康复计划#2 常用基础数论知识杂烩
本篇口胡写给我自己这样的东西都忘光的残废选手…以及那些刚学数论,看了其他的一些东西并且没有完全懂也没有懵逼的人…
大概讲一点非常基础的性质,以及简单的扩展欧几里德算法、中国剩余定理、素性测试、pollardRho的大整数分解什么的…
(数论函数求和呀,默比乌斯反演什么的不够基础,之后专门开一篇写吧)
1、基础知识(前面很简单可以往后跳,或者觉得定义很无聊也可以往后跳,但是毕竟要尽量避免变成民科嘛)
整除
嗯…这个人人都知道啦…不过有些性质对于不熟悉的人并不是很显然…
定义:对于$n,m \in \mathbb{Z}$,如果存在$k \in \mathbb{Z} $,使得$n = mk$,则称$m$整除$n$,记作$m|n$
(注:这里的定义有不同的形式,本篇不做更多的推广,所以直接对整数做出定义)
性质:对于使下列式子有意义的$a,b,c$
(1) $ a|b, b|c \Rightarrow a|c $ (传递性)
(2) $ a|b, c \neq 0 \Rightarrow ac|bc $(同时乘以非零常数)
(3) $ c|a, c|b \Rightarrow \forall m,n \in \mathbb{Z}, c|ma+nb $ (线性组合)
(4) $ a|b, b|a \Rightarrow a=\pm b $ (通过整除关系推相等,在证明中可以用到)
(5*) 若$m,a$的最大公约数为1,则$ m|ab \Rightarrow m|b $ (最大公约数的定义在下面)
证明:(1)(2)(3)(4)只要按照整除的定义写开就可以证明。(5*)的证明留到后面欧几里德算法部分。
带余除法
定理:对于任意$ n,m \in \mathbb{Z}$且$m \neq 0$,存在唯一的$q,r \in \mathbb{Z}$,使得$n=qm+r, 0 \leq r < \left| m \right|$。
定义:上式中的$q$称作$n$除以$m$的不完全商(简称商);$r$称作最小非负余数(简称余数),记作$n \mod m$,这条式子中$m$常称为模数
性质:对于使下列式子有意义的$a,b,m$
(1) $ \left(a \pm b \right) \mod m = \left( \left( a \mod m \right) \pm \left( b \mod m \right) \right) \mod m$
(2) $ \left(a * b \right) \mod m = \left( \left( a \mod m \right) * \left( b \mod m \right) \right) \mod m $
证明:同样很简单,按照性质写开即可…
最大公因数和互质
定义:对于$a_1,a_2,...,a_n \in \mathbb{Z} $,若存在$d$使得$\forall i = 1..n, d|a_i$,则称$d$为这些数的一个公因数。所有公因数中最大的称作最大公因数(GCD),记作$\left( a_1,a_2,...,a_n \right)$。如果这些数的最大公因数为1,则称这些数互质。
(更多性质在下面的欧几里德算法部分会提及哦)
同余
这就是我们所说的“模意义下相等”,虽然这里把基本的东西都给比较严谨地说了一遍,但是其实很多东西都可以在模意义下正确推广的,比如幂级数展开…
定义:对于$a,b,m \in \mathbb{Z}$且$m > 0$,如果$a \mod m = b \mod m$,则称$a$和$b$关于模$m$同余,记作$a \equiv b\pmod{m}$。
性质:
1.同余是$\mathbb{Z}$上的等价关系
(1) $a \equiv a\pmod{m}$ (自反性)
(2) $a \equiv b\pmod{m} \Rightarrow b \equiv a\pmod{m}$ (对称性)
(3) $a \equiv b\pmod{m}, b \equiv c\pmod{m} \Rightarrow a \equiv c\pmod{m}$ (传递性)
2.运算性质:对于使下列式子有意义的$a,b,c,d,m$
(1) $a \equiv b\pmod{m} \Rightarrow ac \equiv bc\pmod{m}$ (注意到这里$c$可以是0了,所以反过来肯定是不对的)
(2) $a \equiv b\pmod{m}, c \equiv d\pmod{m} \Rightarrow a+c \equiv b+d\pmod{m}$
(3) $a \equiv b\pmod{m}, c \equiv d\pmod{m} \Rightarrow ac \equiv bd\pmod{m}$
(4) $a \equiv b\pmod{m} \Rightarrow \forall n \in \mathbb{Z^+}, a^n \equiv b^n\pmod{m} $
(5) $ac \equiv bc\pmod{m} \Rightarrow a \equiv b\pmod{m/\left( c,m \right)}$
证明:
等价关系可以直接使用定义证明。运算性质(1)(2)(3)的证明只需要把$a \equiv b\pmod{m}$改写成整除关系$m|a-b$,即可通过整除的性质证明。运算性质(4)可以通过归纳法利用性质(3)证明。
这里给出性质(5)的证明(这个性质大概是最有用的啦,因为上面那些都很符合直觉,这个稍微有点不同)
令$d=\left( c,m \right)$,原条件等价于$m|ac-bc$即存在$k \in \mathbb{Z}$使得$ac-bc=km$,所以有$\left( a-b \right) \frac{c}{d}=k \frac{m}{d}$,因为$d$是$c,m$的最大公约数,其中$\left( \frac{c}{d}, \frac{m}{d} \right) = 1$,然后利用整除的性质(5*),得到$\frac{m}{d}|a-b$,转化为同余形式即得证。
剩余系
应该是初学时听不懂的第一个词,其实就是把整数按照余数分类…不要被吓怕就行了…
把所有模$m$同余的整数放在一个集合里,这个集合就叫做剩余类,表示成$\left[ a \right]_m$,其中a是集合内任意一个元素(称为代表)。
比如集合${...,-5,-2,1,4,7,...}$就是模3的一个剩余类,可以记作$\left[ -5 \right]_3$,也可以记作$\left[ 1 \right]_3$,不过为了方便我们一般选择$0$到$m-1$的数做代表…另外还是为了方便,有时也省略方括号,直接用余数表示剩余类…
把这些剩余类放在一起就叫剩余系了…如果这些剩余类能够涵盖所有整数,那么称这个剩余系是完全剩余系。
如果这个完全剩余系写得很好看,代表全取了最小非负的代表,那么就把它叫做标准剩余系,然而其实并没有区别,还要让新人多记一个名词,真麻烦…
接下来有个定理,说明在模意义下进行满足某些条件的映射是一个置换,简单的理解为做了这些操作后剩余系大蛋糕不会突然少掉一块。
定理:(平移法则)如果$S = {a_1,a_2,...,a_m}$是模m的一个完全剩余系,则对于$k,b \in \mathbb{Z}$且$\left( k,m \right)=1$,有$S' = {ka_1+b,ka_b+b,...,ka_m+b}$也是模m的一个完全剩余系。
证明:因为这里面有$m$个剩余类,如果$S'$不是完全剩余系就意味着其中有两个剩余类重复了,所以我们只要证明$\forall i \neq j , ka_i+b \not \equiv ka_j+b\pmod{m}$就好了…可以通过反证法,假设$ka_i+b \equiv ka_j+b\pmod{m}$,根据同余性质,推出$a_i \equiv a_j\pmod{m}$,与原本的S是完全剩余系矛盾,故得证。
还有一个定义是既约剩余系,就是在完全剩余系中去掉那些不和模数$m$互质的剩余类。比如模6的既约剩余系是${[1]_6,[5]_6}$,因为$[0]_6,[2]_6,[3]_6,[4]_6$里的元素不与6
互质。显然模$m$的既约剩余系大小等于不超过$m$的与$m$互质的非负整数个数,记作$\phi \left( m \right)$。这个$\phi$就是欧拉函数。
下面给出非常重要的一个定理,在模意义下运算离不开它~
欧拉定理:$a,m \in \mathbb{Z}, m>0, \left( a,m \right)=1 \Rightarrow a^{\phi \left( m \right) } \equiv 1\pmod{m}$。
证明:首先我们要在既约剩余系上弄出一个和上面的平移法则类似的性质,不过平移法则的“+b”在这里不成立,因为不能保证互质,但是乘以一个和模数互质的$k$还是可以的,证明上没什么区别,所以不再展开讲。接着,如果两个剩余系相同,那么它们里面的剩余类其实都是一样的,所以取出剩余类的代表元做乘积也是模意义下相同的。
$$ k^{\phi \left ( m \right ) }\prod_{i=1}^{\phi \left ( m \right )}a_i = \prod_{i=1}^{\phi \left ( m \right )}\left ( ka_i \right ) \equiv \prod_{i=1}^{\phi \left ( m \right )} a_i\pmod{m} $$
式子里的$a_i$代表既约剩余系内的元素。接着看最左和最右,因为既约剩余系的元素都与模数互质,所以应用同余的性质可以除掉$\prod_{i=1}^{\phi \left ( m \right )}a_i$,模数变为$m/1=m$,于是得到$k^{\phi \left( m \right) } \equiv 1\pmod{m}$,欧拉定理就得证啦~(剩余系的证法还是比较简洁的)
欧拉定理特殊化一点就是费马小定理,不过费马小定理的条件稍微有些不同。费马小定理是对于素数模数$p$,有$a^p \equiv a\pmod{p}$。不需要欧拉定理的互质条件了。不过稍微想想就知道是一样的,$p$都是质数了,再不互质的话就只能是同余0了,0显然符合费马小定理,然后如果排除了0的情况,就可以直接除掉一个$a$变成欧拉定理的形式。所以不用刻意来记。
基础知识部分先讲到这里…虽然还有一些东西没有提,但是在下面的具体的算法中如果需要用上,都会在下面证明的。(如果有人不想知道证明的话也可以直接跳)
2、扩展欧几里德算法
扩展欧几里德算法,其实就是欧几里德算法,只是我们的目的有所变化而已。欧几里德算法的直接用处就是求最大公约数,但是它其实非常精妙,它可以给出一个不定方程的解,并且这一点可以证明它自己是正确的(自证明的算法)。
欧几里德算法:对于正整数$a,b$,
初始令$r_0=a,r_1=b$,对于$i \geq 2 $由上面的带余除法可以写成$r_{i-2}=r_{i-1}q_{i-1}+r_i$的形式,其中$0 \leq r_i < r_{i-1}$。不断导出新的$r_i$直到$r_i$第一次出现0,这时得到$\left( a,b \right)$为最后一个非零的余数$r_{i-1}$。
分析:这个算法有很多地方需要分析,我们要证明它能够停止,还要证明它是对的。
首先我们证明它能够停止。注意到我们导出的形式里对于$i \geq 2$有$r_i < r_{i-1}$,所以这是一个比模数大的数取模的过程,它的商至少为1。所以如果$r_{i-2}/2 < r_{i-1}$,那么$r_i=r_{i-2}-r_{i-1}<r_{i-2}/2$,如果$r_{i-2}/2 \geq r_{i-1}$,那么$r_i<r_{i-1} \leq r_{i-2}$。所以无论如何有$r_i<r_{i-2}/2$,也就是说它的大小每两步就减半了,所以只需要$O(\log n)$步就会得到结果。
至于正确性,我们之前说过这是一个自证明的算法,下面就看看它是怎么做到的。欧几里德算法可以得到$a'a+b'b=\left( a,b \right)$这个不定方程的解。因为我们只要逆着上面的过程做就好了,把$r_{i-2}=r_{i-1}q_{i-1}+r_i$移项,变成$r_i=r_{i-2}-r_{i-1}q_{i-1}$,然后对着$r_{i-2}$和$r_{i-1}$用这条式子,最后化成用$r_0$和$r_1$两个数表示的形式,它们的系数就是不定方程的解了。(求解这个不定方程的过程就叫做扩展欧几里德算法)接下来看看它为什么是对的。我们知道,因为$d$是$a$和$b$的公因数,可以分别整除它们两个,根据性质有$d|a'a+b'b$,也就是说$d$整除欧几里德算法返回的结果,那么$d$不可能比这个结果还大(因为要整除),所以这个结果就是真正的最大公因数。干得漂亮~
算法就讲到这里,现在我们补回第一部分遗留的一些问题。欧几里德算法还能给我们的证明带来方便。看下面这个命题:
对于$a,b,c \in \mathbb{Z}$,有$\left( ac,bc \right) = \left( a,b \right) \left| c \right|$。
证明的话,我们只要在欧几里德算法的过程中,把每个$r_i$都乘以$|c|$,容易发现式子的性质仍然保留,所以得到的结果就是$\left( a,b \right) \left| c \right|$
通过这个我们可以得到:如果$\left( a,x \right)=1$,有$\left( a, bx \right) = \left( a,b \right)$
证明:因为$\left( a, bx \right)$能够分别整除$a$和$bx$,所以$\left( a, bx \right)|\left( ab, bx \right)$,利用上面的结果得到$\left( ab, bx \right)=\left( a, x \right)|b|=|b|$,于是$\left( a, bx \right)|b$,又因为它本身是$a$的因数,所以它是$a$和$b$的公因数,于是就能整除最大公因数$\left( a, b \right)$;另一方向,显然$\left( a, b \right)|a, \left( a, b \right)|b, \left( a, b \right)|bx$所以$\left( a, b \right)$是$a$和$bx$的公因数,于是能够整除最大公因数$\left( a, bx \right)$。现在它们两个相互整除了,根据整除的性质(4),它们是相同的(它们都是正数)。
现在我们能够证明整除的性质(5)了。
整除的性质(5) 若$m,a$的最大公约数为1,则$ m|ab \Rightarrow m|b $
证明:由上面的结论立即得到$\left( m, b \right)=\left( m, ab \right)=m$。得证。
欧几里德算法还是非常妙的,接下来的中国剩余定理虽然没有像这样带给我们证明上的便利,但是实际运用也很方便,而且它的思路也具有一点启发性(就像拉格朗日插值一样)
3、中国剩余定理
中国剩余定理,简称是CRT(China Remainder Theorem),也有叫孙子定理、大衍求一术什么的…
是什么呢,其实就是对一次项系数为1的模数两两互质的一次同余方程组的求解(原始版本是这样的,可以做推广)。
中国剩余定理:设$m_1,m_2,...,m_n$是$n$个两两互质的正整数,$m=\prod_{i=1}^{n}m_i$,那么下面的同余方程组
$$ \left\{ \begin{aligned}x & \equiv b_1 &\pmod{m_1} \\x & \equiv b_2 &\pmod{m_2} \\& \vdots & \\x & \equiv b_n &\pmod{m_n} \end{aligned}\right.$$
在模$m$意义下有唯一解:
$$ x \equiv \sum_{i=1}^{n} b_i M_i M'_i\pmod{m} $$
其中$M_i=m/m_i$,$M'_i$满足$M'_i M_i \equiv 1\pmod{m_i}$
乍一看好像不好理解,其实很简单。$M_i$这个因子的出现意味着$b_i M_i M'_i$在除了第$i$条方程以外的方程里都同余0(因为模数是它的因子),而$M'_i$这个因子的出现保证了它在自己的这第$i$条方程里同余$b_i$。这样一来每条方程都满足了。
即使没做什么推广,它已经相当有用了,比如有大量运算需要对$10^{500}$级的大数进行,手写高精度实现当然也可以,那样如果每9位数压进一个int的话也要56个int,并且乘法的复杂度暴力实现是$56*56$的,用FFT的话是$56*\log(56)$(但是FFT常数很大,不一定会快),而如果我们取50个$10^{10}$级的质数,每次各种运算都是做50次$O(1)$的快速运算,只有最后合并结果输出的时候会慢,效率要比手写高精度优,而且注意到这是可以并行的,如果我们分布到50台机上运算的话,相当于每次运算都是$O(1)$完成的,比手写高精度快几十或几百倍…
不过大多数时候我们只是用它解一下同余方程组而已。那么我们需要推广。刚刚的限定词是“一次项系数为1”、“模数两两互质”、“一次同余方程组”三个,我们可以试试分别把它推广。但是其中“一次同余方程组”这条就不要想着推广了…因为高次同余方程至今还没有一般的简便方法,只能用计算机把剩余系中的剩余类一个个试一遍…
我们先来推广“一次项系数为1”这一条:
对于系数不为1的一次同余方程,我们发现它的解其实就是我们要的系数为1的一次同余方程。所以现在我们的问题就变成了简单地求解一次同余方程。
对于同余方程$ax \equiv b\pmod{m}$,其实可以转化为一次不定方程$ax + my = b$的求解。
我们可以容易的知道一般的不定方程$ax+by=c$有解当且仅当$\left( a,b \right)|c$,因为观察等式两边模它的余数,左边是0,所以右边一定要是0才可能有解,并且如果c确实是$\left( a,b \right)$的倍数,我们可以用扩展欧几里德算法得到的解乘以$c/\left( a,b \right)$转化成这个同余方程的解。所以我们可以直接用扩展欧几里德算法求解原来的同余方程。
(这里还有另一种方法,对于满足$a^{-1}a \equiv 1\pmod{m}$的$a^{-1}$,我们称作a关于模m的乘法逆元,乘以它就相当于做了除法,根据欧拉定理,我们对于互质的$a$和$m$可以直接得到$a^{-1}$就是$a^{\phi \left( m \right) -1} \mod m$,单个逆元可以通过快速幂在$O(\log m)$的复杂度内得到。而对于不互质的$a$和$m$,我们希望利用同余的性质(5)除掉一个$\left( a,m \right)$,这就必须要$\left( a,m \right)|b$才能做到。另外,由这个方法我们可以不严谨地发现模数必须除以一个$\left( a,m \right)$才有唯一解。这个也可以通过上面的不定方程的方法稍作分析得到)
现在我们能够求解一次项系数不一定为1的模数两两互质的一次同余方程组或者判断出无解了,接下来我们推广“模数两两互质”这个限制。
显然,我们可以把每个模数分解质因数,转化成若干条模素数$p$的若干次方的同余方程。对于模同一个素数的不同次方的同余方程,如果存在冲突则无解,否则我们保留次数最高的那条,因为它是最紧的限制,蕴含了其它方程。所以可以转化成模数两两互质的情况了。
简单的推广就算完成了,不过还有一个有用的形式需要提一下。如果我们先解方程组中的某两条方程,再把解放回方程组里,相当于减少了一条方程,这么做$n-1$次后就只剩下一条了,那一条就是我们要的解。所以我们可以弄出两条方程版的CRT,用代码实现的话会比上面的方便很多。
对于同余方程组
$$ \left\{\begin{aligned}x & \equiv b_1 &\pmod{m_1} \\x & \equiv b_2 &\pmod{m_2} \\\end{aligned}\right.$$
当且仅当$\left( m_1,m_2 \right)|b_1-b_2$时有解,如果有解,则关于模$m_1 m_2/\left( a,m \right)$有唯一解。
先证明有解的条件。观察到显然如果两个数关于$m$同余,那么关于$m$的因数也同余。所以$b_1 \equiv x \equiv b_2\pmod{\left( m_1,m_2 \right)}$。所以我们证明了有解条件的必要性,下面证明充分性。如果$\left( m_1,m_2 \right)|b_1-b_2$,那么按照前面我们对不定方程的推理,不定方程$m_1 x+m_2 y=b_1-b_2$有解,于是通过模$m_1$我们得到一条有唯一解的同余方程$m_2 y \equiv b_1-b_2\pmod{m_1}$,设解为$t$,那么不难验证这两条式子成立:$m_2 t+b_2 \equiv b_1\pmod{m_1}$,$m_2 t+b_2 \equiv b_2\pmod{m_2}$,于是$m_2 t+b_2$就是方程组的一个解。
下面证明关于模$m_1 m_2/\left( m_1,m_2 \right)$有唯一解,如果存在两个解$x_1,x_2$,那么显然有$x_1$和$x_2$关于$m_1$和$m_2$都同余,即$x_1-x_2$是$m_1,m_2$的公倍数,所以最小公倍数$m_1 m_2/\left( m_1,m_2 \right)|x_1-x_2$,所以关于模$m_1 m_2/\left( m_1,m_2 \right)$有唯一解。
现在就得到了最终我们可以简单地用代码实现的CRT了,同样支持系数不为1,模数不互质。
4、米勒-拉宾素性测试
我们知道判断一个数是否为素数需要很高的代价(暴力判断的复杂度是$O\left(\sqrt{n}\right)$),根据素数定理我们知道素数个数接近$\frac{n}{\ln n}$,所以通过预处理小的素数然后枚举素数来暴力的话可以做到$O\left( \frac{\sqrt{n}}{\ln n} \right)$,但是对于多次询问,仍然是一个巨大的复杂度。
所以我们可以使用一种不安全的近似算法,牺牲一些正确性来换取时间。
可以利用的想法就是费马小定理。如果存在一个整数$a$,使得$a^n \not \equiv a\pmod{n}$的话,$n$一定不是素数。反过来却不能确定$n$是素数。我们把这个过程称作基a的费马素性测试。如果我们能确定一个数$n$是合数,则称它未通过基a的费马素性测试,否则称通过基a的费马素性测试。
理所当然地,我们希望多取几个基就能筛选走大部分合数,尽管其实对于每个基都存在无穷多个能够通过费马素性测试的合数(我们称这些通过基a测试的合数为基a的伪素数)…这个有无穷多伪素数的证明这里就不证了,意义不是很大…实际上对于随机选取的数,即使只做一个基的费马素性测试也有看起来不错的正确率,对于随机选取的$10^9$以内的数,基2的费马素性测试的正确率已经高达99.989%。但是实际上我们基本不用费马素性测试,因为有一些不愿看到的事情发生了…1910年有个叫卡米歇尔的人发现了一些糟糕的数,它们是合数,却可以通过基任何正整数的费马素性测试…其中最小的一个是$561=3*11*17$(如果哪天看到有人说自己还在用费马素性测试的,就可以那这个数怼他)。这些数被称为卡米歇尔数,小于$10^7$的卡米歇尔数有$105$个。关于卡米歇尔数就说到这里了,关于它的判定和性质不继续讨论。因为我们要请出我们的主角:米勒-拉宾素性测试。
米勒-拉宾素性测试:对于大于1的奇数$n$,令$2^\alpha t=n-1$,其中$t$是奇数。如果对于$n \not | a$的某个整数$a$,满足$a^t \not \equiv 1\pmod{n}$且$\forall 0 \leq i \leq \alpha-1, a^{2^i t} \not \equiv -1\pmod{n}$,则$n$一定是合数。
我们可以证明与它等价的逆否命题,如果$p$是奇素数且$p \not | a$,则$a^t \equiv 1\pmod{p}$或$\exists 0 \leq i \leq \alpha-1, a^{2^i t} \equiv -1\pmod{p}$。因为$p$是素数,所以$\phi(p)=p-1$,又$a,p$互质,所以$a^{p-1} \equiv 1\pmod{p}$即$a^{2^\alpha t} \equiv 1\pmod{p}$。所以就是$\left( a^{2^{\alpha -1}\ t} \right) ^2 \equiv 1\pmod{p}$,由拉格朗日定理(模素数的最高次系数不同余0的$n$次同余方程最多有$n$个解,可以用归纳法证明),该方程至多两个解,实际上我们发现这个方程的两个解就是$x \equiv \pm 1\pmod{p}$。所以$a^{2^{\alpha -1}\ t} \equiv 1\pmod{p}$或者$a^{2^{\alpha -1}\ t} \equiv -1\pmod{p}$,我们断言这两个式子不会同时成立,因为$p$是奇数。如果其中同余$-1$的式子成立,则符合我们的命题;如果同余$1$的式子成立,我们可以重复上面的过程,只是指数变成了$2^{\alpha-2}t$,以此类推,最终结果是$a^t \equiv 1\pmod{p}$,符合我们的命题。所以命题得证。
现在我们有了一个看起来非常麻烦的素性测试方法了,而且它也并不显然地比费马素性测试要好。但是实际上,对于米勒-拉宾素性测试不存在类似卡米歇尔数一样的无论如何都没法被正确判断的数。有一个定理:奇合数$n$至多通过$(n-1)/4$个小于$n$的基的米勒-拉宾素性测试。证明我并不会…貌似篇幅较长…(参考文献Elementary Number Theory and Its Applications - K.H.Rosen,如果真的想知道的话可以去看)。另外,如果广义黎曼猜想成立,则对于每个奇合数$n$,都存在$1 < a < 2\left( \log _2 n \right)^2$使得$n$不能通过基$a$的米勒-拉宾素性测试。所以如果广义黎曼猜想是对的,这将是一种复杂度非常不错的确定性算法。虽然还不能确定对所有数的正确性,但是实践已经得出对于比较小的$n$(大概是$10^{13}$以内),都可以用前5个素数作为基准确地判断。
虽然很厉害,但是看起来真的挺麻烦,估计又会吓跑一批初学者…一般情况下并不需要素性测试那么快的速度,用$O\left( \frac{\sqrt{n}}{\ln n} \right)$基本可以满足需求。但是下面这个算法,就真的不得不用素性测试了…
5、Pollard-Rho大整数分解算法
普通的整数分解做法类似于暴力判断一个数是否是质数,枚举小于等于$\sqrt{n}$的数判断就好了,因为$n$至多只有一个大于$\sqrt{n}$的因子。如果预处理质数再进行分解,可以做到$O\left( \frac{\sqrt{n}}{\ln n} \right)$的复杂度,和上一部分讲的暴力判断素性是一样的…
同样,这个复杂度也是很高的。实际运用中我们可能需要对$10^{18}$那么大的整数进行快速分解,或者有大量的数需要在短时间内分解,用暴力的分解做法是不能满足要求的。而且这甚至不能给我们个盼头…(如果是暴力判断素数,我们可能可以希望那些数都是一些小质数的倍数,从而使算法很快就结束。但是对于质因数分解,我们不得不达到我们的复杂度上界,否则可能就会漏掉因数)
如果我们只想要个盼头的话,我们可以想到一种简单“漂亮”的算法,那就是随机一个数,如果它是$n$的因数就输出,不然就继续随机。不用动脑子都会发现这样能够一次选到的概率在$n$为两个素数乘积的情况下是$2/(n-2)$(不把$1$和$n$纳入随机的范围)。对于一个$10^{18}$的数能够一次选中的话…嗯…可能要比宇宙射线突然照到你面前的电脑上让它爆炸的概率高,不错。通过期望我们其实可以算出这样期望尝试次数是$n/2$,比上面的算法还要差多了。
说到随机我们总是会想起生日悖论,就是说在大小为$n$的集合中随机选数,选大约$1.2\sqrt{n}$个数就有超过一半的概率会重复。原来的例子是说同一个班里有人生日相同的概率很高来着…出现重复的概率(选$1.2\sqrt{n}$就有50%以上)比选中某个确定的数(选$\sqrt{n}$个只有$\frac{\sqrt{n}}{n}$)的概率大得多,这是因为分母不同,是指数和阶乘的差别。
$n$个数选$k$个不同的数,选中某个确定的数的概率是$1-\frac{n-1}{n} \times \frac{n-2}{n-1} \times \cdots \times \frac{n-k}{n-k+1}=\frac{k}{n}$
$n$个数选$k$个数,出现重复的概率是$1-\frac{n}{n} \times \frac{n-1}{n} \times \cdots \times \frac{n-k+1}{n}=1-\frac{n!}{n^k \left( n-k \right)!}$
彩票中奖这种好事属于上面那种,哈希冲突这种坏事属于下面这种…惨呀,坏事发生的概率比好事高很多很多…
当然,如果我们能利用上“冲突容易发生”这条性质,那自然是最好的。于是就有了Pollard-Rho算法。
我们如何利用呢?考虑不断选取小于$n$的随机数,现在我们不是看随机到的是不是因数,而是看随机到的数有没有重复。这有什么用呢?如果我们选取到的数出现了重复,那么如果我们把所有选过的数都模掉$n$的一个因子$d$,也一定出现了重复。看起来还是没什么用?如果这些数发生重复之前,模$d$得到的序列就已经有数重复了会发生什么?是的,重复的这两个数相差$d$的倍数!所以这个时候我们只要求一次两数差与$n$的最大公约数,我们就可以分解出$n$的一个因数了~
看起来是玄学?没事我们可以稍微分析一下。假设待分解的数是合数$n=pq$,其中$p \leq q$(于是显然有$p \leq \sqrt{n}$)。
我们随机选数,范围是$0$到$n-1$,那么因为$p$是$n$的因数,我们选的数$\mod p$也还是在$0$到$p-1$等概率选取的(因为$n$的标准剩余系可以看成$p$的标准剩余系重复$n/p$次接在一起嘛)。于是根据生日悖论的分析我们可以进行估算,进行$1.2\sqrt{n}$次就有超过一半的概率出现重复,我们猜测次数的期望是$O \left( \sqrt{n} \right)$的。(其实这个猜测根本不合数学逻辑,因为概率分布完全可以很诡异。但是这符合我们的生活经验,虽然生活经验往往不可靠)
通过一些统计手段,我们可以直观地感受一下这个概率分布(下面是用Mathematica绘制的图)。

图1. 当$n=100$时的重复概率与选数个数的关系(横轴为选数次数)
反过来可以得到另一张更有用的图:
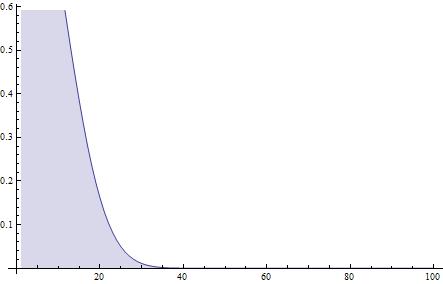
图2. 当$n=100$时的不重复概率与选数个数的关系(横轴为选数次数)
我们根据上面的式子其实可以直接列出期望。如果我们选了$k$个数还没有重复,那么这第$k$次选数会为这些还没有重复的情况贡献$1$的步数,对于其他情况($k$次前就已经重复)没有贡献。于是我们有:
$$E = \sum_{k=0}^{n-1} 1 \times P_k\\P_k = \frac{n!}{n^k \left( n-k \right)!}$$
其中$P_k$就是选$k$次还没有重复的概率。我们发现其实$E$就是图2里的阴影部分面积(其实差一点点,因为$E$是离散的和,我们的图得到的是连续平滑的曲线,但是它们在整点上的值是一样的)。我们其实可以用微积分计算阴影部分面积来近似地得到$E$,不过这条曲线并没有比较合理的形式,但是我们可以近似估计(这里不加证明地给出一个结论:$n!=\sqrt{2 \pi n}\left( \frac{n}{e} \right)^n \left( 1+\frac{1}{12n}+\frac{1}{288n^2}-\frac{139}{51840n^3}+O\left( \frac{1}{n^4} \right) \right)$,这意味着我们可以用$\sqrt{2 \pi n}\left( \frac{n}{e} \right)^n$近似地代替$n!$来得到一个连续的可能比较易于积分的函数…)事实上结果形式还是太复杂了…
如果用下降幂来写的话,这个式子其实可以写成很简单漂亮的形式。然而它并不好算,尽管它是个有限和。(看起来有点像超几何函数但是好像又不是…超几何似乎不是很兹磁这样的下降幂…我超几何没学好什么都不会…)我先后尝试了几种求和的办法都失败了(不排除我太蠢算错了的可能)。但是Mathematica直接告诉了我这个东西的结果:
$$ \sum_{k=0}^{n-1} \frac{n!}{n^k \left( n-k \right)!} = -1+e^n n^{-n}\Gamma \left( 1+n,n\right) $$
其中$\Gamma$是不完全伽马函数,满足$\Gamma \left ( a,z \right ) = \int_{z}^{\infty}t^{a-1}e^{-t} \mathrm{d} t$。
然后小伙伴告诉我这个是显然的,因为把不完全伽马函数分部积分,可以得到关于$a$的递推式,然后展开,提出公因式$z^a e^{-z}$就得到原始式子了…
这下我也很尴尬,懵逼啦…得到了结果也看不出它的性质…但是不慌,我们还有统计手段,画图大法:

图3. $n$增大时$E$(红色线)与$\sqrt{n}$(蓝色线)的比较
看起来我们开始的猜测很有希望嘛,它们的趋势很接近,乘个常数试试?
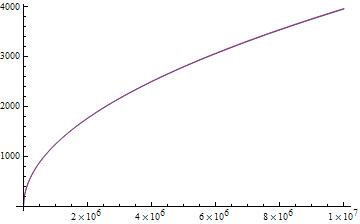
图4. $n$增大时$E$(红色线)与$1.25\sqrt{n}$(蓝色线)的比较
它们几乎重合了!靠谱的小伙伴又告诉我说,这是广义的斯特林近似,我乱取的常数$1.25$其实是一个常数$\sqrt{\frac{\pi}{2}}$…于是还记得我上面给出的那个没有给出证明的近似结论吗?是的就是那个…我们又一次体会到了数学的统一与和谐。被数学虐的感觉真好…
现在至少我们已经通过统计手段加上数学手段知道了我们的做法在一定范围内的期望选数次数真的是$O\left( \sqrt{n} \right)$的,而且它和$\sqrt{n}$的比值接近一个常数$1.25$,所以我们已经可以放心地进行下一步的分析了。
期望情况下,我们选的数发生重复需要$\sqrt{n}$步,而模$p$意义下重复只需要$\sqrt{p}$步。所以期望情况下,我们一定是可以通过上面的办法找到因子$p$的。
但是实际情况不是这样,麦克斯韦的妖精总是在捣乱,比如有一次我们就这么倒霉,碰上了模$p$意义下一直不重复,直到两个数真正地重复。这个样子我们得到的因子就会是$n$,这算是失败了。所以就是这么奇妙,我们分析的时候不需要特意考虑,而实现的时候就需要把极端情况写上。这个时候我们需要重新开始寻找的过程即可。
以及实现上我们还有很多问题,比如说:我们怎么生成随机数,怎么判断是否重复?
我们可以使用一个伪随机数生成器,输入一个数,通过一些运算,返回一个$0$到$n-1$的数。通过不断把输出作为输入调用这个过程,我们可以得到一个伪随机数列表,我们可以直接使用它当做我们的随机数。这个随机数生成器的选取其实很重要,它要足够平均、混乱,而且不能达到一个稳定状态(如果是稳定状态的话输出将不断重复同一个数);而且它又要很简单,因为我们原来的目的就是要快。所以一般的选取是对于输入$x$,输出$\left( x^2+c \right) \mod n$。至于为什么选这个,我个人的理解是这个比较简单,并且初等数论里对二次剩余的研究有很多,平方型的伪随机数可以得到一些结论…(就像委托重任当然委托给熟一点的人了)。另外我们还知道这里的$c$取$0$和$-2$都不好,因为输入为$1$时$c=0$会得到全是$1$的随机数,输入为$-1$时$c=-2$会得到全是$-1$的随机数。
有了伪随机数生成器,我们就可以判断重复了。为什么原来不行?原来必须要记录下所有选过的数,就算用很好的哈希快速判断也需要很大的空间,有些应用中我们时间可以拖得很长,但是空间还是受计算机内存限制的。通过伪随机数生成器,我们可以得到这样的理解:我们站在一条直跑道上,跑道终点直接连接着一条环形跑道(形成一个希腊字母$\rho$形,这也是算法名字rho的来源),我们每一步只知道上一步在哪里,也分辨不出直道和环形的分界点,如何确定我们已经跑过了整个$\rho$形?
我们可以使用Floyd判圈法,它是这样的:有两个人同时在跑道上跑,一个人的速度是另一个人的两倍,当快的那个人赶上慢的那个人的时候,就说明至少跑完一圈了。这样判断显然是对的,而且代价小于总长的常数倍,因为从慢的人到达环形部分开始,经过少于一个环长的时间,快的人就会赶上慢的人。所以我们用两个随机数$x_1,x_2$,其中一个数每次都进行两次迭代(这就是速度比较快的那个人),然后我们判断重复的办法就是直接判断,判断在模$p$意义下重复的办法就是看$\left( x_1-x_2 \mod n, n \right)$是否是$1$与$n$以外的数(如果是的话它就是$p$,我们就分解成功了)。
最后补上一开始就没有考虑的漏洞,如果$n$是素数则直接返回,这个用我们上一部分讲的米勒-拉宾素性测试就可以了。然后我们就得到了最终版Pollard-Rho算法:
首先判断$n$是否素数,是则返回。然后我们初始化$x_1,x_2$为相同的数,接着我们开始循环。每次循环中,如果发现$\left( x_1-x_2 \mod n, n \right)$不是$1$和$n$,则这个数为$p$,把分出来的部分$p$和$n/p$分别递归进行分解并返回。否则如果$x_1=x_2$,我们更换伪随机数生成器的参数$c$,从头开始。然后我们迭代$x_1,x_2$的值,其中$x_2$迭代两次。
有了上面我们分析的结果,我们知道分解出来一个因数的期望时间是$O\left( \sqrt{p} \right)$的,也就是$O\left( \sqrt[4]{n} \right)$的,当然最后我们还要算上求最大公约数时欧几里德算法的复杂度$O(\log n)$,如果要完成分解还需要乘以一个因子个数。即使这些都达到上界,它仍然是一个比较优的复杂度。而且实际情况中,如果存在比较小的因子,根据我们的分析可以知道分解很快就会完成(因为是所有因子中最小的那个$p$的根号)。所以,这是一个相当不错的算法。
(另外,关于里面的判圈还有Brent提出的另一个方法,就是每达到一个2的次幂的步数就另$x_2=x_1$,每次移动$x_1$,可以证明这样的步数同样不超过总长的常数倍,实际情况可能要比Floyd判圈法快 不知道为什么有时比Floyd慢很多,大概有别人的两倍(可能是我实现得比较挫)。但是它们的本质思想还是模$p$意义下重复,所以在这里不分别介绍了。)
后记
本来没想写这个后记的…但是写这篇blog貌似写了一天了,写的长度也远远超过预期…
这次写一次感觉还是比较有收获的…起码以前忘掉的一些理解现在找回来了,而且还得到了一些以前没有注意到的新东西。
如果有新人看到了这里的话那也是挺厉害的…虽然我觉得我写的不是很跳跃,但是能够看下来那么多也非常可贵…希望有所收获。
写的过程中也深深地体会到数学各方面都是紧密相连的,本来想把所有用到的定理都给出证明,但是涉及的太多了…如你所见,现在这样已经那么长了。
我还是要努力呀…
最后感谢靠谱的小伙伴GEOTCBRL在不完全伽马函数部分给我的帮助(度过了一个愉快的乱玩数学的上午)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号