


1.RabbiMQ
在公司业务实际使用中发现以下问题
- 同步发送
- 业务代码一版采用queue处理可异步执行的非核心业务,但是业务代码大多数情况下投递消息都使用同步接口,可能会阻塞整个请求。
- 连接block问题:
- 内存达到一定比例后会阻塞生产者继续发送消息
- Rabbimq积压,Rabbimq io过高都会引起消息投递block
- 使用上
- 发没发不知道,发了什么内容不知道(除非业务代码打印日志),无法追溯
- 消息丢失问题
- 项目中很多Queue的属性配置是写在代码中,一旦选择错误,则在某些场景会造成消息丢失。
- Queue属性 - durable/transient transient消息存在内存中,如果Rabbimq重启则消息丢失。
- 没有启用confirm机制,消息有没有正确的投递到队列中不能保证。
- exchange没有绑定queue或绑定不对
- queue所在节点挂了,用户无感知
2.Kafka
1.支持积压大量消息
2.自动容灾,高可用
3.单实例partition/topic过多会导致吞吐下降
4.适合大吞吐业务(比如用于日志采集),不适合小吞吐业务(资源浪费)
注意点kafka的每个partition都会生成一份commitlog,一个broker上会存在N个topic,所以Kafka的topic数量不能过多。否则会导致pageCache命中率变低,影响吞吐性能。
3.RocketMQ
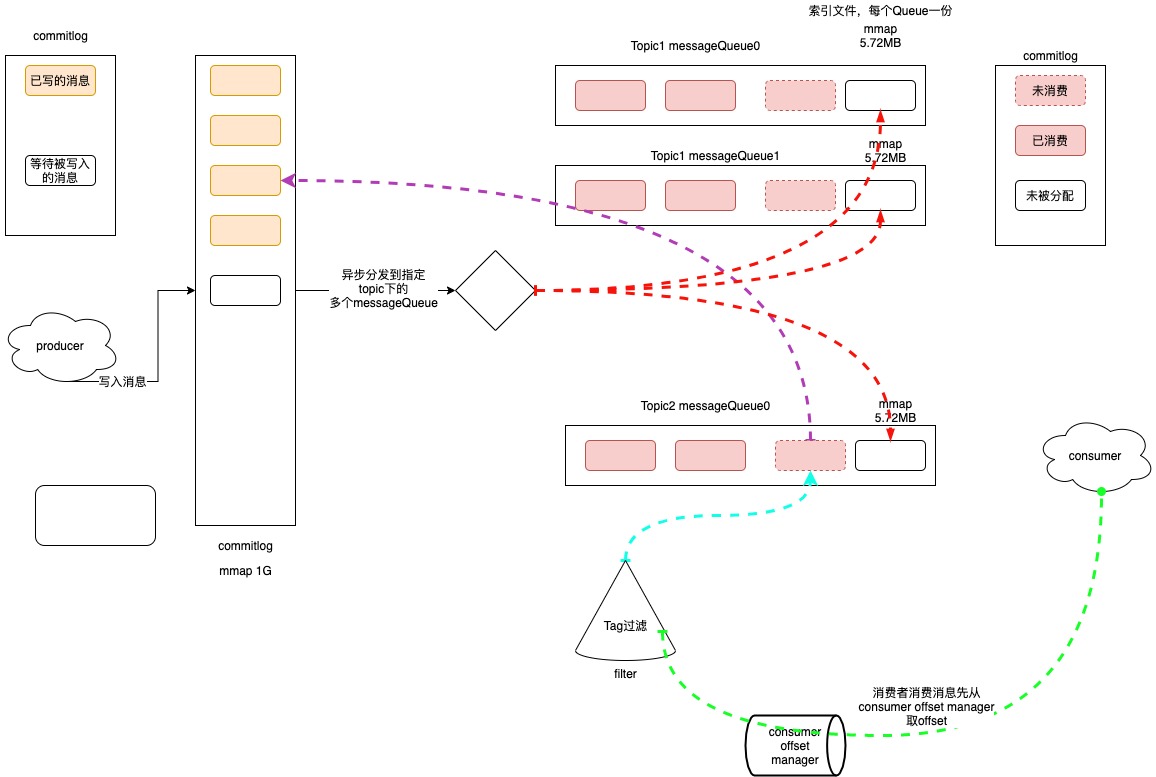
a.消息存取
所有的producer投递的message都会写到统一的一个commitlog中,默认1G,当commitlog写满会根据规则再生成一个commitlog。
RocketMQ底层对CommitLog、ConsumeQueue之类的磁盘文件的读写操作,基本上都会采用mmap技术来实现。如果具体到代码层面,就是基于JDK NIO包下的MappedByteBuffer的map()函数来实现,将一个磁盘文件(比如一个CommitLog文件,或者是一个ConsumeQueue文件)映射到内存里来。省去一次用户态到内核态的拷贝损耗。详细可见:https://blog.csdn.net/qq_42046105/article/details/104218193
rocketmq中会有一个异步线程为commitlog建立索引,通过建立类似索引文件—ConsumeQueue的方式来区分不同Topic下面的不同MessageQueue的消息。
消费者消费时,会先从consumer offset manager中查找offset,找到messageQueue文件,然后在messageQueue文件中读取持久化消息的起始物理位置偏移量offset、大小size和消息Tag的HashCode值,随后再从CommitLog中进行读取待拉取消费消息的真正实体内容部分。
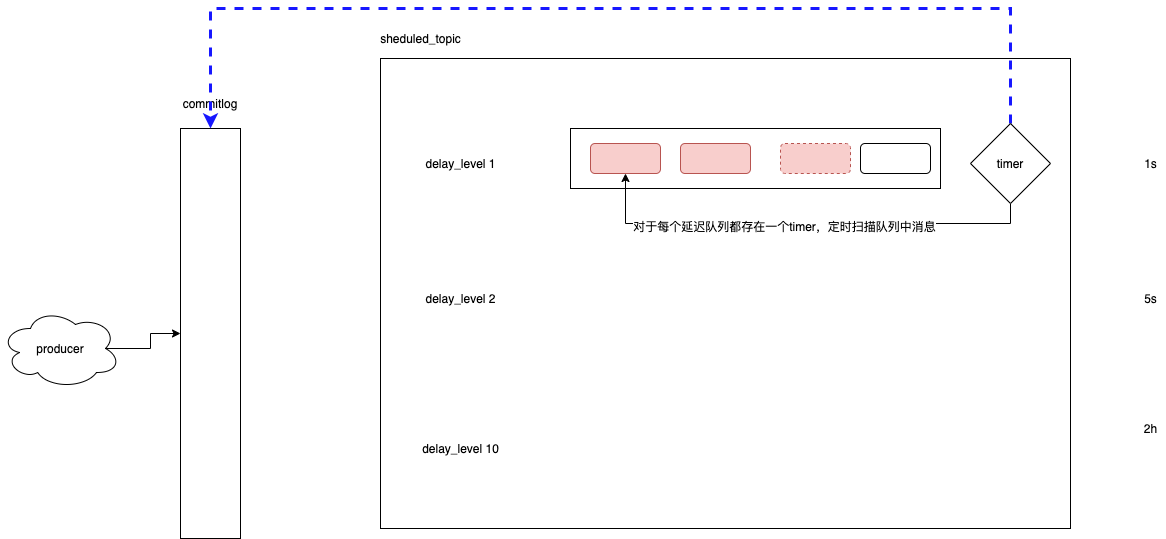
b.延迟队列
RocketMQ中维护一个sheduled_topic,包含多个延迟级别的Queue。对每一个messageQueue,都会维护一个timer定时扫描,达到时间会投递到commitlog,被消费者消费。
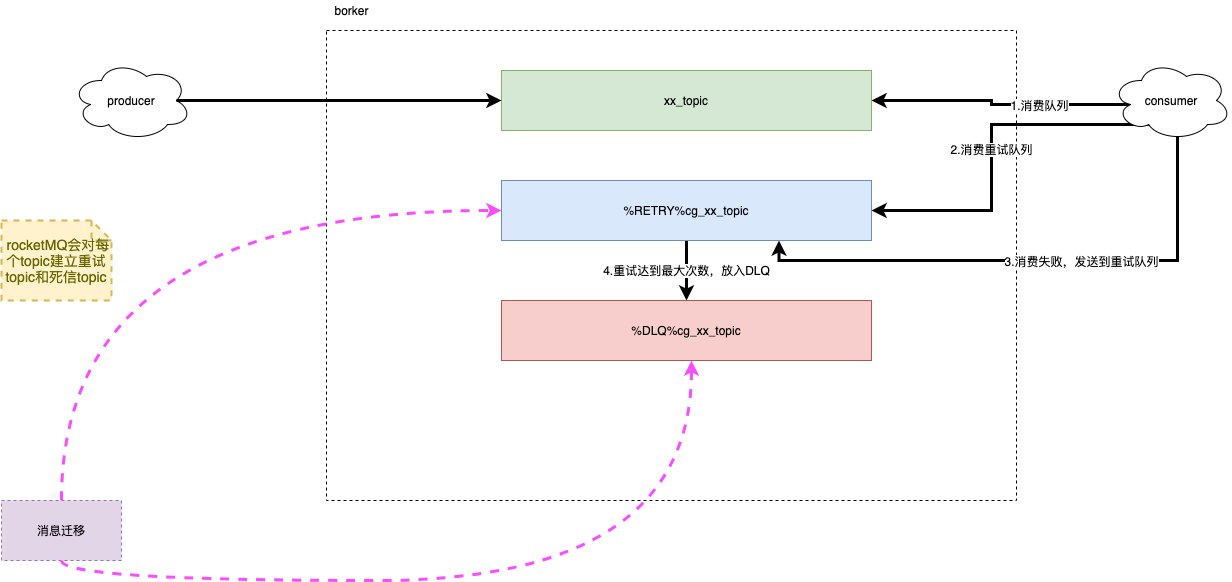
c.死信队列
RocketMQ会对每个topic另外建立两个topic(重试topic和死信topic)
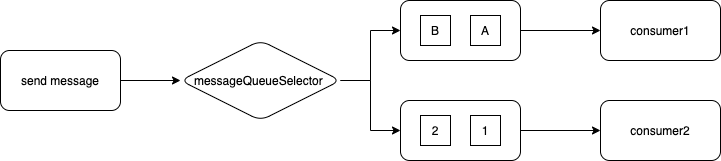
d.有序消息
只能实现MessageQueue的有序,即局部有序,根据自定义路由规则选择需要投递的MessageQueue。
e.事务消息
这部分放在另一篇分布式事务中说。
f.对比Rabbimq和kafka优势劣势
对比Rabbimq优势
支持时间/业务key检索,可重发,自带死信(Rabbimq需要自己配置),使用方便。
抗积压能力强于Rabbimq
高可用
对比Kafka优势
支持时间/业务key检索
能支持更多topic。(这点很适合业务上使用,业务代码一般topic多,流量不是特别巨大)。
劣势:但是所有的topic共用一个commitlog会导致commitlog过期时间是统一的。
一般是系统自定义比如14天,所以14天后消息commitlog中消息会丢失。不能支持topic级别的消息存储时间配置
