


PCIe【3】P2P/Lane
1. P2P
1.1 概述
p2p : peer-to-peer communication
第三方对端设备:和当前PCIe设备没有直接隶属关系,但可以通过PCIe总线从该设备的内存中获取数据。
P2P是指两个PCIe设备之间可以直接传输数据,无需通过主机内存(RAM)拷贝数据,也即无需经过RC。
1. EP设备直接P2P
Bios设置:启用PCIe Bifurcation。
-
两个PCIe设备可以直接传输数据
-
NVMe等第三方对端设备可以直接从PCIe设备的内存读取数据
-
同一插槽的x16拆分为x8+x8(需要BIOS/FW配置),因为插槽的x16实际上是连接到同一个PCIe Switch的
// 检查设备是否支持直接P2P
if (pci_p2pdma_distance(dev1, dev2) == 1)
{
pci_enable_p2p(dev1); // 启用P2P
}
2. 只经过Switch的P2P传输 EP1->Switch->EP2
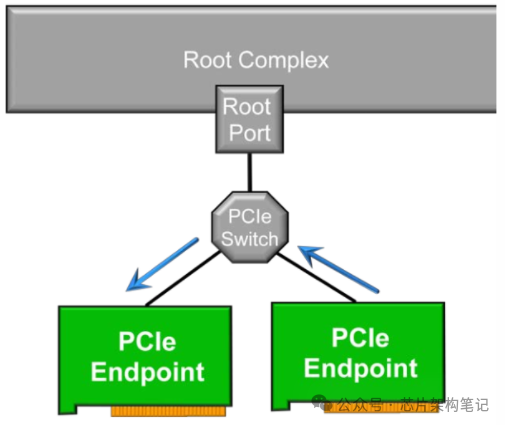
如果EP端的ATC(Address Translation Cache)声称其发出的访问请求是经过转换后的地址,且该地址刚好落在PCIe Switch的BAR范围内,则该请求不会到达RC,而是被Switch路由到该地址所对应的EP。也就是说,该访问请求绕过了IOMMU的隔离,进行了P2P传输。
需要注意的是,这种只经过Switch的P2P传输需要关闭PCIe Switch的ACS(Access Control Service)的p2p重定向(redirect)功能,否则redirect会将请求发给RC。
使用P2P后,如果禁用了ACS,带宽会增加,因为数据直接在设备间传输(直连路径),而不再需要通过RC。
3. 经过RC的P2P传输 EP1->RC->EP2
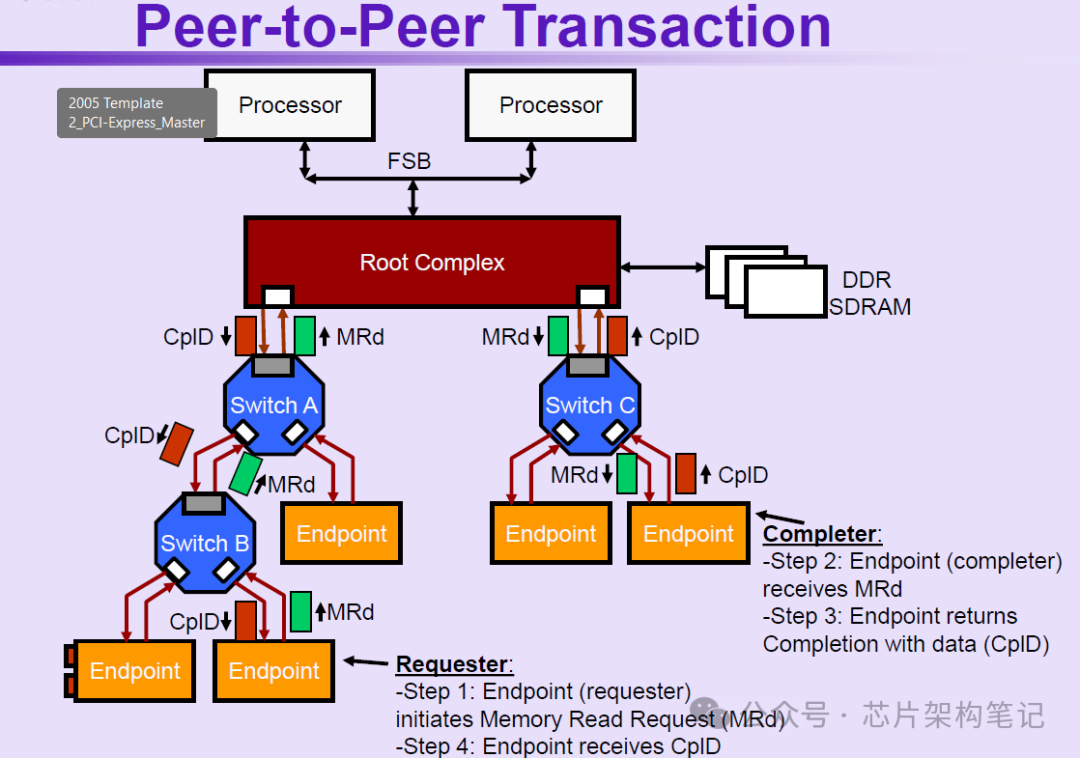
4. 经过片上网络NoC的P2P传输 EP1->RC->NoC->RC->EP2
这个过程可能也会经过Switch。当两个EP设备连接在芯片的不同位置或者不同die上时,P2P传输需要经过NoC。
1.2 一些其他概念
-
d2h: device to host,也就是设备到主机内存
-
h2d:host to device,也就是主机内存到设备
-
单向/双向:单向即A->B,双向即包含A->B和B->A。
P2P Disable走的是d2h和h2d,而不是p2p。
1.3 应用场景
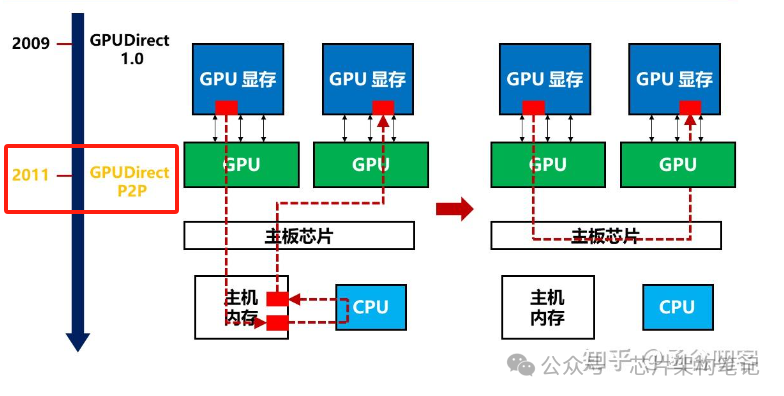
典型应用场景:GPU Direct,可实现GPU与其它设备之间的直接通信和数据传输,包括:
-
GPU Direct P2P
-
GPU Direct RDMA
-
GPU和网卡可以直接通过PCIe进行数据交互,也避免了跨节点通信过程中内存和CPU的参与。
-
通过GPUDirect Storage,GPU可以直接从存储设备(如固态硬盘SSD或NVMe驱动器)访问数据,而无需将数据先复制到CPU的内存中。
-
-
GPU Direct Storage
- 允许存储设备和GPU之间进行直接数据传输,绕过了CPU,减少数据传输的延迟和CPU开销。
1.3 P2P与SMMU
SMMU:System Memory Management Unit
| 架构 | 名称 | 实现技术 |
|---|---|---|
| x86 | IOMMU | Intel VT-d, AMD-Vi |
| ARM / AArch64 | SMMU | ARM SMMUv2, SMMUv3 |
SMMU的主要作用是:
-
将设备看到的IOVA(I/O Virtual Address)映射到物理地址(PA)
-
提供设备访问内存的地址转换和权限保护
-
支持DMA安全隔离(如虚拟机、容器等)
在大多数当前硬件和驱动实现中,SMMU对PCIe P2P流量的支持非常有限或不完整,因此为了稳定性和兼容性,系统通常会禁止在启用SMMU的同时使用PCIe P2P。
SMMU的设计初衷是保护系统内存不被恶意访问,它只对设备发起的DMA到系统内存DRAM进行地址转换和检查,但P2P通信可能不经过系统内存,而是使用设备之间的直接地址空间或通过PCIe内存映射(如ATS),所以SMMU不参与P2P流量的地址转换,且P2P请求可能会绕过SMMU的安全策略。
-
CPU和设备共享一个统一的地址空间(在ARM64/x86中是“物理地址空间”)
-
PCIe设备的BAR被映射到这个空间的某个区域
“直接地址空间”是指一个PCIe设备暴露给其他设备的、可直接访问的内存或寄存器区域,通常通过PCIe BAR(Base Address Register) 映射到系统地址空间(CPU或其他设备可以通过这个地址直接访问它)。
每个PCIe设备都有若干个BAR,用于声明它“拥有”的内存或I/O资源。
物理地址空间:
0x0000_0000 ────────────────┐
│ DRAM
0x8000_0000 ────────────────┤
│ PCIe Memory Space
0x9000_0000 ────────────────┤ ← GPU BAR 映射到这里
│
0xA000_0000 ────────────────┘
案例:
GPU A和GPU B都在SMMU的管理下,加入GPU B的内存通过PCIe BAR映射到某个地址空间,此时GPU A可以通过P2P进行访问,从而绕开SMMU的访问控制。
实际操作:

# 让指定的PCIe设备绕过SMMU的地址转换和保护机制
# 格式:smmu.bypassdev=<vendor_id>:<device_id>
smmu.bypassdev=0x1000:0x17 smmu.bypassdev=0x1000:0x15
2. PCIe ACS
2.1 概述
ACS : Access Control Services
ATS : Address Translation Services
ACS提供了一种机制,能够决定一个TLP被正常路由、阻塞或者redirect。通过在Switch上开启ACS,可以禁止P2P发送,强迫Switch将所有地址的访问请求发送到RC,从而避开P2P访问中的风险。
ACS的主要作用如下:
- 禁用P2P
ACS相当于一个gate-keeper,防止PCIe EP意外或故意写入对等端点上的无效/非法区域,造成未授权事件发生。
- 禁用ATS
通过ATS, 任何设备都可以声称它正在使用已经翻译过的地址,从而绕过IOMMU翻译。因此可以为任何给定的设备禁用ATS,防止设备忽略IOMMU并写入不应该访问的地址。
2.2 OS配置ACS
检查PCI网桥是否启用ACS:
sudo lspci -vvv | grep ACSCtl
如果行显示“SrcValid+”,则可能启用了ACS。查看lspci的完整输出,可以检查PCI桥是否启用了ACS。
sudo lspci -vvv
使用下面的命令使用setpci禁用ACS,用每个PCI桥的PCI总线ID替换03:00.0。
sudo setpci -s 03:00.0 ECAP_ACS+0x6.w=0000
使用脚本关闭系统ACS
# 获取系统中所有PCIe设备的BDF(Bus:Device.Function)地址列表
for BDF in `lspci -d "*:*:*" | awk '{print $1}'`; do
# skip if it doesn't support ACS
# 尝试读取设备的ECAP_ACS+0x6.w寄存器
sudo setpci -v -s ${BDF} ECAP_ACS+0x6.w > /dev/null 2>&1
# 若失败,返回非0
if [ $? -ne 0 ]; then
continue
fi
# 向ECAP_ACS+0x6.w写入0000,关闭ACS功能
sudo setpci -v -s ${BDF} ECAP_ACS+0x6.w=0000
done
-
ECAP_ACS+0x6.w: ACS扩展能力关键寄存器-
ECAP_ACS,ACS扩展能力在PCIe配置空间中的起始偏移(通过遍历PCIe扩展能力链表找到) -
+0x6.w,ACS控制寄存器(16位),位于ACS能力结构的第6字节处(偏移量+0x6)
-
备注:博通switch,纯Base模式下默认支持p2p,需要在BIOS或OS侧关闭ACS服务;base+fw和ssw模式,需要在配置文件中对相关寄存器做配置。
PCIe 4.0 x16的理论带宽:16 GT/s × 16 Lanes × 128/130 ≈ 31.5 GB/s(或 252 Gbps)
- PCIe 4.0 的基频:16 GT/s(Gen3为8 GT/s,Gen5为32 GT/s)
- x16 表示使用 16 对 收发通道(TX/RX)
- PCIe 4.0 使用 128b/130b 编码(Gen3及以前为8b/10b),即每130位信号中,128位为有效数据,2位为同步头,因此编码效率为128/130
- 1 Byte = 8 bits
3. PCIe Lane Enable
关于PCIe Lane Enable功能的说明(基于寄存器0xFFF0_01A0配置):
-
基础约束条件
- 每个设备的最大可用Lanes数量由OTP中的产品配置数据(PCD)预先定义,这是硬件层面的物理限制
- Lane Enable寄存器只能禁用PCD已启用的Lanes,无法启用PCD未配置的Lanes
-
动态降配机制
- 允许从PCD定义的最大Lane数开始,通过写PCIE Lane Enable寄存器(SBR偏移0x007D)向下调整到更少的Lanes
- 示例:如果PCD配置为x16,可通过该寄存器降配为x8/x4/x1,但无法超过x16
-
节能与资源优化
- 功耗控制:禁用Lanes后,对应SerDes(串行解串器)会进入最低功耗状态,同时触发时钟门控
- 总线资源节省:减少的Lanes会降低内部peer-to-peer路径,从而在PCIe枚举时减少总线号占用
-
寄存器操作
- 物理地址:0xFFF0_01A0(通过SBR偏移0x007D配置)
- 典型工作流:读取当前PCD配置 → 计算目标Lane数掩码 → 写入Lane Enable寄存器
注意:此操作通常需在初始化阶段完成,动态修改可能导致链路重建。实际可用Lane组合需参考具体芯片的电气布线约束(如x16可能仅支持拆分为x8+x8,不支持任意组合)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号