"KnowLog: Knowledge Enhanced Pre-trained Language Model for Log Understanding" 论文笔记
背景
① 现有模型无法理解日志中经常出现的特定领域的术语,尤其是缩写
② 现有模型难以充分捕获完整的日志上下文信息,日志通常很简洁,无法提供足够的背景信息,这给模型充分理解日志带来了重大障碍。
③ 现有模型难以获得风格不同的同一日志的通用表示
框架
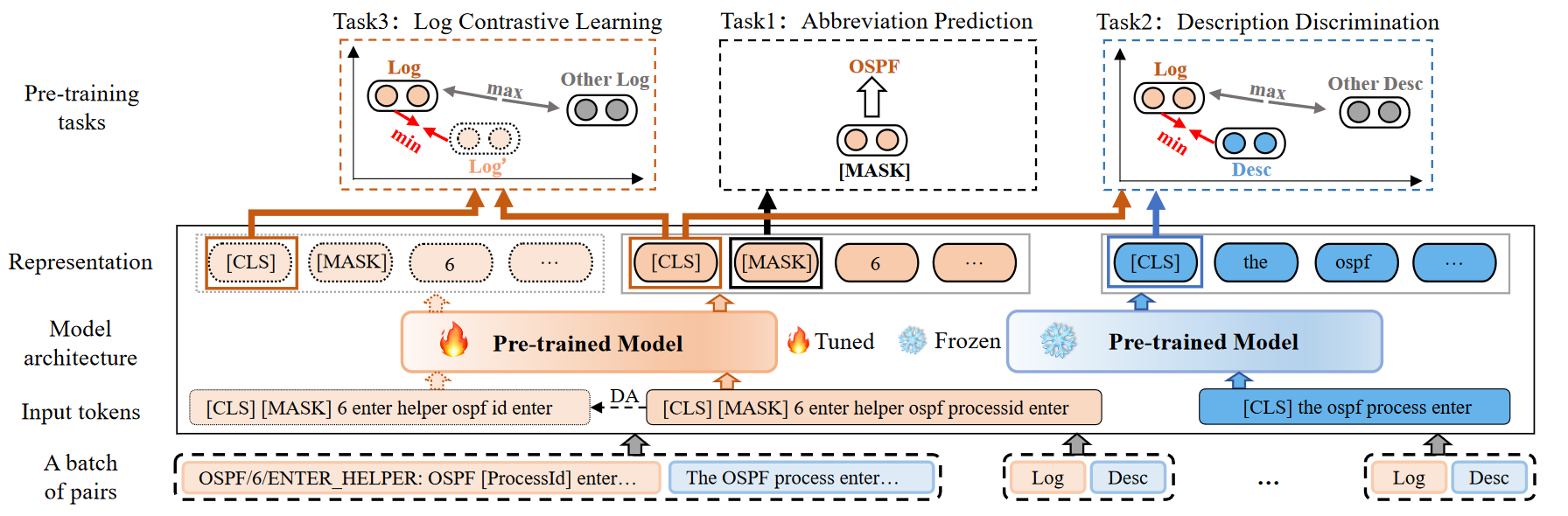
预处理
基于 WordPiece 的方法进行分词,然后得到标记序列 \(\{[CLS],l_1,l_2,\cdots,l_n,[SEP]\}\)
模型结构
使用基于 Encoder 的预训练模型,例如 BERT 和 RoBERTa
构建日志描述对 \(P = \{(l, d)\}\) 作为输入,并采用双编码器架构,其中两个编码器分别处理每种类型的数据。描述的编码器只需学*自然语义,所以冻结参数(前提条件:这里需要利用日志文档中的自然语言描述知识)
预训练任务
缩写预测(AP)
为了解决第一个挑战,我们利用缩写信息作为本地知识来增强模型。首先,我们从多个供应商的公共文档中的术语表中收集了 1,711 个缩写。然后,为了保持缩写词的完整性,我们将所有缩写词添加到分词器的词汇表中,以确保缩写词不会被切片
对每个缩写词以一定的概率 p 进行 Mask,预测被屏蔽的原始缩写
描述判别(DD)
为了解决第二个挑战,我们将 \((h^i_l, h^i_d )\) 构造为正对,将 \(h^i_l\) 与同一批次中的其他描述构造为负对,用余弦相似度作为距离。损失函数为:
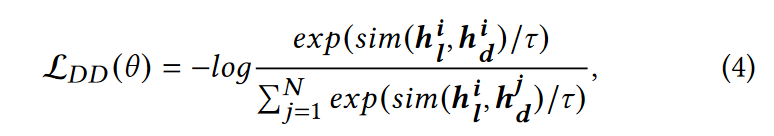
其中 \(sim\) 表示余弦相似度,\(\tau\) 为超参数
日志对比学*(LCL)
为了解决第三个挑战,我们使用数据增强来生成额外的日志正样本,然后通过对比学*拉*日志和正样本之间的语义距离。对于数据增强,我们认为日志模板中的参数更改不会影响日志语义。因此,我们对日志中的参数标记进行同义重写。例如,将日志模板中作为参数标记的“[dec]”修改为“[decimal]”以实现增广样本。
将日志与其对应的增强样本作为正对,与同一批次内的其他日志作为负对,然后与 DD 目标一样进行训练
为了避免灾难性遗忘,我们一起训练三个任务
总结
主要是提出日志-解释对用于双编码器训练,然后新提出了三个微调任务用于解决挑战,最后得到的日志表征在下游任务上有很好的效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号