Keras 迁移学习
keras_cat_do_con
In [1]:
#由于Keras已经与TensorFlow合并,tensorflow下面导入keras
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
import numpy as np
import shutil
import os
2024-12-15 05:10:38.616258: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`. 2024-12-15 05:10:38.630454: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:479] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-12-15 05:10:38.649348: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:10575] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-12-15 05:10:38.649373: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1442] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2024-12-15 05:10:38.662032: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2024-12-15 05:10:39.341306: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
In [2]:
base_dir='/dataset/cat_dog/'
In [3]:
train_dir = os.path.join(base_dir, 'train')
train_dir_dog = os.path.join(train_dir, 'dog')
train_dir_cat = os.path.join(train_dir, 'cat')
test_dir = os.path.join(base_dir, 'test')
test_dir_dog = os.path.join(test_dir, 'dog')
test_dir_cat = os.path.join(test_dir, 'cat')
for d in [train_dir, train_dir_dog, train_dir_dog, test_dir, test_dir_dog, test_dir_cat]:
os.makedirs(d, exist_ok=True)
In [4]:
fnames = ['cat.{}.jpg'.format(i) for i in range(3000)]
for n in fnames:
s = os.path.join(train_dir, n)
d = os.path.join(train_dir_cat, n)
shutil.copyfile(s, d)
In [5]:
fnames = ['dog.{}.jpg'.format(i) for i in range(3000)]
for n in fnames:
s = os.path.join(train_dir, n)
d = os.path.join(train_dir_dog, n)
shutil.copyfile(s, d)
In [6]:
fnames = ['cat.{}.jpg'.format(i) for i in range(3000,4001)]
for n in fnames:
s = os.path.join(train_dir, n)
d = os.path.join(test_dir_cat, n)
shutil.copyfile(s, d)
fnames = ['dog.{}.jpg'.format(i) for i in range(3000,4001)]
for n in fnames:
s = os.path.join(train_dir, n)
d = os.path.join(test_dir_dog, n)
shutil.copyfile(s, d)
In [7]:
#图片生成器
from tensorflow.keras.preprocessing.image import ImageDataGenerator
In [8]:
#归一化
train_g = ImageDataGenerator(rescale=1/255)
test_g = ImageDataGenerator(rescale=1/255)
In [9]:
#target_size 统一处理图片尺寸
#class_mode 二分类
train_gen = train_g.flow_from_directory(train_dir,
target_size=(200,200),
batch_size=16,
class_mode='binary')
Found 6000 images belonging to 2 classes.
In [10]:
test_gen = train_g.flow_from_directory(test_dir,
target_size=(200,200),
batch_size=16,
class_mode='binary')
Found 3003 images belonging to 2 classes.
创建模型¶
In [11]:
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
gpus
2024-12-15 05:10:41.280209: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.338344: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.339445: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
Out[11]:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
导入内置网络(vgg19)¶
In [12]:
#使用imagenet预训练权重
#include_top=False 只使用卷积层
conv_base = tf.keras.applications.VGG19(weights='imagenet', include_top=False)
conv_base.summary()
2024-12-15 05:10:41.353747: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.354844: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.355870: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.504685: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.505844: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.506886: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 2024-12-15 05:10:41.507928: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1928] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 859 MB memory: -> device: 0, name: NVIDIA A100 80GB PCIe, pci bus id: 0000:00:0e.0, compute capability: 8.0
Model: "vgg19"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, None, None, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv1 (Conv2D) │ (None, None, None, 64) │ 1,792 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv2 (Conv2D) │ (None, None, None, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_pool (MaxPooling2D) │ (None, None, None, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv1 (Conv2D) │ (None, None, None, │ 73,856 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv2 (Conv2D) │ (None, None, None, │ 147,584 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv1 (Conv2D) │ (None, None, None, │ 295,168 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv2 (Conv2D) │ (None, None, None, │ 590,080 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv3 (Conv2D) │ (None, None, None, │ 590,080 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv4 (Conv2D) │ (None, None, None, │ 590,080 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv1 (Conv2D) │ (None, None, None, │ 1,180,160 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv2 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv3 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv4 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv1 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv2 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv3 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv4 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 512) │ │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 20,024,384 (76.39 MB)
Trainable params: 20,024,384 (76.39 MB)
Non-trainable params: 0 (0.00 B)
连接vgg19网络¶
In [13]:
model = Sequential()
model.add(conv_base)
#使用GlobalAveragePooling2D将最后 None, None,512进行展平
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(512, activation='relu'))
#模型输出2分类0或1
model.add(layers.Dense(1, activation='sigmoid'))
In [14]:
model.summary()
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ vgg19 (Functional) │ (None, None, None, │ 20,024,384 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_average_pooling2d │ (None, 512) │ 0 │ │ (GlobalAveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 512) │ 262,656 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 1) │ 513 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 20,287,553 (77.39 MB)
Trainable params: 20,287,553 (77.39 MB)
Non-trainable params: 0 (0.00 B)
冻结训练参数¶
In [15]:
conv_base.trainable = False
In [16]:
#之前训练参数Trainable params: 20,287,553 冻结后Trainable params: 263,169 (1.00 MB)
model.summary()
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ vgg19 (Functional) │ (None, None, None, │ 20,024,384 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_average_pooling2d │ (None, 512) │ 0 │ │ (GlobalAveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 512) │ 262,656 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 1) │ 513 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 20,287,553 (77.39 MB)
Trainable params: 263,169 (1.00 MB)
Non-trainable params: 20,024,384 (76.39 MB)
编译¶
In [21]:
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['acc'])
训练¶
In [22]:
#steps_per_epoch * batch_size 等于1个epoch
his = model.fit(train_gen,
epochs=20,
steps_per_epoch=375,
validation_data=test_gen,
validation_steps=180)
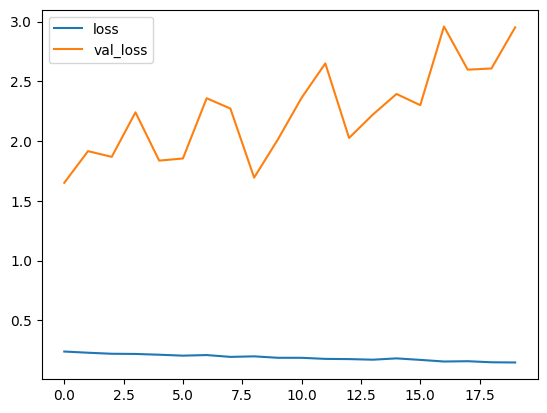
Epoch 1/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 12s 29ms/step - acc: 0.8973 - loss: 0.2475 - val_acc: 0.6594 - val_loss: 1.6508 Epoch 2/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 20s 54ms/step - acc: 0.9066 - loss: 0.2194 - val_acc: 0.6420 - val_loss: 1.9159 Epoch 3/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 20s 55ms/step - acc: 0.8899 - loss: 0.2399 - val_acc: 0.6431 - val_loss: 1.8682 Epoch 4/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 67s 178ms/step - acc: 0.9007 - loss: 0.2245 - val_acc: 0.6208 - val_loss: 2.2409 Epoch 5/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 160ms/step - acc: 0.9113 - loss: 0.2079 - val_acc: 0.6465 - val_loss: 1.8365 Epoch 6/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9171 - loss: 0.1992 - val_acc: 0.6500 - val_loss: 1.8547 Epoch 7/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 160ms/step - acc: 0.9040 - loss: 0.2137 - val_acc: 0.6139 - val_loss: 2.3589 Epoch 8/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9238 - loss: 0.1910 - val_acc: 0.6243 - val_loss: 2.2724 Epoch 9/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 159ms/step - acc: 0.9131 - loss: 0.1981 - val_acc: 0.6542 - val_loss: 1.6942 Epoch 10/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 120s -47374us/step - acc: 0.9304 - loss: 0.1711 - val_acc: 0.6285 - val_loss: 2.0134 Epoch 11/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9119 - loss: 0.1948 - val_acc: 0.6250 - val_loss: 2.3624 Epoch 12/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 160ms/step - acc: 0.9324 - loss: 0.1643 - val_acc: 0.6177 - val_loss: 2.6504 Epoch 13/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9277 - loss: 0.1686 - val_acc: 0.6528 - val_loss: 2.0264 Epoch 14/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 160ms/step - acc: 0.9315 - loss: 0.1683 - val_acc: 0.6472 - val_loss: 2.2215 Epoch 15/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9134 - loss: 0.1938 - val_acc: 0.6483 - val_loss: 2.3946 Epoch 16/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 120s -46918us/step - acc: 0.9282 - loss: 0.1649 - val_acc: 0.6538 - val_loss: 2.3008 Epoch 17/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 160ms/step - acc: 0.9347 - loss: 0.1549 - val_acc: 0.6212 - val_loss: 2.9596 Epoch 18/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 161ms/step - acc: 0.9285 - loss: 0.1656 - val_acc: 0.6413 - val_loss: 2.5979 Epoch 19/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 120s 170ms/step - acc: 0.9423 - loss: 0.1453 - val_acc: 0.6396 - val_loss: 2.6078 Epoch 20/20 375/375 ━━━━━━━━━━━━━━━━━━━━ 60s 159ms/step - acc: 0.9432 - loss: 0.1381 - val_acc: 0.6236 - val_loss: 2.9525
In [23]:
import matplotlib.pylab as plt
%matplotlib inline
In [24]:
plt.plot(his.epoch, his.history.get('loss'), label='loss')
plt.plot(his.epoch, his.history.get('val_loss'), label='val_loss')
plt.legend()
Out[24]:
<matplotlib.legend.Legend at 0x7fdab046aec0>
In [ ]:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号