GPT 系列论文速读
GPT
摘要
基于当时大量的文本任务、标好的数据少。提出先在一个没有标号的数据上训练一个预训练模型,再在有标号的子任务上训练微调模型
GPT做的是生成式预训练,下游任务还是判别任务,所以不是NLG而是NLU
引言
利用无标注文本中的word-level的信息是具有挑战性的,有如下两个原因:①尚不清楚哪种类型的优化目标函数在学习对迁移有用的文本表示方面最有效 ②如何最有效的将学习到的表示迁移到目标任务上,还没有达成共识
所以本文提出一个无监督预训练+有监督微调的方法
模型
(1)无监督预训练:
目标函数:最大化前k个词预测当前词的概率似然
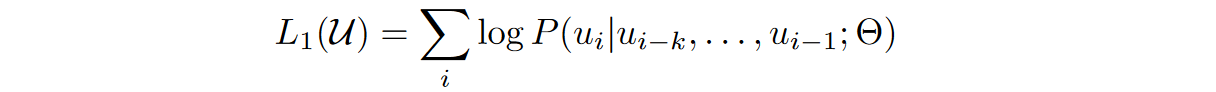
使用的模型为Transformer decoder
Transformer编码器的解码器的最大区别在于:编码器的第i个元素抽取特征时能看到所有的元素,解码器第i个元素抽取特征时只能看到当前元素和他之前的这些元素(因为有掩码)
为什么相对于BERT天花板更高:因为选取了更难的任务(预测未来比完形填空要更难)
(2)微调:
给定一个标号为y的长度为m的序列,将这个序列拿到预训练好的GPT里面,拿到Transformer块的最后一层的输出,最后输出层+softmax
无监督和有监督两个一起训练效果是最佳的,总loss等于两个任务的loss之和,使用\(\lambda\)调整loss权重
各个子任务的处理(这里的Extract是目标词元,相当于BERT中的CLS)
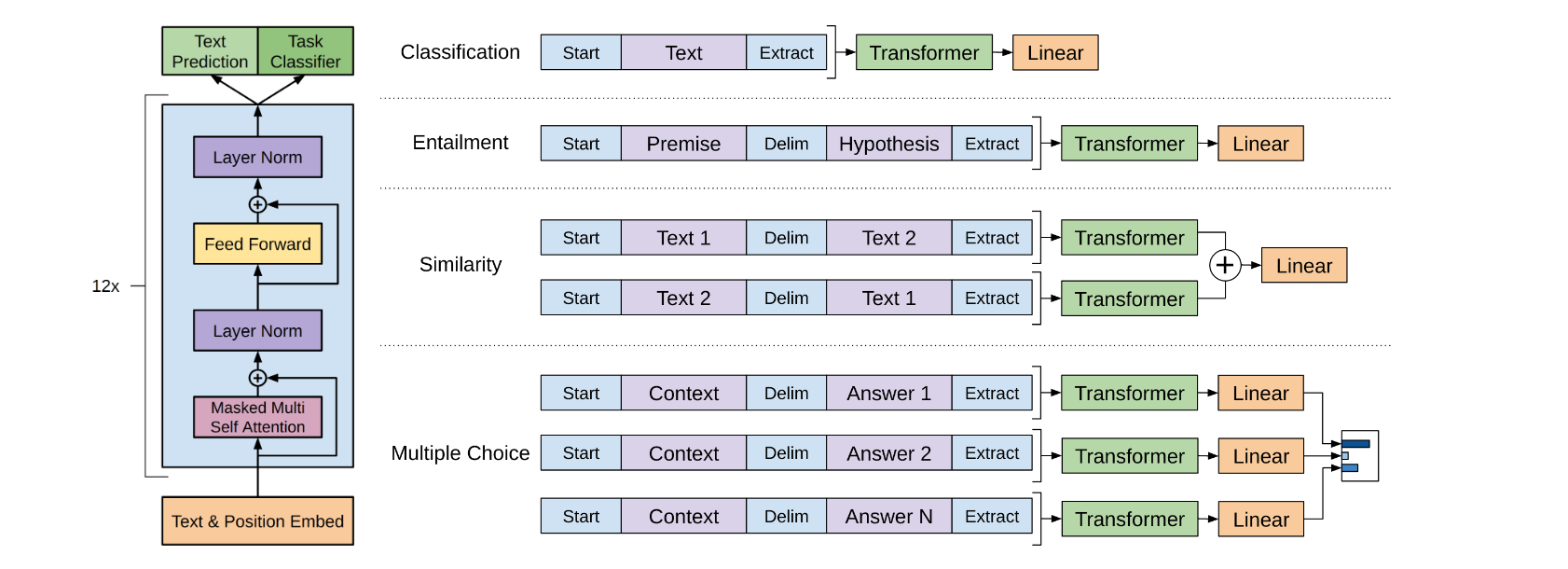
(分类、蕴含、相似、多选)
GPT-2
引言
规模:百万级别文本、十亿级别参数
模型
zero-shot:在下游任务中不需要任何标注的信息(GPT-2使用Prompt的形式来训练下游任务)(在原始数据集中发现已经有相似的例子)
GPT-3
引言
百亿级别参数、75页、大量实验与讨论与结果
模型
few-shot:少样本学习,将人工标注成本控制在合理范围
下游任务不会对预训练模型的参数进行更新
模型和GPT-2yiyang,加了一些Sparse Transformer的改进
局限性
文本生成上还是比较弱的、结构和算法上的局限性、均匀的生成词语(没办法划重点)、可解释性差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号