Unsupervised Pretraining Transfers well Across Languages
利用非平行语料训练跨语种和多语种的语音识别(Automatic Speech Recognization,ASR),使用对比预测编码(Contrastive Predictive Coding,CPC)预训练语音识别系统,效果甚至超过监督学习。
代码地址:CPC_audio
简介
已有较多的工作应用到无监督训练的语音识别系统中,该文主要集中研究对比预测编码在跨语种低数据资源的情况下,能否提升表征的质量。对比预测编码是在特征空间中建模的一种形式,其“预测”音频序列中相近的片段,而“对比”不同音频序列中的音频片段,或者同一音频序列相隔较远的片段。
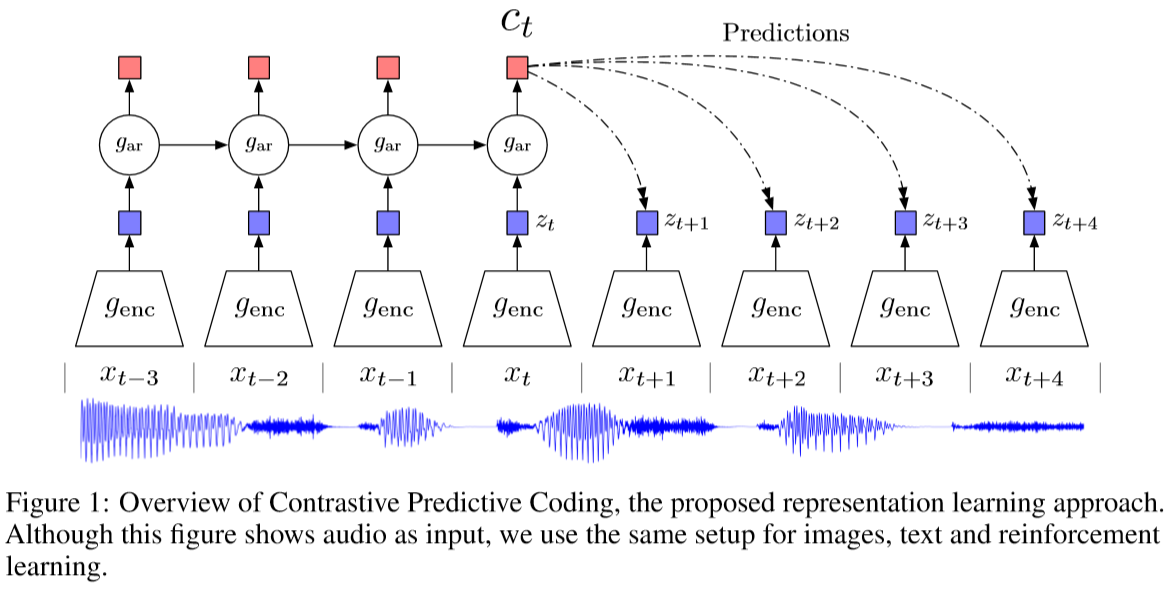
该文主要对原始方法引入一些修改以稳定训练,并且获得更好的音素表征。该文首先用英语数据集Librispeech训练修改之后的对比预测编码模型,然后将其迁移到Common Voice数据库中的其它语言。
对比预测编码(Contrastive Predictive Coding,CPC)
神经网络的无监督学习需要定义一个预训练任务,这个预训练任务引导神经网络生成有辨识度的特征。在对比预测编码中,这个预训练任务就是前向模型(forward modeling),也就是依据历史的序列,生成未来的序列。而对比预测编码的特殊性在于,其前向建模任务中的每一步都是为了获得未来的重建表征,而非未来的序列。在对比预测编码中,历史和未来表征由同一个模型生成,并且利用对比损失函数拉近时序相近的两个序列表征之间的距离,推远时序较远的两个序列表征之间的距离。
具体地,对于语音识别系统而言,首先将一个音频序列切分为\(T\)个片段,之后利用一个编码器将每一个时刻\(t\)的输入信号编码到隐状态\(\phi_\theta(x_t)\),最后利用一个序列模型将信号的隐状态映射为当前的音素表征\(z_t\)。也即:
其中,\(\phi_\theta\)表示编码器,\(\psi_\rho\)表示序列模型,\(\rho,\theta\)均为参数。
在原始的对比预测编码中,如图1中\(g_{enc}\),编码器由5个卷积层组成,卷积核大小分别为10、8、4、4、4,步长分别为5、4、2、2、2,序列模型为一层GRU。编码器的下采样率为160,也就是说,对于一个采样率16kHz的输入信号来说,每一个隐状态向量编码10ms的音频。
给定音素嵌入向量\(z_t\),对比预测编码的预训练任务就是预测接下来的\(K\)个音频隐状态,也就是预测\(\phi_\theta(x_{t+k})\),其中\(k\in \{1,2,...,K\}\)。对比预测编码同时推远随机选取的\(N_t\)个负样本隐状态,最终,在时刻\(t\)的损失函数为:
其中,\(A_k\)是一个线性分类器,有很多的方法选取负样本,比如在一个说话人的语料中选取不同语句的音频,或者选取与当前时刻距离较远的音频片段,参数\(\theta,\rho\)和\(A_{1,...,K}\)通过随机梯度下降学习获得。
修改对比预测编码(CPC)
稳定训练
该文作者观察到对比预测编码的训练较为不稳定,并且常常会收敛到一个较差的点,罪魁祸首是编码器神经网络层之间的批规范化层(batch normalization)。批规范化的可学习重构参数\(\gamma,\beta\)在整个批次的样本上进行计算,并且编码器在整个序列上是共享的,因此批规范化会泄漏序列未来的信息。结合公式1可知,需要将负样本尽可能推开,因此与负样本共享这部分统计信息就有可能导致训练的不稳定。解决方案很简单,就是将批规范化替换为同样可以约束内部表示的、沿通道方向的规范化,这种规范化不会在序列内共享参数。
提升模型
在上图1中的预测模型\(Predictions\),使用1层Transformer层代替线性分类器,使用所有的\(z_1,z_2,...,z_t\)去预测\(\phi(x_{t+k})\);在回归模型\(g_{ar}\)中,该文尝试使用LSTM,而非GRU可以带来性能的小幅提升。
跨语种音素分类能力
在该文中,为了衡量获得的无监督学习音素表征的质量,在预训练之后,冻结模型,仅针对目标语言单独训练一个线性分类器。特别地,对8个窗口的音素特征进行线性分类,然后利用CTC(Connectionist Temporal Classification)损失度量模型预测值和真实值。
论文代码分析
入口函数位于cpc/train.py,对比预测编码的编码器和自回归模型位于cpc/model.py,预测模型及损失函数位于cpc/criterion/criterion.py,模型默认参数位于cpc/cpc_default_config.py。
在run()函数中开始训练和验证过程,其中,在trainStep()函数中训练,在valStep()函数中验证。在训练阶段,cpcModel()输入一批音频数据,输出音频经过编码且自回归模型之后的特征,音频编码后的数据,以及标签,标签是原样输入、原样输出;之后利用预测模型输出损失和准确率;最后反传。
c_feature, encoded_data, label = cpcModel(batchData, label)
allLosses, allAcc = cpcCriterion(c_feature, encoded_data, label)
totLoss = allLosses.sum()
totLoss.backward()
# Show grads ?
optimizer.step()
optimizer.zero_grad()
这里的标签是数据集中的说话人或者音素标签(该代码中,默认情况下的监督学习是说话人分类)。在cpc/dataset.py中,
def __getitem__(self, idx):
if idx < 0 or idx >= len(self.data) - self.sizeWindow - 1:
print(idx)
outData = self.data[idx:(self.sizeWindow + idx)].view(1, -1)
label = torch.tensor(self.getSpeakerLabel(idx), dtype=torch.long)
if self.phoneSize > 0:
label_phone = torch.tensor(self.getPhonem(idx), dtype=torch.long)
if not self.doubleLabels:
label = label_phone
else:
label_phone = torch.zeros(1)
if self.doubleLabels:
return outData, label, label_phone
return outData, label
对比预测编码的模型看起来很简单,由编码器和自回归模型组成。在cpc/model.py中,
class CPCModel(nn.Module):
def __init__(self,
encoder,
AR):
super(CPCModel, self).__init__()
self.gEncoder = encoder
self.gAR = AR
def forward(self, batchData, label):
encodedData = self.gEncoder(batchData).permute(0, 2, 1)
cFeature = self.gAR(encodedData)
return cFeature, encodedData, label
其中,编码器和原始对比预测编码的实现一致,由5个卷积核大小分别为10、8、4、4、4的卷积层组成,只不过在该文中,为了提升模型训练的稳定性,批规范化被替换为通道规范化。提供的代码是实验代码,因此会存在多个规范化选项,默认设置和论文中的最优实验设置保持一致,使用通道规范化,下同。在cpc/model.py中,
class CPCEncoder(nn.Module):
def __init__(self,
sizeHidden=512,
normMode="layerNorm"):
super(CPCEncoder, self).__init__()
validModes = ["batchNorm", "instanceNorm", "ID", "layerNorm"]
if normMode not in validModes:
raise ValueError(f"Norm mode must be in {validModes}")
if normMode == "instanceNorm":
def normLayer(x): return nn.InstanceNorm1d(x, affine=True)
elif normMode == "ID":
normLayer = IDModule
elif normMode == "layerNorm":
normLayer = ChannelNorm
else:
normLayer = nn.BatchNorm1d
self.dimEncoded = sizeHidden
self.conv0 = nn.Conv1d(1, sizeHidden, 10, stride=5, padding=3)
self.batchNorm0 = normLayer(sizeHidden)
self.conv1 = nn.Conv1d(sizeHidden, sizeHidden, 8, stride=4, padding=2)
self.batchNorm1 = normLayer(sizeHidden)
self.conv2 = nn.Conv1d(sizeHidden, sizeHidden, 4,
stride=2, padding=1)
self.batchNorm2 = normLayer(sizeHidden)
self.conv3 = nn.Conv1d(sizeHidden, sizeHidden, 4, stride=2, padding=1)
self.batchNorm3 = normLayer(sizeHidden)
self.conv4 = nn.Conv1d(sizeHidden, sizeHidden, 4, stride=2, padding=1)
self.batchNorm4 = normLayer(sizeHidden)
self.DOWNSAMPLING = 160
def getDimOutput(self):
return self.conv4.out_channels
def forward(self, x):
x = F.relu(self.batchNorm0(self.conv0(x)))
x = F.relu(self.batchNorm1(self.conv1(x)))
x = F.relu(self.batchNorm2(self.conv2(x)))
x = F.relu(self.batchNorm3(self.conv3(x)))
x = F.relu(self.batchNorm4(self.conv4(x)))
return x
具体地,在cpc/model.py中,传入通道规范化的张量大小为:\([N,C_{out},L_{out}]\),也就是说,对张量dim=1的维度上求平均和方差,然后训练self.weight和self.bias恢复参数,具体实现为:
class ChannelNorm(nn.Module):
def __init__(self,
numFeatures,
epsilon=1e-05,
affine=True):
super(ChannelNorm, self).__init__()
if affine:
self.weight = nn.parameter.Parameter(torch.Tensor(1,
numFeatures, 1))
self.bias = nn.parameter.Parameter(torch.Tensor(1, numFeatures, 1))
else:
self.weight = None
self.bias = None
self.epsilon = epsilon
self.p = 0
self.affine = affine
self.reset_parameters()
def reset_parameters(self):
if self.affine:
torch.nn.init.ones_(self.weight)
torch.nn.init.zeros_(self.bias)
def forward(self, x):
cumMean = x.mean(dim=1, keepdim=True)
cumVar = x.var(dim=1, keepdim=True)
x = (x - cumMean)*torch.rsqrt(cumVar + self.epsilon)
if self.weight is not None:
x = x * self.weight + self.bias
return x
另一方面,相比原始的对比预测编码中使用GRU作为自回归模型,该文将自回归模型设置为LSTM。具体地,在cpc/model.py中,
class CPCAR(nn.Module):
def __init__(self,
dimEncoded,
dimOutput,
keepHidden,
nLevelsGRU,
mode="GRU",
reverse=False):
super(CPCAR, self).__init__()
self.RESIDUAL_STD = 0.1
if mode == "LSTM":
self.baseNet = nn.LSTM(dimEncoded, dimOutput,
num_layers=nLevelsGRU, batch_first=True)
elif mode == "RNN":
self.baseNet = nn.RNN(dimEncoded, dimOutput,
num_layers=nLevelsGRU, batch_first=True)
else:
self.baseNet = nn.GRU(dimEncoded, dimOutput,
num_layers=nLevelsGRU, batch_first=True)
self.hidden = None
self.keepHidden = keepHidden
self.reverse = reverse
def getDimOutput(self):
return self.baseNet.hidden_size
def forward(self, x):
if self.reverse:
x = torch.flip(x, [1])
try:
self.baseNet.flatten_parameters()
except RuntimeError:
pass
x, h = self.baseNet(x, self.hidden)
if self.keepHidden:
if isinstance(h, tuple):
self.hidden = tuple(x.detach() for x in h)
else:
self.hidden = h.detach()
# For better modularity, a sequence's order should be preserved
# by each module
if self.reverse:
x = torch.flip(x, [1])
return x
在计算损失值时,使用cpc/criterion/criterion.py中的CPCUnsupervisedCriterion():
class CPCUnsupersivedCriterion(BaseCriterion):
def __init__(self,
nPredicts, # Number of steps
dimOutputAR, # Dimension of G_ar
dimOutputEncoder, # Dimension of the convolutional net
negativeSamplingExt, # Number of negative samples to draw
mode=None,
rnnMode=False,
dropout=False,
speakerEmbedding=0,
nSpeakers=0,
sizeInputSeq=128):
super(CPCUnsupersivedCriterion, self).__init__()
...
self.wPrediction = PredictionNetwork(
nPredicts, dimOutputAR, dimOutputEncoder, rnnMode=rnnMode,
dropout=dropout, sizeInputSeq=sizeInputSeq - nPredicts)
self.nPredicts = nPredicts
self.negativeSamplingExt = negativeSamplingExt
self.lossCriterion = nn.CrossEntropyLoss()
...
def sampleClean(self, encodedData, windowSize):
...
for k in range(1, self.nPredicts + 1):
# Positive samples
if k < self.nPredicts:
posSeq = encodedData[:, k:-(self.nPredicts-k)]
else:
posSeq = encodedData[:, k:]
posSeq = posSeq.view(batchSize, 1, posSeq.size(1), dimEncoded)
fullSeq = torch.cat((posSeq, negExt), dim=1)
outputs.append(fullSeq)
return outputs, labelLoss
...
def forward(self, cFeature, encodedData, label):
...
predictions = self.wPrediction(cFeature, sampledData)
outLosses = [0 for x in range(self.nPredicts)]
outAcc = [0 for x in range(self.nPredicts)]
for k, locPreds in enumerate(predictions[:self.nPredicts]):
locPreds = locPreds.permute(0, 2, 1)
locPreds = locPreds.contiguous().view(-1, locPreds.size(2))
lossK = self.lossCriterion(locPreds, labelLoss)
outLosses[k] += lossK.view(1, -1)
_, predsIndex = locPreds.max(1)
outAcc[k] += torch.sum(predsIndex == labelLoss).float().view(1, -1)
return torch.cat(outLosses, dim=1), \
torch.cat(outAcc, dim=1) / (windowSize * batchSize)
其中,代码中的PredictionNetwork()即为生成模型,相比于原始的对比预测编码,该文为了提升模型能力,将线性分类层修改为一层Transformer层。在cpc/criterion/criterion.py中,
class PredictionNetwork(nn.Module):
def __init__(self,
nPredicts,
dimOutputAR,
dimOutputEncoder,
rnnMode=None,
dropout=False,
sizeInputSeq=116):
super(PredictionNetwork, self).__init__()
self.predictors = nn.ModuleList()
self.RESIDUAL_STD = 0.01
self.dimOutputAR = dimOutputAR
self.dropout = nn.Dropout(p=0.5) if dropout else None
for i in range(nPredicts):
if rnnMode == 'RNN':
self.predictors.append(
nn.RNN(dimOutputAR, dimOutputEncoder))
self.predictors[-1].flatten_parameters()
elif rnnMode == 'LSTM':
self.predictors.append(
nn.LSTM(dimOutputAR, dimOutputEncoder, batch_first=True))
self.predictors[-1].flatten_parameters()
elif rnnMode == 'ffd':
self.predictors.append(
FFNetwork(dimOutputAR, dimOutputEncoder,
dimOutputEncoder, 0))
elif rnnMode == 'conv4':
self.predictors.append(
ShiftedConv(dimOutputAR, dimOutputEncoder, 4))
elif rnnMode == 'conv8':
self.predictors.append(
ShiftedConv(dimOutputAR, dimOutputEncoder, 8))
elif rnnMode == 'conv12':
self.predictors.append(
ShiftedConv(dimOutputAR, dimOutputEncoder, 12))
elif rnnMode == 'transformer':
from transformers import buildTransformerAR
self.predictors.append(
buildTransformerAR(dimOutputEncoder,
1,
sizeInputSeq,
False))
else:
self.predictors.append(
nn.Linear(dimOutputAR, dimOutputEncoder, bias=False))
if dimOutputEncoder > dimOutputAR:
residual = dimOutputEncoder - dimOutputAR
self.predictors[-1].weight.data.copy_(torch.cat([torch.randn(
dimOutputAR, dimOutputAR), self.RESIDUAL_STD * torch.randn(residual, dimOutputAR)], dim=0))
def forward(self, c, candidates):
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号