Machine_Learning_in_Action03 - Decision_trees
Decision Trees
decision tree algorithm
测量数据一致性
使用递归构建决策树
使用matplotlib展示决策树
- 决策树相对knn的优势是对数据有一定的洞见,能帮助人们理解数据
- 决策树常用于专家系统
- 用决策树得到的规则常与人类专家的经验比较
- 实现 ID3 算法
决策树
-
优点:
- 计算量少
- 便于人们理解
- 允许有缺失值
- 可以处理无关特征
-
缺点:
- 易过拟合
-
适用数值类型:
- 数值型
- 名词性数据
-
相关理论:
- 信息论 - 熵
-
基本思路:
- 首先决定在哪个特征上分割数据集,为此,需要尝试每个特征,然后找出最好的结果。
- 然后将数据集按照上一步选出的特征分割数据集
- 遍历每个分支,如果该分支的所有数据都分为同一类,则该分支已正确分类,无需继续分割;否则重复上述两个步骤
- 步骤:
- 收集数据
- 准备,需要离散数据,连续性数据需要转换为离散数据
- 分析,可视化
- 训练:构建决策树
- 测试:计算误差
- 应用
数据
判断五种动物能否不浮出水面而能生存,以及是否有脚蹼
|Can survive without coming to surface? |Has flippers?| Fish?|
| - | - | - | - |
|1| Yes| Yes| Yes|
|2| Yes| Yes| Yes|
|3| Yes| No| No|
|4| No| Yes| No|
|5| No| Yes| No|
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
信息增益
定义
来源于信息论,信息增益为数据集分割前后信息熵之差
信息量:是对信息的量化
\[l(x_i) = log_2{p(x_i)}
\]
信息熵:信息量的期望值
\[H = - \sum_{i=1}^{n}{p(x_i)log_2{p(x_i)}}
\]
\(i\) 是指第i类
实现
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
按照属性分割数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def splitDataSet_test():
dataSet, labels = createDataSet()
ret = splitDataSet(dataSet, 0, 1)
print(ret)
选择最好的特征
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def chooseBestFeatureToSplit_test():
dataSet, labels = createDataSet()
best_feature = chooseBestFeatureToSplit(dataSet)
print(best_feature)
创建树
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def createTree_test():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels)
print(t)
可视化决策树
def plotNode(nodeTxt, centerPt, parentPt, nodeType, arrow_args):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt, decisionNode, leafNode, arrow_args):
numLeafs = getNumLeafs(myTree)
getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode, arrow_args)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key), decisionNode, leafNode, arrow_args)
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode, arrow_args)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree, decisionNode, leafNode, arrow_args):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '', decisionNode, leafNode, arrow_args)
plt.show()
def plot_tree1():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels)
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
createPlot(t, decisionNode, leafNode, arrow_args)
- 结果
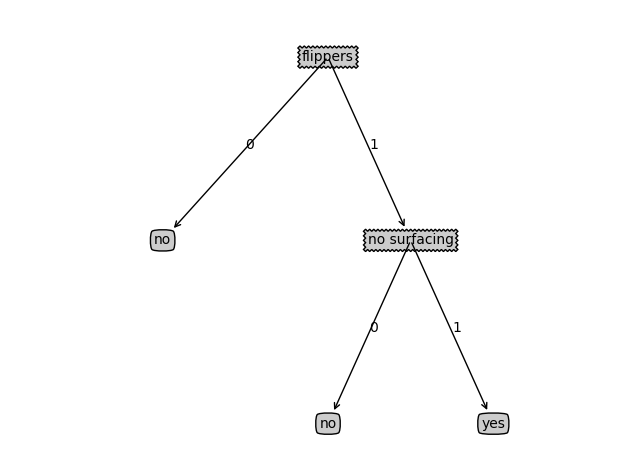
使用决策树分类
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else: classLabel = secondDict[key]
return classLabel
def classify_test():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels.copy())
print(dataSet, labels)
print(t)
label = classify(t, labels, [1,0])
print(label)
完整代码
import os
import operator
import math
import numpy as np
import matplotlib.pyplot as plt
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * math.log(prob,2)
return shannonEnt
def entropy_test():
dataSet, labels = createDataSet()
ent = calcShannonEnt(dataSet)
print(ent)
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def splitDataSet_test():
dataSet, labels = createDataSet()
ret = splitDataSet(dataSet, 0, 1)
print(ret)
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def chooseBestFeatureToSplit_test():
dataSet, labels = createDataSet()
best_feature = chooseBestFeatureToSplit(dataSet)
print(best_feature)
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def majorityCnt_test():
dataSet, labels = createDataSet()
labels_sort = majorityCnt(labels)
print(labels_sort)
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def createTree_test():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels)
print(t)
# plotting0
def plotNode(nodeTxt, centerPt, parentPt, nodeType, arrow_args):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def createPlot(decisionNode, leafNode, arrow_args):
fig = plt.figure(1, facecolor='white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon=False)
plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode, arrow_args)
plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode, arrow_args)
plt.show()
def plot_tree0():
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
createPlot(decisionNode, leafNode, arrow_args)
# construct tree
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def tree_test():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels)
numLeafs = getNumLeafs(t)
depth = getTreeDepth(t)
print(t)
print(numLeafs, depth)
# plotting1
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt, decisionNode, leafNode, arrow_args):
numLeafs = getNumLeafs(myTree)
getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode, arrow_args)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key), decisionNode, leafNode, arrow_args)
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode, arrow_args)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree, decisionNode, leafNode, arrow_args):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '', decisionNode, leafNode, arrow_args)
plt.show()
def plot_tree1():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels)
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
createPlot(t, decisionNode, leafNode, arrow_args)
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else: classLabel = secondDict[key]
return classLabel
def classify_test():
dataSet, labels = createDataSet()
t = createTree(dataSet, labels.copy())
print(dataSet, labels)
print(t)
label = classify(t, labels, [1,0])
print(label)
if __name__ == '__main__':
# entropy_test()
# splitDataSet_test()
# chooseBestFeatureToSplit_test()
# majorityCnt_test()
# createTree_test()
# plot_tree0()
# tree_test()
# plot_tree1()
classify_test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号