二.4 java高级—JVM
1.类加载过程:加载,连接(验证,准备,解析),初始化
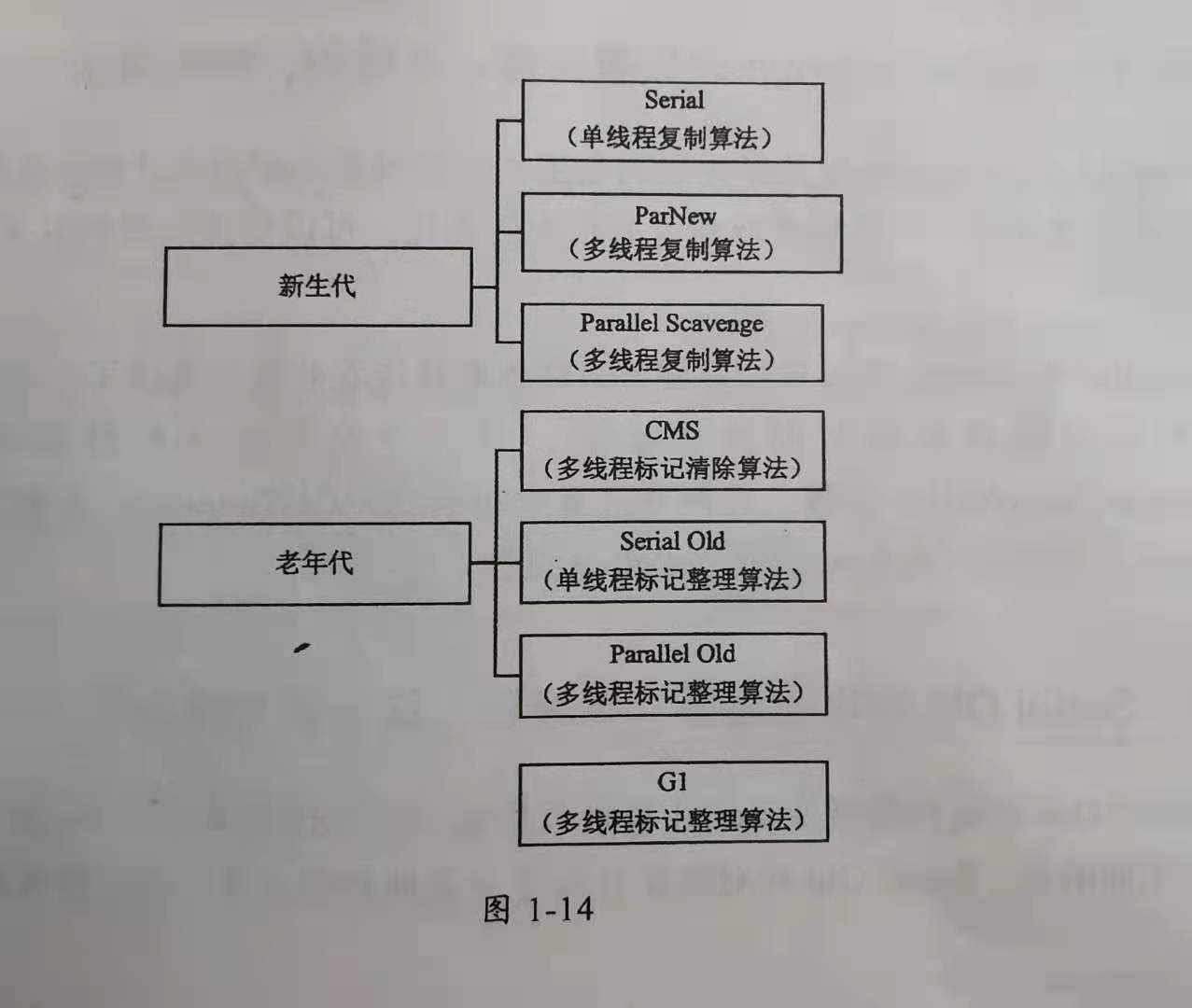
2.垃圾收集器:新生代:Serial,ParNew,Parallel Scavenge 老年代:CMS(标记清除算法),Serial Old,Parallel Old,G1(标记整理算法)
jvm体系总体分四大块:
-
jvm组成
-
类加载
-
java运行时数据区
-
垃圾回收
(1)对象的成员变量存在堆中,方法的局部变量存在栈中
一.JVM组成
-
①. 类加载器子系统
-
②. 运行时数据区[我们核心关注这里 的栈、堆、方法区]
-
③. 执行引擎(解释器和JIT编译器共存)
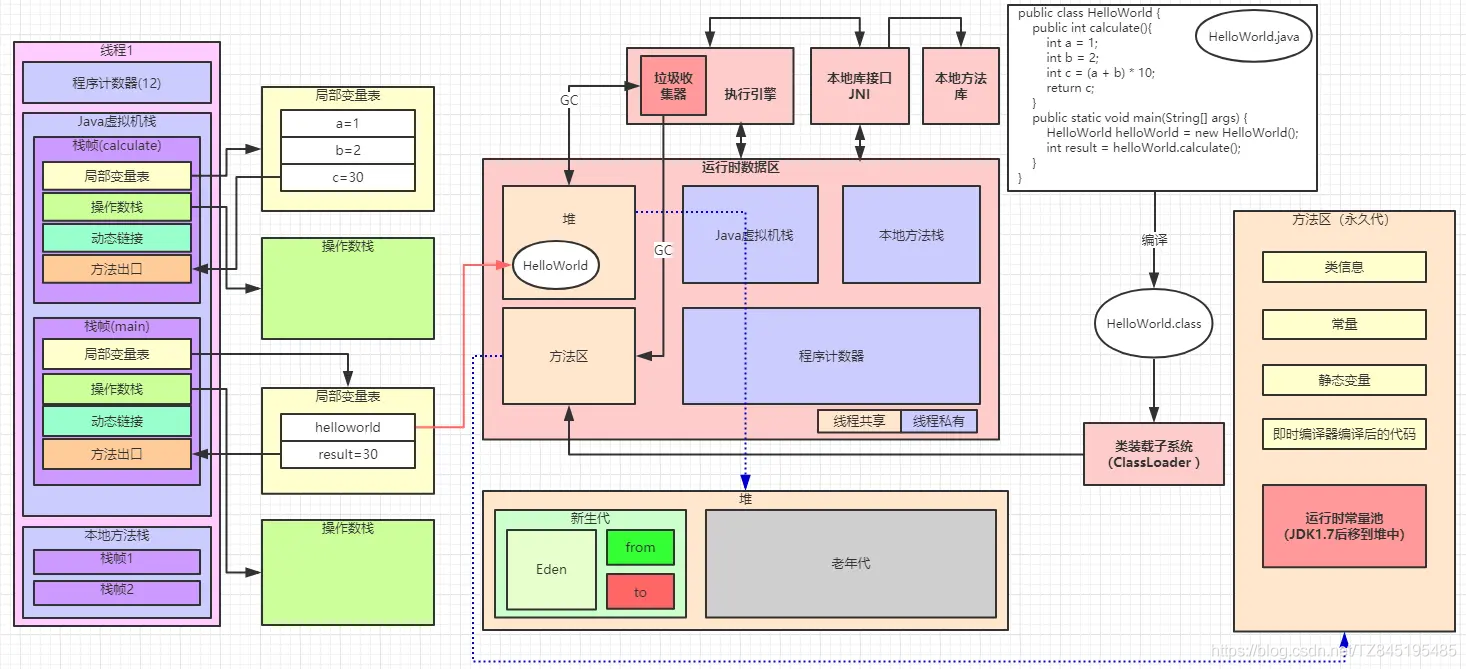
(1)执行引擎:解释器,JIT编译器,垃圾回收器
(2)基本类型变量和引用类型变量的引用(局部变量)存在虚拟机栈中,对象和数组存在堆中
二.类加载
加载机制是指类的加载、链接、初始化的过程

1.什么是类的加载、链接(验证,准备,解析)、初始化
加载:将类的class文件读取到方法区内,并在堆中创建一个该类的Class对象
(1)将类的class文件读取到方法去内
(2)将class文件所代表的静态结构转化为方法区的运行时数据结构
(3)在堆中创建一个该类的Class对象,作为方法区这些数据的访问入口
验证:验证这个class文件是否符合当前虚拟机的规范,保证虚拟机的安全
准备:为类中的静态变量在方法区分配内存并设置初始值(默认值)(这些内存是在方法区中进行分配)
(1)上面说的是类变量,也就是被 static 修饰的变量,不包括实例变量。实例变量会在对象实例化时随着对象一起分配在堆中。
(2)初始值,指的是一些数据类型的默认值
解析:将常量池中的符号引用替换为直接引用(str=“hello”)(str1="hello",str2=str1,编译时常量池中存的是str1,解析阶段会替换为"hello"的地址)
初始化:执行类构造器的<client>方法对类进行初始化。<client>方法是在编译阶段由编译器自动收集类中的静态变量和静态语句块的赋值操作组成的
2.类加载器:
启动类加载器,扩展类加载器,应用程序类加载器
3.jvm通过双亲委派机制对类进行加载
三.java运行时数据区
1.组成

堆也叫:运行时内存 线程私有/线程共享
(1)程序计数器无内存溢出问题。虚拟机栈描述java方法的执行过程。本地方法栈为native方法服务
(2)运行时常量池
属于方法区一部分,用于存放编译期生成的各种字面量和符号引用。编译器和运行期(String 的 intern() )都可以将常量放入池中。内存有限,无法申请时抛出 OutOfMemoryError。
(3)对象的内存布局
在 HotSpot 虚拟机中,分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
实例数据(Instance Data):程序代码中所定义的各种类型的字段内容(包含父类继承下来的和子类中定义的)。可以理解为:运行时成员变量和对象绑定,存储在堆中
2.java运行时内存
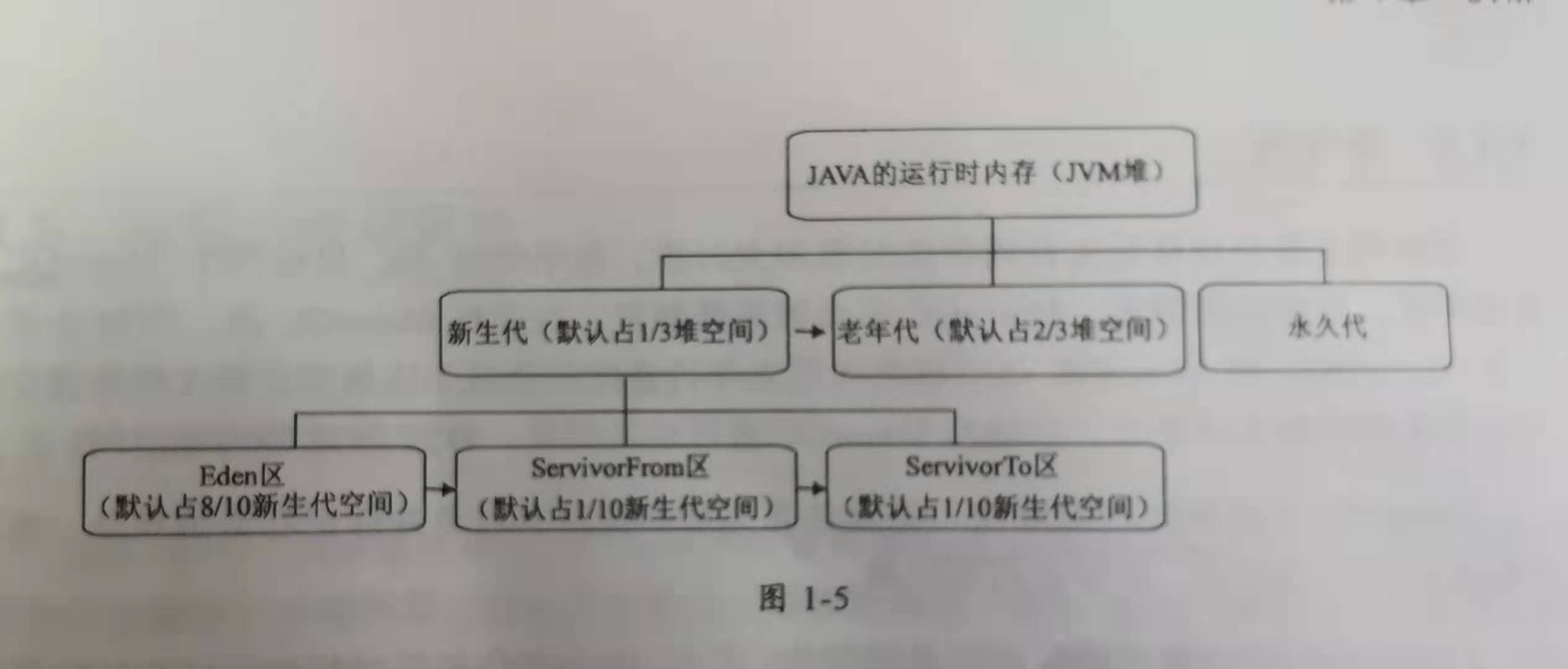
(1)新生代:存放短生命周期对象和小对象。新生代的GC过程叫作MinorGC,采用复制算法实现
老年代:存放长生命周期对象和大对象。老年代的GC过程叫作MajorGC,采用标记清除或标记整理算法
永久代:指内存的永久保存区域。主要存放Class和Meta(元数据)的信息
四.垃圾回收与算法
1.如何确定垃圾:

2.垃圾回收算法
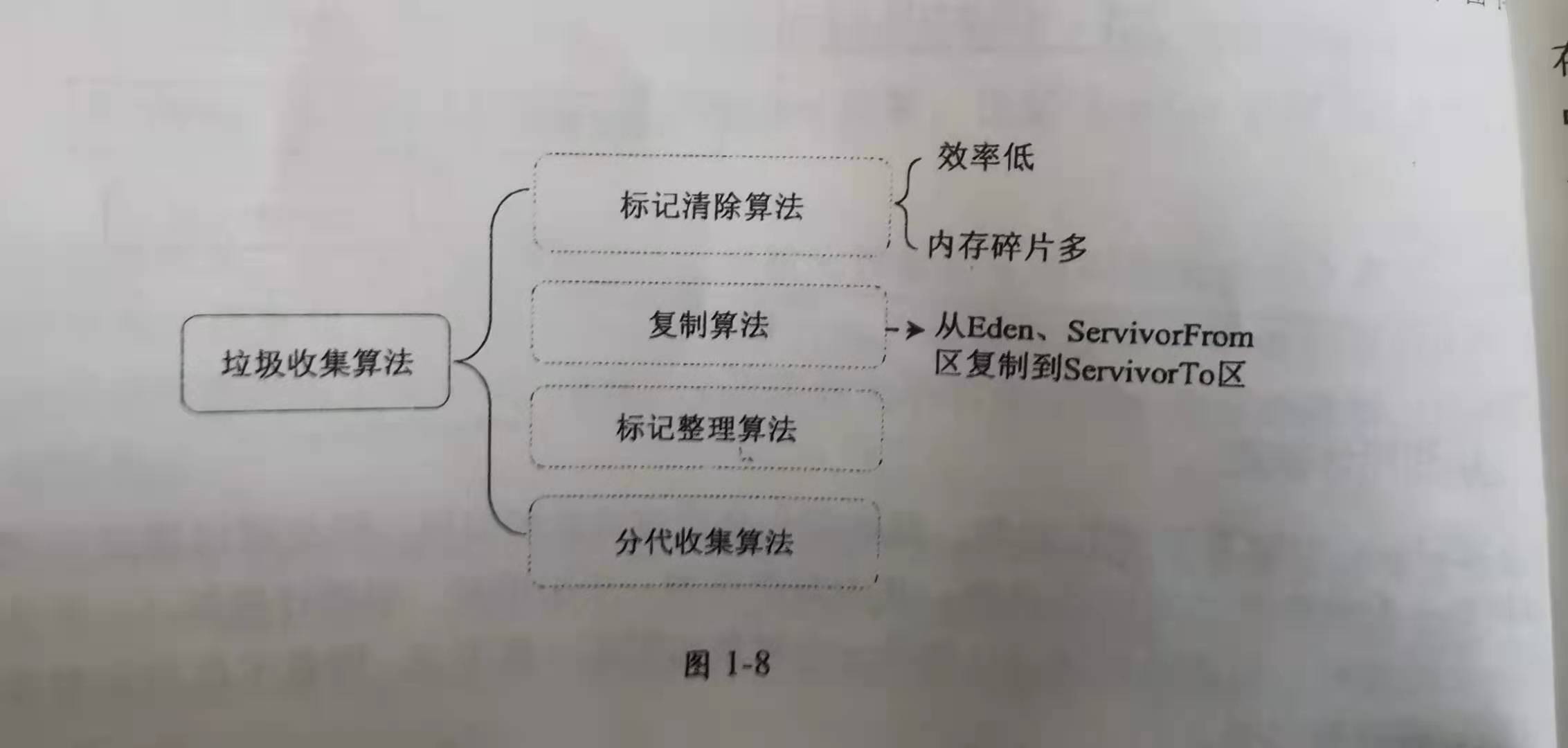
(1)标记-清除算法:将垃圾对象先标记出来,然后清除。 缺点:会产生内存碎片,效率低(标记和清除两个阶段效率都低)
(2)复制算法:(解决了上面的两个缺点)将内存分成两块,将存活的对象复制到另一块,然后再把前一块的对象全部清理掉。
缺点:内存浪费。若对象存活率高,每次都要复制大量对象,效率也会变低
(3)标记-整理算法:标记出所有存活的对象,让所有存活对象向一端移动,然后再清除边界以外的垃圾对象
(4)分代收集算法:(上面几种算法的结合)根据对象生命周期不同,将内存分为几个区域,不同区域采用不同垃圾回收算法(新生代:复制算法,老年代:标记-清除算法)
新生代采用复制算法,每次使用一块Eden区和一块Survivor区,当进行垃圾回收时,将Eden和一块Survivor区域的所有存活对象复制到另一块Survivor区域,然后清理掉刚才存放对象的区域,依次循环。
老年代采用标记-清除或者标记-整理算法,根据使用的垃圾回收器来进行判断。
3.垃圾收集器
1.运行时常量池存放:字面量,符号引用,直接引用
(1)符号引用包括:方法名,字段名,类名。类和接口的完全限定名,字段的名称和修饰符,方法的名称和修饰符(Dog,private name,public shout)
符号引用以一组符号来描述所引用的目标(str=“hello”,str就是符号引用)(直接引用就是用地址来引用目标)
(2)直接引用可以是直接指向目标对象的指针、相对偏移量或是一个能间接定位到目标的句柄(地址)
类在加载的“解析阶段”将符号引用转换为直接指向方法区中类方法,类字段的直接引用,将直接引用存储在类常量池中
补充:
1.方法区,堆,虚拟机栈,本地方法栈,程序计数器。
运行时常量池:用于存放编译期生成的各种字面量和符号引用
直接内存:
2.对象的内存布局
分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
3.关键字 volatile 是 Java 虚拟机提供的最轻量级的同步机制
4.也就是 happens-before 原则。这个原则是判断数据是否存在竞争、线程是否安全的主要依据
补充:
1.运行时常量池在方法区内

 浙公网安备 33010602011771号
浙公网安备 33010602011771号