
复习总结
1、and或or复习总结:
Python中的and从左到右计算表达式,若所有的值均为真,则返回最后一个值,若存在假,返回第一个假值
or也是从左到右计算表达式,返回第一个为真的值
2、描述Python中GIL的概念复习总结:
GIL:全局解释器锁,每一个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行字节码。
3、Python中单引号,双引号,三引号的区别总结复习:
单引号:单引号中可以使用使用双引号,中间会当字符串输出,
双引号:双引号中可以使用单引号,中间会当字符串输出,
三单引号,和三双引号中间的字符串,在输出是保持原来的格式
4、is和==的区别复习总结:
Python中包含三个基本元素:ID(身份标识),type(数据类型),value(值)
其中ID用来唯一标识一个对象,type标识对象类型,value标识对象的一个值
is判断的是a对象是否就是b对象,是通过ID来判断
==判断的是a对象的值是否和b对象的值相等,是通过value来判断
5、可变对象和不可变对象的复习总结:
元组(tupe),数值型(number),字符串(string)均为不可变对象
字典(dict),列表(list)是可变对象
6、PEP8编码规范复习总结:
1、代码编排:缩进,4个空格的缩进。最大长度79,换行可以使用反斜杠
2、文档编排。。。。
3、空格的使用:各种括号前不要加空格,逗号,分号,冒号前不要加空格,
4、注释:块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔,如:
# Description : Module config.
#
# Input : None
#
# Output : None
5、文档描述
6、字符串不要以空格收尾
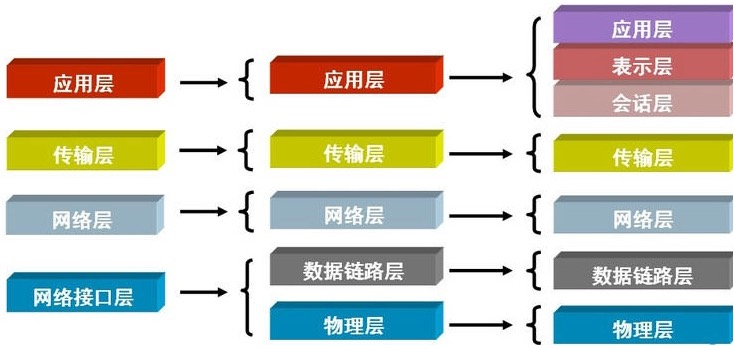
7、osi七层协议复习总结:
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
8、TCP与UDP的复习总结:
TCP:TCP是基于链接的,必须先启动服务端,然后在启动客户端去链接服务端(TCP有粘包现象)
UDP:UDP是无连接的,先启动那一端都不会报错(UDP没有粘包现象)
9、阻塞IO与非阻塞IO 总结复习:
IO阻塞:资源不可用是IO 请求一直阻塞,直到反馈结果
非阻塞IO:资源不可用时IO 请求离开返回,返回数据标识,资源不可用
10、同步IO 与异步IO复习总结:
同步IO :应用阻塞在发送和接受数据的状态,直到数据传输成功或返回失败
异步IO :应用发送或者接受数据立刻返回,数据写入OS 缓存,有OS完成数据的发送和接受,并返回成功和失败的信息给应用
11、网络编程中三次握手,四次挥手复习总结:
首先由服务端,和客户端。服务端先进行初始化Socket,在端口进行监听,等待客户端的连接,在这时,如果有客户端初始化socket,然后就开始连接服务端,如果连接成功,
这时客户端与服务端的连接就建立了,客户端发送数据请求,服务端就开始接受并处理请求,然后把回应数据发送个客户端,客户端读取数据,最后关闭连接。
12、一行代码实现九九乘法表的复习总结:
print('\n'.join([ ' '.join( [ '{}*{} = {}'.format(x,y,x*y) for y in range(1,x+1)] ) for x in range(1,10)]) )
13、函数的复习总结:
函数分为:
1、内置函数:Python解释器已经为我们定义好的函数成为内置函数
2、自定义函数:内置函数为我们提供的功能是有限的,这就需要我们根据自己的需求,定制好我们自己的函数来实现某种功能。以后,在遇到应用场景是,调用自定义的函数即可
函数调用的规则:先定义,在调用
定义函数的三种形式:
1、无参:定义时没有参数,意味着调用的时候无需传入参数
2、有参:定义的时候有参数,意味调用的时候必须传入参数
3、空函数
函数的调用:函数名加括号(先找到自己的名字,根据自己的名字调用代码)
函数返回值:
1、无return 返回None
2、return1个值 返回一个值
3、return逗号多个值 返回多个值
14、函数的参数复习总结:
1、位置参数:按照从左到右的顺序依次定义参数
a、位置形参:必选参数
b、位置实参:按照位置给形参传值
2、关键字参数:按照key=value的形式定义实参(无需按照位置为形参传值)
注意的问题:a、关键字实参必须在位置实参右面
b、对同一个形参不能重复传值
3、默认参数:形参在定义的时候就已经为其赋值(可以传值也可以不传值)
注意的问题: a、只在定义时赋值一次
b、默认参数的定义应该在位置形参右面
c、默认参数通常应该定义成不可变类型
4、可变长参数:可变长参数指的是实参值得个数不固定(存放可变长参数的分别是:*args,**kwargs)
5、命名关键字参数:*后定义的参数,必须被传值(有默认值除外),且必须按照关键字实参的形式传递
内置函数的复习总结:内置函数的ID()可以返回一个对象的身份,返回值为整数。内置函数type()则返回一个对象类型
面向对象的复习总结:
1、面向过程的核心设计是 过程,过程值得是:解决问题的步骤
2、 面向过程的优点:极大的降低了程序的复杂度,只需要顺着要执行的步骤,堆叠代码即可
3、面向过程的缺点:一套流水线或者流程就是来用来解决一个问题,代码牵一发而动全身
4、面向对象的核心设计是对象,
15、面向对象的三大特性:
一、继承:
1、继承:是一种创建新类的方式,在Python中,新建的类可以继承一个个或多个父类,父类又称为基类或者超类,新建的类称为派生类或者子类
2、Python中类的继承分为:单继承或多继承
3、继承的两种用途:
a、继承基类的方法,并且做出自己的改变或者扩展,
b、声明某个子类兼容于某基类,定义一个接口类Interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能
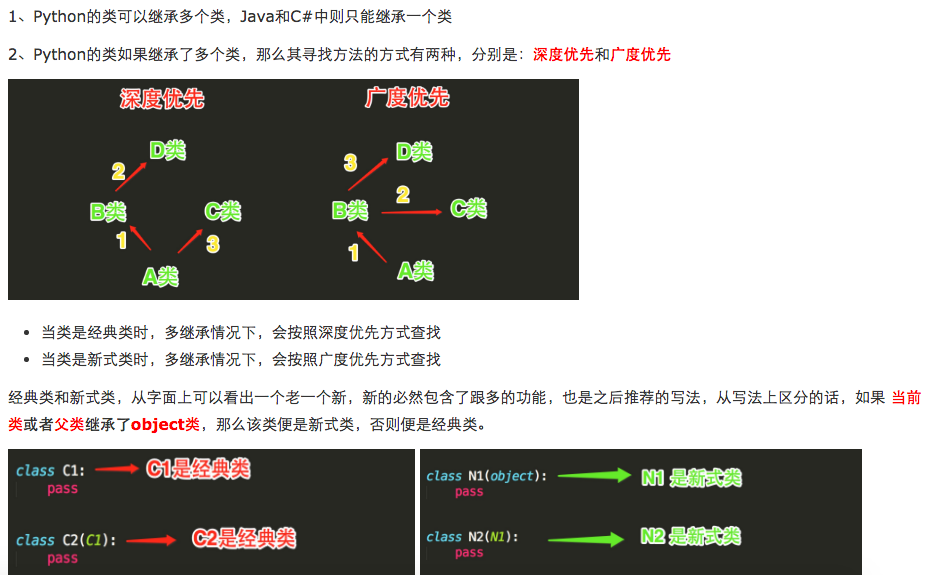
4、继承的顺序:
a、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先或广度优先
5、继承的作用:
a、减少代码的重用
b、提高代码的可读性
c、规范编程模式
二、封装:
----将同一类的方法和属性封装到类中
----将数据封装到对象中
1、隐藏对象的属性和实现细节,仅对外提供公共方式
2、封装的好处:
a、将变化隔离
b、便于使用
c、提高复用性
d、提高安全性
3、封装原则
a、将不需要对外提供的内容都隐藏起来
b、把属性都隐藏,提供公共的方法对其访问
三、多态
----多态指:一类事物有多种形态
类的内置方法复习总结:
__call__(在那用过,单例模式,用类做装饰器,Flask源码中用过__call__方法)
__new__(在那用过,单例模式,自定义Form验证,wtforms源码,Django rest-framework中序列化源码用过)
__init__
__del__
__iter__(在那用过,对象要被for循环,stark组件组合搜索中用过)
__getattr__(在那用过,Flask源码,自定义的‘本地线程’,local,rest-framework request中取值中用过)
__getitem__(在那用过,Session源码中用过)
__dict__(在那用过,自定义form)
__add__(在那用过,
data = obj1 + obj2
# obj1.__add__(obj2))
__metaclass__(在那用过,wtforms源码中用过)
16、*args和**kwargs的复习总结:
*args可以传递任意数量的的位置参数,以元组的形式存储
**kwargs可以传递任意数量的关键字参数,以字典的形式存储
*args和**kwargs可以同时定义在函数中,但必须*args放在**kwargs前面
17、什么是lambda函数,它的好处复习总结:
通常是在需要一个函数,但是有的去命名一个函数的场合下使用,也就是匿名函数
lambda的好处:lambda函数比较方便,匿名函数,一般用来给filter,map这样的函数式编程服务,作为回调函数传递给某些应用,比如消息处理
18、装饰器的的复习总结:
装饰器的本质:闭包函数
装饰器的功能:就是在不改变原函数的调用方式的情况下,在这个函数的前后加上扩展功能
装饰器的开放封闭原则:1、对扩展是开放的 2、对修改是封闭的
装饰器的固定方式:
def timer(func): def inner(*args,**kwargs): '''执行函数之前要做的''' re = func(*args,**kwargs) '''执行函数之后要做的''' return re return inner
19、迭代器的复习总结:
1、可迭代:字符串,列表,集合、字典、元组这些都可以被for循环,说明他们是可迭代的
2、迭代就是:将某个数据集内的数据一个挨一个的取出来,就叫做可迭代
3、可迭代的标志:_iter_
4、迭代协议:希望这个数据类型里的东西也可以使用for循环被一个一个的取出来那我们就必须满足for的要求,这个要求就叫做协议
5、可迭代协议:凡是可迭代的内部都有__iter__方法
6、迭代器协议:内部实现了__iter__,__next__方法(迭代器里面既有__iter__方法,又有__next__方法)
7、迭代器:通过iter得到的结果就是一个迭代器(迭代器大部分都是在Python的内部去使用,我们直接拿来用就可以了,它的内置有__iter__,和__next__方法)
8、迭代器遵循迭代器协议:必须有__iter__和__next__方法
9、不管是迭代器还是可迭代对象,都可以被for循环遍历。迭代器的出现的原因是帮你节省内存
10、迭代器和可迭代的相同点:都可以被for循环
11、迭代器和可迭代的不同点:迭代器多实现了一个__next__方法
12、判断可迭代和迭代器的方法:1、判断内部是不是实现了__next__方法 2、用 Iterable(可迭代),Iterator(迭代器) 来判断
20、生成器的复习总结:
1、生成器函数:常规函数定义,使用yield语句而不是return语句返回结果,函数内部有yield关键字,那么函数名()得到的结果就是生成器,并且不会执行函数内部代码(生成器就是迭代器)
2、生成器表达式:类似于列表推导,但是生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
3、列表推导式:
l =[i*i for i in range(100)] print(l)
21、作用域复习总结:
1、作用域即范围:全局范围(内置名称空间和全局名称空间属于该范围):全局存活,全局有效 局部范围(局部名称空间属于该范围):临时存活,局部有效
2、作用域关系是在函数定义阶段就已经固定的,与函数调用的位置无关
3、查看作用域 :globals()全局变量,locals()局部变量
22、闭包复习总结:
1、什么是闭包:内部函数包含对外部作用域而非全局作用域的引用
2、闭包的意义与应用:
1、闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹一层作用域,这使得,该函数无论在何处调用,
有先使用在外层函数包裹的作用域
2、应用 领域:在延迟计算
23、Cookie和Session的区别、优缺点
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE
4、单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
24、cookies和session的区别复习总结:
cookies的数据是放在客户的浏览器上的,session的数据是放在服务器上的
25、http协议总结复习:
http是一个基于TCP/IP通信协议来传递数据,HTTP是一个属于应用层的面向对象的协议,HTTP协议工作于客户端-服务端架构为上。
HTTP响应有四个部分组成,分别是:状态行,消息报头,空行和响应正文
请求头和请求体分割:\r\n\r\n
请求体:\r\n
GET无请求体
请求头代表的意义:user-agent:来源,referer:防盗链,context-type:请求体是什么格式
26、post与get的区别复习总结:
根据http协议规范,get一般用于获取/查询资源信息,而post一般用于更新资源信息
get是在URL中传送数据,数据放在请求头上,post是在请求体上传送数据
27、视图函数包含两个对象的复习总结:
request:------>请求信息
HttpResponse:----->响应字符串
28、request包含哪些数据的复习总结:
request.GET:GET请求的数据()
request.POST:POST请求的数据()
request.method:请求的方式:POST或GET
键值对的值是多个的时候,比如:chexbox类型,select类型,需要用:request.POST.getlist()
29、django中模板语法变量复习总结:
在Django模板中遍历复杂数据结构的关键字是句点符:.
如果字符串多余指定的数量,那么会被截断,截断的字符串将以可翻译的省略号序列("...")结尾用truncatechars,如:{{value|truncatechars:9}
如果一个变量为空或者false,使用给定的默认值,否则使用变量的值,如:{{li|default:"nothing"}}
循环序号可以用{{forloop}}显示:
forloop.counter0 从0开始
forloop.revcounter0 反向从直到0
forloop.revcounter 反向开始
对象可以调用自己的属性
30、Django的生命周期复习总结:
wsgi -->中间件-->路由-->视图-->(数据,模板)
渲染工作在Django中执行完成后,字符串返回给浏览器
但是js,css额外再发一次请求仅仅获取静态文件
31、在Django中对比render与redirect复习总结:
render:只是返回页面内容,但是末发送请求
redirect:发送了第二次请求,URL更新
32、Django中的MTV分别代表什么:
M代表什么model(模型):负责业务对象和数据对象
T代表Template(模板):负责如何把页面展示给用户
V代表Views(视图):负责业务逻辑,并在适当的时候调用model和template
33、Django之缓存复习总结:
由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加明显,最简单解决方式是使用:缓存,缓存将一个某个views的返回值保存至内存或者memcache中,5分钟内再有人来访问时,则不再去执行view中的操作,而是直接从内存或者Redis中之前缓存的内容拿到,并返回。
Django中提供了6种缓存方式:
- 开发调试


# 此为开始调试用,实际内部不做任何操作 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 引擎 'TIMEOUT': 300, # 缓存超时时间(默认300,None表示永不过期,0表示立即过期) 'OPTIONS':{ 'MAX_ENTRIES': 300, # 最大缓存个数(默认300) 'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3) }, 'KEY_PREFIX': '', # 缓存key的前缀(默认空) 'VERSION': 1, # 缓存key的版本(默认1) 'KEY_FUNCTION' 函数名 # 生成key的函数(默认函数会生成为:【前缀:版本:key】) } } # 自定义key def default_key_func(key, key_prefix, version): """ Default function to generate keys. Constructs the key used by all other methods. By default it prepends the `key_prefix'. KEY_FUNCTION can be used to specify an alternate function with custom key making behavior. """ return '%s:%s:%s' % (key_prefix, version, key) def get_key_func(key_func): """ Function to decide which key function to use. Defaults to ``default_key_func``. """ if key_func is not None: if callable(key_func): return key_func else: return import_string(key_func) return default_key_func
- 内存
# 此缓存将内容保存至内存的变量中 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', 'LOCATION': 'unique-snowflake', } } # 注:其他配置同开发调试版本
- 文件
# 此缓存将内容保存至文件 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', 'LOCATION': '/var/tmp/django_cache', } } # 注:其他配置同开发调试版本
- 数据库
# 此缓存将内容保存至数据库 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.db.DatabaseCache', 'LOCATION': 'my_cache_table', # 数据库表 } } # 注:执行创建表命令 python manage.py createcachetable
- Memcache缓存(python-memcached模块)
# 此缓存使用python-memcached模块连接memcache CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': '127.0.0.1:11211', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': 'unix:/tmp/memcached.sock', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': [ '172.19.26.240:11211', '172.19.26.242:11211', ] } }
- Memcache缓存(pylibmc模块)
# 此缓存使用pylibmc模块连接memcache CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': '127.0.0.1:11211', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': '/tmp/memcached.sock', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': [ '172.19.26.240:11211', '172.19.26.242:11211', ] } }
34、什么是同源策略复习总结:
同源策略是一种约定,它是浏览器最核心也是最基本的安全功能,如果缺少同源策略,则浏览器的正常功能都会受到影响,可以说web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
所谓同源是指,域名,协议,端口相同。
35、jsonp的复习总结:
jsonp是json用来跨域的一个东西,原理是通过script标签的跨域特性来绕过同源策略
jsonp一定是GET请求
36、js作用域的复习总结:
js作用域(全局变量,局部变量)内部可以访问外部,但外部不能访问内部
37、ajax常用的参数复习总结:
URL:发送请求的地址
data:发送到服务器的数据,当前ajax请求要携带的数据,是一个json的object对象,ajax方法就会默认地把它编码成某种格式
processdata:生命当前data数据是否进行转码或者预处理,默认为True
contentType:默认值“application/x-www-form-urlencoded”,发送请求至服务器时内容编码类型,用来指明当前请求的数据编码格式,如果想以其他方式提交数据,即向服务器发送一个json字符串traditional:一般默认为True,一般是我们的data数据有数组时会用到 :data:{a:22,b:33,c:["x","y"]},traditional为false会对数据进行深层次迭代;
38、数据库的复习总结:
1、数据库的存储过程:存储过程包含一些列可执行的sql语句,存储过程存放于MYSQL,通过调用它的名字可以执行其执行内部的一堆sql
2、存储过程的优点:
a、用于替代程序写sql语句,实现程序与sql的解耦
b、基于网络传输,传别名的数据量小,而直接传sql的数据量大
3、触发器:使用触发器可以定制用户对表进行【增,删,改】操作是前后的行为,注意,没有查询。
4、事务:事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据的完整性
5、索引本质:通过不断缩小想要获取的数据的范围来筛选出最终想要的结果,同时吧随机事件变成顺序事件,,也就是说,有了这种索引机制,我们总是用同一种方式来锁定数据
6、mysql常用的索引:
a、普通索引:加速查找
b、唯一索引:加速查找+约束(不能重复)
c、主键索引:加速查找+约束(不能为空,不能重复)
d、联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
7、使用索引
a、索引末命中
b、索引命中
8、数据库创建表
a、数据库文件夹的操作
create database db1 增加文件夹
show databases 查看所有数据库
show create database db1 查看db1文件夹
drop database db1 删除db1文件夹
b、操作文件
use db1 切换文件夹
\c 取消命令
create table t1(id int,name char(10);) 创建表
show table 查看当前下的所有表
show create table t1 查看表
alter table t1 add age int 增加字段
desc t1 查看表结构
drop table t1 删除表结构
c、操作文件的一行行内容
insert into db1.t1 values(1,'mqj'),(2,'mqj1') 增加记录
select * from t1 查看所有字段对应的值
select * from t1 where id > 2 查看id大于2 的字段
select name from t1 查看单个字段
update t1 set name='SB' where id=3 改里面的记录
delect from t1 where id=3 删除一条记录
truncate t1 整体删除
9、mysql是什么
mysql是基于一个socket编写的C/S架构的软件
10.mysql的数据基本类型:
a、数值类型:整数类型,浮点型,位类型,
b、日期类型
c、字符串类型:char类型,varchar类型
d、枚举类型(enum)和集合类型(set)
枚举类型(enum):单选,只能在给定的范围选一个值
集合类型(set) :多选,在给定的范围内选一个或者一个以上的值
39、redis和memecache的不同在于:
1、存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化(笔者注:有快照和AOF日志两种持久化方式,在实际应用的时候,要特别注意配置文件快照参数,要不就很有可能服务器频繁满载做dump)。
2、数据支持类型:
redis在数据支持上要比memecache多的多。
3、使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同:
redis目前官方只支持LINUX 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
40、redis的数据类型复习总结
redis有五大数据类型:字符串,哈希,列表,集合,有序集合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号