Machine_Learning_in_Action07 - AdaBoost
AdaBoost
通过结合相似的分类器进行性能提高
使用AdaBoost算法
处理分类不平衡问题
目录
- 元算法(meta-algorithm)是对其他算法进行组合的一种方式
- AdaBoost 一种监督学习方法,是一种元算法
核心概念
booststraping
自助法,依靠你自己的资源
- 一种有放回的抽样方法
- 是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法
- 小样本效果好,通过方差的估计可以构造置信区间等
bagging
booststrap aggregating 的缩写
- 多次执行booststraping
- 每轮训练集从初始的训练集中随机取出n个训练样本组成
- 每个样本可能在某训练集中出现多次,或者不出现
- 训练后得到n个预测函数
- 对分类问题(离散值预测问题)采用投票方式,对回归问题(连续值预测问题)采用简单平均方式(或加权)判别
boost
提升算法
- 主要是adaboost(adaptive boosting)
- 初始化时对每个训练赋予相同的权重 \(\frac{1}{n}\),然后用其对训练集训练t轮
- 每次训练后对训练失败的数据赋予较大的权重,即让学习算法在后续学习中集中对比较难的训练数据进行训练
- 得到m各个预测函数,每个函数也有一个权重,预测效果好的函数权重大,反之小
- 对分类和回归问题分别进行有权重的投票和平均
- 训练思想类似bagging,但训练时串行的
- 第K个分类器训练时,关注对前k-1个分类器中的错误,不是随机取样本,而是加大去这些分错的样本的权重
bagging vs. boosting
- 主要区别是去样本的方式不同
- bagging 是均匀取样
- boosting 根据错误率采样
- 所以,bossting精度高于bagging
- boosting中的一种改进型adaboost方法在邮件过滤、文本分类中有很好的性能
- bagging 函数可以并行生成,而boosting只能顺序生成
- 对于神经网络这样的消耗时间的算法,bagging可通过并行节省大量的时间开销
gradient boost
boosting是一种思想,Gradient Boosting 是一种实现
- 主要思想是,新模型是对旧模型在损失函数的梯度下降方向的改进
- 损失函数描述模型的不靠谱程度,损失函数越大模型越不靠谱
- 如果新模型能够让损失函数持续下降,则说明模型在不停的改进
Random Forest
随机森林
- 随机森林
- 使用随机的方式建立一个森林
- 森林由很多决策树组成,每颗树是相互独立的
- 预测
- 当有新样本时,每棵树都对其进行判断,然后投票分类
- 构建:采样和完全分裂
- 随机采样,分为行采样和列采样
- 行采样为有放回采样,采样中可能有重复样本
- 每棵树的输入样本都不是全部样本,相对来说不容易出现过拟合
- 列采样是从M个特征中选出m个
- 然后使用完全分裂的方式建立决策树
- 这样的决策树的某一个叶子节点要么是无法继续分裂,要么里面所有样本都指向同一分类
- 随机采样,分为行采样和列采样
- 一般决策树都会进行剪枝,但这里不做剪枝
- 由于之前的行、列采样都是随机采样,所以不剪枝也不会过拟合
- 这种方法得到的每颗树都是很弱的,但大家组合起来就很厉害了
- 相当于每颗树都是某个窄领域的专家,对于新样本,用不同的角度看待它,最终由各个专家投票得出结果
基于多样本的分类器
-
优点
- 低泛化误差,易于写代码,与很多分类器一起工作,没有参数需要调整
-
缺点
- 对奇异点敏感
-
集成方法/元算法的本质
- 使用不同的设置得到的模型,或使用不同的子数据集得到的模型
基于数据集随机多重抽样的分类器:bagging
booststrap aggragating 的缩写,叫做自助法集成算法
有放回采样多次,得到n个数据集,用同一种算法训练出n个模型,对于新样本得到n个结果,然后对其投票或者取平均
Boosting
提升算法
类似于bagging,只是训练时顺序执行,其中一个最流行的版本是AdaBoost(Adaptive Boosting)
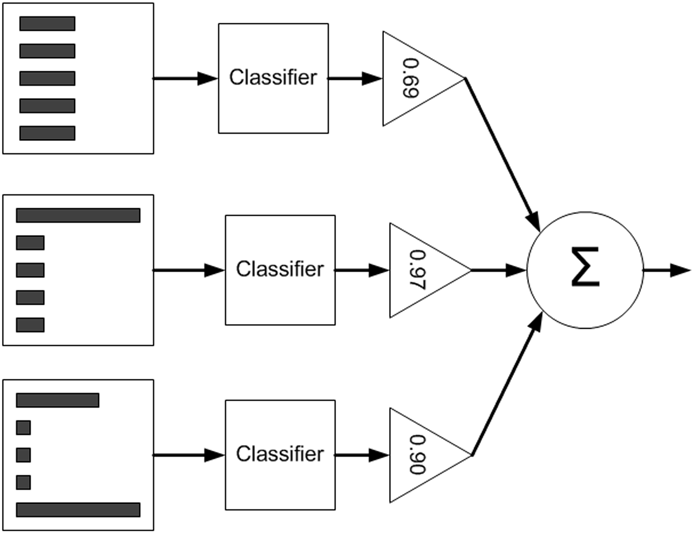
训练:基于错误提升分类器的性能
- 初始化时对每个训练赋予相同的权重 \(\frac{1}{n}\),然后用其对训练集训练t轮
- 每次训练后对训练失败的数据赋予较大的权重,即让学习算法在后续学习中集中对比较难的训练数据进行训练
- 得到m各个预测函数,每个函数也有一个权重,预测效果好的函数权重大,反之小
预测函数的权重为
\[\alpha = \frac{1}{2}ln(\frac{1-\varepsilon}{\varepsilon})
\]
\(\varepsilon\) 是错误率(分类错误数除以总样本数)
创建一个弱学习器
import numpy as np
def loadSimpData():
datMat = np.matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = np.inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = \
stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = np.mat(np.ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" %(i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
if __name__ == '__main__':
data, labels = loadSimpData()
print(data, labels)
D = np.mat(np.ones((5, 1)) / 5)
buildStump(data, labels, D)
实现完整 AdaBoost 算法
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1))/m)
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
print("D:",D.T)
alpha = float(0.5*np.log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print("classEst: ",classEst.T)
expon = np.multiply(-1*alpha*np.mat(classLabels).T,classEst)
D = np.multiply(D,np.exp(expon))
D = D/D.sum()
aggClassEst += alpha*classEst
print("aggClassEst: ",aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))
errorRate = aggErrors.sum()/m
print("total error: ",errorRate,"\n")
if errorRate == 0.0: break
return weakClassArr
def adaboost_test1():
data, labels = loadSimpData()
print(data, labels)
classes = adaBoostTrainDS(data, labels, 9)
print(classes)
测试
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
print(aggClassEst)
return np.sign(aggClassEst)
def adaboost_test2():
data, labels = loadSimpData()
print(data, labels)
classes = adaBoostTrainDS(data, labels, 9)
print(classes)
ret = adaClassify([0,0], classes)
print(ret)
ret = adaClassify([[5,5], [0,0]], classes)
print(ret)
例:在困难数据集上使用 AdaBoost
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
def adaboost_test3():
testdata, testlabels = loadDataSet('horseColicTest2.txt')
classes = adaBoostTrainDS(testdata, testlabels, 10)
prediction = adaClassify(testdata, classes)
print(prediction)
err = np.mat(np.ones((67,1)))
errnum = err[prediction!=np.mat(testlabels).T].sum()
print(errnum, err.sum())
不均衡分类问题
数据不均衡
性能度量
- Precision
\[Precision = \frac{TP}{TP + FP}
\]
- Recall
\[Recall = \frac{TP}{TP + FN}
\]
- ROC
TP-FP 曲线
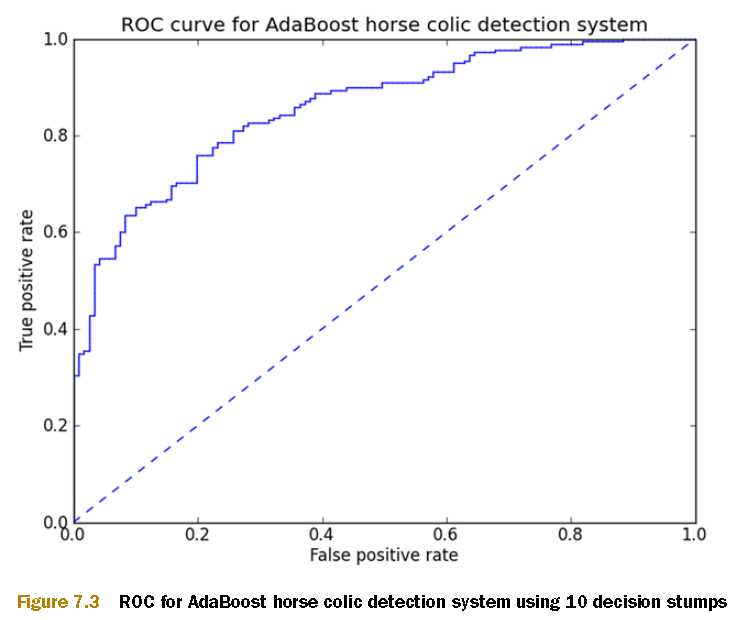
通过调整ROC阈值可以“提高”分类器性能
代价敏感学习
- 代价矩阵
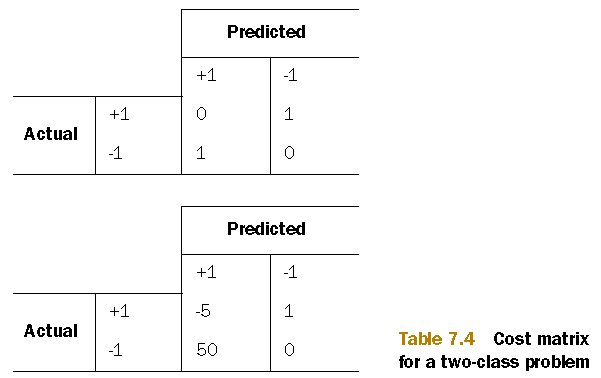
两种代价矩阵。第一种代价计算方法是 \(TP*0+FN*1+FP*1+TN*0\),第二种代价计算法方法是 \(TP*(-5)+FN*1+FP*50+TN*0\)。
对错误结果(FP,FN)使用较大代价,正确结果(TP,TN)使用小代价,甚至负代价
过采样与降采样
- 过采样
- 对数据量小的类进行复制样本
- 降采样
- 对数据量大的类进行删除样本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号