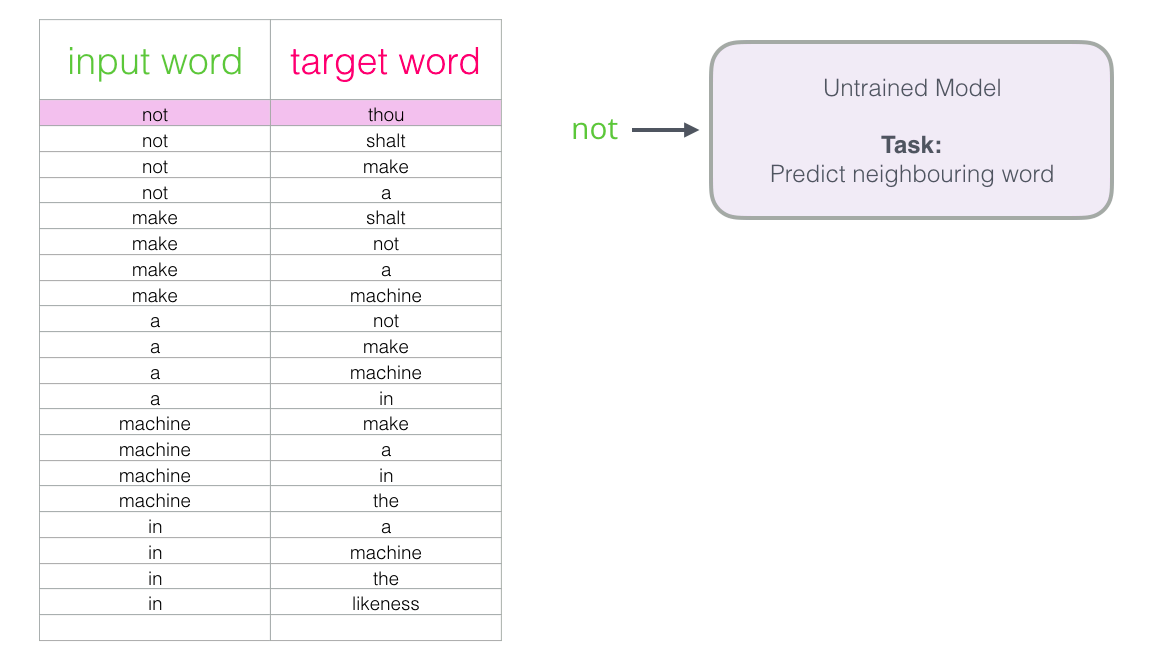
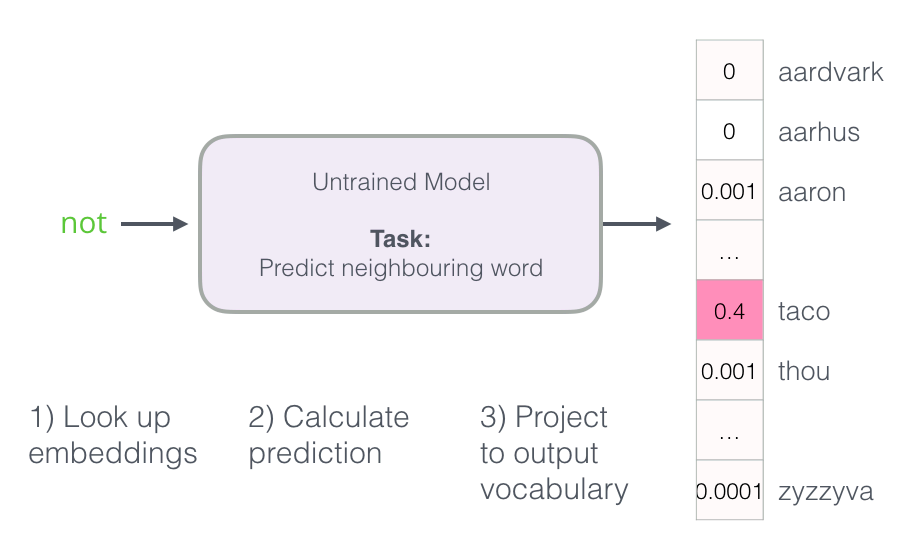
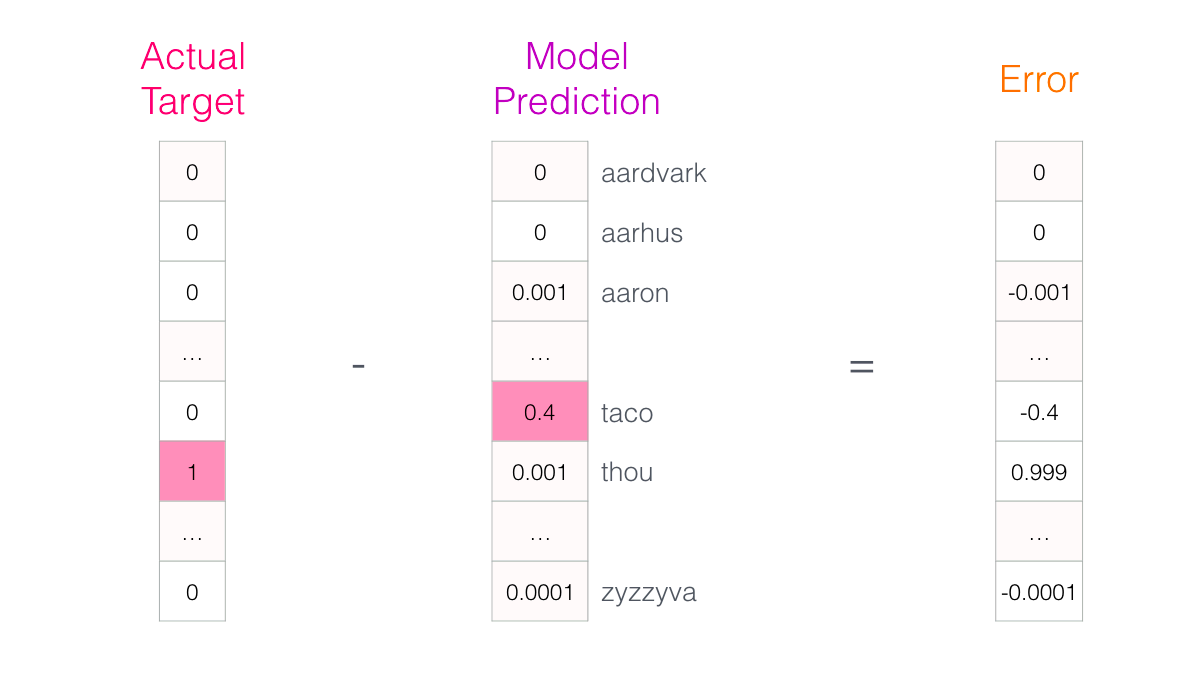
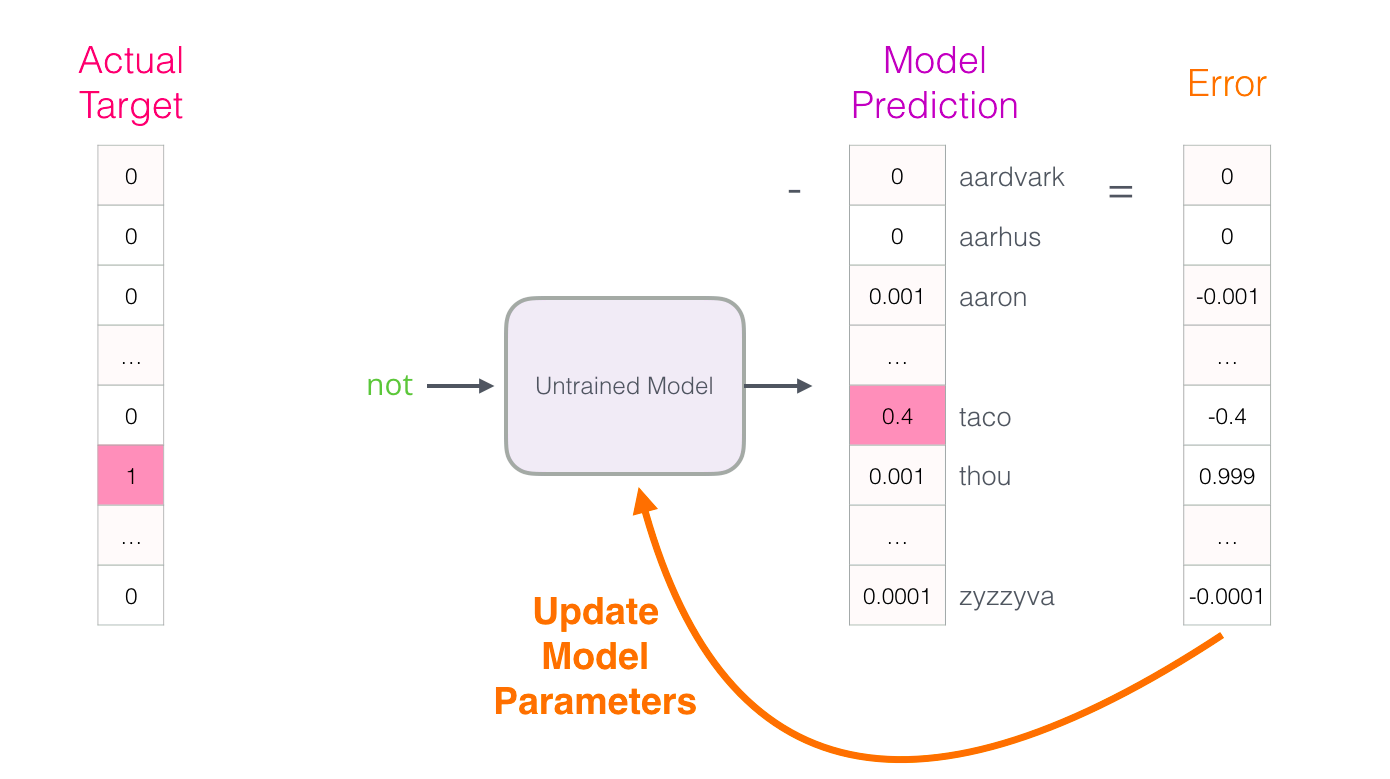
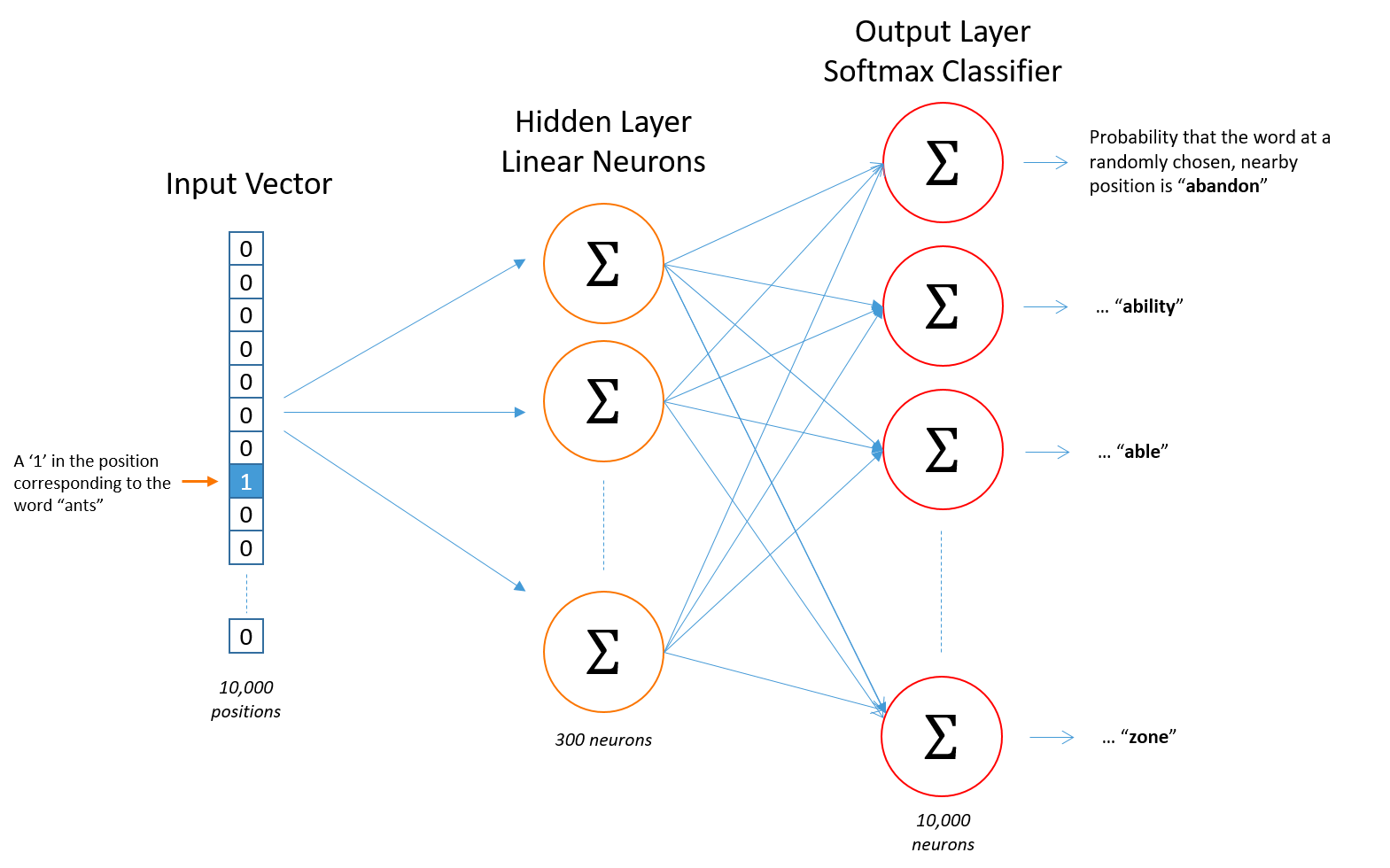
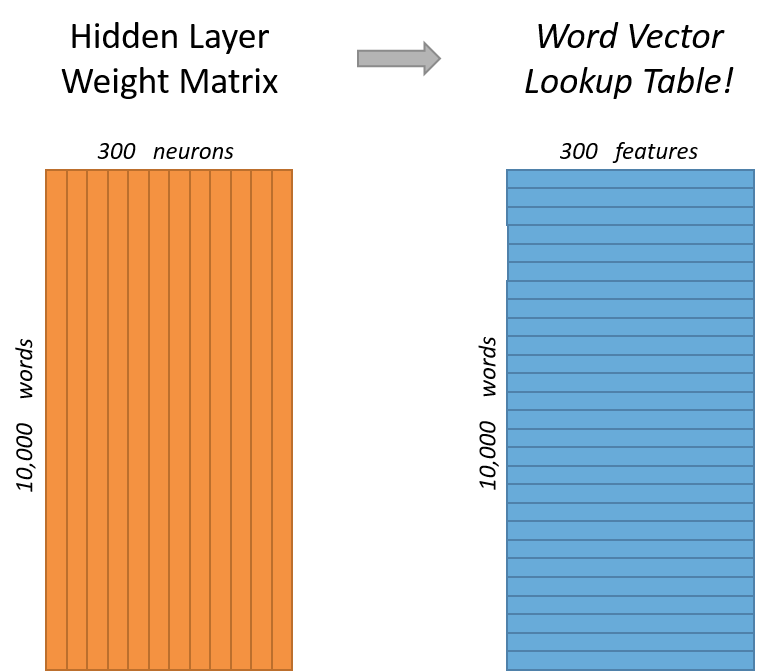
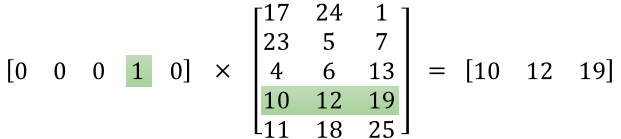
区别:1. skip-gram训练慢,cbow训练快;2. cbow更倾向于学习词的同义表示,skip-gram倾向于表达更全面的语义信息。
上述模型的问题在于:1. 计算量较大(最重要的问题)
2.2.7 H-Softmax
为解决计算量的问题,提出该模型。
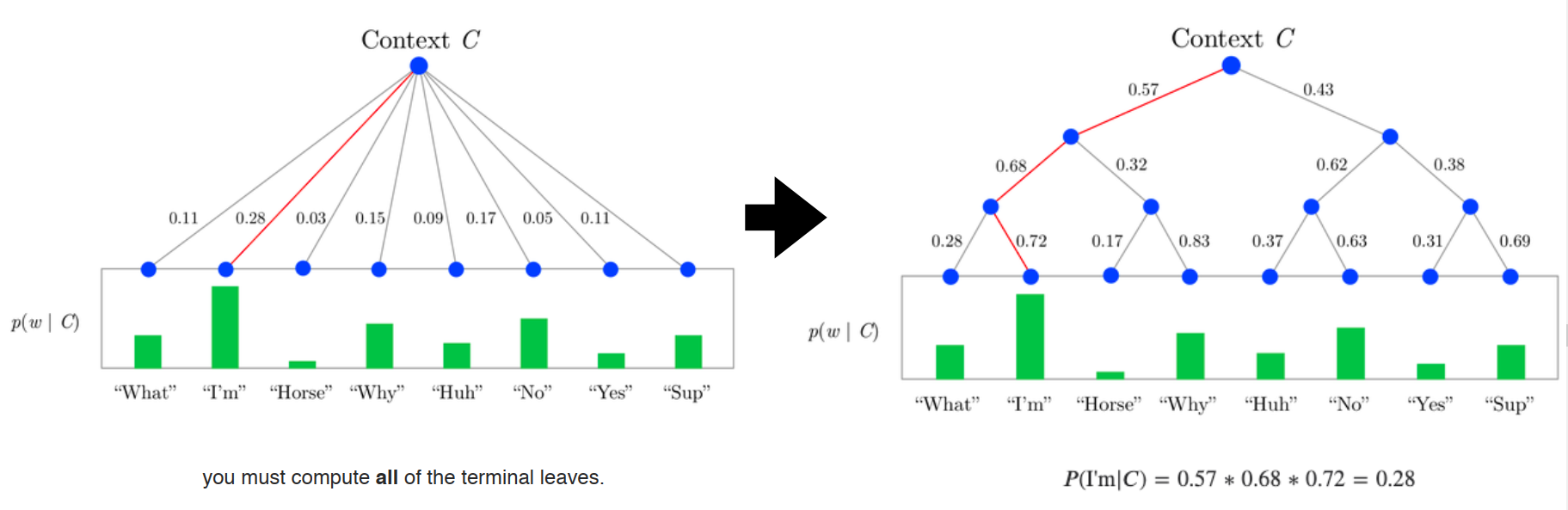
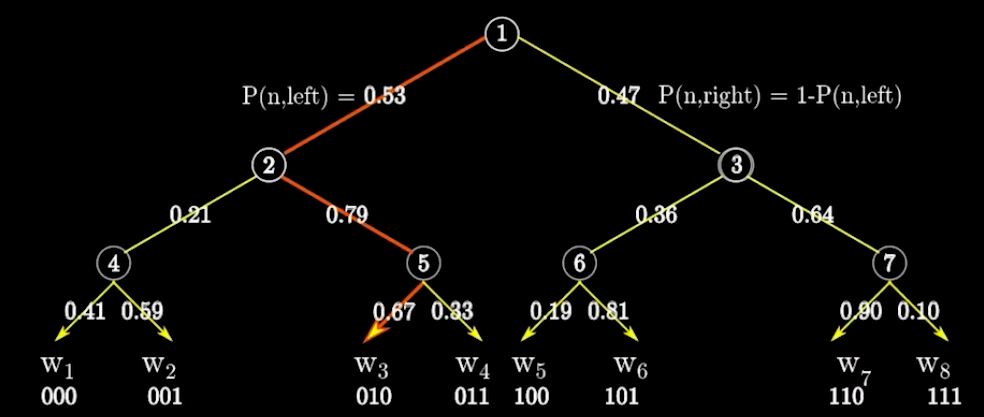
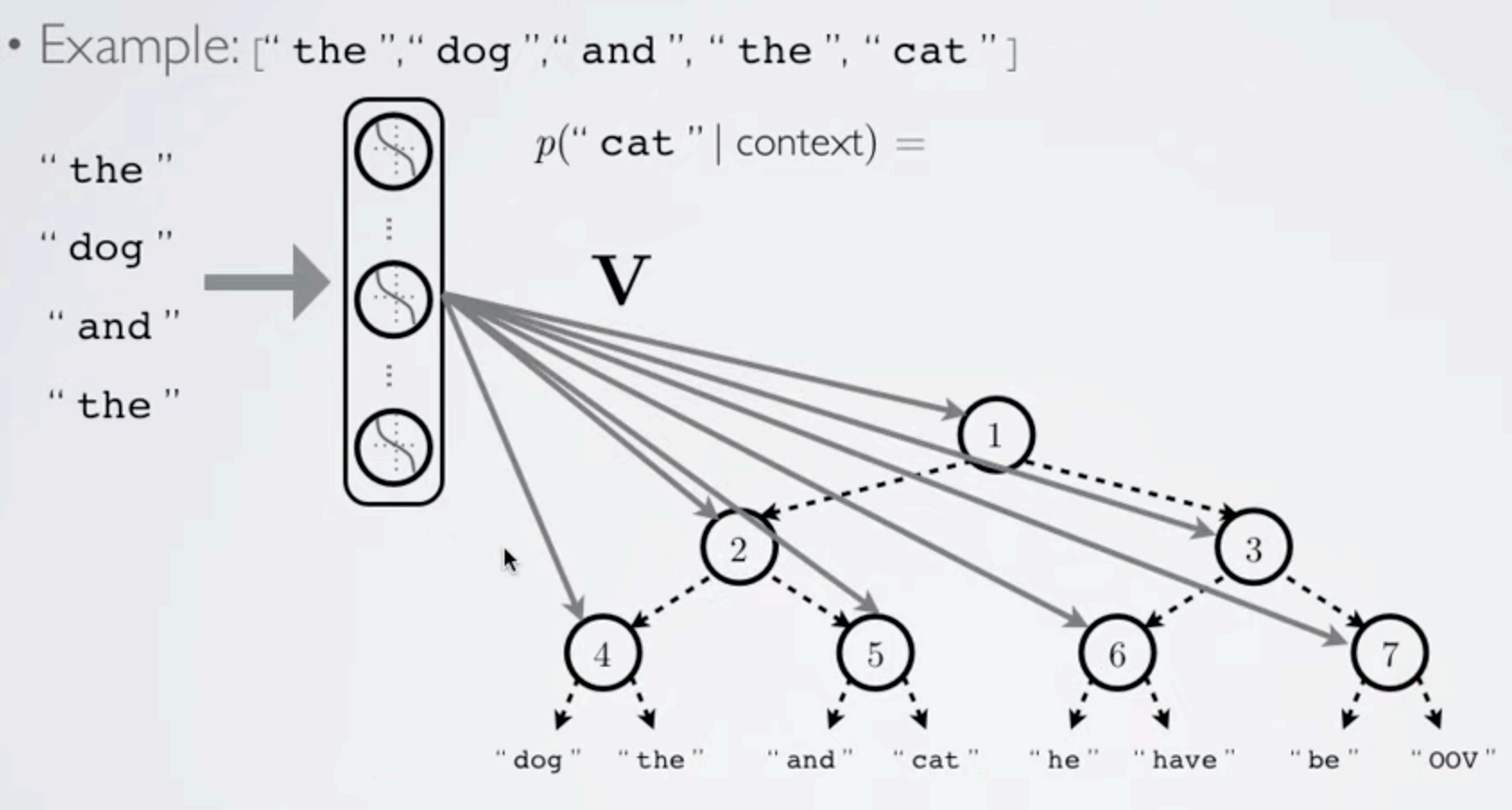
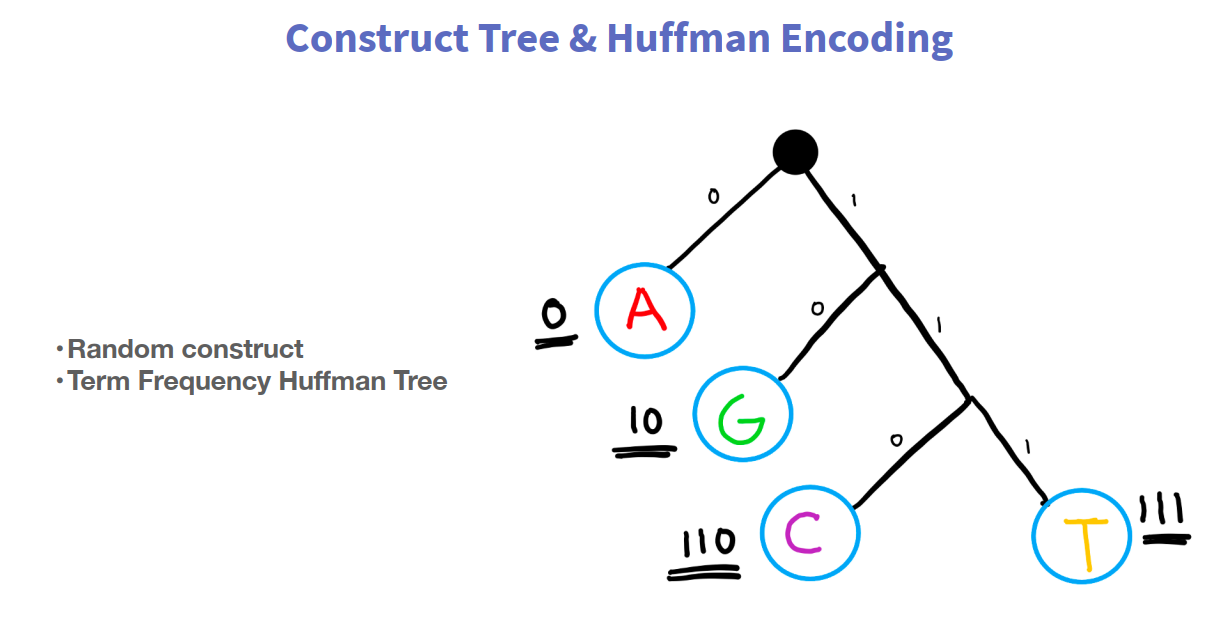
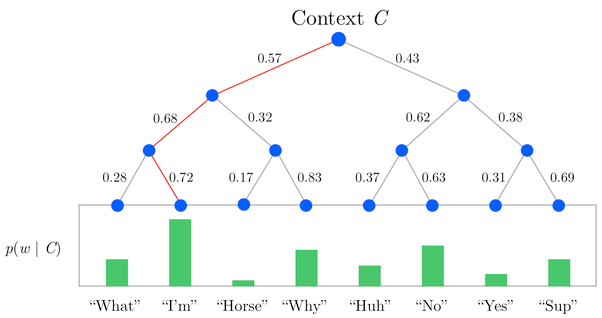
上述模型的问题在于:当预测的词,频率较低的时候,计算量也很大(因为如果依照词频构造树时,低频词深度很深,还是要便利很深。)
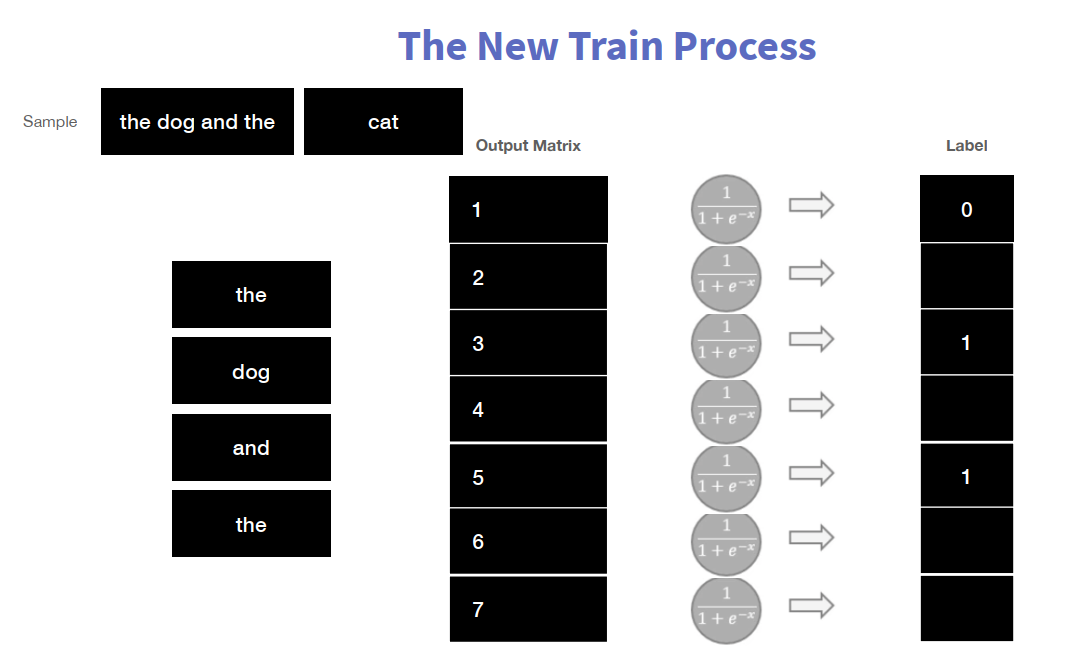
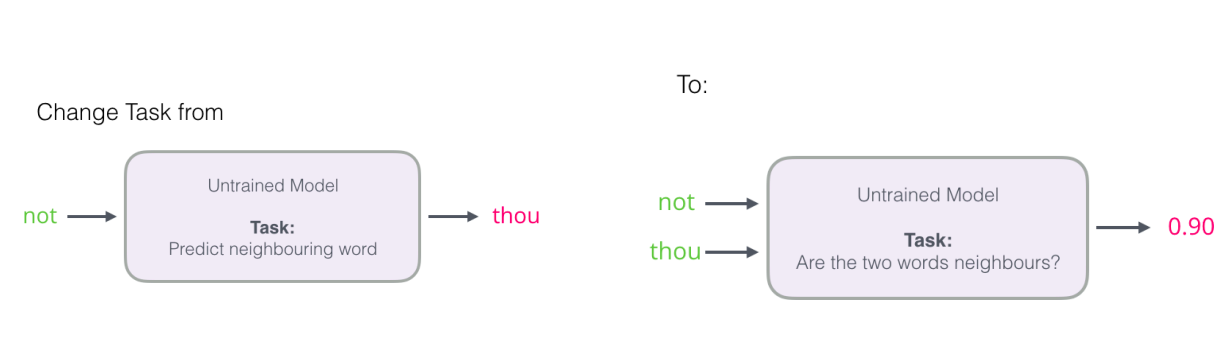
2.2.8 Negative Sampling
针对上述模型的缺陷,提出了负采样的方法;将分类问题转化为回归问题。
将当前词,与周围的词,构成一组(正)样本;
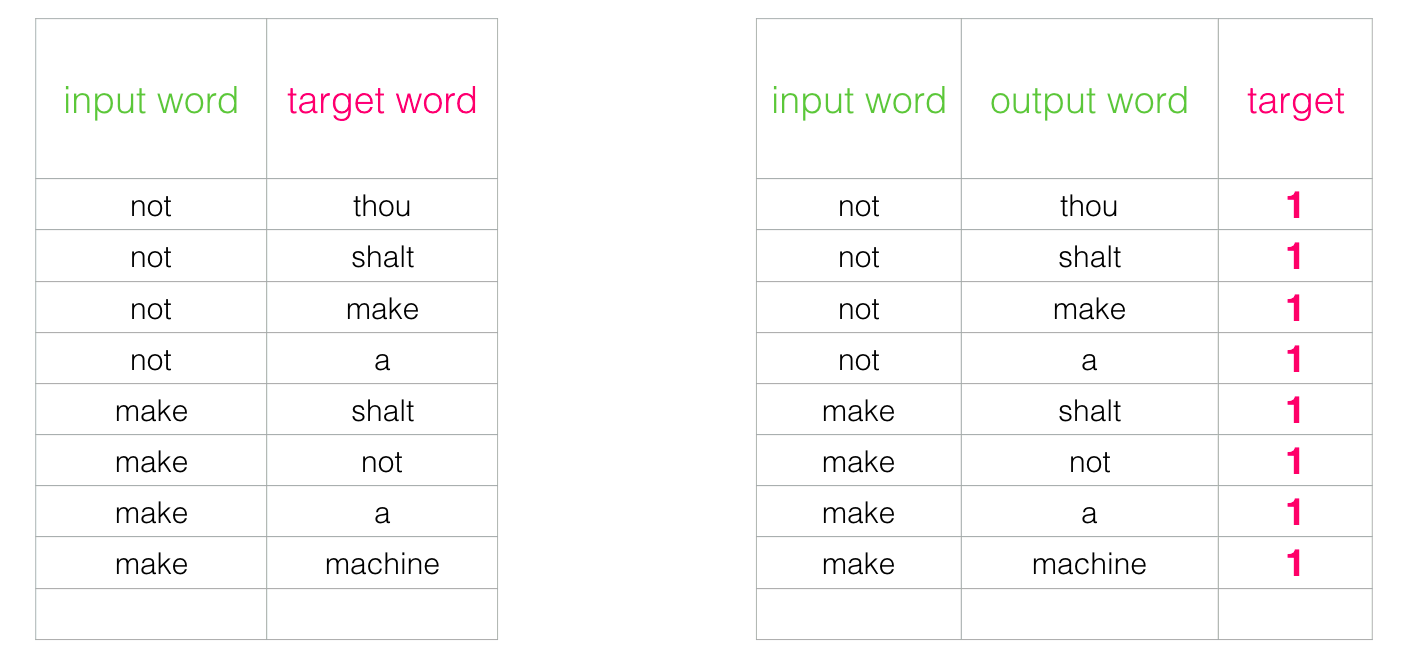
针对都是正样本的问题,继续添加如负样本,即不是当前词的周围词,为负样本。(正样本:(当前词,上下文词);负样本:(当前词,!上下文词))
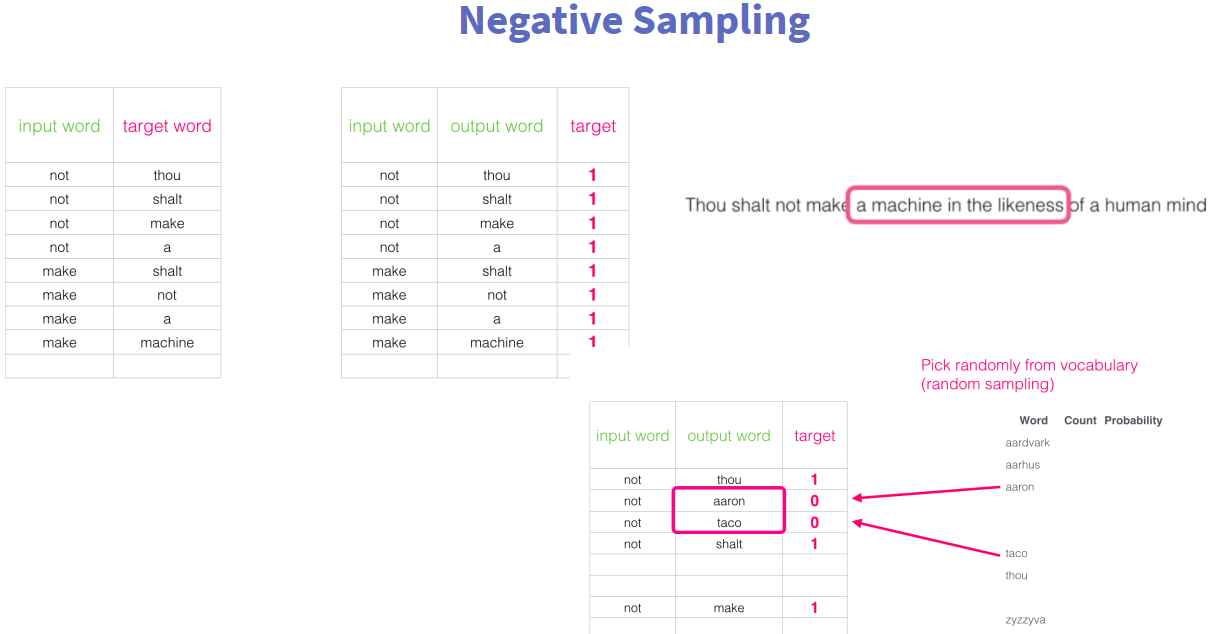
具体流程如下:
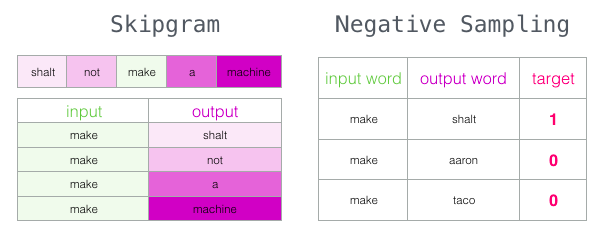
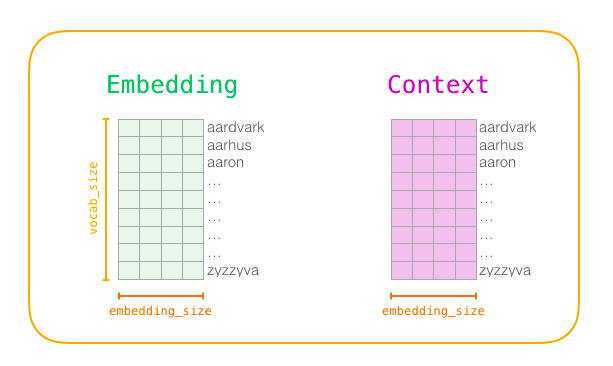
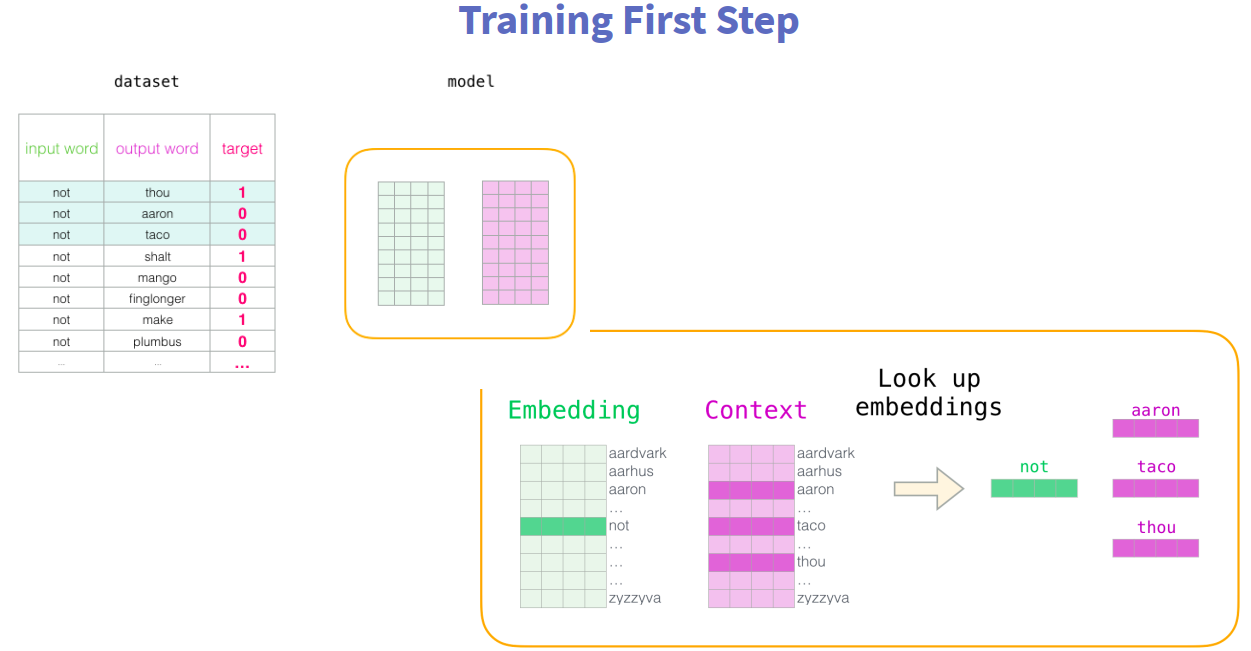


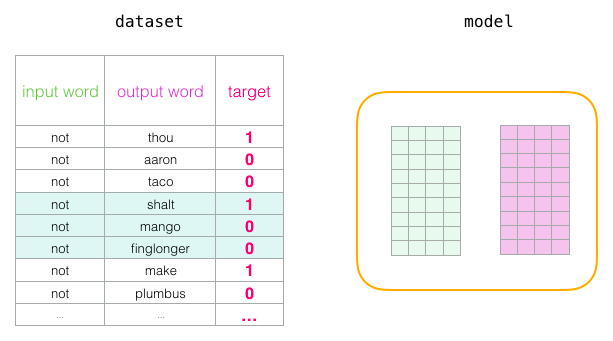
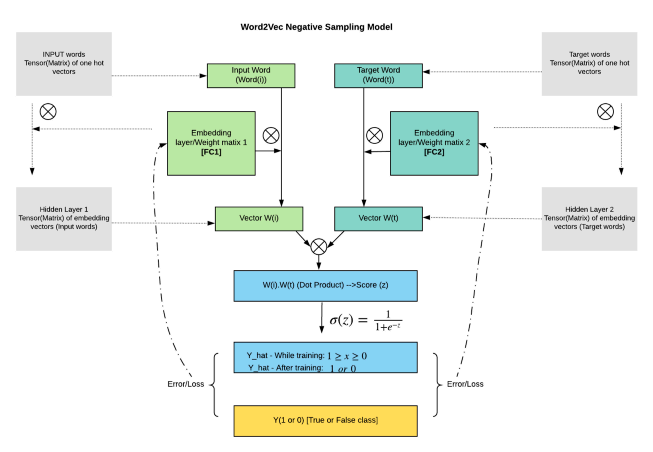
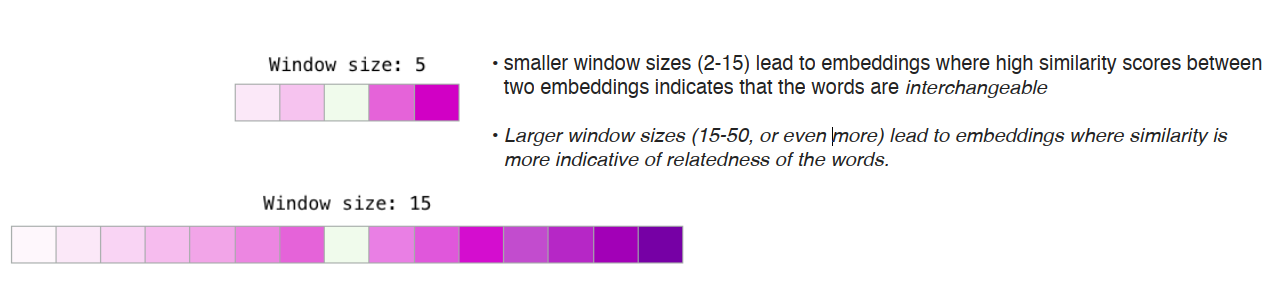
window_size(周围词的数量)的大小影响词向量的结果;一般而言设置为5时,学出来的结果较为相似;而在50的时候,词向量的区分度较大;语料库较大时设置widow_size大一点,语料库较小时设置小一点。
2.2.9 ... ...
...
2.3 实战案例及数据集简介
问题描述
项目一是由百度AI技术生态部门提供,题目为“汽车大师问答摘要与推理”。
要求大家使用汽车大师提供的11万条(技师与用户的多轮对话与诊断建议报告数据)建立模型,模型需基于对话文本、用户问题、车型与车系,输出包含摘要与推断的报告文本,综合考验模型的归纳总结与推断能力。该解决方案可以节省大量人工时间,提高用户获取回答和解决方案的效率。
数据说明
对于每个用户问题"QID",有对应文本形式的文本集合 D = "Brand", "Collection", "Problem", "Conversation",要求阅读理解系统自动对D进行分析,输出相应的报告文本"Report",其中包含摘要与推理。目标是"Report"可以正确、完整、简洁、清晰、连贯地对D中的信息作归纳总结与推理。
训练:所提供的训练集(82943条记录)建立模型,基于汽车品牌、车系、问题内容与问答对话的文本,输出建议报告文本
输出结果:对所提供的测试集(20000条记录)使用训练好的模型,输出建议报告的结果文件,通过最终测评得到评价分数
请提交一个CSV文件,包含QID和Prediction两个字段,分隔符为逗号(','),请注意区分大小写。参考样例如下:
| QID | Prediction |
|---|---|
| Q103432 | 你的预测 |
| Q100965 | 你的预测 |
3. 总结
-
- 对整个word2vec发展历史进行了梳理归纳,从
相似性表达(WordNet)到离散型表达(one hot),再到分布式表达(N-gram)及其改进(word vector -> word matrix -> word2vec -> word2vec H-softmax改进 -> word2vec negative sample改进)。
- 对整个word2vec发展历史进行了梳理归纳,从
-
- 中间有些细节,加深了之前的理解。如:word2vec 的soft max如何处理词向量相似性(中心词与上下文,做点积);H-softmax树的构造,一般用词频构建;负采样将分类问题转化为回归问题等。
4. 附:
- 后续补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号