HCIP-EI v2.0 培训01: 神经网络基础
培训内容
- 神经网络基础
- 图像处理理论和应用
- 语音处理理论和应用
- 自然语言处理理论和应用
- 华为AI发展战略与全栈全场景解决方案介绍
- ModelArts 概览
神经网络基础
内容
了解什么事人工神经网络与深度前馈网络
掌握如何训练神经网络
掌握梯度下降的方法以及反向传播的概念
了解神经网络架构设计的因素
深度学习预备知识
半监督学习(semi-supervised learning):监督学习+无监督学习,用标记数据作为学习的数据集
强化学习(reinforcement learning):算法与环境交互,学习系统和它的训练过程会有反馈回路
- 凸集:集合中任两点连线上的点都在该集合中,则称该集合未凸集
- 凹集:非凸集
- 凸函数:图像上任两点连线,如果函数图像在这两点之间的部分总在连线上方且定义域为凸集,则称凸函数(写反了吧)
凸优化
机器学习的一个根本性问题,工程中有很多问题可以抽象化为一个凸问题,理论上,这个问题可以得到解决。
- 凸优化条件
- 凸优化:约束条件为凸集
- 目标函数为凸函数
- 非凸问题转化为凸优化问题:
- 修改目标函数,使之转化为凸函数
- 抛弃一些约束条件,使新的可行域为凸集并且包含原可行域
损失函数
- 损失函数衡量了评分函数的预测与真实样本标签的吻合度
- Loss的值一般设置为和吻合度负相关
- 神经网络在数据集上学习,就是通过对训练数据集的学习,调整神经网络中每个神经元的参数,使得损失函数的值取得最低或相对较低的值
交叉熵损失函数(Cross Entropy/Softmax Loss)
对第i个样本 \(x_i\) ,神经网络W预测其为第k类的得分记作 \(f(x_i,W)_k\) ,\(x_i\) 的真实标签是 \(y_i\) ,损失函数是:
梯度下降法
- 批量梯度下降(BGD)
- 每次更新使用所有的训练数据,最小化损失函数
- 随机梯度下降(SGD)
- 每次更新只考虑一个样本点,大大加快训练速度,但函数不一定是朝着极小值方向更新,且SGD对噪声更敏感
- 小批量梯度下降(MBGD)
- MBGD解决了批量梯度下降的训练速度慢的问题,以及随机梯度下降对噪声敏感的问题
人工神经网络
- 人工神经网络:由人工神经元互连组成的网络,是从微观结构和功能上对人脑的抽象、简化,是模拟人类智能的一条重要途径,反映了人脑功能的若干基本特征,如并行信息处理、学习、联想、模式分类、记忆等。
神经元
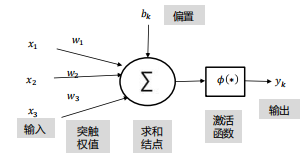
由线性函数和激活函数构成
线性函数:
激活函数:
人工神经网络主要由大量的神经元以及他们之间的有向连接构成,主要考虑三个方面:
- 神经网络的拓扑结构:不同神经元之间的连接关系
- 神经元的激活规则:主要是指神经元输入到输出之间的映射关系,一般为非线性函数
- 学习算法:通过训练数据来学习神经网络的参数
拓扑结构:
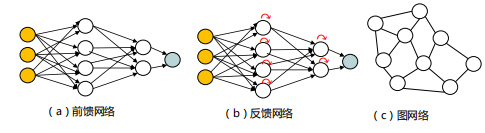
感知器
1957年,Frank Rossenblatt(美)提出了感知器算法。带权重的线性叠加算法。
感知机的训练过程是求解W和b的过程。正确的W和b构成的超平面 WX=0 可以将两类数据点分割在这个平面的两侧。为了找出这样的超平面需要定义目标函数。
目标函数使用误分类点到超平面s的总距离,即点到直线的距离。
损失函数:使误分类的所有样本误分类程度最低,即这些样本到超平面的距离之和最小。
感知机的损失函数:
其中M是所有误分类点的集合。用梯度下降法或拟牛顿法计算最优点
感知机使用随机梯度下降。更新原则是,如果预测准确则权重不更新,否则,增加权重,使其更倾向于正确的类别。
实现步骤
- 设置 \(\theta\) 的初值和步长 \(\alpha\) 的初值,可以将他们分别设置为 0向量和1。由于感知机的解不唯一,初值的设定会影响最终迭代结果
- 在训练数据集中选取点 \((x(i),y(i))\) ,如果它满足 \(y(i)[\theta * x(i)] <= 0\) ,则更新参数。否则继续遍历数据寻找误分类点
- 对 \(\theta\) 向量进行一次随机梯度下降迭代 \(\theta = \theta + \alpha * y(i) * x(i)\)
- 检查训练集中是否还有误分类的点,如果没有,算法结束,此时的 \(\theta\) 为最终结果。如果有,继续第二步
- 说明:
- 如果两个类别线性可分,则感知器一定会收敛。此时,初始化的权值不会影响收敛
- 如果线性不可分,则感知器一定不会收敛
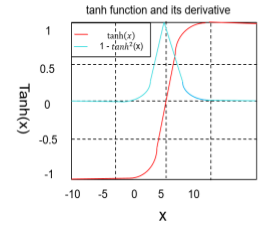
激活函数
sigmoid 函数
tanh 函数
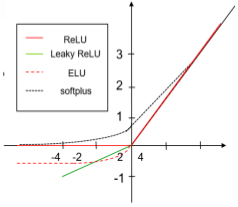
ReLU 函数
Rectified Linear Unit, 修正线性单元
其他类似ReLU 的函数
- 绝对值整流
\(g(z) = |z|\)
- 渗漏整流线性单元 (Leaky)
所有负值赋予一个非0斜率
- ELU(指数线性单元),Softplus函数
\(y = log(1 + e_x)\)
Softmax 函数
常用于多分类任务的输出层
激活函数设计需要考虑的因素
- 非线性
- 当激活函数是非线性的,一个两层神经网络可以拟合通用函数,如果失去了非线性,整个网络相当于一个单层线性模型
- 连续可微性
- 对于梯度优化方法是必要的,如果选择了一些具有局部不可微的函数,则需要强行定义此处的导数
- 有界性
- 如果激活函数有界,基于梯度的训练方法往往更稳定;如果是无界的,训练通常更有效率,但训练容易发散,此时可以适当减小学习率
- 单调性
- 如果激活函数是单调的,与单层模型相关的损失函数是凸的
- 平滑性
- 有单调导数的平滑函数已被证明在某些情况下泛化效果更好
深度前馈网络
神经网络
全连接人工神经网络
把多个感知器连接起来,可以表达种类繁多的非线性曲面
神经网络
神经网络在感知器的基础上做了一些延伸:
- 加入隐藏层,增加网络的表达能力
- 输出层神经元不止一个,有多个输出,可以应用于分类回归,以及其他的机器学习领域比如降维和聚类等
- 对激活函数扩展,包括 sigmoid 函数,Softmax 和 ReLU 等
深度前馈网络
深度学习:隐藏层大于2的神经网络叫做深度神经网络。深度学习就是使用DNN架构的机器学习方法
深度前馈网络(Deep Feedforward Network):也叫前馈神经网络(Feedforward Neural Network)或者多层感知机(Multilayer Perceptron, MLP),是典型的深度学习模型
- 输入节点无计算能力,只是为了表征输入矢量各元素值
- 各层节点表示具有计算功能的神经元,称为计算单元。每个神经元只与前一层的神经元相连;接收前一层的输出,并输出给下一层,采用一种单向多层结构;每一层包含若干个神经元,同一层更多神经元之间没有相互链接,层间信息的传送只沿一个方向进行
反向传播
反向传播算法(Back Propagation)使用链式求导法则将输出层的误差反向传回给网络,使神经网络的权重有较简单的梯度计算实现。
- 根据反向传播算法可以编程实现神经网络权重的梯度计算,从而通过梯度下降法完成神经网络的训练
- 成熟的深度学习框架会自动完成反向传播和求导的部分。我们使用时只需要定义前向运算
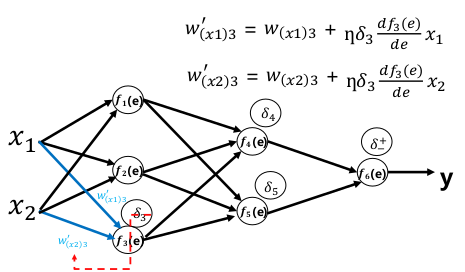
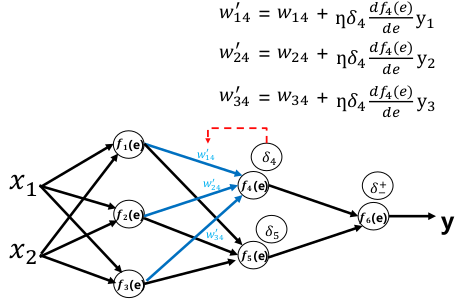
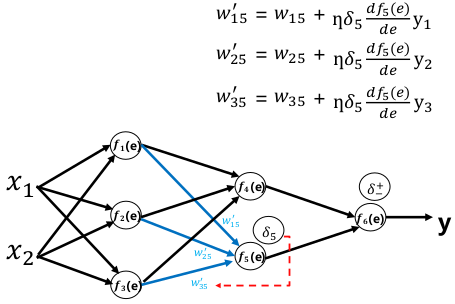
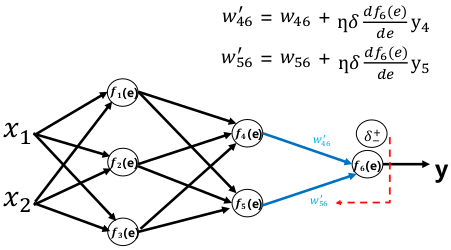
前向传播:
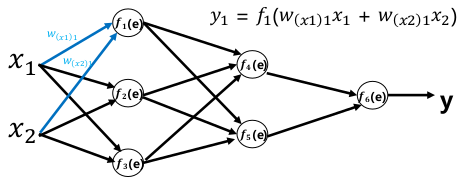
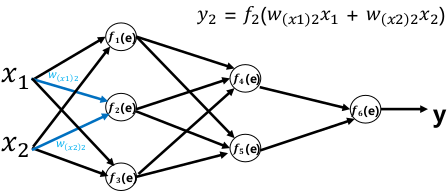
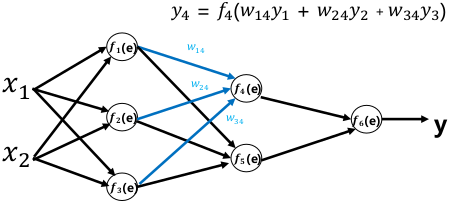
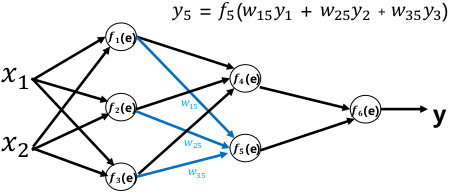
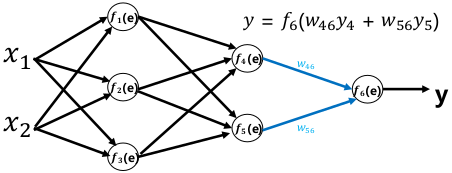
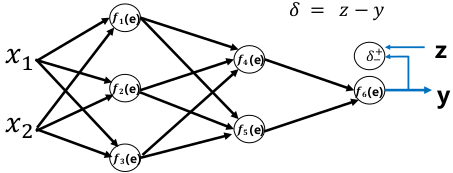
误差反向传播:
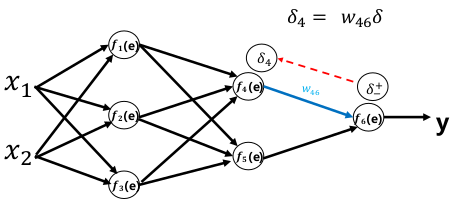
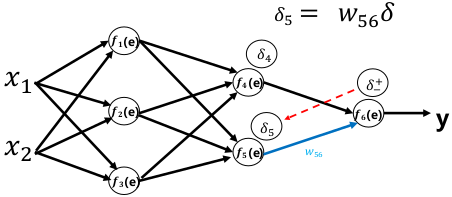
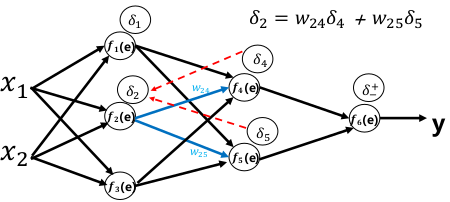
权重更新:
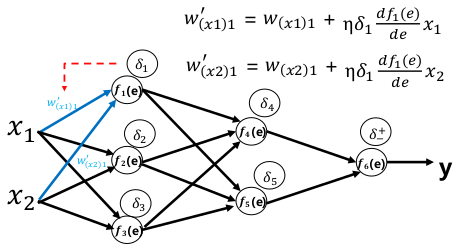
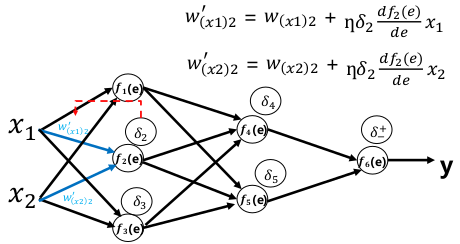
梯度消失
sigmoid梯度最大值是1/4,通常w通常小于1,所以 \(\sigma^{'}(x)*w\) 小于1,而且层数太多,导致链式求导后的导数越来越小
梯度爆炸
同上,当w大于4时,\(\sigma^{'}(x)*w\) 大于1,一层层积累,会使梯度指数增大
关于梯度消失和梯度爆炸,网上有非常多的解释,比如这个
神经网络的架构设计
- 神经网络准确率与深度的关系
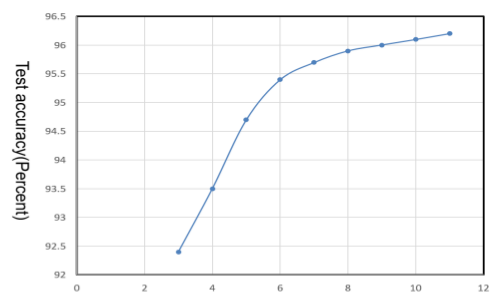
- 与参数的关系
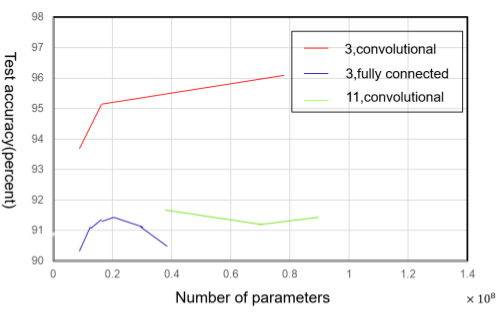
(参数太多会导致过拟合,测试集精度降低)
- 与连接的关系
默认的神经网络采用矩阵W描述线性变换,每个输入单元连接到每个输出单元。而许多专有网络具有较少的连接,使得输入层中的每个单元仅连接到输出层单元的一个小子集。这些减少连接数量的策略减少了参数的数量以及用于评估网络的计算量,但通常高度依赖问题本身。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号