
Datawhale AI夏令营 ——让AI读懂财报PDF(多模态RAG)
Task 1 跑通 baseline 没遇到什么大问题,刚开始忘记修改 .env了。
Task 2 快速看完整个优化思路和代码解析,决定先从第5个方向——升级数据解析方案:从 fitz 到 MinerU 入手,这个方向目前来看不需要读懂大模型思路。
升级数据解析方案
根据手册的操作,运行 python mineru_pipeline_all.py,没想到就报错了。
Traceback (most recent call last):
File "/mnt/workspace/AISumerCamp_multiModal_RAG/mineru_pipeline_all.py", line 7, in
from image_utils.async_image_analysis import AsyncImageAnalysis
ModuleNotFoundError: No module named 'image_utils'!
根据报错信息,在 mineru_pipline_all.py 中调用了 image_utils,缺少该模块。原本以为是第三方库,下载一直报错。翻了群里的聊天记录,找到了这是自定义模块。可以重新克隆下仓库,或者把里面的 image_utils 文件夹内的内容添加到你的 Notebook 环境里面。
GitHub - li-xiu-qi/spark_multi_rag: 科大讯飞多模态RAG图文问答挑战赛
注意:如果你是直接克隆这个库,里面是不包含 datas 文件的,需要把之前的仓库中的数据源文件复制过来。另外里面的json 文件名也与我们的 baseline 是不一样的,记得修改。
添加完成后,发现还是运行不起来,python 没有识别到这个自定义模块。需要在 image_utils 文件夹中添加一个文件 __init__.py,内容空白就行。
添加完成后,这个脚本就可以跑起来了,期间会有几次报错,找不到模块(x)
你可以先把以下三方库安装一下,由于每次运行环境都需要重新装依赖,建议你可以把下面的几个模块加到 requirement.txt 里面,下次就可以使用 pip install -r requirements.txt 快速安装。
loguruminerudoclayout_yoloultralyticsrapid-table<2
rapid_table需要使用pip install "rapid-table<2"命令安装,否则你可能会得到如下错误:
TypeError: RapidTableInput.init() got an unexpected keyword argument 'model_path'
都安装完成后,就可以愉快地解析了
解析过程中发现有的 PDF 文件会报以下错误:
Cannot set gray non-stroke color because /'P158' is an invalid float value
查看参考资料2,似乎不一定会影响解析,先跳过这个信息。解析完再看是否有异常。
这个解析过程要很长时间,可以先去做点别的事情啦。
已处理过的不再处理
在解析过程中发现解析过程要很长时间,本来是放着让他晚上自己解析的,但是 notebook 因为实例时间限制关闭了,还有小部分未解析。在代码中添加解析过的不再解析,就可以让他只处理后面的部分,这样减少了实例占用时间,也减少了重复工作。
def parse_all_pdfs(datas_dir, output_base_dir):
……
for pdf_path in pdf_files:
file_name = pdf_path.stem
output_dir = output_base_dir / file_name
print(f"output_idr: {output_dir}")
content_json_path = output_dir / file_name / 'auto' / (file_name + '_content_list.json')
print(f"content_json_path {content_json_path}")
if content_json_path.exists():
print(f"已处理过: {pdf_path.name},跳过解析")
continue
with open(pdf_path, "rb") as f:
pdf_bytes = f.read()
……
print(f"已输出: {content_json_path}")
def process_all_pdfs_to_page_json(input_base_dir, output_base_dir):
for pdf_dir in pdf_dirs:
……
if not json_path.exists():
……
else:
print(f"未找到: {json_path} 也未找到: {json_path2}")
continue
# 检查输出文件是否已存在
output_dir = output_base_dir / file_name
output_json_path = output_dir / f'{file_name}_page_content.json'
if output_json_path.exists():
print(f"已处理过: {file_name} 的page_content,跳过转换")
continue
with open(json_path, 'r', encoding='utf-8') as f:
content_list = json.load(f)
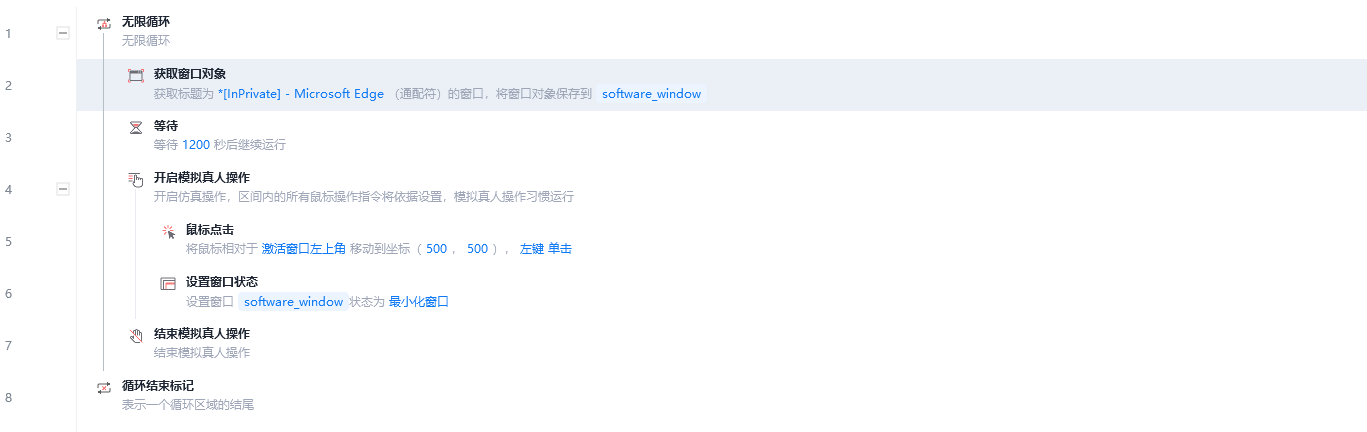
针对魔搭一小时实例未点击就会关闭,30分钟未点击就会提示的问题,可以使用影刀(其他RPA工具应该也可以)进行处理,我写了一个简单的小工具让它20分钟点击窗口一次,测试可用。类似于下面的图片,根据你自己使用的窗口进行修改。如果你使用的是免费额度的GPU实例,记得按时关掉这个自动化工具,不然额度就溜走了🤣
RAG 处理过程中频繁报错的解决
改成全量跑之后,尝试运行了几次 rag_from_page_chunks.py 都在中间出错了,导致我一直没有跑出来全量的结果。参考了 DataWhale 学习手册后面补充的内容后,知道了要限制它的调用,避免1分钟内超量,让豆包帮我调整代码后它给了我一个chat.completions.create重试的装饰器,但我尝试之后仍然会因为各种错误中断。
于是我想这是否可以参考构建向量库时的重试机制,在构建向量库的过程中,日志有打印触发 TPM 重试等待的信息。这部分代码位于 get_text_embedding.py 中,通过捕获异常,循环再次调用。
retry_count = 0
while True:
try:
response = client.embeddings.create(
model=embedding_model,
input=batch_texts
)
batch_embeddings = [embedding.embedding for embedding in response.data]
all_embeddings.extend(batch_embeddings)
break
except RateLimitError as e:
retry_count += 1
print(f"RateLimitError: {e}. 等待10秒后重试(第{retry_count}次)...")
time.sleep(10)
参考这个处理方式,对generate_answer中的主体处理方法进行异常捕获处理,就可以避免问答过程因为 RateLimitError, APIConnectionError 或者其他类似于网络异常,调用量超过阈值的异常的程序中断,以便跑完全量的数据。
加入 Rerank 的方法也尝试了,但只提升了 0.01 分 (x
参考资料
本文来自博客园,作者:JunyuHuang,转载请注明原文链接:https://www.cnblogs.com/mgtpez/p/19030149/datawhale-learn-rag

 浙公网安备 33010602011771号
浙公网安备 33010602011771号