
OO第一单元总结
OO第一单元总结
第一单元的作业为表达式求导,三次作业层层递进,目标为掌握面向对象的基本思维方式,体会面向对象特性为程序带来的便捷之处。
Homework_1
一、程序结构
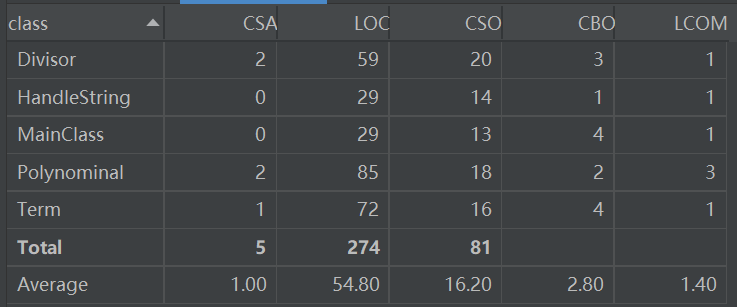
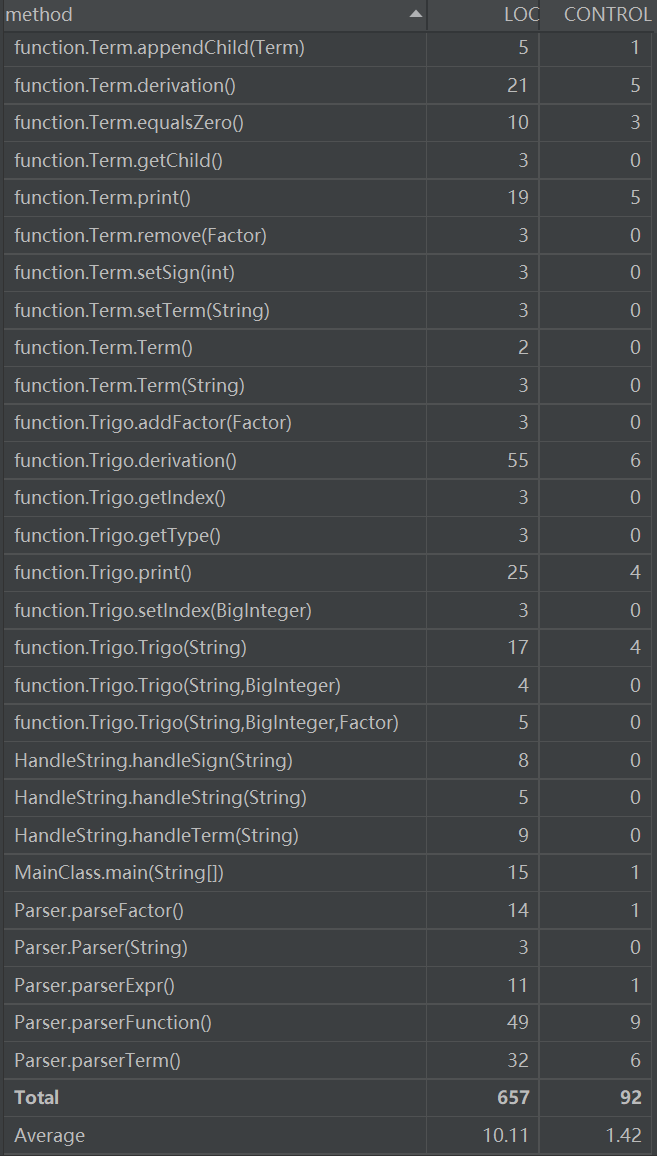
可以看到MainClass和Term类与其他类耦合度较高,Polynominal类内聚度缺乏程度较高。但总体来说,基本符合高内聚、低耦合的原则。
 !
!
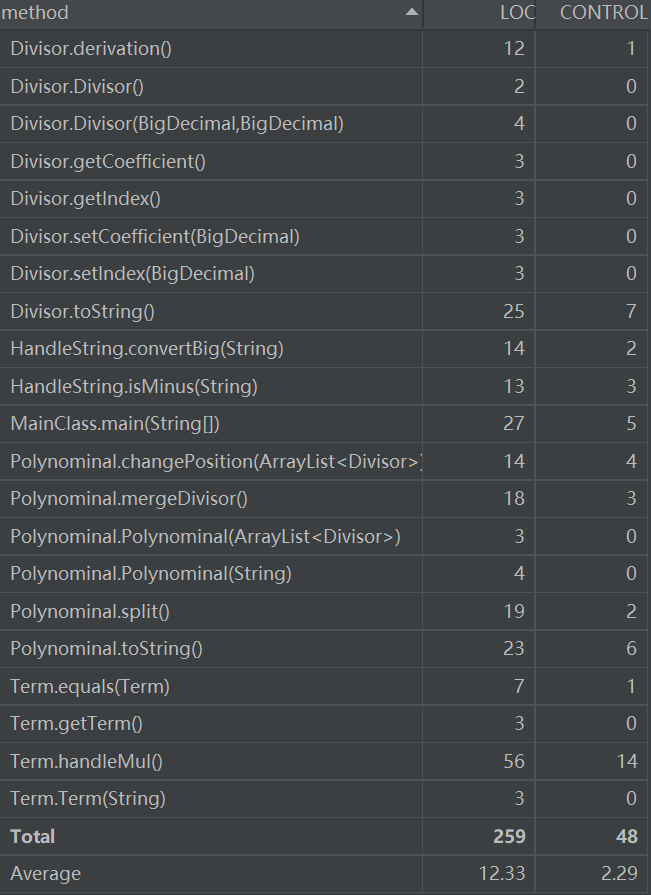
- 分为五个类,Mainclass为主类,负责控制程序整体过程,HandleString为处理字符串类,负责对输入的字符串进行处理,Polynominal为表达式类,负责分隔项等与表达式相关的操作,Term为项类,主要负责处理项内部的乘法,进行化简,Divisor为因子类,包括系数和指数两大属性。
过程大致如下:读入字符串后,按照正则表达式规定格式分割项,再将每个项进行简化处理,全部变为因子形式,后对每个因子 进行求导,最后输出。
-
优点:比较简单,逻辑较为清晰
缺点:可扩展性差,基本只能针对多项式求导
二、 bug分析
-
自己的bug
- 笔者在强测和互测中均被测出bug,原因在于将表达式中的字符串类型的数字转化为BigInterger类型的数字时(HandleString中的convertBig方法),正则表达式有误,将[0-9]+误写为[1-9]+,这样写的话,单个数字0以及+0、-0java不会报错,BigInterger可以对其进行处理,但是遇到+-0或者符号和0中间有空格的情况java则会抛出异常,未通过的三个测试点均是源于此bug。
- 分析此bug出现的原因,根源在于考虑不周全以及测试不全面。误以为BigInterger不能处理前导0的情况,便检测遇到的第一个不为0的数字,但是漏考虑了只有0的情况。测试时考虑了数字前有空格、有+-等连续符号的情况,但是未考虑到单个数字0前面的特殊情况,导致未发现此bug。
- 实则将[1-9]+改为[0-9]+便可修补此bug,无需修改代码结构、方法内部逻辑。
-
别人的bug
-
为追求化简将-1中的1省去而导致出现 -* 的格式错误
-
通过观察对方代码,发现若项为0,则不进行输出,未考虑到只有一项的情况,构造数据hack成功
-
正则表达式有误,导致识别出的格式有误
-
三、测试策略
-
参考评论区大佬提供的递归下降的测试样例构造方法,自动生成样例,进行覆盖性测试;手动构造特殊情况样例,特别是指导书中出现的特殊形式,需要特殊处理的,进行特例测试;观察别人代码,查看细节是否有漏洞
-
利用python,驱动测试数据输入jar包,并将输出结果与sympy生成的标准结果进行对比,判断程序正确性。
由于时间安排的不合理,笔者直到互测开始才把测试样例以及评测机写完,所以自己的代码草草地测试后便提交了上去,未考虑全面特殊情况,而且自动生成测试样例同样不易生成如此特殊的样例,所以在强测和互测中出现了bug。但是在测试他人代码时,评测机发挥了一定的作用。
Homework_2
一、程序结构
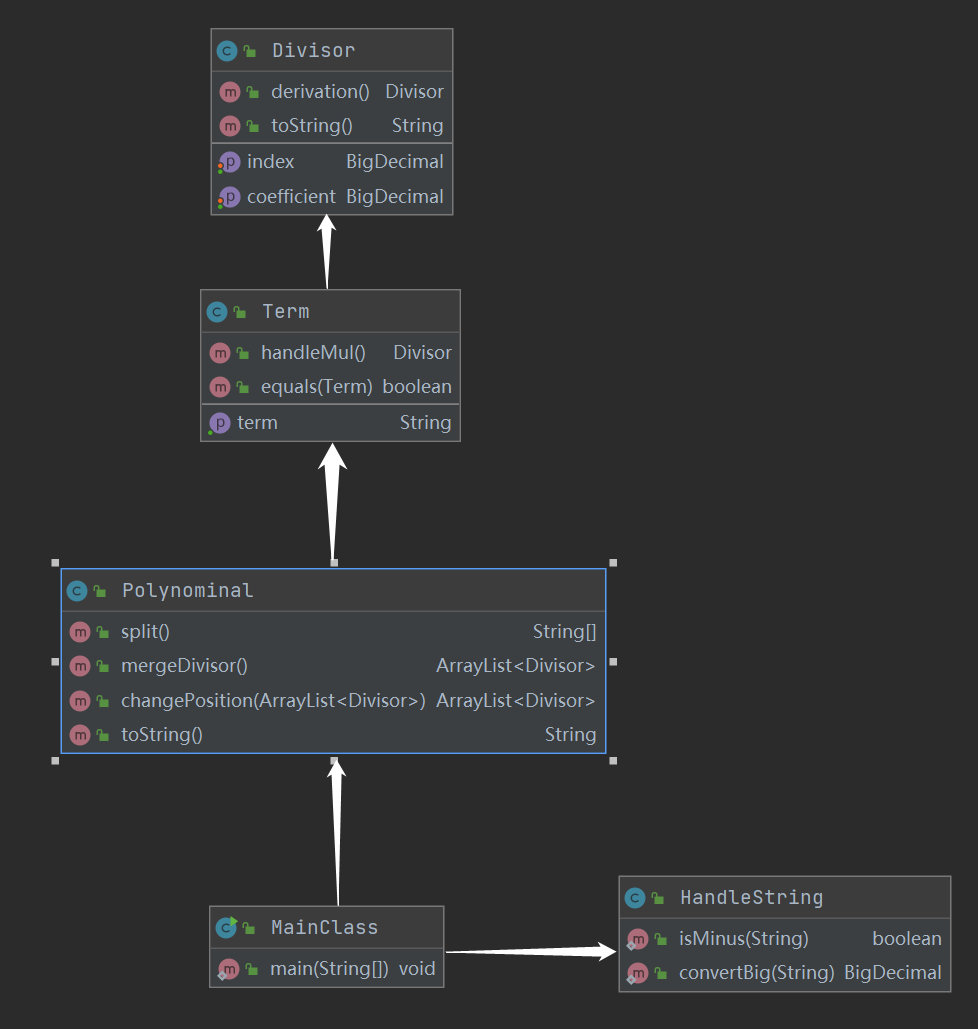
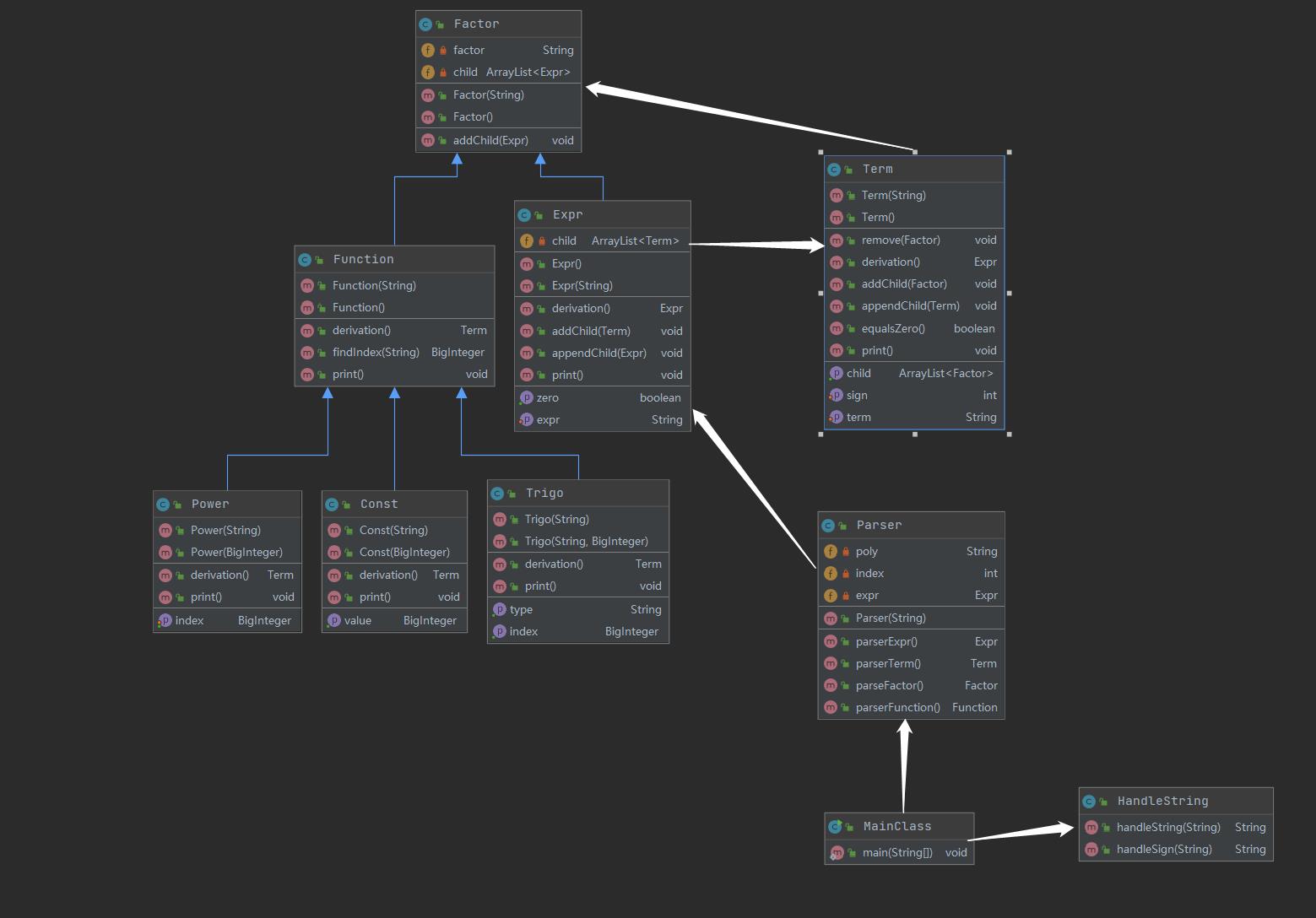
可以看到,Parser类、Funtion类、Term类与其他类耦合度较高,具体原因初步猜测为需要在Parser类中建立表达式树,三个类继承于Funtion类,而Term类向上联系表达式、向下联系因子。内聚度都较为良好。
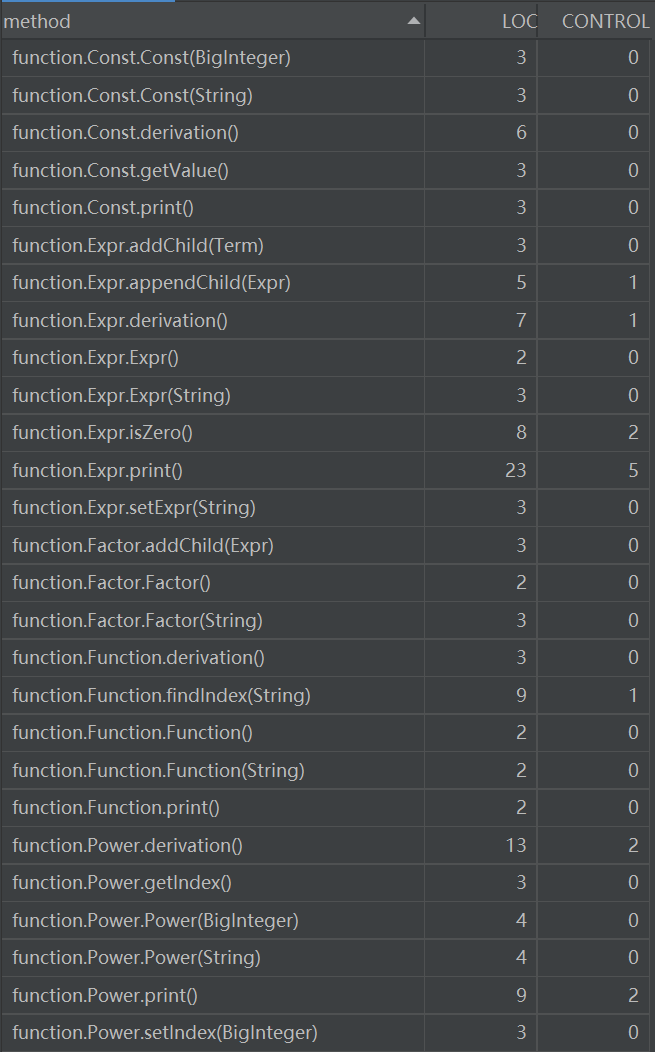

-
分为以下的类:Const类,为常数类,Power类,为幂函数类,Trigo类,为三角函数类,均继承Funtion类(函数类),拥有获得对应指数或值、求导、打印方法;Expr类,为表达式(因子)类,拥有求导、打印等方法,与Funtion类一同继承Factor类(以上继承关系均处于a属于b,则a继承b考虑)。Term类,为项类,拥有对项处理并打印的方法,Parser类,解析类,通过递归下降的方法,对表达式、项、因子递归解析,构成表达式树。HandleString类,对符号、空格进行预处理,以便后续的解析。
过程大致如下:首先对输入的字符串进行预处理,例如去掉空白符(保证数据一定合法),简化符号等,再进入Parser类递归解析,构成表达式树,之后利用各个表达式、项、不同函数的求导规则相应求导,构成求导后的表达式树,最后进行输出。
-
优点:思路较为清晰,每个类都有对应的职责和与其他类的关系
缺点:代码有些地方有些冗余,可以适当简化;未对化简进行过多处理,只是考虑了项为0不输出的情况
二、bug分析
-
自己的bug
笔者在强测和互测中未出现bug。可能因为没怎么优化 😮
-
别人的bug
笔者在本次测试中并未发现别人的bug,但是通过观察公开的测试样例,发现大多是由于优化,例如合并同类项、拆解括号、化简三角函数等产生了计算错误、输出格式错误等问题。
三、测试策略
- 由于笔者能力有限,对如何控制测试样例的括号嵌套层数以及合理性的方法掌握不到位,所以未采用自动生成样例的方法,而是手动构造测试样例。但未充分考虑优化可能出现的锅,所以大多还是正常的格式有关的样例。
- 依旧采用测评机自动测评。但由于测试样例较弱,并且对别人的代码设计结构未深入研究,未发现别人的bug。
Homework_3
一、程序结构
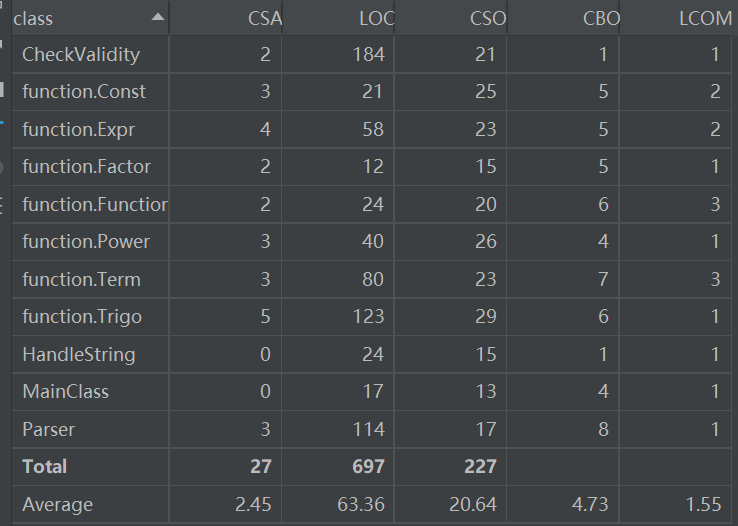
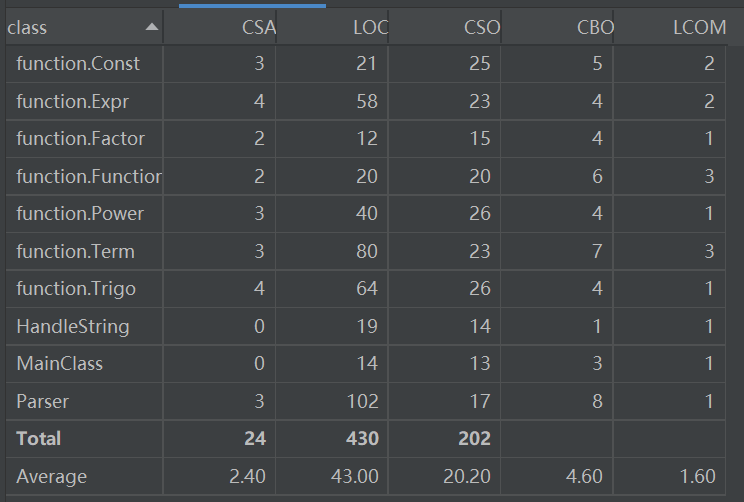
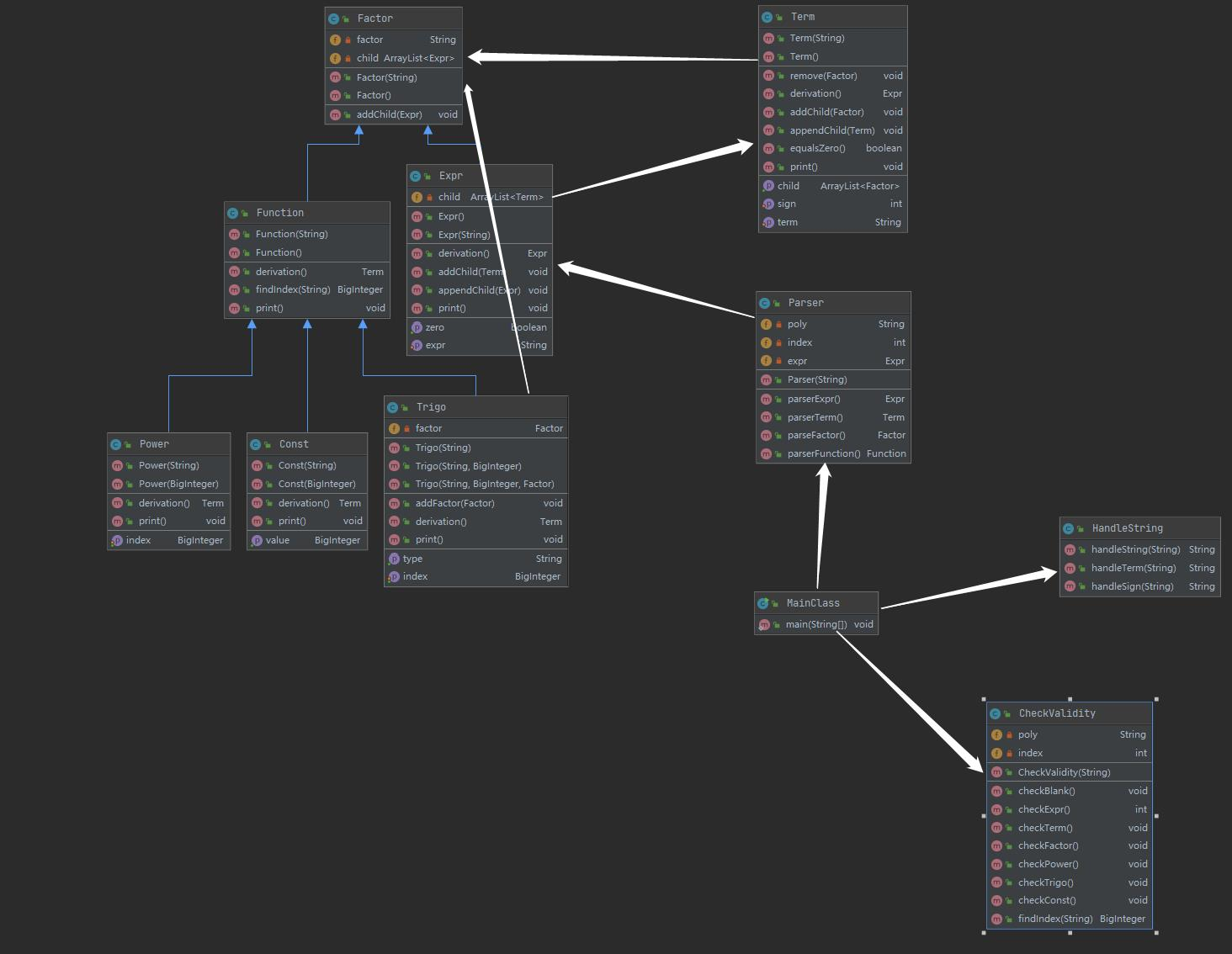
可以看出,Parser类、Funtion类、Term类、Trigo类与其他类耦合度较高,前三类与第二次作业相同,Trigo类由于需要判断其中的Factor,需要嵌套,所以耦合度升高。内聚度依旧较为合理。

-
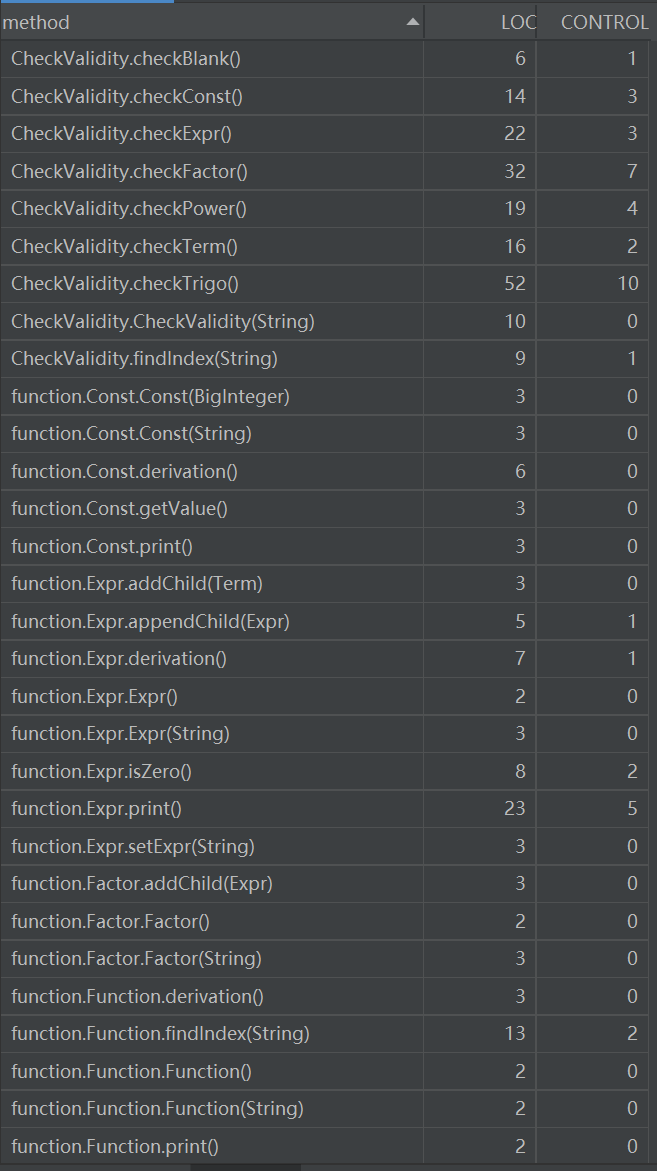
与第二次作业类的情况大致相同,加入了一个CheckValidity的类,用来检查输入的表达式是否合法,若不合法则输出“WRONG FORMAT!”并退出程序,合法才可以进行后面的求导工作。后续过程与第二次作业基本相同,只不过对三角函数的处理会更加复杂些,加入了嵌套求导规则
-
优点:各个类划分较为清晰,关系也较为明确
缺点:后来仔细想了想,CheckValidity可以在Parser的过程中完成,无需再多建一个类;未充分利用面向对象编程的优越性,如继承(感觉自己使用的继承没有深入精髓)、接口等。
二、 bug分析
-
自己的bug
- 笔者在互测中未被发现bug,但在强测中被发现了一个bug。原因在于判断合法性时,判断三角函数内的表达式因子合法性递归返回后,未判断是否已经到达字符串结尾,导致当出现类似格式错误的测试样例时,会出现下标越界的异常抛出。
- 考虑不周全以及测试不全面依旧是出现此bug的罪魁祸首。
- 修复bug方法:在判断表达式因子返回后,先判断是否到字符串结尾,若已经到达则输出“WRONG FORMAT!”并结束程序,如未到达结尾再进行后续判断。
-
别人的bug
- 在优化括号时,误拆解了不能拆解的括号,导致求导错误
- 通过观察程序发现,对方未考虑表达式后括号前的空格,导致若出现此类情况,输出格式错误
- 处理表达式内部格式时有误,未能正确判断合法性
三、测试策略
基本同第一二次作业。稍稍不同的是,由于第三次作业是建立在第二次作业的基础上的,而第二次作业的样例仍应输出正确结果,所以采用了部分第二次作业互测错误率较高的用例,有一定的收获。
重构经历总结
-
由于第一次作业较为简单,只是多项式而且无需格式检查,所以将因子列为了一类,且包含指数和系数两个属性,而且处理项的时候依据乘号分开,对指数和系数分别处理合并,这两项操作可以应用在第一次作业上,却拿后面的作业束手无策。而且此方法感觉面向对象的意味不强,局限性也较强,不是一个好的架构,几乎毫无扩展的空间,稍微扩充一点功能即需要重构,以后编程需尽力避免这种情况的发生(P.S.:因为第二次作业太痛苦了,还不如在第一次时间充裕的时候好好为后面做些准备,果然一时摸鱼的代价就是之后的万念俱灰: (
-
笔者在第二次作业时进行了全新的设计(就是重写),利用研讨课上大佬分享的递归下降方法依次解析表达式、项、因子,构建表达式树,再依据表达式树按照对应的求导规则求导。不仅对递归一知半解,数据结构也学的不太好的笔者在黑暗中,一边摸索着递归的层层嵌套,一边艰难的建着表达式树,最终成功的解析完成。之后的工作相对而言就会轻松一些,对三角函数、幂函数、常数依据相应的求导规则进行求导,对项的分支--因子采用乘法规则求导,对表达式的分支--项采用加法规则求导,最后再组建成一个表达式树,而输出其实与第一次作业倒是差别不大。遍历树依次输出即可。总的来说,此次重构是重新整理了思路,回归到了表达式求到的正确道路上,也初步领略了面向对象编程的好处(虽然主要还是面向过程)。(P.S.:传说有四元组的方法,写起来会容易一些,但是想到第三次作业又要重构,所以放弃了)
-
有了第二次作业的基础以及递归下降的可拓展性,第三次作业相对来说就没有那么困难了。加入了合法性判断以及三角函数嵌套因子,由于当时认为加入一个判断合法性的类会更清晰,所以采用了增加类的方法(其实是觉得以自己的能力,边解析边判断会出大问题,但后来经身边的同学反应,认真点没啥问题……果然,不想动脑子就得动手,而且动手还很容易出bug)。在处理三角函数嵌套因子时,也无需对程序架构进行过多改动,只需在三角函数属性中加入因子类容器,并且添加求导法则即可,剩下的就让强大的递归下降来帮我们完成。总体来说,第三次除了debug时间有点长(有些第三次不适用的优化方法忘记改了,三角函数嵌套求导没太搞明白等问题困扰了我整个下午……后来发现它们的时候,还是觉得考虑全面些,想清楚再动手写比较重要),写代码的时间确实不长,而且思路很顺畅。果然好一些的架构会为今后工作的开展打下良好的基础。
心得体会
总的来说,第一单元作业经历了痛苦的过程,同时也有了蜕变。了解了哪些抽象实体适合被当做对象,创建一个类时需要包含哪些属性以及构造哪些方法;了解了某些情况下,面向对象相比于面向过程方法的优越性,比如求导过程的简化;了解了在面对一个大问题时,如何一步步化整为零,从全局考虑将问题拆解,有了整体视角后再逐个对细节进行攻破;了解了思考问题不能局限于眼前,更应该看到长远的需求,设计时应考虑得更加全面。
初步尝试了自己构造测试样例和搭建评测集,体会到了自动测评的简便性和相对全面性。也在debug的过程中领略到构造测试样例的小小要领,学习如何在整个程序中一步步找到埋藏在字里行间的bug,并且找到较为合理有效且简便的解决方式。从前,通过评测机给的测试样例就万事大吉,无需再进行全面的测试,而如今,却要全面、细致地测试自己的程序,提高了能力,也更贴近未来面对的开发工作。所以在这里体验的这些,都是过往从未有过的经历。
也有一些小小的遗憾,比如出现了两个比较明显的bug而自己并未发现,比如没有进行过多优化,只是化简了和零有关的项和指数,比如有些可能会使程序更加高效、更加简洁的知识没有用到,尚未领悟它的精髓,例如HashMap、lambda表达式等等。希望在未来,可以更好地使用工具,学习更多知识来使得自己的思维更靠近面向对象思维方式、掌握更多面向对象设计方法;希望在完成正确性的基础上,可以给自己施一些小小的压力,去尝试些本不能完成的事。
前路漫漫,愿负重前行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号