
第一次个人编程作业
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 50 | 70 |
| · 估计这个任务需要多少时间 | 80 | |
| 开发 | 360 | 400 |
| 需求分析 (包括学习新技术) | 50 | 60 |
| 生成设计文档 | 30 | 60 |
| 设计复审 | 40 | 50 |
| 代码规范 (为目前的开发制定合适的规范) | 25 | 30 |
| 具体设计 | 60 | 55 |
| 具体编码 | 120 | 160 |
| 代码复审 | 45 | 40 |
| 测试(自我测试,修改代码,提交修改 | 70 | 90 |
| 报告 | 120 | 120 |
| 测试报告 | 50 | 80 |
| 计算工作量 | 30 | 30 |
| 事后总结, 并提出过程改进计划 | 40 | 60 |
| 合计 | 1170 | 1305 |
代码组织:1.func模块,需要的函数
2.main,运行查重工具
3.test,测试模块
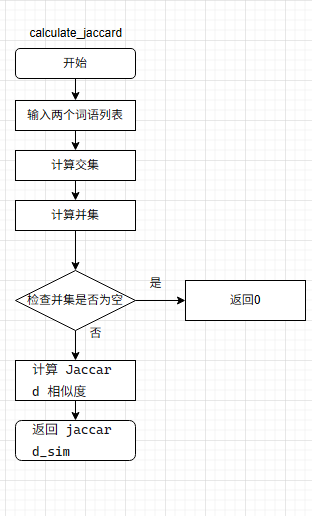
核心算法:基于词频的余弦相似度和Jaccard 相似度记算
text
文本输入
↓
预处理 (去除标点、空格规范化)
↓
分词 → 过滤停用词
↓
短文本判断 → 字符级相似度计算
↓
长文本处理
├─ 构建词频向量 → 余弦相似度计算
└─ 构建词语集合 → Jaccard相似度计算
↓
相似度融合 (平均值)
↓
结果输出
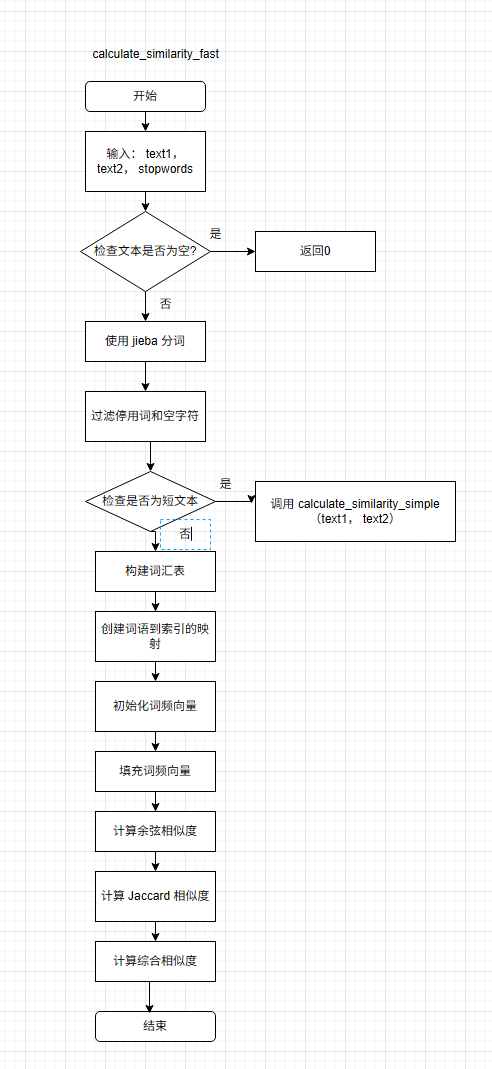
关键算法函数的流程图
独到之处:
1.使用jieba分词库划分词语
2.用正则表达式库re对文本进行去标点和保留核心词的预处理
3.使用中文停用词去噪
4.运用词频的余弦相似度和Jaccard 相似度综合计算查重率
性能改进
最耗费时间的模块是核心函数calculate_similarity_fast
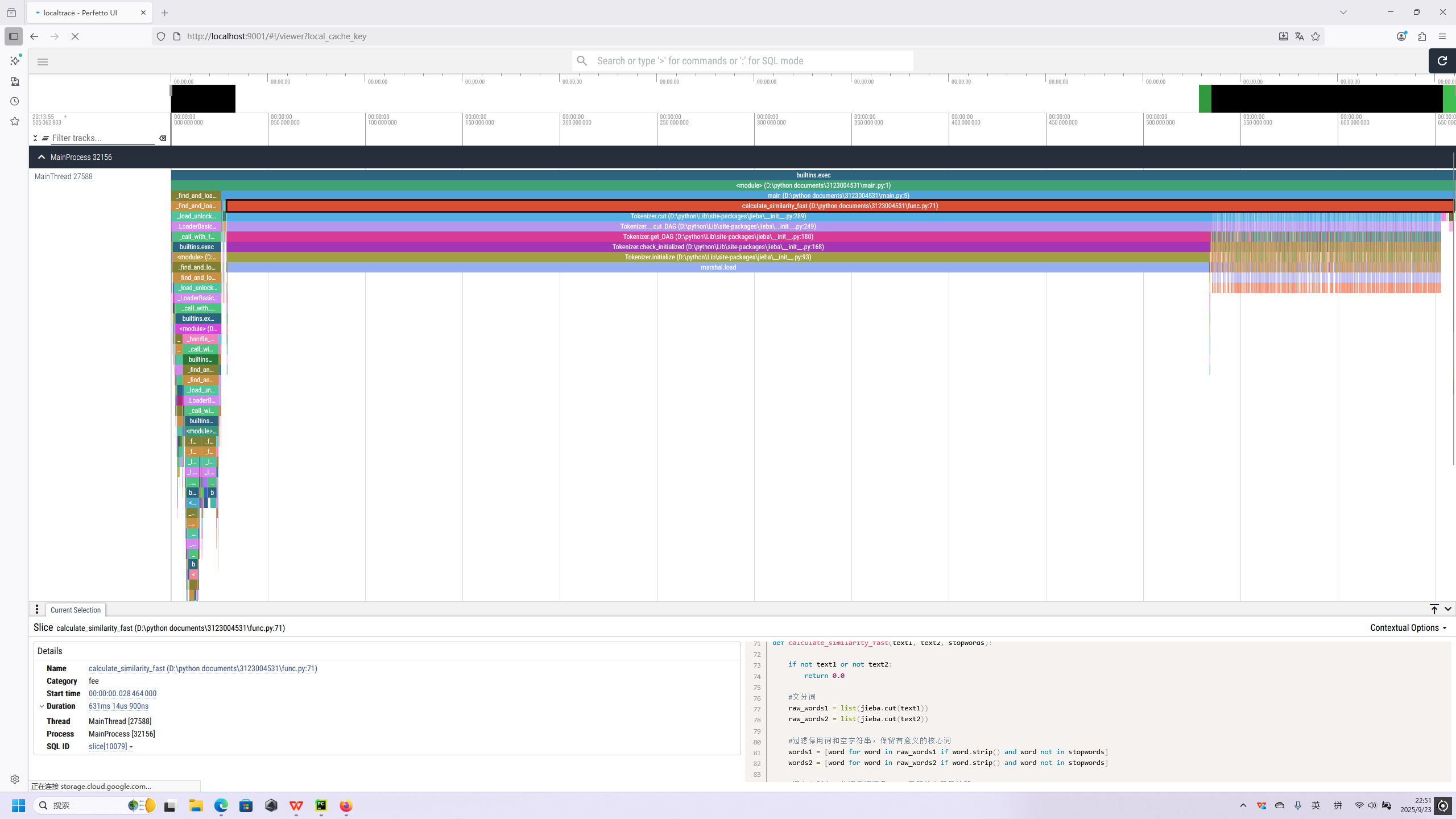
改进思路:
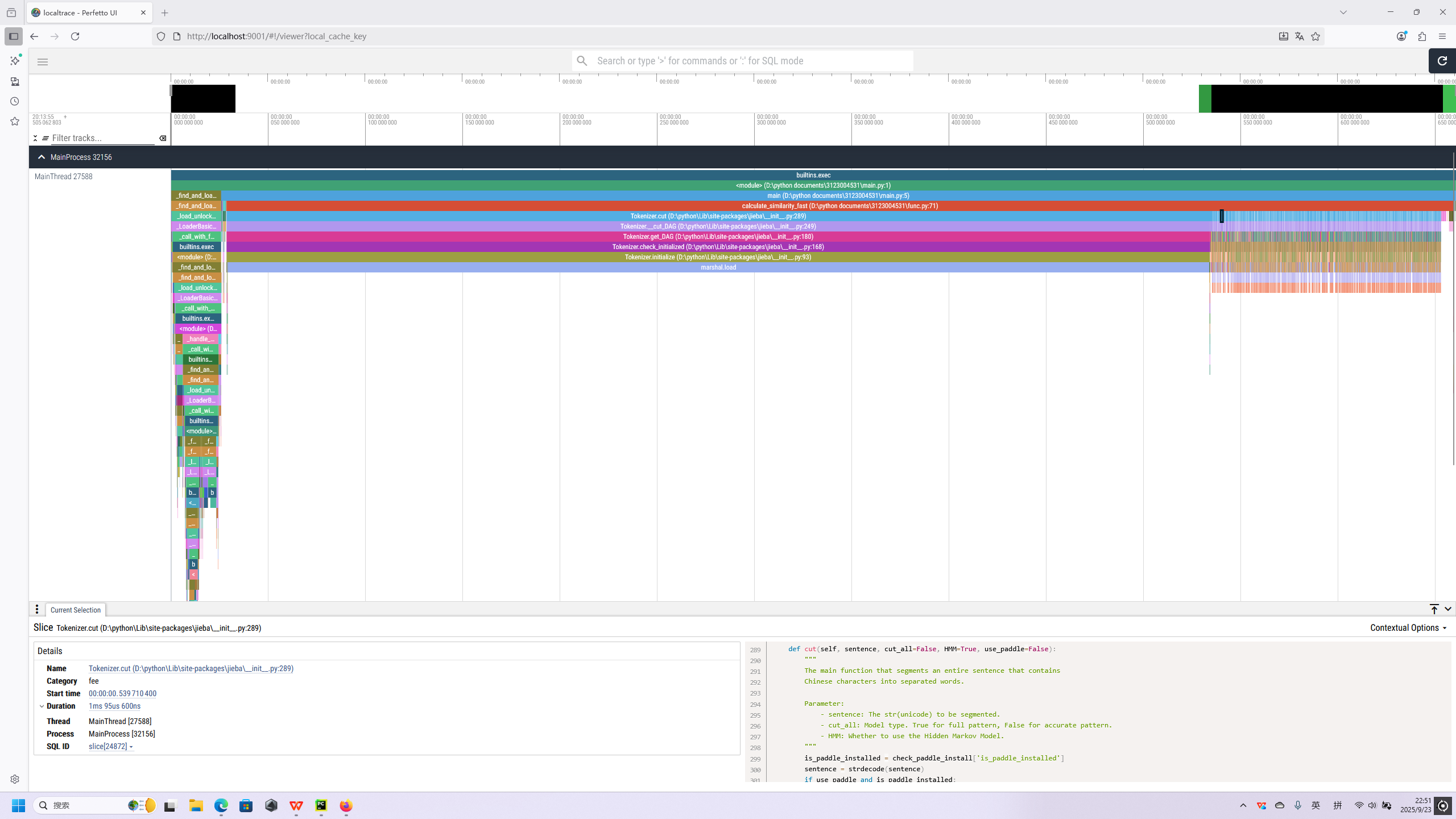
分词jieba.cut是函数的首个性能消耗点,尤其在批量处理文本或重复处理相同文本时,冗余分词会严重拖慢速度,可从 “缓存复用” 和 “分词参数优化” 入手
jieba.cut函数运行情况
单元测试代码:
测试用例5: 简单相似度-完全相同文本
def test_similarity_identical_texts(self):
#测试完全相同文本的相似度
text1 = "今天天气很好"
text2 = "今天天气很好"
similarity = calculate_similarity_simple(text1, text2)
self.assertAlmostEqual(similarity, 100.0, places=2)
# 测试用例6: 简单相似度-完全不同文本
def test_similarity_different_texts(self):
#测试完全不同文本的相似度
text1 = "abcdef"
text2 = "ghijkl"
similarity = calculate_similarity_simple(text1, text2)
self.assertAlmostEqual(similarity, 0.0, places=2)
# 测试用例7: 简单相似度-空文本处理
def test_similarity_empty_texts(self):
"""测试空文本的相似度计算"""
similarity = calculate_similarity_simple("", "测试")
self.assertEqual(similarity, 0.0)
similarity = calculate_similarity_simple("", "")
self.assertEqual(similarity, 0.0)
# 测试用例8: 快速相似度-短文本触发简单算法
def test_fast_similarity_short_text(self):
"""测试短文本触发简单相似度算法"""
short_text = "短文本测试"
similarity = calculate_similarity_fast(short_text, short_text, set())
self.assertAlmostEqual(similarity, 100.0, places=2)
说明测试的函数,构造测试数据的思路:
场景全覆盖:从 “完全匹配→完全不匹配→异常输入→分支触发”,覆盖 calculate_similarity_simple 和 calculate_similarity_fast 的核心路径与边界场景。
结果可预期:所有测试数据的理论相似度均明确(100%/0%),无模糊性,便于快速定位 Bug。
排除干扰因素:通过 “控制文本长度、空停用词集合、无歧义字符” 等设计,确保测试结果仅由 “目标函数逻辑” 决定,而非外部变量。
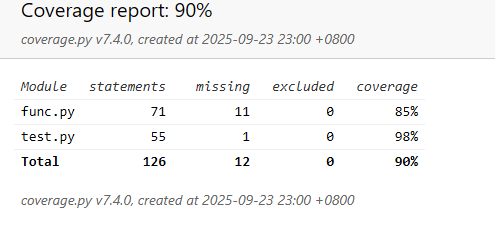
测试覆盖率


 浙公网安备 33010602011771号
浙公网安备 33010602011771号