作业二:1.安装Spark 2.Python编程练习 3.根据自己的编程习惯搭建编程环境
1.安装Spark
- 检查基础环境hadoop,jdk
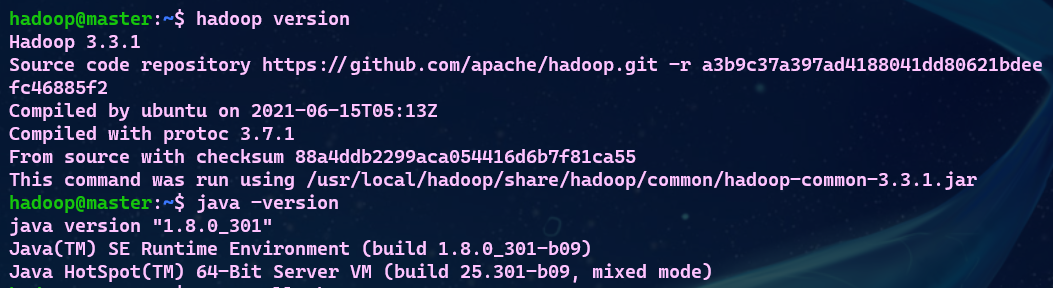

- 配置文件
vim /usr/local/spark/conf/spark-env.sh

- 环境变量
# 修改环境变量
vim ~/.bashrc
# 加载修改后的设置,使之生效
source ~/.bashrc
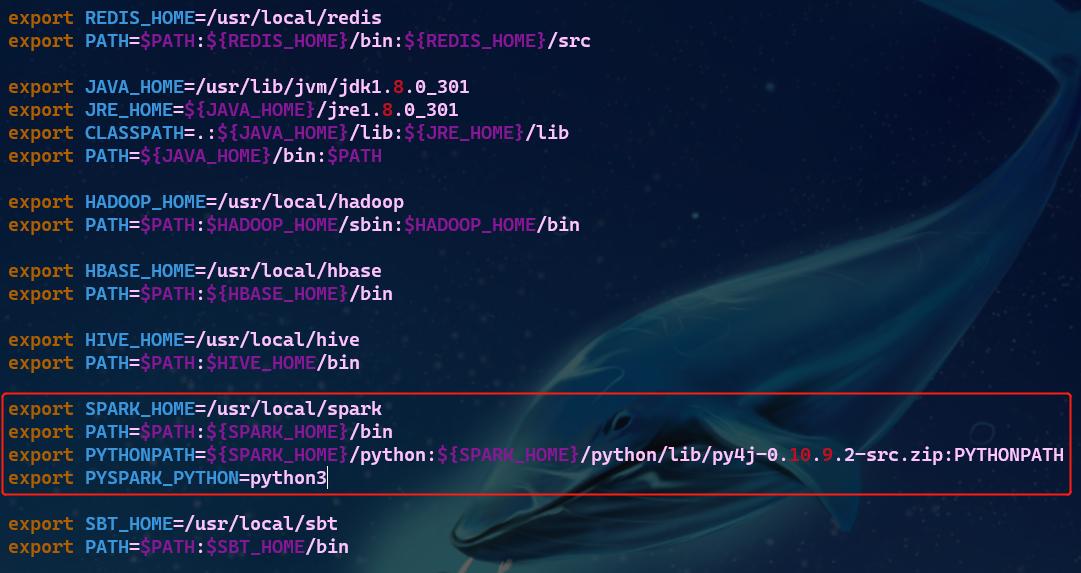

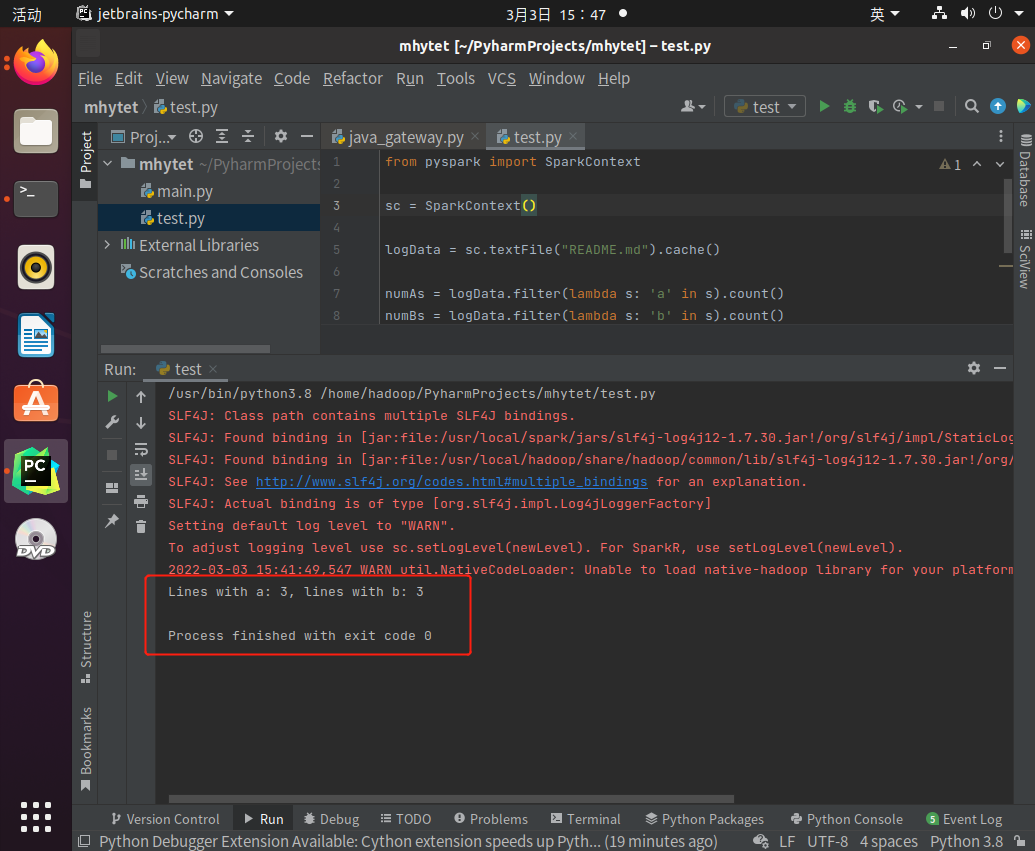
- 运行Python代码

2.Python编程练习
- 准备文本文件


- 读文件
# 打开文件
file = open(r'D:\Desktop\data.txt',encoding='utf-8')
# 读取文件
data = file.read()
# 关闭文件
file.close()
- 预处理:大小写,标点符号,停用词
# "-"用" "代替
data = data.replace('-',' ')
# 去掉标点符号,去掉首尾
word_list[i] = word_list[i].strip(string.punctuation)
# 统一小写
word_list[i] = word_list[i].lower()
- 分词
# 生成所有单词的列表
word_list = data.split()
- 统计每个单词出现的次数
# 统计词频与单词
if word_list[i] in data_dict:
# 不是第一次
data_dict[word_list[i]] = data_dict[word_list[i]] + 1
else:
# 第一次
data_dict[word_list[i]] = 1
- 按词频大小排序
# 遍历字典
for key,value in data_dict.items():
# 变量值,变量
temp = [value, key]
# 添加数据
data_list.append(temp)
# 排序
data_list.sort(reverse = True)
- 结果写文件
# 写入文件
with open(r'D:\Desktop\data_out.txt','w') as files:
for value,key in data_list:
files.write('{} {}\n'.format(value,key))
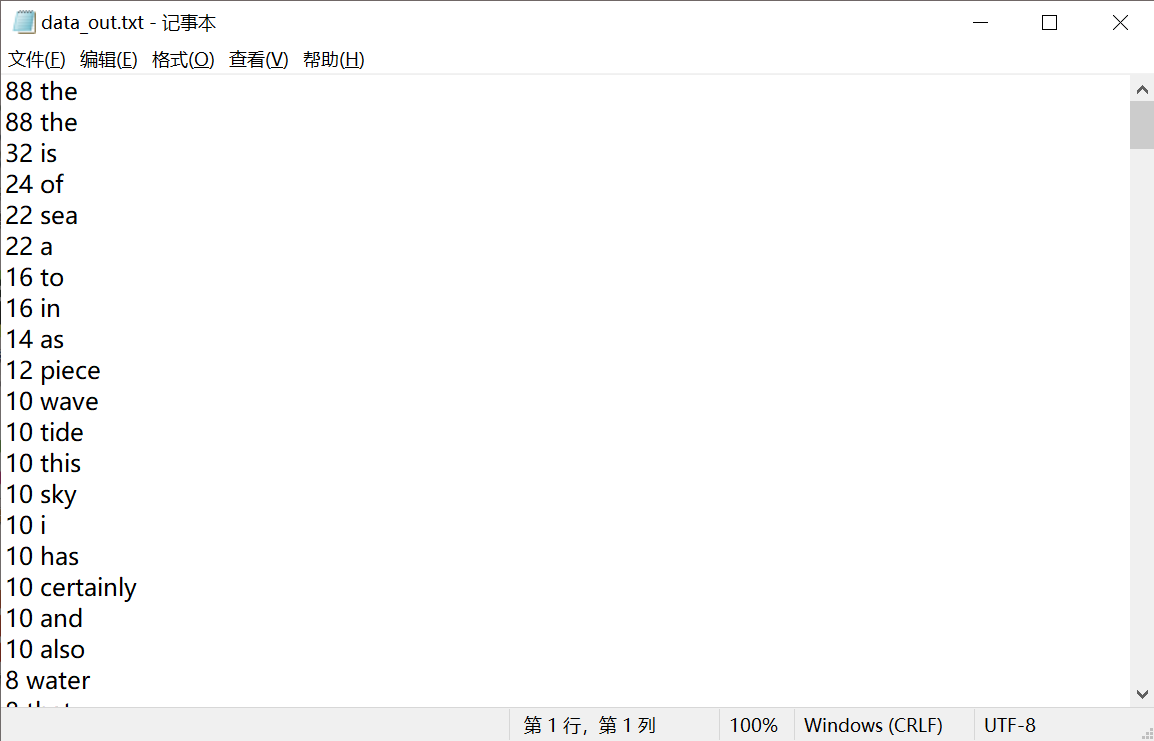
点击查看代码
# 导入字符串模块
import string
# 导入re模块
import re
# 导入matplotlib模块,取别名plt
import matplotlib.pyplot as plt
# 创建一个空字典,放词频和单词,无序排列
data_dict = {}
# 创建一个空列表,放词频和单词,有序排列
data_list = []
# 打开文件
file = open(r'D:\Desktop\data.txt',encoding='utf-8')
# 读取文件
data = file.read()
# 关闭文件
file.close()
# "-"用" "代替
data = data.replace('-',' ')
# 生成所有单词的列表
word_list = data.split()
# 对数据进行处理,并存入
for i in range(len(word_list)):
# 去掉标点符号,去掉首尾
word_list[i] = word_list[i].strip(string.punctuation)
# 统一小写
word_list[i] = word_list[i].lower()
# 统计词频与单词
if word_list[i] in data_dict:
# 不是第一次
data_dict[word_list[i]] = data_dict[word_list[i]] + 1
else:
# 第一次
data_dict[word_list[i]] = 1
# 打印字典(单词与词频,无序)
print(data_dict)
# 遍历字典
for key,value in data_dict.items():
# 变量值,变量
temp = [value, key]
# 添加数据
data_list.append(temp)
# 排序
data_list.sort(reverse = True)
# 打印列表(单词与词频,有序,从多到少)
print(data_list)
# 写入文件
with open(r'D:\Desktop\data_out.txt','w') as files:
for value,key in data_list:
files.write('{} {}\n'.format(value,key))
3.根据自己的编程习惯搭建编程环境
- 使用pycharm
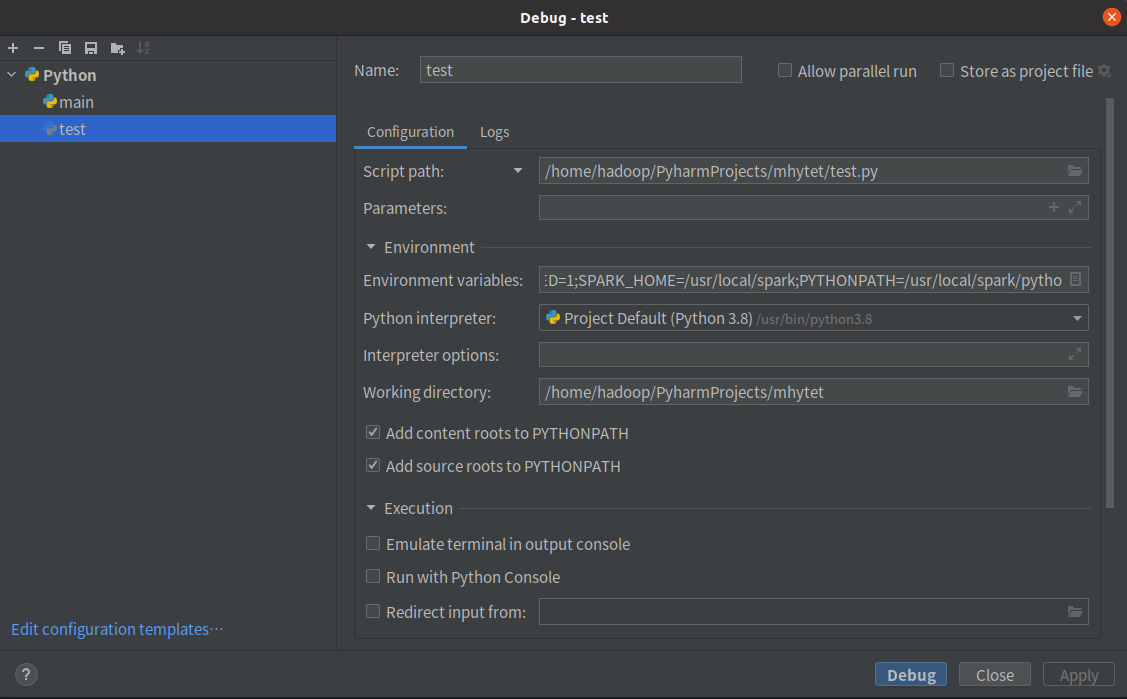
新建README.md文件,上传至hdfs://master:9000/user/hadoop/README.md


 浙公网安备 33010602011771号
浙公网安备 33010602011771号