作业五:RDD操作综合实例
welcome to 肥怡滴blog~~
1、词频统计
A. 分步骤实现
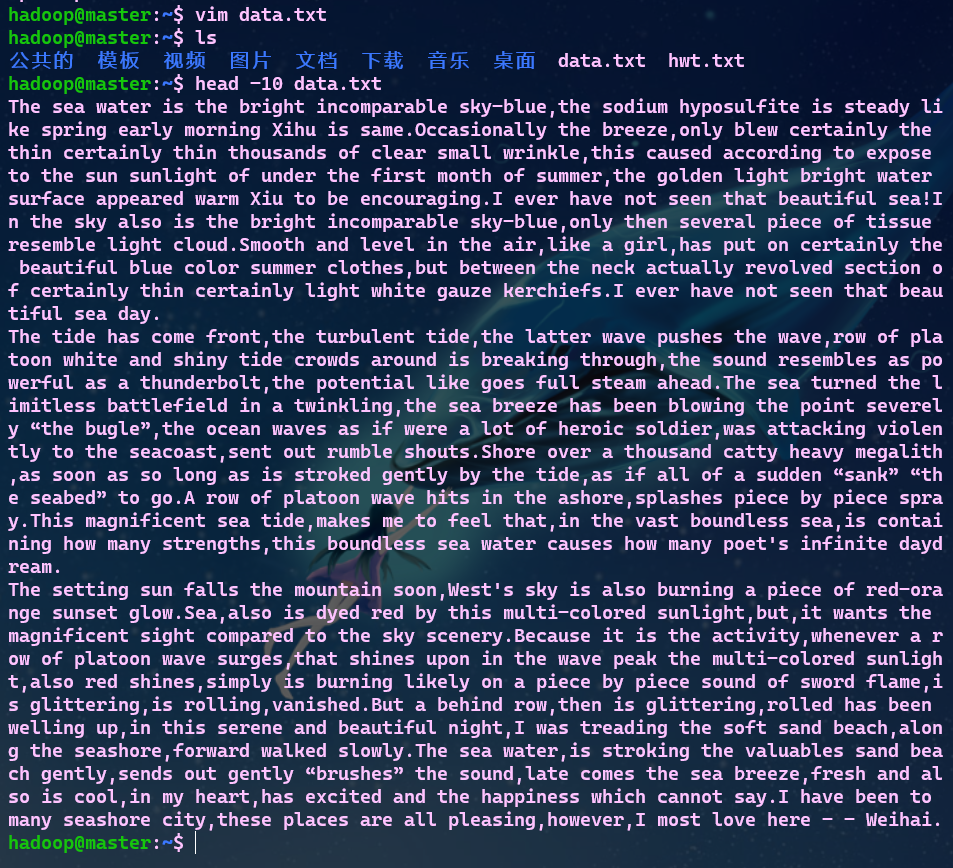
- 1.准备文件
-
- 下载小说或长篇新闻稿
-
- 上传到hdfs上

- 2.读文件创建RDD

- 3.分词

- 4.标点符号[re.split(pattern,str),flatMap()]
# 导入正则表达式re库,使用re.split分词

# 再次分词,清楚去标点符号后产生的无用数据

-
- 排除大小写lower(),map()

-
- 停用词,可网盘下载stopwords.txt,filter()
# 将停用词文件分词存储到变量中

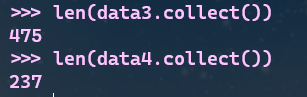
# 筛选不在停用表中的词

# 筛选前后对比
-
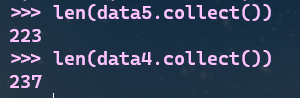
- 长度小于2的词filter()

# 筛选前后对比
- 5.统计词频
# 把单词映射成键值对
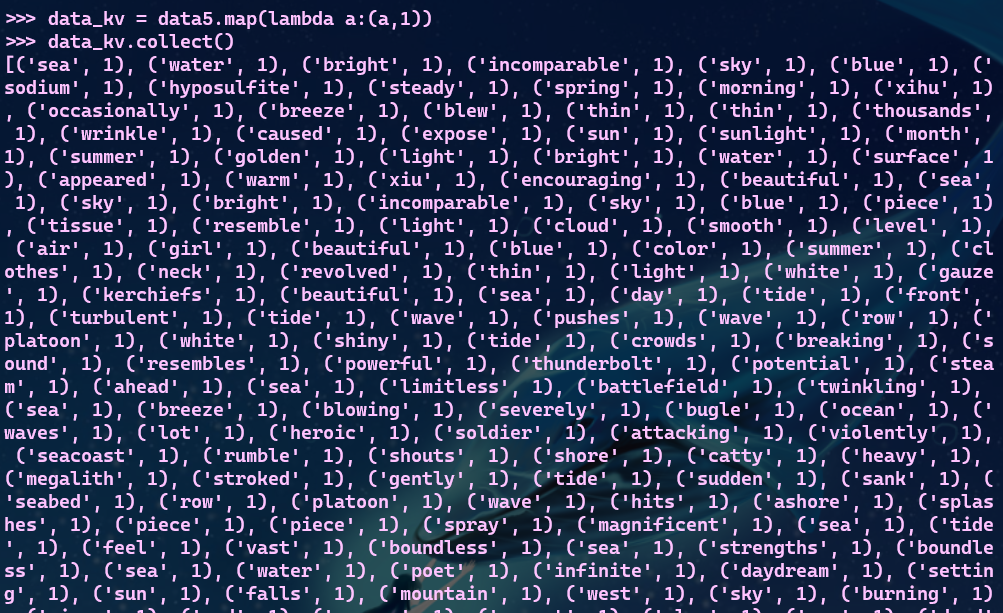
# 将key相同的values合并,进行词频统计
data_kv = data_kv.reduceByKey(lambda a,b:a+b)

- 6.按词频排序
# sortBY进行词频排序
# [False: 对values值进行降序处理,并指定区块数量为1,方便查文件]
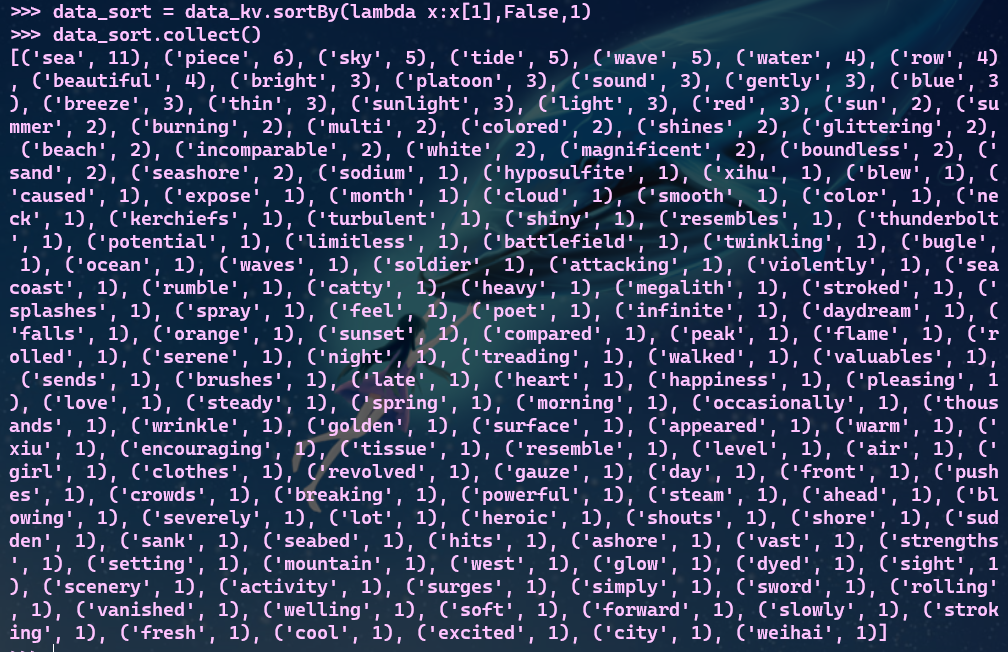
- 7.输出到文件
# 分别在本地文件和HDFS文件上输出
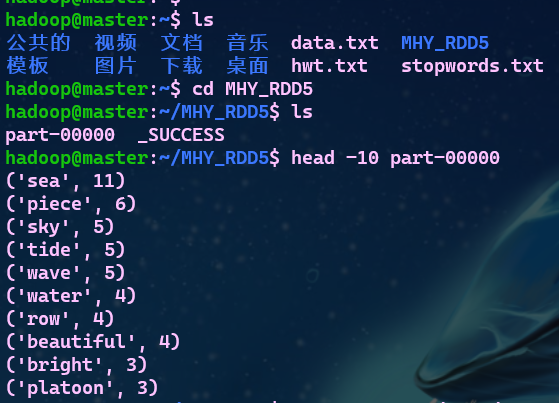
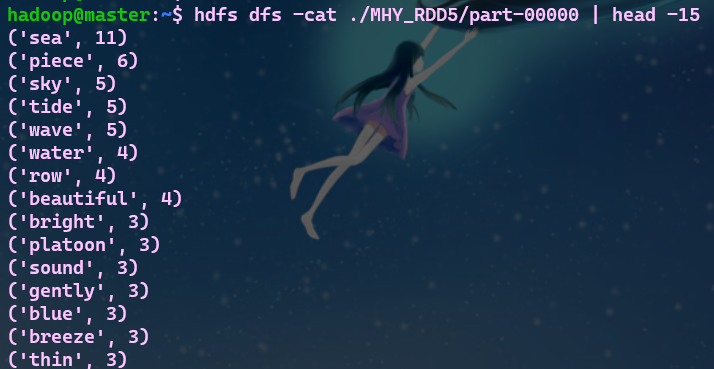
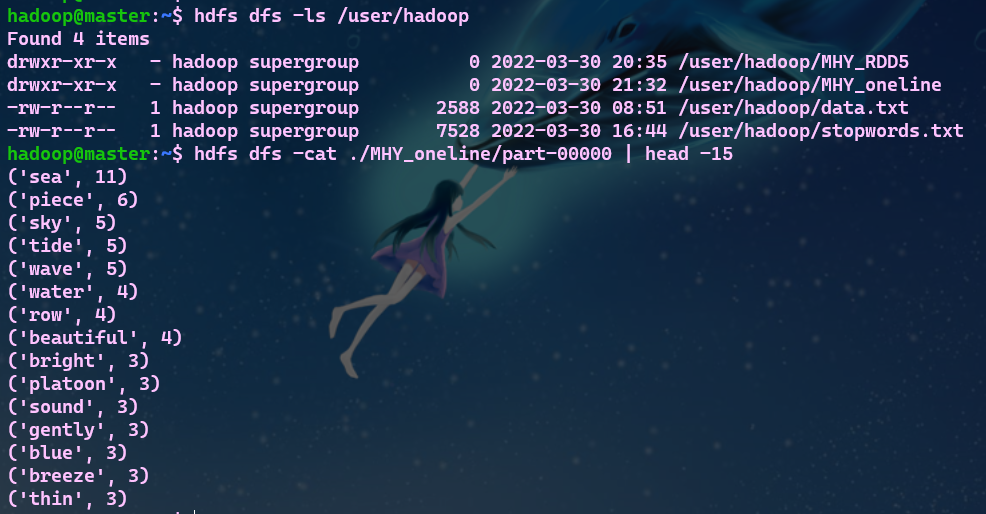
- 8.查看结果
B. 一句话实现:文件入文件出
# 一句话完成文件需求并保存文件

# 查看结果
C. 和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点。
点击查看代码
# 导入字符串模块
import string
# 导入re模块
import re
# 导入matplotlib模块,取别名plt
import matplotlib.pyplot as plt
# 创建一个空字典,放词频和单词,无序排列
data_dict = {}
# 创建一个空列表,放词频和单词,有序排列
data_list = []
# 打开文件
file = open(r'D:\Desktop\data.txt',encoding='utf-8')
# 读取文件
data = file.read()
# 关闭文件
file.close()
# "-"用" "代替
data = data.replace('-',' ')
# 生成所有单词的列表
word_list = data.split()
# 对数据进行处理,并存入
for i in range(len(word_list)):
# 去掉标点符号,去掉首尾
word_list[i] = word_list[i].strip(string.punctuation)
# 统一小写
word_list[i] = word_list[i].lower()
# 统计词频与单词
if word_list[i] in data_dict:
# 不是第一次
data_dict[word_list[i]] = data_dict[word_list[i]] + 1
else:
# 第一次
data_dict[word_list[i]] = 1
# 打印字典(单词与词频,无序)
print(data_dict)
# 遍历字典
for key,value in data_dict.items():
# 变量值,变量
temp = [value, key]
# 添加数据
data_list.append(temp)
# 排序
data_list.sort(reverse = True)
# 打印列表(单词与词频,有序,从多到少)
print(data_list)
# 写入文件
with open(r'D:\Desktop\data_out.txt','w') as files:
for value,key in data_list:
files.write('{} {}\n'.format(value,key))
在python中读取文件后,没有用到flatMap操作,也没有分区块操作,python是按顺序进行各种操作。
所以,pyspark主要是对分布式的数据进行处理,而python是对单数据进行处理。
2、求Top值
- 网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
# 下载payment.txt文件
# 拆分字段

# 丢弃空行与字段不完整的行

# 丢弃有空值的行

# 有效的记录

# 支付金额转换为数值型,按支付金额排序

# 取出Top3


 浙公网安备 33010602011771号
浙公网安备 33010602011771号