
软件工程实践个人编程作业
| 这个作业属于哪个课程 | 软件工程2020秋学期 |
|---|---|
| 这个作业要求在哪里 | 个人编程作业 |
| 这个作业的目标 | 学习 Python 常用库实现数据处理、性能优化,以及单元测试等过程,巩固 Git 使用 |
| 学号 | 031802113 |
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | 180 | 240 |
| Design Spec | 生成设计文档 | 10 | 30 |
| Design Review | 设计复审 | 10 | 5 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 180 | 300 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 20 | 40 |
| Size Measurement | 计算工作量 | 10 | 5 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 40 | 80 |
| 合计 | 610 | 930 |
解题思路描述与设计实现过程
我最终上传的代码是一份 Python 实现的简单的调用 SQLite 数据库的程序。
怎么说呢,其实成品与我的计划完全不同……🙄基本上可以说完全是因为赶工期误打误撞才写成了调用数据库的样子。为了解释这一点,我想按照时间的顺序,说说我这一周都想了些什么,干了些什么,并在其中穿插完成博客作业的任务。不过我估计会很啰嗦,看当前代码分析的话跳到代码说明即可。
9 月 8 日(周二):拿到题目,思考方案
刚拿到题目一下子有点懵。题目程序的任务倒不难懂。不过这给个 Python 的代码是什么意思?说好的三种语言都有范例呢?我是要改,还是重写呢?粗看下来参考程序的结构倒不算太难理解,不过细看之下我很快就陷入了“递归式学习”。😵os、json、argparse 三个库我没一个熟悉的,各个变量、函数也看得我眼花缭乱。半个晚上的时间都奉献给了百度。json 库中 load、loads、dump、dumps 函数的区别让我花了好一番时间理解。
大致理解代码了之后,我跑了一遍测试数据,看起来还不错。尝试跑了次 9G(解压后)的数据,这时问题出现了:初始化时程序直接占去了 10G 的内存,不久我突然发现 C 盘满了,赶紧结束了程序。(后来想想应该是内存不够用使用了硬盘空间作为虚拟内存)考虑到时间较紧,我这时定下的目标是基本理解参考程序,并在此基础上修改代码适应大量数据处理。当天先 fork 了 GitHub 上 fzusoft/2020-personal-python 仓库。
9 月 9 日(周三):第一步优化
这天继续分析代码,以分析内存爆炸的原因为基本方向。不久发现了一个明显的问题,即参考程序是将 JSON 数据文件全部读出后才进行转化和储存。而原始数据文件中含有大量无效数据,真正有用的只有 actor__login、repo__name 和 type 这三项。因此第一步优化就是将原始数据读入部分改为读一行处理一行。此时初始化基本能在 7~8 分钟内跑完,内存占用也大幅下降,完成了初步优化目标。
接下来的方向,我考虑的是并行读入,即多线程优化,以充分利用多核 CPU 的优势。也考虑过用 C++ 重写,但害怕时间来不及,以及调库可能没那么方便。虽说 C++ 写算法题快,可我这手写的输入输出是否能比优化过的库快,我也没啥信心,遂放弃。该天还按要求提交了 Pull request。由于满课,没干多少别的事。
9 月 10 日(周四)~ 9 月 13 日(周日):基本没干啥
从周四晚上到周日晚上,我基本全天忙于数学建模竞赛的事,中间还通宵了一天,近期应该不敢再爆肝了……(命要紧,命要紧)总之这几天软工实践这边确实没干啥,比较无奈。周日晚上写了代码规范。
9 月 14 日(周一):尝试多线程、多进程读入优化
周一晚上接着上周三的代码来修改。可是搜了一下 Python 多线程,查到的结果却是说 Python 多线程是假的,由于什么全局解释器锁,实际上还是轮流执行的。我不信邪,还是写了一份。结果发现不仅内存翻倍了,运行时间好像还慢了一点。好吧,那就用多进程。
我采用的做法是将参考代码 init 函数中 for f in files 之下的部分独立写成一个 read 函数,引入 multiprocessing 模块,通过多进程调用这个函数来加速运行。细节上先后采用了手动创建进程和使用进程池(pool)的方法,感觉区别不太大,进程数较多时后者比较方便一些。
pool = multiprocessing.Pool(5)
for f in files:
pool.apply_async(self.read, (f, dict_address,))
pool.close()
pool.join()
但我很快发现了问题:读文件倒是快了,可是初始化生成的 JSON 文件都是空的!调试发现 __4Events4PerP、__4Events4PerR、__4Events4PerPPerR 这三个 list 本身就是空的。倒也不难理解,多个进程同时读写变量很容易出问题的嘛。改 global 当然没用,那些锁机制什么的还不太懂,几番搜索终于发现一个“好东西”,叫做 multiprocessing.Manager,用它构造变量就可以自动处理这些写入冲突了。
我试写了几个样例程序,感觉没问题,就开始改代码了。然而,结果依然没什么变化!找了数十分钟 bug 才发现,for i in records 里的赋值语句不能正常工作。而且它竟然不!报!错!🤬只是默默地不执行。(现在看应该用代码覆盖率测试)原因就是这个类只支持对单层 dict 的赋值操作,而代码中已经有三层了。替代方案的话,用 dict.update 似乎并不行,我是没想到办法在保留第三层原数据的情况下加入新数据。那就压缩成单层?于是我尝试把三层的键按字符串拼接。程序倒是能跑了,不过这开销着实大,速度还不如单进程呢。
于是,发现浪费了一晚上、离 deadline 只剩两天(周四交四舍五入等于扣分啊)的我,只好先放弃。代码也没有 push 到 GitHub 上。
9 月 15 日(周二):尝试用 SQLite 数据库
这天继续想解决方案,想了一上午,有点思路基本也马上发现不可行给否了。上到数据库课,想着反正也没啥别的思路了,不如试试调用数据库重写?反正也没说不能嘛……虽然我之前没有接触过数据库,上手倒是意外的容易。(中间被 sqlite3.cursor 坑了一段时间)性能也让我挺惊讶的:初始化的时候内存占用相当小,速度也还不错,对上面说的测试数据可能比手写多进程慢些,但基本两三分钟也可以跑完。
不过初始化的目的其实变了:参考程序在初始化中就完成了数字统计,按格式存入 JSON 文件。而这一版程序其实只是去除了冗余数据之后存入数据库,统计是在查询中完成的,当然保存的也是数据库文件而不是 JSON。
查询就比之前快多了。虽然查询的时候才实时统计,但看起来仍比文件读写要快不少。接下来得去了解了解数据库的黑科技啊。(但是好像代码不是百分百稳定,暂时不知原因)
(更新)9 月 20 日(周日):完成多进程 json 文件读写版本
代码文件在 GitHub 上的 GHAnalysisMP.py 中。这几天还是一堆事情要补,于是拖到了现在才完成。采用的折衷方案是:先用多进程筛选数据暂存,再用单进程读入筛选后的数据。本次采用重写,而不再在参考程序基础上修改。本来预想这样做还是一大块单进程,应该快不了多少,不过可能数据冗余度实在太高了,初始化时间的改进还是挺可观的,比上面说的单进程数据库处理方式要快。查询没做什么特殊处理,因此速度当然慢于数据库,不过仍明显比参考程序快,好像是因为原版不管查询什么都是先把三个文件读入。下文补了一张初始化时间对比表格,其他部分仍保留数据库版本的。
代码说明
这份代码真挺简单的。导入 os、argparse、json、sqlite3 共 4 个库,没有自定义类。
一共 2 个函数,其中 init 负责初始化,接受一个字符串参数用于指示数据文件存放目录;query 负责初始化后的查询,用第一个整数参数决定查询类型(0、1、2 分别代表按用户、事件查询,按仓库、事件查询,按用户在仓库的事件查询),另三个可选参数接受用户名、仓库名和事件类型。主函数根据传入参数调用这两个函数之一,函数中再执行创建和查询数据库的 SQL 语句。
大致框架如下:
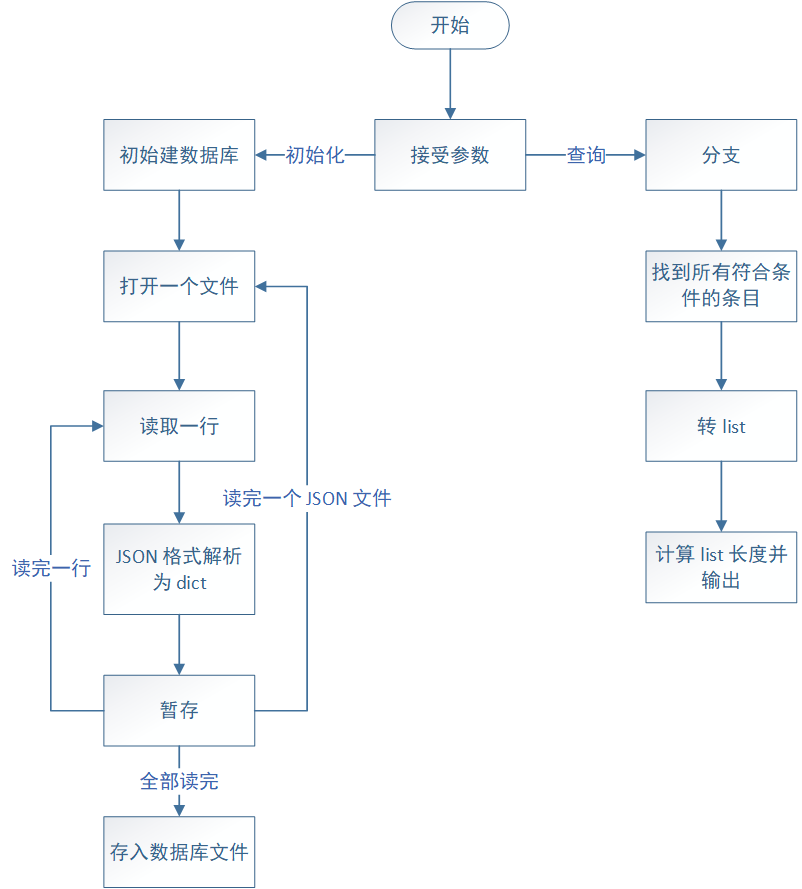
各部分简要分析:
主函数:
if __name__ == '__main__':
# 设置接受的参数
parser = argparse.ArgumentParser()
parser.add_argument(
'-i', '--init', help='Initialize the database with files in the folder given.')
parser.add_argument('-u', '--user', help='Provide a user name.')
parser.add_argument('-r', '--repo', help='Provide a repository\'s name.')
parser.add_argument('-e', '--event', help='Provide a type of events.')
# 处理传入的参数
args = parser.parse_args()
if args.init:
init(args.init)
else:
# 未初始化
if not os.path.exists('data.db'):
raise RuntimeError('Error: Initialization is required.')
elif args.event:
if args.user:
if args.repo:
# 三个参数都提供即为第 3 种查询
query(2, user=args.user, repo=args.repo, event=args.event)
else:
query(0, user=args.user, event=args.event)
elif args.repo:
query(1, repo=args.repo, event=args.event)
else:
raise RuntimeError('Error: Argument -l or -c is required.')
else:
raise RuntimeError('Error: Argument -e is required.')
这一部分主要是接受与传递参数,整体逻辑和参考程序基本没有差别。代码也采用了相同的 argparse 库。原本自己只知道用 sys.argv 这个 list 来传参,但对参数缩写和顺序都要手动处理,argparse 库确实方便不少。
代码逻辑就是先设置接受的参数,这是每次运行程序都要跑的公共部分。接着按输入参数分为初始化和 3 种查询,以及异常的情况,应该很容易看懂。
初始化函数:
def init(directory):
# 初始化建表
if os.path.exists("data.db"):
os.remove("data.db")
connector = sqlite3.connect("data.db")
connector.execute('''CREATE TABLE GITHUB (
user_name TEXT NOT NULL,
repo_name TEXT NOT NULL,
event TEXT NOT NULL
);''')
connector.commit()
for fileName in os.listdir(directory):
if fileName.endswith(".json"):
fullPath = directory + '/' + fileName
with open(fullPath, 'r', encoding='utf-8') as file:
for line in file:
# 读取 json 文件中一行并暂存有效数据
data = json.loads(line)
insertData = (data['actor']['login'],
data['repo']['name'], data['type'])
sqlInsert = 'INSERT INTO GITHUB(user_name, repo_name, event) VALUES(?, ?, ?)'
connector.execute(sqlInsert, insertData)
# 实际写入文件
connector.commit()
print(0)
connector.close()
该函数接受一个参数,即从主函数传入的目录名。首先检查是否已存在数据库文件,如果有则删除。sqlite3.connect 语句可以建立 Python 代码与数据库间的联系。之后执行 SQL 建表语句,三个项目覆盖了查询内容。之后调用 os 库读取文件列表,使用文件输入指令逐行处理各个数据文件,并调用 json 库将数据文件转为 dict 类型。再调用 SQL 语句添加表项。最后 commit 写入文件。
查询函数:
def query(query_type, user="", repo="", event=""):
connector = sqlite3.connect("data.db")
getCount0 = 'SELECT * FROM GITHUB WHERE user_name=? AND event=?'
getCount1 = 'SELECT * FROM GITHUB WHERE repo_name=? AND event=?'
getCount2 = 'SELECT * FROM GITHUB WHERE user_name=? AND repo_name=? AND event=?'
if query_type == 0:
# 查用户事件数
value = connector.execute(getCount0, (user, event))
elif query_type == 1:
# 查仓库事件数
value = connector.execute(getCount1, (repo, event))
elif query_type == 2:
# 查用户在仓库的事件数
value = connector.execute(getCount2, (user, repo, event))
result = len(list(value))
print(result)
connector.close()
return result
查询的代码应该也很容易看懂。首个参数对应三种查询类型,后三个参数默认为空字符串,需要时才传入。SQL 的查询语句用 AND 组合各条件。value 是一个数据库的 cursor,指向符合条件的所有数据。这时用 list 函数将其转换为列表,再用 len 函数计算列表项目数,即得到查询结果。
单元测试、覆盖率、性能测试
这一块我理解上可能会有些偏差。操作上大部分使用了 PyCharm 的相关内置功能。
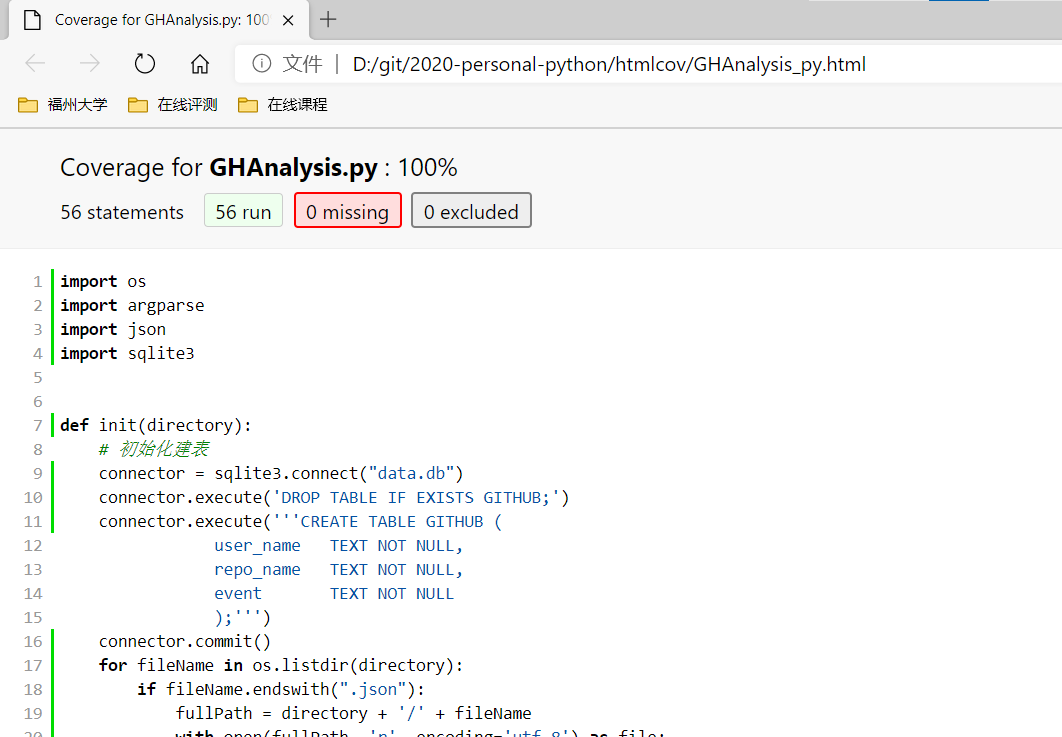
单元测试按我的理解似乎是测函数的?如果是这样的话那主函数的部分就是覆盖不到?这里我设计了三组测试过程,查询语句相同而初始化使用的数据文件不同(第一组 34 MB,第二组 1.27 GB,第三组 9.06 GB),正解是使用参考程序得出。测试代码及结果的截图如下:
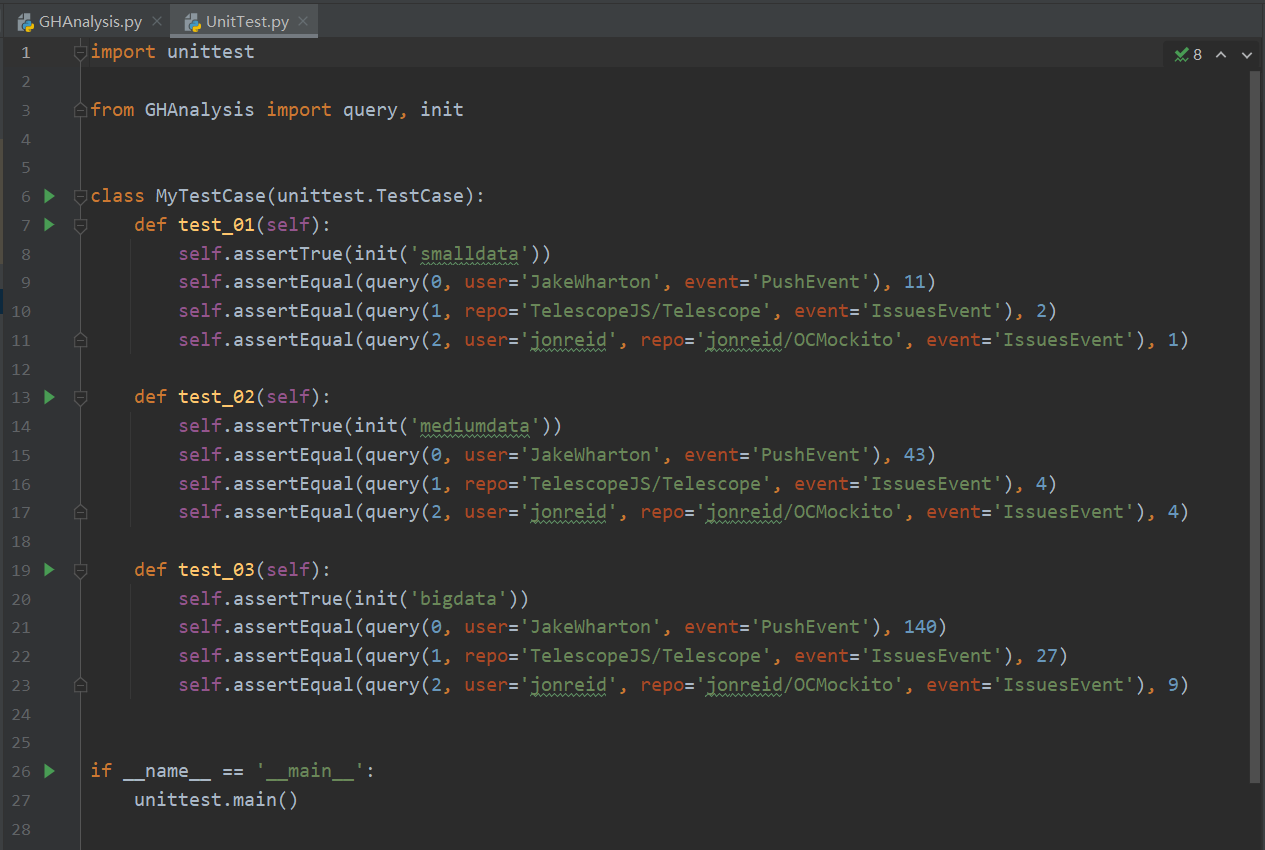

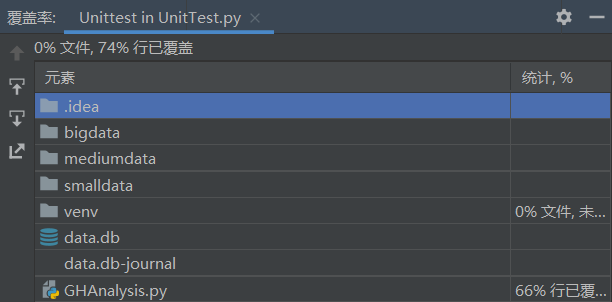
之后又用 pip 安装了 coverage 库,并用命令行方式尝试了各种能考虑到的情况,将覆盖率整合,是能达到 100% 的。(不过我是不是理解错了?)
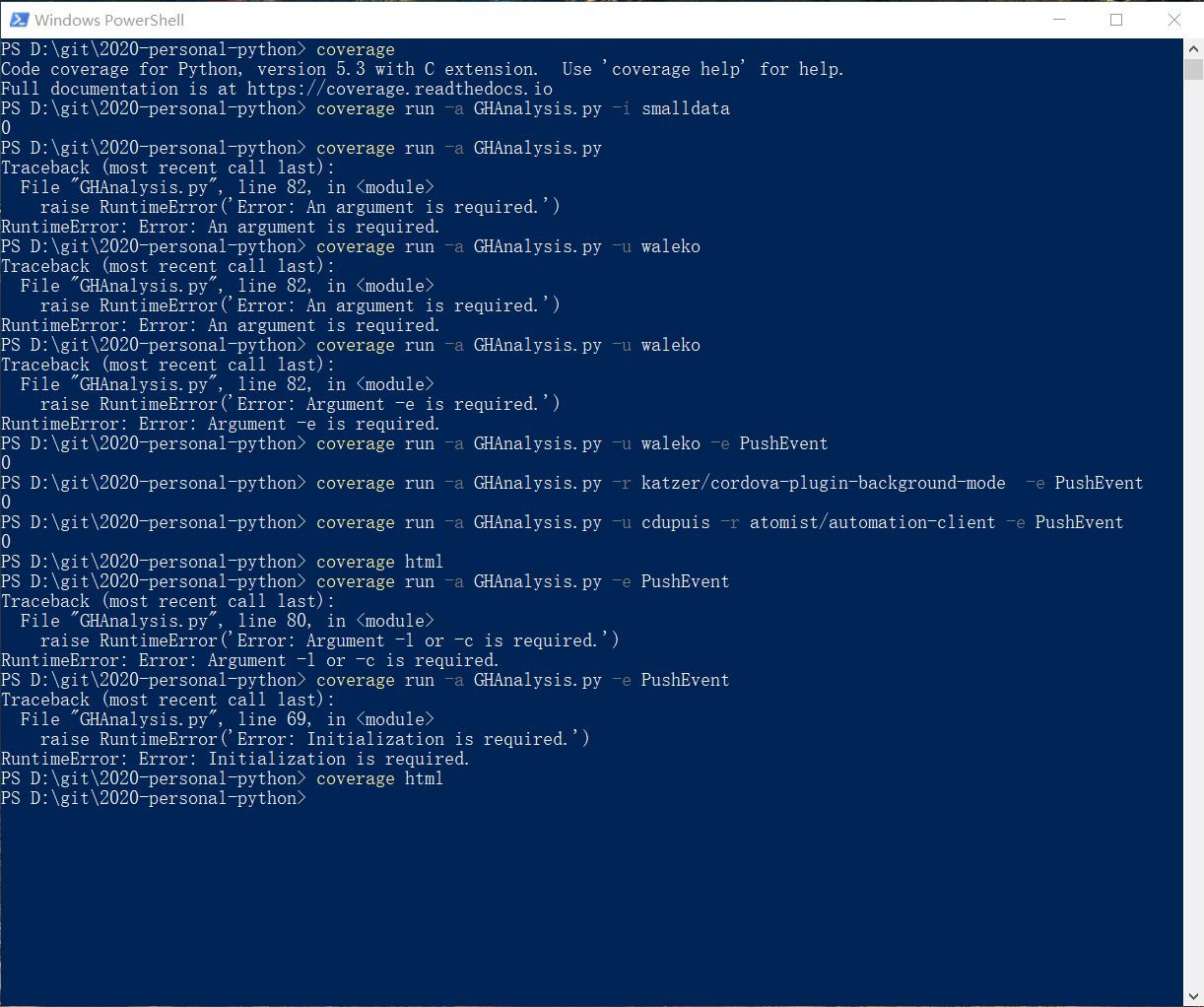
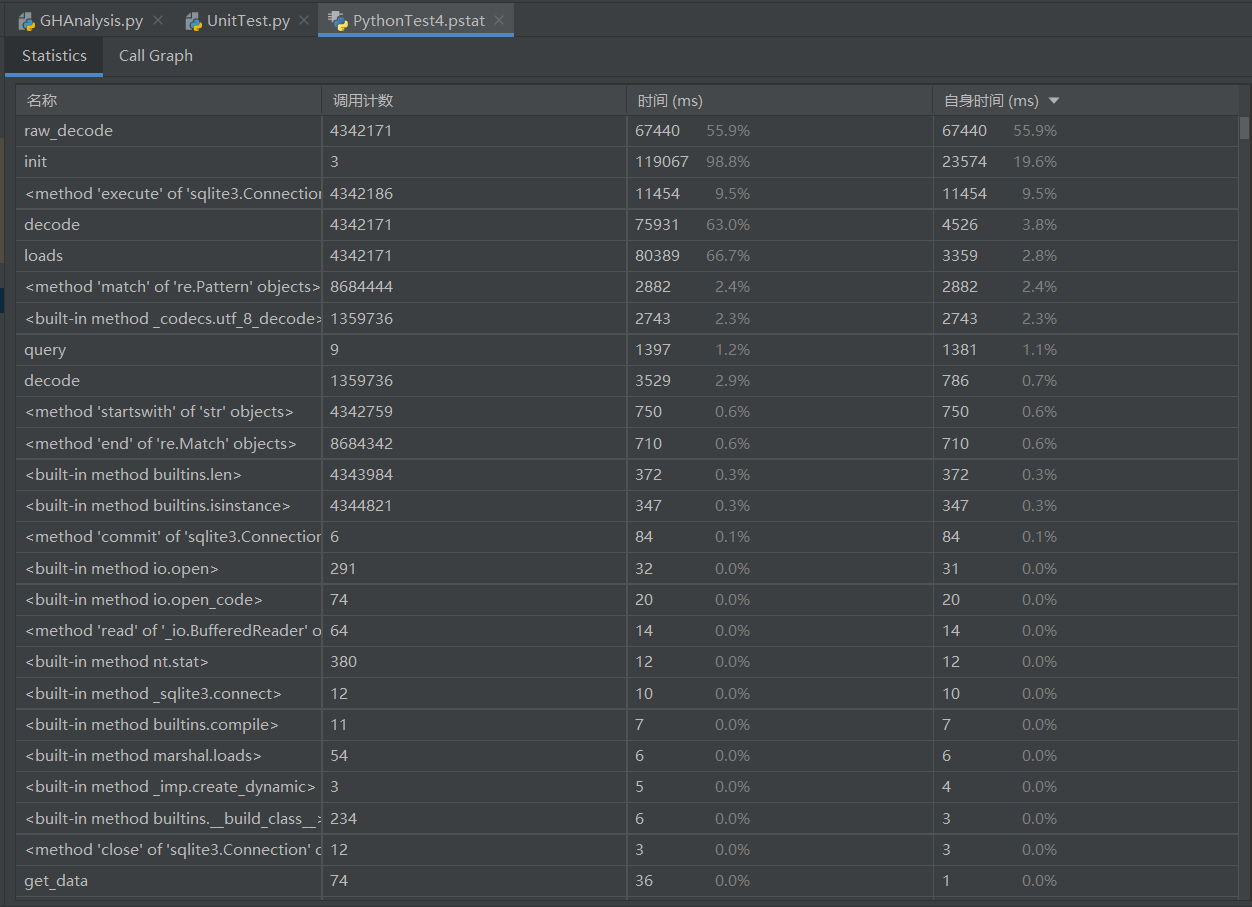
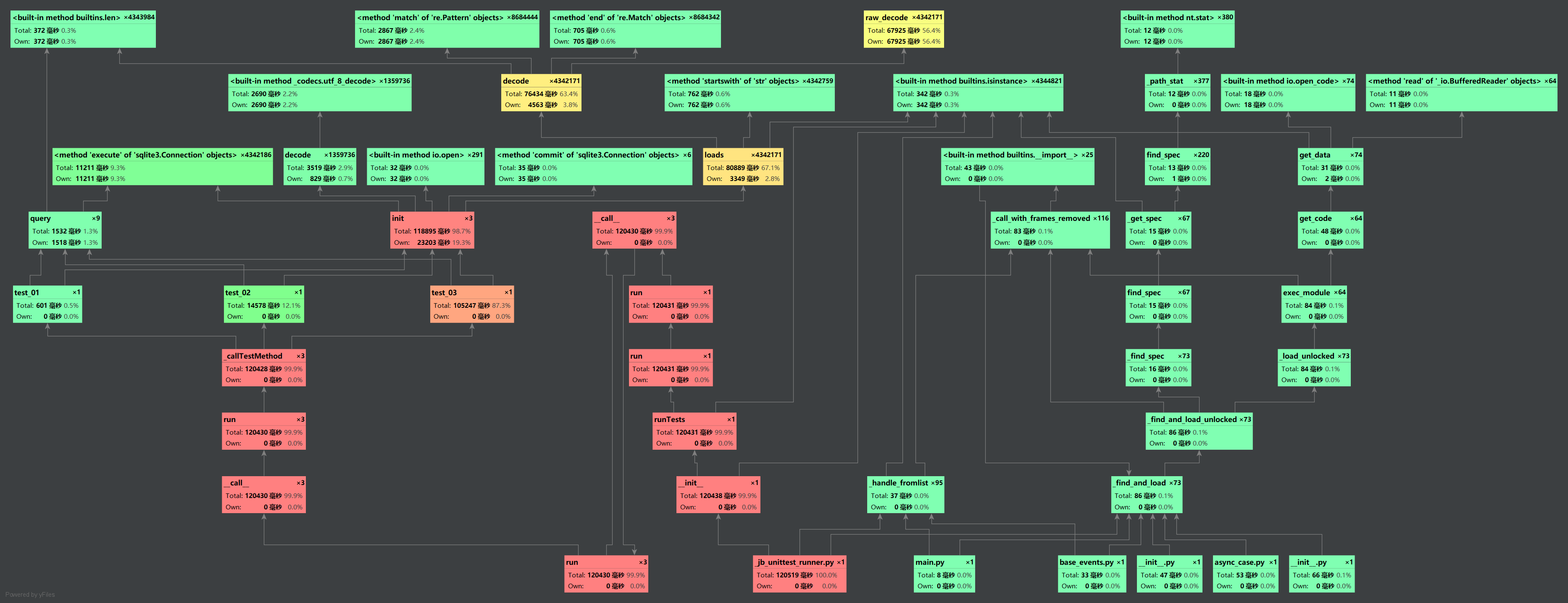
性能测试试着用了 PyCharm 的 Profile 功能,得到如下结果:(用上面的三组测试跑的,还不知道怎么用比较好)
各版本运行时间对比
以下初始化时间是在我自己的笔记本电脑(6 核 12 线程)上测试所得,用 Python time 库中函数计时,三次运行取平均值。可以看出,单进程数据库版本的表现进似于 2 进程的 JSON 文件版。如果说评测环境是双核的话,那多进程的优势也不算很明显?
| 1.27GB | 9.06GB | |
|---|---|---|
| 原始版本 | 57s | ?(内存不足) |
| 原始版本初步优化 | 58s | 433s |
| 重写数据库版 | 13s | 93s |
| 重写 JSON 文件版(单进程) | 23s | 162s |
| 重写 JSON 文件版(2 进程) | 15s | 98s |
| 重写 JSON 文件版(4 进程) | 10s | 67s |
| 重写 JSON 文件版(8 进程) | 8s | 56s |
| 重写 JSON 文件版(12 进程) | 8s | 51s |
查询时间记录的是按上述 9.06GB 文件分别初始化后,进行一次查询所需时间。可以看到,原始版尽管初始化后生成了 1.json、2.json、3.json 三个文件,但由于查询时三个文件都读入,因此所需时间最长且相近。数据库由于保存在同一文件中,三种查询耗时基本一致,得益于其出色的优化,为三者中最快。我后续重写的 JSON 文件版本由于只读入相应查询类型的文件,因此时间也与类型有关,总体时间位于以上二者之间。
| -u 查询 | -r 查询 | -u -r 查询 | |
|---|---|---|---|
| 原始版本 | 3.11s | 3.17s | 3.13s |
| 重写数据库版 | 0.37s | 0.37s | 0.37s |
| 重写 JSON 文件版 | 0.47s | 0.61s | 2.04s |
代码规范
请点击链接到我的 GitHub 仓库查看代码规范。该代码规范主要参考了 PEP 8,仅适用于 Python 代码。
总结
- (9.20 代码已上传)希望这几天能重写一份多进程 json 读写的代码,毕竟这是我的出发点,而且数据库确实规避了很大一块的数据处理和转换。不过可能赶不上截止日期了。
- 虽说有客观时间限制,但完不成既定目标很大程度上还是因为我对 Python 和相关库的理解运用还很肤浅,需要更多的实践。
- 还是没怎么用到软件工程的思想,整体开发流程依然比较盲目,像单元测试都是最后补的,PSP 表格也不太准,没养成实时记录与复查的习惯。
- 学到了 Python 中 os、json、argparse、time 库和文件读写的基本使用,多进程
虽然还没写成功,基本用法也是了解了。 - 很意外地学习了 SQL 的基本语句。
- Git 和 GitHub 用得更熟悉了一些。不过回头看好像应该用用 Git 的分支功能比较好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号