



个人项目
个人项目
| 作业所属班级 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024 |
|---|---|
| 作业的要求 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
| 我理解的作业目标 | 1.自我介绍,并掌握如何用Markdown进行排版;2.初步掌握github的用法,注册github账号,并调整设置,完善账号信息,便于日后使用 |
github链接
https://github.com/Miaomia0QAQ/miaomiao
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 5 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 50 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 240 |
| Design Spec | 生成设计文档 | 10 | 15 |
| Design Review | 设计复审 | 60 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 3天 | 3天 |
| Code Review | 代码复审 | 30 | 2天 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 15 | 10 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 4天 | 6天 |
开发
1.本次个人项目通过java进行实现,由 3 个类构成--main 类、TxtIOput 类、sentence 类。
2.开发环境:
编程语言:Java
IDE:Intellij IDEA
项目构建工具:maven
性能分析工具:JProfiler
模块具体接口
一、main类
负责调用其他类的方法,先调用TxtIOput类的setArticle方法,再调用senten类计算,最后由TxtIOput类的printResult方法将答案输出到指定文件。
二、TxtIOput类
主要负责从指定文件中接收信息并转为字符串并进行处理,以便于后续计算。
三、sentence类
核心算法模块,具体的实现原理是在对照文本中按字符搜索原文对应语句,标记重复且连续的字符,最终计算重复连续字符在文本中的占比得出相似度。在计算过程中,划分段落与句子,动态计算对照文本段落的相似度,在低于特定值时就跳过正在对照的原文段落,同时若对照文本的某段落与原文某段落最终的相似度超过一定值时,则认定该段落就是抄袭了原文的这一段落,就不比较其与原文其他段落的相似度,以此方式来达到简化运算和提高效率的效果,还能够提高计算的精度,防止相似度偏高。
相较于网上的汉明距离等算法,这一套算法更简单直接,擅长处理较短文本,但要面临在极端情况下效率低下的问题,而且在一个段落极长的情况下,重复字词的出现频率就会变高,会导致一些专业名词术语或者常用字词被错误标记,从而导致相似度虚高,此时则需要引入一个关键字词库来解决这一个问题。
性能分析

性能改进的方案在之前已经提出,但这种改进也只是减少了在理想情况的计算次数,想要真正提高计算效率仍然是要从算法入手,采用更加专业有效的算法来解决问题。
单元测试
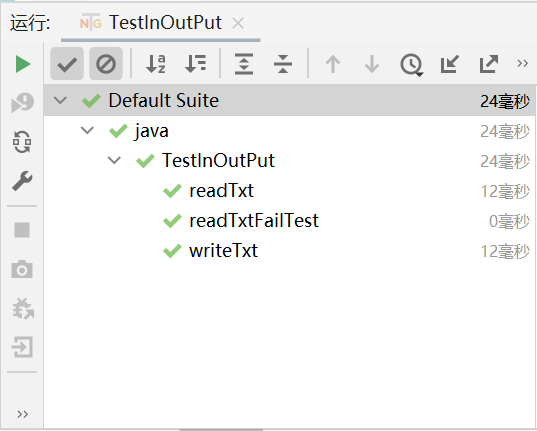
TxtIOput模块测试
点击查看代码
package gdut.miaomiao;
import org.testng.annotations.Test;
import java.io.IOException;
public class TestInOutPut {
@Test
public void readTxt() throws IOException {
// 路径存在,正常读取
TxtIOput t = new TxtIOput("D:/test/orig.txt");
String str = t.getArticle();
String[] strings = str.split(" ");
for (String string : strings) {
System.out.println(string);
}
}
@Test
public void writeTxt() throws IOException {
// 路径存在,正常写入
TxtIOput t = new TxtIOput("D:/test/result.txt");
double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55};
for (double v : elem) {
t.printResult("D:/test/result.txt",v);
}
}
@Test
public void readTxtFail() throws IOException {
// 路径不存在,读取失败
TxtIOput t = new TxtIOput("D:/test/orig888.txt");
}
}
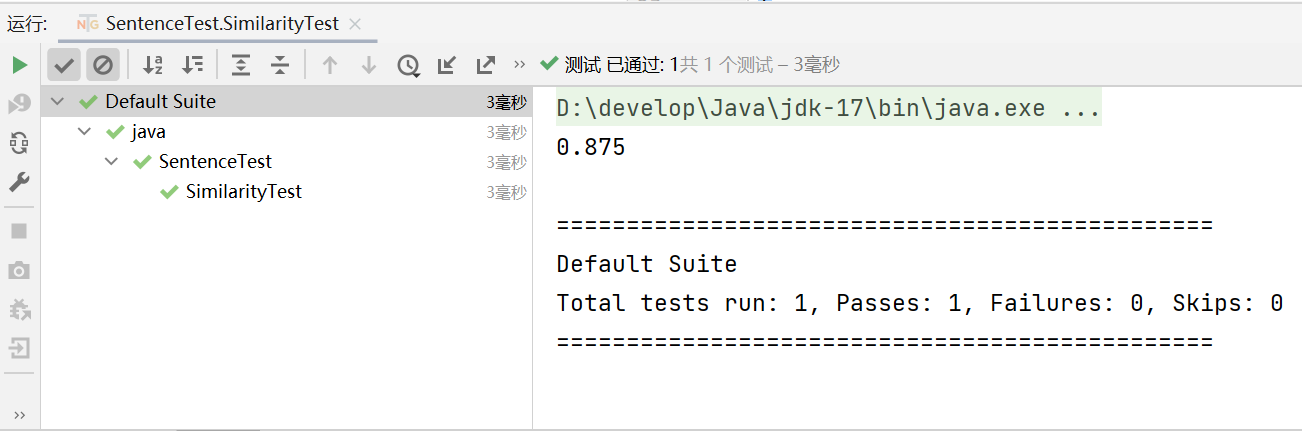
sentence模块测试
点击查看代码
package gdut.miaomiao;
import org.testng.annotations.Test;
import java.io.IOException;
public class SentenceTest {
@Test
public void SimilarityTest() throws IOException {
//输入两端字符串,预期相似度为0.875
String str1 = "v床前明月光\n" +
"我疑是地上霜\n" +
"5举头望明月\n" +
"0低头思故乡"; //对照文
String str2 = "床前明月光\n" +
"疑是地上霜\n" +
"举头望明月\n" +
"低头思故乡"; //原文
Sentence s = new Sentence(str1, str2);
double rs = s.Similarity();
System.out.println(rs);
}
}
异常处理
当输入文件地址不存在时,抛出异常,详细在文件读写测试模块有提及。
总结
本项目的最大难点在于查重算法的实现,如何进行高效地、准确地进行查重是这个项目最核心的点。本次算法设计由本人设计,算法难免相对朴素,但是在不断的测试和优化中提高了对算法和软件设计的理解,掌握了一些工具的使用,收获颇丰。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号