

数据库
数据库
第一部分 数据库系统[1]
1.1.组成
数据库系统(DataBase Systems)由 用户、数据库应用程序、数据库管理程序、数据库 组成:

-
用户
- 最终用户:调用数据库应用程序操作数据库数据。数据库应用程序基于数据库管理程序提供的接口和环境。
- DBA 用户:使用 DBMS 软件提供的管理根据对数据库进行创建、管理、维护。
-
数据库应用程序:一种在 DBMS 支持下对数据库进行访问和处理的应用程序。它们以窗口或页面等表单形式来读取、更新、查询或统计数据库信息,从而实现业务数据处理与信息服务。数据库应用程序需要使用 DBMS 提供的标准接口(如 ODBC、JDBC 等)驱动程序连接数据库。在程序设计语言(如 Java、C++、C#、VB、PB 等)编程中,我们需要使用数据库访问接口实现对数据库的操作。
-
数据库管理系统:数据库管理系统是一类用于创建、操纵和管理数据库的系统软件。
一般具有如下功能:①创建数据库、数据库表及其他对象;②读/写、更新、删除数据库表数据;③维护数据库结构;④执行数据访问规则;⑤提供数据库并发访问控制和安全控制;⑥执行数据库备份和恢复。
其结构层面如下:
![]()
- 操作界面层:由若干管理工具和应用程序 API 组成,它们分别为用户和应用程序访问数据库提供接口界面。
- 语言翻译处理层:对应用程序中的数据库操作语句进行语法分析、视图转换、授权检查、完整性检查、查询优化等处理。
- 数据存取层:处理的对象是数据表中的记录,它将上层的集合关系操作转换为数据记录操作,如对数据记录进行存取、维护存取路径、并发控制、事务管理、日志记录等。
- 数据存储层:基于操作系统提供的系统调用对数据库文件进行数据块读/写操作,并完成数据页、系统缓冲区、内外存交换、外存数据文件等系统操作管理。
MySQL、Redis 是一种 DBMS。
-
数据库:存放系统各类数据的容器。该容器按照一定的数据模型组织与存储数据。除了存放用户数据外,我们还需要存放描述数据库结构的元数据。例如,在关系数据库中,各个关系表的表名称、列名称、列数据类型、数据约束规则等都是元数据,这些描述数据库结构的数据需要存放在数据库的系统表中。

1.2.Normal Forma
关系数据库的规范化范式有 6 种:
- 第一范式(1NF):关系表的属性列不能重复,并且每个属性列都是不可分割的基本数据项。
- 第二范式(2NF):满足 1NF 的同时,消除关系中的属性部分函数依赖。
- 第三范式(3NF):满足 2NF 的同时,所有非主键属性均不存在传递函数依赖。
- 巴斯-科德范式(BCNF):满足 3NF 的同时,所有函数依赖的决定因子必须是候选键。
- 第四范式(4NF):满足 BCNF 的同时,消除多值依赖。
- 第五范式(5NF):如果一个关系为消除其中连接依赖,进行投影分解,所分解的各个关系均包含原关系的一个候选键。
在数据库应用中,一般满足 3NF 或 BCNF。
1.3.事务
数据库中,事务指由构成单个逻辑处理单元的一组数据库访问操作,这些操作的 SQL 语句被封装在一起,要么都被成功执行,要么都不被执行。事务是 DBMS 执行的最小任务单元。
事务的 ACID 特性:
- 原子性(Atomicity)
- 一致性(Consistency):指事务执行前后都为正常状态。
- 隔离性(Isolation):指多个事务并发执行时,事务对数据的修改对其他并发事务是隔离的,各个并发事务之间不能相互影响。
- 持续性(Durability):指事务提交后对数据库中数据的修改是永久性的。
BEGIN/START TRANSACTION为事务开始语句,COMMIT保存修改到数据库文件中并该事务结束,ROLLBACK回滚事务到事务开始或者SAVEPOINT并该事务结束,SAVEPOINT会立即保存修改到数据库文件。DBMS 默认设置下,每条 SQL 操作语句都单独构成一个事务。
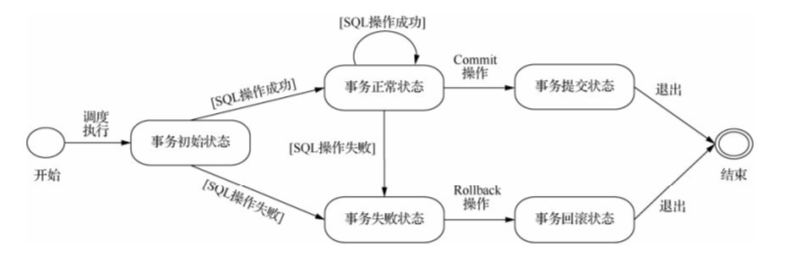
事务程序中,能写 DML、DQL,不能写 DDL(DDL 在数据库中自动提交,导致事务中断)。
1.4.并发
1.4.1.并发控制问题
- 脏读:A 事务读取了 B 事务修改后的数据,但 B 在 A 读取后 ROLLBACK 了。
- 不可重复读:A 事务多次读取数据,结果不一样或丢失。这是因为 B 事务在 A 读取之间执行了修改或删除。
- 幻读:A 事务多次读取数据,结果变多。这是因为 B 事务在 A 读取之间执行了添加操作。
- 丢失更新:A 事务更新(
并提交)后,后面查询发现不是更新值。这是因为 B 事务在 A 更新后又进行了更新。
1.4.2.事务调度、锁机制
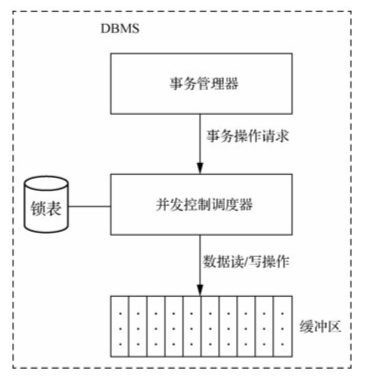
DBMS 并发控制调度器安排各事务数据读/写操作指令的执行顺序来实现针对共享数据访问。事务管理器将并发运行事务的数据读/写操作请求提交给并发控制调度器。并发控制调度器将各个事务的数据读/写指令按照一定顺序进行调度执行,并完成对数据库缓冲区的读/写操作。事务并发控制调度器确保在这些事务执行结束后,数据库始终处于一致性状态。
在事务并发运行中,只有当事务调度顺序的执行结果与事务串行执行的数据结果一样时,该并发事务调度才能保证数据库的一致性,符合这样效果的调度被称为可串行化调度。因此,DBMS 的并发控制调度器应确保并发事务调度是一种可串行化调度。
实现机理:当任何事务进行共享数据修改操作前,需要通过在锁表中对共享数据进行加锁处理,以禁止其他事务同时修改或删除该共享数据。当本事务修改共享数据结束并在锁表中进行解锁处理后,其他事务才被允许修改或删除该共享数据。
数据库锁机制可以在多种粒度(如数据库、表、页面、行的粒度级别)上对共享数据资源进行锁定处理。DBMS 中锁分为排他锁和共享锁:
- 排他锁:封锁其他事务对共享数据的任何加锁操作,限制其他事务对共享数据的修改、删除、读取操作。
- 共享锁:只封锁其他事务对加锁数据的修改或删除操作,但可以允许其他事务对加锁数据进行共享数据读操作。
两种锁的相容性(A 事务对资源加某种锁后,B 事务能否立即加某种锁):

加锁协议:
- 一级加锁协议:任何事务在修改共享数据对象之前,必须对该共享数据单元执行排他锁定指令,直到该事务处理完成,才执行解锁指令。该加锁协议可以防止“丢失更新”的数据不一致问题。
- 二级加锁协议:在一级加锁协议基础上,针对并发事务对共享数据进行读操作前,必须对该数据执行共享锁定指令,读完数据后即可释放共享锁定。该加锁协议不但可以防止“丢失更新”的数据不一致问题,还可防止出现脏读数据问题。
- 三级加锁协议:在一级加锁协议基础上,针对并发事务对共享数据进行读操作前,必须先对该数据执行共享锁定指令,直到该事务处理结束才释放共享锁定。该加锁协议不但可以防止“丢失更新”、“脏读”的数据不一致性问题,还可防止出现“不可重复读取”的数据一致性问题。

调度器按照两阶段锁定协议执行操作调度,实现对任意的事务请求顺序的并发事务操作可串行化调度。两阶段锁定协议指所有并发事务在进行共享数据操作处理时,必须按照两个阶段(增长阶段、缩减阶段)对共享数据进行加锁和解锁申请。在增长阶段,事务可以对共享数据进行加锁申请,但不能释放已有的锁定;在缩减阶段,事务可以对已有的锁定进行释放,但不能对共享数据提出新的加锁申请。实践证明,在并发事务运行中,若所有事务都遵从两阶段锁定协议,则这些事务的任何并发调度都是可串行化调度(充分条件,而不是必要条件),即这些并发调度执行结果可以保证数据库一致性。如下图 T1 不符合而 T2 符合两阶段锁定协议:
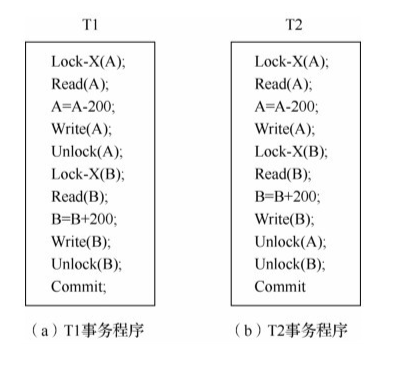
遵循两阶段锁定协议可能出现死锁情况(一次封锁法遵循两阶段锁定协议,但不会死锁)。数据库系统中解决死锁问题有两种策略:
- 在并发事务执行时,预防死锁:产生死锁的4个必要条件(互斥、请求和保持、不剥夺、环路等待)之一不成立,就可以最大限度地预防死锁。
- 在死锁出现后,其中一个事务释放资源以解除死锁:一般采用超时法或事务等待图法检测系统是否出现死锁,出现了死锁,通常选择一个处理死锁代价最小的事务进行撤销,释放该事务持有的所有锁定,使其他事务能够继续运行下去。
事务隔离级别:设置 DBMS 的事务隔离级别以避免并发控制问题。

1.5.相关技术
1.5.1.JDBC
JDBC 即 Java 数据库连接,SUN公司为使 Java 语言支持 SQL 功能而提供的与数据库相连的用户接口。JDBC 包括一组用 Java 语言书写的接口和类,独立于特定的 DBMS,统一对数据库的操作。有了 JDBC,可以方便地在 Java 语言中使用 SQL ,从而使 Java 应用程序或 Java Applet 可以对分布在网络上的各种关系数据库进行访问。但 JDBC 不能直接操作数据库,JDBC 通过接口加载数据库的驱动,然后操作数据库。JDBC 的接口封装在java.sql和Javax.sql的两个包里,因此,用Java开 发连接数据库的应用程序时必须加载这两个包,同时还需要导入相应 JDBC 的数据库驱动程序。
JDBC 标准主要分为两部分:
- 面向应用程序的 API 接口:负责与 JDBC 驱动程序管理器 API 进行通信,供应用程序开发人员连接数据库,发送 SQL 语句,处理结果。
- 面向驱动程序的 API 接口:供各开发商开发数据库驱动程序(JDBC Driver)使用。
1.5.2.MyBatis
MyBatis 是支持普通 SQL 查询、存储过程和高级映射的优秀持久层框架,,提供的持久层框架包括 SQL Maps 和 DAOs。MyBatis 使用简单的 XML 或注解用于配置和原始映射,将接口和 Java 的 POJOs 映射成数据库中的记录,而不使用 JDBC 代码和参数实现对数据的检索。
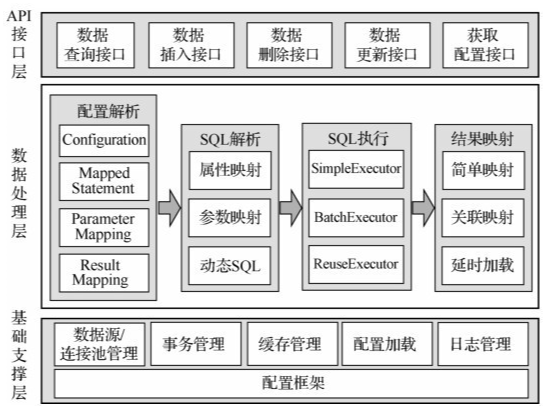
MyBatis 功能框架:
-
API 接口层:提供给外部使用的接口 API,开发人员通过这些本地 API 来操纵数据库。
-
数据处理层:负责配置解析、SQL 解析、SQL 执行和执行结果映射处理等,其主要目的是根据调用的请求完成一次数据库操作。
- 配置解析:对配置文件和 Java 代码注解进行解析,生成 MappedStatement 对象,该对象包括参数映射信息、执行的 SQL 语句、结果映射信息,并存储在内存中。
- SQL 解析:当 API 接口层接收到调用请求时,会接收到传入 SQL 的 ID 和传入对象, MyBatis 根据 SQL 的 ID 找到对应的 MappedStatement 对象,然后根据传入参数对象,对 MappedStatement 进行解析,解析后可以得到最终要执行的 SQL 语句和参数。
- SQL 执行:将解析得到的 SQL 语句和参数在数据库上执行,得到操作结果集。
- 结果映射:根据映射配置信息对操作结果集进行转换,可以转换成 HashMap、JavaBean 或者基本数据类型,并将最终结果返回。
-
基础支撑层:负责提供最基础的功能支撑,包括数据源/连接池管理、事务管理、缓存管理、配置加载和日志管理,将它们抽取出来作为最基础的组件,为上层的数据处理层提供最基础的支撑。
核心组件:
SqlSession:作为 MyBatis 工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增、删、改、查功能。Executor:MyBatis 执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成和查询缓存的维护。StatementHandler:封装了 JDBC Statement 操作,负责对 JDBC Statement 的操作,如设置参数、将 Statement 结果集转换成 List 集合。ParameterHandler:负责对用户传递的参数转换成 JDBC Statement 所需要的参数。ResultSetHandler:负责将 JDBC 返回的 ResultSet 结果集对象转换成List类型的集合。TypeHandler:负责 Java 数据类型和 JDBC 数据类型之间的映射和转换。MappedStatement:维护了一条<select|update|delete|insert>结点的封装。SqlSource:负责根据用户传递的 parameterObject,动态地生成 SQL 语句,将信息封装到 BoundSql 对象中,并返回。BoundSql:表示动态生成的 SQL 语句及相应的参数信息。Configuration:MyBatis 所有的配置信息都维持在 Configuration 对象之中。
访问数据库基本过程:

- 读取配置文件 SqlMapConfig.xml,此文件作为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息。mapper.xml 文件即 SQL 映射文件,文件中配置了操作数据库的 SQL 语句,此文件需要在 SqlMapConfig.xml 中加载;MyBatis 基于 XML 配置文件生成 Configuration 对象,和一个个MappedStatement(包括了参数映射配置、动态SQL语句、结果映射配置),其对应着<select|update|delete|insert>标签项。
- SqlSessionFactoryBuilder 通过 Configuration 生成 sqlSessionFactory 对象。
- 通过 sqlSessionFactory 打开一个数据库会话 sqlSession,操作数据库需要通过 sqlSession 进行。
- MyBatis 底层自定义了 Executor 执行器接口操作数据库,Executor 接口负责动态 SQL 的生成和查询缓存的维护,将 MappedStatement 对象进行解析,SQL 参数转化、动态SQL拼接,生成 JDBC Statement 对象。
MappedStatement 也是 MyBatis 一个底层封装对象,它包装了 MyBatis 配置信息及 SQL 映射信息等。mapper.xml 文件中的一个 SQL 对应一个 MappedStatement 对象,SQL的 id 即为 MappedStatement 的 id。MappedStatement 对 SQL 执行的输入参数进行定义,包括 HashMap、基本类型、POJO,Executor 通过 MappedStatement 在执行 SQL 前将输入的 Java 对象映射至 SQL 中,输入参数映射就是 JDBC 编程中对 preparedStatement 设置参数。MappedStatement 对 SQL 执行的输出结果进行定义,包括 HashMap、基本类型、POJO,Executor 通过 MappedStatement 在执行 SQL 后将输出结果映射至Java 对象中,输出结果映射过程相当于 JDBC 编程中对结果的解析处理过程。
第二部分 MySQL[2]
2.1.MySQL 安装
Linux 的安装包分为 RPM 包、二进制包和源码包:
| RPM | 二进制 | 源码 | |
|---|---|---|---|
| 优点 | 安装简单,适合初学者学习使用。 | 安装简单;可以安装到任何路径下,灵活性好;一台服务器可以安装多个 MySQL。 | 在实际安装的操作系统进行可根据需要定制编译,最灵活;性能最好;一台服务器可以安装多个 MySQL。 |
| 缺点 | 需要单独下载客户端和服务器;安装路径不灵活,默认路径不能修改,一台服务器只能安装一个 MySQL。 | 已经经过编译,性能不如源码编译得好;不能灵活定制编译参数。 | 安装过程较复杂;编译时间长。 |
| 文件布局 |
/usr/bin(客户端程序和脚本) /usr/sbin(mysqld 服务器) /var/lib/mysql(日志文件和数据库) /usr/share/doc/packages(文档) /usr/include/mysql(包含(头)文件) /usr/lib/mysql(库文件) /usr/share/mysql(错误消息和字符集文件) /usr/share/sql-bench(基准程序) |
bin(客户端程序和 mysqld服务器) data(日志文件和数据库) docs(文档和 ChangeLog) include(包含(头)文件)lib(库文件) scripts (mysql_install_db 脚本,用来安装系统数据库) share/mysql(错误消息文件) sql-bench(基准程序) |
bin(客户端程序和脚本) include/mysql(包含(头)文件) info(Info 格式的文档) lib/mysql(库文件) libexec(mysqld 服务器) share/mysql(错误消息文件) sql-bench(基准程序和 crash-me 测试) var(数据库和日志文件) |
2.1.1.源码包安装
groupadd mysql
useradd -g mysql mysql
gunzip < mysql-VERSION.tar.gz | tar -xvf -
cd mysql-VERSION
./configure --prefix=/usr/local/mysql
make
make install
cp support-files/my-medium.cnf /etc/my.cnf
cd /usr/local/mysql
bin/mysql_install_db --user=mysql # 在数据目录下创建系统数据库和系统表,--user 表示这些数据库和表的 owner 是此用户。
# 设置目录权限,将 var 目录 owner 改为 mysql(源码安装,默认数据目录为 var),其他目录和文件为 root。
chown -R root .
chown -R mysql var
chgrp -R mysql .
bin/mysqld_safe --user=mysql & # 启动 MySQL
Linux 平台上 MySQL 参数文件读取顺序:

搜索顺序靠后的文件中的参数将覆盖靠前的参数。
参数修改的三种方式:
-
session 级修改。只对本 session 有效。
SET para_name = para_value; -
全局级修改。对所有新的连接都有效,但是对本 session 无效,数据库重启后失效。
SET GLOBAL para_name = para_value; -
永久修改。将参数在 my.cnf 中增加或者修改,数据库重启后生效。
2.1.2.源码包安装的性能考虑
执行如下命令可以看到所有编译的配置选项:
./configure --help
-
去掉需要的模块
只安装客户端:
./configure --without-server不想要位于 /usr/local/var 目录下面的日志文件和数据库,可以使用类似于下列 configure 命令的一个:
./configure --prefix=/usr/local/mysql./configure --prefix=/usr/local localstatedir=/usr/local/mysql/data第一个命令改变安装前缀以便将所有内容安装到 /usr/local/mysql 下面而非默认的 /usr/local 。第二个命令保留默认安装前缀,但是覆盖了数据库目录默认目录(通常是 /usr/local/var)并且把它改为 /usr/local/mysql/data。编译完 MySQL 后,可以通过选项文件更改这些选项。
修改 socket 的默认位置:
./configure --with-unix-socket-path=/usr/local/mysql/tmp/mysql.sock -
只选择要使用的字符集
MySQL 使用 LATIN1 和 LATIN1_SWEDISH_CI 作为默认的字符集和校对规则。如果想改变安装后的默认字符集和默认排序规则,可以使用如下编译选项:
./configure --with-charset=CHARSET ./configure --with-collation=COLLATION如果不需要安装所有的字符集,那么编译的时候可以选择只安装用户需要的字符集。这样可以节省更多的系统资源,并且使得安装后的 MySQL 速度更快。编译选项如下:
./configure --with-extra-charset=LISTLIST 可以是这些中的一项:以空格为间隔的一系列字符集名、complex(包括不能动态装载的所有字符集)、all(包括所有字符集)。
-
使用静态编译以提高性能:
./configure --with-client-ldflags=-all-static --with-mysqld-ldflags=-all-static选项前后者分别表示以纯静态方式编译客户端、服务端。
2.1.3.升级 MySQL
升级 MySQL 有以下方法:
-
最简单,适合于任何存储引擎,不一定速度最快。
-
在目标服务器上安装新版本的 MySQL。
-
在新版本 MySQL 上创建和老版本同名的数据库。
mysqladmin -h hostname -P port -u user -p passwd CREATE db_name -
将老版本 MySQL 上的数据库通过管道导入到新版本数据库中。
mysqldump --opt db_name | mysql -h hostname -P port -u user -p passwd db_name这里的 --opt 选项表面采用优化(OPTIMIZE)方式导出。如果网络较慢,可以在导出选项中加上 --compress 来减少网络传输。
对于不支持管道的 OS,可以将其旧版本数据导出为文本文件在往新版本导入此文件。如:
mysqldump --opt db_name > filename mysql -u root -p passwd db_name < filename -
将旧版本的 MySQL 中的数据库目录全部 cp 过来覆盖新版本 MySQL 中的数据库。如:
cp -R /home/mysql_old/data/mysql /home/mysql_new/data/mysql -
在新版本服务器的 shell 里升级权限表:
mysql_fix_privilege_tables -
重启新版本 MySQL 服务。
-
-
适合于任何存储引擎,速度较快。
-
参照第一种方法中步骤 1 安装新版本 MySQL。
-
在旧版本 MySQL 中,创建用来保存输出文件的目录并用 mysqldump 备份数据库。
mkdir DUMPDIR mysqldump -tab=DUMPDIR db_name这里使用--tab 选项不会生成 SQL 文本。而是在备份目录下对每个表分别生成了 .sql 和 .txt 文件,其中 .sql 保存了表的创建语句,.txt 保存了用默认分隔符生成的纯数据文本。
-
将 DUMPDIR 目录中的文件转移到目标服务器上相应的目录中并将文件装载到新版本的 MySQL 中。
mysqladmin CREATE db_name # 创建数据库 cat DUMPDIR/*.sql | mysql db_name # 创建数据库表 mysqlimport db_name DUMPDIR/*.txt # 加载数据 -
参照第一种方法中步骤 4、5、6 升级权限表,并重启 MySQL 服务。
-
-
适合于 MyISAM 存储引擎的表,速度最快。
- 参照第一种方法中步骤 1 安装新版本 MySQL。
- 将旧版本 MySQL 中的数据目录下的所有文件(.frm、.MYD 和 .MYI)cp 到新版本 MySQL 下的相应目录下。
- 参照第一种方法中步骤 4、5、6 升级权限表,并重启 MySQL 服务。
上述三种方法区别仅仅在于数据迁移方法的不同。这里需要注意两点:
- 上面的升级方法都是假设升级期间旧版本 MySQL 不再进行数据更新,否则,迁移过去的数据将不能保证和原数据库一致。
- 迁移前后的数据库字符集最好能保持一致,否则可能会出现各种各样的乱码问题。
2.1.4.降级 MySQL
对于 MyISAM 存储引擎,要想实现 MySQL 降级,可以直接将数据文件 cp 到低版本数据库上的数据目录下。如果发生表格式冲突,或者是其他存储引擎的表,则可以先使用 mysqldump 命令导出文本后再将其导入低版本的数库。
2.2.SQL 语句
操作系统的大小写敏感性决定了数据库名和表名的大小写敏感性。(大多数 UNIX 大小写敏感,Windows 大小写不敏感)。在 MySQL 中如何在硬盘上保存、使用表名和数据库名由 lower_case_tables_name 系统变量决定,可以在启动 mysqld 时设置这个系统变量,其设置值意义如下:

2.2.1基本语句
-
DDL:
information_schema:主要存储了系统中的一些数据库对象信息。比如用户表信息、列信息、权限信息、字符集信息、分区信息。cluster:存储了系统的集群信息。mysql:存储了系统的用户权限信息。test:系统自动创建的测试数据库,任何用户都可以使用。
CREATE DATABASE test1; SHOW DATABASES; USE test1; SHOW TABLES;DROP DATABASE test1;CREATE TABLE emp( ename VARCHAR(10), hiredate DATE, sal DECIMAL(10, 2), deptno INT(2) ); DESC emp; SHOW CREATE TABLE emp \G;DROP TABLE emp;ALTER TABLE emp MODIFY ename VARCHAR(20); ALTER TABLE emp ADD COLUMN age INT(3); ALTER TABLE emp DROP COLUMN age; ALTER TABLE emp CHANGE age age1 INT(4);MODIFY、ADD、CHANGE可在后面添加FIRST、AFTER column_name。ALTER TABLE emp ADD birth DATE AFTER ename; ALTER TABLE emp MODIFY age INT(3) FIRST;ALTER TABLE emp RENAME [TO] emp1; -
DML:
INSERT INTO emp(ename, hiredate, sal, deptno) VALUES('zzxl', '2001-01-01', '2000', 1); INSERT INTO emp VALUES('zzxl', '2001-01-01', '2000', 1); INSERT INTO emp(ename, sal) VALUES('dony', '1000'); SELECT * FROM emp; INSERT INTO dept VALUES(5, 'dept5'), (6, 'dept6');UPDATE emp SET sal = 4000 WHERE ename = 'lisa'; UPDATE emp a, dept b SET a.sal = a.sal * b.deptno, b.deptname = a.ename WHERE a.deptno = b.deptno;DELETE FROM emp WHERE ename = 'dony'; DELETE a, b FROM emp a, dept b WHERE a.deptno = b.deptno AND a.deptno = 3;SELECT ename, hiredate, sal, deptno FROM emp; SELECT DISTINCT deptno FROM emp; SELECT * FROM emp WHERE deptno = 1 AND sal < 3000; SELECT * FROM emp ORDER BY sal; SELECT * FROM emp ORDER BY deptno, sal DESC;DESC降序、ASC升序(默认)。SELECT * FROM emp ORDER BY sal LIMIT 3; SELECT * FROM emp ORDER BY sal LIMIT 1, 3;SELECT COUNT(1) FROM emp; SELECT deptno, COUNT(1) FROM emp GROUP BY deptno; SELECT deptno, COUNT(1) FROM emp GROUP BY deptno WITH ROLLUP; SELECT deptno, COUNT(1) FROM emp GROUP BY deptno HAVING COUNT(1) > 1; SELECT SUM(sal), MAX(sal), MIN(sal) FROM emp;WITH ROLLUP和ORDER BY互斥,不能同时使用。LIMIT用在ROLLUP后面。SELECT ename, deptname FROM emp, dept WHERE emp.deptno = dept.deptno; SELECT ename, deptname FROM emp LEFT JOIN dept ON emp.deptno = dept.deptno; SELECT ename, deptname FROM dept RIGHT JOIN emp ON dept.deptno = emp.deptno; SELECT * FROM emp WHERE deptno IN(SELECT deptno FROM dept); SELECT * FROM emp WHERE deptno = (SELECT deptno FROM dept); SELECT * FROM emp WHERE deptno = (SELECT deptno FROM dept limit 1);使用
=的子查询需要子查询结果唯一。SELECT deptno FROM emp UNION ALL SELECT deptno FROM dept; SELECT deptno FROM emp UNION SELECT deptno FROM dept;UNION较于UNION ALL会进行一次DISTINCT。 -
DCL:
GRANT SELECT, INSERT ON sakila.* TO 'z1'@'localhost' IDENTIFIED BY '123'; REVOKE INSERT ON sakila.* FROM 'z1'@'localhost';
帮助的使用:
? CONTENTS; ? DATA TYPES; ? INT; ? SHOW; ? CREATE TABLE;
2.2.2.数据类型
-
数值类型:
![]()
INT默认INT(11),如果添加ZEROFILL会在长度不够时添加0。所以类型有可选项UNSIGNED。整数类型可设置为
AUTO_INCREMENT,一个表最多只能有一个AUTO_INCREMENT,且要设置为NOT NULL并定义为PRIMARY KEY或UNIQUE键。浮点数、定点数都可在后加
(M, D),浮点数以四舍五入保存,默认会按照实际的精度(取决于硬件和OS)来显示;定点数以字符串保存,默认精度为(10, 0)。插入值实际精度大于列定义精度时,浮点数会四舍五入,定点数在默认的 SQLMode 下会警告并四舍五入插入,而 TRADITIONAL(传统模式)下系统报错无法插入。浮点数比较最好使用范围而不是==。CREATE TABLE t1( id1 FLOAT(5, 2) DEFAULT NULL, id2 DOUBLE(5, 2) DEFAULT NULL, id3 DECIMAL(5, 2) DEFAULT NULL ); DESC t1; INSERT INTO t1 VALUES(1.23, 1.23, 1.23); INSERT INTO t1 VALUES(1.234, 1.234, 1.23); INSERT INTO t1 VALUES(1.234, 1.234, 1.234); SELECT * FROM t1; ALTER TABLE t1 MODIFY id1 FLOAT; ALTER TABLE t1 MODIFY id2 DOUBLE; ALTER TABLE t1 MODIFY id3 DECIMAL; DESC t1; SELECT * FROM t1; INSERT INTO t1 VALUES(1.234, 1.234, 1.234); SHOW WARNINGS;对于
BIT类型,使用SELECT不能直接看到结果,使用bin()(二进制)或hex()(十六进制)函数进行读取。对于新增的数据先转换为二进制,过长无法加入。CREATE TABLE t2( id BIT(1) DEFAULT NULL ); INSERT INTO t2 VALUES(1); SELECT BIN(id), HEX(id) FROM t2; INSERT INTO t2 VALUES(2); SHOW WARNINGs; ALTER TABLE t2 MODIFY id BIT(2); INSERT INTO t2 VALUES(2);MySQL 中,常量数字默认会以 8 个字节来表示。
-
日期时间类型
![]()
上图为 MySQL5.0 支持的日期和时间类型,不同版本可能有所差异。
如果需要经常插入或者更新日期为当前系统时间,则通常使用 TIMESTAMP 来表示。TIMESTAMP 值返回后显示为“YYYY-MM-DD HH:MM:SS”格式的字符串,显示宽度固定为 19 个字符。如果想要获得数字值,应在 TIMESTAMP 列添加
+0。MySQL 会给表中的第一个 TIMESTAMP 字段设置默认值为 CURRENT_TIMESTAMP(系统日期),其它的 TIMESTAMP 默认值被设置为 0。MySQL 规定 TIMESTAMP 类型字段只能有一列的默认值为 CURRENT_TIMESTAMP。TIMESTAMP 还有一个重要特点,就是和时区相关。当插入日期时,会先转换为本地时区后存放;而从数据库里面取出时,也同样需要将日期转换为本地时区后显示。SHOW VARIABLES LIKE 'time_zone'; // SYSTEM,系统时间,假设这里是东八区 CREATE TABLE t8( id1 TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, id2 DATETIME DEFAULT NULL ); INSERT INTO t8 VALUES(NOW(), NOW()); SELECT * FROM t8; SET time_zone = '+9:00'; // 设置当前时区为东九区 SELECT * FROM t8; // id1 比 id2 快一小时 SET time_zone = SYSTEM;如果只是表示年份,可以用 YEAR 来表示,它比 DATE 占用更少的空间。YEAR 有 2 位或 4 位格式的年。默认是 4 位格式。在 4 位格式中,允许的值是 1901~2155 和 0000。在 2 位格式中,允许的值是 00 ~ 99,表示从 1970~2069 年。MySQL 以 YYYY 格式显示 YEAR 值。
每种日期时间类型都有一个有效值范围,如果超出这个范围,在默认的 SQLMode 下,系统会进行错误提示,并将以零值来进行存储。
-
字符串类型
![]()
在检索的时候,CHAR 列删除了尾部的空格,而 VARCHAR 则保留这些空格。CHAR 与 VARCHAR 存储区别示例(最后一个只在非严格模式下保存):
![]()
CHAR 与 VARCHAR 在存储引擎中选择建议:
- MyISAM:建议使用固定长度的数据列代替可变长度的数据列。
- MEMORY:没关系,目前都使用固定长度的数据行存储,两者都是作为 CHAR 类型处理。
- InnoDB:建议使用 VARCHAR 类型。对于 InnoDB 数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的 CHAR 列不一定比使用可变长度 VARCHAR 列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于 CHAR 平均占用的空间多于 VARCHAR,因此使用 VARCHAR 来最小化需要处理的数据行的存储总量和磁盘 I/O 是比较好的。
在保存较大文本时,通常会选择使用 TEXT(保存字符数据) 或者 BLOB(能用来保存二进制数据)。删除该数据类型数据会在数据表中留下很大的“空洞”,所以建议定期使用
OPTIMIZE TABLE table_name;命令对这类表进行碎片整理。可以使用合成索引来提高大文本字段(BLOB、TEXT)的查询性能。如果需要对 BLOB 或者 CLOB 字段进行模糊查询,MySQL 提供了前缀索引,也就是只为字段的前 n 列创建索引。考虑性能问题,在不必要的时候避免检索大型的 BLOB 或 TEXT 值,BLOB 或 TEXT 列最好分离到单独的表中。CREATE TABLE t ( id VARCHAR(100), context BLOB, hash_value VARCHAR(40) ); INSERT INTO t VALUES(1, REPEAT('beijing', 2), MD5(context)); CREATE INDEX idx_blob ON t(context(100)); DESC SELECT * FROM t WHERE context LIKE 'beijing%' \G;散列值只能用于精确的查询,对于类似
<、>=等是无意义的。如果散列值生成字符串带有空格,就不要存放在 CHAR、VARCHAR 列中,否则会受到尾部空格删除的影响。上述例子中,模糊查询的条件中,
%不能放在最前面否则前缀索引不会被使用。BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不包含非二进制字符串。当保存 BINARY 值时,在值的最后通过填充“0x00”(零字节)以达到指定的字段定义长度。
CREATE TABLE t9( c BINARY(3) ); INSERT INTO t9 SET c = 'a'; SELECT *, HEX(c), c = 'a', c = 'a\0', c = 'a\0\0' FROM t9;ENUM 值范围需要在创建表时通过枚举方式显式指定。 ENUM 类型是忽略大小写的。对于插入不在 ENUM 指定范围内的值时,会插入枚举的第一个值。
CREATE TABLE t10( gender ENUM('M', 'F') ); INSERT INTO t10 VALUES('M'), ('f'), ('1'), (NULL); SELECT * FROM t10;Set 和 ENUM 类型非常类似,也是一个字符串对象,里面可以包含 0~64 个成员。Set 和 ENUM 除了存储之外,最主要的区别在于 Set 类型一次可以选取多个成员,而 ENUM则只能选一个。
CREATE TABLE t11( col SET('a', 'b', 'c', 'd') ); INSERT INTO t11 VALUES('a'), ('a', 'b'); SELECT * FROM t11;




运算符使用事项:
-
NULL值不能用于=、<>(不等)比较,但可以用<=>(相等)比较。 -
BETWEEN min AND max指大于等于min,小于等于max。 -
NOT NULL的逻辑非(NOT、!)为NULL。 -
REGEXP在匹配时区分大小写。
// TODO::=是个啥?
2.2.3.常用函数
MySQL 数据库中,函数可以用在 SELECT、UPDATE、DELETE 语句及其子句。
-
字符串函数:
![]()
-
数值函数:
![]()
COUNT函数传递一个布尔值时,不要写成COUNT(exp)而是COUNT(exp OR NULL),布尔为false还是会被统计,但为NULL时不会被统计。SUM函数的列参数没有提供值(如行数为 0,或行数不为 0 但所有行该列都为 NULL)的情况下返回 NULL。 -
日期和时间函数:
![]()
应当使用
DATEDIFF而不是对日期做减法,减法在诸如2023-02-01 - 2023-01-31情况下会计算错误。 -
流程函数:
![]()
-
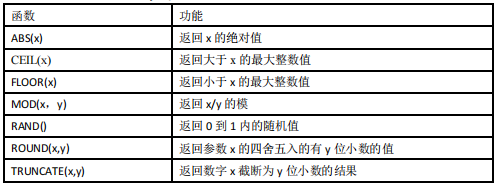
其它常用函数:
![]()
RAND()用于取随机数,ORDER BY RAND()则是进行乱序。如这样使用:SELECT * FROM sales ORDER BY RAND() LIMIT 5;




2.2.4.视图
MySQL 视图的定义有一些限制,例如,在 FROM 关键字后面不能包含子查询。视图的可更新性和视图中查询的定义有关系,以下类型的视图是不可更新的:
- 包含以下关键字的 SQL 语句:聚合函数、
DISTINCT、GROUP BY、HAVING、UNION或者UNION ALL。 - 常量视图。
SELECT中包含子查询。JION。FROM一个不能更新的视图。WHERE子句的子查询引用了FROM子句中的表。
创建视图时,WITH [CASCADE|LOCAL] CHECK OPTION决定了是否允许更新数据使记录不再满足视图的条件。LOCAL是只要满足本视图的条件就可以更新;CASCADE(默认)则是必须满足所有针对该视图的所有视图的条件才可以更新。
CREATE OR REPLACE VIEW payment_view AS
SELECT payment_id, amount
FROM payment
WHERE amount < 10
WITH CHECK OPTION;
CREATE OR REPLACE VIEW payment_view1 AS
SELECT payment_id, amount
FROM payment_view
WHERE amount > 5
WITH LOCAL CHECK OPTION;
CREATE OR REPLACE VIEW payment_view2 AS
SELECT payment_id, amount
FROM payment_view
WHERE amount > 5
WITH CASCADE CHECK OPTION;
UPDATE payment_view1 SET amount = 10 WHERE payment_id = 3;
UPDATE payment_view2 SET amount = 10 WHERE payment_id = 3; // 出错,amount = 10 不满足 payment_view 的条件。
MySQL5.1 开始,使用SHOW TABLES;语句也可查看视图(不存在SHOW VIEWS;语句)。在使用SHOW TABLE STATUS命令时也包含视图信息。SHOW CREATE VIEW view_name \G;查看视图定义。
2.2.5.存储过程
存储过程和函数是事先经过编译并存储在数据库中的一段 SQL 语句的集合。存储过程和函数的区别在于函数必须有返回值,而存储过程没有,存储过程的参数可以使用 IN、OUT、INOUT 类型,而函数的参数只能是 IN 类型的(可不写IN)。创建、修改、调用存储过程、函数的语法 :
CREATE PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
CREATE FUNCTION sp_name ([func_parameter[,...]])
RETURN type
[characteristic ...] routine_body
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
CALL sp_name([proc_parameter[,...]])
MySQL 的存储过程和函数中允许包含 DDL 语句,也允许在存储过程中执行提交或者回滚,但是存储过程和函数中不允许执行LOAD DATA INFILE语句。此外,存储过程和函数中可以调用其他的过程或者函数。
DELIMITER $$
CREATE PROCEDURE film_in_stock(IN p_film_id INT, IN p_store_id INT, OUT p_film_count INT)
READS SQL DATA
BEGIN
SELECT inventory_id
FROM inventory
WHERE film_id = p_film_id
AND store_id = p_store_id
AND inventory_in_stock(inventory_id);
SELECT FOUND_ROWS() INTO p_film_count;
END; $$
DELIMITER ;
CALL film_in_stock(2, 2, @a);
SELECT @a;
存储过程和函数的 CREATE 语法不支持使用
CREATE OR REPLACE对存储过程和函数进行修改,如果需要对已有的存储过程或者函数进行修改,需要执行ALTER语法。
characteristic 简单说明:
-
LANGUAGE SQL:说明下面过程的 BODY 是使用 SQL 语言编写,这条是系统默认的,为今后 MySQL 会支持的除 SQL 外的其他语言支持的存储过程而准备。 -
[NOT] DETERMINISTIC:DETERMINISTIC确定的,即每次输入一样输出也一样的程序,NOT DETERMINISTIC非确定的,默认是非确定的。当前,这个特征值还没有被优化程序使用。 -
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }:这些特征值提供子程序使用数据的内在信息,这些特征值目前只是提供给服务器,并没有根据这些特征值来约束过程实际使用数据的情况。CONTAINS SQL(默认)表示子程序不包含读或写数据的语句。NO SQL表示子程序不包含 SQL 语句。READS SQL DATA表示子程序包含读数据的语句,但不包含写数据的语句。MODIFIES SQL DATA表示子程序包含写数据的语句。 -
SQL SECURITY { DEFINER | INVOKER }:可以用来指定子程序该用创建子程序者的许可来执行,还是使用调用者的许可来执行。默认值是DEFINER。 -
COMMENT 'string':存储过程或者函数的注释信息。
查看存储过程或函数:
SHOW PROCEDURE STATUS LIKE 'film_in_stock' \G;
SHOW CREATE PROCEDURE film_in_stock \G;
SELECT * FROM routines WHERE ROUNT_NAME = 'film_in_stock' \G;
通过DECLARE可以定义一个局部变量,该变量的作用范围只能在 BEGIN…END 块中,可以用在嵌套的块中。变量的定义必须写在复合语句的开头,并且在任何其他语句的前面。可以一次声明多个相同类型的变量。如果需要,可以使用DEFAULT赋默认值。变量可以直接赋值(使用SET),或者通过查询赋值(使用SELECT ... INTO ...,要求查询结果必须只有一行)。
CREATE FUNCTION get_customer_balance(p_customer INT, p_effective_date DATETIME)
RETURN DEVIMAL(5, 2)
DETERMINISTIC
READS SQL DATA
BEGIN
...
DECLARE v_payments DECIMAL(5, 2);
...
SELECT IFNULL(SUM(payment.amount), 0) INTO v_payments
FROM payment
WHERE payment.payment_date <= p_effective_date
AND payment.customer_id = p_customer_id;
...
RETURN v_rentfees + v_overfees - v_payment;
END; $$
条件的定义与处理:
DECLARE condition_name CONDITION FOR {SQLSTATE [VALUE] sqlstate_value | mysql_error_code}
DECLARE {CONTINUE | EXIT | UNDO} HANDLER FOR condition_value[, ...] sp_statement
其中condition_value可以是condition_name | SQLSTATE [VALUE] sqlstate_value | mysql_error_code | SQLWARNING | NOT FOUND | SQLEXCEPTION(SQLWARNING、SQLSTATE分别是 01、02 开头的 SQLSTATE,其它的 SQLSTATE 是SQLEXCEPTION)。UNDO现在还不支持。如:
DELIMITER $$
CREATE PROCEDURE actor_insert()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET @x2 = 1;
SET @x = 1;
INSERT INTO actor(actor_id, first_name, last_name) VALUES(201, 'Test', '201');
SET @x = 2;
INSERT INTO actor(actor_id, first_name, last_name) VALUES(1, 'Test', '1');
SET @x = 3;
END; $$
DELIMITER ;
上面这个例子中,如果有INSERT语句插入后出现了Duplicate entry(SQLSTATE '23000')时,存储过程就会退出,@x的值可能是1、2、3,而有条件处理后,这里定义的是出现该错误后CONTINUE,最后会执行到SET @x = 3,并且设置@x2 = 1。
在存储过程和函数中可以使用光标对结果集进行循环的处理。如:
DELIMITER $$
CREATE PROCEDURE payment_stat()
BEGIN
DECLARE i_staff_id INT;
DECLARE d_amount DECIMAL(5, 2);
DECLARE cur_payment CURSOR FOR
SELECT staff_id, amount FROM payment;
DECLARE EXIT HANDLER FOR NOT FOUND
CLOSE cur_payment;
SET @x1 = 0;
SET @x2 = 0;
OPEN cur_payment;
REPEAT
FETCH cur_payment INTO i_staff_id, d_amount;
IF i_staff_id = 2 THEN
SET @x1 = @x1 + d_amount;
ELSE
SET @x2 = @x2 + d_amount;
END IF;
UNTIL 0
END REPEAT;
CLOSE cur_payment;
END; $$
DELIMITER ;
变量、条件、处理程序、光标都是通过
DECLARE定义的,变量和条件必须在最前面声明,然后才能是光标的声明,最后才可以是处理程序的声明。
流程控制:
-
IF语句:IF search_condition THEN statement_list [ELSEIF search_condition THEN statement_list]... [ELSE statement_list] END IF -
CASE语句:CASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list]... [ELSE statement_list] END CASECASE WHEN when_condition THEN statement_list [WHEN when_condition THEN statement_list]... [ELSE statement_list] END CASE -
LOOP语句:[begin_label:] LOOP statement_list END LOOP [end_label]要退出循环需要由
statement_list中其它的语句(如LEAVE)定义,否则死循环。 -
REPEAT语句:有条件的循环控制语句,当满足条件的时候退出循环。[begin_label:] REPEAT statement_list UNTIL search_condition END REPEAT [end_label]WHILE语句:有条件的循环控制语句,当满足条件的时候执行循环。[begin_label:]WHILE search_condition DO statement_list END WHILE [end_label] -
LEAVE语句:用来从标注的流程构造中退出,通常和 BEGIN ... END 或者循环一起使用。ITERATE语句:必须用在循环中,作用是跳过当前循环的剩下的语句,直接进入下一轮循环。如:
DELIMITER $$ CREATE PROCEDURE actor_insert() BEGIN SET @x = 0; ins: LOOP SET @x = @x + 1; IF @x = 100 THEN LEAVE ins; ELSEIF MOD(@x, 2) = 0 THEN ITERATE ins; END IF; INSERT INTO actor(first_name, last_name) VALUES('Test', '201'); END LOOP ins; END; $$ DELIMITER ;
2.2.6.触发器
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。触发器只能创建在永久表上,不能对临时表创建触发器。对同一个表相同触发时间的相同触发事件,只能定义一个触发器。使用别名OLD和NEW来引用触发器中发生变化的记录内容。现在触发器还只支持行级触发的,不支持语句级触发。
CREATE TRIGGER trigger_name {BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON tab_name FOR EACH ROW
trigger_statement
MySQL 的触发器是按照 BEFORE 触发器、行操作、AFTER 触发器的顺序执行的,其中任何一步操作发生错误都不会继续执行剩下的操作。如果是对事务表进行的操作,那么会整个作为一个事务被回滚,但是如果是对非事务表进行的操作,那么已经更新的记录将无法回滚。
如果对tab_name表有多个触发器,并且对tab_name表执行INSERT INTO ... ON DUPLICATE KEY UPDATE语句时,如果只执行了INSERT那么触发器的执行顺序是BEFORE INSERT、AFTER INSERT;如果执行了UPDATE,那么触发器的执行顺序是BEFORE INSERT、BEFORE UPDATE、AFTER UPDATE。
触发器的使用限制:
-
触发程序不能调用将数据返回客户端的存储程序,也不能使用采用
CALL语句的动态 SQL 语句,但是允许存储程序通过参数将数据返回触发程序。也就是存储过程或者函数通过 OUT 或者 INOUT 类型的参数将数据返回触发器是可以的,但是不能调用直接返回数据的过程。 -
不能在触发器中使用以显式或隐式方式开始或结束事务的语句,如
START TRANSACTION、COMMIT或ROLLBACK。
2.2.7.事务控制和锁定语句
MySQL 支持对 MyISAM 和 MEMORY 存储引擎的表进行表级锁定,对 BDB 存储引擎的表进行页级锁定,对 InnoDB 存储引擎的表进行行级锁定。默认情况下,表锁和行锁都是自动获得的,不需要额外的命令。
LOCK TABLES可以锁定用于当前线程的表。UNLOCK TABLES可以释放当前线程获得的任何锁定。当前线程执行另一个 LOCK TABLES 时,或当与服务器的连接被关闭时,所有由当前线程锁定的表被隐含地解锁。
LOCK TABLES tab_name [AS alias] {READ [LOCAL] | [LOW_PRIORITY] WRITE}
[tab_name [AS alias] {READ [LOCAL] | [LOW_PRIORITY] WRITE}]...
UNLOCK TABLES
MySQL 通过SET AUTOCOMMIT、START TRANSACTION、COMMIT和ROLLBACK等语句支持本地事务。定义相同名字的 SAVEPOINT,则后面定义的 SAVEPOINT 会覆盖之前的定义。对于不再需要使用的 SAVEPOINT,可以通过RELEASE SAVEPOINT命令删除 SAVEPOINT。
START TRANSACTION | BEGIN [WORK]
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
SET AUTOCOMMIT = {0 | 1}
默认情况下,MySQL 是自动提交的。设置CHAIN会立即启动一个新事物,并且和刚才的事务具有相同的隔离级别,RELEASE则会断开和客户端的连接。
锁表期间,用START TRANSACTION等命令开启一个新的事务,会造成一个隐含的UNLOCK TABLES;被执行(遵循两阶段锁定协议)。
对LOCK方式加表锁的表,无法通过ROLLBACK回滚。DDL 语句不能回滚,部分 DDL 语句会被隐式提交。在同一个事务中,最好不使用不同存储引擎的表,否则 ROLLBACK 时需要对非事务类型的表进行特别的处理,因为COMMIT、ROLLBACK只能对事务类型的表进行提交和回滚。
2.3.存储引擎
MySQL 5.0 支持的存储引擎包括 MyISAM(默认)、InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED 等,其中 InnoDB 和 BDB 提供事务安全表,其他存储引擎都是非事务安全表。

使用以下命令查看当前数据库支持的存储引擎:
SHOW ENGINES \G;
SHOW VARIABLES LIKE 'have%';
默认存储引擎可通过以下命令查看:
SHOW VARIABLES LIKE '%storage_engine%';
创建新表时可指定使用的存储引擎:
CREATE TABLE ai(
...
) ENGINE = ...;
修改已存在表的存储引擎:
ALTER TABLE ai ENGINE = InnoDB;
2.3.1.MyISAM
访问的速度快,对事务完整性没有要求或者以 SELECT、INSERT 为主的应用基本上都可以使用这个引擎来创建表。
每个 MyISAM 在磁盘上存储成 3 个文件,分别是table_name.frm(存储表定义)、table_name.MYD(存储数据)、table_name.MYI(存储索引)。数据文件和索引文件可以放置在不同的目录,在创建表的时候通过DATA DIRECTORY和INDEX DIRECTORY语句指定(使用绝对路径且有访问权限)。
MyISAM 类型的表可能会损坏,可以用CHECK TABLE语句检查表健康,用REPAIR TABLE语句修复损坏的 MyISAM 表。
MyISAM 表支持 3 种不同的存储格式:
- 静态表(默认):字段都是非变长字段,每条记录都是固定长度。优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。静态表的数据在存储的时候会按照列的宽度定义在尾部补足空格,但是在访问的时候并不会得到这些空格,这些空格在返回给应用之前已经去掉(包括保存的内容尾部本来就带的空格)。
- 动态表:包含变长字段。优点是占用空间相对较少;缺点是频繁地更新删除记录会产生碎片(需要定期执行
OPTIMIZE TABLE语句或myisamchk -r命令来改善性能),出现故障的时候恢复相对比较困难。 - 压缩表:由 myisampack 工具创建,每个记录是被单独压缩的,占据磁盘空间小,访问开支小。
2.3.2.InnoDB
提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比 MyISAM 的存储引擎,InnoDB 写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
InnoDB 存储表和索引有两种方式:
- 使用共享空间存储:表结构存储在
.frm文件中,数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path 定义的表空间中,可以是多个文件。 - 使用多表空间存储:表结构存储在
.frm文件中,每个表(分区表则是每个分区)的数据和索引单独保存在.ibd中。
修改存储方法需要修改参数innodb_file_per_table并重启,但这只对新表生效。多表空间的数据文件没有大小限制。使用多表空间的表可以方便地进行单表备份和恢复操作,但是直接复制.ibd文件是不行的,因为没有共享表空间的数据字典信息,直接复制的.ibd文件和.frm文件恢复时是不能被正确识别的,但可以通过以下命令将备份恢复到数据库中:
ALTER TABLE table_name DISCARD TABLESPACE;
ALTER TABLE table_name IMPORT TABLESPACE;
但是这样的单表备份,只能恢复到表原来在的数据库中,而不能恢复到其他的数据库中。如果要将单表恢复到目标数据库,则需要通过 mysqldump 和mysqlimport 来实现。
即便在多表空间的存储方式下,共享表空间仍然是必须的,InnoDB 把内部数据词典和未作日志放在这个文件中。
InnoDB 表的自动增长列可以手工插入,但是插入的值如果是空或者 0,实际插入的将是自动增长后的值。通过ALTER TABLE table_name AUTO_INCREMENT = n;强制设置自动增长列初始值(默认为 1),该初始值被保存在内存中,数据库重启后需要重新设置。使用LAST_INSERT_ID()可查询当前线程最后插入记录使用的值,如果一次插入多条,则返回第一条使用的自动增长值(// TODO:LAST_INSERT_ID 函数使用问题)。InnoDB 表的自动增长列必须是索引,对于组合索引还必须是组合索引的第一个。
对于 MyISAM 表,自动增长列可以是组合索引的非第一个,这样插入记录后,自动增长列是按照组合索引的前面几列进行排序后递增的。
MySQL 支持外键的存储引擎只有 InnoDB,在创建外键的时候,要求父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引(对于其他类型存储引擎的表,当使用REFERENCES tbl_name(col_name)子句定义列时可以使用外部关键字,但是没有实际的效果,只作为备忘录或注释来提醒用户目前正定义的列指向另一个表中的一个列)。RESTRICT和NO ACTION限制子表在有关联记录情况下父表不能更新;CASCADE表示父表在更新或者删除时,更新或者删除子表对应记录;SET NULL表示父表在更新或者删除的时候,子表的对应字段被设置为NULL。当某个表被其他表创建了外键参照,该表的对应索引、主键禁止被删除。SET FOREIGN_KEY_CHECKS = 0;用于在导入多个表数据或执行LOAD DATA、ALTER TABLE时关闭外键检查(执行完后记得使用SET FOREIGN_KEY_CHECKS = 1;重新开启)。外键信息可通过SHOW CREATE TABLE或者SHOW TABLE STATUS命令查看。
CREATE TABLE country (
country_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
country VARCHAR(50) NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (country_id)
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
CREATE TABLE city (
city_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
city VARCHAR(50) NOT NULL,
country_id SMALLINT UNSIGNED NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (city_id),
KEY idx_fk_country_id (country_id),
CONSTRAINT fk_city_country FOREIGN KEY (country_id)
REFERENCES country (country_id)
ON DELETE RESTRICT
ON UPDATE CASCADE
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
2.3.2.MEMORY
主要用在那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果。
MEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表只实际对应一个磁盘文件,格式是.frm。MEMORY 类型的表访问非常得快,因为它的数据是放在内存中的,但是一旦服务关闭,表中的数据就会丢失掉。
CREATE TABLE tab_memory ENGINE = MEMORY
SELECT city_id, city, country_id
FROM city
GROUP BY city_id;
在启动 MySQL 服务的时候使用
--init-file选项,把INSERT INTO ... SELECT或LOAD DATA INFILE这样的语句放入这个文件中,就可以在服务启动时从持久稳固的数据源装载表。
MEMORY 表默认使用 HASH 索引。MEMORY 表创建索引时可指定使用 HASH 索引或是 BTREE 索引:
CREATE INDEX mem_hash USING HASH on tab_memory(city_id);
SHOW INDEX FROM tab_memory \G;
服务器需要足够内存来维持所有在同一时间使用的 MEMORY 表,当不再需要 MEMORY 表的内容之时,要释放被 MEMORY 表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除这个表。
每个 MEMORY 表中可以放置的数据量的大小,受到max_heap_table_size系统变量(初始值 16MB)的约束。在定义 MEMORY 表的时候,可以通过 MAX_ROWS子句指定表的最大行数。
2.3.4.MERGE
MERGE 存储引擎是一组 MyISAM 表的组合,这些 MyISAM 表必须结构完全相同,MERGE 表本身并没有数据,对 MERGE 类型的表可以进行查询、更新、删除的操作,这些操作实际上是对内部的实际的 MyISAM 表进行的。对于 MERGE 类型表的插入操作,是通过INSERT_METHOD子句定义插入的表,可以有 3 个不同的值,使用FIRST或LAST值使得插入操作被相应地作用在第一或最后一个表上,不定义这个子句或者定义为NO,表示不能对这个 MERGE 表执行插入操作。对 MERGE 表进行DROP操作,这个操作只是删除 MERGE 的定义,对内部的表没有任何的影响。
MERGE 表在磁盘上保留两个文件:.frm文件存储表定义,.MRG文件包含组合表的信息( MERGE 表由哪些表组成、插入新的数据时的依据)。可以通过修改.MRG文件来修改 MERGE 表,但是修改后要通过FLUSH TABLES刷新。
CREATE TABLE payment_all (
country_id SMALLINT,
payment_date DATETIME,
amount DECIMAL(15, 2),
INDEX(country_id)
) ENGINE = MERGE
UNION = (payment_2006, payment_2007)
INSERT_METHOD = LAST;
2.3.5.存储引擎选择
- MyISAM:以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常适合的。MyISAM 是在 Web、数据仓储和其他应用环境下最常使用的存储引擎之一。
- InnoDB:用于事务处理应用程序,支持外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询以外,还包括很多的更新、删除操作,那么 InnoDB 存储引擎应该是比较合适的选择。
- MEMORY:用于更新不太频繁的小表,用以快速得到访问结果。MEMORY 表将所有数据保存在 RAM 中,在需要快速定位记录和其他类似数据的环境下,可提供极快的访问。MEMORY 的缺陷是对表的大小有限制,太大的表无法 CACHE 在内存中,其次是要确保表的数据可以恢复,数据库异常终止后表中的数据是可以恢复的。
- MERGE:用于将一系列等同的 MyISAM 表以逻辑方式组合在一起,并作为一个对象引用它们。MERGE 表的优点在于可以突破对单个 MyISAM 表大小的限制,并且通过将不同的表分布在多个磁盘上,可以有效地改善MERGE表的访问效率。
2.4.字符集
UTF-8 是 MySQL5.0 支持的唯一 Unicode 字符集。
MySQL 服务器可以支持多种字符集,在同一台服务器、同一个数据库、甚至同一个表的不同字段都可以指定使用不同的字符集。SHOW CHARACTER SET;查看所有可用的字符集。information_schema.character_sets 表存储所有字符集及默认的校对规则。使用SHOW COOLATION LIKE '***';或查看 information_schema.COLLATION 查看相关字符集的校对规则。
MySQL 的字符集和校对规则有 4 个级别的默认设置:服务器级、数据库级、表级和字段级。
- 服务器级字符集和校对规则可
my.cnf中设置default-character-set=gdk、启动选项中设置mysqld --default-character-set=gbk、编译时指定./configure --with-charset=gbk。默认latin1。 - 数据库级字符集和校对规则可以在创建数据库时指定、或创建后使用
ALTER DATABASE CHARACTER SET ***;命令。显示当前数据库字符集及校对规则使用SHOW VARIABLES LIKE 'character_set_database';和SHOW VARIABLES LIKE 'collation_database';。 - 表级字符集和校对规则可以在创建数据库时指定、或创建后使用
ALTER TABLE CHARACTER SET ***;命令。 - 字段级字符集和校对规则可在创建表时指定,或创建表后修改。
以上修改字符集只对新数据有效。要修改源数据到新字符集需要以下步骤(假设源字符集为 latin1,新字符集为 gbk):
导出表结构:
mysqldump -uroot -p --default-character-set=gbk -d databasename > createtab.sql
--default-character-set设置以什么字符集连接;-d表示只导出表结构不导出数据。手工修改
createtab.sql表结构定义的字符集为新的字符集。导出所有记录:
mysqldump -uroot -p --quick --no-create-info --extended-insert --default-character-set=latin1 databasename > data.sql
--quick用于转储大的表,强制 mysqldump 从服务器一次一行地检索表中的行而不是检索所有行,并在输出前将它缓存到内存中;--extended-insert使用包括几个 VALUES 列表的多行 INSERT 语法,这样使转储文件更小,重载文件时可以加速插入;--no-create-info不写重新创建每个转储表的 CREATE TABLE 语句;--default-character-set按照原有的字符集导出所有数据,这样导出的文件中,所有中文都是可见的,不会保存成乱码。打开 data.sql,将
SET NAMES latin1修改为SET NAMES gdk。使用新字符集创建新数据库:
CREATE DATABASE database_name DEFAULT CHARSET gbk;创建表,执行 createtab.sql:
mysql -uroot -p databasename < createtab.sql;导入数据,执行 data.sql:
mysql -uroot -p databasename < data.sql;注意选择新字符集最好是源字符集的超集,否则可能会乱码。
上面 4 种设置方式,确定的是数据保存的字符集和校对规则,对于实际的应用访问来说,还存在客户端和服务器之间交互的字符集和校对规则的设置。对于客户端和服务器的交互操作,MySQL 提供了 3 个不同的参数:character_set_client、character_set_connection 和 character_set_results,分别代表客户端、连接和返回结果的字符集,通常情况下,这 3 个字符集应该是相同的,通过SET NAMES ***;命令(每次连接数据库时)或my.cnf中default-character-set=gdk设置。
2.5.索引
MyISAM 和 InnoDB 存储引擎的表只支持 BTREE 索引。
前缀索引的长度跟存储引擎相关,MyISAM 可以达到 1000 字节,InnoDB 最长是 767 字节(注意这是字节,CREATE TABLE语句中前缀长度解释为字符)。
MySQL5.0 仅 MyISAM 存储引擎支持 FULLTEXT 索引并且只限于 CHAR、VARCHAR 和 TEXT 列。全文索引总是对整个列进行的。
仅 MyISAM 存储引擎空间类型索引,且索引的字段必须是非空的。
HASH 索引的一些重要特征:
- 只用于使用
=或<=>操作符的等式比较。 - 优化器不能使用 HASH 索引来加速 ORDER BY 操作。
- MySQL 不能确定在两个值之间大约有多少行。如果将一个 MyISAM 表改为 HASH 索引的 MEMORY 表,会影响一些查询的执行效率。
- 只能使用整个关键字来搜索一行。
HASH 索引实际上是全表扫描的。
2.5.1.索引使用情况
查询要使用索引最主要的条件是查询条件中需要使用索引关键字。
查看索引使用情况可以使用SHOW STATUS LIKE 'Handler_read%'语句,其中:
- Handler_read_key:代表了一个行被索引值读的次数。很低的值表明增加索引得到的性能改善不高,因为索引并不经常使用。
- Handler_read_rnd_next:指在数据文件中读下一行的请求次数。较高的值表示查询运行低效,应该建立索引补救,这通常说明表索引不正确或写入的查询没有利用索引。
MySQL 中,下列几种情况有可能使用索引:
- 对于创建的多列索引,只要查询的条件中用到了最左边的列,索引一般就会被使用。
- 对于使用 LIKE 的查询,后面如果是常量并且只有
%不在第一个字符,索引才可能被使用。LIKE 后面是一个列的名字,索引不会被使用。 - 如果对大的文本进行搜索,使用全文索引而不使用
LIKE '%...%'。 - 如果列名是索引,使用
column IS NULL将使用索引。
存在但不使用索引:
- 如果 MySQL 估计使用索引比全表扫描慢,则不使用索引。
- 如果使用 MEMORY/HEAP 表并且 WHERE 条件中不使用
=进行索引列,那么不会用到索引。HEAP 表只有在=条件下才会使用索引。 - 用
OR分割开的条件,如果OR前的条件中的列有索引,而后面的列中没有索引。 - 如果是复合索引的某一列但不是第一列,不会使用该索引。
- 如果 LIKE 是以
%开头的。 - 如果列类型是字符串,那么一定记得在 WHERE 条件中把字符常量值用引号引起来,否则即使这个列上有索引,MySQL 也不会用到。因为 MySQL 默认把输入的常量值进行转换后才进行检索。
2.5.2.设计索引的原则
- 最适合索引的列是出现在 WHERE 子句中的列,或连接子句中指定的列,而不是出现在 SELECT 关键字后的选择列表中的列。
- 索引列的基数越大,索引的效果越好。如对一个只有男、女性别的枚举类型列创建索引用处不大。
- 使用短索引。如果对字符串列进行索引,应该指定一个前缀长度,只要有可能就应该这样做。
- 利用最左前缀。在创建一个 n 列的索引时,实际是创建了 MySQL 可利用的 n 个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为最左前缀。
- 不要过度索引。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能。
- 对于 InnoDB 存储引擎的表,记录默认会按照一定的顺序保存,如果有明确定义的主键,则按照主键顺序保存。如果没有主键,但是有唯一索引,那么就是按照唯一索引的顺序保存。如果既没有主键又没有唯一索引,那么表中会自动生成一个内部列,按照这个列的顺序保存。按照主键或者内部列进行的访问是最快的,所以 InnoDB 表尽量自己指定主键,当表中同时有几个列都是唯一的,都可以作为主键的时候,要选择最常作为访问条件的列作为主键,提高查询的效率。另外,还需要注意,InnoDB 表的普通索引都会保存主键的键值,所以主键要尽可能选择较短的数据类型,可以有效地减少索引的磁盘占用,提高索引的缓存效果。
2.6.SQL Mode
SELECT @@sql_mode;查看当前 SQL Mode(默认REAL_AS_FLOAT, PIPES_AS_CONCAT, ANSI_QUOTES, GNORE_SPACE, ANSI)。SELECT [SESSION | GLOBAL] sql_mode = 'modes'修改 SQL Mode(SESSION只在本次连接中生效,GLOBAL本次连接不生效,下次连接开始生效),还可以在 MySQL 启动时使用--sql-mode="modes"设置。
常用 SQL Mode:
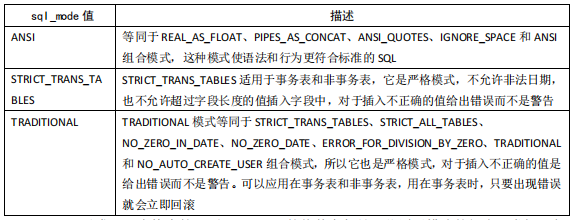
NO_BACKSLASH_ESCAPES 模式会使反斜线成为普通字符。PIPES_AS_CONCAT 模式会将||视为字符串连接符。NO_TABLE_OPTIONS 模式会去掉创建表时的 ENGINE(用于数据迁移)。
2.7.MySQL 优化
2.7.1.SQL 优化
优化 SQL 语句的一般步骤:
-
了解 SQL 执行频率:
mysqladmin extended-status或
SHOW [SESSION|GLOBAL] STATUS; SHOW [SESSION|GLOBAL] STATUS LIKE 'Com_%';默认 session。Innodb 那几个只是针对 InnoDB 存储引擎的。除此之外,一下的几个参数解释:
- Connections:试图连接 MySQL 服务器的次数。
- Uptime:服务器工作时间。
- Slow_queries:慢查询次数。
-
定位执行效率较低的 SQL 语句
可以通过慢查询日志,用
--log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句日志文件。慢查询日志在查询结束以后才记录,对于在应用反应执行效率出现问题的时候,可以使用SHOW PROCESSLIST;可查看当前 MySQL 在进行的线程,实时地查看 SQL 执行情况,同时对一些锁表操作进行优化。 -
通过 EXPLAIN 分析低效 SQL 的执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以使用 EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息。如:
EXPLAIN SELECT SUM(moneys) FROM sales a, company b WHERE a.company_id = b.id AND a.year = 2006 \G;其中各列的简单解释:
-
id:SQL执行的顺序的标识,SQL 从大到小的执行。
-
select_type:表示 SELECT 的类型。常见取值有:
- SIMPLE:简单表,即不使用表连接或者子查询。
- PRIMARY:主查询,即外层的查询。
- UNION:UNION 中的第二个或者后面的查询语句。
- SUBQUERY:子查询中的第一个 SELECT。
-
table:输出结果集的表。
-
type:表示表的连接类型。性能由好到差的连接类型为:
- system:表中仅有一行,即常量表。
- const:单表中最多有一个匹配行,例如 PRIMARY KEY 或者 UNIQUE KEY。
- eq_ref:对于前面的每一行,在此表中只查询一条记录。简单来说,就是多表连接中使用 PRIMARY KEY 或者 UNIQUE KEY。
- ref:与 eq_ref 类似,区别在于不是使用 PRIMARY KEY 或者 UNIQUE KEY,而是使用普通的索引。
- ref_or_null:与 ref 类似,区别在于条件中包含对 NULL 的查询。
- index_merge:索引合并优化。
- unique_subquery:IN 的后面是一个查询主键字段的子查询。
- index_subquery:与 unique_subquery 类似, 区别在于 IN 的后面是查询非唯一索引字段的子查询。
- range:单表中的范围查询。
- index:对于前面的每一行,都通过查询索引来得到数据。
- all:对于前面的每一行,都通过全表扫描来得到数据。
-
possible_keys:表示查询时,可能使用的索引。
-
key:表示实际使用的索引。
-
key_len:索引字段的长度。
-
rows:扫描行的数量。
-
Extra:执行情况的说明和描述。
-
-
确定问题并采取相应的优化措施
如创建索引:
CREATE INDEX ind_sales_year ON sales2(year);
实用的优化方法:
-
分析表:
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[, tbl_name...]分析和存储表的关键字分布。分析的结果将可以使得系统得到准确的统计信息,是的 SQL 能够生成正确的执行计划。如果用户感觉实际执行计划并不是预期的执行计划,执行一次分析表可能会解决问题。在分析期间,使用一个读取锁定对表进行锁定。这对于 MyISAM、BDB 和 InnoDB 表有作用。对于 MyISAM 表,本语句与使用
muisamchk -a相当。 -
检查表:
CHECK TABLE tbl_name[, tbl_name...] [option...] option = {QUICK | FAST | EXTENDED | CHANGED}检查一个或多个表是否有错误,对 MyISAM 和 InnoDB 表有效。也可检查视图,如视图被引用的表是否还存在。
-
优化表:
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[, tbl_name...]如果已经删除了表的一大部分,或者如果已经对含有可变长度行的表(含有 VARCHAR、 BLOB 或 TEXT 列的表)进行了很多更改,则应使用
OPTIMIZE TABLE命令来进行表优化。这个命令可以将表中的空间碎片进行合并,并且可以消除由于删除或者更新造成的空间浪费,但OPTIMIZE TABLE命令只对 MyISAM、BDB 和 InnoDB 表起作用。
ANALYZE、CHECK、OPTIMIZE 执行期间将对表进行锁定,因此一定注意要在数据库不繁忙的时候执行相关操作。
常用 SQL 的优化:
-
大批量插入数据:
向非空的 MyISAM 表导入大量数据,可通过使用
DISABLE KEYS和ENABLE KEYS语句来打开或者关闭 MyISAM 表非唯一索引的更新从而加快导入速率。而对于导入到空的 MyISAM 表,由于默认就是先导入数据才创建索引,所以不用设置。如:ALTER TABLE tbl_name DISABLE KEYS; LOAD DATA INFILE '/home/meyok/film_test.txt' INTO TABLE film_test; ALTER TABLE tbl_name ENABLE KEYS对于 InnoDB 表这种方法不能提高导入数据的效率,但可以有以下方法:
- 因为 InnoDB 类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效地提高导入数据的效率。
- 在导入数据前执行
SET UNIQUE_CHECKS = 0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS = 1,恢复唯一性校验,可以提高导入的效率。 - 如果应用使用自动提交的方式,建议在导入前执行
SET AUTOCOMMIT = 0,关闭自动提交,导入结束后再执行SET AUTOCOMMIT = 1,打开自动提交,也可以提高导入的效率。
-
优化 INSERT 语句:
- 如果同时从同一客户插入很多行,尽量使用多个值表的 INSERT 语句,这种方式将大大 缩减客户端与数据库之间的连接、关闭等消耗,使得效率比分开执行的单个 INSERT 语 句快(在一些情况中几倍)。
- 如果从不同客户插入很多行,能通过使用 INSERT DELAYED 语句得到更高的速度。 DELAYED 的含义是让 INSERT 语句马上执行,其实数据都被放在内存的队列中,并没有 真正写入磁盘,这比每条语句分别插入要快的多;LOW_PRIORITY 刚好相反,在所有其 他用户对表的读写完后才进行插入。
- 将索引文件和数据文件分在不同的磁盘上存放(利用建表中的选项)。
- 如果进行批量插入,可以增加 bulk_insert_buffer_size 变量值的方法来提高速度,但是, 这只能对 MyISAM 表使用。
- 当从一个文本文件装载一个表时,使用 LOAD DATA INFILE。这通常比使用很多 INSERT 语 句快 20 倍。
-
优化 GROUP BY 语句:
默认情况下,MySQL 对所有 GROUP BY 的字段进行排序。这与在查询中指定 ORDER BY 类似。因此,如果显式包括一个包含相同的列的 ORDER BY 子句,则对 MySQL 的实际执行性能没有什么影响。 如果查询包括 GROUP BY 但用户想要避免排序结果的消耗,则可以指定
ORDER BY NULL禁止排序. -
优化 ORDER BY 语句:
在 WHERE 条件和 ORDER BY 使用相同的索引,并且 ORDER BY 的顺序和索引顺序相同,并且 ORDER BY 的字段都是升序或者都是降序情况下,MySQL 可以使用一个索引来满足 ORDER BY 子句,而不需要额外的排序。
-
优化嵌套查询:
有些情况下,子查询可以被更有效率的连接替代。如:
EXPLAIN SELECT * FROM sales WHERE company_id NOT IN(SELECT id FROM company) \G; EXPLAIN SELECT * FROM sales LEFT JOIN company ON sale.company_id = company.id WHERE sale.company_id IS NULL \G;连接之所以更有效率一些,是因为 MySQL 不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
-
优化 OR 条件:
对于含有 OR 的查询子句,如果要利用索引,则 OR 之间的每个条件列都必须用到索引。如果没有索引,则应该考虑增加索引。MySQL 在处理含有 OR 字句的查询时,实际是对 OR 的各个字段分别查询后的结果进行了 UNION。
-
使用 SQL HINT:
-
在查询语句中表名的后面,添加
USE INDEX来提供希望 MySQL 去参考的索引列表,就可以让 MySQL 不再考虑其他可用的索引。如:EXPLAIN SELECT * FROM sale USE INDEX(ind_sale_id) WHERE id = 3 \G; -
如果用户只是单纯地想让 MySQL 忽略一个或者多个索引,则可以使用 IGNORE INDEX 作为 HINT。如:
EXPLAIN SELECT * FROM sale IGNORE INDEX(ind_sale_id) WHERE id = 3 \G; -
为强制 MySQL 使用一个特定的索引,可在查询中使用 FORCE INDEX 作为 HINT。如:'
EXPLAIN SELECT * FROM sale FORCE INDEX(ind_sale_id) WHERE id > 0 \G;
-
2.7.2.数据库对象优化
-
优化表的数据类型:
使用函数
PROCEDURE ANALYSE()对当前应用的表进行分析,该函数可以对数据表中列的数据类型提出优化建议,用户可以根据应用的实际情况酌情考虑是否实施优化。如:SELECT * FROM tbl_name PROCEDURE ANALYSE(); SELECT * FROM tbl_name PROCEDURE ANALYSE(16, 256);以上第二个语句告诉
PROCEDURE ANALYSE()不要为那些包含的值多于 16 个或者 256 字节的 ENUM 类型提出建议。 如果没有这样的限制,输出信息可能很长,ENUM 定义通常很难阅读。 -
拆分表提高表的访问效率:
如果针对 MyISAM 表进行,那么有两种拆分方法:
-
垂直拆分:把主码和一些列放到一个表,然后把主码和另外的列放到另一个表中。 如果一个表中某些列常用,而另外一些列不常用,则可以采用垂直拆分,另外垂直拆分可以使得数据行变小,一个数据页就能存放更多的数据,在查询时就会减少 I/O 次数。其缺点是需要管理冗余列,查询所有数据需要联合操作。
-
水平拆分,即根据一列或多列数据的值把数据行放到两个独立的表中。 水平拆分通常在以下几种情况下使用:
- 表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
- 表中的数据本来就有独立性,例如,表中分别记录各个地区的数据或不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
- 需要把数据存放到多个介质上。
水平拆分会给应用增加复杂度,它通常在查询时需要多个表名,查询所有数据需要 UNION 操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加 2 至 3 倍数据量,查询时也就增加读一个索引层的磁盘次数,所以水平拆分要考虑数据量的增长速度,根据实际情况决定是否需要对表进行水平拆分。
-
-
逆规范化:
反规范的好处是降低连接操作的需求、降低外码和索引的数目,还可能减少表的数目,相应带来的问题是可能出现数据的完整性问题。
常用的反规范技术:
- 增加冗余列:指在多个表中具有相同的列,它常用来在查询时避免连接操作。
- 增加派生列:指增加的列来自其他表中的数据,由其他表中的数据经过计算生成。增加的派生列其作用是在查询时减少连接操作,避免使用集函数
- 重新组表:指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能。
- 分割表。
-
使用中间表提高统计查询速度:
中间表在统计查询中经常会用到,其优点如下:
- 中间表复制源表部分数据,并且与源表相“隔离”,在中间表上做统计查询不会对在线应用产生负面影响。
- 中间表上可以灵活的添加索引或增加临时用的新字段,从而达到提高统计查询效率和辅助统计查询作用。
2.7.3.MySQL Server 优化
MySQL 服务启动后,我们可以用SHOW VARIABLES和SHOW STATUS命令查看 MySQL 的服务器静态参数值和动态运行状态信息。前者是在数据库启动后不会动态更改的值,比如缓冲区大小、字符集、数据文件名称等;后者是数据库运行期间的动态变化的信息,比如锁等待、当前连接数等。也可在 OS 下直接查看数据库参数或数据库状态信息(如mysqladmin -uroot variables)。MySQL 服务器的参数很多,如果需要了解某个参数的详细定义,可以使用mysqld --verbose --help | grep '...'。
其中,影响 MySQL 性能的重要参数如下,其中 key_buffer_size 和 table_cache 仅仅适用于 MyISAM,其他以 innodb_ 开始的仅仅适用于 InnoDB:
-
key_buffer_size:用来设置索引块缓存的大小,它被所有线程共享。
MySQL5.1 以前只允许使用一个系统默认的 key_buffer,MySQL5.1 以后提供了多个 key_buffer,可以将指定的表索引缓存入指定的 key_buffer,这样可以更小地降低线程之间的竞争。如:
SET GLOBAL hot_cache2.key_buffer_size = 128*1024; # 创建一个索引缓存,GLOBAL 表示对于新连接此参数将生效,hot_cache2 是新 key_buffer 名称 SET hot_cache2.key_buffer_size = 200*1024; # 更改参数值 CACHE INDEX sales, sales2 IN hot_cache2; # 把相关表的索引放到指定的索引缓存 LOAD INDEX INTO CACHE sales; # 将索引放到默认的索引缓存中 SET GLOBAL hot_cache2.key_buffer_size = 0; # 删除索引缓存 SET GLOBAL key_buffer_size = 0; # ERROR,不能删除默认 key_bufferCACHE INDEX命令在一个表和 key_buffer 之间建立一种联系,但每次服务器重启时 key_buffer 中的数据将清空。如果想要每次服务器重启时相应表的索引能自动放到 key_buffer 中,可以在配置文件中设置 init-file 选项来指定包含CACHE INDEX语句的文件路径,然后在对应的文件中写入CACHE INDEX语句。如:/etc/my.cnf:init_file = /path/to/data-directory/mysqld_init.sql/path/to/data-directory/mysqld_init.sql:CACHE INDEX a.t1, a.t2, b.t3 IN hot_cache; CACHE INDEX a.t4, b.t5, b.t6 IN cold_cache; -
table_size:表示数据库用户打开表的缓存数量。
每个连接进来,都会至少打开一个表缓存。 因此 table_cache 与 max_connections 有关。例如,对于 200 个并行运行的连接,应该让表的缓存至少 $ 200 \times N $,这里 $ N $ 是可以执行的查询的一个联接中表的最大数量。此外,还需要为临时表和文件保留一些额外的文件描述符。
可以通过检查 mysqld 的状态变量 open_tables 和 opened_tables 确定这个参数是否过小,这两个参数的区别是前者表示当前打开的表缓存数,如果执行
FLUSH TABLES操作,则此系统会关闭一些当前没有使用的表缓存而使得此状态值减小;后者表示曾经打开的表缓存数,会一直进行累加,如果执行FLUSH TABLES操作,值不会减少。状态值 open_tables 对于设置 table_cache 值有着更有价值的参考。 -
innodb_buffer_pool_size:定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区大小。
在一个专用的数据库服务器上,可以设置这个参数达机器物理内存大小的 80%。尽管如此,还是建议用户不要把它设置得太大,因为对物理内存的竞争可能在操作系统上导致内存调度。
-
innodb_additional_mem_pool_size:InnoDB 存储引擎用来存储数据库结构和其他内部数据结构的内存池的大小, 其默认值是 1MB。
应用程序里的表越多,则需要在这里分配越多的内存。如果 InnoDB 用光了这个池内的内存,则 InnoDB 开始从操作系统分配内存,并且往 MySQL 错误日志写警告信息。
没有必要给这个缓冲池分配非常大的空间。
-
innodb_flush_log_at_trx_commit:用来控制缓冲区中的数据写入到日志文件以及日志文件数据刷新到磁盘的操作时机。其设置值及解释如下:
设置值 解释 0 日志缓冲每秒一次地被写到日志文件,并且对日志文件做向磁盘刷新的操作,但是在一个事务提交不做任何操作。 1(默认值) 在每个事务提交时,日志缓冲被写到日志文件,并且对日志文件做向磁盘刷新的操作。 2 在每个事务提交时,日志缓冲被写到日志文件,但不对日志文件做向磁盘刷新的操作,对日志文件每秒向磁盘做一次刷新操作。 设置成 0,则在数据库崩溃的时候会丢失那些没有被写入日志文件的事务,最多丢失 1 秒钟的事务,这种方式是最不安全的,也是效率最高的。设置成 2 的时候,因为只是没有刷新到磁盘,但是已经写入日志文件,所以只要操作系统没有崩溃,那么并没有丢失数据,比设置成 0 更安全一些。在 MySQL 官方手册中,为了确保事务的持久性和复制设置的一致性,都是建议将这个参数设置为 1 的。
-
innodb_lock_wait_timeout:MySQL 可以自动地监测行锁导致的死锁并进行相应的处理,但是对于表锁导致的死锁不 能自动的监测,所以该参数主要被用于在出现类似情况的时候等待指定的时间后回滚。系统默认值是 50 秒。
-
innodb_support_xa:是否支持分布式事务,默认值是 ON 或者 1,表示支持分布式事务。
如果确认应用中不需要使用分布式事务,则可以关闭这个参数,减少磁盘刷新的次数并获得更好的 InnoDB 性能。
-
innodb_log_buffer_size:定义日志缓存的大小。默认 1 MB。
默认的设置在中等强度写入负载以及较短事务的情况下,一般都可以满足服务器的性能要求。
如果它的值设置太高了,可能会浪费内存,因为它每秒都会刷新一次,因此无需设置超过 1 秒所需的内存空间。通常设置为 8~16MB 就足够了。
-
innodb_log_file_size:一个日志组中每个日志文件的大小。默认值是 5 MB。
此参数在高写入负载尤其是大数据集的情况下很重要。这个值越大则性能相对越高,但是带来的副作用是,当系统灾难时恢复时间会加大。
2.7.4.磁盘 I/O 优化
RAID 级别的选择:
- 数据读写都很频繁,可靠性要求也很高,最好选择 RAID 10。
- 数据读很频繁,写相对较少,对可靠性有一定要求,可以选择 RAID 5。
- 数据读写都很频繁,但可靠性要求不高,可以选择 RAID 0。
MySQL 的数据库名和表名是与文件系统的目录名和文件名对应的,默认情况下,创建的数据库和表都存放在参数 datadir 定义的目录下。这样如果不使用 RAID 或逻辑卷,所有的表都存放在一个磁盘设备上,无法发挥多磁盘并行读写的优势。在这种情况下,我们就可以利用 OS 的符号链接将不同的数据库或表、索引指向不同的物理磁盘, 从而达到分布磁盘 I/O 的目的。如:
-
将一个数据库指向其他物理磁盘:
mkdir /otherdisk/database/test # 在目标磁盘上创建目录 ln -s /otherdisk/database/test /path/to/datadir # 创建从 MySQL 数据目录到目标目录的符号链接 -
将 MyISAM(其他存储引擎不支持)表的数据文件或索引文件指向其他的物理磁盘。
-
对于新建表,可以通过
DATA DIRECTORY和INDEX DIRECTORY选项来完成。如:CREATE TABLE test( id INT PRIMARY KEY, name VARCHAR(20) ) ENGINE = MyISAM DATA DIRECTORY = '/disk2/data' INDEX DIRECTORY = '/disk3/index'; -
对于已有表,可以先将其数据文件(.MYD)或索引文件(.MYI)转移到目标磁盘,然后再建立符号连接即可。需要说明的是表定义文件(.frm)必须位于 MySQL 数据文件目录下,不能用符号连接。
-
atime 是 Linux/UNIX 系统下的一个文件属性,每当读取文件时,操作系统都会将读操作发生的时间回写到磁盘上。对于读写频繁的数据库文件来说,记录文件的访问时间一般没有任何用处,却会增加磁盘系统的负担,影响 I/O 的性能。如:
vim /etc/fstab
...
LABEL=/home /home ext3 noatime 1 2
...
mount -o remount /home
MyISAM 存储引擎有自己的索引缓存机制,但数据文件的读写完全依赖于操作系统,操作系统磁盘 I/O 缓存对 MyISAM 表的存取很重要。但 InnoDB 存储引擎与 MyISAM 不同,它采用类似 Oracle 的数据缓存机制来 Cache 索引和数据,操作系统的磁盘 I/O 缓存对其性能不仅没有帮助,甚至还有反作用。因此,在 InnoDB 缓存充足的情况下,可以考虑使用 Raw Device 来存放 InnoDB 共享表空间,具体操作方法如下:
-
修改 MySQL 配置文件,在 innodb_data_file_path 参数中增加裸设备文件名并指定 newraw 属性:
innodb_data_file_path = /dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw -
启动 MySQL,使其完成分区初始化工作,然后关闭 MySQL。此时还不能创建或修改 InnoDB 表。
-
将 innodb_data_file_path 中的 newraw 改为 raw:
innodb_data_file_path = /dev/hdd1:3Graw;/dev/hdd2:2Graw -
重新启动即可开始使用。
2.7.5.应用优化
主要有以下方法:
-
使用连接池。
-
减少对 MySQL 的访问:
-
避免对同一数据做重复检索。
如以下两次查询使用一次代替,将查询数据保存即可:
SELECT old, gender FROM users WHERE userid = 231; SELECT address FROM users WHERE userid = 231;SELECT old, gender, address FROM users WHERE userid = 231; -
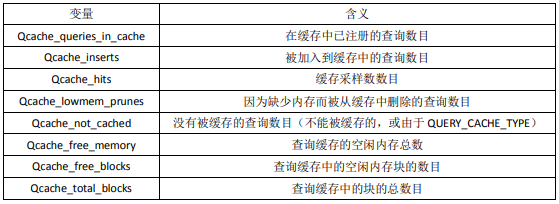
使用查询缓存。MySQL4.1 后新增查询缓存功能,它的作用是存储 SELECT 查询的文本以及相应结果。如果随后收到一个相同的查询,服务器会从查询缓存中重新得到查询结果,而不再需要解析和执行查询。查询缓存的适用对象是更新不频繁的表,当表更改(包括表结构和表数据)后,查询缓存值的相关条目被清空。
查询缓存相关的参数(
SHOW VARIABLES LIKE '%query_cache%')解释:- have_query_cache:服务器在安装是否已经配置了高速缓存。
- query_cache_size:缓存区大小,单位为 M。
- query_cache_type:变量值从 0 到 2,含义分别为: 0/off 缓存关闭;1/on 缓存打开,使用
SQL_NO_CACHE提示的SELECT除外;2/demand 只有带SQL_CACHE的SELECT语句提供高速缓存。
通过
SHOW STATUS命令,可以监视查询缓存的使用情况。![]()
-
增加 CACHE 层。
-
-
负载均衡
-
利用 MySQL 复制分流查询操作。
具体的实现是一个主服务器承担更新操作,而多台从服务器承担查询操作,主从之间通过复制实现数据的同步。
对于主从之间不需要复制全部表的情况,可以通过在主服务器上搭建一个虚拟的从服务器,将需要复制到从服务器的表设置成 BLACKHOLE 引擎,然后定义 replicate-do-table 参数只复制这些表,这样就过滤出需要复制的 BINLOG,减少了传输 BINLOG 的带宽。
但是这种办法也存在一些问题,最主要的问题是当主数据库上更新频繁或者网络出现问题的时候,主从之间的数据可能存在比较大的延迟更新,从而造成查询结果和主数据库上有所差异。
-
采用分布式数据库架构。
可以使用 MySQL 的 CLUSTER 功能或者通过用户自己编写的程序来实现全局事务。需要注意的是当前分布式事务只支持 InnoDB 存储引擎。
-
-
其他优化措施
- 对于没有删除行操作的 MyISAM 表,插入操作和查询操作可以并行进行,因为没有删除操作的表查询期间不会阻塞插入操作。对于确实需要执行删除操作的表,尽量在空闲时间进行批量删除操作,并且在进行删除操作之后应该进行
OPTIMIZE操作来消除由于删除操作带来的空洞,以避免将来的更新操作阻塞其他操作。 - 充分利用列有默认值的事实。只有当插入的值不同于默认值时,才明确地插入值。这会减少 MySQL 需要做的语法分析从而提高插入速度。
- 表的字段尽量不使用自增长变量,在高并发情况下该字段的自增可能对效率有比较大的影响,推荐通过应用来实现字段的自增长。
- 对于没有删除行操作的 MyISAM 表,插入操作和查询操作可以并行进行,因为没有删除操作的表查询期间不会阻塞插入操作。对于确实需要执行删除操作的表,尽量在空闲时间进行批量删除操作,并且在进行删除操作之后应该进行
2.8.锁问题
MySQL 三种锁的特性可大致归纳如下:
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如 Web 应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
可通过检查 table_locks_waited 和 table_locks_immediate 状态变量(SHOW STATUS LIKE 'table_%';)来分析系统上的表锁定争夺,如果 table_locks_waited 值较高,则说明存在着较严重的表级锁争用情况。
MySQL 表级锁有共享锁和排它锁。如:
LOCK TABLE film_text WRITE;
LOCK TABLE film_text READ;
LOCK TABLE orders WRITE LOCAL, order_detail READ LOCAL;
UNLOCK TABLES;
LOCAL表明在满足表并发插入条件的情况下,允许其他事务在表尾并发插入记录。
在用 LOCK TABLES 给表显式加表锁时,必须同时取得所有涉及到表的锁,并且 MySQL 不支持锁升级。也就是说,在执行 LOCK TABLES 后,只能访问显式加锁的这些表,不能访问未加锁的表;同时,如果加的是读锁,那么只能执行查询操作,而不能执行更新操作。而且,同一个表在 SQL 语句中出现多少次,就要通过与 SQL 语句中相同的别名锁定多少次,否则也会出错。如:
LOCK TABLE actor AS a READ, actor AS b READ;
SELECT a.first_name, b.last_name FROM actor a, actor b WHERE ...;
“丢失更新”需要应用程序对要更新的数据加必要的锁来解决,因此防止丢失更新应该是应用的责任。而“脏读”、“不可重复读”、“幻读”其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本上可分为以下两种:
- 加锁:在读取数据前,对其加锁,阻止其他事务对数据进行修改。
- MVCC/MCC(MultiVersion Concurrency Control,多版本并发控制):不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照,并用这个快照来提供一定级别(语句级或事务级)的一致性读取。
MySQL 支持全部 4 个隔离级别,在具体实现时,有些情况使用 MVCC,有些情况不是。
2.8.1.MyISAM 锁
MyISAM 只支持表锁。MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁;在执行更新操作 (UPDATE、DELETE、INSERT 等)前,会自动给涉及的表加写锁。因此,用户一般不需要直接用 LOCK TABLE 命令给 MyISAM 表显式加锁。
由于 MySQL 不支持锁升级,MyISAM 总是一次获得 SQL 语句所需要的全部锁,所以 MyISAM 表不会出现死锁。
在一定条件下,MyISAM 表支持查询和插入操作的并发进行,其他事务的并发插入的数据在查询事务结束前是不可见的。 MyISAM 存储引擎有一个系统变量 concurrent_insert,专门用以控制其并发插入的行为,其可取值及控制的并发插入行为解释如下:
| 可取值 | 并发插入行为 |
|---|---|
| 0 | 不允许并发插入。 |
| 1(默认值) | 如果 MyISAM 表中没有空洞(即表的中间没有被删除的 行),MyISAM 允许在一个进程读表的同时,另一个进程从表尾插入记录。 |
| 2 | 无论 MyISAM 表中有没有空洞,都允许在表尾并发插入记录。 |
MyISAM 对于对同一表的多个事务请求同时请求读锁和写锁,会让写事务先获得锁(大量更新操作可能会造成查询操作很难获得读锁,这也是 MyISAM 不太适合有大量更新操作和查询操作应用的原因)。所以,应用中应尽量避免出现长时间运行的查询操作,不要总想用一条 SELECT 语句来解决问题,因为这种看似巧妙的SQL语句,往往比较复杂执行时间较长,在可能的情况下可以通过使用中间表等措施对 SQL 语句做一定的“分解”,使每一步查询都能在较短时间完成,从而减少锁冲突。可以通过以下设置 MyISAM 的调度行为:
- 指定启动参数
low-priority-updates,使 MyISAM 引擎默认给予读请求以优先的权力。 - 执行命令
SET LOW_PRIORITY_UPDATES = 1;,使该连接发出的更新请求优先级降低。 - 指定 INSERT、UPDATE、DELETE 语句的 LOW_PRIORITY 属性,降低该语句的优先级。
另外,MySQL 也提供了一种折中的办法来调节读写冲突,即给系统参数 max_write_lock_count 设置一个合适的值,当一个表的读锁达到这个值后,MySQL 就暂时将写请求的优先级降低, 给读进程一定获得锁的机会。
2.8.2.InnoDB 锁
InnoDB 支持表级锁、行级锁。
可以通过检查 InnoDB_row_lock 状态变量(SHOW STATUS LIKE 'InnoDB_row_lock%';)来分析系统上的行锁争夺情况。如果锁争夺较严重(如InnoDB_row_lock_waits、InnoDB_row_lock_time_avg值较高),可以通过设置 InnoDB Monitors 来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因,具体方法如下:
CREATE TABLE innodb_monitor(a INT) ENGINE = INNODB;
SHOW INNODB STATUS \G; # 使用此语句查看
DROP TABLE innodb_monitor; # 监视器通过此语句来停止查看
打开监视器以后,默认情况下每 15 秒会向日志中记录监控的内容。如果长时间打开会导致 err 文件变得非常的巨大,所以用户在确认问题原因之后,要记得删除监控表以关闭监视器,或者通过使用--console选项来启动服务器以关闭写日志文件。
InnoDB 允许表锁、行锁共存,除了行锁支持排他锁和共享锁外,还有两种内部使用的意向表锁:
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
上述锁的兼容情况如下:
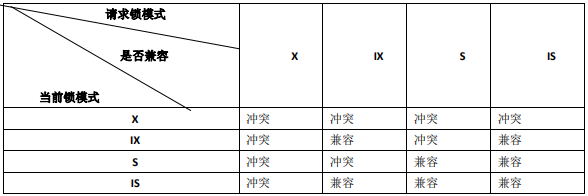
意向锁是 InnoDB 自动加的,不需用户干预。对于 UPDATE、DELETE 和 INSERT 语句,InnoDB 会自动给涉及数据集加排他锁(X);对于普通 SELECT 语句,InnoDB 不会加任何锁。事务可以通过以下语句显式给记录集加共享锁或排他锁:
- 共享锁(S):
SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE; - 排他锁(X):
SELECT * FROM table_name WHERE ... FOR UPDATE;
InnoDB 行锁是通过给索引上的索引项加锁来实现的,这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB 才使用行级锁,否则 InnoDB 将使用表锁。
对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB 也会对这个“间隙”加锁。InnoDB 除了通过范围条件加锁时使用间隙锁(Next-Key 锁)外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB 也会使用间隙锁。InnoDB 使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求;另外一方面,是为了满足其恢复和复制的需要。在使用范围条件检索并锁定记录时,InnoDB 这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此在实际应用开发中,尤其是并发插入比较多的应用,尽量使用相等条件来访问更新数据,避免使用范围条件。
MySQL 通过 BINLOG 记录执行成功的 INSERT、UPDATE、DELETE 等更新数据的 SQL 语句,并由此实现 MySQL 数据库的恢复和主从复制。MySQL 的恢复机制(复制其实就是在 Slave MySQL 不断做基于 BINLOG 的恢复)有以下特点。
- MySQL 的恢复是 SQL 语句级的,也就是重新执行 BINLOG 中的 SQL 语句。
- MySQL 的 BINLOG 是按照事务提交的先后顺序记录的,恢复也是按这个顺序进行的。
从上面两点可知,MySQL 的恢复机制要求:在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,也就是不允许出现幻读。这已经超过了“可重复读”隔离级别的要求,实际上是要求事务要串行化。这也是许多情况下, InnoDB 要用到间隙锁的原因。比如在用范围条件更新记录时,无论在 Read Committed 或是 Repeatable Read 隔离级别下,InnoDB 都要使用间隙锁,但这并不是隔离级别要求的。
另外,对于
INSERT INTO target_tab SELECT * FROM source_tab WHERE ...和CREATE TABLE new_tab SELECT ... FROM source_tab WHERE ...(CATS)这种 SQL 语句,用户并没有对 source_tab 做任何更新操作,但 MySQL 对这种 SQL 语句做了特别处理。这里 InnoDB 给 source_tab 加了共享锁(并没有使用多版本数据一致性读技术),如果 SELECT 条件是范围条件,InnoDB 则为 source_tab 加的是间隙锁,这会阻止对源表的并发更新。这种语句被 MySQL 称为不确定的 SQL,不推荐使用。如果一定要使用这种语句,又不希望对 source_tab 的并发更新产生影响,可以采取以下两种措施:
- 执行
SET innodb_locks_unsafe_for_binlog = 'on';,强制 MySQL 使用多版本数据一致性读。但付出的代价是可能无法用 binlog 正确地恢复或复制数据。因此,不推荐使用这种方式。- 通过使用
SELECT * FROM source_tab ... INTO outfile和LOAD DATA infile ...语句组合来间接实现,采用这种方式 MySQL 不会给 source_tab 加锁。
| Read Uncommitted | Read Committed | Repeatable Read | Serializable | ||
|---|---|---|---|---|---|
| SQL | 条件 | ||||
| SELECT | 相等 | none locks | consisten read/none lock | consisten read/none lock | share locks |
| 范围 | none locks | consisten read/none lock | consisten read/none lock | share next-key | |
| UPDATE | 相等 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 范围 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| INSERT | N/A | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| REPLACE | 无键冲突 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 键冲突 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| DELETE | 相等 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 范围 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| SELECT ... FROM ... LOCK IN SHARE MODE | 相等 | share locks | share locks | share locks | share locks |
| 范围 | share locks | share locks | share next-key | share next-key | |
| SELECT ... FROM ... FOR UPDATE | 相等 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 范围 | exclusive locks | share locks | exclusive next-key | exclusive next-key | |
| INSERT INTO ... SELECT ... (指原表) | innodb_locks_unsafe_for_binlog = off | share next-key | share next-key | share next-key | share next-key |
| innodb_locks_unsafe_for_binlog = on | none locks | consisten read/none lock | consisten read/none lock | share next-key | |
| CREATE TABLE ... SELECT ... (指原表) | innodb_locks_unsafe_for_binlog = off | share next-key | share next-key | share next-key | share next-key |
| innodb_locks_unsafe_for_binlog = on | none locks | consisten read/none lock | consisten read/none lock | share next-key | |
在应用中,应该尽量使用较低的隔离级别,以减少锁争用的机率。实际上,通过优化事务逻辑,大部分应用使用 Read Committed 隔离级别就足够了。对于一些确实需要更高隔离级别的事务,可以通过在程序中执行SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ或SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE动态改变隔离级别的方式满足需求。
InnoDB 表大部分情况下都应该使用行锁,但在个别特殊事务中,也可以考虑使用表级锁:
- 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁, 不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
- 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
当然,应用中这两种事务不能太多,否则,就应该考虑使用 MyISAM 表了。
InnoDB 使用表锁的注意事项:
-
使用
LOCK TABLES虽然可以给 InnoDB 加表级锁,但必须说明的是,表锁不是由 InnoDB 存储引擎层管理的,而是由其上一层 MySQL Server 负责的。仅当autocommit = 0、innodb_table_locks = 1(默认设置)时,InnoDB 层才能知道 MySQL 加的表锁,MySQL Server 也才能感知 InnoDB 加的行锁。这种情况下,InnoDB 才能自动识别涉及表级锁的死锁;否则, InnoDB 将无法自动检测并处理这种死锁。 -
在用
LOCK TABLES对 InnoDB 表加锁时要注意,要将 AUTOCOMMIT 设为 0,否则 MySQL 不会给表加锁;事务结束前,不要用UNLOCK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK并不能释放用LOCK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁。正确的方式见如下语句:SET AUTOCOMMIT = 0; LOCK TABLES t1 WRITE, t2 READ, ...; # do something with tables t1, t2, ... here COMMIT; UNLOCK TABLES;
2.8.3.死锁
MyISAM 表锁是 deadlock free 的,这是因为 MyISAM 总是一次获得所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。但在 InnoDB 中,除单个 SQL 组成的事务外,锁是逐步获得的,这就决定了在 InnoDB 中发生死锁是可能的。
发生死锁后,InnoDB 一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及表锁的情况下,InnoDB 并不能完全自动检测到死锁,这需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决。
innodb_lock_wait_timeout 参数并不是只用来解决死锁问题。在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
通常来说,死锁都是应用设计的问题。避免死锁的常用方法:
-
在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
-
在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
-
在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
-
在 REPEATABLE READ 隔离级别下,如果两个线程同时对相同条件记录用
SELECT ... FOR UPDATE加排他锁,在没有符合该条件记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成 READ COMMITTED,就可避免问题。session1 session2 SET @@tx_isolation;
REPEATABLE-READSET @@tx_isolation;
REPEATABLE-READSET AUTOCOMMIT = 0;SET AUTOCOMMIT = 0;SELECT first_name FROM actor WHERE actor_id = 201 FOR UPDATE;
对不存在的记录加 for update 锁。SELECT first_name FROM actor WHERE actor_id = 201 FOR UPDATE;
对不存在的记录加 for update 锁。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
因为其他 session 也对该记录加了锁,所以当前插入会等待。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
因为其他 session 已经对记录进行了更新,这时候再插入记录就会提示死锁并退出。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
由于其他 session 已经退出,当前 session 可以获得锁并成功插入记录。 -
当隔离级别为 READ COMMITTED 时,如果两个线程都先执行
SELECT ... FOR UPDATE,判断是否存在符合条件的记录,如果没有,就插入记录。此时,只有一个线程能插入成功,另一个线程会出现锁等待,当第 1 个线程提交后,第 2 个线程会因主键重出错,但虽然这个线程出错了,却会获得一个排他锁!这时如果有第 3 个线程又来申请排他锁,也会出现死锁。 对于这种情况,可以直接做插入操作,然后再捕获主键重异常,或者在遇到主键重错误时,总是执行 ROLLBACK 释放获得的排他锁。session1 session2 session3 SET @@tx_isolation;
READ-COMMITTEDSET @@tx_isolation;
READ-COMMITTEDSET @@tx_isolation;
READ-COMMITTEDSET AUTOCOMMIT = 0;SET AUTOCOMMIT = 0;SET AUTOCOMMIT = 0;SELECT first_name FROM actor WHERE actor_id = 201 FOR UPDATE;
session1 获得 for update 的共享锁。SELECT first_name FROM actor WHERE actor_id = 201 FOR UPDATE;
由于记录不存在,session2 也可以获得 for update 的共享锁。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
session1 可以成功插入记录。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
session2 插入申请等待获得锁。COMMIT;
session1 成功提交。INSERT INTO actor(actor_id, name) VALUES(201, 'Tom');
session2 获得锁,发现插入记录主键重,这个时候抛出了异常,但是并没有释放共享锁。SELECT actor_id, name FROM actor WHERE actor_id = 201 FOR UPDATE;
session3 申请获得共享锁,因为 session2 已经锁定该记录,所以 session3 需要等待。UPDATE actor SET name = 'Lan' WHERE actor_id = 201;
这个时候,如果 session2 直接对记录进行更新操作,则会抛出死锁的异常。SELECT actor_id, name FROM actor WHERE actor_id = 201 FOR UPDATE;
session2 释放锁后,session3 获得锁。
如果出现死锁,可以使用SHOW INNODB STATUS \G;命令来确定最后一个死锁产生的原因。
2.9.MySQL 常用工具
-
mysql
mysql 是连接数据库的客户端工具。其语法如下:
mysql [options] [database]如果不写 database,连接后需要使用
USE database;语句进入要操作的数据库。如果不写 options,mysql 将会使用
'用户'@'localhost'和空密码连接本机上的 3306 端口。options 有如下常用选项:-u、--user=name:指定用户名。-p、--password[=name]:指定密码。-h、--host=name:指定服务器 IP 或域名。-P、--port=#:指定端口。
空用户在 MySQL 刚刚安装完毕后会自动生成,这也就是我们只使用一个
mysql命令就可以连接到数据库的原因。如果空用户被删除,mysql 会接着去 my.cnf 里面去找 [client] 组内的用户名和密码,如果有则按照此用户名和密码进行登录;如果没有记录此选项,则系统会使用'root'@'localhost'用户进行登录。可以使用以下 MySQL 语句查看当前连接用户:
SELECT CURRENT_USER();默认端口(3306)一般不要使用,可以改为任意操作系统未占用的端口。
默认字符集可以在 my.cnf 中的 [mysql] 组和 [client] 组分别设置(
default-character-set=charset-name),也可在 mysql 连接时设置客户端默认字符集(mysql --default-character-set=charset-name),相当于在 mysql 客户端连接成功后执行SET names charset;。可以通过以下指令查看相关客户端字符集:
SHOW VARIABLES LIKE 'chara%';options 还可以添加以下选项:
-
-e/--execute=name,表示执行对应 SQL 语句并退出。多个 SQL 语句之间用分号隔开。如:mysql -u root -p -e "SELECT name FROM country WHERE name LIKE 'AU%'; SELECT COUNT(*) FROM city" world -
-E/--vertical,将输出方式按照字段顺序竖着显示,类似于 MySQL 中执行 SQL 语句添加\G,经常和-e参数一起使用。 -
-s/--silent,mysql 安静模式,这会将输出中线条框去掉,字段之间用 tab 进行分隔,每条记录显示一行。 -
-f/--force,强制执行 SQL,在批量执行 SQL 时,这会跳过出错的 SQL 强制执行后面的 SQL。 -
-v/--verbose,显示更多信息,如出错的 SQL 语句。 -
--show-warnings,显示警告信息。
-
myisampack
myisampack 是 MyISAM 表压缩工具。压缩后的表将成为只读表,不能执行 DML 操作。其语法如下:
myisampack [options] filename -
mysqladmin
mysqladmin 是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前的状态,创建并删除数据库等。它的功能和 mysql 客户端非常类似,主要区别在于它更侧重于一些管理方面的功能,比如关闭数据库。其语法如下:
mysqladmin [options] command [command-options]...这里将可以执行的命令行简单列举如下:
![]()
如关闭数据库:
mysqladmin -u root -p shutdown -
mysqlbinlog
由于服务器生成的二进制日志文件以二进制格式保存,所以如果要想检查这些文件的文本格式,就会用到 mysqlbinlog 日志管理工具。其语法如下:
mysqlbinlog [options] log-files1 log-files2...options 常用如下:
-
-d/--database=name:指定数据库名称,只列出指定的数据库相关操作。 -
-o/--offset=#:忽略掉日志中的前 n 行命令。 -
-r/--result-file=name:将输出的文本格式日志输出到指定文件。 -
-s/--short-form:显示简单格式,省略掉一些信息。 -
--set-charset=char-name:在输出为文本格式时,在文件第一行加上SET names char-name。 这个选项在某些情况下装载数据时,非常有用。 -
--start-datetime=name –stop-datetime=name:指定日期间隔内的所有日志。如:mysqlbinlog localhost-bin.000033 --start-datetime='2007/08/30 05:00:00' --stop-datetime='2007/08/30 05:06:30' -
--start-position=# --stop-position=#:指定位置间隔内的所有日志。如:mysqlbinlog localhost-bin.000033 --start-position=4 --stop-position=196
-
-
mysqlcheck
mysqlcheck 客户端工具可以检查和修复 MyISAM 表,还可以优化和分析表。实际上,它集成了 MySQL 工具中 check、repair、analyze、optimize 的功能。有 3 种方式调用 mysqlcheck:
mysqlcheck [options] db_name [tables] mysqlcheck [options] --database DB1 [DB2 DB3 ...] mysqlcheck [options] --all-databaseoptions 有这些常用选项:
-c/--check检查表(默认选项)、-r/--repair修复表、-a/--analyze分析表、-o/--optimize优化表。如:
mysqlcheck -u root -a test -
mysqldump
mysqldump 客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表或装载表的 SQL 语句。有 3 种方式调用 mysqldump:
mysqldump [options] db_name [tables] # 备份单个数据库或者数据库中部分数据表 mysqldump [options] --database DB1 [DB2 DB3 ...] # 备份指定的一个或多个数据库 mysqldump [options] --all-database # 备份所有数据库如果没有指定数据库中的任何表,默认导出所有数据库中所有表。
选项中,除了与 mysql 中一样的连接选项,还有:
- 输出内容选项:
--add-drop-database:每个数据库创建语句前加上DROP DATABASE语句。默认自动加上。--add-drop-table:在每个表创建语句前加上DROP TABLE语句。默认自动加上。-n/--no-create-db:不包含数据库的创建语句。-t/--no-create-info:不包含数据表的创建语句。-d/--no-data:不包含数据。
- 输出格式选项:
--compact:输出结果简洁,不包括默认选项中的各种注释。-c/--complete-insert:输出文件中的INSERT语句包括字段名称,默认是不包括字段名称的。-T/--tab=name:将指定数据表中的数据备份为单纯的数据文本和建表 SQL 两个文件,经常和以下几个选项一起配合使用,将数据导出为指定格式显示。--fields-terminated-by=name:域分隔符。--fields-enclosed-by=name:域引用符。--fields-optionally-enclosed-by=name:域可选引用符。--fields-escaped-by=name:转义字符。--lines-terminated-by=name:记录结束符。
- 字符集选项:
--default-character-set=name选项可以设置导出的客户端字符集。 - 其他常用选项:
-F/--flush-logs:备份前刷新日志。加上此选项后,备份前将关闭旧日志,生成新日志。使得进行恢复的时候直接从新日志开始进行重做,大大方便了恢复过程。-l/--lock-tables:给所有表加读锁。可以在备份期间使用,使得数据无法被更新,从而使备份的数据保持一致性,可以配合-F选项一起使用。
- 输出内容选项:
-
mysqlhotcopy
mysqlhotcopy 是一个 Perl 脚本,它使用
LOCK TABLES、FLUSH TABLES、cp 或 scp 来快速备份数据库。它是备份数据库或单个表的最快途径,其缺点是mysqlhotcopy 只用于备份 MyISAM, 而且它需要运行在 Linux/UNIX 环境中。 -
mysqlimport
mysqlimport 是客户端数据导入工具,用来导入 mysqldump 加
-T选项后导出的文本文件。它实际上是客户端提供了LOAD DATA INFILEQL语句的一个命令行接口。用法和LOAD DATA INFILE子句非常类似,其基本语法如下:mysqlimport [options] db_name textfile1 [textfile2 ...] -
mysqlshow
mysqlshow 客户端对象查找工具,用来很快地查找存在哪些数据库、数据库中的表、表中的列或索引。和 mysql 客户端工具很类似,不过有些特性是 mysql 客户端工具所不具备的。其语法如下:
mysqlshow [option] [db_name [tbl_name [col_name]]]如果不加任何选项,默认情况下,会显示所有数据库。常用选项:
--count:显示数据库和表的统计信息。如果不指定数据库,则显示每个数据库的名称、表数量、记录数量;如果指定数据库,则显示指定数据库的每个表名、字段数量,记录数量;如果指定具体数据库中的具体表,则显示表的字段信息。-k/--keys:显示指定表中的所有索引。其显示内容其实和 MySQL 客户端执行SHOW FULL COLUMNS FROM tbl_name; SHOW INDEX FROM tab_name结果一样。-i/--status:显示表中的一些状态信息。其显示内容其实和 MySQL 客户端执行SHOW TABLE STATUS FROM db_name LIKE 'tabl_name'结果一样。
-
perror
perror 用于解释错误代码详细含义。其语法如下:
perror [options] [error_code [error_code...]] -
replace
replace 是 MySQL 自带的一个对文件中的字符串进行替换的工具,类似于 Linux 下的 sed。其语法如下:
replace from to [from to] ... -- file [file ...] # 会覆盖源文件 replace from to [from to] ... < file # 替换后的内容显示在 stdout,不会覆盖源文件如:
# more a # a1 a2 a3 # b1 b2 b3 replace a1 aa1 b1 bb1 -- a # more a # aa1 a2 a3 # bb1 b2 b3

2.10.MySQL 日志
在 MySQL 中,有 4 种不同的日志,分别是错误日志、二进制日志(BINLOG 日志)、查询日志和慢查询日志。
2.10.1.错误日志
记录当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。
可以用--log-error[=file_name]选项来指定 mysqld 保存错误日志文件的位置。 如果没有给定 file_name 值,mysqld 使用错误日志名 host_name.err(host_name 为主机名) 并默认在参数 DATADIR 指定的目录中写入日志文件。
2.10.2.二进制日志
二进制日志记录了所有的 DDL 语句和 DML 语句,但是不包括数据查询语句。语句以“事件”的形式保存,它描述了数据的更改过程。此日志对于灾难时的数据恢复起着极其重要的作用。
当用--log-bin[=file_name]选项启动时,mysqld 将包含所有更新数据的 SQL 命令写入日志文件。 如果没有给出 file_name 值,默认名为主机名后面跟“-bin”。如果给出了文件名,但没有包含路径,则文件默认被写入参数 DATADIR 指定的目录。
对于比较繁忙的 OLTP(在线事务处理)系统,由于每天生成日志量大,需要定期删除日志。常用删除方法如下:
-
执行 MySQL 命令
RESET MASTER;。 -
执行 MySQL 命令
PURGE MASTER LOGS TO 'mysql-bin.******',该命令将删除******编号之前的所有日志。 -
执行 MySQL 命令
PURGE MASTER LOGS BEFORE 'yyyy-mm-dd hh:mm:ss',该命令将删除日期为yyyy-mm-dd hh:mm:ss之前产生的所有日志。 -
设置参数
--expire_logs_days=#,此参数的含义是设置日志的过期天数,过了指定的天数后日志将会被自动删除。修改该参数后记得使用
FLUSH LOGS;语句刷新。
MySQL 还提供了一些其他参数选项来进行更小粒度的管理:
--binlog-do-db=db_name、--binlog-ignore-db=db_name:分别表示,如果当前的数据库是 db_name,应将、不应将更新记录到二进制日志中,其他所有没有显式指定的数据库更新将被忽略、记录。该语句可重复设置以设置多个数据库。--innodb-safe-binlog:此选项经常和--sync-binlog=N(每写 N 次日志同步磁盘)一起配合使用,使得事务在日志中的记录更加安全。SET SQL_LOG_BIN=0:具有 SUPER 权限的客户端可以通过此语句禁止将自己的语句记入二进制记录。它很可能造成日志记录的不完整或者在复制环境中造成主从数据的不一致。
2.10.3.查询日志
查询日志记录了客户端的所有语句。
当用--log[=file_name]/-l [file_name]选项启动 mysqld 时,查询日志开始被记录。如果没有给定 file_name 的值,日志将写入参数 DATADIR 指定的路径下,默认文件名是 host_name.log。
查询日志记录的格式是纯文本,可以直接进行读取。
2.10.4.慢查询日志
慢查询日志记录了包含所有执行时间超过参数 long_query_time(单位:秒)所设置值的 SQL 语句的日志。获得表锁定的时间不算作执行时间。
当用--log-slow-queries[=file_name]选项启动 mysqld 时,慢查询日志开始被记录。如果没有给定 file_name 的值,日志将写入参数 DATADIR指定的路径下,默认文件名是 host_name-slow.log。
慢查询日志记录的格式是纯文本,可以被直接读取。
如果慢查询日志中记录内容很多,可以使用 mysqldumpslow 工具 来对慢查询日志进行分类汇总。mysqldumpslow 将会自动视为同一个语句进行统计,变量值用 N 来代替。
在 MySQL5.1 中,通过--log-slow-admin-statements服务器选项,可以请求将慢管理语句(例如OPTIMIZE TABLE、ANALYZE TABLE和ALTER TABLE)写入慢查询日志。
2.11.备份与恢复
MySQL 的备份主要分为逻辑备份和物理备份。在 MySQL 里面,逻辑备份的最大优点是对于各种存储引擎,都可以用同样的方法来备份;而物理备份则不同,不同的存储引擎有着不同的备份方法。因此,对于不同存储引擎混合的数据库,用逻辑备份会更简单一些。
2.11.1.备份、恢复策略
以下是在进行备份或恢复操作时需要考虑的一些因素:
-
确定要备份的表的存储引擎是事务型还是非事务性,两种不同的存储引擎备份方式在处理数据一致性方面是不太一样的。
-
确定使用全备份还是增量备份。
全备份的优点是备份保持最新备份,恢复的时候可以花费更少的时间;缺点是如果数据量大,将会花费很多的时间,并对系统造成较长时间的压力。
增量备份则恰恰相反,只需要备份每天的增量日志,备份时间少,对负载压力也小;缺点就是恢复的时候需要全备份加上次备份到故障前的所有日志,恢复时间会长些。
-
可以考虑采取复制的方法来做异地备份,但是记住,复制不能代替备份,它对数据库的误操作也无能为力。
-
要定期做备份,备份的周期要充分考虑系统可以承受的恢复时间。备份要在系统负载较小的时候进行。
-
确保 MySQL 打开
log-bin选项,有了 BINLOG,MySQL 才可以在必要的时候做完整恢复,或基于时间点的恢复,或基于位置的恢复。 -
要经常做备份恢复测试,确保备份是有效的,并且是可以恢复的。
2.11.2.逻辑备份和恢复
在 MySQL 中,使用 mysqldump 工具来完成逻辑备份。
需要强调的是,为了保证数据备份的一致性,MyISAM 存储引擎在备份的时候需要加上-l/--lock-tables参数,表示将所有表加上读锁。对于事务存储引擎(InnoDB 和 BDB)来说,可以采用更好的选项--single-transaction,此选项将使得 InnoDB 存储引擎得到一个快照,使得备份的数据能够保证一致性。
完全恢复示例:
mysqldump -u root -p -l -F test > test.dmp # 备份数据
mysql -u root -p test < test.dmp # 恢复数据
mysqlbinlog localhost-bin.000015 | mysql -u root -p test # 注意,将备份恢复后数据并不完整,还需要将备份后执行的日志进行重做
由于误操作(比如误删除了一张表),这时使用完全恢复是没有用的,因为日志里面还存在误操作的语句,我们需要的是恢复到误操作之前的状态,然后跳过误操作语句,再恢复后面执行的语句,完成我们的恢复。这种恢复叫不完全恢复,在 MySQL 中,不完全恢复分为基于时间点的恢复(mysqlbinlog 的--stop-date、--start-date选项)和基于位置的恢复(mysqlbinlog 的--stop-position、--start-position选项)。
2.11.3.物理备份和恢复
物理备份又分为冷备份和热备份两种,和逻辑备份相比,它的最大优点是备份和恢复的速度更快,因为物理备份的原理都是基于文件的 cp。
冷备份其实就是停掉数据库服务,cp 数据文件的方法。这种方法对 MyISAM 和 InnoDB 存储引擎都适合,但是一般很少使用,因为很多应用是不允许长时间停机的。
MySQL 中,对于不同的存储引擎热备份方法也有所不同:
-
MyISAM 热备份:本质就是将要备份的表加读锁,然后再 cp 数据文件到备份目录。常用的有以下两种方法:
-
使用 mysqlhotcopy 工具
mysqlhotcopy db_name [/path/to/new_directory] -
手工锁表 copy。首先数据库中所有表加读锁(
FLUSH TABLES FOR READ;),然后 cp 数据文件到备份目录即可。
-
-
InnoDB 热备份:使用 ibbackup 工具(收费)。
2.11.4.表的数据导出、导入
-
导出:可以用以下两种方法:
-
SELECT ... INTO OUTFILE 'target_file' [options];命令。options 参数可以是:FILEDS TERMINATED BY 'string':字段分隔符,默认为制表符。FILEDS [OPTIONALLY] ENCLOSED BY 'char':字段引用符,如果加OPTIONALLY选项则只用在 char、 varchar 和 text 等字符型字段上。默认不使用引用符。FILEDS ESCAPED BY 'char':转义字符,默认为\。FILEDS STARTING BY 'string':每行前都加此字符串,默认\0。FILEDS TERMINATED BY 'string':行结束符,默认为\n。
char是单字符,string是字符串。 -
用 mysqldump 导出数据为文本。
其实,mysqldump 实际调用的就是前者提供的接口,并在其上面添加了一些新的功能而已。
-
-
导入:只讨论用
SELECT… INTO OUTFILE ...或者 mysqldump 导出的纯数据文本的导入方法。和导出类似,导入也有两种不同的方法,分别是LOAD DATA INFILE ...和 mysqlimport。LOAD DATA [LOCAL] INFILE 'filename' INTO TABLE tbl_name [options];命令。options 参数除了含有SELECT… INTO OUTFILE ...的 options 参数外(前三个一样,后两个FILEDS改为LINES),还有:IGNORE number LINES:忽略文件中前 n 行。(col_name_or_user_var, ...):按照列出的字段顺序和字段数量加载数据。SET col_name = expr, ...:将列做一定的数值转换后再加载。
- 用 mysqlimport 导入数据文本。options 参数除了前面提到的与
-T配合使用的五个,还有--ignore-lines=number表示忽略前几行。
如果导入和导出是跨平台操作的(Windows 和 Linux),那么要注意设置参数line-terminated-by, Windows 上设置为line-terminated-by='\r\n' , Linux 上设置为line-terminated-by='\n'。
2.12.MySQL 权限与安全
2.12.1.MySQL 权限管理
MySQL 权限系统通过下面两个阶段进行认证:
- 对连接的用户进行身份认证,合法的用户通过认证,不合法的用户拒绝连接。
- 对通过认证的合法用户赋予相应的权限,用户可以在这些权限范围内对数据库做相应的操作。
对于身份的认证,MySQL 是通过 IP 地址和用户名联合进行确认的。MySQL 的权限表在数据库启动的时候就载入内存。在权限存取的两个过程中,系统会用到名为“mysql”的数据库中 user、host 和 db 这 3 个最重要的权限表。
当用户进行连接的时候,权限表的存取过程有以下两个阶段:
- 先从 user 表中的 host、user 和 password 这 3 个字段中判断连接的 IP、用户名和密码是否存在于表中,如果存在,则通过身份验证,否则拒绝连接。
- 如果通过身份验证, 则按照 user、db、tables_priv、columns_priv 权限表的顺序得到数据库权限。 在这几个权限表中,权限范围依次递减,全局权限覆盖局部权限。按照这个顺序检查时,前者权限表更广泛的权限列为“Y”时,不再检查后者权限表。
对所有数据库都具有相同权限的用户记录并不需要记入 db 表,仅仅需要将 user 表中的对应列改为“Y”。user 表中的每个权限都代表了对所有数据库都有的权限。当只授予部分数据库某些权限时,user 表中的相应权限列保持“N”,而将具体的数据库权限写入 db 表。
两种方法创建账号:
-
使用
GRANT语句(本质是修改权限表然后刷新权限)。语法如下:GRANT priv_type [(column_list)] [, priv_type [(column_list)]]... ON [object_type] {tbl_name | * | *.* | db_name.*} TO user_identifier [IDENTIFIED BY [PASSWORD] 'passwd'] [, user_identifier [IDENTIFIED BY [PASSWORD] 'passwd']]... [WITH GRANT OPTION] # object_type = TABLE | FUNCTION | PROCEDURE如:
GRANT ALL PRIVILEGES ON *.* TO 'z1'@'localhost'; GRANT ALL PRIVILEGES ON *.* TO 'z2'@'localhost' WITH GRANT OPTION; GRANT ALL PRIVILEGES ON *.* TO 'z3'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;ALL PRIVILEGES会赋予除 Grant_priv 外所有权限。在 MySQL5.0 里面,密码会被加密为“*”开头的 41 位字符串,而 MySQL4.0 之前是 16 位。
host 可以是:
- 主机名或 IP 号,或“localhost”指出本地主机。
- 使用通配符字符“%”和“_”。“%”匹配任何主机名,空值等价于“%”。它们的含义与
LIKE操作符的模式匹配操作相同。如“%.mysql.com”匹配“mysql.com”域所有主机。
如果 host 有多个匹配,而服务器读入 user 表,会按 host 具体程度排序,这只会匹配最具体的 host。
host 的值为”*“或者空,表示所有外部 IP 都可以连接,但是不包括本地服务器 localhost。因此,如果要包括本地服务器,必须单独为 localhost 赋予权限。
SUPER、PROCESS、FILE权限都属于管理权限,因此不能指定某个数据库,ON后必须设置为*.*。USAGE权限只能由于数据库登录,不能执行任何操作。 -
直接操作权限表。如:
INSERT INTO db(host, db, user, select_priv, insert_priv, update_priv, delete_priv) VALUES('%', 'test1', 'z2', 'Y', 'Y', 'Y', 'Y'); FLUSH PRIVILEGES;
可以通过SHOW GRANTS FOR user@host;查看权限(host可以不写,默认为%)。MySQL5.0 以后的版本,也可以利用新增的 information_schema 数据库进行权限的查看,如:
USE information_schema;
SELECT * FROM SCHEMA_PRIVILEGES WHERE grantee="'z1'@'localhost'";
更改权限可以使用GRANT、REVOKE语句或者更改权限表。REVOKE语法如下:
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]]...
ON [object_type] {tbl_name | * | *.* | db_name.*}
FROM user_identifier [, user_identifier]...
REVOKE ALL PRIVILEGES, GRANT OPTION FROM user_identifier [, user_identifier]...
USAGE权限不能被回收,即REVOKE用户并不能删除用户。删除账号需要使用DROP USER user [, user]...或者修改权限表。
修改密码的方式:
-
使用 mysqladmin。
mysqladmin -u user_name -h host_name password "newpwd" -
执行
SET PASSWORD语句。SET PASSWORD FOR user_identifier = PASSWORD('newpwd');更改自己的密码可以省略
FOR自己使用SET PASSWORD = PASSWORD('newpwd');。 -
在全局级别使用
GRANT USAGE语句而不影响账户权限。GRANT USAGE ON *.* TO user_identifier IDENTIFIED BY 'newpwd'; -
直接修改 user 表。
UPDATE user SET Password = PASSWORD('newpwd') WHERE Host = 'host' AND User = 'user_name'; FLUSH PRIVILEGES;
2.12.2.MySQL 安全问题
OS 相关:
-
严格控制 OS 账号和权限。比如:
- 锁定 mysql 用户。
- 其他任何用户都采取独立的账号登录,管理员通过 mysql 专有用户管理 MySQL,或者通过 root su 到 mysql 用户下进行管理。
- mysql 用户目录下,除了数据文件目录,其他文件和目录属主都改为 root。
-
尽量避免以 root 权限运行 MySQL。如果使用 root 用户启动数据库,则任何具有
FILE权限的用户都可以读写 root 用户的文件,这样会给系统造成严重的安全隐患。而使用 mysql 用户启动数据库时,可以防止任何具有FILE权限的用户能够用 root 创建文件。 -
防止 DNS 欺骗。host 可以指定域名,如果域名对应 IP 被恶意修改,可能导致安全隐患。
数据库相关:
-
删除匿名账号。某些版本 MySQL 安装后会自动安装空账号,此账号具有对 test 数据库的全部权限。而普通用户如果使用该数据库,如创建一个大表占用大量磁盘空间,将给系统造成安全隐患。建议删除空账号,或者对此账号添加密码。
-
给 root 账号设置口令。MySQL 安装完毕后,root 口令默认为空,需要马上修改。
-
设置安全密码。
-
只授予账号必须的权限。
-
除 root 外,任何用户不应有 mysql 库 user 表的存取权限。
-
不要把
FILE、PROCESS或SUPER权限授予管理员以外的账号。-
FILE权限主要作用:1.将数据库的信息通过SELECT ... INTO OUTFILE ...写到服务器上有写权限的目录下,作为文本格式存放。具有权限的目录也就是启动 MySQL 时的用户权限目录。2.可以将有读权限的文本文件通过LOAD DATA INFILE ...命令写入数据库表,如果这些表中存放了很重要的信息,将对系统造成很大的安全隐患。 -
PROCESS权限能被用来执行SHOW PROCESSLIST;命令,查看当前所有用户执行的查询的明文文本,包括设定或改变密码的查询。在默认情况下,每个用户都可以执行SHOW PROCESSLIST;命令,但是只能查询本用户的进程。因此,对PROCESS权限管理不当,有可能会使得普通用户能够看到管理员执行的命令。 -
SUPER权限能执行 kill 命令,终止其他用户进程。如:SHOW PROCESSLIST; # Id User Host db Command Time State Info # 51 root localhost mysql Query 157 Locked SET PASSWORD = PASSWORD('123') KILL 51;
-
-
LOAD DATA LOCAL带来的安全问题。LOAD DATA默认读的是服务器上的文件,但是加上LOCAL参数后,就可以将本地具有访问权限的文件加载到数据库中。这在带来方便的同时,也带来了以下安全问题:- 可以任意加载本地文件到数据库。
- 在 Web 环境中,客户从 Web 服务器连接,用户可以使用
LOAD DATA LOCAL语句来读取 Web 服务器进程有读访问权限的任何文件(假定用户可以运行 SQL 服务器的任何命令)。在这种环境中,MySQL 服务器的客户实际上是 Web 服务器,而不是连接 Web 服务器的用户运行的程序。
解决方法是,可以用
--local-infile=0选项启动 mysqld 从服务器端禁用所有LOAD DATA LOCAL命令。对于 mysql 命令行客户端,可以通过指定--local-infile[=1]选项启用LOAD DATA LOCAL,或通过--local-infile=0选项禁用。类似地,对于 mysqlimport,-L/--local选项启用本地数据文件装载。 -
使用 MERGE 存储引擎潜藏的安全漏洞。比如用户创建一个包含 T 表的 MERGE 表后被收回对 T 的权限,但该用户依然能通过 MERGE 表访问 T 表。
-
DROP TABLE命令并不收回以前的相关访问权限。重新创建同名的表时,对此新表的权限会自动赋予进而产生权限外流。因此,删除表时同时注意取消用户在此表上的相应权限。 -
使用 SSL。在 MySQL 中,要想使用 SSL 进行安全传输,对于服务器需要添加
--ssl选项(不想使用 SSL 则将选项指定为--skip-ssl/--ssl=0)同时通过--ssl-ca=file_name、--ssl-cert=file_name、--ssl-key=file_name选项指定含可信 SSL CA 的清单的文件的路径、SSL 证书、SSL 密钥;对于客户端需要允许客户使用 SSL 连接服务器。如果编译的服务器或客户端不支持 SSL,则使用普通的未加密的连接。确保使用 SSL 连接的安全方式是,使用含
REQUIRE SSL子句的GRANT语句在服务器上创建一个账户,然后使用该账户来连接服务器,服务器和客户端均应启用 SSL 支持。如:GRANT SELECT ON *.* TO 'z4'@'localhost' IDENTIFIED BY '123' REQUIRE SSL; -
如果可能,给所用用户加上访问 IP 限制。
-
REVOKE命令的漏洞。在一个数据库上多次赋予权限,权限会自动合并。但是在多个数据库上多次赋予权限,每个数据库上都会认为是单独的一组权限,必须在此数据库上用REVOKE命令来单独进行权限收回,而REVOKE ALL PRIVILEGES ON *.*并不会替用户自动完成这个各种。
其他安全设置选项:
-
old-passwords。当 4.1 以前的客户端需要连接 4.1 以后的服务器时候,由于无法理解新的密码算法,会导致无法认证。可以通过以下方法解决:
-
在服务器修改密码,使用旧密码格式:
SET PASSWORD FOR 'user'@'host' = OLD_PASSWORD('pwd'); -
在 my.cnf 的[mysqld]中增加
old-passwords参数并重启服务器,这样新的数据库连接成功之后做的SET PASSWORD、GRANT、PASSWORD()操作后,生成的新密码全部变成旧的密码格式。
-
-
safe-user-create。使用
--safe-user-create参数启动 MySQL 时,用户没有 user 表的INSERT权限时,无法使用GRANT语句创建新用户。 -
secure-auth。此参数会让 MySQL4.1 前客户端无法进行用户验证,即使使用 old-passwords 参数。
-
skip-grant-tables。此参数会导致服务器根本不使用权限系统,直到执行
mysqladmin flush-privileges/mysqladmin reload命令,或FLUSH PRIVILEGES;语句。 -
skip-network。此参数使得在网络上不允许 TCP/IP 连接,所有到数据库的连接必须经由命名管道、共享内存或 UNIX 套接字文件进行。这个选项适合应用和数据库共用一台服务器的情况,其他客户端将无法通过网络远程访问数据库。
-
skip-show-database。此参数使得只允许有
SHOW DATABASES权限的用户执行SHOW DATABASES语句。不使用该选项,允许所有用户执行SHOW DATABASES,但只显示用户有SHOW DATABASES权限或部分数据库权限的数据库名。
2.13.MySQL 复制
MySQL3.23 版本开始提供复制的功能。复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从服务器上,然后在从服务器上对这些日志重新执行(也叫重做),从而使得从服务器和主服务器的数据保持同步。 MySQL 支持一台主服务器同时向多台从服务器进行复制,从服务器同时也可以作为其他服务器的主服务器,实现链状的复制。
MySQL 复制的优点:
- 如果主服务器出现问题,可以快速切换到从服务器提供服务。
- 可以在从服务器上执行查询操作,降低主服务器的访问压力。
- 可以在从服务器上执行备份,以避免备份期间影响主服务器的服务。
由于 MySQL 实现的是异步的复制,所以主从服务器之间存在一定的差距,在从服务器上进行的查询操作需要考虑到这些数据的差异,一般只有更新不频繁的数据或者对实时性要求不高的数据可以通过从服务器查询,实时性要求高的数据仍然需要从主数据库获得。
2.13.1.安装配置
复制配置步骤:
-
确保主从服务器上安装了相同版本的数据库。
-
在主服务器上,设置一个复制使用的账户,并授予
REPLICATION SLAVE权限。 -
修改主数据库服务器的配置文件 my.cnf,开启 BINLOG,并设置 server-id 的值。如:
[mysqld] log-bin = /home/mysql/log/mysql-bin.log server-id = 1 -
在主服务器上,设置读锁定有效,这个操作是为了确保没有数据库操作,以便获得一个一致性的快照:
FLUSH TABLES WITH READ LOCK; -
然后得到主服务器上当前的二进制日志名和偏移量值。这个操作的目的是为了在从数据库启动以后,从这个点开始进行数据的恢复。
SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000039 | 102 | | | +------------------+----------+--------------+------------------+ -
现在主数据库服务器已经停止了更新操作,需要生成主数据库的备份,可以通过 OS 上 cp 主数据库数据文件到从数据库上,也可以是用 mysqldump、ibbackup 工具等进行数据库备份。
-
主数据库的备份完毕后,主数据库可以恢复写操作,剩下的操作只需要在从服务器上执行。
UNLOCK TABLES; -
将主数据库的一致性备份恢复到从数据库上。
-
修改从数据库的配置文件 my.cnf,增加 server-id 参数。注意 server-id 的值必须是唯一的,不能和主数据库和其他从数据库的配置相同。
[mysqld] server-id = 2 -
在从服务器上,使用
--skip-slave-start选项启动从数据库,这样不会立即启动从数据库服务上的复制进程,方便我们对从数据库的服务进行进一步的配置。./bin/mysqld_safe --skip-slave-start & -
对从数据库服务器做相应设置,指定复制使用的用户,主数据库服务器的 IP、端口以及开始执行复制的日志文件和位置等,具体语法如下:
CHANGE MASTER TO MASTER_HOST='master_host_name', MASTER_USER='replication_user_name', MASTER_PASSWORD='replication_password', MASTER_LOG_FILE='recorded_log_file_name', MASTER_LOG_POS=recorded_log_position; -
在从服务器上启动 slave 线程:
START SLAVE; -
这时 slave 上执行
SHOW PROCESSLIST;命令查看是否具有接受并执行相应日志的线程。 -
也可以测试复制服务的正确性,在主数据库上执行一个更新操作,观察是否在从数据库上同步。
-
在从数据库上检查数据是否同步。
2.13.2.主要复制启动选项
除了上述的 MASTER_HOST、MASTER_USER、MASTER_PASSWORD、MASTER_LOG_FILE、MASTER_LOG_POS,还有以下从服务器启动参数:
-
log-slave-updates:用来配置从服务器上的更新操作是否写二进制日志,默认是不打开的。但是如果这个从服务器同时也要作为其他服务器的主服务器,搭建一个链式的复制, 那么就需要打开这个选项,通常和
--logs-bin参数一起使用。 -
master-connect-retry:用来设置在和主服务器的连接丢失的时候,重试的时间间隔,默认 60 秒,即每 60 秒重试一次。
-
read-only:用来设置从服务器只能接受超级用户的更新操作,从而限制应用程序错误的对从服务器的更新操作。
-
可以使用 replicate-do-db、replicate-do-table、replicate-ignore-db、replicate-ignore-table 或 replicate-wild-do-table 来指定从主数据库复制到从数据库的数据库或者表。
-
slave-skip-errors。在复制过程中,由于各种原因从服务器可能会遇到执行 BINLOG 中的 SQL 出错的情况(比如主键冲突),默认情况下从服务器将会停止复制进程不再进行同步,等待用户介入处理。此参数的作用就是用来定义复制过程中从服务器可以自动跳过的错误号,这样当复制过程中遇到定义中的错误号时, 便可以自动跳过,直接执行后面的 SQL 语句。此参数可以定义多个错误号(之间用逗号),或者通过定义成 all 跳过全部的错误。
如果从数据库主要是作为主数据库的备份,那么就不应该使用这个启动参数,设置不当,很可能造成主从数据库的数据不同步。
2.13.3.日常管理维护
检查从服务器的复制状态:
SHOW SLAVE STATUS \G;
在显示的这些信息中,我们主要关心以下这两个进程状态是否是 yes:
- Slave_IO_Running:此进程负责从服务器从主服务器上读取 BINLOG 日志,并写入从服务器上的中继日志中。
- Slave_SQL_Running:此进程负责读取并且执行中继日志中的 BINLOG 日志。
只要其中有一个进程的状态是 no,则表示复制进程停止,错误原因可以从 Last_Errno 字段的值中看到。除了查看上面的信息,用户还可以通过这个命令了解从服务器的配置情况以及当前和主服务器的同步情况。
在某些繁忙的 OLTP 系统上,由于主服务器更新频繁,而从服务器由于各种原因导致更新速度较慢,从而使得主从服务器之间的数据差距越来越大,最终对某些应用产生影响。在这种情况下,我们就需要定期地进行主从服务器的数据同步,使得主从数据差距能够减到最小。常用的方法是:在负载较低的时候暂时阻塞主数据库的更新,强制主从数据库更新同步。具体操作步骤如下:
-
在主服务器上,阻塞主数据库的所有更新操作,并查看二进制日志名和偏移量值:
FLUSH TABLES WITH READ LOCK; SHOW MASTER STATUS; -
在从服务器上执行下面语句,其中
MASTER_POS_WAIT()函数的参数是前面步骤中得到的复制坐标值。如:SELECT MASTER_POS_WAIT('mysql-bin.000039', '974');这个
SELECT语句会阻塞直到从服务器达到指定的日志文件和偏移量后返回 0,则从服务器与主服务器同步(返回 -1,则表示超时退出)。 -
在主服务器上允许主服务器重新开始处理更新:
UNLOCK TABLES;
在某些情况下,会出现从服务器更新失败。这时,首先需要确定是否是从服务器的表与主服务器的不同造成的。如果是表结构不同导致的,则修改从服务器的表与主服务器的相同,然后重新运行START SLAVE语句;如果不是表结构不同导致的更新失败,则需要确认手动更新是否安全,然后忽视来自主服务器的更新失败的语句,跳过来自主服务器的语句的命令为SET GLOBAL SQL_SLAVE_SKIP_COUNTER = n,如果来自主服务器的更新语句不使用AUTO_INCREMENT或LAST_INSERT_ID(),n 值应为 1,否则值应为 2,原因是使用AUTO_INCREMENT或LAST_INSERT_ID()的语句需要从二进制日志中取两个事件。
如果应用中使用大的 BLOG 列或者长字符串,那么在从服务器上恢复的时候,可能会出现 log event entry exceeded max_allowed_packet 错误,这是因为含有大文本的记录无法通过网络进行传输导致。解决的办法就是在主从服务器上增加max_allowed_packet参数的大小,这个参数的默认值为 1MB,可以按照实际需要进行修改。如:
SET @@global.max_allowed_packet=16777216;
同时在 my.cnf 中设置max_allowed_packet = 16M,保证下次数据库重新启动后参数继续有效。
在某些情况下,可能会需要使用多主复制(多台主服务器对一台从服务器)。这时如果主服务器的表采用自动增长变量,那么复制到从服务器的同一张表后很可能会引起主键冲突,因为系统参数 auto_increment_increment 和 auto_increment_offset 默认值为 1。这时就需要定制 auto_increment_increment 和auto_increment_offset 的设置,保证多主之间复制到从数据库不会有重复冲突。如两个主服务器上 auto_increment_increment、auto_increment_offset 分别设置为 2、1 和 2、0。
查看从服务器的复制进度如何,可通过SHOW PROCESSLIST列表中的 Slave_SQL_Running 线程的 Time 值得到,它记录了从服务器当前执行的 SQL 时间戳与系统时间之间的差距,单位是秒。
2.13.4.切换主从服务器
假如从服务器 S1、S2 的主服务器 M 宕机,需要修改 S1 作为 S2 的主服务器,就需要切换主从服务器。步骤如下:
-
首先要确保所有的从数据库都已经执行了 relay log 中的全部更新,在每个从服务器上,执行
STOP SLAVE IO_THREAD,然后检查SHOW PROCESSLIST的输出,直到看到状态是 Has read all relay log,表示更新都执行完毕。STOP SLAVE IO_THREAD; SHOW PROCESSLIST \G; -
在从数据库 S1 上,执行
STOP SLAVE停止从服务,然后RESET MASTER重置成主数据库。STOP SLAVE; RESET MASTER; -
在 S2 上,执行
STOP SLAVE停止从服务,然后执行CHANGE MASTER TO MASTER_HOST = 'S1'重新设置主数据库,然后再执行START SLAVE启动复制。STOP SLAVE; CHANGE MASTER TO MASTER_HOST='192.168.1.101'; START SLAVE; -
通知所有的客户端将应用指向 S1,这样客户端发送的所有的更新语法写入到 S1 的二进制日志。
-
删除新的主数据库服务器上的 master.info 和 relay-log.info 文件,否则下次重启的时候还会按照从服务器启动。
-
最后,如果 M 服务器可以修复,则可以按照 S2 的方法配置成 S1 的从服务器。
上面测试的步骤是默认 S1 是打开 log-bin 选项的,这样重置成主数据库后可以将二进制日志传输到其他从服务器。其次,S1 上没有打开 log-slave-updates 参数,否则重置成主数据库后,可能会将已经执行过的二进制日志重复传输给 S2,导致 S2 的同步错误。
2.14.MySQL Cluster
MySQL4.1.x 版本开始推出 MySQL Cluster 功能。Cluster 中各节点的功能各不相同,有的用来存储数据(数据节点),有的用来存放表结构(SQL 节点),有的用来对其他节点进行管理(管理节点)。MySQL 使用 NDB 存储引擎来对数据节点的数据进行存储,以前版本的 NDB 存储引擎只支持基于内存的数据表,从 5.1 版本开始支持基于磁盘的数据表。
2.14.1.MySQL Cluster 架构
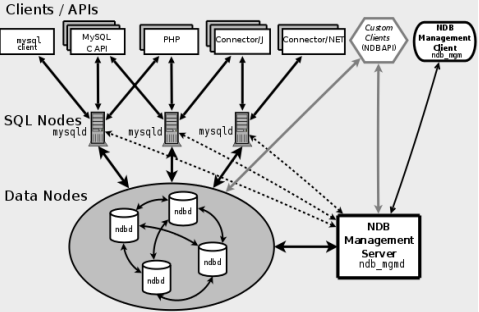
- 管理节点:用来对其他节点进行管理。实际操作中,是通过对一个叫作 config.ini 的配置文件进行维护而起到管理的作用。该文件可以用来配置有多少需要维护的副本、需要在每个数据节点上为数据和索引分配多少内存、数据节点的位置、在每个数据节点上保存数据的磁盘位置、SQL节点的位置等信息。管理节点只能有一个,配置要求不高。
- SQL 节点:可以理解为应用和数据节点之间的一个桥梁。应用不能直接访问数据节点,只能先访问 SQL 节点,然后 SQL 节点再去访问数据节点来返回数据。Cluster 中可以有多个 SQL 节点,通过每个 SQL 节点查询到的数据都是一致的,通常来说,SQL节点越多,分配到每个 SQL 节点的负载就越小,系统的整体性能就越好。
- 数据节点:用来存放 Cluster 里面的数据,可以有多个数据节点。每个数据节点可以有多个镜像节点。任何一个数据节点发生故障,只要它的镜像节点正常,Cluster 就可以正常运行。
MySQL Cluster 访问过程:前台应用利用一定的负载均衡算法将对数据库的访问分散到不同的 SQL 节点上,然后 SQL 节点对数据节点进行数据访问并从数据节点返回结果,最后 SQL 节点将收到的结果返给前台应用。而管理节点并不参与访问过程,它只用来对 SQL 节点和数据节点进行配置管理。
2.14.2.MySQL Cluster 配置
Server 包默认是不包括 Cluster 组件的,为了支持 Cluster 功能,还需要单独下载 Cluster 相关包。对于 SQL 节点和数据节点,除了必须下载的 Server 包外,还需要下载 Cluster storage engine 包。如果是管理节点,则不用下载 Server 包,但是需要下载 Client 包,此外还需要下载 Cluster storage engine management、Cluster storage engine basic tools 和 Cluster storage engine extra tools 3 个管理工具包。这 3 个工具包分别提供了 MySQL Cluster 管理服务器(ndb_mgmd)、客户端管理工具(最重要的是 ndb_mgm)、额外的集群测试和监控工具。其中,前两个包是必须的,最后一个包没有也可以,不会影响 Cluster 的正常运行和管理。
管理节点配置:
mkdir /home/zzx2/mysql-cluster
cd /home/zzx2/mysql-cluster
vim config.ini
[NDBD DEFAULT]
NoOfReplicas=1 # 每个数据节点的镜像数量
DataMemory=500M # 每个数据节点中给数据分配的内存
IndexMemory=300M # 每个数据节点中给索引分配的内存
[TCP DEFAULT]
portnumber=2202 # 数据节点的默认连接端口
[NDB_MGMD]# 配置管理节点
id=1
hostname=192.168.7.187 # 管理节点 IP
datadir=/home/zzx2/mysql-cluster # 管理节点数据目录
[NDBD]
id=2
hostname =192.168.7.187
datadir =/home/zzx2/mysql/data
[NDBD]
id=3
hostname=192.168.7.55
datadir=/home/zzx2/mysql/data
[MYSQLD]
hostname=192.168.7.187
[MYSQLD]
hostname=192.168.7.55
[MYSQLD]# Options for mysqld process:
主要的 3 类节点组配置:
[NDB_MEMD]:表示管理节点的配置,只能有一个。[NDBD DEFAULT]:表示每个数据节点的默认配置,在每个节点的[NDBD]中不用再写这些选项。只能有一个。[NDBD]:表示每个数据节点的配置,可以有多个。[MYSQLD]:表示 SQL 节点的配置,可以有多个分别写上不同 SQL 节点的 IP 地址。也可以不用写 IP 地址,只保留一个空节点,表示任意一个 IP 地址都可以进行访问。 此节点的个数表明了可以用来连接数据节点的 SQL 节点总数。
每个节点都要有一个独立的 id 号,可以手工填写也可以不写,系统会按照配置文件的填写顺序自动分配。
SQL 节点和数据节点的配置:
对节点的配置文件(my.cnf)添加如下内容:
# Options for mysqld process:
[MYSQLD]
ndbcluster # 运行 NDB 存储引擎
ndb-connectstring=192.168.7.187 # 定位管理节点
# Options for ndbd process:
[MYSQL_CLUSTER]
ndb-connectstring=192.168.7.187 # 定位管理节点
SQL 节点和数据节点的不同之处在于数据节点只需要配置上述选项即可,SQL 节点还需要配置 MySQL 服务器的其他选项。
2.14.3.开始使用 Cluster
Cluster 需要各个节点都进行启动后才可以运行,节点的启动顺序为管理节点、数据节点、SQL 节点。如:
-
在管理节点服务器上启动管理节点:
ndb_mgmd -f ./config.ini # 或者 --config-file=./config.ini启动完后可以通过
ps命令查看是否启动进程成功。 -
在每台数据节点服务器上(本例为 192.168.7.55 和 192.168.7.187),运行下述命令启动 ndbd 进程:
ndbd --initial-ndb-connectstring=192.168.7.187:1186 ps -ef # 查看进程是否启动成功ndbd 进程是使用 NDB 存储引擎处理表中数据的进程。通过该进程,存储节点能够实现分布式事务管理、节点恢复、在线备份等相关的任务。
仅应在首次启动 ndbd 时,或在备份/恢复或配置变化后重启 ndbd 时使用
--initial参数,这很重要。原因在于,该参数会使节点删除由早期 ndbd 实例创建的、用于恢复的任 何文件,包括恢复用日志文件。 -
依次启动 SQL 节点上的 MySQL 服务。
# node1(192.168.7.187) ./bin/mysqld_safe &# node1(192.168.7.55) ./bin/mysqld_safe & -
节点全部成功启动后,用 ndb_mgm 工具的 show 命令查看集群状态:
ndb_mgm ndb_mgm> show;
如果要使用 Cluster,则表的存储引擎必须为 NDB,其他类型存储引擎的数据将不会保存到数据节点中。
配置文件中[NDBD DEFAULT]组中的NoOfReplicas参数,如果这个参数等于 1,表示只有一份数据,但是分成 n 块分别存储在 n 个数据节点上;如果等于 2,则表示数据被分成 n/2 块,每块数据都有两个备份。
Cluster 的关闭,只需执行:
ndb_mgm -e shutdown
也可以用 ndb_mgm 工具进入管理界面后,使用shutdown命令关闭。需要注意的是,集群关闭后,SQL 节点的 MySQL 服务并不会停止。
2.14.4.维护 Cluster
可以使用 mysqldump 工具对 Cluster 进行逻辑备份,其他存储引擎的备份方法一样,唯一的区别是在任意一个 SQL 节点上都可以执行。
对于 Cluster 的物理备份,以上述 Cluster 为例,启动管理服务器 (ndb_mgm),并执行start backup命令启动备份:
ndb_mgm
ndb_mgm> start backup;
在备份日志中,需要注意 Backup 1 ,它表示该备份的唯一 ID,如果做第二次备份,备份 ID 会变成 Backup 2 。当日志中显示 Backup 1 started from node 1 completed 的时候,本次备份结束 。备份的数据保存在每个数据节点下, 具体备份路径是:$MYSQL_HOME/data/BACKUP/BACKUP-备份 ID。
对于大数据量的备份,MySQL Cluster 还提供了几个备份的参数可供调整,这些参数需要写在 config.ini 的[NDBD DEFAULT]或者[NDBD]组中,对各参数的具体说明如下:
BackupDataBufferSize:将数据写入磁盘之前用于对数据进行缓冲处理的内存量。BackupLogBufferSize: 将日志记录写入磁盘之前用于对其进行缓冲处理的内存量。BackupMemory:在数据库节点中为备份分配的总内存。它应是分配给备份数据缓冲的内存和分配给备份日志缓冲的内存之和。BackupWriteSize:每次写入磁盘的块大小,适用于备份数据缓冲和备份日志缓冲。
对于用start backup进行备份的 Cluster,必须使用 ndb_restore 工具进行数据恢复。如:
ndb_restore -b 3 -n 2 -c host=192.168.7.187:1187 -m -r /home/zzx2/data/BACKUP/BACKUP-3
各参数含义如下:

第一个节点恢复,需要添加参数-m来恢复表定义,这样在其他节点恢复的时候就不需要再加此参数,否则会报错。
MySQL Cluster 提供了两种日志,分别是集群日志和节点日志。前者记录了所有 Cluster 节点生成的日志,后者仅仅记录了数据节点的本地事件。在大多数情况下,我们都推荐使用集群日志,因为它在一个地方记录了所有节点的数据,更便于进行管理。节点日志一般只在开发过程中使用,或者用来调试程序代码。
clusterlog 一般记录在和配置文件(config.ini)同一个目录下,文件名格式为ndb_<nodeid>_cluster.log,其中 nodeid 为管理节点号。
可以使用 ndb_mgm 客户端管理程序打开/关闭日志,相关操作:
ndb_mgm
ndb_mgm> clusterlog info
ndb_mgm> clusterlog off
ndb_mgm> clusterlog on
Cluster 中的日志有很多类型,我们可以按照如下类别进行过滤,使得日志只记录我们关心的东西:
-
Category(类别):可以是下述值之一,STARTUP、SHUTDOWN、STATISTICS、CHECKPOINT、NODERESTART、CONNECTION、ERROR 或 INFO。
-
Priority(优先级):由从 1~15 的数字表示,“1”表示“最重要”,而“15”表示“最不重要”。每种 Category 都有一个默认的优先级阈值。优先级阈值以下的日志将被记录,反之优先级阈值以上的日志不会被记录。
![]()
-
Severity Level(严重级别):可以是下述值之一,ALERT、CRITICAL、ERROR、WARNING、 INFO 或 DEBUG。
![]()


这 3 种分类让用户可以从 3 个不同的角度来对日志进行过滤。过滤的方法可以用 ndb_mgm 工具来完成,具体设置方法如下:
node_id CLUSTERLOG category=threshold:用小于或等于 threshold 的优先级将 category 事件记录到 Cluster 日志。node_id 可以为 ALL(所有节点)或者只指定某个节点。CLUSTERLOG TOGGLE severity_level:使得指定的 severity_level 打开或者关闭。
2.15.MySQL 常见问题和应用技巧
-
忘记 MySQL 的 root 密码,需要通过以下步骤修改 root 密码:
-
登录到数据库所在服务器,手工 kill 掉 MySQL 进程:
kill 'cat /mysql-data-directory/hostname.pid'其中,
/mysql-data-directory/hostname.pid指的是 MySQL 数据目录下的 .pid 文件,它记录了 MySQL 服务的进程号。 -
使用
--skip-grant-tables选项重启 MySQL 服务:./bin/mysql_safe --skip-grant-tables --user=zzx & -
用空密码的 root 用户连接到 MySQL,并且更改 root 口令:
mysql -u rootSET PASSWORD = PASSWORD('newpwd'); # ERROR UPDATE user SET password = PASSWORD('newpwd') WHERE user = 'root' AND host = 'localhost';由于使用了
--skip-grant-tables选项启动,使用SET PASSWORD命令更改密码失败,直接更新 user 表的 password 字段后更改密码成功。 -
刷新权限表:
FLUSH PRIVILEGES; -
重新登录 MySQL。
-
-
修复 MyISAM 表损坏。
一张损坏的表的症状通常是查询意外中断并且能看到下述错误:
- “tbl_name.frm”被锁定不能更改。
- 不能找到文件“tbl_name.MYI”(Errcode:nnn)。
- 文件意外结束。
- 记录文件被毁坏。
- 从表处理器得到错误 nnn。
解决方法有以下两种:
-
使用 MySQL 自带的专门用来修复 MyISAM 表的工具 myisamchk:
myisamchk -r tbl_name # -r 指的是 recover myisamchk -o tbl_name # -o 指的是 --safe-recover,使用 -r 不行则使用 -o -
使用
CHECK TABLE和REPAIR TABLE。
-
MyISAM 表超过 4G 无法访问的问题。
MySQL5.0 版本之前,MyISAM 存储引擎默认的表大小只支持到 4GB,可以用以下命令来查看:
myisamchk -dv t1可以用下面命令对数据文件的最大 size 进行扩充:
ALTER TABLE tbl_name MAX_ROWS = 1000000000 AVG_ROW_LENGTH = 15000; -
数据目录磁盘空间不足的问题。
对于 MyISAM 表,建表时通过
DATA DIRECTOREY和DATA DIRECTORY分别指定数据目录和索引目录存储到不同的磁盘空间。但如果表已经创建,使用过程中无法对这些路径再次变更(如ALTER TABLE tbl_name INDEX DIRECTORY = 'newdirectory';),这时可以将源数据、索引文件 mv 到其他位置,使用符号连接原位置到新位置。对于 InnoDB 表,数据文件和索引文件是存放在一起的无法将它们进行分离。当磁盘空间出现不足时,可以增加一个新的数据文件,这个文件放在有充足空间的磁盘上。具体实现方法是在参数
innodb_data_file_path中增加此文件,路径写为新磁盘的绝对路径。例如,如果/home下空间不足,希望在/home1下新增加一个可自动扩充数据文件, 那么参数就可以这么写:innodb_data_file_path=/home/ibdata1:2000M;/home1/ibdata2:2000M:autoextend -
DNS 反向解析的问题。
在 MySQL5.0 以前的版本中执行
SHOW PROCESSLIST命令的时候,有时会出现很多进程。MySQL 默认情况下,对于远程连接过来的 IP 地址,会进行域名的逆向解析,如果系统的 hosts 文件中没有与之对应的域名,MySQL 就会将此连接认为是无效用户,所以在进程中出现“unauthenticated user”并导致进程阻塞。解决的方法很简单,在启动的时候加上--skip-name-resolve选项,则 MySQL 就可以跳过域名解析过程,避免上述问题。在 MySQL5.0 以后版本,默认都会跳过域名逆向解析。 -
mysql.sock 丢失后如何连接数据库。
在 MySQL 服务器本机上连接数据库时,经常会出现 mysql.sock 不存在,导致无法连接的问题。这是因为如果指定 localhost 作为一个主机名,则 mysqladmin 默认使用 UNIX 套接字文件连接,而不是 TCP/IP。而这个套接字文件(一般命名为 mysql.sock)经常会因为各种原因而被删除。从 MySQL4.1 开始,通过
--protocol= {TCP | SOCKET | PIPE | MEMORY}选项,用户可以显式地指定连接协议。 -
同一台服务器运行多个 MySQL 数据库。略
-
客户端怎么访问内网数据库。略
第三部分 Redis[3]
3.1.基本指令示例[4]
SET name "meyok"
GET name
DEL name
HMSET meyok name "meyok"
HGET meyok name
DEL meyok
LPUSH name_list meyok
LPUSH name_list yi
LPUSH name_list yang
LRANGE name_list 0 10
DEL name_list
SADD id 20200909027
SMEMEBERS id
DEL id
ZADD id 0 2020090909027
ZRANGEBYSCORE id 0 10
redis-cli -h 127.0.0.1 -p 6379 -a "mypass"
PING
键:
DEL key # 删除 key
DUMP key # 序列化给定 key,返回序列化值
EXISTS key # 检查 key 是否存在
EXPIRE key seconds # 为 key 设置过期时间
EXPIRE key timestamp
EXPIRE key milliseconds
EXPIRE key milliseconds-timestamp
KEYS pattern # 查找符合 pattern 的所有 key
MOVE key db # 将当前数据库的 key 移动到给定数据库 db 中
PERSIST key # 移除 key 过期时间,key 将持久保持
PTTL key # 返回 key 剩余过期毫秒时间
TTL key # 返回 key 剩余过期秒时间
RANDOMKEY # 从当前数据库随机返回一个 key
RENAME key newkey # 修改 key 名
RENAMENX key newkey # newkey 不存在时,修改 key 名
SCAN cursor [MATCH pattern] [COUNT count] # 迭代数据库中的数据库键
TYPE key # 返回 key 所存储的值的类型
字符串:
SET key value # 设置 key 的值
GET key # 获取 key 的值
GETRANGE key start end # 获取 key 中字符串值的子字符串
GETSET key value # 给 key 设置新值并返回旧值
GETBIT key offset # 对 key 所储存的字符串值,获取指定偏移量上的位
MGET key1 [key2 ...] # 获取所有给定 key 的值
SETBIT key offset value # 对 key 所储存的字符串值,设置或清除指定偏移量上的位
SETEX key seconds value
SETNX key value
SETRANGE key offset value # 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始
STRLEN key
MSET key value [key value ...]
MSETNX key value [key value ...]
PSETEX key milliseconds value
INCR key # 将 key 中储存的数字值增一
INCRBY key increment
INCRBYFLOAT key increment
DECR key
DECRBY key decrement
APPEND key value # 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾
哈希:
HDEL key field1 [field2 ...]
HEXISTS key field
HGET key field
HGETALL key
HINCRBY key field increment
HINCRBYFLOAT key field increment
HKEYS key
HLEN key
HMGET key field1 [field2 ...]
HMSET key field1 value1 [field2 value2 ...]
HSET key field value
HSETNX key field value
HVALS key # 获取哈希表中所有值
HSCAN key cursor [MATCH pattern] [COUNT count] # 迭代哈希表中的键值对
列表:
BLPOP key1 [key2 ...] timeout # 移除并获取列表第一个元素,没有则会阻塞列表直到超时或可弹出元素为止
BRPOP key1 [key2 ...] timeout
BRPOPLPUSH source destination timeout # 从一个列表中弹出值返回,并放到另一个列表中,阻塞……
LINDEX key index # 通过索引获取列表中元素
LINSERT key BEFORE|AFTER pivot value # 在列表的元素前或/后插入元素
LLEN key
LPOP key
LPUSH key value1 [value2 ...]
LPUSHX key value # 将一个值插入到已存在的列表头部
LRANGE key start stop
LREM key count value # 移除列表中元素
LSET key index value
LTRIM key start stop # 移除指定范围外的元素
RPOP key
RPOPLPUSH source destination
RPUSH key value1 [value2 ...]
RPUSHX key value
集合:
SADD key member1 [member2 ...]
SCARD key # 获取集合的成员数
SDIFF key1 [key2]
SDIFFSTORE destination key1 [key2]
SINTER key1 [key2 ...]
SINTERSOTRE destination key1 [key2]
SISMEMBER key member # 判断 member 是否是集合 key 成员
SMEMBERS key # 返回集合中所有成员
SMOVE source destination member
SPOP key # 移除并返回集合 key 中随机一个元素
SRANDMEMBER key [count] # 返回集合中一个或多个随机数
SREM key member1 [member2 ...]
SUNION key1 [key2 ...]
SUNIONSTORE destination key1 [key2]
SSCAN key cursor [MATCH pattern] [COUNT count] # 迭代集合中的元素
有序集合:
ZADD key score1 member1 [score2 member2] # 向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZCARD key
ZCOUNT key min max
ZINCRBY key increment member # 有序集合中对指定成员的分数加上增量 increment
ZINTERSTORE destination numkeys key [key ...] # 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中,numkeys 表示 key 数量
ZLEXCOUNT key min max
ZRANGE key start stop [WITHSCORES] # 通过索引区间返回有序集合指定区间内的成员
ZRANGEBYLEX key min max [LIMIT offset count] # 通过字典区间返回有序集合的成员
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] # 通过分数返回有序集合指定区间内的成员
ZEANK key member # 返回有序集合中指定成员的索引
ZREM key member [member ...]
ZREMRANGEBYLEX key min max # 移除有序集合中给定的字典区间的所有成员
ZREMRANGEBYRANK key start stop # 移除有序集合中给定的排名区间的所有成员
ZREMRANGEBYSCORE key min max # 移除有序集合中给定的分数区间的所有成员
ZREVRANGE key start stop [WITHSCORES] # 返回有序集中指定区间内的成员,通过索引,分数从高到低
ZREVRANGEBYSCORE key max min [WITHSCORES] # 返回有序集中指定分数区间内的成员,分数从高到低排序
ZREVRANK key member # 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
ZSCORE key member # 返回有序集中,成员的分数值
ZUNIONSTORE destination numkeys key [key ...] # 计算给定的一个或多个有序集的并集,并存储在新的 key 中
ZSCAN key cursor [MATCH pattern] [COUNT count] # 迭代有序集合中的元素(包括元素成员和元素分值)
HyperLogLog:
PFADD key element [element ...] # 添加指定元素到 HyperLogLog 中
PFCOUNT key [key ...] # 返回给定 HyperLogLog 的基数估算值
PFMERGE destkey sourcekey [sourcekey ...] # 将多个 HyperLogLog 合并为一个 HyperLogLog
发布订阅:
PSUBSCRIB pattern [pattern ...] # 订阅一个或多个符合给定模式的频道
PUBSUB subcommand [argument [argument ...]] # 查看订阅与发布系统状态
PUBLISH channel message # 将信息发送到指定的频道
PUNSUBSCRIBE [pattern [pattern ...]] # 退订所有给定模式的频道
SUBSCRIBE channel [channel ...] # 订阅给定的一个或多个频道的信息
UNSUBSCRIBE [channel [channel ...]] # 指退订给定的频道
事务:
DISCARD # 取消事务,放弃执行事务块内的所有命令
EXEC # 执行所有事务块内的命令
MULTI # 标记一个事务块的开始
UNWATCH # 取消 WATCH 命令对所有 key 的监视
WATCH key [key ...] # 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
脚本:
EVAL script numkeys key [key ...] arg [arg ...] # 执行 Lua 脚本
EVALSHA sha1 numkeys key [key ...] arg [arg ...] # 执行 Lua 脚本
SCRIPT EXISTS script [script ...] # 查看指定的脚本是否已经被保存在缓存当中
SCRIPT FLUSH # 从脚本缓存中移除所有脚本
SCRIPT KILL # 杀死当前正在运行的 Lua 脚本
SCRIPT LOAD script # 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本
连接:
AUTH password # 验证密码是否正确
ECHO message # 打印字符串
PING # 查看服务是否运行
QUIT # 关闭当前连接
SELECT index # 切换到指定的数据库
服务器:
BGREWRITEAOF # 异步执行一个 AOF(AppendOnly File) 文件重写操作
BGSAVE # 在后台异步保存当前数据库的数据到磁盘
CLIENT KILL [ip:port] [ID client-id] # 关闭客户端连接
CLIENT LIST # 获取连接到服务器的客户端连接列表
CLIENT GETNAME # 获取连接的名称
CLIENT PAUSE timeout # 在指定时间内终止运行来自客户端的命令
CLIENT SETNAME connection-name # 设置当前连接的名称
CLUSTER SLOTS # 获取集群节点的映射数组
COMMAND # 获取 Redis 命令详情数组
COMMAND COUNT # 获取 Redis 命令总数
COMMAND GETKEYS # 获取给定命令的所有键
TIME # 返回当前服务器时间
COMMAND INFO command-name [command-name ...] # 获取指定 Redis 命令描述的数组
CONFIG GET parameter # 获取指定配置参数的值
CONFIG REWRITE # 对启动 Redis 服务器时所指定的 redis.conf 配置文件进行改写
CONFIG SET parameter value # 修改 redis 配置参数,无需重启
CONFIG RESETSTAT # 重置 INFO 命令中的某些统计数据
DBSIZE # 返回当前数据库的 key 的数量
DEBUG OBJECT key # 获取 key 的调试信息
DEBUG SEGFAULT # 让 Redis 服务崩溃
FLUSHALL # 删除所有数据库的所有 key
FLUSHDB # 删除当前数据库的所有 key
INFO [section] # 获取 Redis 服务器的各种信息和统计数值
LASTSAVE # 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示
MONITOR # 实时打印出 Redis 服务器接收到的命令,调试用
ROLE # 返回主从实例所属的角色
SAVE # 同步保存数据到硬盘
SHUTDOWN [NOSAVE] [SAVE] # 异步保存数据到硬盘,并关闭服务器
SLAVEOF host port # 将当前服务器转变为指定服务器的从属服务器
SLOWLOG subcommand [argument] # 管理 redis 的慢日志
SYNC # 用于复制功能的内部命令
3.2.数据结构
3.2.1.底层数据结构
-
SDS
SDS(Simple Dynamic String,简单动态字符串)的 C 实现如下:
// sds.h struct sdshdr { int len; // 记录 buf 数组中已使用字节的数量,等于 SDS 所保存字符串的长度 int free; // 记录 buf 数组中未使用字节的数量 char buf[]; // 字节数组,用于保存字符串,遵循 C 字符串以空字符结尾的惯例 }Redis 使用 SDS 作为默认字符串表示。SDS 在 Redis 中被使用在:可以被修改的字符串值;缓冲区(AOF 缓冲区,客户端状态中的输入缓冲区等)等。
Redis 中,C 字符串指挥作为字符串字面量用在一些无须对字符串值进行修改的地方。如打印日志:
redisLog(REDIS_WARNING, "Redis is now ready to xit, bye bye ...");SDS 比 C 字符串更适用于 Redis 的原因:
- SDS 获取字符串长度只有 $ O(1) $ 时间复杂度。C 字符串获取长度(如 strlen)会遍历。
- 杜绝缓冲区溢出。SDS API 对 SDS 修改时会检查 SDS 空间是否满足。C 字符串的函数(如 strcat)会假设有足够空间。
- 减少修改字符串时带来的内存重分配次数。SDS 实现了空间预分配和惰性空间释放两种优化策略:
- 空间预分配:SDS 需要进行空间扩展时,还会为 SDS 分配额外的未使用空间。如果修改后 SDS 长度小于 1 MB,free 属性分配 len 属性相同长度,否则 free 分配 1 MB 长度。
- 惰性空间释放:SDS API 缩短 SDS 保存的字符串时,并不立即使用内存重分配来回收缩短后多出来的字节,而使用 free 属性将其记录等待将来使用。同时,SDS 也提供了相应的 API 在有需要时真正地释放 SDS 的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
- 二进制安全。所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设,数据在写入时是什么样的,它被读取时就是什么样。
- 兼容部分 C 字符串函数。
C 字符串 SDS 获取字符串长度的复杂度为 $ O(N) $ 获取字符串长度的复杂度为 $ O(1) $ API 是不安全的,可能会造成缓冲区溢出 API 是安全的,不会造成缓冲区溢出 修改字符串长度 N 次必然需要执行次内存重分配 修改字符串长度 N 次最多需要执行 N 次内存重分配 只能保存文本数据 可以保存文本或者二进制数据 可以使用所有 <string.h>库中的函数可以使用一部分 <string.h>库中的函数主要 SDS API:
函数 作用 时间复杂度 sdsnew 创建一个包含给定 C 字符串的 SDS $ O(N) $,N 为给定 C 字符的长度 sdsempty 创建一个不包含任何内容的空 SDS $ O(1) $ sdsfree 释放给定的 SDS $ O(N) $,N 为被释放 SDS 的长度 sdslen 返回 SDS 的已使用空间字节数 这个值可以通过读取 SDS 的 len 属性来直接获得,复杂度为 $ O(1) $ sdsavail 返回 SDS 的未使用空间字节数 这个值可以通过读取 SDS 的 free 属性来直接获得,复杂度为 $ O(1) $ sdsdup 创建一个给定 SDS 的副本 $ O(N) $,N 为给定 SDS 的长度 sdsclear 清空 SDS 保存的字符串内容 因为惰性空间释放策略,复杂度为 $ O(1) $ sdscat 将给定 C 字符串拼接到 SDS 字符的末尾 $ O(N) $,N 为被拼接 C 字符的长度 sdscatsds 将给定 SDS 字符串拼接到另一个 SDS 字符串的末尾 $ O(N) $,N 为被拼接 SDS 字符的长度 -
链表
链表以及链表节点的 C 实现如下:
// adlist.h typedef struct listNode { struct listNode * prev; // 前置节点 struct listNode * next; // 后置节点 void * value; // 节点值 } listNode; typedef struct list { listNode * head; // 表头节点 listNode * tail; // 表尾节点 unsigned long len; // 链表节点数 void* (*dup)(void* ptr); // 节点值复制函数 void (*free)(void* ptr); // 节点值释放函数 int (*match)(void* ptr, void* key); // 节点值对比函数 } list;链表在 Redis 中被使用在:列表键的底层实现之一;发布与订阅、慢查询、监视器等功能;多个客户端的状态信息的保存;构建客户端输出缓冲区。
链表以及链表节点的 API:
函数 作用 时间复杂度 listSetDupMethod 将给定的函数设置为链表的节点值复制函数 复制函数可以通过链表的 dup 属性直接获得,$ O(1) $ listGetDupMethod 返回链表当前正在使用的节点值复制函数 $ O(1) $ listSetFreeMethod 将给定的函数设置为链表的节点值释放函数 释放函数可以通过链表的 free 属性直接获得,$ O(1) $ listGetFree 返回链表当前正在使用的节点值释放函数 $ O(1) $ listSetMatchMethod 将给定的函数设置为链表的节点值对比函数 对比函数可以通过链表的 match 属性直接获得,$ O(1) $ listGetMatchMethod 返回链表当前正在使用的节点值对比函数 $ O(1) $ listLength 返回链表的长度(包含了多少个节点) 链表长度可以通过链表的 len 属性直接获得,$ O(1) $ listFirst 返回链表的表头节点 表头节点可以通过链表的 head 属性直接获得,$ O(1) $ listLast 返回链表的表尾节点 表尾节点可以通过链表的 tail 属性直接获得,$ O(1) $ listPrevNode 返回给定节点的前置节点 前置节点可以通过节点的 prev 属性直接获得,$ O(1) $ listNextNode 返回给定节点的后置节点 后置节点可以通过节点的 next 属性直接获得,$ O(1) $ listNodeValue 返回给定节点目前正在保存的值 节点值可以通过节点的 value 属性直接获得,$ O(1) $ listCreate 创建一个不包含任何节点的新链表 $ O(1) $ listAddNodeHead 将一个包含给定值的新节点添加到给定链表的表头 $ O(1) $ listAddNodeTail 将一个包含给定值的新节点添加到给定链表的表尾 $ O(1) $ listInsertNode 将一个包含给定值的新节点添加到给定节点的之前或者之后 $ O(1) $ listSearchKey 查找并返回链表中包含给定值的节点 $ O(N) $,N 为链表长度 listIndex 返回链表在给定索引上的节点 $ O(N) $,N 为链表长度 listDelNode 从链表中删除给定节点 $ O(N) $,N 为链表长度 listRotate 将链表的表尾节点弹出,然后将被弹出的节点插人到链表的表头,成为新的表头节点 $ O(1) $ listDup 复制一个给定链表的副本 $ O(N) $,N 为链表长度 listRelease 释放给定链表,以及链表中的所有节点 $ O(N) $,N 为链表长度 -
字典
字典以及哈希表的 C 实现:
// dict.h typedef struct dictEntry { void* key; // 键 union // 值 { void* val; uint64_tu64; int64_ts64; } v; struct dictEntry* next; // 指向下一个哈希表节点,形成链表 } dictEntry; typedef struct dictht { dictEntry ** table; // 哈希表数组 unsigned long size; // 哈希表大小 unsigned long sizemask; // 大小表大小掩码,用于计算哈希值,总是等于 size - 1 unsigned long used; // 该哈希表已有节点的数量 } dictht; typedef struct dictType { unsigned int (*hashFunction)(const void *key); // 计算哈希值的函数 void *(*keyDup)(void *privdata, const void *key); // 复制键的函数 void *(*valDup)(void *privdata, const void *obj); // 复制值的函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 对比键的函数 void (*keyDestructor)(void *privdata, void *key); // 销毁键的函数 void (*valDestructor)(void *privdata, void *obj); // 销毁值的函数 } dictType; typedef struct dict { dictType *type; // 类型特定函数,Redis 会为用途不同的 dict 设置不同的类型特定函数 void *privdata; // 私有数据,保存需要传给那些类型特定函数的可选参数 dictht ht[2]; // 哈希表,ht[0] 保存哈希表,而 ht[1] 是 rehash 时使用的辅助哈希表 int rehashidx; // rehash 索引。当 rehash 不在进行时,值为 -1 }Redis 的哈希表使用链地址法来解决哈希冲突,处于速度考虑,新节点总是添加到链表的表头位置。
Redis 对字典的哈希表执行 rehash 的步骤:
- 为字典的 ht[1] 哈希表分配空间,大小取决于要执行的操作和 $ ht[0].used $。
- 如果执行的是扩展操作,那么 $ ht[1].size $ 为第一个大于等于 $ ht[0].used \times 2 $ 的 $ 2^n $。
- 如果执行的是收缩操作,那么 $ ht[1].size $ 为第一个大于等于 $ ht[0].used $ 的 $ 2^n $。
- 将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面。
- 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0] 变为空表),释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 新创建一个空白哈希表,为下一次 rehash 做准备。
负载因子 $ load_factor = \frac{ht[0].used}{ht[0].size} $
Redis 自动对哈希表执行扩展操作的时机:
- 服务器目前没有执行
BGSAVE命令或者BGREWRITEAOF命令,并且 $ load_factor \ge 1 $。 - 服务器目前正在执行
BGSAVE命令或者BGREWRITEAOF命令,并且 $ load_factor \ge 5 $。
在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
Redis 自动对哈希表执行收缩操作的时机:
- $ load_factor \lt 0.1 $
rehash 动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。哈希表渐进式 rehash 的详细步骤:
- 为 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
- 在字典中维持一个索引计数器变量 rehashidx,并将它的值设置为 0,表示 rehash 工作正式开始。
- 在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],当 rehash 工作完成之后,程序将 rehashidx 属性的值增一。
- 随着字典操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],这时程序将 rehashidx 属性的值设为 -1,表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。因为在进行渐进式 rehash 的过程中,字典会同时使用 ht[0] 和 ht[1] 两个哈希表,所以在渐进式 rehash 进行期间,字典的删除、查找 、更新等操作会在两个哈希表上进行。例如,要在字典里面查找一个键的话,程序会先在 ht[0] 里面进行查找,如果没找到的话,就会继续到 ht[1] 里面进行查找,诸如此类。另外,在渐进式 rehash 执行期间,新添加到字典的键值对一律会被保存到 ht[1] 里面,而 ht[0] 则不再进行任何添加操作,这一措施保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
字典在 Redis 中被使用在:哈希键的底层实现之一;Redis 的数据库、对数据库的增、删、查、改操作等。
字典的 API:
函数 作用 时间复杂度 dictCreate 创建一个新的字典 $ O(1) $ dictAdd 将给定的键值对添加到字典里面 $ O(1) $ dictReplace 将给定的键值对添加到字典里面,如果键已经存在于字典,那么用新值取代原有的值 $ O(1) $ dictFetchValue 返回给定键的值 $ O(1) $ dictGetRandomKey 从字典中随机返回一个键值对 $ O(1) $ dictDelete 从字典中删除给定键所对应的键值对 $ O(1) $ dictRelease 释放给定字典,以及字典中包含的所有键值对 $ O(N) $,N 为字典包含的键值对数量 - 为字典的 ht[1] 哈希表分配空间,大小取决于要执行的操作和 $ ht[0].used $。
-
跳跃表
跳跃表的 C 实现:
// redis.h typedef struct zskiplistNode { struct zskiplistLevel // 层 { struct zskiplistNode *forward; // 前进指针 unsigned int span; // 跨度 } level[]; struct zskiplistNode *backward; // 后退指针 double score; // 分值 robj *obj; // 成员对象 } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; // 表头节点和表尾节点 unsigned long length; // 表中节点的数量 int level; // 表中层数最大的节点的层数 }跳跃表支持平均 $ O(\log_2N) $、最坏 $ O(N) $ 复杂度的节点查找。
跳跃表中的所有节点都按分值从小到大来排序。节点的成员对象(obj 属性)是一个指针,它指向一个字符串对象,而字符串对象则保存着一个 SDS 值。在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的,分值相同时成员对象较大的节点则会排在后面。
Redis 只在两个地方用到了跳跃表:
- 有序集合键的底层实现之一。
- 在集群节点中用作内部数据结构。
跳跃表的 API:
函数 作用 时间复杂度 zslCreate 创建一个新的跳跃表 $ O(1) $ zslFree 释放给定跳跃表,以及表中包含的所有节点 $ O(N) $,N 为跳跃表的长度 zslInsert 将包含给定成员和分值的新节点添加到跳跃表中 平均 $ O(\log_2N) $,最坏 $ O(N) $,N 为跳跃表长度 zslDelete 删除跳跃表中包含给定成员和分值的节点 平均 $ O(\log_2N) $,最坏 $ O(N) $,N 为跳跃表长度 zslGetRank 返回包含给定成员和分值的节点在跳跃表中的排位 平均 $ O(\log_2N) $,最坏 $ O(N) $,N 为跳跃表长度 zslGetElementByRank 返回跳跃表在给定排位上的节点 平均 $ O(\log_2N) $,最坏 $ O(N) $,N 为跳跃表长度 zslIsInRange 给定一个分值范围,比如 0 到 15,20 到 28 诸如此类,如果跳跃表中有至少一个节点的分值在这个范围之内,那么返回 1,否则返回 0 通过跳跃表的表头节点和表尾节点这个检测可以用 $ O(1)$ 复杂度完成 zslFirstInRange 给定一个分值范围,返回跳跃表中第一个符合这个范围的节点 平均 $ O(\log_2N) $,最坏 $ O(N) $。N 为跳跃表长度 zslLastInRange 给定一个分值范围,返回跳跃表中最后一个符合这个范围的节点 平均 $ O(\log_2N) $,最坏 $ O(N) $。N 为跳跃表长度 zslDeleteRangeByScore 给定一个分值范围,删除跳跃表中所有在这个范围之内的节点 $ O(N) $,N 为被删除节点数量 zslDeleteRangeByRank 给定一个排位范围,删除跳跃表中所有在这个范围之内的节点 $ O(N) $,N 为被删除节点数量 -
整数集合
整数集合的 C 实现:
// intset.h typedef struct intset { uint32_t encoding; // 编码方式 uint32_t length; // 集合包含的元素数量 int8_t contents[]; // 保存元素的数组 } intset;整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组,但实际上 contents 数组并不保存任何 int8_t 类型的值,contents 数组的真正类型取决于 encoding 属性的值,encoding 为 INSERT_ENC_INT16、INSERT_ENC_INT32、INSERT_ENC_INT64 时,item 类型分别为 int16_t、int32_t、int64_t。
每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级,然后才能将新元素添加到整数集合里面。 升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需 要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
因为每次向整数集合添加新元素都可能会引起升级,而每次升级都需要对底层数组中已有的所有元素进行类型转换,所以向整数集合添加 新元素的时间复杂度为 $ O(N) $。
整数集合的升级策略有两个好处,一个是提升整数集合的灵活性, 另一个是尽可能地节约内存。
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
整数集合在 Redis 中被使用在:集合键的底层实现之一等。
整数集合的 API:
函数 作用 时间复杂度 intsetNew 创建一个新的压缩列表 $ O(1) $ intsetAdd 将给定元素添加到整数集合里面 $ O(N) $ intsetRemove 从整数集合中移除给定元素 $ O(N) $ intsetFind 检查给定值是否存在于集合 因为底层数组有序,查找可以通过二分查找法来进行,所以复杂度为 $ O(\log_2N)$ intsetRandom 从整数集合中随机返回一个元素 $ O(1) $ intsetGet 取出底层数组在给定索引上的元素 $ O(1) $ intsetLen 返回整数集合包含的元素个数 $ O(1) $ intsetBlobLen 返回整数集合占用的内存字节数 $ O(1) $ -
压缩列表
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
压缩列表的组成部分以及用途说明:
![]()
![]()
压缩列表节点的构成:
![]()
-
previous_entry_length:记录前一个节点的长度。
- 如果前一节点的长度小于 254 字节,则 previous_entry_length 长度为 1 字节,前一节点的长度就保存在这一个字节里面。
- 如果前一节点的长度大于等于 254 字节,则 previous_entry_length 长度为 5 字节,第一字节会被设置为 0xFE,之后的四个字节则用于保存前一节点的长度。
-
encoding:记录节点的 content 属性所保存数据的类型以及长度。
-
content 为字节数组:数组的长度由编码除去最高两位之后的其他位记录。
![]()
-
content 为整数值:整数值的类型和长度由编码除去最高两位之后的其他位记录。
![]()
-
连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作,而每次空间重分配的最坏复杂度为 $ O(N) $,所以连锁更新的最坏复杂度为 $ O(N^2) $。ziplistPush 等命令的平均复杂度仅为 $ O(N) $,
压缩列表在 Redis 中被使用在:列表键和哈希键的底层实现之一等。
压缩列表的 API:
函数 作用 算法复杂度 ziplistNew 创建一个新的压缩列表 $ O(1) $ ziplistPush 创建一个包含给定值的新节点,并将这个新节点添加到压缩列表的表头或者表尾 平均 $ O(N) $,最坏 $ O(N^2) $ ziplistInsert 将包含给定值的新节点插人到给定节点之后 平均 $ O(N) $,最坏 $ O(N^2) $ ziplistIndex 返回压缩列表给定索引上的节点 $ O(N) $ ziplistFind 在压缩列表中查找并返回包含了给定值的节点 因为节点的值可能是一个字节数组,所以检查节点值和给定值是否相同的复杂度为 $ O(N) $,而查找整个列表的复杂度则 $ O(N^2) $ ziplistNext 返回给定节点的下一个节点 $ O(1) $ ziplistPrev 返回给定节点的前一个节点 $ O(1) $ ziplistGet 获取给定节点所保存的值 $ O(1) $ ziplistDelete 从压缩列表中删除给定的节点 平均 $ O(N) $,最坏 $ O(N^2) $ ziplistDeleteRange 删除压缩列表在给定索引上的连续多个节点 平均 $ O(N) $,最坏 $ O(N^2) $ ziplistBlobLen 返回压缩列表目前占用的内存字节数 $ O(1) $ ziplistLen 返回压缩列表目前包含的节点数量 节点数量小于 65535 时为 $ O(1) $,大于 65535 时为 $ O(N) $ -



3.2.2.对象
Redis 并没有直接使用上述数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统。Redis 使用对象来表示数据库中的键和值:
typedef struct redisObejct
{
unsigned type:4; // 类型
unsigned encoding:4; // 编码
void *ptr; // 指向底层实现数据结构的指针
int refcount; // 引用计数
unsigned lru:22; // 对象最后移除被命令程序访问的时间
}
-
类型:
![]()
Redis 的键总是一个字符串对象,而值则可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象的其中一种。
TYPE命令根据数据库键对应的值对象的类型返回结果(string、list、hash、set、zset)。Redis 中操作键的命令分为两种:
- 对任何类型键有效,如
DEL、EXPIRE、RENAME、TYPE、OBJECT等。 - 对特定类型键有效,如:
SET、GET、APPEND、STRLEN等命令只能对字符串键执行。HDEL、HSET、HGET、HLEN等命令只能对哈希键执行。RPUSH、LPOP、LINSERT、LLEN等命令只能对列表键执行。SADD、SPOP、SINTER、SCARD等命令只能对集合键执行。ZADD、ZCARD、ZRANK、ZSCORE等命令只能对有序集合键执行。
在执行一个类型特定命令之前,服务器会先检查输入数据库键的值对象是否为执行命令所需的类型。不是的话,服务器将拒绝执行命令,并向客户端返回一个类型错误。
- 对任何类型键有效,如
-
编码:
![]()
记录对象使用什么数据结构作为对象的底层实现。
OBJECT ENCODING命令数据库键的值对象的编码(int、embstr、raw、hashtable、linkedlist、ziplist、intset、skiplist)。Redis 除了会根据值对象的类型来判断键是否能够执行指定命令之外,还会根据值对象的编码方式,选择正确的命令实现代码来执行命令。
-
引用计数:
主要用于内存回收机制和对象共享:
-
内存回收
创建一个新对象该值被初始化为 1,当对象被/不再被一个(新)程序引用时,该值增一/减一,变为 0 时,对象所占用内存被释放。
通过内存回收机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
-
对象共享
对现有的值对象,可被其它程序共享,共享时该值增一。
通过对象共享机制,节约内存。
目前来说,Redis 会在初始化服务器时,创建一万个字符串对象, 这些对象包含了从 0 到 9999 的所有整数值,当服务器需要用到值为 0 到 9999 的字符串对象时,服务器就会使用这些共享对象,而不是新创建对象。
创建共享字符串对象的数量可通过 redis.h/REDIS_SHARED_INTEGERS 常量修改。
OBJECT REFCOUNT命令查看引用次数。修改对象引用次数的 API:
![]()
-
-
LRU:
OBJECT IDLETIME命令查看该字段。OBJECT IDLETIME命令不会修改 LRU。如果服务器打开了 maxmemory 选项,并且服务器用于回收内存的算法为 volatile-lru 或者 allkeys-lru,那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
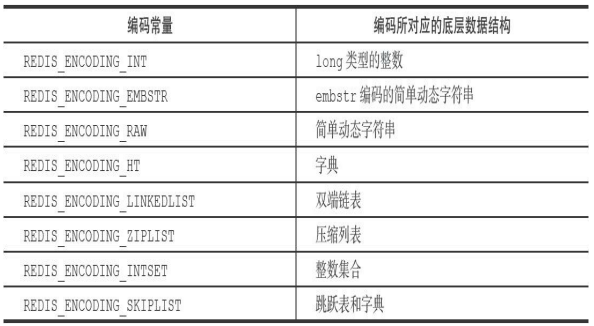

不同类型可以使用的编码:
-
字符串对象。
其编码可以是
int、embstr、raw:-
int:字符串对象保存可以用 long 类型表示的整数值时。该整数值保存在 ptr 属性中,类型转为 long,编码设置为int。对于 long double 类型的浮点数会转为字符串值来保存。
int编码的字符串在经过一些命令后变得不再是整数值时,将转为raw编码。 -
embstr:字符串对象保存长度小于等于 32 字节的字符串值时。使用 embstr 编码方式来保存该字符串。
Redis 没有为
embstr编码的字符串提供任何修改程序,所以embstr编码的字符串是只读的。对embstr编码的字符串执行修改命令时,会先将其装换为raw编码再对其修改,这会将其变为raw编码的字符串。embstr 编码是专门用于保存短字符串的一种优化编码方式。这种编码和 raw 编码一样,都使用 redisObject 结构和 sdshdr 结构来表示字符串对象,但 raw 编码会调用两次内存分配函数来分别创建 redisObject 结构和 sdshdr 结构,而 embstr 编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含 redisObject 和 sdshdr 两个结构。
-
raw:字符串对象保存长度大于 32 字节的字符串值时。使用 SDS 来保存该字符串。
字符串命令:
![]()
-
-
列表对象
其编码可以是
ziplist、linkedlist:-
ziplist:所有字符串长度小于 64 字节,且元素数量小于 512 个时。 -
linkedlist:不满足ziplist条件时。linkedlist编码的列表对象使用双端链表,其表节点保存一个字符串对象,每个字符串对象为一个列表元素。
上述两个条件的上限值可通过
list-max-ziplist-value和list-max-ziplist-entries选项修改。列表命令:
![]()
-
-
哈希对象
其编码可以是
ziplist、hashtable:-
ziplist:所有键和值的字符串长度都小于 64 字节,且键值对数量小于 512 个时。ziplist编码的哈希对象,其键、值是紧挨在压缩列表中的。 -
hashtable:不满足ziplist条件时。hashtable编码的哈希对象,其键、值都是字符串对象被保存在字典中。
上述两个条件的上限值可通过
hash-max-ziplist-value和hash-max-ziplist-entries选项修改。哈希命令:
![]()
-
-
集合对象
其编码可以是
intset、hashtable:-
intset:所有元素都为整数值,且数量不超过 512 个时。 -
hashtable:不满足intset条件时。hashtable编码的集合对象所使用的字典,其键为保存元素的字符串对象,值为 NULL。
上述条件的上限值可通过
set-max-inset-entires选项修改。集合命令:
![]()
![]()
-
-
有序集合对象
其编码可以是
ziplist、skiplist:-
ziplist:所有元素长度小于 64 字节,且元素数量小于 128 个时。ziplist编码的有序集合对象,其元素成员、分值是紧挨在压缩列表中的,元素按从小到大进行排序。 -
skiplist:不满足ziplist条件时。skiplist编码的有序集合使用 zset 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表:typedef struct zset { zskiplist *zsl; dict *dict; } zset;zsl 跳跃表按分值从小到大保存了所有集合元素。通过这个跳跃表,程序可以对有序集合进行范围型操作(比如
ZRANK、ZRANGE)。dict 字典为有序集合创建了一个从成员到分值的映射。通过这个字典,程序可以用 $ O(1) $ 复杂度查找给定成员的分值(如
ZSCORE)。虽然同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以不会因此而浪费额外的内存。
上述两个条件的上限值可通过
zset-max-ziplist-value和zset-max-ziplist-entries选项修改。有序集合命令:
![]()
-



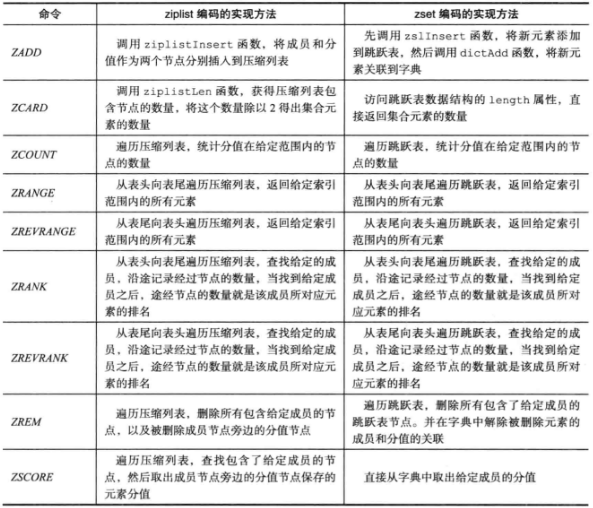
3.3.数据库
3.3.1.客户端状态
客户端状态:
typedef struct redisClient
{
int fd; // 套接字描述符
robj *name; // 客户端名字
int flags; // 标志
int authenticated; // 客户端是否通过了身份验证
redisDb *db; // 客户端当前正在使用的数据库
sds querybuf; // 输入缓冲区
robj **argv; // 命令及参数
int argc; // argv 数组长度
struct redisCommand *cmd; // 实现命令
char buf[REDIS_REPLY_CHUNK_BYTES]; // 固定大小输出缓冲区
int bufpos; // 固定大小输出缓冲区已使用的字节数量
list *reply; // 可变大小输出缓冲区
time_t ctime; // 创建客户端的时间
time_t lastinteraction; // 客户端服务器之间最后一次互动时间
time_t obuf_soft_limit_reached_time; // 输出缓冲区第一次到达软性限制的时间
redisClient *lua_client; // Lua 脚本的伪客户端
int slave_listening_port; // 从服务器的监听端口号
// ...
} redisClient;
-
fd:客户端的套接字描述符。 伪客户端为 -1。 -
name:客户端的名字。默认没有名字。CLIENT setname设置客户端名字。 -
flags:客户端的标志值。可以是多个以下标志的组合:-
REDIS_MASTER:主从服务器进行复制操作时,客户端是主服务器。REDIS_SLAVE:主从服务器进行复制操作时,客户端是从服务器。 -
REDIS_PRE_PSYNC:客户端是版本低于 Redis2.8 的从服务器,主服务器不能使用PSYNC命令与这个从服务器进行同步。这个标志只能在REDIS_SLAVE标志处于打开状态时使用。 -
REDIS_LUA_CLIENT:客户端是专门用于处理 Lua 脚本里面包含的 Redis 命令的伪客户端。 -
REDIS_MONITOR:客户端正在执行MONITOR命令。 -
REDIS_UNIX_SOCKET:服务器使用 UNIX 套接字来连接客户端。 -
REDIS_BLOCKED:客户端正在被BRPOP、BLPOP等命令阻塞。 -
REDIS_UNBLOCKED:客户端已经从REDIS_BLOCKED标志所表示的阻塞状态中脱离出来,不再阻塞。只能在REDIS_BLOCKED标志已经打开的情况下使用。 -
REDIS_MULTI:客户端正在执行事务。 -
REDIS_DIRTY_CAS:事务使用WATCH命令监视的数据库键已经被修改。REDIS_DIRTY_EXEC:事务在命令入队时出现了错误。以上两个标志都表示事务的安全性已经被破坏,只要这两个标记中的任意一个被打开,
EXEC命令必然会执行失败。这两个标志只能在客户端打开了REDIS_MULTI标志的情况下使用。 -
REDIS_CLOSE_ASAP:客户端的输出缓冲区大小超出了服务器允许的范围,服务器会在下一次执行 serverCron 函数时关闭这个客户端,以免服务器的稳定性受到这个客户端影响。积存在输出缓冲区中的所有内容会直接被释放,不会返回给客户端。 -
REDIS_CLOSE_AFTER_REPLY:有用户对这个客户端执行了CLIENT KILL命令,或者客户端发送给服务器的命令请求中包含了错误的协议内容。服务器会将客户端积存在输出缓冲区中的所有内容发送给客户端,然后关闭客户端。 -
REDIS_ASKING:客户端向集群节点(运行在集群模式下的服务器)发送了ASKING命令。 -
REDIS_FORCE_AOF:强制服务器将当前执行的命令写入到AOF文件里面。REDIS_FORCE_REPL:强制主服务器将当前执行的命令复制给所有从服务器。执行
PUBSUB命令会使客户端打开REDIS_FORCE_AOF标志,执行SCRIPT LOAD命令会使客户端打开REDIS_FORCE_AOF标志和REDIS_FORCE_REPL标志。 -
REDIS_MASTER_FORCE_REPLY:在主从服务器进行命令传播期间,从服务器需要向主服务器发送REPLICATION ACK命令,在发送这个命令之前,从服务器必须打开主服务器对应的客户端的REDIS_MASTER_FORCE_REPLY标志,否则发送操作会被拒绝执行。
-
-
authenticated:客户端的身份验证标志,0/1 表示未通过/通过了客户端身份验证。未通过只能使用AUTH指令。该属性只在服务器启用了身份验证时使用。 -
db:指向客户端正在使用的数据库的指针,以及该数据库的号码。默认情况下,Redis 客户端的目标数据库为 0 号数据库。 -
querybuf:客户端当前要执行的指令。默认大小 1 GB。argv:保存querybuf中指令被解析后的指令以及参数的数组。argc。cmd:实现querybuf中指令的 redisCommand。 -
buf、bufpos。reply:可变大小的输出缓冲区的字符串对象链表。Redis 的输出缓冲区分固定大小和可变大小,长度较小的回复(如
OK)被保存在固定大小输出缓冲区,否则保存在可变大小中。 -
ctime:客户端创建时间,即CLIENT list的 age 字段。lastinteraction:客户端服务器之间最后一次互动时间,用于计算空转时间(CLIENT list的 idle 字段)。 -
obuf_soft_limit_reached_time:输出缓冲区第一次到达软性限制的时间。由于可使用可变大小输出缓冲区,理论上输出缓冲区无限制大小,使用软性/硬性限制可限制这种措施。指令格式为:
client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>如:
client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256 mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 -
lua_client:Lua 脚本的伪客户端。该伪客户端会在服务器运行整个生命周期存在,直到服务器被关闭。 -
slave_listening_port。
普通客户端被关闭的情况:
-
如果客户端进程退出或者被杀死,那么客户端与服务器之间的网络连接将被关闭,从而造成客户端被关闭。
-
如果客户端向服务器发送了带有不符合协议格式的命令请求,那么这个客户端也会被服务器关闭。
-
如果客户端成为了
CLIENT KILL命令的目标,那么它也会被关闭。 -
如果用户为服务器设置了 timeout 配置选项,那么当客户端的空转时间超过 timeout 选项设置的值时,客户端将被关闭。
不过 timeout 选项有一些例外情况:如果客户端是主服务器,从服务器正在被
BLPOP等命令阻塞或者正在执行SUBSCRIBE、PSUBSCRIBE等订阅命令,那么即使客户端的空转时间超过了 timeout 选项的值,客户端也不会被服务器关闭。 -
如果客户端发送的命令请求的大小超过了输入缓冲区的限制大小 ,那么这个客户端会被服务器关闭。
-
如果要发送给客户端的命令回复的大小超过了输出缓冲区的限制大小,那么这个客户端会被服务器关闭。
3.3.2.服务器
服务器状态:
// redis.h
struct redisServer
{
list *clients; // 保存所有客户端状态的链表
// 数据库相关
int dbnum; // 服务器的初始数据库数量
redisDb *db; // 一个数组,保存服务器中所有数据库
// RDB 相关
struct saveparam *saveparams; // 记录了 RDB 持久化的 save 选项自动间隔性保存的条件
long long dirty; // 上次 SAVE/BGSAVE 后对数据库修改次数
time_t lastsave; // 上次 SAVE/BGSAVE 时间戳
// AOF 相关
sds aof_buf; // AOF 缓冲区,保存要被写入 AOF 文件中的内容
time_t unixtime; // 秒级精度的系统当前 UNIX 时间戳
long long mstime; // 毫秒级精度的系统当前 UNIX 时间戳
unsigned lruclock:22; // 服务器的 LRU 时钟
long long ops_sec_last_sample_time; // 上次抽样时间
long long ops_sec_last_sample_ops; // 上次抽样后服务器已执行的命令数
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES]; // 记录抽样结果的环形数组
int ops_sec_idx; // ops_sec_samples 索引值
size_t stat_peak_memory; // 服务器内存峰值
int shutdown_asap; // 关闭服务器标识
pid_t rdb_child_pid; // BGSAVE 命令子进程 ID,没有执行则为 -1
pid_t aof_child_pid; // BGREWRITEAOF 命令子进程 ID,没有执行则为 -1
int aof_rewrite_scheduled; // BGREWRITEAOF 命令延迟标志
int cronloops; // serverCron 函数运行次数计数器
// 主从复制相关
char *masterhost; // 主复制器的地址
int masterport; // 主复制器的端口
// ...
}
struct saveparam
{
time_t seconds; // 秒数
int changes; // 修改数
}
-
clients。CLIENT list列出目前所有连接到服务器的普通客户端。 -
dbnum:服务器的初始数据库数量,由 database 选项决定。db。 -
saveparams、dirty、lastsave。 -
aof_buf。 -
unixtime、mstime。为提高指令运行效率,除了需要高精度时间的功能(如设置键过期时间、添加慢查询日志)使用系统调用外,其余功能使用这两个字段表示的近似时间。这两个字段每次在 serverCron 中被更新。
-
lruclock:保存服务器的 LRU 时钟,每 10 秒一次的频率被 serverCron 更新,可使用INFO server指令查看。可用于计算数据库键的空转时间(服务器的lruclock减去 Redis 对象的lru)。 -
ops_sec_。可用于估算服务器最近一秒处理命令的请求数量(
INFO status的 instantaneous_ops_per_sec 字段)等功能:ops_sec_last_sample_ops除以当前时间减去ops_sec_last_sample_time,将其保存在ops_sec_samples[ops_sec_idx]中,然后ops_sec_idx %= REDIS_OPS_SEC_SAMPLES,最后计算 ops_sec_samples 中平均值再计算每秒的值就得到 instantaneous_ops_per_sec 值。 -
stat_peak_memory:服务器内存峰值。serverCron 中会使用当前内存使用量与其比较并更新。 -
shutdown_asap:关闭服务器标识。sigtermHandler 函数在服务器进程收到 SIGTERM 信号时打开该标识。serverCron 函数运行时检查该标识,打开时则关闭服务器。 -
rdb_child_pid、aof_child_pid。aof_rewrite_scheduled:标志BGSAVE执行期间,收到BGREWRITEAOF指令,该指令延迟到BGSAVE执行完后执行。serverCron 函数会检查这三个值:
rdb_child_pid、aof_child_pid其中一个为 -1 时,程序执行一次 wait3 操作,检查子进程是否由信号发来表示 RDB 文件生成完毕/ AOF 文件重写完毕,有则用新文件替换旧文件,否则不做任何操作。rdb_child_pid、aof_child_pid这两个均为 -1 时:aof_rewrite_scheduled为 1 时,执行BGREWRITEAOF。- 否则,如果 RDB 自动保存条件满足,执行
BGSAVE。 - 否则,AOF 重写条件满足,执行
BGREWRITEAOF。
-
cronloops。 -
masterhost、masterport。
serverCron 每次执行时都会调用 clientsCron 函数,该函数会对一定数量客户端进行如下检查:
- 如果客户端与服务器之间的连接已经超时(很长一段时间里客户端和服务器都没有互动),那么程序释放这个客户端。
- 如果客户端在上一次执行命令请求之后,输入缓冲区的大小超过了一定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存。
3.3.3.数据库
// redis.h
typedef struct redisDb
{
dict *dict; // 数据库键空间,保存着数据库中所有键值对
dict *expires; // 过期字典,保存着键的过期时间
}
键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键,每个键都是一个字符串对象。
- 键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种 Redis 对象。
当使用 Redis 命令对数据库进行读写时,服务器不仅会对键空间执行指定的读写操作,还会执行一些额外的维护操作:
- 在读取一个键之后(读操作和写操作都要对键进行读取),服务器会根据键是否存在来更新服务器的键空间命中次数或键空间不命中次数,这两个值可以在
INFO stats命令的 keyspace_hits 属性和 keyspace_misses 属性中查看。 - 在读取一个键之后,服务器会更新键的 LRU 时间,这个值可以用于计算键的闲置时间,使用
OBJECT idletime <key>命令可以查看键 key 的闲置时间。 - 如果服务器在读取一个键时发现该键已经过期,那么服务器会先删除这个过期键,然后才执行余下的其他操作。
- 如果有客户端使用
WATCH命令监视了某个键,那么服务器在对被监视的键进行修改之后,会将这个键标记为 dirty,从而让事务程序注意到这个键已经被修改过。 - 服务器每次修改一个键之后,都会对脏(dirty)键计数器的值增 1,这个计数器会触发服务器的持久化以及复制操作。
- 如果服务器开启了数据库通知功能,那么在对键进行修改之后, 服务器将按配置发送相应的数据库通知。
3.3.4.过期时间
EXPIRE/PEXPIRE命令为数据库中的某个键设置生存时间(Time To Live,TTL)。EXPIREAT/PEXPIREAT命令为数据库中的某个键设置过期时间(UNIX 时间戳)。到达指定时间时,服务器自动删除对应键。
事实上,
EXPIRE、PEXPIRE、EXPIREAT都是通过PEXPIREAT命令实现的。
TTL/PTTL命令返回某个键的剩余生存时间。PERSIST命令移除某个键的过期时间。
过期键删除策略:
-
定时删除:在设置键的过期时间的同时创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。
优点:内存友好,过期键能被尽早删除。
缺点:CPU 时间不友好;定时器用到的时间事件实现结构为无序链表,查找的时间复杂度为 \(O(N)\) 而不能高效处理大量时间事件。
-
惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
优点:CPU 时间友好。
缺点:内存不友好,除非使用
FLUSHDB,未被访问的键过期时永不删除而造成内存泄漏。 -
定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
Redis 服务器实际使用的是惰性删除和定期删除两种策略。过期键的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有读写数据库的 Redis 命令在执行之前都会调用 expireIfNeeded 函数对输入键进行检查;过期键的定期删除策略由 redis.c/activeExpireCycle 函数实现,每当 Redis 的服务器周期性操作 redis.c/serverCron 函数执行时,activeExpireCycle 函数就会被调用。
使用SAVE/BGSAVE生成 RDB 文件时,过期键不会保存到 RDB 文件中。载入 RDB 文件时,如果是主服务器,只载入未过期的键;如果是从服务器,所有键都被载入。
当服务器以 AOF 持久化模式运行时,如果键已过期但还未惰性删除/定期删除,AOF 文件不会删除该过期键;当过期键被惰性删除/定期删除时,AOF 文件会追加DEL命令。AOF 重写时已过期键不会被保存到 AOF 文件中。
当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制:
- 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个
DEL命令,告知从服务器删除这个过期键。 - 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键。 从服务器只有在接到主服务器发来的
DEL命令之后,才会删除过期键。
// TODO 数据库通知,9.8节
3.3.5.命令执行过程
-
发送命令请求
当用户在客户端中键入一个命令请求时,客户端会将这个命令请求转换成协议格式,然后通过连接到服务器的套接字,将协议格式的命令请求发送给服务器。
-
读取命令请求
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时,服务器将调用命令请求处理器来执行以下操作:
- 读取套接字中协议格式的命令请求,并将其保存到客户端状态的输入缓冲区里面。
- 对输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数,以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的 argv 属性和 argc 属性里面。
- 调用命令执行器,执行客户端指定的命令。
-
命令执行器执行
-
查找命令实现
根据客户端状态的 argv[0] 参数,在命令表(command table)中查找参数所指定的命令,并将找到的命令保存到客户端状态的 cmd 属性里面。
命令表是一个字典,字典的键是命令名字(如
"set"、"get"),字典的值则是一个 redisCommand 结构,该结构记录了一个 Redis 命令的实现信息:属性名 类型 作用 name char* 命令的名字,比如 "set"。proc redisCommandProc* 函数指针,指向命令的实现函数,比如 setCommand。redisCommandProc 类型的定义为 typedef void redisCommandProc(redisClient *c);。arity int 命令参数的个数,用于检查命令请求的格式是否正确。如果这个值为负数 -N,那么表示参数的数量大于等于 N。注意命令的名字本身也是一个参数,比如说 SET msg "helloworld"命令的参数是"SET"、"msg"、"hello world"。sflags char* 字符串形式的标识值,这个值记录了命令的属性,比如这个命令是写命令还是读命令,这个命令是否允许在载入数据时使用,这个命令是否允许在 Lua 脚本中使用等等。 flags int 对 sflags 标识进行分析得出的二进制标识,由程序自动生成。服务器对命令标识进行检查时使用的都是 flags 属性而不是 sflags 属性,因为对二进制标识的检查可以方便地通过 &、^、~等操作来完成。calls long long 服务器总共执行了多少次这个命令。 milliseconds long long 服务器执行这个命令所耗费的总时长。 sflags 属性可使用标识值:
标识 意义 带有这个标识的命令 w 这是一个写人命令,可能会修改数据库。 SET、RPUSH、DEL等等r 这是一个只读命令,不会修改数据库。 GET、STRLEN、EXISTS等等m 这个命令可能会占用大量内存,执行之前需要先检查服务器的内存使用情况,如果内存紧缺的话就禁止执行这个命令。 SET、APPEND、RPUSH、LPUSH、SADDSINTERSTORE等等a 这是一个管理命令。 SAVE、BGSAVE、SHUTDOWN等等p 这是一个发布与订阅功能方面的命令。 PUBLISH、SUBSCRIBE、PUBSUB等等s 这个命令不可以在 Lua 脚本中使用。 BRPOP、BLPOP、BRPOPLPUSH、SPOP等等R 这是一个随机命令,对于相同的数据集和相同的参数,命令返回的结果可能不同。 SPOP、SRANDMEMBER、SSCAN、RANDOMKEY等等S 当在Lua脚本中使用这个命令时,对这个命令的输出结果进行一次排序,使得命令的结果有序。 SINTER、SUNION、SDIFF、SMEMBERS、KEYS等等l 这个命令可以在服务器载入数据的过程中使用。 INFO、SHUTDOWN、PUBLISH等等t 这是一个允许从服务器在带有过期数据时使用的命令。 SLAVEOF、PING、INFO等等M 这个命令在监视器模式下不会自动被传播。 EXEC -
执行预备操作
这些操作包括:
- 检查客户端状态的 cmd 指针是否指向 NULL,如果是的话服务器不再执行后续步骤并向客户端返回一个错误。
- 根据客户端 cmd 属性指向的 redisCommand 结构的 arity 属性,检查命令请求所给定的参数个数是否正确,当参数个数不正确时不再执行后续步骤并向客户端返回一个错误。
- 检查客户端是否已经通过了身份验证,未通过身份验证的客户端只能执行
AUTH命令,如果未通过身份验证的客户端试图执行除AUTH命令之外的其他命令,那么服务器将向客户端返回一个错误。 - 如果服务器打开了 maxmemory 功能,那么在执行命令之前,先检查服务器的内存占用情况,并在有需要时进行内存回收,从而使得接下来的命令可以顺利执行。如果内存回收失败,那么不再执行后续步骤并向客户端返回一个错误。
- 如果服务器上一次执行
BGSAVE命令时出错,并且服务器打开了 stop-writes-on-bgsave-error 功能,而且服务器即将要执行的命令是一个写命令,那么服务器将拒绝执行这个命令并向客户端返回一个错误。 - 如果客户端当前正在用
SUBSCRIBE命令订阅频道,或者正在用PSUBSCRIBE命令订阅模式,那么服务器只会执行客户端发来的SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE、PUNSUBSCRIBE四个命令,其他命令都会被服务器拒绝。 - 如果服务器正在进行数据载入,那么客户端发送的命令必须带有 l 标识才会被服务器执行,其他命令都会被服务器拒绝。
- 如果服务器因为执行 Lua 脚本而超时并进入阻塞状态,那么服务器只会执行客户端发来的
SHUTDOWN nosave命令和SCRIPT KILL命令, 其他命令都会被服务器拒绝。 - 如果客户端正在执行事务,那么服务器只会执行客户端发来的
EXEC、DISCARD、MULTI、WATCH四个命令,其他命令都会被放进事务队列中。 - 如果服务器打开了监视器功能,那么服务器会将要执行的命令和参数等信息发送给监视器。
当完成了以上预备操作之后,服务器就可以开始真正执行命令了。
-
调用命令的实现函数
执行以下语句:
client->cmd->proc(client); -
执行后续工作
在执行完实现函数之后,服务器还需要执行一些后续工作:
- 如果服务器开启了慢查询日志功能,那么慢查询日志模块会检查是否需要为刚刚执行完的命令请求添加一条新的慢查询日志。
- 根据刚刚执行命令所耗费的时长,更新被执行命令的 redisCommand 结构的 milliseconds 属性,并将命令的 redisCommand 结构的 calls 计数器的值增一。
- 如果服务器开启了 AOF 持久化功能,那么 AOF 持久化模块会将刚刚执行的命令请求写入到 AOF 缓冲区里面。
- 如果有其他从服务器正在复制当前这个服务器,那么服务器会将刚刚执行的命令传播给所有从服务器。
-
-
将命令回复发送给客户端
当客户端套接字变为可写状态时,服务器就会执行命令回复处理器,将保存在客户端输出缓冲区中的命令回复发送给客户端。
-
客户端接收并打印命令回复
当客户端接收到协议格式的命令回复之后,它会将这些回复转换成人类可读的格式,并打印给用户观看。
3.4.持久化
3.4.1.RDB
RDB 持久化既可以手动执行,也可以根据服务器配置选项定期执行,生成的 RDB 文件是一个经过压缩的二进制文件。
SAVE命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止;BGSAVE命令会派生出一个子进程,然后由子进程负责创建 RDB 文件,服务器进程(父进 程)继续处理命令请求。创建 RDB 文件的实际工作由 rdb.c/rdbSave 函数完成。
因为 AOF 文件的更新频率通常比 RDB 文件的更新频率高,所以:
- 如果服务器开启了 AOF 持久化功能,那么服务器会优先使用 AOF 文件来还原数据库状态。
- 只有在 AOF 持久化功能处于关闭状态时,服务器才会使用 RDB 文件来还原数据库状态。
在BGSAVE命令执行期间,客户端发送的SAVE、BGSAVE命令会被服务器拒绝。如果BGSAVE命令正在执行,客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。如果BGREWRITEAOF命令正在执行,客户端发送的BGSAVE命令会被服务器拒绝。
可通过 save 选项设置多个保存条件,只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。如:
save 900 1
save 300 10
save 60 10000
RDB 文件的载入工作是在服务器启动时自动执行的,只要 Redis 服务器在启动时检测到 RDB 文件存在,它就会自动载入 RDB 文件。载入 RDB 文件的实际工作由 rdb.c/rdbLoad 函数完成。
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
RDB 文件结构如下,其中 db_version 记录 RDB 文件版本号,databases 包含任意多个数据库以及其中的键值对数据(如果所有数据库为空则 databases 为空)。

databases 结构示例:

database 结构如下:

key_value_pairs 在键含有过期时间和不含有时其结构如下:


- TYPE:记录 value 类型,可以是
REDIS_RDB_TYPE_STRING、REDIS_RDB_TYPE_LIST、REDIS_RDB_TYPE_SET、REDIS_RDB_TYPE_ZSET、REDIS_RDB_TYPE_HASH、REDIS_RDB_TYPE_LIST_ZIPLIST、REDIS_RDB_TYPE_SET_INTSET、REDIS_RDB_TYPE_ZSET_ZIPLIST、REDIS_RDB_TYPE_HASH_ZIPLIST。 - key:总是一个字符串对象,编码格式和
REDIS_RDB_TYPE_STRING类型编码的 value 一样。
value 编码格式:
-
REDIS_RDB_TYPE_STRING:value 保存一个字符串对象。-
字符串对象编码为
REDIS_ENCODING_INT8/16/32时,其结构为:![]()
-
字符串对象编码为
REDIS_ENCODING_RAW时:如果字符串长度小于等于 20 字节,字符串原样保存:
![]()
否则,字符串压缩保存:
![]()
REDIS_RDB_ENC_LZF 常量标志着字符串已经被 LZF 算法压缩过。
-
-
REDIS_RDB_TYPE_LIST:value 保存REDIS_ENCODING_LINKEDLIST编码的列表对象。其结构如下:![]()
item 处理方式同处理字符串对象方式。
-
REDIS_RDB_TYPE_SET:value 保存REDIS_ENCODING_HT编码的集合对象。其结构如下:![]()
elem 处理方式同处理字符串对象方式。
-
REDIS_RDB_TYPE_HASH:value 保存REDIS_ENCODING_HT编码的哈希对象。其结构如下:![]()
key、value 处理方式同处理字符串对象方式。
-
REDIS_RDB_TYPE_ZSET:value 保存REDIS_ENCODING_SKIPLIST编码的有序集合对象。其结构如下:![]()
member 处理方式同处理字符串对象方式。score 是类型的浮点数。
-
REDIS_RDB_TYPE_SET_INTSET:value 保存整数集合对象。RDB 文件保存这种对象会先将整数集合转换为字符串对象,然后将其保存到 RDB 文件。 -
REDIS_RDB_TYPE_LIST_ZIPLIST、REDIS_RDB_TYPE_ZSET_ZIPLIST、REDIS_RDB_TYPE_HASH_ZIPLIST:value 保存压缩列表对象。RDB 文件保存这种对象先将列表转换为字符串对象后再保存。







3.4.2.AOF
AOF 持久化是通过保存 Redis 服务器所执行的写命令来记录数据库状态的,生成的 AOF 文件是纯文本文件。
在服务器每次结束一个事件循环之前, 会调用 flushAppendOnlyFile 函数,考虑是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里面,flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值(默认 everysec)来决定:
| 选项 | 行为 |
|---|---|
| always | 将 aof_buf 缓冲区中的所有内容写入并同步到 AOF 文件 |
| everysec | 将 aof_buf 缓冲区中的所有内容写人到 AOF 文件,如果上次同步 AOF 文件的时间距离现在超过一秒钟,那么再次对 AOF 文件进行同步,并且这个同步操作是由一个线程专门负责执行的 |
| no | 将 aof_buf 缓冲区中的所有内容写人到 AOF 文件,但并不对 AOF 文件进行同步,何时同步由操作系统来决定 |
Redis 使用 AOF 文件还原数据库状态方式:创建一个不带网络连接的伪客户端,从 AOF 文件中读取指令并在该伪客户端上执行。
BGREWRITEAOF命令实现 AOF 文件重写,AOF 文件重写并不需要对现有的 AOF 文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。
为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数量,如果元素的数量超过了 redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,那么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。
AOF 重写先在子进程中进行,该过程会将数据库状态添加到新的 AOF 文件中,且同时服务器执行的写指令会添加到 AOF 重写缓冲区,这个过程中主进程不会阻塞。当子进程执行完毕时,向父进程发送信号,父进程调用处理函数,此时阻塞,并将 AOF 重写缓冲区中的内容添加到新的 AOF 文件,然后重命名新 AOF 文件,原子地覆盖旧文件。通过此设计可以在保证数据一致性的情况下,将 AOF 重写对服务器性能影响降到最低。
正常情况下,Redis 只会将对数据库进行修改的命令写入 AOF 文件,PUBSUB和SCRIPT LOAD是例外,因为其会修改客户端标志。当然写入的SELECT也是例外。
3.5.事件
Redis 服务器需要处理以下两类事件:
- 文件事件(file event):Redis 服务器通过套接字与客户端(或者其他 Redis 服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
- 时间事件(time event):Redis 服务器中的一些操作(比如 serverCron 函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
3.5.1.文件事件
文件事件处理器构成:
-
I/O 多路复用程序:负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。
因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现,但 I/O 多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,通过该队列有序、同步、每次一个套接字的方式向文件事件分派器传送套接字,上个套接字产生的事件处理完毕才会传送下一个套接字。
I/O 多路复用程序是包装在 select、epoll、evport、kqueue 等函数库实现的,他们实现了相同 API,程序编译时会利用
#include宏自动选择系统中性能最高的函数库作为实现。 -
文件事件分派器:接收 I/O 多路复用程序传来的套接字,并根据套接字产生的事件的类型,调用相应的事件处理器。
-
事件处理器:为一个个函数。服务器会为执行不同任务的套接字关联不同的事件处理器。
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。I/O 多路复用程序可以监听多个套接字的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件:
- 当套接字变得可读时(客户端对套接字执行 write 操作,或者执行 close 操作),或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行 connect 操作),套接字产生 AE_READABLE 事件。
- 当套接字变得可写时(客户端对套接字执行 read 操作),套接字产生 AE_WRITABLE 事件。
常用事件处理器:
-
连接应答处理器(networking.c/acceptTcpHandler):用于对连接服务器监听套接字的客户端进行应答,具体实现为 sys/socket.h/accept 函数的包装。
当 Redis 服务器进行初始化的时候,程序会将这个连接应答处理器和服务器监听套接字的 AE_READABLE 事件关联起来,当有客户端用 sys/socket.h/connect 函数连接服务器监听套接字的时候,套接字就会产生 AE_READABLE 事件,引发连接应答处理器执行,并执行相应的套接字应答操作,
-
命令请求处理器(networking.c/readQueryFromClient):负责从套接字中读入客户端发送的命令请求内容,具体实现为 unistd.h/read 函数的包装。
当一个客户端通过连接应答处理器成功连接到服务器之后,服务器会将客户端套接字的 AE_READABLE 事件和命令请求处理器关联起来,当客户端向服务器发送命令请求的时候,套接字就会产生 AE_READABLE 事件,引发命令请求处理器执行,并执行相应的套接字读入操作。在客户端连接服务器的整个过程中,服务器都会一直为客户端套接字的 AE_READABLE 事件关联命令请求处理器。
-
命令回复处理器(networking.c/sendReplyToClient):负责将服务器执行命令后得到的命令回复通过套接字返回给客户端,具体实现为 unistd.h/write 函数的包装。
当服务器有命令回复需要传送给客户端的时候,服务器会将客户端套接字的 AE_WRITABLE 事件和命令回复处理器关联起来,当客户端准备好接收服务器传回的命令回复时,就会产生 AE_WRITABLE 事件,引发命令回复处理器执行,并执行相应的套接字写入操作。当命令回复发送完毕之后,服务器就会解除命令回复处理器与客户端套接字的 AE_WRITABLE 事件之间的关联。
一次完整客户端与服务器连接事件示例:
-
Redis 服务器正在运作,监听套接字的 AE_READABLE 事件应该正处于监听状态之下,而该事件所对应的处理器为连接应答处理器。
-
Redis 客户端向服务器发起连接时,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行。
处理器会对客户端的连接请求进行应答,然后创建客户端套接字,以及客户端状态, 并将客户端套接字的 AE_READABLE 事件与命令请求处理器进行关联,使得客户端可以向主服务器发送命令请求。
-
客户端向主服务器发送一个命令请求时,客户端套接字将产生 AE_READABLE 事件,引发命令请求处理器执行,处理器读取客户端的命令内容,然后传给相关程序去执行。
执行命令将产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 AE_WRITABLE 事件与命令回复处理器进行关联。
当客户端尝试读取命令回复的时候,客户端套接字将产生 AE_WRITABLE 事件,触发命令回复处理器执行,当命令回复处理器将命令回复全部写入到套接字之后,服务器就会解除客户端套接字的 AE_WRITABLE 事件与命令回复处理器之间的关联。
3.5.2.时间事件
Redis 的时间事件分为定时事件(在指定时间执行一次)和周期性事件(每隔一段时间执行一次)。一个时间事件由以下属性组成:
-
id:服务器为时间事件创建的全局唯一 ID(标识号),越大事件约新。
-
when:时间事件到达时的 UNIX 时间戳(毫秒精度)。
-
timeProc:时间事件处理器,一个函数。
该函数返回值为 ae.h/AE_NOMORE 时表示定时事件;否则为周期性事件,返回值为下次该事件到达的时间间隔。
目前版本的 Redis 只使用周期性事件,而没有使用定时事件。
服务器将所有时间事件都放在一个无序链表(该无序指的不是 id 而是 when)中,每当时间事件执行器运行时,它就遍历整个链表,查找所有已到达的时间事件,并调用相应的事件处理器。
在目前版本中,正常模式下的 Redis 服务器只使用 serverCron 一个时间事件,而在 benchmark 模式下,服务器也只使用两个时间事件。在这种情况下,服务器几乎是将无序链表退化成一个指针来使用,所以使用无序链表来保存时间事件,并不影响事件执行的性能。
redis.c/serverCron 函数主要工作:
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 关闭和清理连接失效的客户端。
- 尝试进行 AOF 或 RDB 持久化操作。
- 如果服务器是主服务器,那么对从服务器进行定期同步。
- 如果处于集群模式,对集群进行定期同步和连接测试。
Redis2.6 的 serverCron 默认每隔 100 毫秒就会执行一次,Redis2.8 开始可通过
hz选项修改。
3.5.3.事件驱动
Redis 服务器是一个事件驱动程序,其主函数伪代码实现如下:
def main():
init_server() # 初始化服务器
while server_is_not_shutdown(): # 一直处理事件,直到服务器关闭为止
aeProcessEvents()
clean_server() # 服务器关闭,执行清理操作
ae.c/aeProcessEvents 函数负责事件的调度和执行。该函数中首先估计最接近的时间事件到达时间,然后阻塞直到文件事件产生或到达该估计时间(该gu'ji小于当前时间不阻塞),然后在依次处理产生的文件事件和到达的时间事件。
对文件事件和时间事件的处理都是同步、有序、原子地执行的,服务器不会中途中断事件处理,也不会对事件进行抢占。因此,不管是文件事件的处理器,还是时间事件的处理器,它们都会尽可能地减少程序的阻塞时间,并在有需要时主动让出执行权,从而降低造成事件饥饿的可能性。
3.6.多机数据库
3.6.1.复制
在 Redis 中,用户可以通过执行SLAVEOF命令或者设置 slaveof 选项,让一个服务器去复制另一个服务器。
Redis 的复制功能分为同步和命令传播两个操作:
- 同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
- 命令传播操作则用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
同步操作的执行过程:
- 从服务器向主服务器发送
SYNC命令。 - 收到
SYNC命令的主服务器执行BGSAVE命令,在后台生成一个 RDB 文件,并使用一个缓冲区记录从现在开始执行的所有写命令。 - 当主服务器的
BGSAVE命令执行完毕时,主服务器会将BGSAVE命令生成的 RDB 文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。 - 主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。
命令传播的执行过程:
- 在同步操作执行完毕之后,主服务器会将自己执行的写命令,也即是造成主从服务器不一致的那条写命令,发送给从服务器执行。
旧版复制存在缺陷,当处于命令传播阶段的主从服务器因为网络原因而中断了复制,重连之后,有得使用包含所有数据的 RDB 文件来重新同步,效率低。Redis2.8 开始使用PSYNC代替SYNC来执行同步操作。
PSYNC的完整重同步与SYNC的同步过程相同,但它还有部分重同步模式。PSYNC重同步基于以下几点:
-
主从服务器含有各自的运行 ID以及复制偏移量,主服务器存在复制积压缓冲区。
-
从服务器对主服务器进行初次复制时,主服务器会将自己的运行 ID 传送给从服务器,而从服务器则会将这个运行 ID 保存起来。
-
主服务器每次向从服务器传播 N 字节数据时,主服务器的复制偏移量加上 N;从服务器每次接受主服务器的 N 字节数据时,从服务器的复制偏移量加上 N。
-
复制积压缓冲区是由主服务器维护的一个固定长度先进先出队列,默认大小为 1MB。主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区里面。
复制积压缓冲区的大小最好设为 $ 2 \times second \times write_size_per_second $,second 为重连时间(单位秒),write_size_per_second 是主服务器每秒产生写命令数据量(协议格式命令长度和)。
PSYNC(重)同步实现机理如下:
-
从服务器以前未进行过同步,或者执行过
SLAVEOF no one,从服务器发送PSYNC ? -1请求完整重同步。从服务器以前进行过复制,开启新的复制时发送
PSYNC <runid> <offset>。 -
主服务器返回
+FULLRESYNC <runid> <offset>,表示进行完整重同步操作。主服务器返回
+CONTINUE,表示进行部分重同步操作。主服务器返回
-ERR,表示主服务器版本低于 Redis2.8,识别不了PSYNC,从服务器将向主服务器发送SYNC进行同步。
复制功能实现步骤:
-
设置主服务器的地址和端口
SLAVEOF是一个异步操作,完成 masterhost 和 masterport 设置后返回"OK",实际复制工作之后进行。 -
建立套接字连接
-
发送
PING命令 -
身份验证
从服务器设置了 masterauth 选项时将进行身份验证,向主服务器发送
AUTH命令;同时,masterauth 选项被设置时也需要主服务器设置 requirepass 选项。 -
发送端口信息
从服务器发送
REPLCONF listening-port <port-number>,主服务器中的客户端状态的 slave_listening_port 保存从服务器的监听端口。 -
同步
在该步骤之前,从服务器是主服务器的客户端,而此时他们互相成为客户端。
-
命令传播
命令传播阶段,从服务器默认每秒一次向主服务器发送REPLCONF ACK <replication_offset>以实现心跳检测。有以下作用:
-
检测主从服务器的网络连接状态。
主服务器中发送
INFO replication显示的 lag 表示相应从服务器最后一次向主服务器发送REPLCONF ACK过了多少秒。 -
辅助实现 min-slaves 配置选项。
主服务器中设置 min-slaves-to-write 表示主服务器执行写命令要求的最少从服务器数量,设置 min-slaves-max-lag 表示主服务器执行写命令要求的从服务器目前最大延迟不能超过多少。
-
检测命令丢失
通过 replication_offset 与服务器的 offset 比较来检查是否同步,未同步则进行重同步。
REPLCONF ACK是 Redis2.8 新增的,之前版本中出现传播过程中的命令丢失不会被发觉而采取任何行动。
3.6.2.Sentinel
启动一个 Sentinel 可使用:
redis-sentinel /path/to/your/sentinel.conf
redis-server /path/to/your/sentinel.conf --sentinel
当一个 Sentinel 启动时,它需要执行以下步骤:
-
初始化服务器。
Sentinel 与普通 Redis 服务器启动类似但不完全相同,其包含各个主要功能使用情况使用如下:
![]()
-
将普通 Redis 服务器使用的代码替换成 Sentinel 专用代码。
如:
-
普通 Redis 服务器的服务器端口被替换为 Sentinel 专用的端口:
#define REDIS_SERVERPORT 6379#define REDIS_SENTINEL_PORT 26379 -
普通 Redis 服务器使用 redis.c/redisCommandTable 作为服务器的命令表,而 Sentinel 使用 sentinel.c/sentinelcmds 作为命令表:
// sentinel.c struct redisCommand sentinelcmds[] = { {"ping", pingCommand,1, "", 0, NULL, 0, 0, 0, 0, 0}, {"sentinel", sentinelCommand, -2, "", 0, NULL, 0, 0, 0, 0, 0}, {"subscribe", subscribeCommand, -2, "", 0, NULL, 0, 0, 0, 0, 0}, {"unsubscribe", unsubscribeCommand, -1, "", 0, NULL, 0, 0, 0, 0, 0}, {"psubscribe", psubscribeCommand, -2, "", 0, NULL, 0, 0, 0, 0, 0}, {"punsubscribe", punsubscribeCommand, -1, "", 0, NULL, 0, 0, 0, 0, 0}, {"info", sentinelInfoCommand, -1, "", 0, NULL, 0, 0, 0, 0, 0} };Sentinel 中
INFO使用 sentinelInfoCommand 而不是 infoCommand。
-
-
初始化 Sentinel 状态。
接下来会初始化 sentinel.c/sentinelState 结构,该结构保存服务器中与 Sentinel 功能相关的状态。
// sentinel.c struct sentinelState { uint64_t current_epoch; // 当前纪元,用于实现故障转移 dict *masters; // 保存所有被该 sentinel 监视的主服务器,键为主服务器名,值为指向 sentinelRedisInstance 结构的指针 int tilt; // 是否进入了 TILT 模式 mstime_t tilt_start_time; // 进入 TILT 模式的时间 int running_scripts; // 目前正在执行的脚本的数量 list *scripts_queue; // 一个 FIFO 队列,包含了所有需要执行的用户脚本 mstime_t previous_time; // 最后一次执行时间处理器的时间 } sentinel; -
根据给定的配置文件,初始化 Sentinel 的监视主服务器列表。
即初始化 sentinelState 的 masters。每个 sentinelRedisInstance 结构代表一个被 Sentinel 监视的 Redis 服务器实例,这个实例可以是主服务器、从服务器,或者另外一个 Sentinel。
typedef struct sentinelRedisInstance { int flags; // 标识值,记录了实例的类型,以及该实例的当前状态。主服务器为 SRI_MASTER,从服务器为 SRI_SLAVE char *name; // 实例的名字。主服务器的名字由配置文件设置;从服务器以及 Sentinel 的名字由 Sentinel 自动设置,格式为 ip:port。 char *runid; // 实例的运行ID、 uint64_t config_epoch; // 配置纪元,用于实现故障转移 sentinelAddr *addr; // 实例的地址 mstime_t down_after_period; // 判断为主观下线时间 int quorum; // 判断为客观下线所需的支持投票数量 int parallel_syncs; // 在执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量(SENTINEL parallel-syncs <master-name> <number> 选项)。 mstime_t failover_timeout; // 刷新故障迁移状态的最大时限(SENTINEL failover-timeout <master-name> <ms> 选项)。 // slave_master_host、slave_master_port、slave_master_link_status、slave_repl_offset、slave_priority... } sentinelRedisInstance;// sentinel.c typedef struct sentinelAddr { char *ip; int port; } sentinelAddr; -
创建连向主服务器的网络连接。
创建连向被监视主服务器的网络连接,Sentinel 将成为主服务器的客户端。对于每个被 Sentinel 监视的主服务器来说,Sentinel 会创建两个连向主服务器的异步网络连接:
- 命令连接,这个连接专门用于向主服务器发送命令,并接收命令回复。
- 订阅连接,这个连接专门用于订阅主服务器的 _sentinel_:hello 频道。

Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,并通过分析 INFO 命令的回复来获取主服务器的当前信息,主要有:
- 关于主服务器本身的信息,包括 run_id 域记录的服务器运行 ID,以及 role 域记录的服务器角色。
- 关于主服务器属下所有从服务器的信息,如 ip 和 port。
根据这些信息,Sentinel 对对应实例结构进行新建/更新。如果从服务器信息是新的,除了新建实例结构,还会建立命令连接和订阅连接。创建连接后,默认十秒一次通过命令连接向从服务器发送 INFO 命令,主要获取以下信息:
- 从服务器的运行 ID 以及角色。
- 主服务器的 IP 地址 master_host 以及端口号 master_port。
- 主从服务器的连接状态 master_link_status。
- 从服务器的优先级 slave_priority。
- 从服务器的复制偏移量 slave_repl_offset。
当 Sentinel 与一个主服务器或者从服务器建立起订阅连接之后, Sentinel 就会通过订阅连接,向服务器发送以下命令:
SUBSCRIBE _sentinel_:hello
在默认情况下,Sentinel 会以每两秒一次的频率,通过命令连接向所有被监视的主服务器和从服务器发送以下格式的命令:
PUBLISH _sentinel_:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>"
s_开头的是 Sentinel 相关信息,m_开头的是主服务器相关信息。
Sentinel 既通过命令连接向服务器的 __sentinel__:hello 频道发送信息,又通过订阅连接从服务器的 __sentinel__:hello 频道接收信息。分析该频道获取的订阅信息,如果是自己发送的则忽略,如果是其它 Sentinel 发送的,则会建立/更新其它 Sentinel 的实例结构,新建的话还会创建一个命令连接(不会建立订阅连接),最终所有 Sentinel 形成一个相互连接的网络。
主服务器故障处理流程:
-
主观下线:
默认情况下,Sentinel 会以每秒一次的频率向所有与它创建了命令连接的实例发送 PING 命令,在 down_after_period 设置(
SENTINEL down-after-milliseconds)时间下没有收到回复则将其判断为主观下线,打开 flags 的 SRI_S_DOWN 标识。SENTINEL down-after-milliseconds选项在 sentinel.conf 设置,是针对该 Sentinel 的主服务器、从服务器以及其它 Sentinel 的实例的设置。不同 sentinel.conf 设置可能不同,所以不同 Sentinel 判断某实例主观下线状态可能不同。 -
客观下线:
一个 Sentinel 将主服务器设置为主观下线后,会向其它 Sentinel 发送以下指令来判断客观下线:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> *ip、port 是主服务器地址。其它 Sentinel 会回复:
<down_state> * 0down_state 为 1 表示目标 Sentinel 也将其判断为下线。当其它 Sentinel 判断主服务器为下线的数量达到 quorum(
SENTINEL monitor <master-name> <IP> <port> <quorum>选项设置)时,将其判断为客观下线,打开 flags 的 SRI_O_DOWN 标识。 -
领头 Sentinel 选举
每个配置纪元中所有 Sentinel 都有一次将某个 Sentinel 设置为局部领头 Sentinel 的机会,局部领头 Sentinel 一旦设置该配置纪元中就不能修改。每次进行领头 Sentinel 选举之后,不论选举是否成功,所有 Sentinel 的配置纪元的值都会自增一次。设置局部领头 Sentinel 的规则是先到先得,如果有某个 Sentinel 被半数以上的 Sentinel 设置为局部领头 Sentinel,则其被设置为领头 Sentinel。给定时限中领头 Sentinel 未被选举成功会再次进行选举。
源 Sentinel 向目标 Sentinel 发送以下指令请求目标 Sentinel 将源 Sentinel 设置为该目标 Sentinel 的局部领头 Sentinel,只有首先到达的会被设置:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>ip、port 是源 Sentinel地址,current_epoch 是源 Sentinel 的当前配置纪元,runid 是源 Sentinel 的运行 id。目标 Sentinel 会回复:
1 <leader_runid> <leader_epoch>leader_runid、leader_epoch 是目标 Sentinel 的局部领头 Sentinel 的运行 id、配置纪元。然后源 Sentinel 比对 epoch、runid 并统计数量来确定是否被选举为领头 Sentinel。
-
故障转移
-
领头 Sentinel 被选举出来后,首先要挑选一个从服务器作为新的主服务器。挑选从服务器过程:首先过滤掉领头 Sentinel 记录的下线、断线的从服务器(确保正常在线),然后过滤掉最近 5 秒没有回复领头 Sentinel
INFO的从服务器(确保是最近成功进行过通信的),再过滤掉与已下线主服务器连接断开超过 $ down \mbox{-} after \mbox{-} milliseconds \times 10 $ 毫秒的从服务器(确保保存的数据是比较新的),最后按照高优先级、偏移量大、run ID 较小的主次条件选择从服务器。然后向选出的从服务器发送
SLAVE no one命令,随后领头 Sentinel 会以每秒一次地向被升级的从服务器发送INFO命令,直到被升级服务器的 role 从原来的 slave 变为 master。 -
向所有其它从服务器发送
SLAVEOF命令让其复制新的主服务器。 -
旧的主服务器在重新上线时,领头 Sentinel 发送
SLAVOF命令让其复制新的主服务器,降级为从服务器。
-
3.6.3.集群
集群通过分片来进行数据共享,并提供复制和故障转移功能。
Redis 服务器在启动时会根据 cluster-enabled 配置选项是否为 yes 来决定是否开启服务器的集群模式。在刚开始的时候, 每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,连接各个节点的工作可以使用CLUSTER MEET <ip> <port>命令来完成。CLUSTER NODES命令查看集群信息。
节点只能使用 0 号数据库。
typedef struct clusterState
{
clusterNode *myself; // 指向当前节点的指针
uint64_t currentEpoch; // 集群当前的配置纪元,用于实现故障转移
int state; // 集群状态:在线还是下线
int size; // 集群中至少处理着一个槽的节点数量
dict *nodes; // 集群节点名单(包括 myself),键为节点名,值为对应的 clusterNode
clusterNode *slots[16384]; // 记录各个槽是被那些节点处理的
zskiplist *slots_to_keys; // 保存数据库键与槽的关系,分值是槽号,值为数据库键
clusterNode *importing_slots_from[16384]; // 当前节点正在从其他节点导入的槽
clusterNode *migrating_slots_to[16384]; // 当前节点正在迁移至其他节点的槽
// ...
}
struct clusterNode
{
mstime_t ctime; // 创建节点时间
char name[REDIS_CLUSTER_NAMELEN]; // 节点名
int flags; // 节点标志,如主节点、从节点、节点状态
uint64_t configEpoch; // 节点当前的配置纪元,用于实现故障转移
char ip[REDIS_IPSTR_LEN]; // IP
int port; // port
clusterLink *link; // 保存连接节点所需的有关信息
unsigned char slots[16384/8]; // 记录该节点处理那些槽
int numslots; // 记录该节点处理的槽数目
struct clusterNode *slaveof; // 如果这是一个从节点,那么指向主节点
int numslaves; // 正在复制这个主节点的从节点数量
struct clusterNode **slaves; // 每个数组项指向一个正在复制这个主节点的从节点的 clusterNode 结构
list *fail_reports; // 记录了所有其他节点对该节点的下线报告,其元素为 clusterNodeFailReport
// ...
}
struct clusterNodeFailReport {
struct clusterNode *node; // 报告目标节点已经下线的节点
mstime_t time; // 最后一次从 node 节点收到下线报告的时间。程序使用这个时间戳来检查下线报告是否过期(与当前时间相差太久的下线报告会被删除)
} typedef clusterNodeFailReport;
typedef struct clusterLink
{
mstime_t ctime; // 连接的创建信息
int fd; // TCP 套接字描述符
sds sndbuf; // 输出缓冲区
sds rcvbuf; // 输入缓冲区
struct clusterNode *node; // 与这个连接相关联的节点
} clusterLink;
CLUSTER MEET命令实现:

节点 A 会为节点 B 创建一个 clusterNode 结构,并将添加到自己的 clusterState.nodes 字典里面。之后,节点 A 将根据CLUSTER MEET命令给定的 IP 地址和端口 号,向节点 B 发送一条MEET消息。如果一切顺利,节点 B 将接收到节点 A 发送的MEET消息,节点 B 会为节点 A 创建一个 clusterNode 结构,并添加到自己的 clusterState.nodes 字典里面。 之后,节点 B 将向节点 A 返回一条PONG消息。如果一切顺利,节点 A 将接收到节点 B 返回的PONG消息,通过这条 PONG 消息节点 A 可以知道节点 B 已经成功地接收到了自己发送的MEET消息。 之后,节点 A 将向节点 B 返回一条PING消息。 如果一切顺利,节点 B 将接收到节点 A 返回的PING消息,通过这条PING消息节点 B 可以知道节点 A 已经成功地接收到了自己返回的PONG消息,握手完成。之后,节点 A 会将节点 B 的信息通过 Gossip 协议传播给集群中的其他节点,让其他节点也与节点 B 进行握手,最终,经过一段时间之后,节点 B 会被集群中的所有节点认识。
集群的整个数据库被分为 16384 个槽,集群中的每个节点可以处理 0 个或最多 16384 个槽。当数据库中的 16384 个槽都有节点在处理时,集群处于上线状态,否则任意一个槽没有处理则处于下线状态。CLUSTER ADDSLOTS <slot> [slot ...]命令指定节点处理那些槽,其中一个 slot 已被其它节点处理时整个配置都会失败。
计算某个键处于哪个槽是使用键的 CRC-16 校验和和 16383 进行与操作。CLUSTER KEYSLOT <key>命令可查看键位于哪个槽。如果对应键是使用当前节点的槽,那么会直接处理,否则,会向客户端返回MOVED错误,客户端根据MOVED错误中提供的 IP 地址和端口号,转向至负责处理对应槽的节点,并向该节点重新发送之前想要执行的命令。
集群模式的客户端在接收到
MOVED错误时,并不会打印出MOVED错误,而是根据MOVED错误自动进行节点转向。单机模式的客户端收到MOVED错误会打印,它不清楚MOVED错误的作用。
CLUSTER GETKEYSINSLOT <slot> <count>命令可以返回最多 count 个属于槽 slot 的数据库键。
Redis 集群的重新分片操作可以将任意数量已经指派给某个节点的槽改为指派给另一个节点,并且相关槽所属的键值对也会从源节点被移动到目标节点。此操作可在线进行。
Redis 集群的重新分片操作是由 Redis 的集群管理软件 redis-trib 负责执行的,其对集群的单个槽 slot 进行重新分片的步骤如下:
-
redis-trib 对目标节点发送
CLUSTER SETSLOT <slot> IMPORTING <source_id>命令,让目标节点准备好从源节点导入属于槽 slot 的键值对。 -
redis-trib 对源节点发送
CLUSTER SETSLOT <slot> MIGRATING <target_id>命令,让源节点准备好将属于槽 slot 的键值对迁移至目标节点。 -
redis-trib 向源节点发送
CLUSTER GETKEYSINSLOT <slot> <count>命令,获得最多 count 个属于槽 slot 的键值对的键名。 -
对于步骤 3 获得的每个键名,redis-trib 都向源节点发送一个
MIGRATE <target_ip> <target_port> <key_name> 0 <timeout>命令,将被选中的键原子地从源节点迁移至目标节点。 -
重复执行步骤 3 和步骤 4,直到源节点保存的所有属于槽 slot 的键值对都被迁移至目标节点为止。
![]()
-
redis-trib 向集群中的任意一个节点发送
CLUSTER SETSLOT <slot> NODE <target_id>命令,将槽 slot 指派给目标节点,这一指派信息会通过消息发送至整个集群,最终集群中的所有节点都会知道槽 slot 已经指派给了目标节点。

在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面的情况。此时如果发送的指令位于迁移槽中,会先检查该节点数据库中是否存在键,有则直接在该节点执行,否则会向客户端返回ASK错误,指引客户端转向正在导入槽的目标节点,客户端首先向目标节点发送一个ASKING命令,之后再重新发送原本想要执行的命令。
与
MOVED类似,集群下客户端接收到ASK错误不会打印而是转向对应目标节点,单机下会打印ASK错误。
ASKING命令唯一要做的就是打开发送该命令的客户端的 REDIS_ASKING 标识。在一般情况下,如果客户端向节点发送一个关于槽 i 的命令,而槽 i 又没有指派给这个节点的话,那么节点将向客户端返回一个MOVED错误;但是,如果节点的 clusterState.importing_slots_from[i] 显示节点正在导入槽 i,并且发送命令的客户端带有 REDIS_ASKING 标识,那么节点将破例执行这个关于槽 i 的命令一次。当客户端接收到ASK错误并转向至正在导入槽的节点时,客户端会先向节点发送一个ASKING命令,然后才重新发送想要执行的命令,这是因为如果客户端不发送ASKING命令,而直接发送想要执行的命令的话,那么客户端发送的命令将被节点拒绝执行,并返回MOVED错误。另外要注意的是,客户端的REDIS_ASKING标识是一个一次性标识,当节点执行了一个带有REDIS_ASKING标识的客户端发送的命令之后,客户端的REDIS_ASKING标识就会被移除。

CLUSTER REPLICATE <node_id>可以让接收命令的节点成为 node_id 所指定节点的从节点,并开始对主节点进行复制:
- 接收到该命令的节点首先会在自己的 clusterState.nodes 字典中找到 node_id 所对应节点的 clusterNode 结构,并将自己的 clusterState.myself.slaveof 指针指向这个结构,以此来记录这个节点正在复制的主节点。
- 然后节点会修改自己在 clusterState.myself.flags 中的属性,关闭原本的 REDIS_NODE_MASTER 标识,打开 REDIS_NODE_SLAVE 标识,表示这个节点已经由原来的主节点变成了从节点。
- 最后,节点会调用复制代码,并根据 clusterState.myself.slaveof 指向的 clusterNode 结构所保存的 IP 地址和端口号,对主节点进行复制。因为节点的复制功能和单机 Redis 服务器的复制功能使用了相同的代码,所以让从节点复制主节点相当于向从节点发送命令
SLAVEOF。
一个节点成为从节点,并开始复制某个主节点这一信息会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。
故障处理:
-
集群中的每个节点都会定期地向集群中的其他节点发送
PING消息,以此来检测对方是否在线,如果接收PING消息的节点没有在规定的时间内,向发送PING消息的节点返回PONG消息,那么发送PING消息的节点就会将接收PING消息的节点标记为疑似下线(打开对应 clusterNode 结构 flags 属性的 REDIS_NODE_PFAIL 标识)。 -
集群中的各个节点会通过互相发送消息的方式来交换集群中各个节点的状态信息。当一个主节点 A 通过消息得知主节点 B 认为主节点 C 进入了疑似下线状态时,那么 A 节点会向 C 节点的 clusterNode 中 fail_reports 链表添加下线报告。
-
如果在一个集群里面,半数以上负责处理槽的主节点都将某个主节点 x 报告为疑似下线,那么这个主节点 x 将被标记为已下线, 将主节点 x 标记为已下线的节点会向集群广播一条关于主节点 x 的
FAIL消息,所有收到这条FAIL消息的节点都会立即将主节点 x 标记为已下线。 -
当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移:
-
复制下线主节点的所有从节点里面,会有一个从节点被选中。
选举方法与领头 Sentinel 选举类似,当从节点发现自己正在复制的主节点进入已下线状态时,从节点会向集群广播一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票。每个参与选举的从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,如果收到的主节点支持票大于主节点数量的一半,这个从节点就会当选为新的主节点。 -
被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点。 -
新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
-
新的主节点向集群广播一条
PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。 -
新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
-
陆鑫,张凤荔,陈安龙.数据库系统:原理、设计和编程[M].北京:人民邮电出版社,2019-03:1-229. ↩︎
唐汉明,翟振兴,关宝军,王洪权,黄潇.深入浅出 MySQL[M].北京:人民邮电出版社,2014-06-05:1-288. ↩︎
黄健宏.Redis 设计与实现[M].北京:机械工业出版社,2014-04:1-388. ↩︎
runoob.com.Redis 教程[EB/OL].yyyy-MM-dd.https://www.runoob.com/redis. ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号