「算法01」排序算法小结
排序算法是一类比较基础的算法,也是在学习编程与算法的过程中必须学习的一类问题。初学者经常在排序时摸不着头脑,面对一众的排序,不知从何处下手。下面笔者将以笔记的形式分享一下我在学习算法时整理的一些排序算法。
假设现有乱序数组:5, 2, 7, 4, 6, 1, 8, 我们将其排序为升序数组,各种方法过程如下:
1.冒泡排序。
冒泡排序是最简单的一种排序手段,也是新手最容易想到的一种算法。它通过每一项与其后面的每一项依次比较,找到最大(最小)值并交换位置,经过一次遍历,即可将数组排序。其过程大致如下:
首先提取第一个元素5, 与它后面每一项进行比较,找到最小项1,并与其交换位置,得到数组:1, 2, 7, 4, 6, 5, 8。
随后的第二个元素2, 经比较后发现没有比2更小的项,数组不变。
再依次提取7, 4, 6, 5,分别与它们后面的每一项进行对比,找到最小项并交换位置,最终数组将按照升序排序,即1, 2, 4, 5, 6, 7, 8。
其代码如下:
1 for (int i = 0; i < n - 1; i++) 2 for (int j = i + 1; j < n; j++) 3 if (arr[i] > arr[j]) 4 { 5 int tmp = arr[i]; 6 arr[i] = arr[j]; 7 arr[j] = tmp; 8 }
由执行过程可以看到,冒泡排序执行中需要双层嵌套循环,一旦需要排序的数组过长,其效率也随之迅速降低。
在日常使用中,笔者仅在小型数组的排序中使用这种算法,因为其代码简单直接,工程量比较小,代码也易于维护。
2.并归排序。
并归排序采用的是分治思想,利用函数的递归,将庞大的排序问题逐级化简,最后并归得到有序的数组。它的思想是将一个数组一分为二,再将两个子数组分别排序,再依次比较数组的首项,将较小值依次放入原数组中,最终得到有序数组。其过程大致如下:
首先将数组拆分为array1:5, 2, 7, 4, 和array2:6, 1, 8, 分别对这两个数组进行排序:array1:2, 4, 5, 7, 和array2:1, 6, 8。
再将两个数组并归为一个数组:首先比较两个数组的首项:由于1 < 2,将array2中的1提取,归入原数组。再比较两个数组的首项:由于2 < 6,本次提取值为2。。。以此类推。同时,为了防止数组发生越界问题,需要在数组末项之后人为添加一个无穷项,保证该项大于数组中的每一项,从而防止数组越界的现象发生。经过并归过程后,原数组排序完成。
但是这里会引出一个问题,该如何排序这两个子数组呢?这里便需要用到递归的思想。我们可以让函数调用它自身从而完成对拆分开来的子项的排序。
但这样又会产生接下来的问题,该如何控制递归结束?这里由于最后无穷项的存在,当数组长度为2时,数组内有效值便只有一个,在此时,递归结束,将这项返回,交由函数下面的内容完成并归操作。
其代码如下:
1 void merge(int* arr, int n) //由于采用指针传递的方式,函数将直接对原地址进行操作,故函数被定义为无返回值 2 { 3 if (n > 1) //笔者的函数传递的n是数组长度,当数组长度大于1,数组可以被继续拆分,继续递归若等于1,无法拆分,递归结束 4 { 5 int* arr1 = new int[n / 2 + n % 2 + 1], * arr2 = new int[n / 2 + 1]; //开辟新数组,为了添加无穷项防止越界,每一个数组长度增加1位 6 for (int i = 0; i < n / 2 + n % 2; i++) 7 arr1[i] = arr[i]; 8 arr1[n / 2 + n % 2] = 100; //笔者代码排序的数组最小项为0, 最大项为99, 故将无穷项设置为100 9 for (int i = n / 2 + n % 2; i < n; i++) 10 arr2[i - n / 2 - n % 2] = arr[i]; 11 arr2[n / 2] = 100; 12 merge(arr1, n / 2 + n % 2); //递归排序子数组 13 merge(arr2, n / 2); 14 for (int i = 0, j = 0, k = 0; i < n; i++) //将两个子数组并归 15 if (arr1[j] <= arr2[k]) 16 { 17 arr[i] = arr1[j]; 18 j++; 19 } 20 else 21 { 22 arr[i] = arr2[k]; 23 k++; 24 } 25 } 26 delete[] (arr1); //释放由new申请的内存
27 delete[] (arr2);
28 }
并归排序采用了递归的方式,由于无需双重循环,其执行效率相较冒泡排序在处理长数组时有所提升。但是由于其代码相对复杂,笔者在日常使用中不常使用这种算法。
3.堆排序。
堆排序利用了堆的性质,通过维护一个最大堆或最小堆,提取堆顶元素放入原数组完成排序。
这里首先要理解二叉堆的性质:二叉堆是一个数组,可以近似为一个完全二叉树。
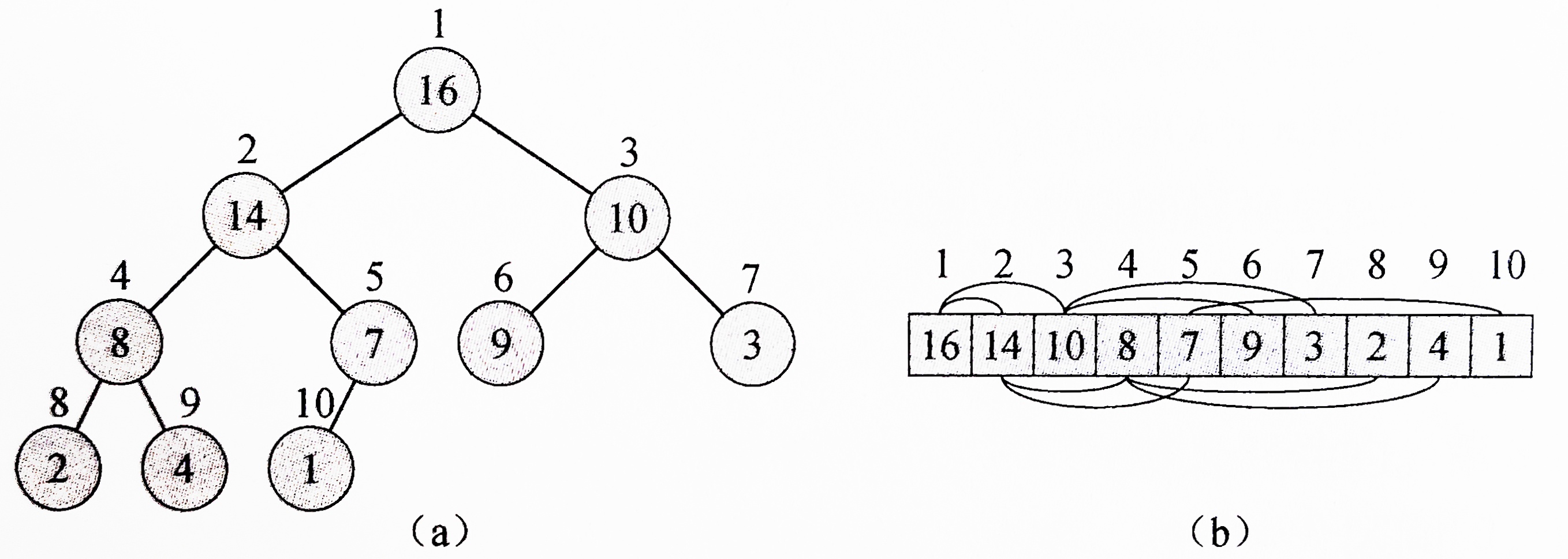
如图为一个最大堆,a为展开为树的形态,b为数组形态。由堆的对应关系容易得到,任意节点的下标除以2即可得到其父节点的下标,而父节点下标乘2可获得子节点的左节点,乘2加1可获得右节点,而这个最大堆的根是最大值。
若要维护堆的性质,需要自上而下比较,找到父节点与两个子节点中的最大项,将最大的值与父节点交换位置,直到到堆的底层结束。
而建立堆的过程就是对堆的每一个节点执行维护堆的过程。而每次取出根节点,便需要重新执行维护堆,以确保堆始终为最大堆。
其代码如下:
1 void heap(int* arr, int n) //利用堆进行排序,笔者传值方式采用指针,无返回值 2 { 3 for (int i = n / 2; i >= 0; i--) //建堆,自下而上对每一个非底层节点执行维护,确保最终得到最大堆 4 heapify(arr, i, n); 5 for (int i = n - 1; i >= 1; i--) //依次取出堆顶最大值,插入数组末端 6 { 7 int tmp = arr[i]; //用堆底层值替换掉顶层值,从而取出顶层值 8 arr[i] = arr[0]; 9 arr[0] = tmp; 10 heapify(arr, 0, --n); //由于取出最大值后,堆被破坏,重新维护,而此时需要维护的堆长度应该减1,因为末项已经是我们需要的值,因此从堆中剔除 11 } 12 } 13 14 void heapify(int* arr, int n, int size) //维护堆的性质 15 { 16 int largest, l, r; //分别为最大的节点,左节点,右节点 17 l = n * 2; 18 r = n * 2 + 1; 19 if (l < size && arr[l] > arr[n]) //两次判断,比较出三个节点中最大值的下标 20 largest = l; 21 else 22 largest = n; 23 if (r < size && arr[r] > arr[largest]) 24 largest = r; 25 if (largest != n) //如果父节点不是最大值,交换最大值到父节点,重新维护子节点所在分支堆的性质 26 { 27 int tmp = arr[n]; 28 arr[n] = arr[largest]; 29 arr[largest] = tmp; 30 heapify(arr, largest, size); 31 } 32 }
堆排序同样利用了递归的思想,效率相对较高,其主要时间消耗在建堆的过程,后期仅需要循环取值,重新维护堆即可。但是堆排序亦或是建堆,可以用于决策算法等其它算法,这是堆的独特优势,因此我们在大型项目可以重复利用建堆代码,发挥其独到优势,减少工程量。
4.快速排序。
快速排序,顾名思义它是排序速度最快的排序方式。它也利用了递归的思想。同并归排序类似,它通过将数组一分为二,两侧分别排序,从而达到排序的目的。但与并归不同的是,快速排序没有后期并归的过程。在拆分数组的过程中,快速排序可以做到一侧的最大值小于另一侧的最小值,故最后无需比较,直接连接即可。其思想如下:
首先取数组末尾值为中间值,对数组前面的所有值依次比较,小于该中间值的向前移动,大于的向后移动。即,当一个值小于中间值,它会与大于中间值部分的下标最小的值进行交换,同时令大于中间值部分的下标加一,实现大于中间支部分的移动。而当一个值大于中间值时,将大于中间值部分扩张包含该值即可。当大于中间值部分移动到中间值处,将中间值移动至两个子数组之间。至此,中间值左侧所有值都小于中间值,中间值右侧所有值都大于中间值。将中间值两侧的数组再次分别排序,直到数组不可在分,排序结束。
其代码如下:
1 void quick(int* arr, int m, int n) //快速排序递归部分 2 { 3 if (m < n) 4 { 5 int i = partition(arr, m, n); //每次递归寻找中间值下标,再依次递归中间值左侧与右侧部分 6 quick(arr, m, i - 1); 7 quick(arr, i + 1, n); 8 } 9 } 10 11 int partition(int* arr, int m, int n) //快速排序处理数组部分 12 { 13 int x = arr[n]; //数组末尾值作为中间值 14 int i = m - 1; //i用于小于中间值部分下标的计数 15 for (int j = m; j < n; j++) //遍历数组,将值归档 16 { 17 if (arr[j] <= x) //对大于中间值的值的处理 18 { 19 i++; 20 int tmp = arr[i]; 21 arr[i] = arr[j]; 22 arr[j] = tmp; 23 } 24 } 25 int tmp = arr[i + 1]; //将中间值插入两个子数列之间 26 arr[i + 1] = arr[n]; 27 arr[n] = tmp; 28 return i + 1; //返回中间值 29 }
快速排序是运行效率极高的一种排序算法,在处理大型数组时极其有效,而且算法消耗的内存少,适合对性能有要求的项目。当然,对于小型数组的排序很难体现快速排序的优越性,微小型数组排序更多还是冒泡等相对简单的排序比较方便开发。
5.线性时间排序。
线性时间排序是一类特殊的排序算法,这类算法不是简单的依赖比较数组元素的大小,而是巧妙地利用数组的下标对其进行排序。其时间消耗随着需要排序的数组的特点会有所变化,有时效率会很高,甚至超过快速排序,而有时效率则一般。但是这类算法普遍的特点是会有内存消耗,内存的开销会大于快速排序,因此仅适用于特定数据的排序,不如快速排序普适。
计数排序
计数排序适用于一个连续正整数数组,数组的连续性越强,其效率也就越高。
计数排序巧妙地将数组的元素当作数组下标,开辟一个新数组,利用数组元素充当新数组的下标,利用新数组的值来计数,最后直接将新数组的下标从小到大按统计的数量输出,完成排序。
其代码如下:
1 void count(int* arr, int n) 2 { 3 int max = arr[0]; 4 for (int i = 1; i < n; i++) //找出数组最大值 5 if (arr[i] > max) 6 max = arr[i]; 7 max++; 8 int* tmp = new int[n]; 9 int* count = new int[max]; 10 for (int i = 0; i < max; i++) //数组初始化 11 count[i] = 0; 12 for (int i = 0; i < n; i++) //将数组下标用于计数 13 count[arr[i]]++; 14 for (int i = 1; i < max; i++) //统计每个下标的排位 15 count[i] += count[i - 1]; 16 for (int i = n - 1; i > 0; i--) //重新写回原数组 17 { 18 tmp[count[arr[i]]] = arr[i]; 19 count[arr[i]]--; 20 } 21 for (int i = 0; i < n; i++) 22 arr[i] = tmp[i]; 23 delete[] (tmp); //释放空间 24 delete[] (count); 25 }
基数排序:
基数排序同样适用于连续正整数数组,与计数排序不同的是,基数排序数组最大值位数越低,其排序效率越高。
基数排序也是将数组元素作为下标,依次统计在每一位上的数据的数量,经过多次循环排序统计后,可以得到有序数组。
其代码如下:
1 void radix(int* arr, int n) 2 { 3 int max = arr[0]; //找到最高为位数 4 for (int i = 1; i < n; i++) 5 if (arr[i] > max) 6 max = arr[i]; 7 int digit = 0; 8 while (max > 10) 9 { 10 max /= 10; 11 digit++; 12 } 13 int* tmp = new int[n]; //用于存储中间数据 14 int* count = new int[10]; //用于位数的统计 15 for (int i = 0, radix = 1; i <= digit; i++, radix *= 10) 16 { 17 for (int j = 0; j < 10; j++) //初始化统计数组 18 count[j] = 0; 19 for (int j = 0; j < n; j++) //位数数量统计 20 { 21 int k = (arr[j] / radix) % 10; 22 count[k]++; 23 } 24 for (int j = 1; j < 10; j++) 25 count[j] += count[j - 1]; 26 for (int j = n - 1; j >= 0; j--) //将一轮排列的值写入中间数组 27 { 28 int k = (arr[j] / radix) % 10; 29 tmp[count[k] - 1] = arr[j]; 30 count[k]--; 31 } 32 for (int j = 0; j < n; j++) //将中间数组值写回 33 arr[j] = tmp[j]; 34 } 35 delete[] (tmp); //释放空间 36 delete[] (count); 37 }
以上就是笔者最近统计的一些排序算法,同时笔者也在不断学习其它的算法。欢迎指正。
(算法参考自《算法导论(原书第三版)》--机械工业出版社)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号